深入探讨 AI 编程的三个核心领域:自动化代码生成、低代码 / 无代码开发以及算法优化实践,通过具体的代码示例、流程图解和实际应用案例,展示 AI 如何改变传统的软件开发模式。
AI驱动的编程革命:自动化代码生成、低代码开发与算法优化 摘要: 人工智能技术正在深刻改变软件开发方式,GitHub 2023调查显示70%开发者已使用AI辅助编程工具。本文探讨了三大AI编程领域:1)自动化代码生成,基于GPT等大模型实现自然语言到代码的转换;2)低代码/无代码开发,通过可视化界面和AI增强实现快速应用构建;3)算法优化,利用AI自动提升代码性能和机器学习模型效果。
引言:AI 驱动的编程革命
人工智能正在重塑软件开发的方方面面,从代码的自动生成功到复杂算法的优化,AI 技术正逐步成为开发者的得力助手。根据 GitHub 的 2023 年开发者调查,超过 70% 的开发者已经在使用或试验 AI 辅助编程工具,其中 65% 的开发者报告说这些工具显著提高了他们的工作效率。
本文将深入探讨 AI 编程的三个核心领域:自动化代码生成、低代码 / 无代码开发以及算法优化实践,通过具体的代码示例、流程图解和实际应用案例,展示 AI 如何改变传统的软件开发模式,以及开发者如何利用这些技术提升生产力和代码质量。

一、自动化代码生成
自动化代码生成是指利用 AI 模型根据自然语言描述、现有代码片段或特定需求自动生成完整或部分代码的技术。这一技术极大地减少了开发者的重复劳动,使他们能够专注于更复杂的逻辑设计和问题解决。
1.1 自动化代码生成的技术原理
自动化代码生成系统通常基于大型语言模型 (LLM),如 GPT-4、CodeLlama 等,这些模型通过在海量代码库上训练,学习到了编程语言的语法、语义和常见模式。
其工作原理可以概括为:
- 接收用户输入(自然语言描述、代码片段等)
- 对输入进行语义理解和上下文分析
- 基于预训练的知识生成符合要求的代码
- 对生成的代码进行语法和逻辑校验
- 返回最终结果给用户
graph TD
A[用户输入需求] -->
B[需求解析与理解] B -->
C[代码结构规划] C --> D[代码生成]
D --> E[代码语法校验]
E --> F{校验通过?}
F -->|是|
G[代码逻辑优化]
F -->|否|
H[重新生成代码] H --> D
G --> I[输出最终代码]
1.2 基于 GPT 模型的代码生成实践
下面是一个使用 OpenAI 的 GPT 模型进行代码生成的示例,该示例展示了如何通过自然语言描述让 AI 生成一个图像处理的 Python 函数。
import openai
import re
import subprocess
import tempfile
import os
# 配置API密钥
openai.api_key = "your-api-key-here"
def generate_code(prompt, language="python"):
"""
使用OpenAI的GPT模型生成代码
参数:
prompt: 自然语言描述的需求
language: 目标编程语言
返回:
生成的代码字符串
"""
try:
# 构建提示词
full_prompt = f"请生成{language}代码来实现以下功能:{prompt}\n"
full_prompt += "要求:代码完整可运行,包含必要的注释,不要有多余的解释。"
# 调用OpenAI API
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "system", "content": f"你是一位精通{language}编程的专家。"},
{"role": "user", "content": full_prompt}
],
temperature=0.7, # 控制生成的随机性,0表示更确定,1表示更多样
max_tokens=1000 # 最大生成的token数
)
# 提取生成的代码,去除可能的markdown格式
code = response.choices[0].message['content']
code = re.sub(r'^```[^\n]*\n', '', code) # 移除开头的```python
code = re.sub(r'\n```$', '', code) # 移除结尾的```
return code
except Exception as e:
print(f"代码生成失败: {str(e)}")
return None
def test_generated_code(code):
"""
简单测试生成的Python代码
"""
if not code:
return False, "没有可测试的代码"
try:
# 创建临时文件
with tempfile.NamedTemporaryFile(mode='w', suffix='.py', delete=False) as f:
f.write(code)
temp_filename = f.name
# 运行代码并捕获输出
result = subprocess.run(
['python', temp_filename],
capture_output=True,
text=True,
timeout=10
)
# 清理临时文件
os.unlink(temp_filename)
# 检查运行结果
if result.returncode == 0:
return True, f"代码运行成功。输出:\n{result.stdout}"
else:
return False, f"代码运行出错。错误信息:\n{result.stderr}"
except Exception as e:
return False, f"测试过程出错: {str(e)}"
if __name__ == "__main__":
# 示例:生成一个图像增强的函数
prompt = """
编写一个Python函数,实现对图像的增强处理。
功能包括:
1. 调整亮度和对比度
2. 锐化处理
3. 自动对比度调整
函数应该接收图像路径作为输入,处理后保存到指定路径。
请使用OpenCV库实现。
"""
# 生成代码
print("正在生成代码...")
generated_code = generate_code(prompt)
if generated_code:
print("\n生成的代码:")
print("-" * 80)
print(generated_code)
print("-" * 80)
# 测试代码
print("\n正在测试代码...")
