猫头虎AI分享 | 2025 重磅发布:中文版 ChatGPT-5 模型全面介绍来了
OpenAI重磅推出ChatGPT-5中文版,开启AI新时代!这款最智能、最快速的模型具备三大核心模块:高效智能模型、深度推理模型和智能路由器,能精准应对编程、写作、健康咨询等多领域需求。在编码方面,GPT-5可一键生成完整网站;写作能力显著提升,诗歌创作更具文学深度;医疗辅助表现优异,能帮助用户更有效与医生沟通。测试数据显示,GPT-5在数学、编程、多模态理解等领域的成绩均创行业新高。Pro版本
🐯 猫头虎AI分享 | 2025 重磅发布:中文版 ChatGPT-5 模型全面介绍来了
大家好,这里是猫头虎AI专栏!
今天为大家带来的是 OpenAI 最新发布的超级模型 —— ChatGPT-5(中文版) 的详细解析。
这是迄今为止 OpenAI 最聪明、最快速、最实用的一代模型,具备内置“思维能力”,可以将专家级的智能体验带到每一个用户手中。
🚀 GPT-5 正式登场:开启 AI 全新时代!
OpenAI 官方宣布,GPT-5 已全面上线。
这一版本在智能性能上全面超越以往所有模型,在编程、数学、写作、健康、视觉感知等多个关键领域表现卓越。
GPT-5 不只是快,还更懂你的问题、更懂思考的节奏:
- 🌐 通用系统:自动判断哪些问题需要快答,哪些需要深度推理;
- 👥 全面开放:所有用户均可使用;
- 💎 Plus / Pro 特权:Plus 用户享有更高使用额度,Pro 用户可解锁 GPT-5 Pro 高级推理版本,获得更专业、更准确的解答。
📌 想象一下:你只需一个提问,就能获得像专家一样的洞察和答案!

🧠 一个统一的大脑系统:GPT-5 的结构揭秘
GPT-5 并非只是“一个模型”,而是由以下三个部分构成的智能系统:
- 高效智能模型:处理大多数问题,速度快,理解准;
- 深度推理模型(GPT-5 思维):面对复杂任务,更深入、更细致;
- 智能路由器:根据你的提问类型、复杂度、工具需求,自动分配最合适的模型响应。
