
打卡第三周-Pytorch实现天气识别
1.可能算是初步体会到了调参数的感觉。一开始看提升要求要达到95%,就想着说把卷积核调小一点,结果数据结果很差,测试准确率振荡的厉害,也存在严重的过拟合。好吧,以为是K老师的卷积核大小是特别合适的,又老老实实调回去了,结果发现结果还是一样的,好吧,那可能是硬件设备区别太大了,只好老实求助ai。2.后续调用模型识别本地图片也是自己重跑了一遍模型保存好了.pth文件,再让copilot写了一段识别程序
- 🍨 本文为🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者:K同学啊
一、代码部分
1.引入库和配置好GPU
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms,datasets
import os,PIL,pathlib,random #os,pathlib文件处理,PIL图像处理,random
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device2.加载本地数据
#2. 加载数据地址并分类
data_dir = './data/'#文件夹相对路径和程序在同一根目录下
data_dir = pathlib.Path(data_dir)#将字符串类型的文件夹路径转为pathlib.Path对象(方便很多啊)
data_paths = list(data_dir.glob('*'))#glob获取文件夹路径下的所有文件路径并以列表存储在data_paths中
classNames = [str(path).split("\\")[1] for path in data_paths]#对字符串使用split("\\")方法进行分割。
#注意,这里使用双反斜杠,因为在字符串中反斜杠是转义字符,所以要用两个反斜杠表示一个反斜杠
#取第二个部分,也就是第二级目录名
classNames3.图像显示以及对数据进行处理(由于原先训练集和测试集处理方式一样导致过拟合程度过高,对训练集采用了数据增强的方式)
#3. 数据预处理
import matplotlib.pyplot as plt
from PIL import Image
#指定图像文件夹路径
image_folder = './data/cloudy/'
# 指定获取文件夹中的所有图像文件存在列表里
image_files = [f for f in os.listdir(image_folder) if f.endswith((".jpg", ".png", ".jpeg"))]
#`os.listdir()是Python的os模块中的一个函数,用于返回指定目录下的所有文件和子目录的名称列表
#.endswith() 是字符串方法,可以接受一个字符串元组作为参数,只要文件名以其中任意一个扩展名结尾,就返回True
#创建Matplotlib图像
#- `g`:返回整个图形(Figure)对象。
# axes`:返回一个包含所有子图(Axes)对象的数组(numpy数组),其形状为(3,8),即3行8列。
g, axes = plt.subplots(3,8,figsize=(16,6))
#使用列表推导式加载和显示图像
#axes.flat:将子图网格展平为一维数组(按行优先顺序)
#zip创建 (ax, img_file) 对,每个对包含:一个子图对象(ax),一个图像文件名(img_file)
#使用PIL库打开图像文件,并将其显示在对应的子图上
for ax, img_file in zip(axes.flat, image_files):
img_path = os.path.join(image_folder, img_file)
img = Image.open(img_path)
ax.imshow(img)
ax.axis('off')
#优化图形布局和显示图形
plt.tight_layout()
plt.show()运行结果:

total_datadir = './data/'
#训练集数据增强
train_transfroms = transforms.Compose([
