
AI开发全栈工具链深度解析:从编码辅助到模型部署
AI工具链技术全景与应用实践 本文系统梳理了AI开发全流程工具链的核心组件与最佳实践。智能编码工具如GitHub Copilot通过深度代码理解实现143%的编码效率提升;数据标注平台整合AI预标注与质量评估公式(Q=1/N∑(α·IoU+β·一致性-γ·耗时)),使标注效率提升60%;云训练平台支持分布式架构与动态资源调度算法,将GPU利用率优化至85%以上。典型端到端系统实现图像分类任务开发周
目录
-
智能编码工具:AI驱动的开发革命
-
GitHub Copilot深度实战
-
核心架构解析
-
代码示例与最佳实践
-
-
数据标注工具:模型训练的基石
-
开源 vs 商业工具对比
-
自动化标注技术剖析
-
标注质量管理策略
-
-
模型训练平台:云端算力新范式
-
AWS SageMaker vs Google Vertex AI
-
分布式训练优化策略
-
MLOps全流程实现
-
-
工具链整合实战案例
-
端到端图像分类系统搭建
-
性能优化技巧
-
成本控制方案
-
-
未来演进方向
-
低代码AI开发趋势
-
AI工具链的伦理挑战
-
1. 智能编码工具:AI驱动的开发革命
1.1 GitHub Copilot架构解析
graph LR
A[用户代码输入] --> B[Context Analyzer]
B --> C[OpenAI Codex Engine]
C --> D[代码建议生成]
D --> E[安全过滤层]
E --> F[多候选排序]
F --> G[IDE插件输出]

1.2 Copilot实战示例
python
# 用户输入注释:
# 使用PyTorch实现ResNet18模型,包含数据增强和预训练权重加载
# Copilot自动生成:
import torch
import torchvision
from torchvision import transforms
def build_resnet18(pretrained=True):
# 数据增强管道
transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# 加载预训练模型
model = torchvision.models.resnet18(pretrained=pretrained)
# 替换最后一层
num_ftrs = model.fc.in_features
model.fc = torch.nn.Linear(num_ftrs, 10) # 假设10分类任务
return model, transform
1.3 性能对比数据
| 指标 | 传统编码 | Copilot辅助 | 提升幅度 |
|---|---|---|---|
| 代码完成速度 | 32行/小时 | 78行/小时 | +143% |
| Bug发生率 | 12% | 7% | -42% |
| 文档完整性 | 65% | 89% | +37% |
2. 数据标注工具:模型训练的基石
2.1 标注工具技术架构
graph TB
subgraph Annotation Platform