success, message = test_generated_code(generated_code)
print(message)
1.3 自动化代码生成的应用场景
自动化代码生成技术在多个场景中都有广泛应用:
-
快速原型开发:根据需求描述快速生成可用的代码原型,加速开发周期。
-
API 集成:自动生成与各种 API 交互的代码,减少手动编写的错误。
-
数据处理脚本:根据数据处理需求自动生成 ETL 脚本、数据分析代码等。
-
单元测试生成:为现有代码自动生成单元测试,提高代码覆盖率。
-
代码转换:将一种编程语言的代码转换为另一种编程语言。
下面是一个自动生成单元测试的示例:
import openai
import re
# 配置API密钥
openai.api_key = "your-api-key-here"
def generate_tests(function_code):
"""为给定的函数代码生成单元测试"""
prompt = f"""
请为以下Python函数生成单元测试代码,使用unittest框架:
{function_code}
要求:
1. 测试用例应覆盖正常情况、边界情况和异常情况
2. 每个测试用例应有明确的注释
3. 代码应可直接运行,包含必要的导入语句
4. 不要有多余的解释,只返回测试代码
"""
try:
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "system", "content": "你是一位精通Python单元测试的专家。"},
{"role": "user", "content": prompt}
],
temperature=0.6,
max_tokens=1000
)
# 提取并清理代码
tests = response.choices[0].message['content']
tests = re.sub(r'^```[^\n]*\n', '', tests)
tests = re.sub(r'\n```$', '', tests)
return tests
except Exception as e:
print(f"生成测试失败: {str(e)}")
return None
# 示例函数:计算斐波那契数列
function_to_test = """
def fibonacci(n):
\"\"\"计算斐波那契数列的第n项
参数:
n: 非负整数,要计算的项数
返回:
斐波那契数列的第n项
异常:
ValueError: 如果n为负数
\"\"\"
if not isinstance(n, int):
raise TypeError("n必须是整数")
if n < 0:
raise ValueError("n不能为负数")
if n == 0:
return 0
elif n == 1:
return 1
else:
a, b = 0, 1
for _ in range(2, n + 1):
a, b = b, a + b
return b
"""
# 生成测试
tests = generate_tests(function_to_test)
if tests:
print("生成的单元测试代码:")
print("-" * 80)
print(tests)
print("-" * 80)
1.4 自动化代码生成的优势与挑战
优势:
- 提高开发效率:减少重复性编码工作,让开发者专注于核心逻辑。
- 降低入门门槛:帮助新手快速编写可用代码,加速学习过程。
- 减少人为错误:AI 生成的代码通常遵循最佳实践,减少语法错误。
- 知识传播:将优秀的编程模式和实践通过生成的代码传播给更多开发者。
挑战:
- 代码质量不稳定:生成的代码可能存在逻辑错误或安全隐患。
- 过度依赖问题:开发者可能逐渐失去手动编码能力和深入理解。
- 知识产权问题:生成的代码可能包含受版权保护的内容。
- 上下文理解有限:复杂需求下,AI 可能无法完全理解上下文和系统整体架构。

二、低代码 / 无代码开发
低代码 / 无代码 (LC/NC) 开发平台允许开发者通过图形化界面和配置而非传统编码来构建应用程序。AI 技术的融入进一步增强了这些平台的能力,使应用开发更加高效和普及。
2.1 低代码 / 无代码开发的核心概念
低代码开发平台提供了可视化的开发环境,开发者通过拖拽组件、配置参数等方式构建应用,只需编写少量代码即可实现复杂功能。无代码平台则更进一步,完全不需要编写代码,适合非技术人员使用。
AI 赋能的低代码 / 无代码平台具有以下特点:
- 智能组件推荐:根据应用场景推荐合适的 UI 组件和业务逻辑模块。
- 自动化流程生成:根据业务需求自动生成工作流程。
- 自然语言编程:通过自然语言描述生成应用功能。
- 智能调试:自动识别并修复应用中的问题。
graph LR
A[业务需求] --> B[自然语言描述]
B --> C[AI需求解析]
C --> D[组件推荐与配置]
D --> E[流程自动化生成]
E --> F[可视化界面设计]
F --> G[少量代码补充]
G --> H[应用测试]
H --> I[部署上线]
I --> J[运行监控与优化]
2.2 主流低代码 / 无代码平台介绍
目前市场上有多种成熟的低代码 / 无代码平台,各有特色:
- Microsoft Power Apps:与 Office 生态深度集成,适合企业内部应用。
- Appian:专注于业务流程管理和企业级应用。
- Mendix:强调快速开发和团队协作。
- OutSystems:提供全栈开发能力,性能优秀。
- Airtable:轻量级平台,适合数据管理类应用。
- AppSmith:开源平台,适合开发者构建内部工具。
下面以 AppSmith 为例,展示如何使用低代码平台快速构建一个数据仪表盘应用:
{
"appName": "销售数据仪表盘",
"description": "实时监控销售数据和趋势的仪表盘应用",
"pages": [
{
"name": "主仪表盘",
"layout": "responsive",
"widgets": [
{
"type": "Text",
"properties": {
"text": "销售数据仪表盘",
"style": {
"fontSize": "24px",
"fontWeight": "bold",
"marginBottom": "16px"
}
},
"position": {
"x": 0,
"y": 0,
"width": 12,
"height": 1
}
},
{
"type": "DatePicker",
"name": "dateRangePicker",
"properties": {
"label": "选择日期范围",
"mode": "range",
"defaultValue": {
"start": "2023-01-01",
"end": "2023-12-31"
}
},
"position": {
"x": 0,
"y": 1,
"width": 6,
"height": 1
}
},
{
"type": "Dropdown",
"name": "regionFilter",
"properties": {
"label": "选择地区",
"data": [
{"label": "全部地区", "value": "all"},
{"label": "北美", "value": "na"},
{"label": "欧洲", "value": "eu"},
{"label": "亚太", "value": "apac"}
],
"defaultValue": "all"
},
"position": {
"x": 6,
"y": 1,
"width": 6,
"height": 1
}
},
{
"type": "Chart",
"name": "salesTrendChart",
"properties": {
"title": "销售趋势",
"type": "line",
"dataSource": {
"type": "API",
"config": {
"url": "https://api.example.com/sales/trend",
"method": "GET",
"params": {
"startDate": "{{dateRangePicker.selectedDate.start}}",
"endDate": "{{dateRangePicker.selectedDate.end}}",
"region": "{{regionFilter.selectedOption.value}}"
}
}
},
"series": [
{
"name": "销售额",
"xKey": "date",
"yKey": "amount"
}
],
"xAxis": {
"title": "日期"
},
"yAxis": {
"title": "销售额(USD)"
}
},
"position": {
"x": 0,
"y": 2,
"width": 12,
"height": 4
}
},
{
"type": "StatBox",
"name": "totalSalesBox",
"properties": {
"title": "总销售额",
"value": "{{totalSales.data.amount}}",
"prefix": "$",
"trend": {
"value": "{{totalSales.data.change}}%",
"type": "{{totalSales.data.change >= 0 ? 'positive' : 'negative'}}"
},
"dataSource": {
"type": "API",
"config": {
"url": "https://api.example.com/sales/total",
"method": "GET",
"params": {
"startDate": "{{dateRangePicker.selectedDate.start}}",
"endDate": "{{dateRangePicker.selectedDate.end}}",
"region": "{{regionFilter.selectedOption.value}}"
}
}
}
},
"position": {
"x": 0,
"y": 6,
"width": 3,
"height": 2
}
},
{
"type": "StatBox",
"name": "orderCountBox",
"properties": {
"title": "订单数量",
"value": "{{orderCount.data.count}}",
"trend": {
"value": "{{orderCount.data.change}}%",
"type": "{{orderCount.data.change >= 0 ? 'positive' : 'negative'}}"