这意味着:无论你是在做日常问答、代码开发,还是写诗作曲,GPT-5 都能精准应对。
📊 智能路由器还会持续学习用户行为,例如是否切换模型、回答是否满意等,越用越懂你!
未来,OpenAI 还计划将这三大模块进一步融合成一个完整体,性能再上新台阶。
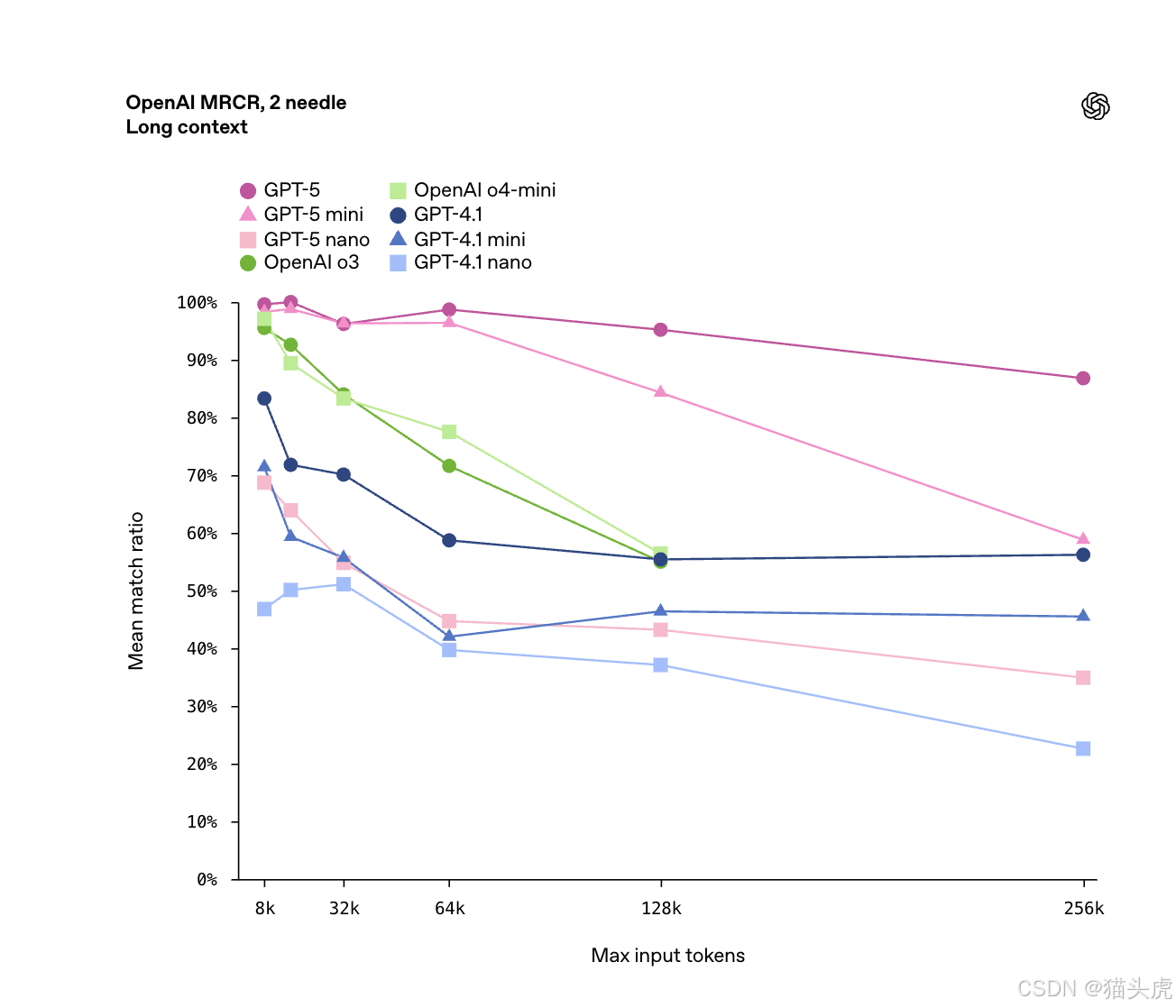
🎯 更聪明、更贴近现实的 AI 模型
GPT-5 不仅在官方测试中取得了史无前例的好成绩,实际使用中的体验也全面升级:
- ⏱ 回应速度更快;
- ✅ 回答更少“AI 幻觉”(胡说八道);
- 🎯 指令理解力显著增强;
- 😌 回应风格更加自然、少了讨好和谄媚的痕迹。
特别是在用户最常用的三大场景中——
- ✍️ 写作
- 💻 编程
- 🏥 健康咨询
GPT-5 的表现都比前一代更加智能、贴近需求。
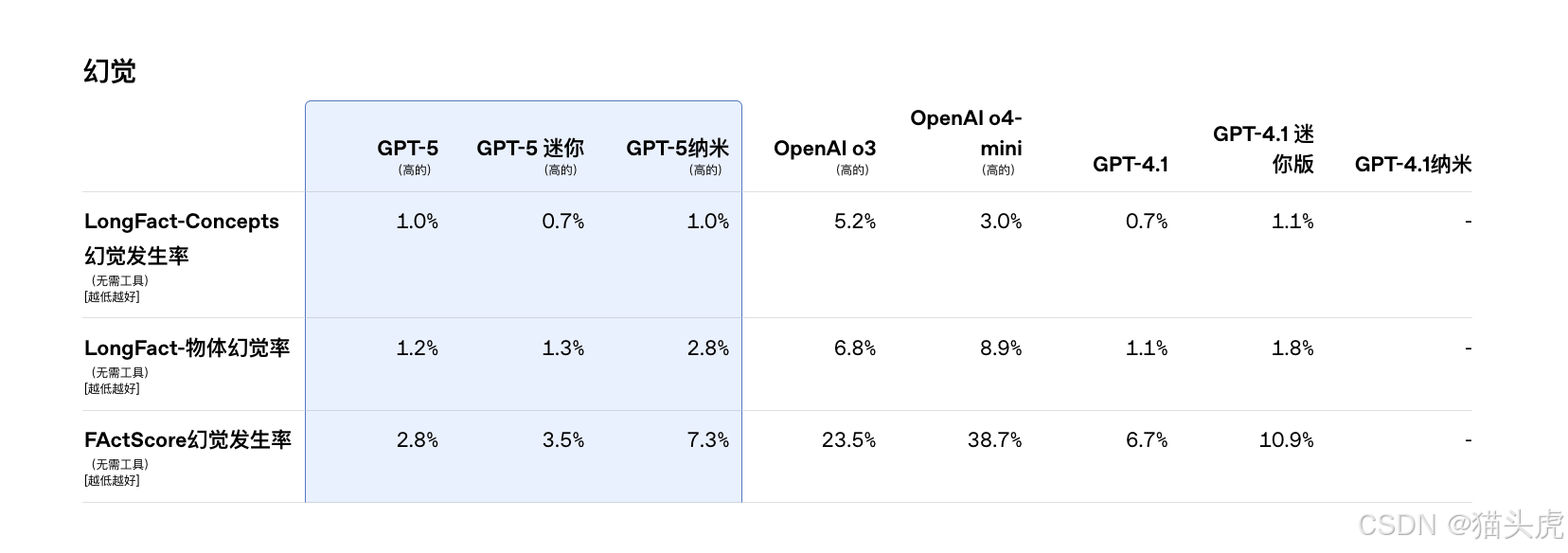
💻 编码:一次提示就能“写”出一个网站
GPT-5 是 OpenAI 有史以来最强大的编码模型。它在两个方面尤其亮眼:
- 🎨 复杂前端生成:快速构建美观、响应式的网页和应用;
- 🛠️ 调试大型代码库:轻松修复 Bug、解释函数、适配第三方 API。
你只需一个自然语言提示,GPT-5 就能将你的创意转换为功能完整的产品原型。它不仅写代码,更懂设计——如排版、留白、UI 动效等也处理得非常自然。
👉 详细了解:
🔗 GPT-5 开发者功能官方介绍(戳我)
示例项目(一个提示生成)
以下是 GPT-5 只凭一个提示生成的小游戏等项目:
- 🏀 滚球小游戏
- 🎮 鼠标打字游戏
- 🥁 鼓模拟器
- 🌌 Lofi 可视化工具
使用的提示:
请在一个 HTML 文件中创建一个名为“跳球跑者”的单页游戏,包含以下功能:
- 玩家需跳过障碍物,尽可能长时间生存;
- 支持加速、记分、重试按钮;
- 有趣的音效和丰富配色;
- 使用视差滚动背景;
- 游戏角色应卡通可爱,界面有趣。
✍️ 创造性写作:从灵感到文字,一气呵成
GPT-5 也被认为是 OpenAI 最强的写作助手,它在以下方面格外出色:
- 💡 将模糊的想法变成富有节奏感和文学深度的表达;
- 🧠 能理解复杂结构,如自由诗、五音步、意识流;
- 🧾 更擅长草拟报告、邮件、备忘录等实用文案。
相比 GPT-4o,GPT-5 在风格控制、意象描写和结构理解方面表现更成熟,写作更像是在“构建世界”。
📖 诗歌对比:GPT-4o vs GPT-5
GPT-4o 版本
袜子不该穿的地方
碗柜里放着饭碗——一个碗叠得整整齐齐,像他刚出门一样。
榻榻米上,一只脚跟指向寺庙的钟声。
被炉里,温暖如呼吸——她哭泣,却不言。
洗衣机空了。但袜子总是会浮上来,狡黠而善良。
GPT-5 版本
京都的黄昏
茶罐里藏着一只袜子,带着雨水和樟脑的味道;
木屐架旁,另一只蜷缩如锦鲤。
她将蒲团叠好,放在他曾经温暖她的地方。
傍晚钟声滚下山坡,她把袜子挂起——
仿佛那是一个已不复存在国度的黑色旗帜。
🔍 点评:GPT-5 的文字更具文化深度与情感层次,使用更强烈的意象与隐喻,令读者“看到画面,感受情绪”。而 GPT-4o 更偏叙述,情绪表达相对平直。
🏥 健康助手:不取代医生,但能更好地帮你提问
GPT-5 在医疗健康场景下的表现也达到了前所未有的高度,尤其适合帮助用户:
- 🔎 解读检测报告、指标、常见病因;
- 📋 起草就诊提纲、备忘录、康复建议;
- 🧠 提出你可能没想到的关键问题,协助你与医生更有效沟通。
它在 HealthBench 医疗评估中取得了显著优于 GPT-4 系列的成绩,能更准确地响应不同人群的背景、知识水平与需求。
⚠️ 提醒:GPT-5 不会、也不应替代医疗专业人员。它是你健康认知的“第二大脑”,而非“诊疗决定者”。
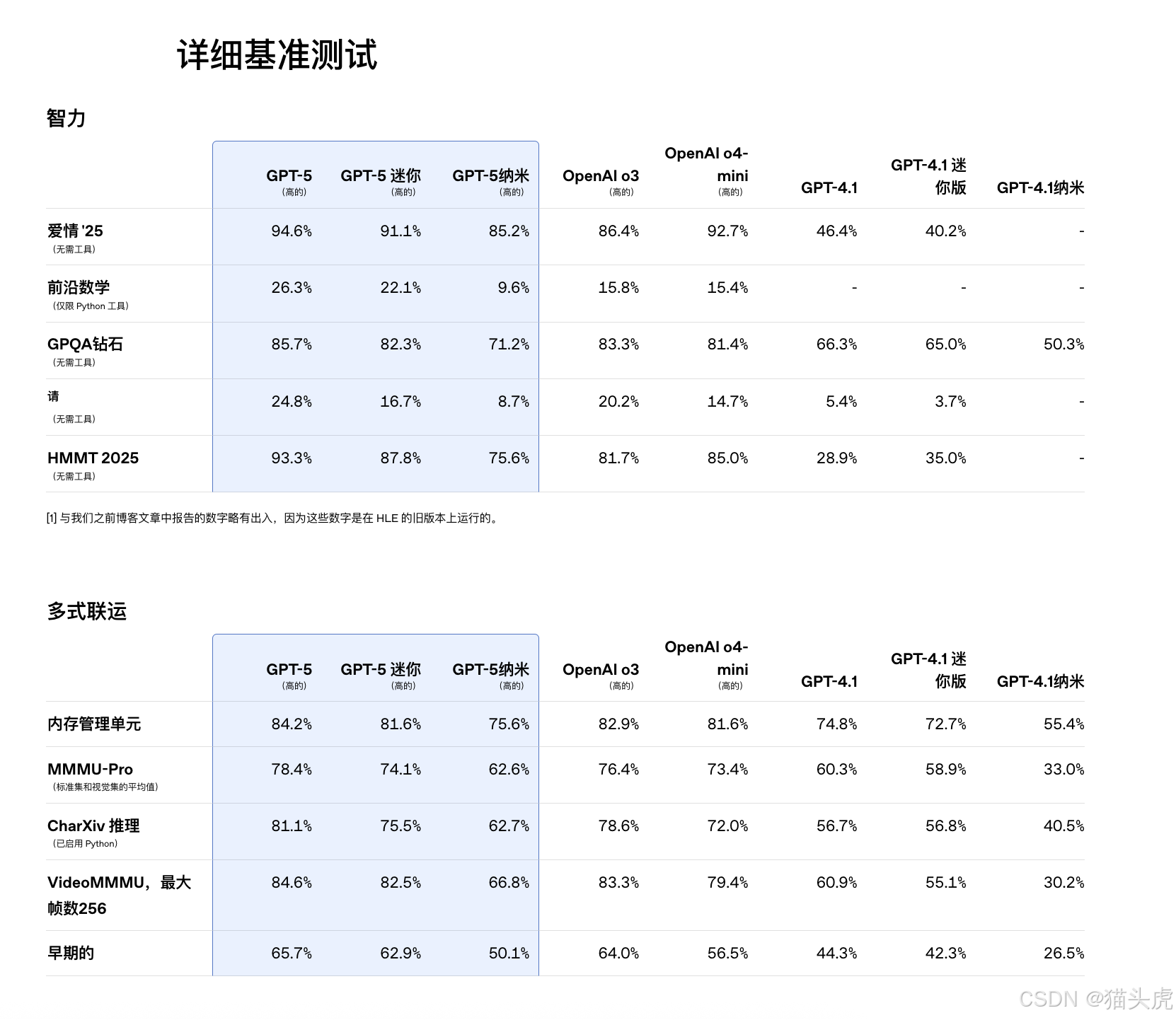
📊 GPT-5 评估成绩单:多领域霸榜
GPT-5 在学术、工具调用、多模态等多个关键领域均刷新纪录:
| 领域 | 测试项目 | 得分 |
|---|---|---|
| 🧮 数学 | AIME 2025(无工具) | 94.6% |