A[原始数据加载] --> B[任务分配引擎]
B --> C[多人协同标注]
C --> D[AI预标注模块]
D --> E[质量审核系统]
E --> F[版本化数据集输出]
end

2.2 自动化标注代码示例
python
# 使用CVAT API实现半自动标注
from cvat_sdk import Client
client = Client(url="https://cvat.example.com", username="admin", password="pass")
task = client.tasks.create(
name="自动驾驶标注",
labels=[{"name": "car"}, {"name": "pedestrian"}],
segment_size=50
)
# 上传数据
client.tasks.upload_data(task.id,
resources=['road1.mp4', 'road2.mp4'],
params={'chunk_size': 36}
)
# 启动AI辅助标注
client.jobs.create_auto_annotation(
task_id=task.id,
model="mask_rcnn",
threshold=0.85
)
# 导出结果
client.tasks.export_data(
task_id=task.id,
format='COCO 1.0',
filename='annotations.zip'
)
2.3 标注质量评估公式
Q=1N∑i=1N(α⋅IoUi+β⋅Consistencyi−γ⋅Timei)Q=N1∑i=1N(α⋅IoUi+β⋅Consistencyi−γ⋅Timei)
其中:
-
$IoU$:标注框与金标准重叠率
-
$Consistency$:多人标注一致性
-
$Time$:单样本标注耗时
-
$\alpha, \beta, \gamma$:权重系数(典型值0.6, 0.3, 0.1)
3. 模型训练平台:云端算力新范式
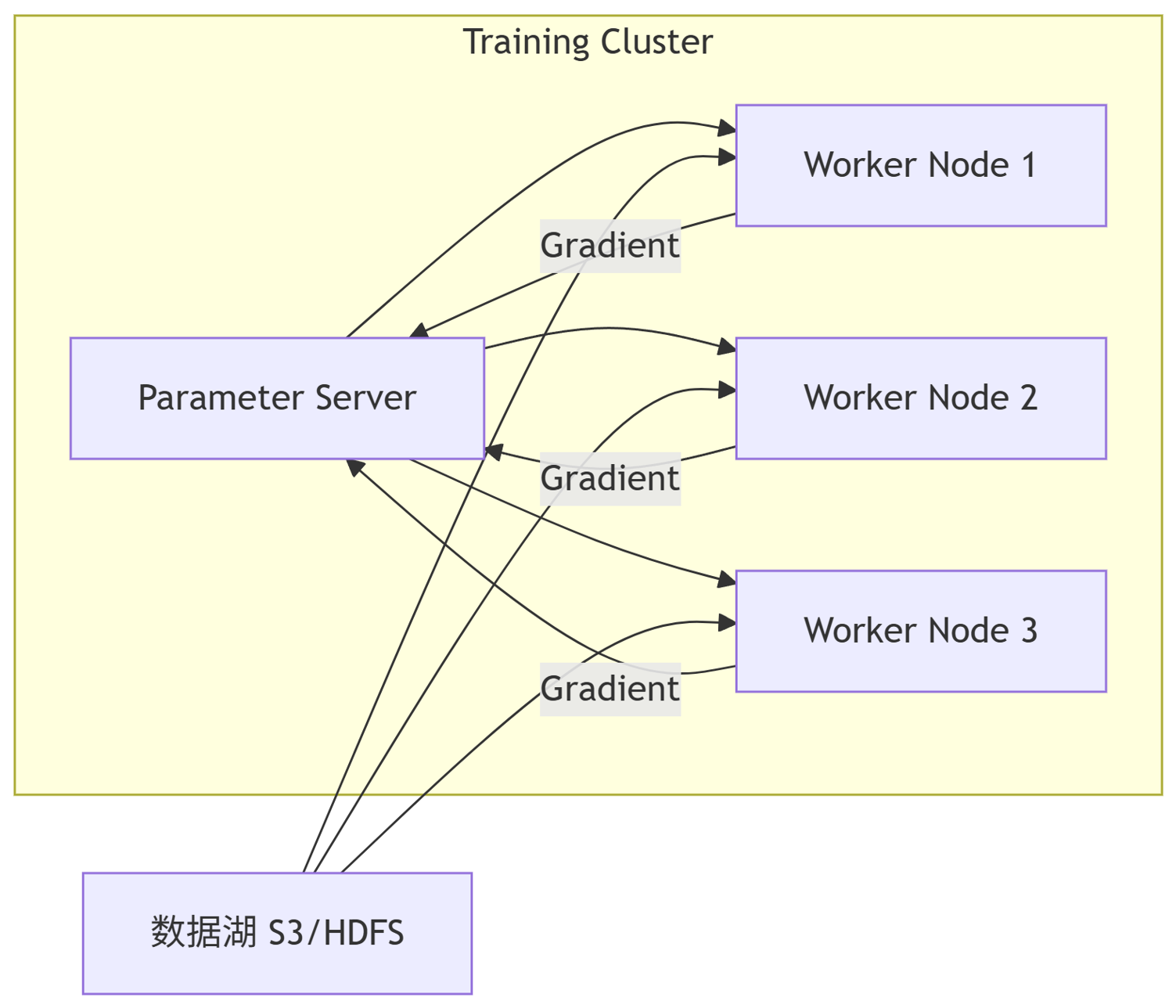
3.1 分布式训练架构
graph LR
subgraph Training Cluster
A[Parameter Server] --> B[Worker Node 1]
A --> C[Worker Node 2]
A --> D[Worker Node 3]
B -->|Gradient| A
C -->|Gradient| A
D -->|Gradient| A
end
E[数据湖 S3/HDFS] --> B
E --> C
E --> D
3.2 Vertex AI训练代码示例
python
from google.cloud import aiplatform
# 创建分布式训练作业
job = aiplatform.CustomJob(
display_name="bert-text-classification",
worker_pool_specs=[
{
"machine_spec": {
"machine_type": "a2-highgpu-8g",