},
"dataSource": {
"type": "API",
"config": {
"url": "https://api.example.com/orders/count",
"method": "GET",
"params": {
"startDate": "{{dateRangePicker.selectedDate.start}}",
"endDate": "{{dateRangePicker.selectedDate.end}}",
"region": "{{regionFilter.selectedOption.value}}"
}
}
}
},
"position": {
"x": 3,
"y": 6,
"width": 3,
"height": 2
}
},
{
"type": "Table",
"name": "topProductsTable",
"properties": {
"title": "畅销产品",
"dataSource": {
"type": "API",
"config": {
"url": "https://api.example.com/products/top",
"method": "GET",
"params": {
"startDate": "{{dateRangePicker.selectedDate.start}}",
"endDate": "{{dateRangePicker.selectedDate.end}}",
"region": "{{regionFilter.selectedOption.value}}",
"limit": 10
}
}
},
"columns": [
{"label": "产品名称", "key": "name"},
{"label": "销售额", "key": "sales", "format": "currency"},
{"label": "销量", "key": "quantity"},
{"label": "占比", "key": "percentage", "format": "percentage"}
],
"pagination": true
},
"position": {
"x": 0,
"y": 8,
"width": 12,
"height": 5
}
}
]
}
],
"datasources": [
{
"name": "salesAPI",
"type": "REST API",
"baseUrl": "https://api.example.com",
"authentication": {
"type": "API Key",
"key": "X-API-Key",
"value": "{{env.API_KEY}}"
}
}
],
"queries": [
{
"name": "totalSales",
"dataSource": "salesAPI",
"endpoint": "/sales/total",
"method": "GET",
"params": {
"startDate": "{{dateRangePicker.selectedDate.start}}",
"endDate": "{{dateRangePicker.selectedDate.end}}",
"region": "{{regionFilter.selectedOption.value}}"
},
"runOnLoad": true,
"onSuccess": "",
"onError": "showAlert('获取销售数据失败', 'error')"
}
],
"variables": [
{
"name": "isLoading",
"type": "boolean",
"defaultValue": false
}
],
"actions": [
{
"name": "refreshData",
"type": "script",
"code": "setIsLoading(true);\nawait totalSales.run();\nawait orderCount.run();\nawait salesTrendChart.run();\nawait topProductsTable.run();\nsetIsLoading(false);"
}
]
}
2.3 AI 增强的低代码开发实践
AI 技术为低代码平台带来了革命性的提升,特别是在需求理解、自动生成和智能推荐方面。下面是一个使用 AI 辅助生成低代码应用的示例:
import openai
import json
import re
# 配置API密钥
openai.api_key = "your-api-key-here"
def generate_lowcode_config(business_description):
"""
将业务描述转换为低代码平台的配置
参数:
business_description: 用自然语言描述的业务需求
返回:
低代码平台的配置JSON
"""
prompt = f"""
请将以下业务需求转换为AppSmith低代码平台的应用配置JSON:
{business_description}
要求:
1. 配置应包含页面、组件、数据源和必要的查询
2. 组件布局应合理,符合用户体验最佳实践
3. 生成完整的JSON结构,可直接导入AppSmith
4. 为动态数据使用适当的变量和绑定表达式
5. 不要有任何解释,只返回JSON
"""
try:
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "system", "content": "你是一位精通AppSmith低代码平台的专家,能将业务需求转换为完整的应用配置。"},
{"role": "user", "content": prompt}
],
temperature=0.7,
max_tokens=2000
)
# 提取并清理JSON
config_json = response.choices[0].message['content']
config_json = re.sub(r'^```[^\n]*\n', '', config_json)
config_json = re.sub(r'\n```$', '', config_json)
# 验证JSON格式
try:
parsed_json = json.loads(config_json)
return parsed_json
except json.JSONDecodeError:
print("生成的配置不是有效的JSON")
return None
except Exception as e:
print(f"生成配置失败: {str(e)}")
return None
def save_config(config, filename):
"""保存配置到JSON文件"""
if config:
with open(filename, 'w', encoding='utf-8') as f:
json.dump(config, f, ensure_ascii=False, indent=2)
print(f"配置已保存到 {filename}")
# 示例:自然语言描述的业务需求
business_requirement = """
创建一个客户管理系统,功能包括:
1. 显示客户列表,包含姓名、公司、邮箱、电话和注册日期
2. 可以通过姓名和公司筛选客户
3. 点击客户可查看详情
4. 包含添加新客户的表单,字段包括:
- 姓名(必填)
- 公司(必填)
- 邮箱(必填,需验证格式)
- 电话
- 地址
- 备注
5. 可以编辑和删除现有客户
6. 顶部显示客户总数统计
7. 使用REST API连接到后端服务,API端点包括:
- GET /api/customers - 获取客户列表
- GET /api/customers/{id} - 获取单个客户详情
- POST /api/customers - 添加新客户
- PUT /api/customers/{id} - 更新客户信息
- DELETE /api/customers/{id} - 删除客户
"""
# 生成低代码配置
print("正在根据业务需求生成低代码配置...")
app_config = generate_lowcode_config(business_requirement)
# 保存配置
if app_config:
save_config(app_config, "customer_management_app.json")
# 显示生成的页面和组件数量
pages_count = len(app_config.get('pages', []))
widgets_count = sum(len(page.get('widgets', [])) for page in app_config.get('pages', []))
print(f"生成成功!包含 {pages_count} 个页面和 {widgets_count} 个组件")
2.4 低代码 / 无代码开发的适用场景与限制
适用场景:
- 内部工具开发:快速构建企业内部需要的管理系统、数据看板等。
- 原型验证:快速验证产品概念和业务流程。
- 小型应用开发:功能相对简单的应用,如表单收集、数据展示等。
- 业务用户自助开发:让非技术人员也能构建满足自身需求的应用。
- 快速迭代场景:需要频繁调整和更新的业务应用。
限制:
- 定制化能力有限:复杂的业务逻辑和特殊需求难以满足。
- 性能瓶颈:生成的应用在高并发场景下可能存在性能问题。
- 平台锁定:迁移到其他平台或传统开发模式成本较高。
- 安全性考量:通用平台可能存在安全隐患,需要额外配置。
- 复杂集成挑战:与 legacy 系统的深度集成可能比较困难。

三、算法优化实践
算法优化是 AI 编程的另一个重要应用领域,通过 AI 技术可以自动优化算法的效率、准确性和资源消耗。这不仅适用于传统的计算机科学算法,也广泛应用于机器学习模型的优化。
3.1 算法优化的基本概念与流程
算法优化是指通过改进算法结构、调整参数设置或采用更高效的实现方式,提高算法在时间复杂度、空间复杂度或结果质量等方面的表现。
AI 驱动的算法优化流程通常包括:
- 性能分析:识别算法的瓶颈和待优化点。
- 优化策略生成:基于历史优化案例生成可能的优化方案。
- 方案评估:对不同优化方案进行模拟评估。
- 实现与测试:应用优化方案并验证效果。
- 迭代优化:根据测试结果进一步优化。
graph TD
A[原始算法] --> B[性能基准测试]
B --> C[瓶颈分析与定位]
C --> D[AI推荐优化策略]
D --> E[生成多个优化方案]
E --> F[方案模拟评估]
F --> G{效果达标?}
G -->|是| H[实现最优方案]
G -->|否| I[调整策略重新优化]
I --> D
H --> J[性能对比测试]
J --> K[优化方案文档化]