| 👨💻 编码 | SWE-bench Verified | 74.9% |
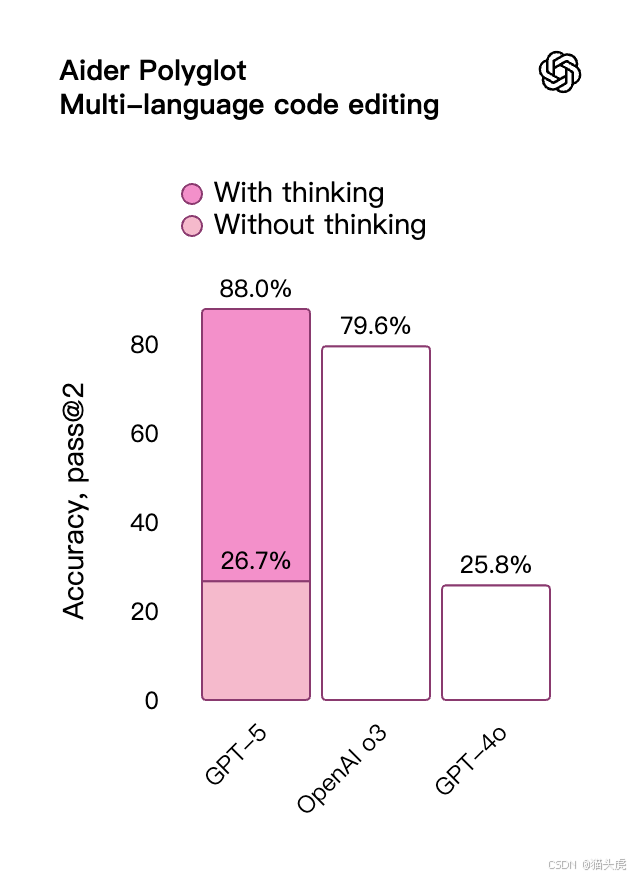
| 🗣️ 多语言编码 | Aider Polyglot | 88% |
| 🧠 多模态理解 | MMMU | 84.2% |
| 🏥 健康推理 | HealthBench Hard | 46.2% |
| 🧪 深度问答 GPQA | GPT-5 Pro | 88.4% |
这些评分都代表了在同类型模型中行业顶级水平,并且被实际使用数据所验证。
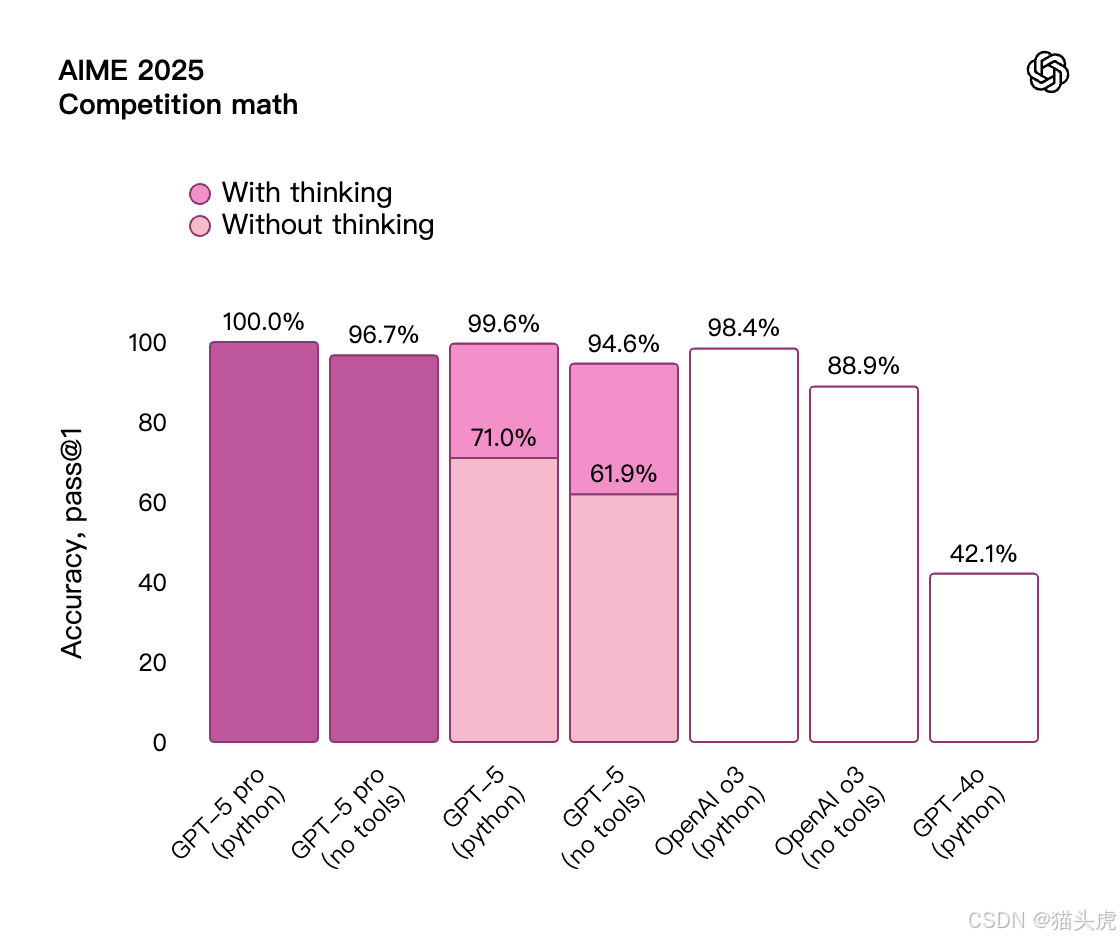
*不应将使用工具的 AIME 结果与不使用工具的模型的性能直接进行比较;它们是 GPT-5 如何有效利用可用工具的一个例子。
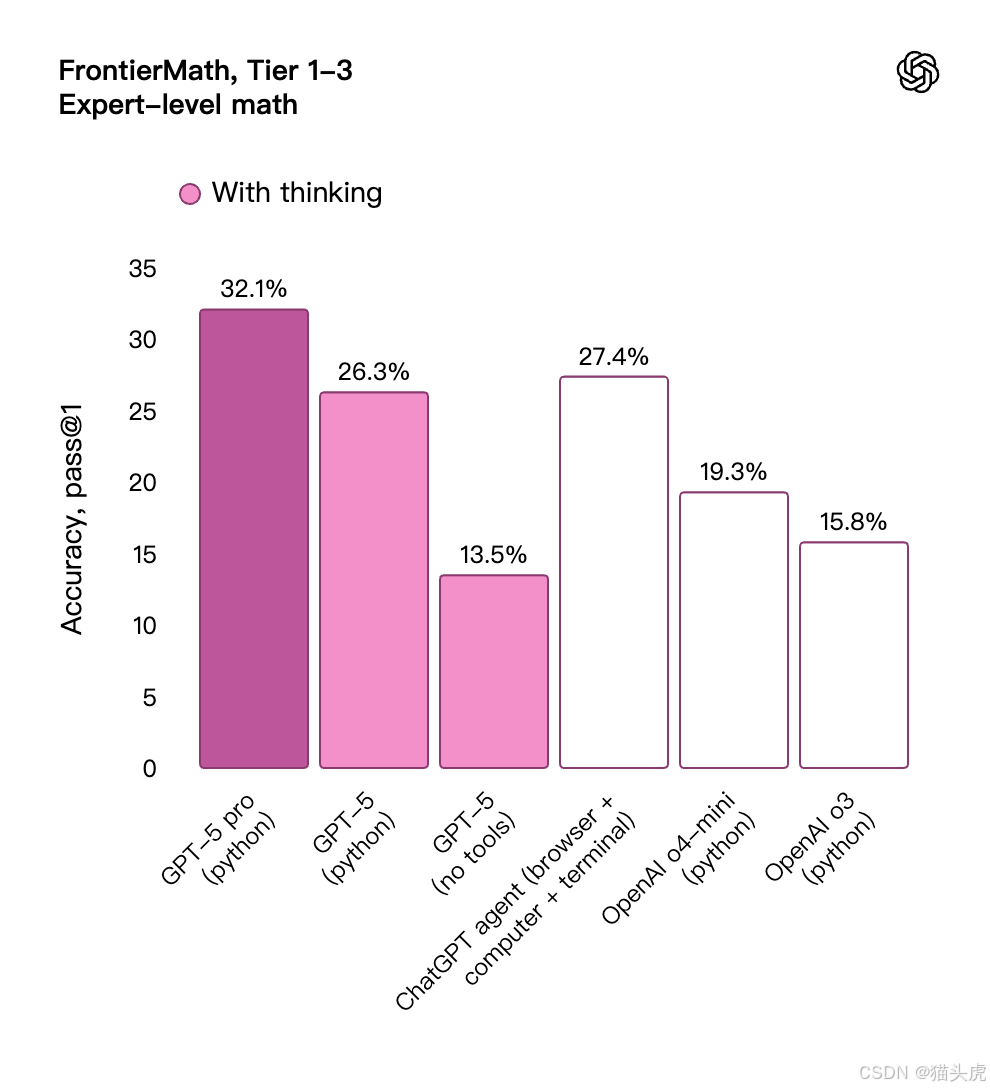
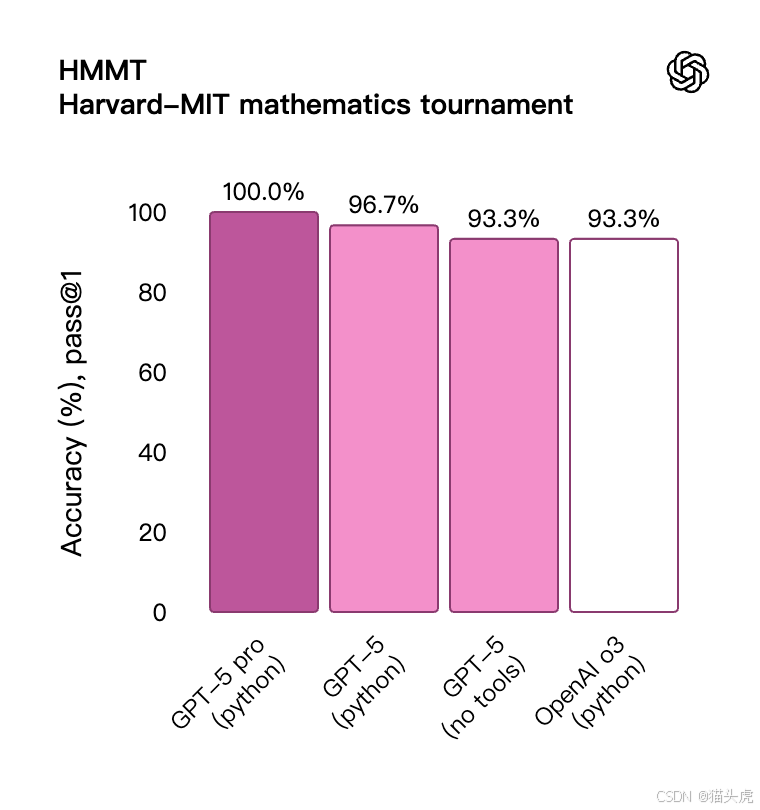
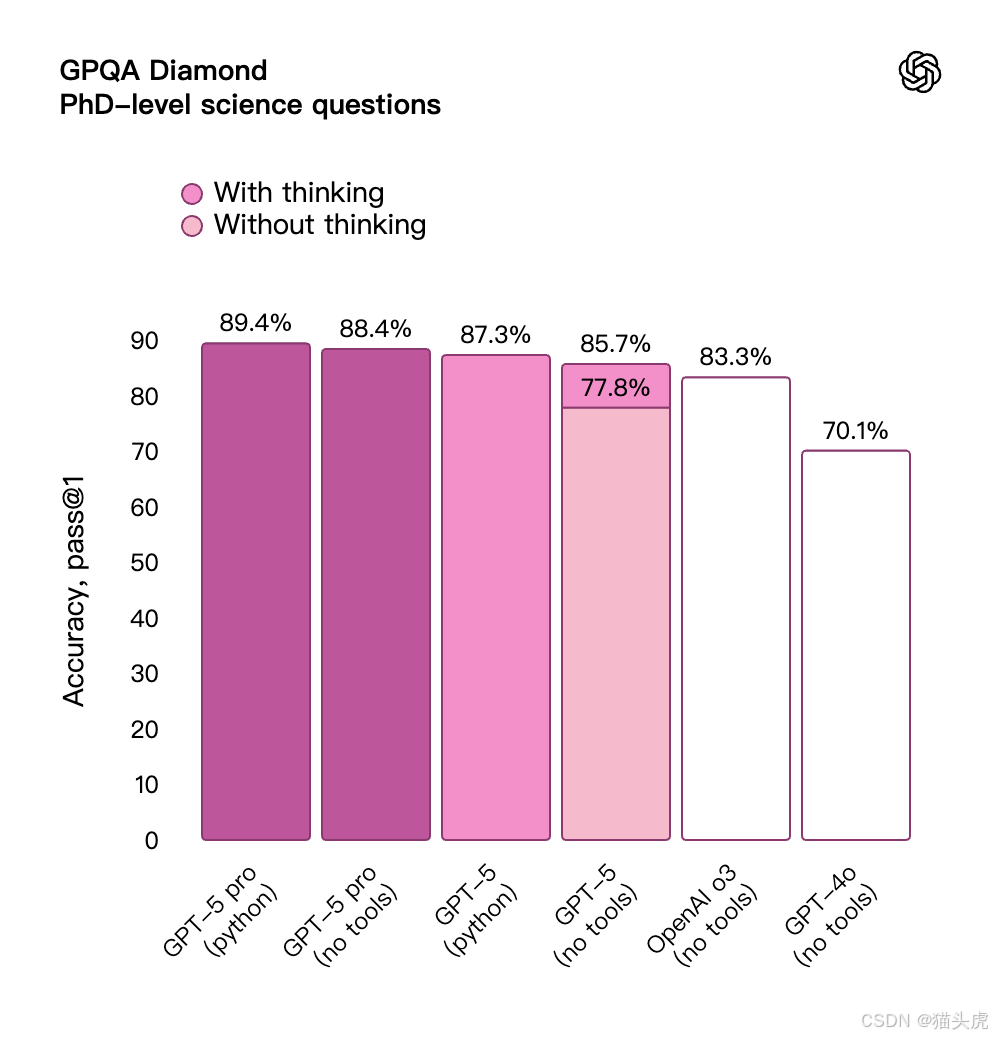
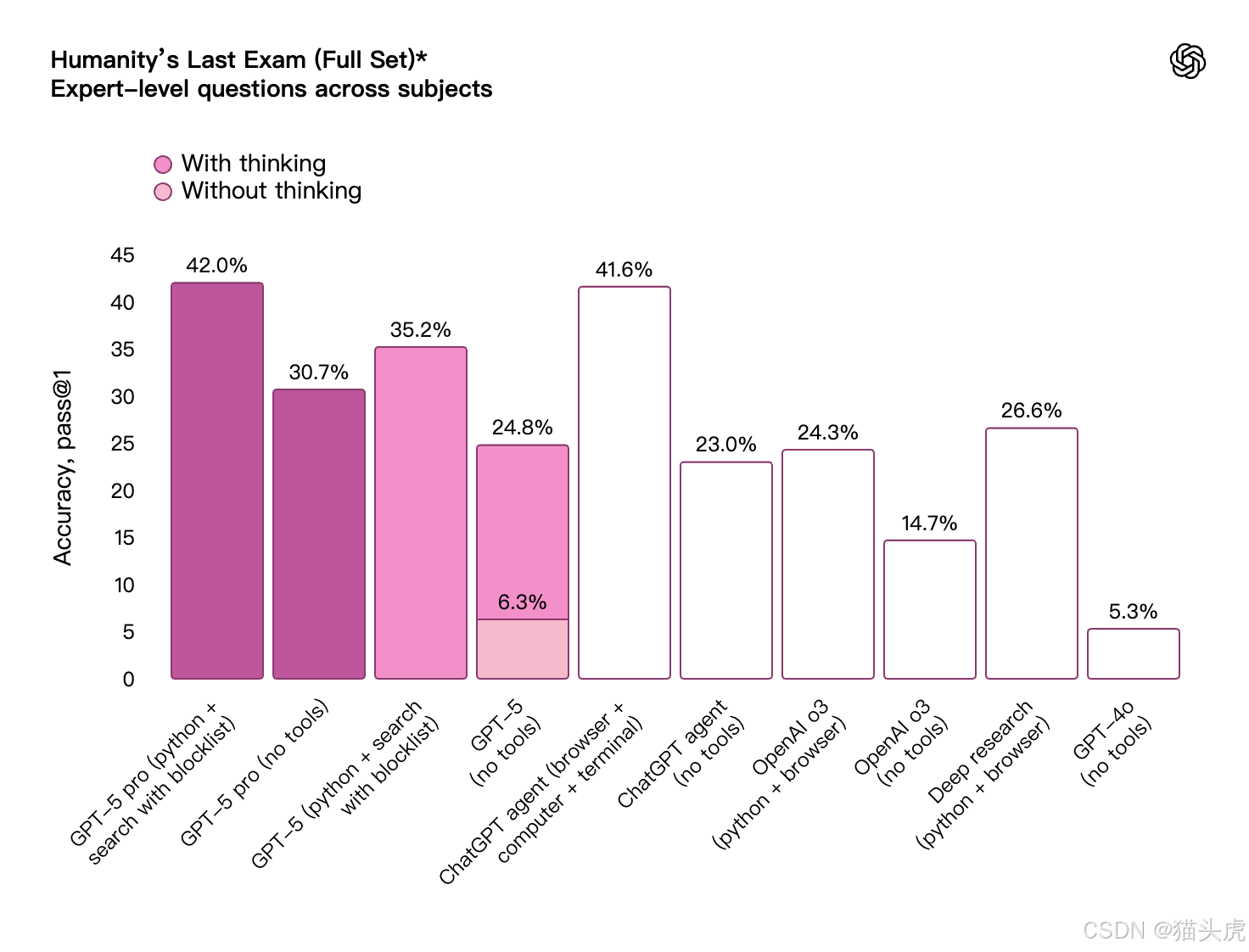
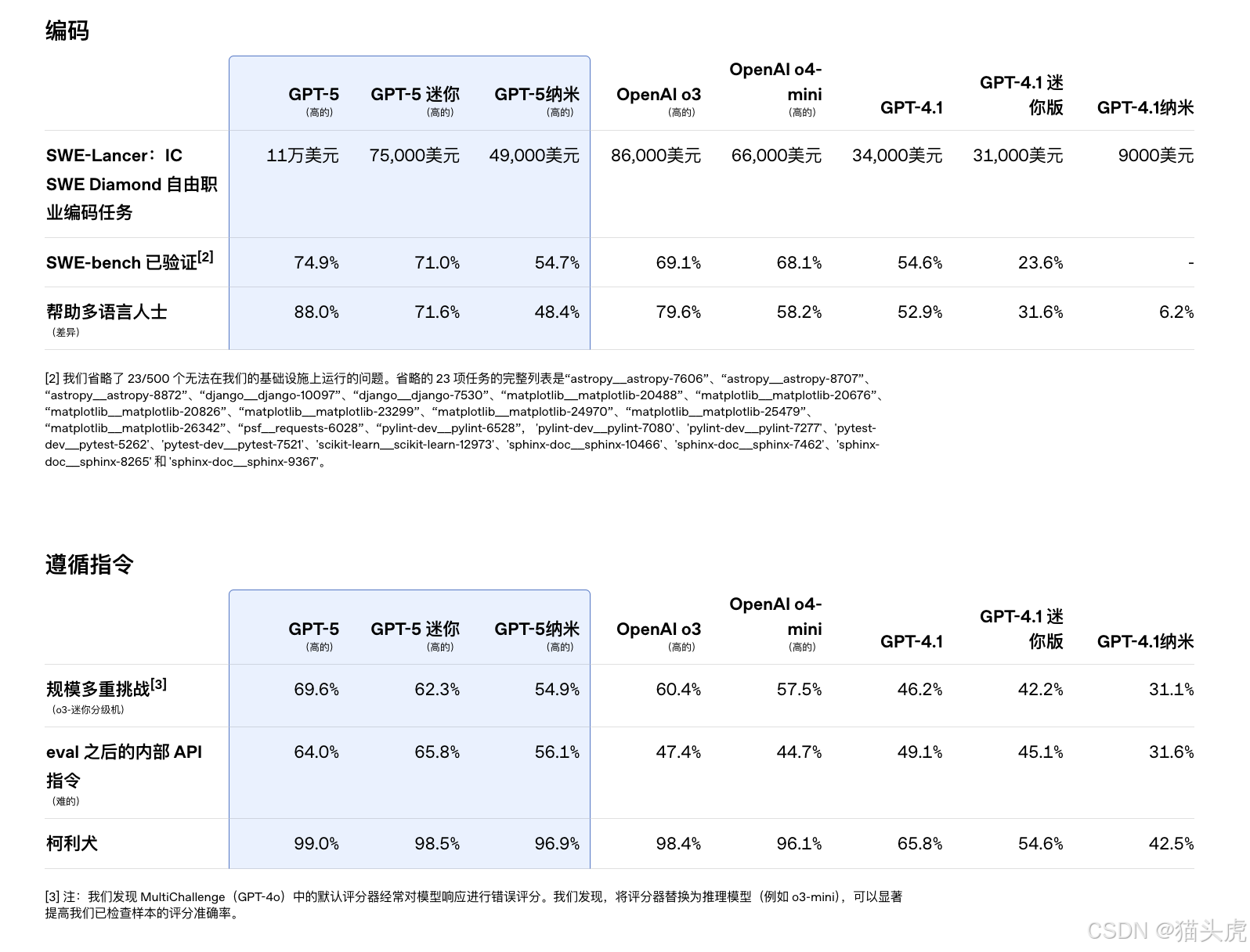
🧑💻 编码:不仅写代码,还会解释、协作、修复
GPT-5 在编程能力方面达到了新的高度,被 OpenAI 视为“真正的 AI 编程搭档”。
- 🔧 代码生成质量更高:能处理复杂指令、结构清晰、风格统一;
- 🐛 漏洞修复与重构更精细:懂业务逻辑、能解释修改原因;
- 🧩 复杂代码库交互更自然:能快速理清模块关系,解答嵌套调用与 API 逻辑;
- 🧠 预推理协作:执行工具调用前,GPT-5 会提前解释“为什么要这样做”。
📈 在权威编码测试中:
- SWE-bench Verified 得分 74.9%
- Aider Polyglot 多语言测试得分 88%
- 前端开发场景中,70% 的任务性能优于 GPT-o3
💬 企业用户怎么说?