transforms.Resize([224,224]),
transforms.ColorJitter(brightness=0.2, contrast=0.2, hue=0.1),
transforms.RandomAffine(degrees=0, shear=20),
transforms.ToTensor(),
transforms.Normalize(
mean = [0.485, 0.456, 0.406],
std = [0.229, 0.224, 0.225])#RGB固定的
])#对数据进行预处理
#测试集数据不增强
test_transforms = transforms.Compose([
transforms.Resize([224, 224]),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
total_data = datasets.ImageFolder(total_datadir)4.划分数据集以及加载数据
train_size = int(0.85*len(total_data))
test_size = len(total_data) - train_size
train_ds, test_ds = torch.utils.data.random_split(total_data, [train_size,test_size])#随机训练85%,测试15%
#定义了一个 PyTorch 数据集包装类,用于在数据加载过程中应用变换(transforms)
class TransformDataset(torch.utils.data.Dataset):
def __init__(self, subset, transform=None):
self.subset = subset
self.transform = transform
def __getitem__(self, index):
x, y = self.subset[index] #获取原数据集样本
if self.transform:
x = self.transform(x)#x应用变换,y不变,直接返回(因为有图像和标签两个部分)
return x, y
def __len__(self):
return len(self.subset)
#将不同变换应用到训练集和测试集
train_ds = TransformDataset(train_ds, train_transfroms)
test_ds = TransformDataset(test_ds, test_transforms)
#加载数据
batch_size = 32
train_dl = torch.utils.data.DataLoader(train_ds,
batch_size = batch_size,
shuffle = True)
test_dl = torch.utils.data.DataLoader(test_ds,
batch_size = batch_size,
shuffle = True)
for m,n in test_dl:
print("Shape of m[N, C, H, W]:", m.shape)
print("Shape of n:", n.shape, n.dtype)#在分类任务中,每个样本的标签通常是一个整数(类别索引),则有32个整数标签。
break
运行结果:

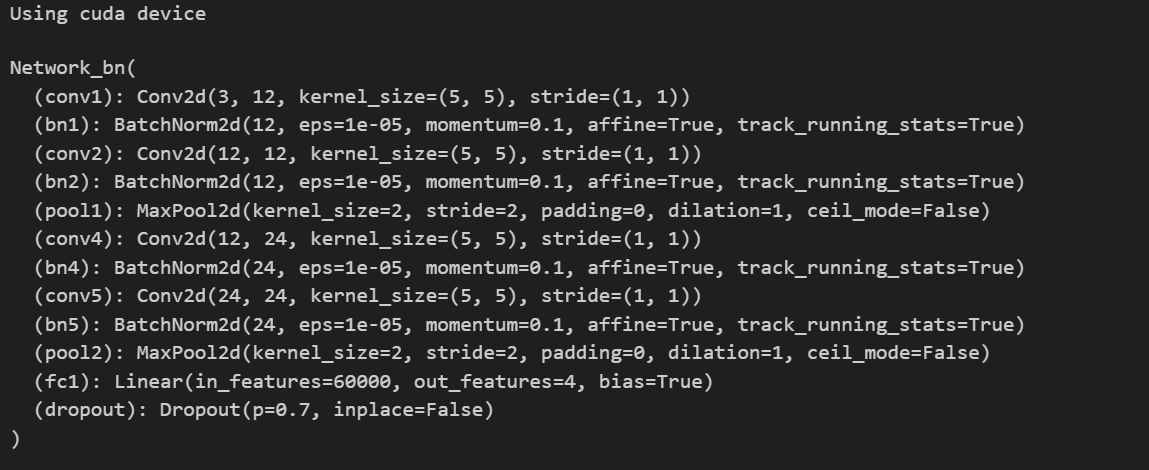
5.构建cnn网络
#5. 构建cnn网络
import torch.nn.functional as F
class Network_bn(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.utils.weight_norm(nn.Conv2d(3, 12, 5, 1, 0))# --(12,220,220))
#对卷积层的权重应用权重归一化,缓解梯度爆炸/消失问题
self.bn1 = nn.BatchNorm2d(12)#批量归一化