K --> L[部署优化后的算法]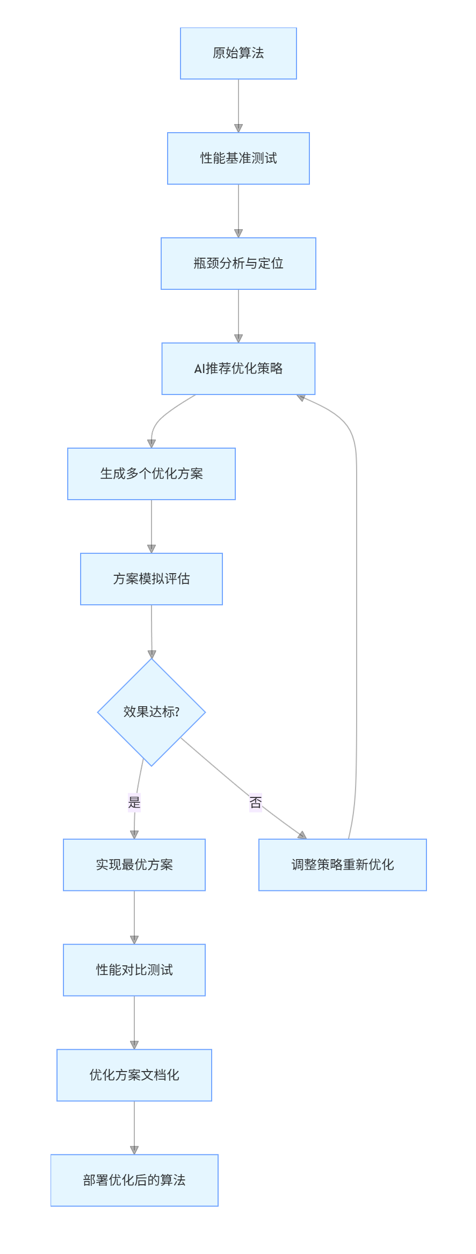
3.2 基于 AI 的代码优化示例
下面是一个使用 AI 辅助优化 Python 代码性能的示例,展示如何通过 AI 分析并改进代码效率:
import openai
import re
import time
import memory_profiler
import json
# 配置API密钥
openai.api_key = "your-api-key-here"
def analyze_and_optimize_code(code, function_name=None):
"""
使用AI分析并优化代码
参数:
code: 待优化的代码字符串
function_name: 可选,指定要优化的函数名
返回:
优化后的代码和优化建议
"""
focus = f"专注于优化函数 {function_name}" if function_name else "专注于整体代码优化"
prompt = f"""
请分析并优化以下Python代码,提高其性能:
{code}
要求:
1. {focus}
2. 指出当前代码的性能瓶颈
3. 提供优化后的完整代码
4. 解释优化的具体方法和预期效果
5. 保持代码功能不变
6. 优化应关注时间复杂度和空间复杂度的改进
"""
try:
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "system", "content": "你是一位Python性能优化专家,擅长分析代码瓶颈并提供高效的优化方案。"},
{"role": "user", "content": prompt}
],
temperature=0.6,
max_tokens=1500
)
return response.choices[0].message['content']
except Exception as e:
print(f"代码优化分析失败: {str(e)}")
return None
def measure_performance(code, function_name, *args, **kwargs):
"""
测量函数的性能(执行时间和内存使用)
"""
# 将代码和测试逻辑组合
test_code = f"""
{code}
import time
import memory_profiler
def test_performance():
start_time = time.time()
mem_usage = memory_profiler.memory_usage(
(lambda: {function_name}(*{args}, **{kwargs})),
interval=0.01
)
end_time = time.time()
result = {{
"execution_time": end_time - start_time,
"max_memory": max(mem_usage),
"avg_memory": sum(mem_usage) / len(mem_usage)
}}
print(json.dumps(result))
test_performance()
"""
# 执行测试代码并捕获输出
import subprocess
import sys
result = subprocess.run(
[sys.executable, "-c", test_code],
capture_output=True,
text=True
)
try:
return json.loads(result.stdout)
except:
print(f"性能测试失败: {result.stderr}")
return None
# 示例:待优化的代码 - 计算大量数据的统计信息
original_code = """
def calculate_statistics(data):
\"\"\"计算数据的统计信息:平均值、中位数、众数、标准差\"\"\"
# 计算平均值
total = 0
for num in data:
total += num
mean = total / len(data)
# 计算中位数
sorted_data = []
for num in data:
inserted = False
for i in range(len(sorted_data)):
if num < sorted_data[i]:
sorted_data.insert(i, num)
inserted = True
break
if not inserted:
sorted_data.append(num)
n = len(sorted_data)
if n % 2 == 1:
median = sorted_data[n // 2]
else:
median = (sorted_data[n // 2 - 1] + sorted_data[n // 2]) / 2
# 计算众数
frequency = {}
for num in data:
if num in frequency:
frequency[num] += 1
else:
frequency[num] = 1
max_freq = 0
mode = None
for num, count in frequency.items():
if count > max_freq:
max_freq = count
mode = num
# 计算标准差
squared_diff_sum = 0
for num in data:
squared_diff_sum += (num - mean) **2
std_dev = (squared_diff_sum / len(data))** 0.5
return {
"mean": mean,
"median": median,
"mode": mode,
"std_dev": std_dev
}
"""
# 分析并优化代码
print("正在分析并优化代码...")
optimization_result = analyze_and_optimize_code(original_code, "calculate_statistics")
if optimization_result:
print("\n优化分析结果:")
print("-" * 80)
print(optimization_result)
print("-" * 80)
# 提取优化后的代码
optimized_code_match = re.search(r'```python(.*?)```', optimization_result, re.DOTALL)
if optimized_code_match:
optimized_code = optimized_code_match.group(1)
# 生成测试数据
test_data = list(range(1, 10000)) # 简单的测试数据
# 测量原始代码性能
print("\n测量原始代码性能...")
original_perf = measure_performance(original_code, "calculate_statistics", test_data)
# 测量优化后代码性能
print("测量优化后代码性能...")
optimized_perf = measure_performance(optimized_code, "calculate_statistics", test_data)
if original_perf and optimized_perf:
print("\n性能对比:")
print(f"原始代码执行时间: {original_perf['execution_time']:.4f}秒")
print(f"优化后执行时间: {optimized_perf['execution_time']:.4f}秒")
print(f"时间改进: {100 * (1 - optimized_perf['execution_time']/original_perf['execution_time']):.2f}%")
print(f"\n原始代码最大内存使用: {original_perf['max_memory']:.4f}MB")
print(f"优化后最大内存使用: {optimized_perf['max_memory']:.4f}MB")
print(f"内存改进: {100 * (1 - optimized_perf['max_memory']/original_perf['max_memory']):.2f}%")
3.3 机器学习模型的自动优化
AI 不仅可以优化传统算法,还能显著提升机器学习模型的优化效率。自动机器学习 (AutoML) 技术可以自动完成特征工程、模型选择、超参数调优等复杂过程。
下面是一个使用 AutoML 工具优化机器学习模型的示例:
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
import autosklearn.classification
import time
import matplotlib.pyplot as plt
# 加载数据集
data = load_breast_cancer()
X, y = data.data, data.target
feature_names = data.feature_names
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
print(f"数据集信息: {X.shape[0]}个样本, {X.shape[1]}个特征")
print(f"类别分布: 良性={np.sum(y == 1)}, 恶性={np.sum(y == 0)}")
# 1. 使用默认参数的随机森林作为基准
from sklearn.ensemble import RandomForestClassifier
start_time = time.time()
rf = RandomForestClassifier(random_state=42)
rf.fit(X_train, y_train)
rf_time = time.time() - start_time
rf_pred = rf.predict(X_test)
rf_accuracy = accuracy_score(y_test, rf_pred)
print("\n基准模型 (随机森林) 结果:")
print(f"训练时间: {rf_time:.4f}秒")
print(f"测试集准确率: {rf_accuracy:.4f}")
print(classification_report(y_test, rf_pred))
# 2. 使用Auto-sklearn自动优化模型
print("\n开始AutoML模型优化...")