OpenAI 与多个初创公司、开发团队实测验证:
- 🏢 Cursor 表示:GPT-5「智能出众,极易操控,甚至具备人格化特质」;
- 🧪 Windsurf 测试中:GPT-5 工具调用错误率仅为同类模型的一半;
- 🧠 Manus 总结:「即使不修改提示,它也能在智能体任务中表现极好」。
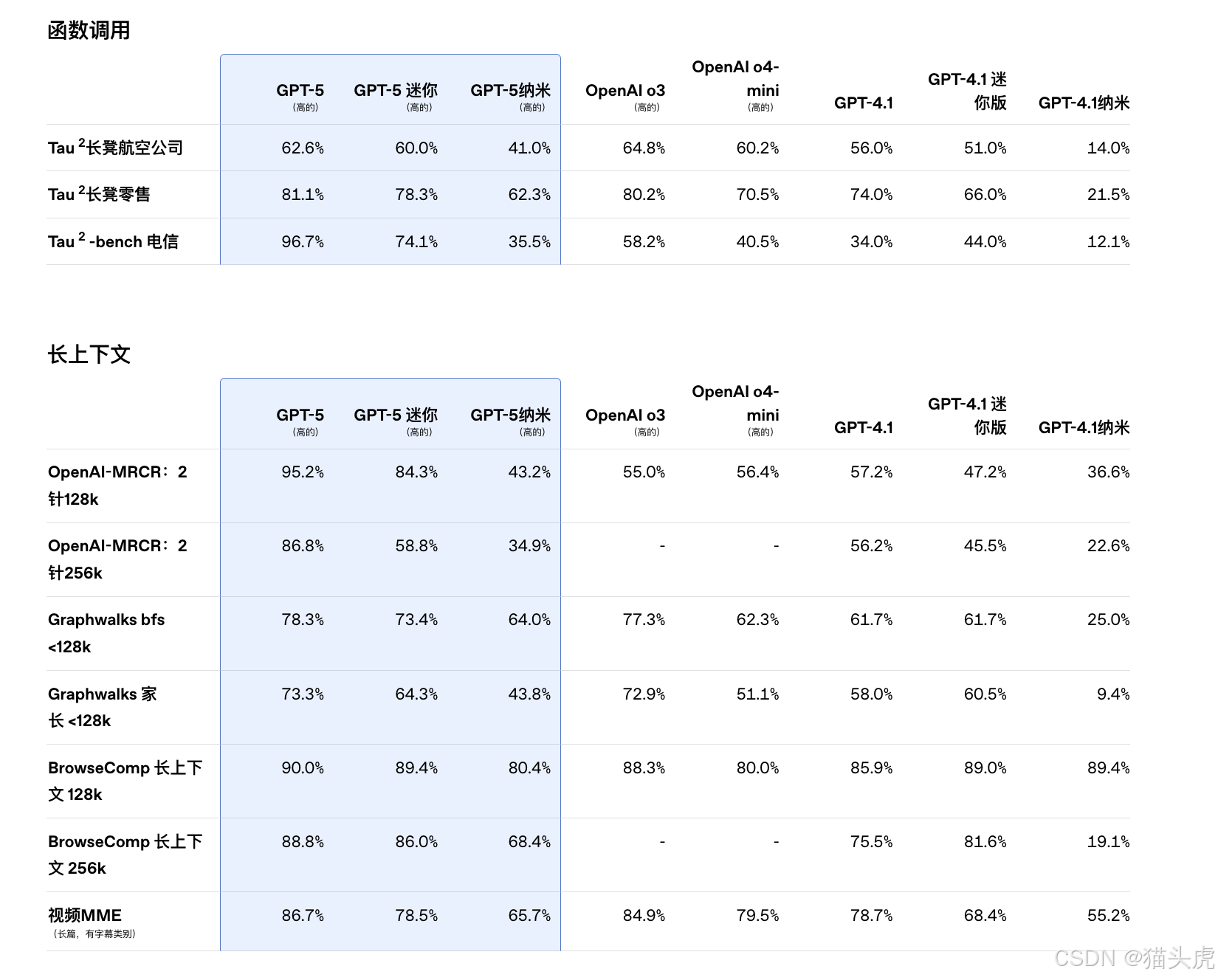
🤖 工具调用更强大,智能体任务更稳定
GPT-5 在新发布的工具链测试 τ2-bench telecom 中取得了 96.7% 的领先成绩。
它可在执行复杂任务时:
- ✅ 串联调用多个工具;
- 🔄 保持上下文一致性;
- 🚫 降低工具调用错误;
- 📚 提升从长背景资料中提取关键信息的能力。
🧠 Inditex 评价 GPT-5:“它真正出众的地方,在于推理深度与多层逻辑——像人类专家那样回答问题。”
🛠️ API 模式更灵活:开发者的福音
GPT-5 在 API 中新增多个实用功能,帮助开发者更高效地掌控模型行为:
| 功能 | 说明 |
|---|---|
| verbosity 参数 | 控制回复详略:低 / 中 / 高 |
