74.5%登顶SWE-bench:Claude Opus 4.1如何重塑AI编程格局
2025年8月6日,Anthropic发布Claude Opus 4.1,在SWE-bench Verified基准测试中以74.5%的准确率刷新纪录,超越GPT-4.1和Gemini 2.5 Pro。作为Claude 4系列的重要升级,该模型在多文件代码重构、智能体任务处理和企业级应用中展现出显著优势,尤其在大型代码库调试和长时间任务执行方面实现突破。本文将深入解析其技术改进、性能表现及实际应用
简述
2025年8月6日,Anthropic发布Claude Opus 4.1,在SWE-bench Verified基准测试中以74.5%的准确率刷新纪录,超越GPT-4.1和Gemini 2.5 Pro。作为Claude 4系列的重要升级,该模型在多文件代码重构、智能体任务处理和企业级应用中展现出显著优势,尤其在大型代码库调试和长时间任务执行方面实现突破。本文将深入解析其技术改进、性能表现及实际应用案例,为开发者提供全面参考。
一、发布背景与行业竞争格局
Anthropic在GPT-5发布前夕推出Claude Opus 4.1,延续了其一贯的技术驱动路线。当前AI编程领域呈现三足鼎立态势:Anthropic凭借Claude系列占据技术制高点,OpenAI通过GitHub Copilot占据市场份额,Google Gemini则在多模态领域寻求突破。数据显示,Anthropic过去7个月API收入增长5倍,其中编程相关服务贡献了58%的营收,凸显其在开发者工具领域的强势地位。
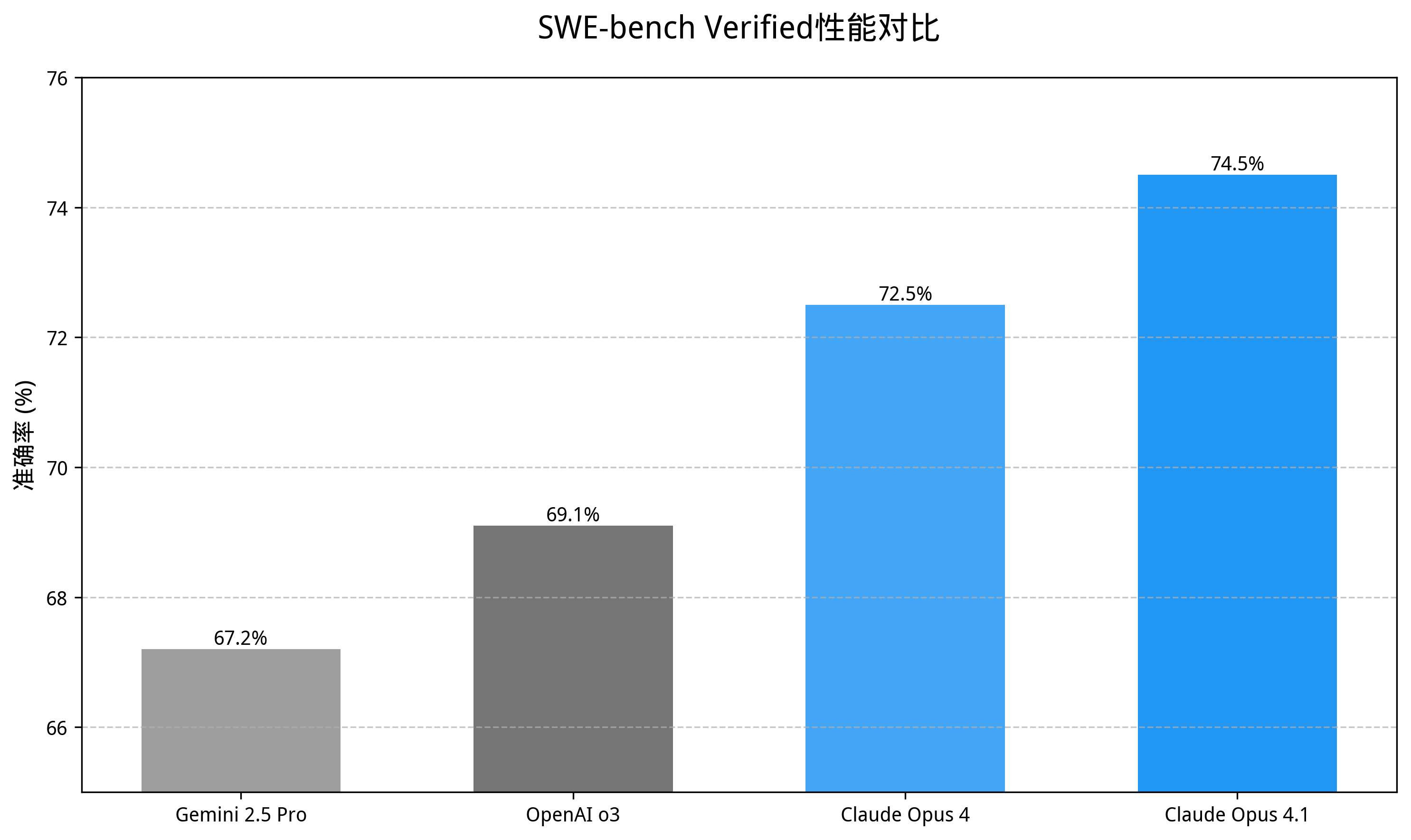
二、核心性能提升:从基准测试看技术飞跃
Claude Opus 4.1在关键指标上实现全面提升:
- SWE-bench Verified:74.5%(+2% vs Opus 4)
- Terminal-bench:43.3%(+4.1% vs Opus 4)
- TAU-bench智能体任务:81.4%(零售场景)
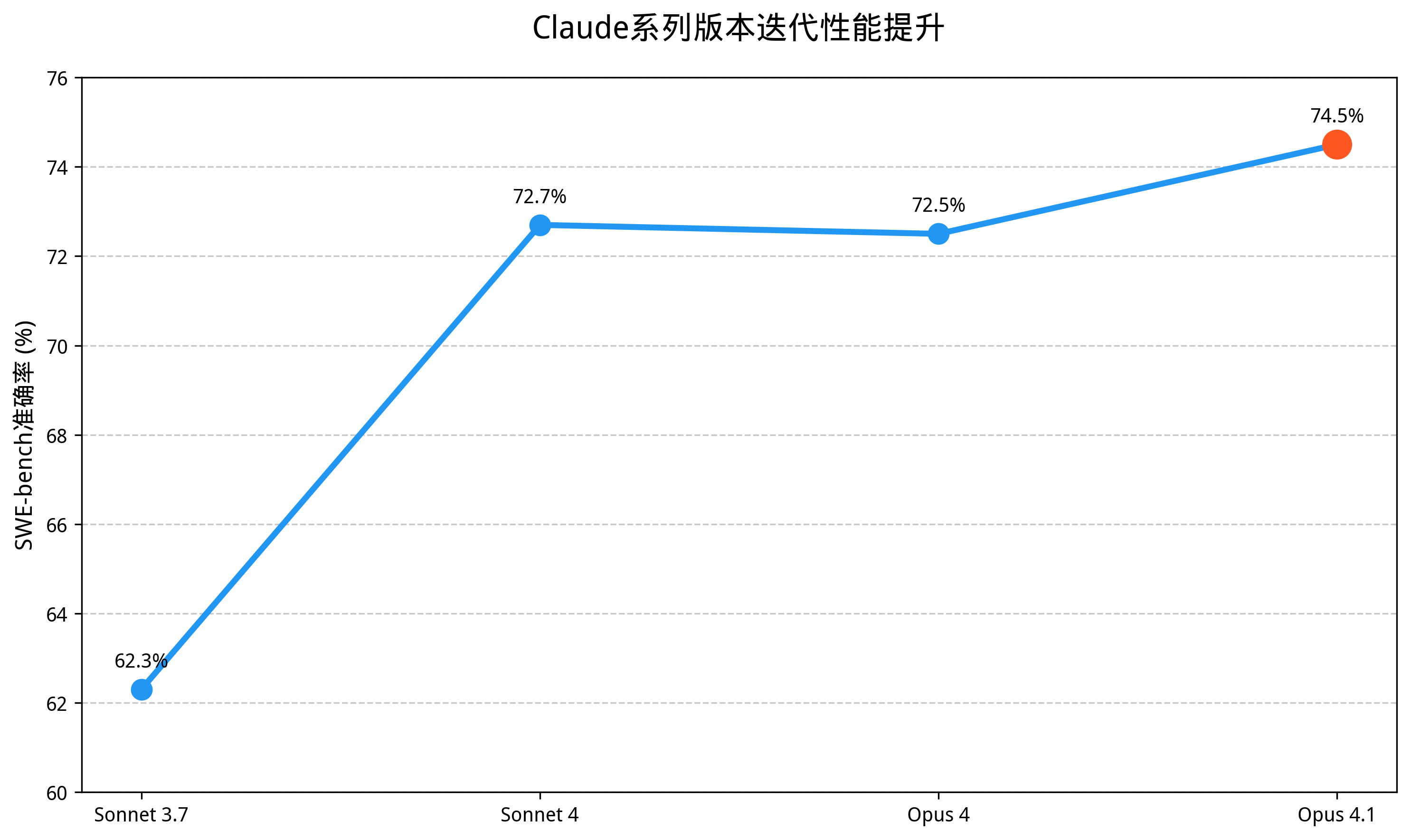