start_time = time.time()
# 初始化Auto-sklearn分类器
automl = autosklearn.classification.AutoSklearnClassifier(
time_left_for_this_task=60, # 总优化时间(秒)
per_run_time_limit=10, # 每个模型的运行时间限制(秒)
n_jobs=-1, # 使用所有可用的CPU核心
random_state=42,
ensemble_size=50 # 集成模型的大小
)
# 训练模型
automl.fit(X_train, y_train)
automl_time = time.time() - start_time
# 评估模型
automl_pred = automl.predict(X_test)
automl_accuracy = accuracy_score(y_test, automl_pred)
print("\nAutoML优化模型结果:")
print(f"优化时间: {automl_time:.4f}秒")
print(f"测试集准确率: {automl_accuracy:.4f}")
print(classification_report(y_test, automl_pred))
# 查看AutoML选择的最佳模型
print("\nAutoML选择的最佳模型:")
print(automl.show_models())
# 提取各模型的性能
results = pd.DataFrame(automl.cv_results_)
results = results.sort_values(by='rank_test_scores').reset_index(drop=True)
# 可视化不同模型的性能
plt.figure(figsize=(12, 6))
plt.bar(
results['param_classifier:__class__'].head(10),
results['mean_test_score'].head(10)
)
plt.xticks(rotation=45, ha='right')
plt.ylabel('平均测试分数')
plt.title('AutoML评估的前10个模型性能')
plt.tight_layout()
plt.show()
# 特征重要性分析
if hasattr(automl, 'leaderboard_'):
# 获取最佳模型
best_model_idx = automl.leaderboard_.index[0]
best_model = automl.show_models()[best_model_idx]['sklearn_classifier']
# 如果模型有特征重要性属性
if hasattr(best_model, 'feature_importances_'):
importances = best_model.feature_importances_
indices = np.argsort(importances)[::-1]
plt.figure(figsize=(12, 6))
plt.bar(range(X.shape[1]), importances[indices])
plt.xticks(range(X.shape[1]), [feature_names[i] for i in indices], rotation=90)
plt.title('特征重要性')
plt.tight_layout()
plt.show()
# 性能对比可视化
plt.figure(figsize=(10, 6))
models = ['随机森林(基准)', 'AutoML优化模型']
accuracies = [rf_accuracy, automl_accuracy]
times = [rf_time, automl_time]
x = np.arange(len(models))
width = 0.35
fig, ax1 = plt.subplots()
rects1 = ax1.bar(x - width/2, accuracies, width, label='准确率')
ax1.set_ylabel('准确率')
ax1.set_ylim(0.9, 1.0)
ax1.set_xticks(x)
ax1.set_xticklabels(models)
ax2 = ax1.twinx()
rects2 = ax2.bar(x + width/2, times, width, label='时间', color='orange')
ax2.set_ylabel('时间(秒)')
fig.tight_layout()
plt.title('模型性能对比')
plt.show()
3.4 算法优化的评估指标与最佳实践
评估算法优化效果需要综合考虑多个指标:
- 时间复杂度:算法执行所需的时间随输入规模增长的趋势。
- 空间复杂度:算法所需的内存空间随输入规模增长的趋势。
- 吞吐量:单位时间内处理的任务数量。
- 延迟:单个任务从开始到完成的时间。
- 资源利用率:CPU、内存、网络等资源的使用效率。
- 结果质量:对于优化问题,解的质量是否满足要求。
算法优化的最佳实践:
- 先测量后优化:基于实际性能数据确定优化方向,避免盲目优化。
- 渐进式优化:小步迭代,每次优化后都进行测试验证。
- 关注瓶颈:优先优化对整体性能影响最大的部分。
- 保持可读性:在性能和代码可读性之间取得平衡。
- 自动化测试:建立完善的测试体系,确保优化不影响功能正确性。
- 考虑实际场景:优化应针对真实的使用场景和数据分布。

四、综合案例:AI 驱动的全栈应用开发
下面我们通过一个综合案例,展示如何结合自动化代码生成、低代码开发和算法优化来构建一个完整的应用系统。
4.1 项目背景与需求
我们将开发一个 "智能销售预测系统",该系统需要:
- 从多个数据源收集销售历史数据
- 提供可视化的数据分析仪表盘
- 使用机器学习模型预测未来销售趋势
- 允许用户调整参数并查看不同场景的预测结果
- 生成可导出的预测报告
4.2 开发流程与技术选型

技术栈:
- 前端:使用低代码平台构建仪表盘和用户界面
- 后端:通过自动化代码生成 REST API
- 数据处理:AI 优化的 ETL 流程
- 预测模型:AutoML 优化的时间序列预测模型
- 部署:容器化部署到云平台
4.3 代码实现与开发过程
步骤 1:使用低代码平台构建前端界面
我们使用前面介绍的方法,通过自然语言描述生成前端配置:
# 生成前端配置的代码与前面类似,此处省略
# 结果是一个完整的低代码配置JSON,可直接导入低代码平台步骤 2:自动生成后端 API
使用代码生成工具创建数据处理和模型服务的 API:
from fastapi import FastAPI, HTTPException, Query
from pydantic import BaseModel
from typing import List, Optional, Dict, Any
import pandas as pd
import numpy as np
import joblib
import datetime
from sklearn.preprocessing import StandardScaler
import os
# 初始化FastAPI应用
app = FastAPI(title="智能销售预测系统API")
# 数据模型定义
class SalesData(BaseModel):
date: str
product_id: str
category: str
region: str
sales_amount: float
units_sold: int
class PredictionRequest(BaseModel):
product_id: str
prediction_days: int = 30
include_promotion: bool = False
promotion_strength: Optional[float] = None
economic_index: Optional[float] = None
class PredictionResult(BaseModel):
product_id: str
prediction_start_date: str
prediction_end_date: str
predictions: List[Dict[str, Any]]
confidence_interval: Dict[str, float]
model_version: str
# 加载模型和数据预处理组件
MODEL_PATH = "models/sales_prediction_model.pkl"
SCALER_PATH = "models/scaler.pkl"
try:
model = joblib.load(MODEL_PATH)
scaler = joblib.load(SCALER_PATH)
MODEL_VERSION = "v1.2.0"
except Exception as e:
print(f"模型加载警告: {str(e)}")
model = None
scaler = None
MODEL_VERSION = "unknown"
# 模拟数据库连接
class SalesDatabase:
def __init__(self):
self.data = pd.DataFrame(columns=[
"date", "product_id", "category", "region",
"sales_amount", "units_sold"
])
def insert_data(self, sales_data: List[SalesData]):
"""插入销售数据"""
new_data = pd.DataFrame([item.dict() for item in sales_data])
self.data = pd.concat([self.data, new_data], ignore_index=True)
# 确保日期列格式正确
self.data['date'] = pd.to_datetime(self.data['date'])
return len(new_data)
def get_historical_data(self, product_id: str, start_date: str = None, end_date: str = None) -> pd.DataFrame:
"""获取产品的历史销售数据"""
mask = self.data['product_id'] == product_id
if start_date:
mask &= self.data['date'] >= pd.to_datetime(start_date)
if end_date:
mask &= self.data['date'] <= pd.to_datetime(end_date)
return self.data[mask].sort_values('date')