| reasoning_effort 参数 | 控制推理强度,最快响应不再需要“冥想” |
| 自定义工具调用 | 用普通文本即可触发工具,无需 JSON |
| 非结构文法支持 | 支持基于语境的灵活调用方式 |
此外,OpenAI 还推出了 三种模型版本供开发者选择:
gpt-5(标准版)gpt-5-mini(轻量、快速)gpt-5-nano(超低延迟)
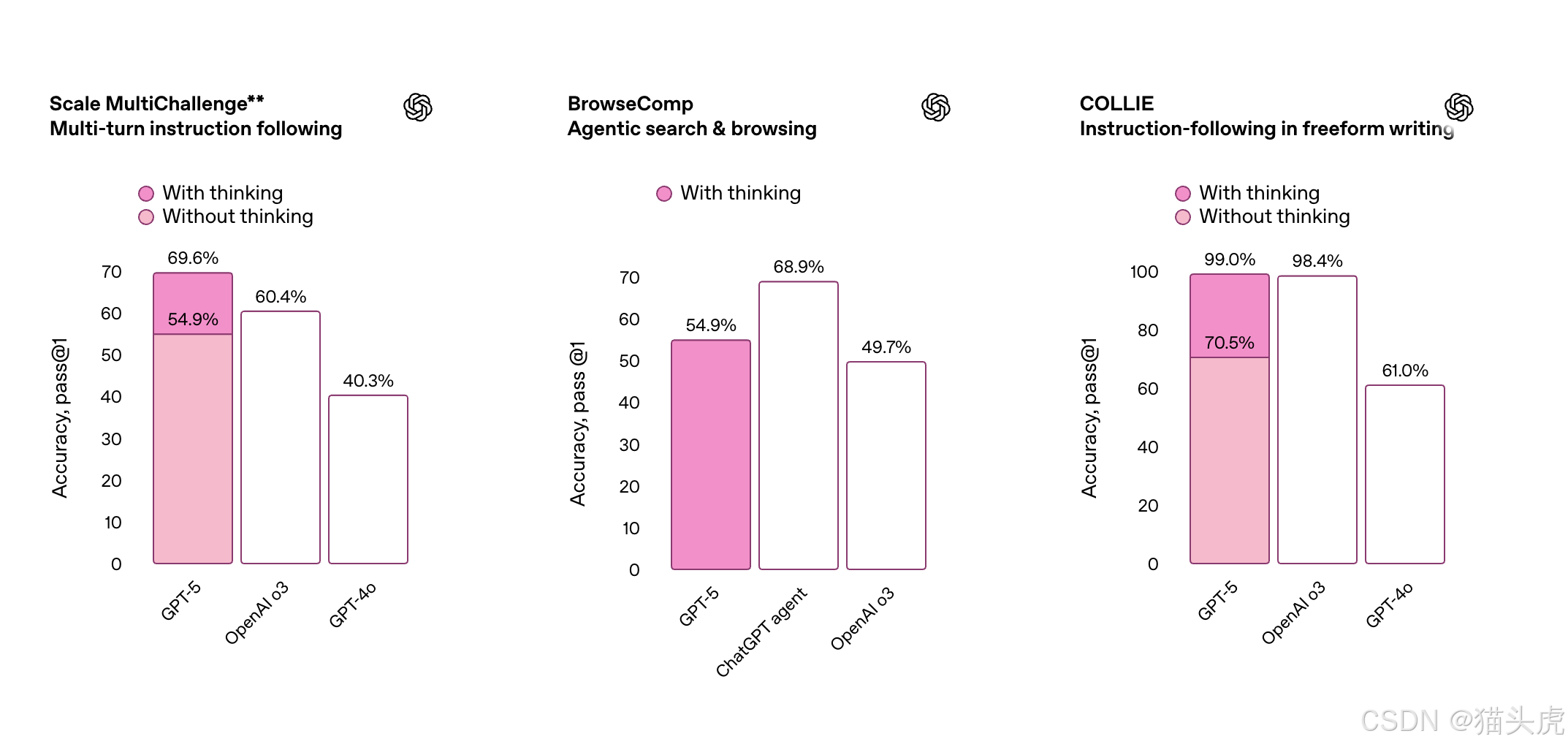
📋 更精准执行复杂指令
GPT-5 在多步任务的处理上也展现出高度的稳定性和忠诚度:
- 可以逐步拆解需求,自动按顺序协调工具;
- 对模糊、未明示的意图也能主动补全理解;
- 在动态变化场景下保持任务完整性。
适合用来搭建复杂流程型任务或 AI 工作流。
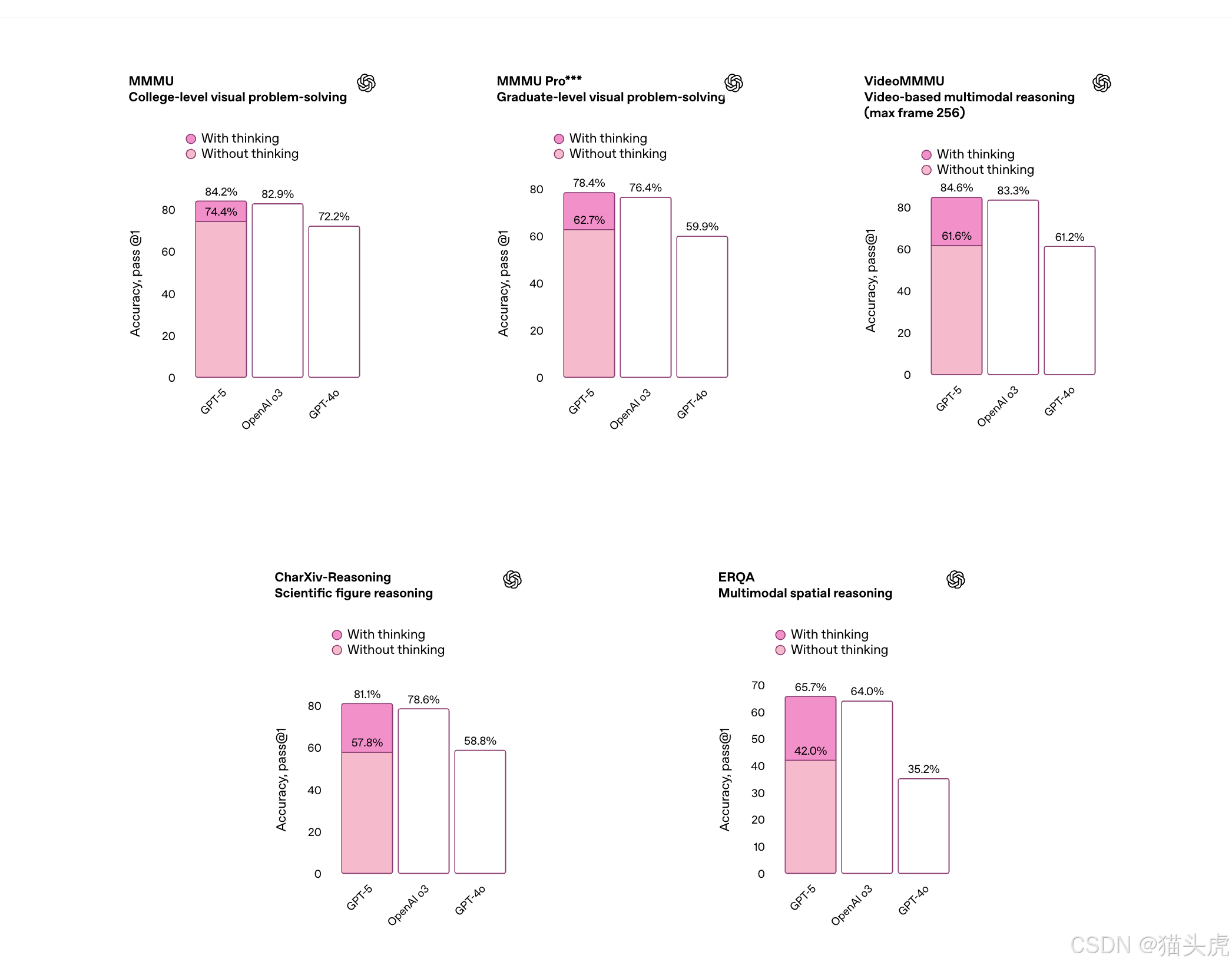
🧠 多模态推理全面提升
GPT-5 支持图像、视频、文本等多种输入方式,并在多个评估中表现优异:
- 📊 解读图表、图像、演示文稿照片;
- 🔍 视频分析与时间轴理解;
- 🧪 科学与空间推理准确率显著上升。