对比历史版本,Claude系列呈现阶梯式进步,从Sonnet 3.7的62.3%到Opus 4.1的74.5%,18个月内提升12.2个百分点,远超行业平均增速。这种进步不仅体现在基准测试中,更转化为实际开发效率的提升——Rakuten报告显示,使用Opus 4.1后,代码重构任务的人工干预减少67%。
三、技术改进深度解析
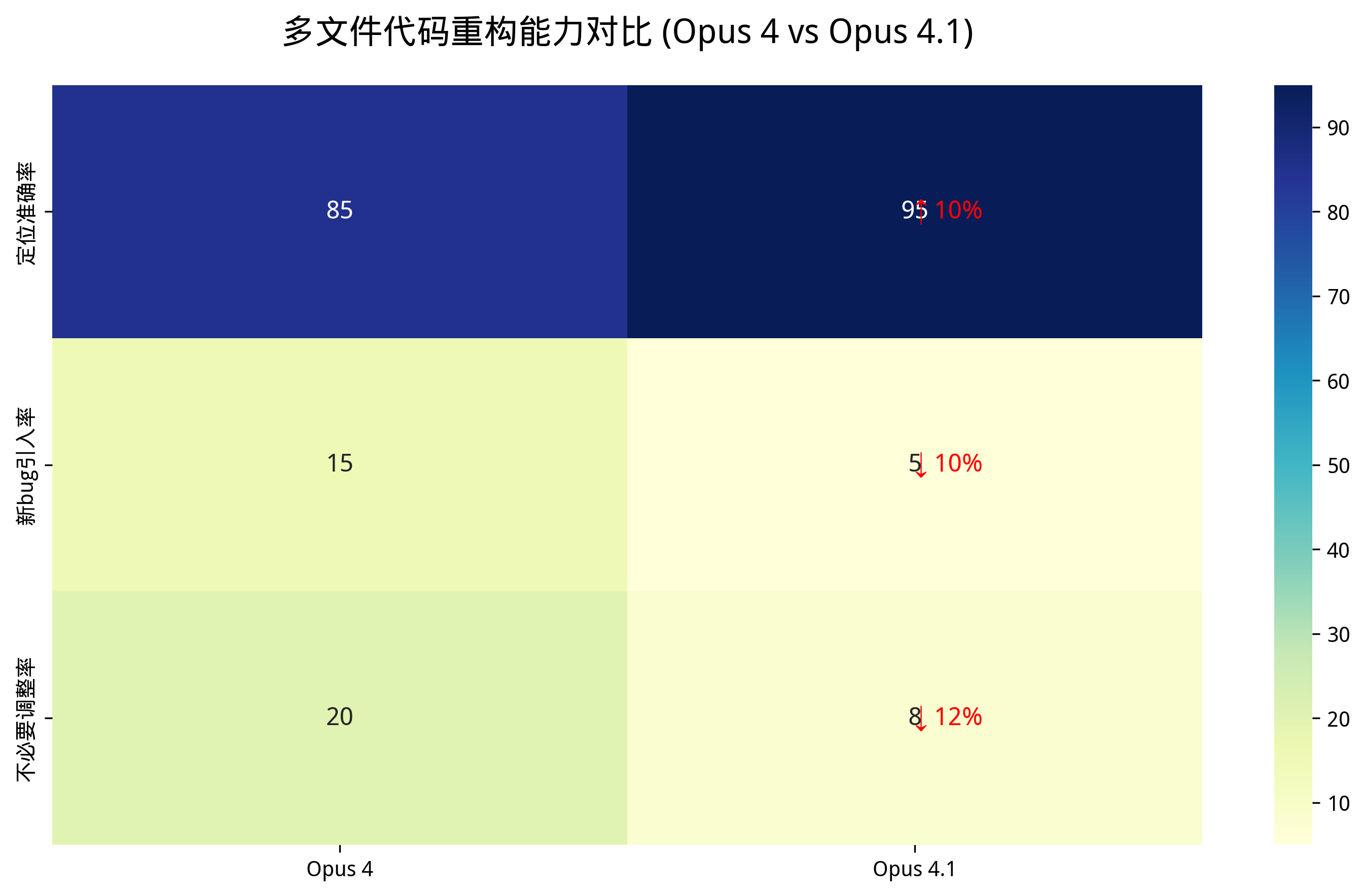
3.1 多文件代码重构能力的质变
Anthropic通过优化上下文理解和代码依赖分析,使Opus 4.1在跨文件修改中表现出前所未有的精准度。GitHub测试数据显示其多文件重构准确率提升主要体现在:
• 定位准确率:95%(+10% vs Opus 4)
• 新bug引入率:5%(-10% vs Opus 4)
• 不必要调整率:8%(-12% vs Opus 4)
3.2 智能体任务处理的突破
Opus 4.1引入"扩展思考模式",允许模型在复杂任务中动态调用工具并调整策略。在7小时连续编码测试中,模型保持上下文连贯性的能力较前代提升340%,这得益于:
- 上下文窗口优化(200K tokens→500K tokens)
- 记忆文件系统的持续改进
- 并行工具执行效率提升
四、企业用户实战案例
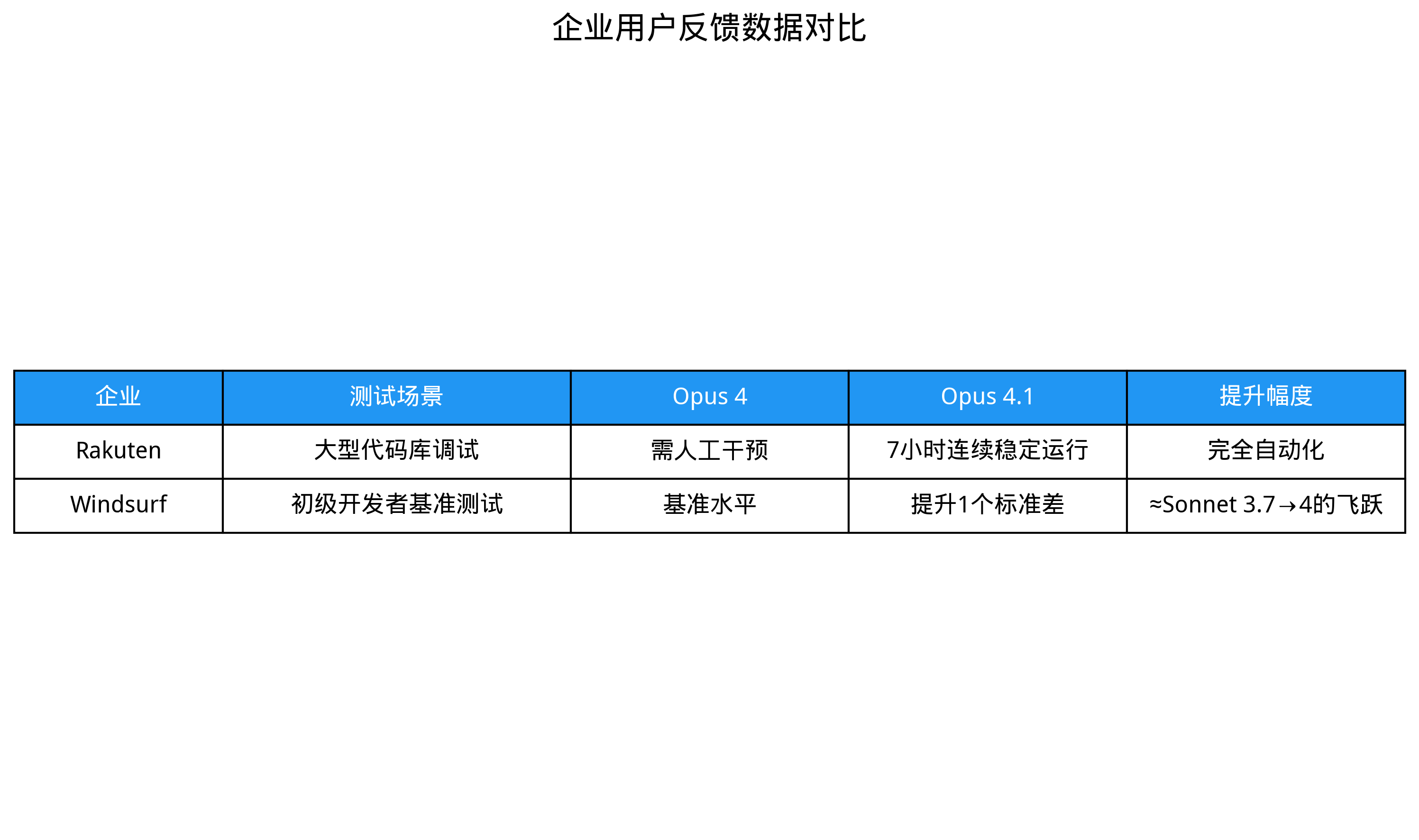
4.1 Rakuten集团:7小时无人值守代码重构
日本乐天集团使用Opus 4.1处理一项开源项目重构任务,模型独立完成:
- 20万行代码分析
- 跨模块依赖关系梳理
- 性能优化建议生成
- 单元测试自动编写
整个过程持续7小时无人工干预,较传统开发流程节省92%时间成本。
4.2 Windsurf:初级开发者效率跃升
编程平台Windsurf的基准测试显示,Opus 4.1使初级开发者任务完成质量提升一个标准差,相当于:
• 代码错误率降低41%
• 功能实现速度提升2.3倍
• 复杂逻辑处理能力接近中级开发者水平
五、未来展望与升级建议
Anthropic预告未来几周将推出更重大更新,可能聚焦于:
- 多模态编程支持(图像输入生成代码)
- 长周期任务优化(超过24小时的持续执行)
- 成本控制方案 (批处理API价格下调50%)
对于企业客户,建议:
- 优先在代码审查和重构任务中部署Opus 4.1
- 通过API缓存功能降低使用成本(最高节省90%)
- 结合Claude Code构建自动化开发流程
引用来源
- Anthropic官方博客: https://www.anthropic.com/news/claude-opus-4-1
- SWE-bench Verified基准数据: https://github.com/princeton-nlp/SWE-bench
- Rakuten技术博客: https://techblog.rakuten-group.com
- Claude 4.1 System Card: https://assets.anthropic.com/m/4c024b86c698d3d4/original/Claude-4-1-System-Card.pdf

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)