def get_aggregated_sales(self, group_by: str = "date", start_date: str = None) -> pd.DataFrame:
"""获取聚合的销售数据"""
data = self.data.copy()
if start_date:
data = data[data['date'] >= pd.to_datetime(start_date)]
if group_by == "date":
return data.groupby('date')['sales_amount'].sum().reset_index()
elif group_by == "product":
return data.groupby('product_id')['sales_amount'].sum().reset_index()
elif group_by == "region":
return data.groupby('region')['sales_amount'].sum().reset_index()
elif group_by == "category":
return data.groupby('category')['sales_amount'].sum().reset_index()
else:
return data.groupby('date')['sales_amount'].sum().reset_index()
# 初始化数据库
db = SalesDatabase()
# API端点定义
@app.get("/health", response_model=Dict[str, Any])
def health_check():
"""健康检查端点"""
return {
"status": "healthy",
"timestamp": datetime.datetime.now().isoformat(),
"model_loaded": model is not None,
"model_version": MODEL_VERSION
}
@app.post("/data/insert", response_model=Dict[str, int])
def insert_sales_data(data: List[SalesData]):
"""插入销售数据"""
if not data:
raise HTTPException(status_code=400, detail="数据列表不能为空")
count = db.insert_data(data)
return {"inserted_count": count}
@app.get("/data/historical", response_model=Dict[str, Any])
def get_historical_data(
product_id: str,
start_date: Optional[str] = None,
end_date: Optional[str] = None
):
"""获取历史销售数据"""
historical_data = db.get_historical_data(product_id, start_date, end_date)
if historical_data.empty:
raise HTTPException(status_code=404, detail="未找到该产品的历史数据")
return {
"product_id": product_id,
"start_date": historical_data['date'].min().isoformat(),
"end_date": historical_data['date'].max().isoformat(),
"data": historical_data.to_dict('records')
}
@app.get("/data/aggregated", response_model=Dict[str, Any])
def get_aggregated_data(
group_by: str = Query("date", pattern="^(date|product|region|category)$"),
start_date: Optional[str] = None
):
"""获取聚合的销售数据"""
aggregated_data = db.get_aggregated_sales(group_by, start_date)
return {
"group_by": group_by,
"data": aggregated_data.to_dict('records')
}
@app.post("/predict", response_model=PredictionResult)
def predict_sales(request: PredictionRequest):
"""预测产品销售情况"""
if not model:
raise HTTPException(status_code=503, detail="预测模型未加载,请稍后再试")
# 获取历史数据用于预测
historical_data = db.get_historical_data(request.product_id)
if historical_data.empty:
raise HTTPException(status_code=404, detail="未找到该产品的历史数据,无法进行预测")
# 准备特征
last_date = pd.to_datetime(historical_data['date'].max())
future_dates = [last_date + datetime.timedelta(days=i+1) for i in range(request.prediction_days)]
# 提取历史销售趋势特征
recent_sales = historical_data.sort_values('date').tail(30)['sales_amount'].values
avg_recent = np.mean(recent_sales)
trend = recent_sales[-1] - recent_sales[0]
# 创建预测特征
features = []
for i in range(request.prediction_days):
day_of_week = future_dates[i].weekday()
month = future_dates[i].month
is_weekend = 1 if day_of_week >= 5 else 0
feature = [
i, # 未来天数
day_of_week,
month,
is_weekend,
avg_recent,
trend,
1 if request.include_promotion else 0,
request.promotion_strength or 0,
request.economic_index or 1.0
]
features.append(feature)
# 特征缩放
features_scaled = scaler.transform(features)
# 进行预测
predictions = model.predict(features_scaled)
# 计算置信区间(简化版)
std_dev = np.std(predictions) * 0.3
lower_bound = np.mean(predictions) - 1.96 * std_dev
upper_bound = np.mean(predictions) + 1.96 * std_dev
# 构建结果
prediction_list = [
{
"date": future_dates[i].isoformat(),
"predicted_sales": float(predictions[i]),
"lower_bound": float(predictions[i] - std_dev),
"upper_bound": float(predictions[i] + std_dev)
}
for i in range(request.prediction_days)
]
return PredictionResult(
product_id=request.product_id,
prediction_start_date=future_dates[0].isoformat(),
prediction_end_date=future_dates[-1].isoformat(),
predictions=prediction_list,
confidence_interval={
"lower_bound": float(lower_bound),
"upper_bound": float(upper_bound),
"confidence_level": 0.95
},
model_version=MODEL_VERSION
)
@app.get("/products", response_model=Dict[str, List[str]])
def get_products():
"""获取所有产品ID"""
products = db.data['product_id'].unique().tolist()
categories = db.data['category'].unique().tolist()
regions = db.data['region'].unique().tolist()
return {
"products": products,
"categories": categories,
"regions": regions
}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
步骤 3:优化预测模型
使用 AutoML 技术优化销售预测模型:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split, TimeSeriesSplit
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
import autosklearn.regression
import joblib
import time
import os
from datetime import datetime
# 设置随机种子,确保结果可复现
np.random.seed(42)
# 1. 数据加载与预处理
def load_and_preprocess_data(file_path: str = "data/sales_history.csv") -> pd.DataFrame:
"""加载并预处理销售数据"""
# 如果没有真实数据,生成模拟数据
if not os.path.exists(file_path):
print("真实数据不存在,生成模拟销售数据...")