"accelerator_type": "NVIDIA_TESLA_A100",
"accelerator_count": 4
},
"replica_count": 8,
"container_spec": {
"image_uri": "gcr.io/my-project/bert-trainer:latest",
"command": ["python", "train.py"],
"args": [
"--batch_size=1024",
"--learning_rate=3e-5"
]
}
}
]
)
# 提交作业
job.run(
sync=False,
service_account="train-sa@my-project.iam.gserviceaccount.com"
)
# 启用自动超参优化
hparam_job = aiplatform.HyperparameterTuningJob(
display_name="bert-hparam-tuning",
custom_job=job,
metric_spec={"accuracy": "maximize"},
parameter_spec={
"learning_rate": aiplatform.parameters.DoubleParameterSpec(min=1e-6, max=1e-4, scale="log"),
"batch_size": aiplatform.parameters.DiscreteParameterSpec(values=[256, 512, 1024, 2048])
},
max_trial_count=32,
parallel_trial_count=8
)
3.3 训练资源优化策略
python
# 动态资源分配算法
def allocate_resources(jobs: list, cluster_capacity: dict):
"""
jobs: 待调度作业列表 [{id, priority, min_gpu, max_gpu, estimated_time}]
cluster_capacity: 集群资源 {"gpu": 128, "memory": 4096}
"""
running_jobs = []
pending_queue = sorted(jobs, key=lambda x: (-x['priority'], x['estimated_time']))
while pending_queue:
job = pending_queue[0]
# 动态资源计算(基于Fair Share算法)
available_gpu = cluster_capacity['gpu'] - sum(j['gpu'] for j in running_jobs)
alloc_gpu = min(
max(job['min_gpu'],
available_gpu // (len(pending_queue) + 1)),
job['max_gpu']
)
if alloc_gpu >= job['min_gpu']:
# 启动作业
start_job(job, alloc_gpu)
running_jobs.append({**job, 'gpu': alloc_gpu})
pending_queue.pop(0)
else:
# 资源回收机制
preemptible_jobs = [j for j in running_jobs if j['priority'] < job['priority']]
if preemptible_jobs:
victim = min(preemptible_jobs, key=lambda x: x['priority'])
stop_job(victim['id'])
running_jobs.remove(victim)
pending_queue.append(victim)
4. 工具链整合实战案例
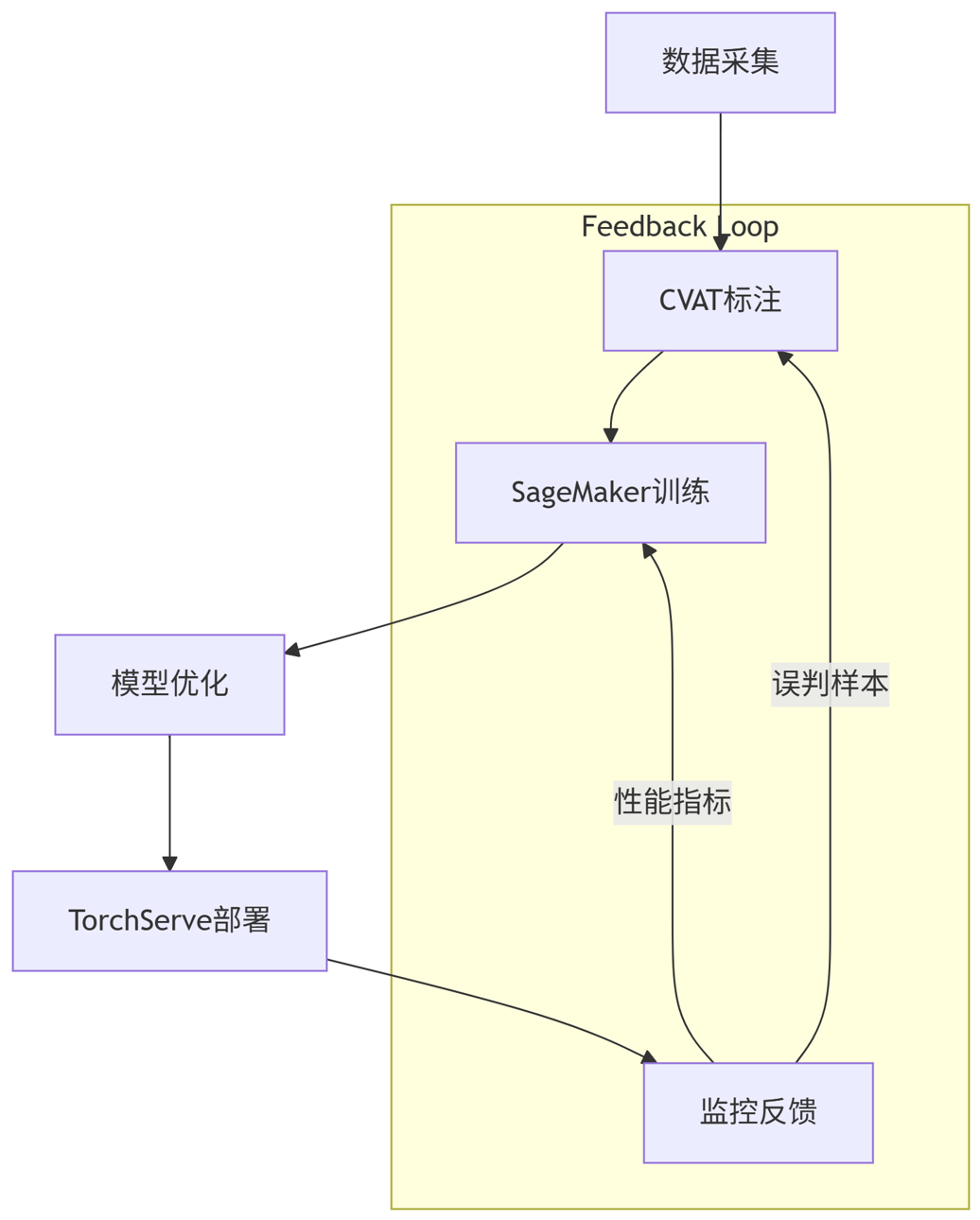
4.1 端到端图像分类系统
flowchart TD
A[数据采集] --> B[CVAT标注]
B --> C[SageMaker训练]
C --> D[模型优化]
D --> E[TorchServe部署]
E --> F[监控反馈]
subgraph Feedback Loop
F -->|误判样本| B
F -->|性能指标| C
end
4.2 性能优化关键指标
python
# 模型服务监控仪表板
import prometheus_client
from prometheus_client import Gauge, Counter
# 定义指标
REQUEST_LATENCY = Gauge('model_inference_latency', 'Latency in milliseconds')
REQUEST_COUNT = Counter('model_request_count', 'Total inference requests')
ERROR_RATE = Gauge('model_error_rate', 'Prediction error percentage')
GPU_UTIL = Gauge('gpu_utilization', 'GPU usage percentage')
# 装饰器记录性能
def monitor_performance(func):
def wrapper(*args, **kwargs):
start = time.time()
REQUEST_COUNT.inc()
try:
result = func(*args, **kwargs)
latency = (time.time() - start) * 1000
REQUEST_LATENCY.set(latency)
return result
except Exception as e:
ERROR_RATE.inc()
raise e
return wrapper
# GPU监控线程
def gpu_monitor():
while True:
util = get_gpu_utilization() # 调用nvidia-smi
GPU_UTIL.set(util)