#加速训练收敛:减少内部协变量偏移(Internal Covariate Shift)
# 允许更高的学习率:使优化过程更稳定
# 正则化效果:轻微减少对 Dropout 的依赖
# 改善梯度流:缓解梯度消失/爆炸问题
self.conv2 = nn.utils.weight_norm(nn.Conv2d(12, 12, 5, 1, 0)) # (12,216,216)
self.bn2 = nn.BatchNorm2d(12)
self.pool1 = nn.MaxPool2d(2,2)# --(12,108,108)
self.conv4 = nn.utils.weight_norm(nn.Conv2d(12, 24, 5, 1, 0)) # (24,104,104)
self.bn4 = nn.BatchNorm2d(24)
self.conv5 = nn.utils.weight_norm(nn.Conv2d(24, 24, 5, 1, 0)) # (24,100,100)
self.bn5 = nn.BatchNorm2d(24)
self.pool2 = nn.MaxPool2d(2,2)#--(24,50,50)
self.fc1 = nn.utils.weight_norm(nn.Linear(24*50*50, len(classNames)))#
self.dropout = nn.Dropout(0.7) # 正则化抑制过拟合
def forward(self,x):
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = self.pool1(x)
x = F.relu(self.bn4(self.conv4(x)))
x = F.relu(self.bn5(self.conv5(x)))
x = self.pool2(x)
x = torch.flatten(x, 1)
#x = x.view(-1, 24*50*50)
x = self.dropout(x)
x = self.fc1(x)
return x
#输入-卷积1-卷积2-池化1-卷积4-卷积5-池化2-展平-全连接1-输出
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))
model = Network_bn().to(device)
model运行结果:
6.训练和测试函数(为了解决过拟合、梯度爆炸等问题在训练函数里调整了学习率、进行了梯度裁剪、权重衰减等操作)
#6. 训练和测试函数
import torch.optim.lr_scheduler as lr_scheduler
# 定义多种学习率调度器(验证损失,固定步长降低,余弦退火)
def create_scheduler(optimizer, scheduler_type='plateau', total_epochs=20, steps_per_epoch=None):
if scheduler_type == 'plateau':
# 基于验证损失调整,当损失停止改善时降低学习率
return lr_scheduler.ReduceLROnPlateau(
optimizer,
mode='min', # 监控损失最小化
factor=0.5, # 学习率衰减因子
patience=2, # 无改善的epoch数
verbose=True,
min_lr=1e-6
)
elif scheduler_type == 'step':
# 阶梯式衰减,固定间隔衰减学习率
return lr_scheduler.StepLR(
optimizer,
step_size=5, # 每5个epoch衰减一次
gamma=0.5 # 衰减因子
)
else:
# 默认使用余弦退火,平滑调整避免突变,促使模型跳出局部最优
return lr_scheduler.CosineAnnealingLR(optimizer, T_max=total_epochs, eta_min=1e-6)
loss_fn = nn.CrossEntropyLoss()
learn_rate = 1e-4
#权重衰减正则化,防止过拟合;动量抑制震荡