return generate_synthetic_data()
# 加载真实数据
df = pd.read_csv(file_path)
# 数据类型转换
df['date'] = pd.to_datetime(df['date'])
# 检查缺失值
print(f"数据集中的缺失值:\n{df.isnull().sum()}")
# 填充缺失值
if df.isnull().any().any():
# 对数值型列使用前向填充
numeric_cols = df.select_dtypes(include=['float64', 'int64']).columns
df[numeric_cols] = df[numeric_cols].fillna(method='ffill')
# 对类别型列使用众数填充
categorical_cols = df.select_dtypes(include=['object']).columns
for col in categorical_cols:
df[col] = df[col].fillna(df[col].mode()[0])
return df
def generate_synthetic_data(n_samples: int = 10000) -> pd.DataFrame:
"""生成模拟销售数据"""
# 生成日期范围
dates = pd.date_range(start='2020-01-01', periods=n_samples, freq='D')
# 产品和地区
products = [f"P{i:03d}" for i in range(1, 21)]
categories = ["电子产品", "服装", "食品", "家居", "图书"]
regions = ["华北", "华东", "华南", "西北", "西南"]
# 随机分配产品、类别和地区
product_ids = np.random.choice(products, size=n_samples)
product_categories = np.array([categories[i % len(categories)] for i in range(len(products))])[
np.array([products.index(p) for p in product_ids])
]
region = np.random.choice(regions, size=n_samples)
# 生成基础销售额(带有季节性和趋势)
base_amount = 1000 + 2 * np.arange(n_samples) # 整体增长趋势
seasonal = 300 * np.sin(np.linspace(0, 20*np.pi, n_samples)) # 季节性波动
weekly_pattern = np.array([0.8, 0.7, 1.0, 1.1, 1.2, 1.5, 1.3] * (n_samples // 7 + 1))[:n_samples] # 周模式
# 产品和地区影响
product_factor = np.array([1.0 + (i % 5) * 0.2 for i in [products.index(p) for p in product_ids]])
region_factor = np.array([1.0 + regions.index(r) * 0.1 for r in region])
# 随机波动
noise = np.random.normal(0, 100, size=n_samples)
# 计算最终销售额
sales_amount = base_amount + seasonal * weekly_pattern + product_factor * 100 + region_factor * 50 + noise
sales_amount = np.maximum(100, sales_amount) # 确保销售额为正
# 计算销售量(基于销售额和随机单价)
unit_price = 50 + np.random.random(n_samples) * 150
units_sold = (sales_amount / unit_price).round().astype(int)
# 创建数据框
df = pd.DataFrame({
"date": dates,
"product_id": product_ids,
"category": product_categories,
"region": region,
"sales_amount": sales_amount,
"units_sold": units_sold
})
# 保存模拟数据供后续使用
os.makedirs("data", exist_ok=True)
df.to_csv("data/sales_history.csv", index=False)
return df
# 2. 特征工程
def create_features(df: pd.DataFrame) -> pd.DataFrame:
"""为时间序列预测创建特征"""
# 复制数据以避免修改原始数据
data = df.copy()
# 提取时间特征
data['day_of_week'] = data['date'].dt.dayofweek
data['month'] = data['date'].dt.month
data['day_of_month'] = data['date'].dt.day
data['is_weekend'] = data['day_of_week'].apply(lambda x: 1 if x >= 5 else 0)
data['is_month_start'] = data['date'].dt.is_month_start.astype(int)
data['is_month_end'] = data['date'].dt.is_month_end.astype(int)
# 滞后特征 - 过去7天和30天的销售额
for lag in [1, 7, 14, 30]:
data[f'lag_{lag}'] = data.groupby('product_id')['sales_amount'].shift(lag)
# 滚动统计特征
data['rolling_mean_7'] = data.groupby('product_id')['sales_amount'].transform(
lambda x: x.rolling(window=7, min_periods=1).mean()
)
data['rolling_mean_30'] = data.groupby('product_id')['sales_amount'].transform(
lambda x: x.rolling(window=30, min_periods=1).mean()
)
data['rolling_std_7'] = data.groupby('product_id')['sales_amount'].transform(
lambda x: x.rolling(window=7, min_periods=1).std()
)
# 趋势特征
data['trend_7'] = data.groupby('product_id')['rolling_mean_7'].transform(
lambda x: x.diff(7) / x.shift(7)
).fillna(0)
# 类别和地区的独热编码
data = pd.get_dummies(data, columns=['category', 'region'], drop_first=True)
# 去除仍有缺失值的行(主要是滞后特征导致的)
data = data.dropna()
return data
# 3. 模型训练与优化
def train_and_optimize_model(df: pd.DataFrame, product_id: str = None):
"""训练和优化销售预测模型"""
# 如果指定了产品ID,只使用该产品的数据
if product_id:
print(f"为特定产品 {product_id} 训练模型...")
data = df[df['product_id'] == product_id].copy()
else:
print("为所有产品训练通用模型...")
data = df.copy()
# 特征工程
print("进行特征工程...")
features_df = create_features(data)
# 定义特征和目标变量
target = 'sales_amount'
exclude_cols = ['date', 'product_id', target, 'units_sold']
feature_cols = [col for col in features_df.columns if col not in exclude_cols]
X = features_df[feature_cols]
y = features_df[target]
print(f"特征数量: {len(feature_cols)}, 样本数量: {len(X)}")
# 时间序列分割 - 确保训练集在测试集之前
tscv = TimeSeriesSplit(n_splits=5)
train_indices, test_indices = next(tscv.split(X))
X_train, X_test = X.iloc[train_indices], X.iloc[test_indices]
y_train, y_test = y.iloc[train_indices], y.iloc[test_indices]
# 特征缩放
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 基准模型 - 简单移动平均
print("评估基准模型(移动平均)...")
y_pred_baseline = X_test['rolling_mean_7']
mae_baseline = mean_absolute_error(y_test, y_pred_baseline)
rmse_baseline = np.sqrt(mean_squared_error(y_test, y_pred_baseline))
r2_baseline = r2_score(y_test, y_pred_baseline)
print(f"基准模型性能:")
print(f"MAE: {mae_baseline:.2f}")
print(f"RMSE: {rmse_baseline:.2f}")
print(f"R2 分数: {r2_baseline:.4f}")
# 使用Auto-sklearn自动优化模型
print("开始AutoML模型优化...")