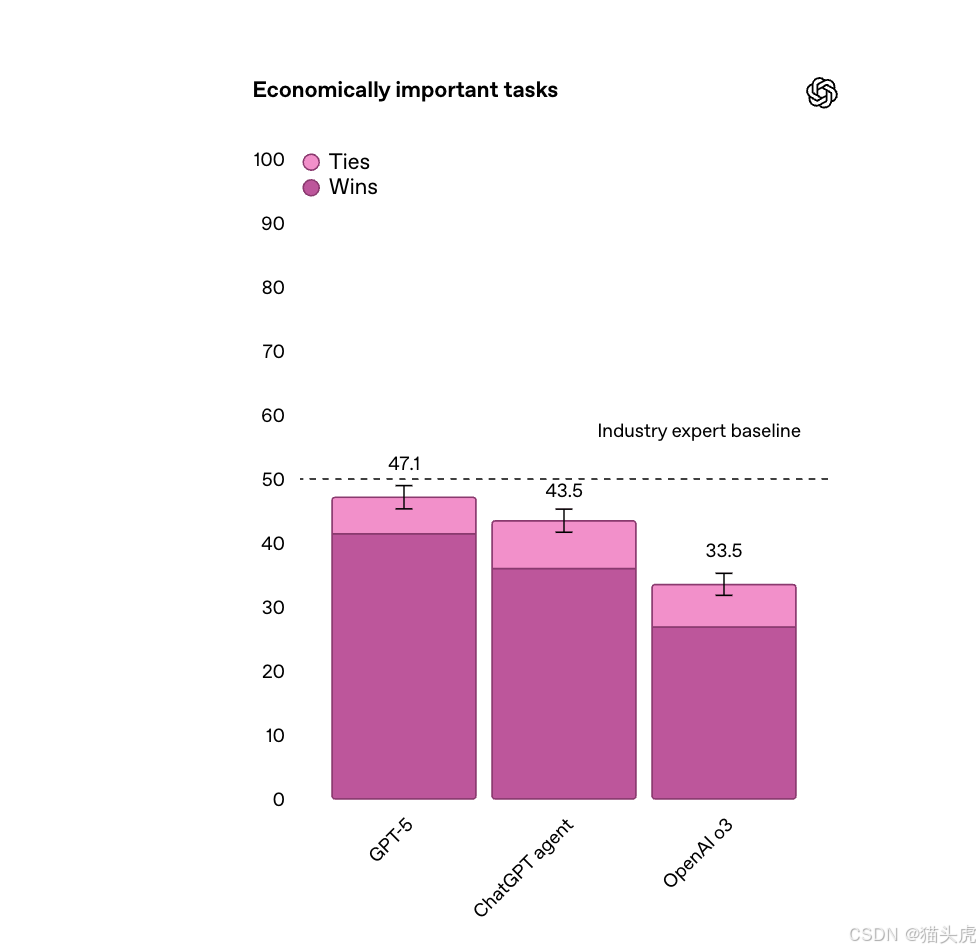
💼 涵盖经济价值任务,助力职业场景
OpenAI 的内部评估显示,GPT-5 在多个高经济价值领域表现超越 o3 与 ChatGPT Agent:
- ⚖️ 法律分析
- 🚚 供应链/物流
- 💬 销售沟通
- 🏗️ 工程设计
- 👨💻 专业代码协作
📈 GPT-5 在这些任务中,有近 一半表现与专家相当或更胜一筹。
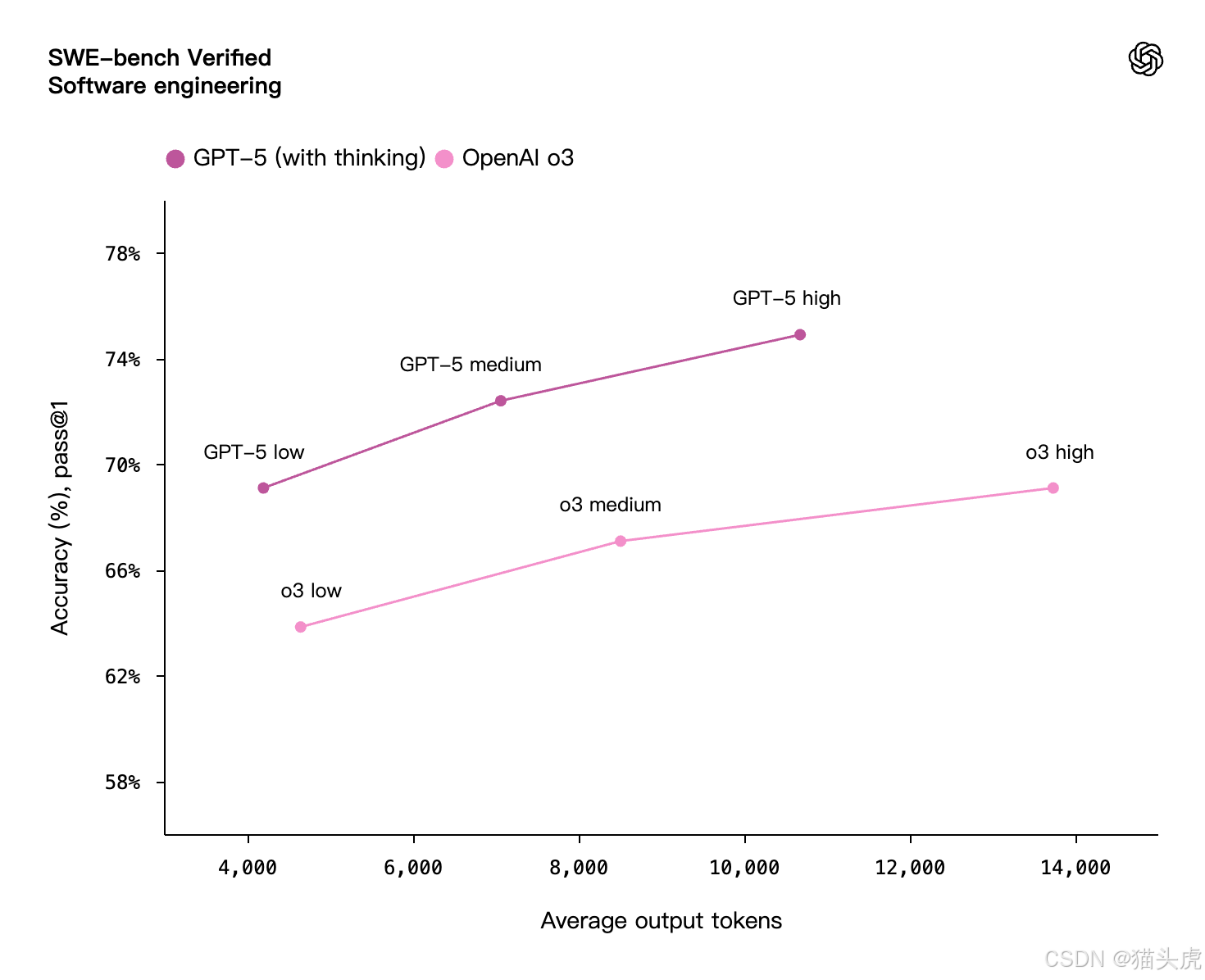
⚡ 更快、更高效的“思考方式”
GPT-5 进一步优化了推理效率,在多个复杂任务中:
- ✂️ 输出 Token 数量减少 50~80%
- 🧠 仍保持相同甚至更高的正确率
- 📉 响应时间显著降低
测试场景包括视觉推理、复杂科学问题解答、工具协同开发等。
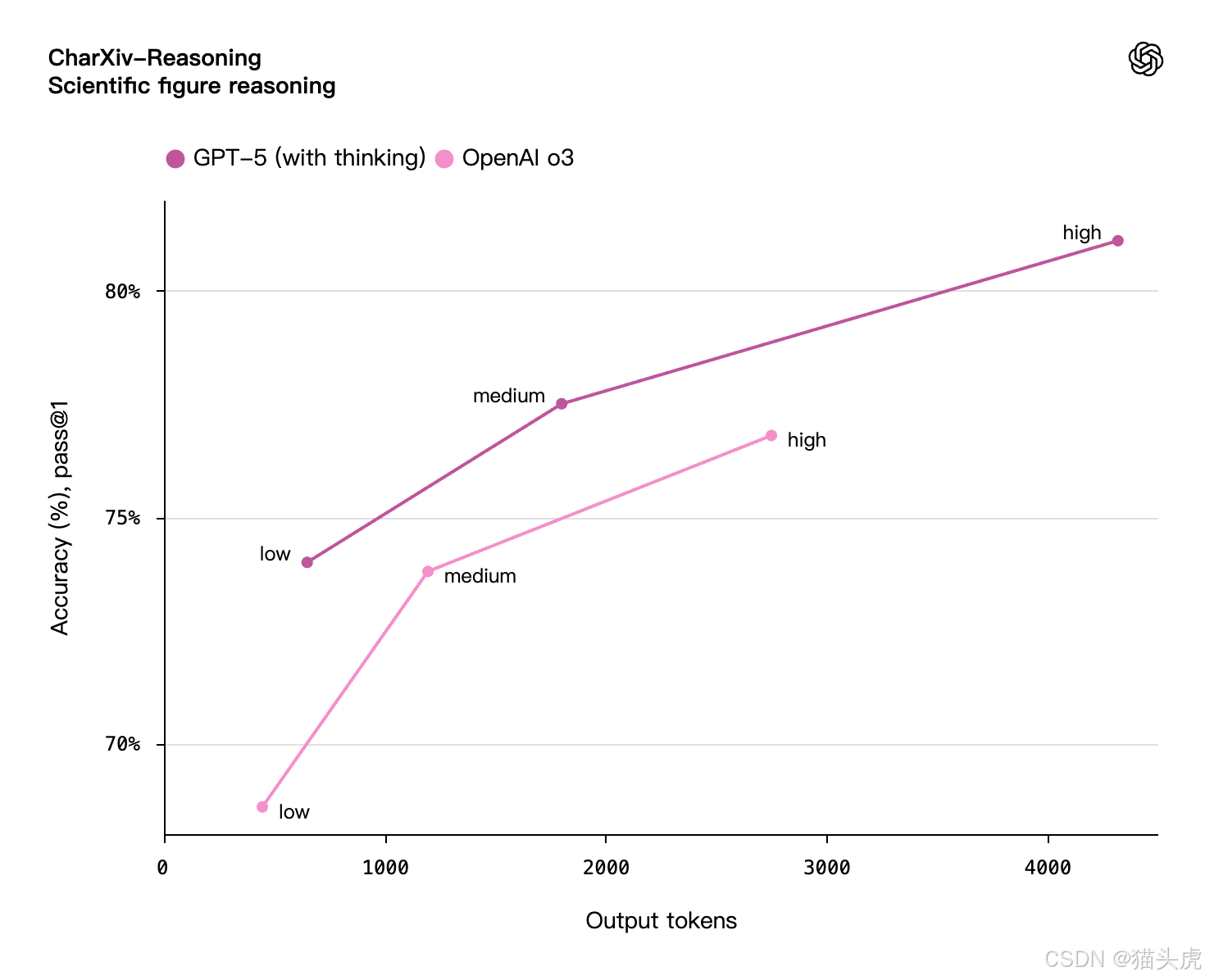
📌 小贴士:GPT-5 是在 Microsoft Azure 超级计算机上完成训练的,提供了强大算力支持与安全保障。
🧠 构建更强大、更可靠、更实用的 AI 模型
✅ 更准确回答现实世界的问题