opt = torch.optim.SGD(model.parameters(), lr=learn_rate, weight_decay=5e-4, momentum=0.9)
# 创建调度器(根据类型选择)
total_epochs = 20
steps_per_epoch = len(train_dl) # 需要您的dataloader
scheduler = create_scheduler(opt,
scheduler_type='onecycle', # 推荐使用,学习率上升下降周期
total_epochs=total_epochs,
steps_per_epoch=steps_per_epoch)
def train(dataloader, model, loss_fn, optimizer, scheduler=None, epoch=None):
size = len(dataloader.dataset)
num_batches = len(dataloader)
train_loss, train_acc = 0, 0
model.train()
for batch_idx, (m, n) in enumerate(dataloader):
m, n = m.to(device), n.to(device)
# 前向传播
pred = model(m)
loss = loss_fn(pred, n)
# 反向传播
optimizer.zero_grad()
loss.backward()
#梯度剪裁
# 动态计算裁剪阈值 `clip_value`,其值在0.1到1.0之间,具体为 `0.5/(当前损失+极小值)`,但限制在[0.1, 1.0]区间内。
# 使用 `clip_grad_value_` 函数将模型所有参数的梯度裁剪到 `[-clip_value, clip_value]` 范围内。这可以防止梯度爆炸。
clip_value = min(1.0, max(0.1, 0.5 / (loss.item() + 1e-7)))
torch.nn.utils.clip_grad_value_(model.parameters(), clip_value=clip_value)
optimizer.step()
# 每个batch后更新学习率(仅限OneCycleLR)
if scheduler and isinstance(scheduler, lr_scheduler.OneCycleLR):
scheduler.step()
train_acc += (pred.argmax(1)==n).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_lossdef test(datalodar, model, loss_fn):
size = len(datalodar.dataset)
num_batches = len(datalodar)
test_loss, test_acc = 0,0
with torch.no_grad():
for imgs, target in datalodar:
imgs, target = imgs.to(device), target.to(device)
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1)==target).type(torch.float).sum().item()
test_loss /= num_batches
test_acc /= size
return test_acc, test_loss7.开始训练
#7. 战争开始
epochs = 20
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(total_epochs):
epoch_train_acc, epoch_train_loss = train(
train_dl,
model,
loss_fn,
opt,
scheduler, # 传入调度器
epoch+1 # 传入当前epoch
)