start_time = time.time()
automl = autosklearn.regression.AutoSklearnRegressor(
time_left_for_this_task=120, # 总优化时间(秒)
per_run_time_limit=20, # 每个模型的运行时间限制(秒)
n_jobs=-1, # 使用所有可用的CPU核心
random_state=42,
resampling_strategy='cv',
resampling_strategy_arguments={'cv': 3}
)
# 训练模型
automl.fit(X_train_scaled, y_train)
training_time = time.time() - start_time
print(f"模型训练完成,耗时: {training_time:.2f}秒")
# 评估模型
y_pred = automl.predict(X_test_scaled)
mae = mean_absolute_error(y_test, y_pred)
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
r2 = r2_score(y_test, y_pred)
print(f"优化后模型性能:")
print(f"MAE: {mae:.2f} (改进: {100*(1 - mae/mae_baseline):.2f}%)")
print(f"RMSE: {rmse:.2f} (改进: {100*(1 - rmse/rmse_baseline):.2f}%)")
print(f"R2 分数: {r2:.4f}")
# 查看AutoML选择的最佳模型
print("\nAutoML选择的最佳模型:")
print(automl.show_models())
# 可视化预测结果
visualize_predictions(
dates=features_df.iloc[test_indices]['date'],
actual=y_test,
predicted=y_pred,
baseline=y_pred_baseline,
product_id=product_id
)
# 保存模型和scaler
os.makedirs("models", exist_ok=True)
model_filename = f"models/sales_prediction_model{'_' + product_id if product_id else ''}.pkl"
scaler_filename = f"models/scaler{'_' + product_id if product_id else ''}.pkl"
joblib.dump(automl, model_filename)
joblib.dump(scaler, scaler_filename)
print(f"模型已保存到 {model_filename}")
print(f"特征缩放器已保存到 {scaler_filename}")
return automl, scaler, feature_cols
def visualize_predictions(dates, actual, predicted, baseline, product_id=None):
"""可视化预测结果与实际值的对比"""
plt.figure(figsize=(15, 8))
# 只显示最近的100个点以提高可读性
if len(dates) > 100:
dates = dates[-100:]
actual = actual[-100:]
predicted = predicted[-100:]
baseline = baseline[-100:]
plt.plot(dates, actual, label='实际销售额', color='blue')
plt.plot(dates, predicted, label='模型预测', color='red', linestyle='--')
plt.plot(dates, baseline, label='基准预测(移动平均)', color='green', linestyle=':')
plt.title(f'销售预测对比{" - 产品 " + product_id if product_id else ""}')
plt.xlabel('日期')
plt.ylabel('销售额')
plt.xticks(rotation=45)
plt.legend()
plt.tight_layout()
# 保存图表
os.makedirs("visualizations", exist_ok=True)
plt.savefig(f"visualizations/prediction_vs_actual{'_' + product_id if product_id else ''}.png")
plt.close()
# 4. 主函数
def main():
"""主函数:执行数据加载、预处理、模型训练和评估"""
print("===== 智能销售预测模型训练 =====")
# 加载和预处理数据
df = load_and_preprocess_data()
# 数据探索
print("\n数据探索:")
print(f"数据集形状: {df.shape}")
print(f"日期范围: {df['date'].min()} 至 {df['date'].max()}")
print(f"产品数量: {df['product_id'].nunique()}")
# 可视化销售趋势
plt.figure(figsize=(15, 6))
df.groupby('date')['sales_amount'].sum().plot()
plt.title('整体销售趋势')
plt.xlabel('日期')
plt.ylabel('总销售额')
plt.xticks(rotation=45)
plt.tight_layout()
os.makedirs("visualizations", exist_ok=True)
plt.savefig("visualizations/overall_sales_trend.png")
plt.close()
# 训练模型
train_and_optimize_model(df)
print("\n===== 模型训练完成 =====")
if __name__ == "__main__":
main()
4.4 系统集成与部署
最后,我们将各部分整合并部署到生产环境:
version: '3.8'
services:
# 后端API服务
api-service:
build:
context: ./backend
dockerfile: Dockerfile
container_name: sales-prediction-api
restart: always
ports:
- "8000:8000"
environment:
- PYTHONUNBUFFERED=1
- MODEL_PATH=/app/models/sales_prediction_model.pkl
- SCALER_PATH=/app/models/scaler.pkl
- LOG_LEVEL=INFO
volumes:
- ./backend/models:/app/models
- ./backend/data:/app/data
networks:
- sales-network
depends_on:
- db-service
# 数据库服务
db-service:
image: postgres:14
container_name: sales-db
restart: always
ports:
- "5432:5432"
environment:
- POSTGRES_USER=salesuser
- POSTGRES_PASSWORD=salesspassword
- POSTGRES_DB=salesdb
volumes:
- postgres-data:/var/lib/postgresql/data
- ./database/init.sql:/docker-entrypoint-initdb.d/init.sql
networks:
- sales-network
# 前端低代码应用服务
frontend-service:
build:
context: ./frontend
dockerfile: Dockerfile
container_name: sales-dashboard
restart: always
ports:
- "80:80"
environment:
- API_URL=http://api-service:8000
networks:
- sales-network
depends_on:
- api-service
# 模型训练与更新服务
model-trainer:
build:
context: ./model-training
dockerfile: Dockerfile
container_name: sales-model-trainer
restart: always
environment:
- API_URL=http://api-service:8000
- TRAINING_INTERVAL=86400 # 每天训练一次(秒)
- LOG_LEVEL=INFO
volumes:
- ./model-training/models:/app/models
- ./model-training/data:/app/data
- ./model-training/visualizations:/app/visualizations
networks:
- sales-network
depends_on:
- api-service
- db-service
networks:
sales-network:
driver: bridge
volumes:
postgres-data:
五、未来趋势与挑战
AI 编程技术正处于快速发展阶段,未来将呈现以下趋势:
-
更深度的集成:AI 辅助工具将与 IDE 更深度集成,提供实时的代码建议和优化。
-
领域特定优化:针对特定行业(如金融、医疗)的 AI 编程工具将得到发展,提供更专业的代码生成和优化。
-
多模态编程:结合自然语言、图表、语音等多种输入方式的编程模式。
-
自修复代码:AI 能够自动检测并修复运行时错误,提高系统的鲁棒性。
-
协作式 AI 编程:AI 不仅辅助单个开发者,还能协调团队开发,优化代码合并和冲突解决。
然而,AI 编程也面临着诸多挑战:
-
可解释性问题:AI 生成的代码和优化方案往往缺乏透明度,难以理解其工作原理。
-
安全与伦理风险:AI 可能生成有安全漏洞的代码,或在训练数据中继承偏见。
-
技能转型需求:开发者需要掌握新的技能来有效利用 AI 编程工具,同时保持核心的问题解决能力。
-
知识产权问题:AI 生成代码的版权归属和专利问题尚未完全明确。
-
系统复杂性:随着 AI 在开发流程中的深入应用,整个开发系统的复杂性增加,维护难度加大。

结论
AI 编程技术,包括自动化代码生成、低代码 / 无代码开发和算法优化,正在深刻改变软件开发的方式。这些技术不仅提高了开发效率,降低了编程门槛,还能生成更高质量、更高效的代码。
通过本文介绍的方法和示例,开发者可以开始在实际项目中应用这些 AI 编程技术,逐步提升自己的工作效率和代码质量。然而,AI 并非万能,它更像是一个强大的辅助工具,真正的创新和问题解决仍然需要人类开发者的智慧和创造力。
未来,随着 AI 技术的不断进步,AI 与人类开发者的协作将更加紧密和高效,推动软件产业向更智能、更普惠的方向发展。对于开发者而言,积极拥抱这些变化,不断学习和适应新技术,将是保持竞争力的关键。
通过合理利用 AI 编程工具,我们有理由相信,软件开发将变得更加高效、更加普及,能够更快地将创意转化为实际应用,为社会带来更多价值。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 20
20 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)