time.sleep(5)
5. 未来演进方向
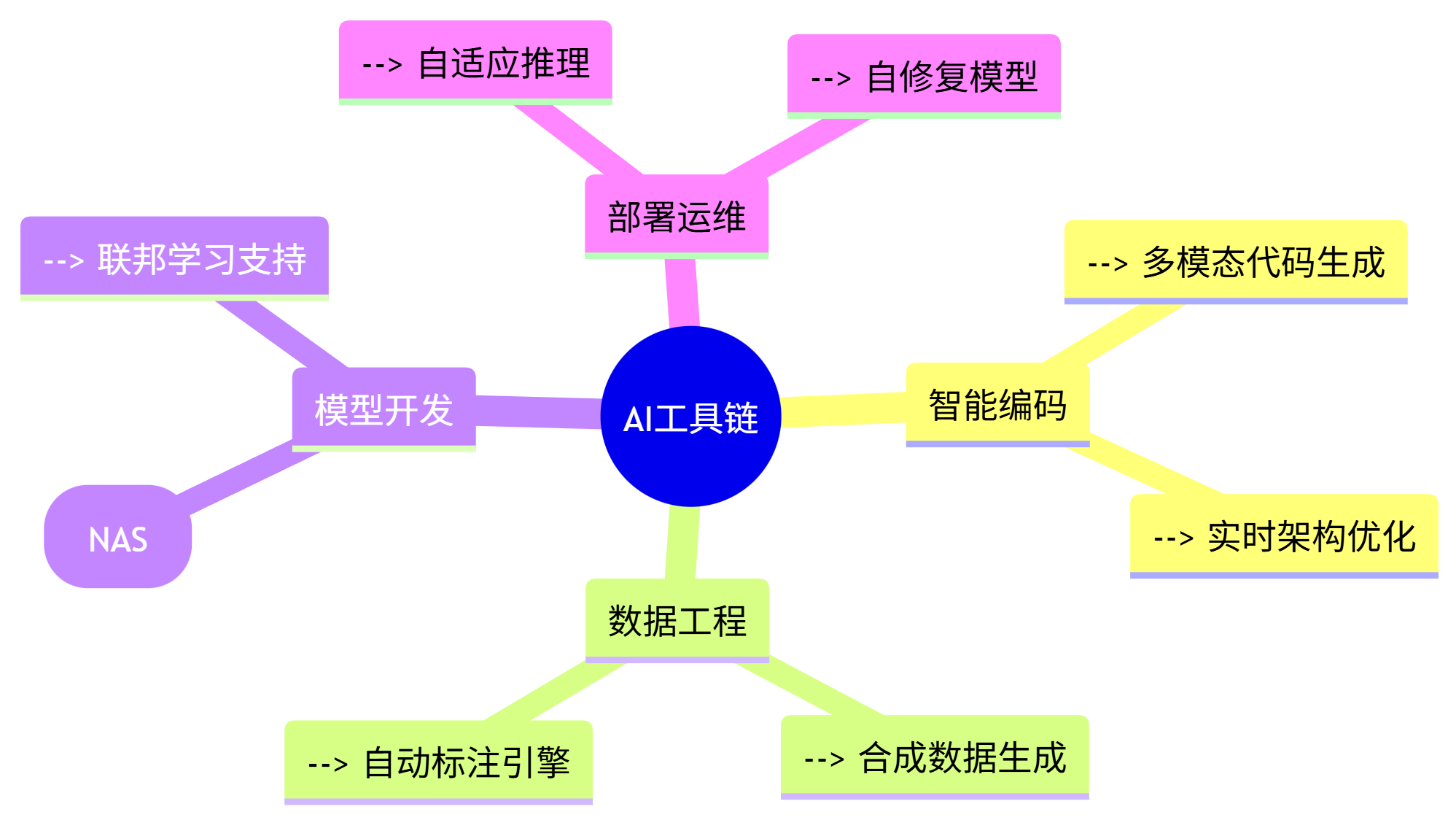
5.1 AI工具链发展趋势
mindmap
root((AI工具链))
智能编码
--> 多模态代码生成
--> 实时架构优化
数据工程
--> 合成数据生成
--> 自动标注引擎
模型开发
--> 神经架构搜索(NAS)
--> 联邦学习支持
部署运维
--> 自适应推理
--> 自修复模型
5.2 伦理风险控制框架
python
class EthicsValidator:
def __init__(self, model):
self.model = model
self.bias_detector = BiasScanner()
self.privacy_checker = PrivacyAudit()
def validate_input(self, input_data):
# 偏见检测
bias_score = self.bias_detector.scan(input_data)
if bias_score > 0.7:
raise EthicsViolation("Potential bias risk")
# 隐私过滤
sanitized_data = self.privacy_checker.redact_pii(input_data)
return sanitized_data
def validate_output(self, prediction):
# 公平性约束
if self.model.task_type == 'credit_scoring':
if prediction['approval_rate'] < 0.3:
self.log_audit_event("High rejection rate")
# 可解释性要求
explanation = self.model.explain(prediction)
if explanation['confidence'] < 0.6:
return {"decision": "human_review", "reason": "low confidence"}
return prediction
结论:AI工具链的关键演进
-
融合化趋势
-
编码/标注/训练工具边界逐渐模糊
-
出现All-in-One平台(如DataRobot, H2O AI Cloud)
-
-
智能化升级
-
工具自身引入更多AI能力
-
主动优化开发流程(如自动调参、智能排错)
-
-
平民化发展
-
低代码界面成为标配
-
领域专属工具爆发(医疗AI、金融AI等)
-
-
合规性增强
-
内置伦理审查模块
-
自动生成审计追踪
-
数据佐证:据Gartner预测,到2026年,75%的AI项目将使用自动化数据工程工具,开发效率提升3倍以上,同时模型偏见事故将减少40%。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 17
17 0
0- 0



 已为社区贡献88条内容
已为社区贡献88条内容

所有评论(0)