model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
# 更新学习率(基于epoch的调度器)
if scheduler and not isinstance(scheduler, lr_scheduler.OneCycleLR):
if isinstance(scheduler, lr_scheduler.ReduceLROnPlateau):
scheduler.step(test_loss) # 基于测试损失更新
else:
scheduler.step() # 标准epoch更新
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}')
print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss))
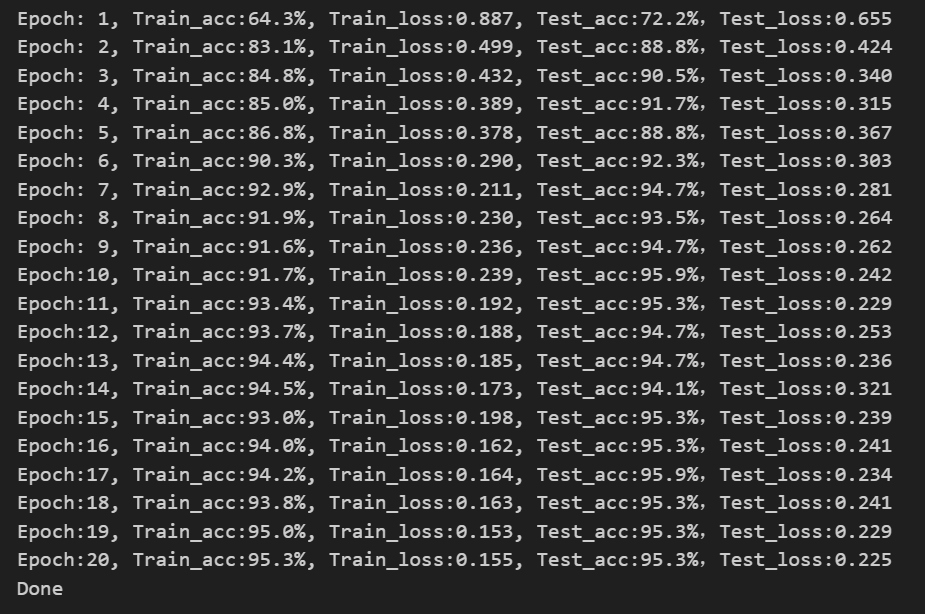
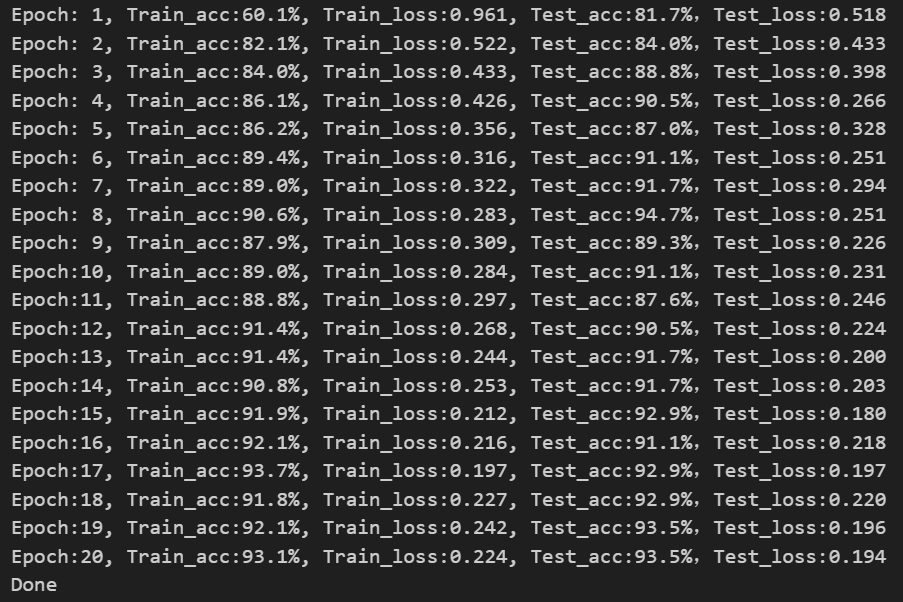
print('Done')运行结果:(好吧,调整了很多参数,满心欢喜以为到95%了,结果又跑了一遍又回来了)
8.结果可视化
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率
from datetime import datetime
current_time = datetime.now() # 获取当前时间
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.xlabel(current_time) # 打印当前时间
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
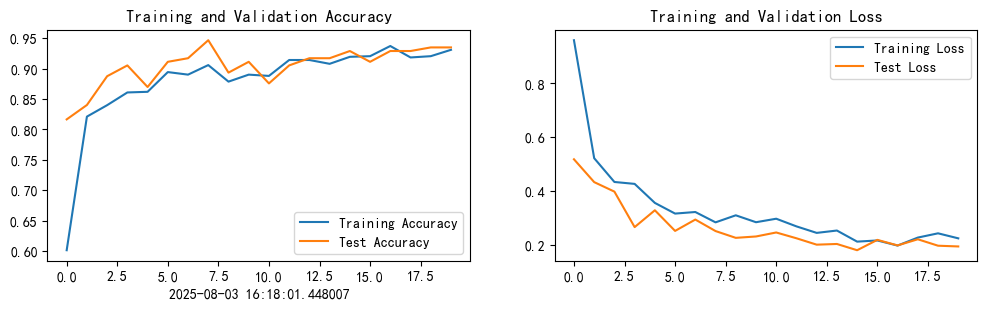
plt.show()运行结果:
9.保存模型以及调用模型识别本地图片(只能说感觉有时候ok,好像多云天的亮度强一点就分不清cloudy和shine了)
#保存模型
torch.save(model, 'model.pth')
from PIL import Image
# 加载模型并识别本地图片
# 加载模型
model = torch.load('model.pth')
model.eval()
# 选择一张本地图片路径
img_path = 'test_weather.jpg' # 替换为你的图片路径
# 加载并预处理图片(使用测试集的transform)
img = Image.open(img_path).convert('RGB')
img_tensor = test_transforms(img).unsqueeze(0).to(device)
# 推理
with torch.no_grad():
output = model(img_tensor)
pred_idx = output.argmax(1).item()
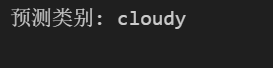
pred_class = classNames[pred_idx]
print(f'预测类别: {pred_class}')测试图片:

运行结果:
二、个人总结
1.可能算是初步体会到了调参数的感觉。一开始看提升要求要达到95%,就想着说把卷积核调小一点,结果数据结果很差,测试准确率振荡的厉害,也存在严重的过拟合。好吧,以为是K老师的卷积核大小是特别合适的,又老老实实调回去了,结果发现结果还是一样的,好吧,那可能是硬件设备区别太大了,只好老实求助ai。中间也是把结果丢给ai让他帮忙出具解决方案,从一开始数据增强-dropout-权重归一化-梯度裁剪-学习率调度器-权重衰减等等大概路线是这样。
2.后续调用模型识别本地图片也是自己重跑了一遍模型保存好了.pth文件,再让copilot写了一段识别程序就ok了。
3.要抓紧学习一些基础知识了,总得看着结果能知道有些什么主要问题吧(虽然说ai很全能啊,但是方案很多还是需要自己选择)。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)