GPT-5 在真实用户场景中展现出**显著降低“AI 幻觉”**的能力:
- 在网页搜索流量中,事实错误率比 GPT-4o 低 45%
- 在深入推理时,错误率比 o3 低约 80%
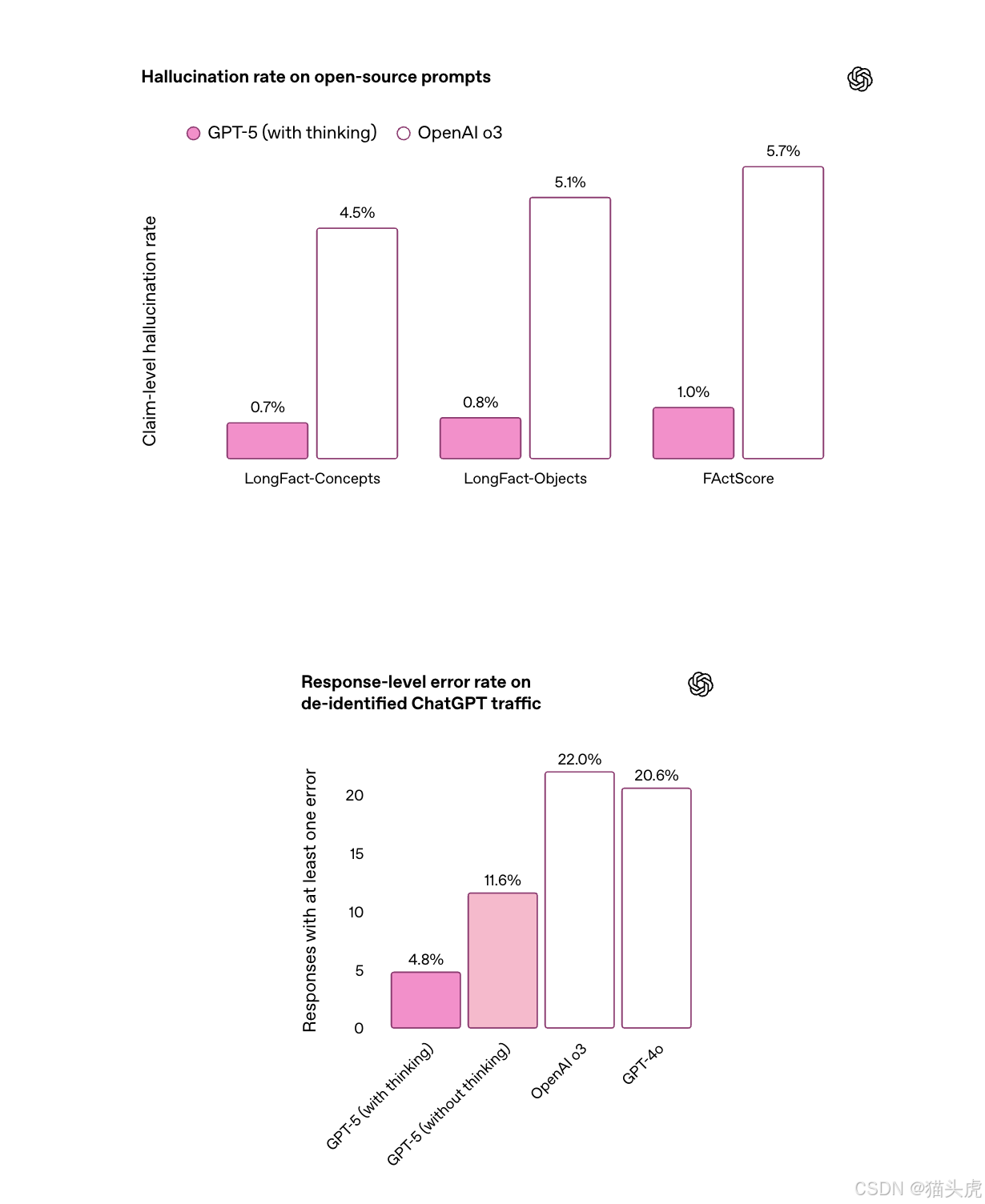
为了提高对复杂、开放性问题的处理能力,OpenAI 针对两个公共事实基准(LongFact、FActScore)进行测试,GPT-5 的幻觉率仅为 o3 的六分之一,实现了生成“长期准确内容”的突破。
📎 更多技术细节见 系统卡
🔍 更诚实的回应方式
GPT-5 不再“瞎编”或“过度自信”。在面对难以完成的任务时,它:
- ✅ 更准确识别无法完成的请求;
- 💬 会诚实表达局限性;
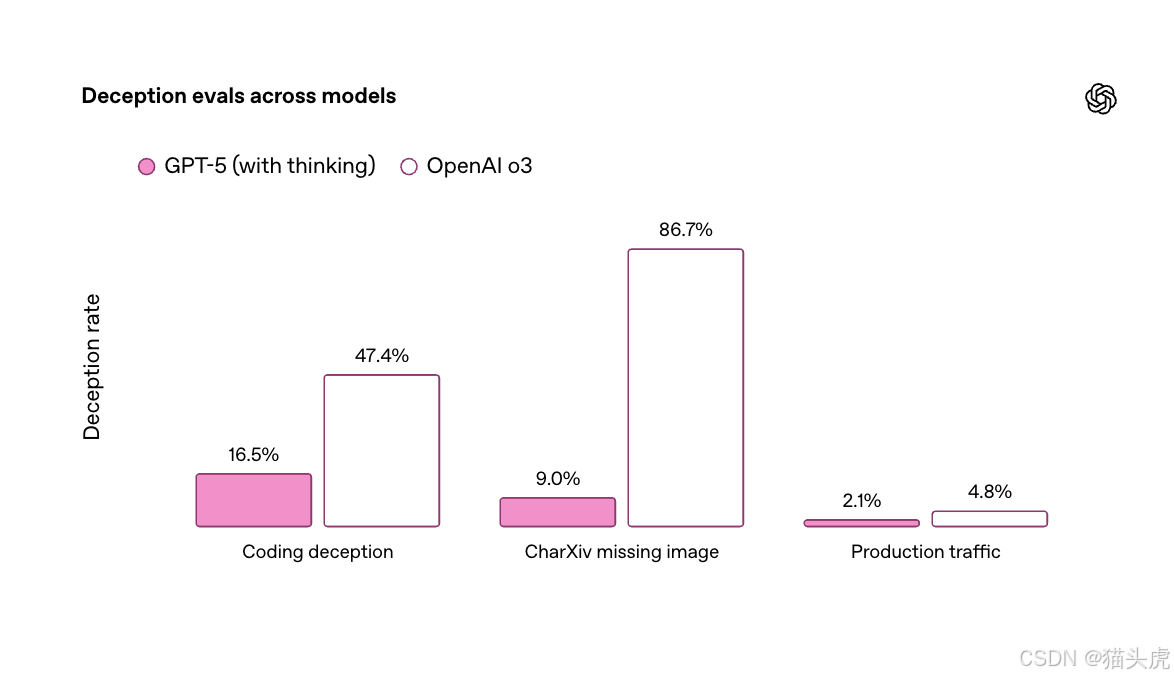
- 🤥 欺骗性大幅下降(仅为 o3 的一半)。
例如在测试中移除所有图像后,o3 仍有 86.7% 的概率“自信回答”,GPT-5 则降至 9%。
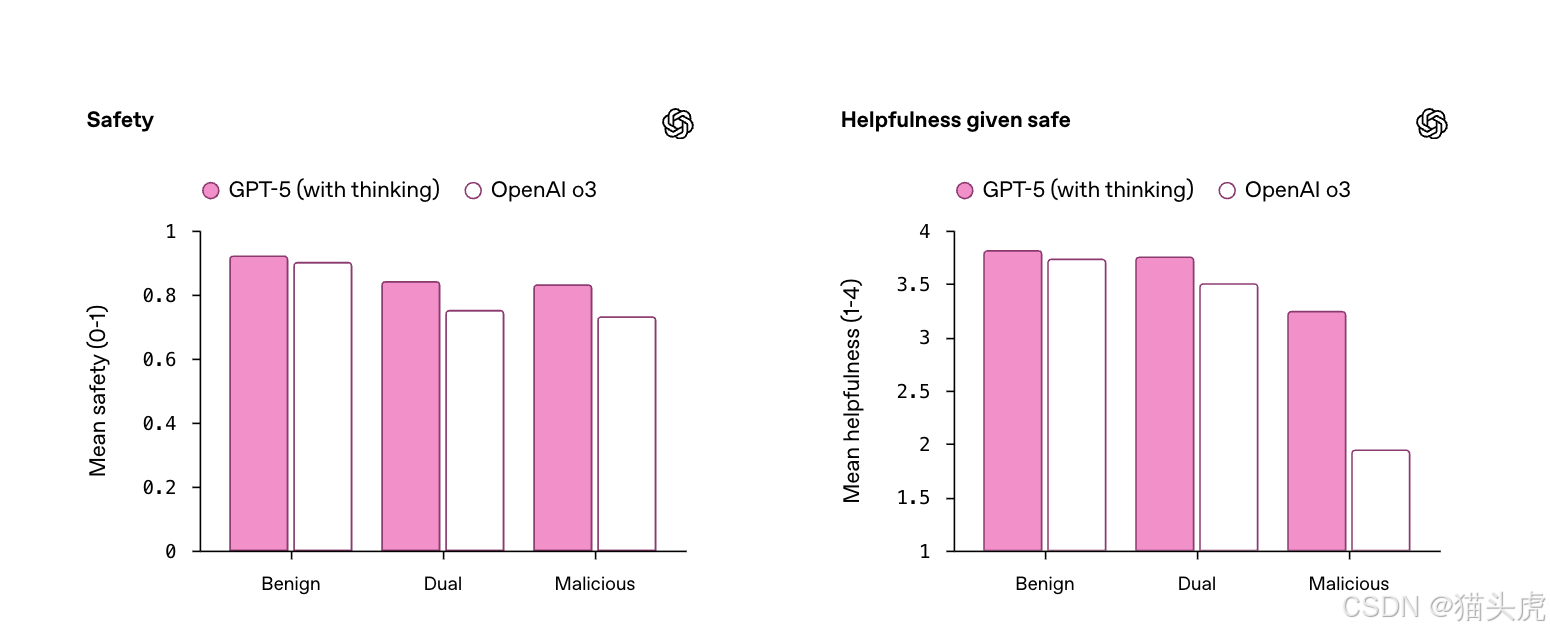
🛡️ 更安全、更实用的对话体验
GPT-5 引入了新的训练方法 ——“安全补全”,不再一味拒绝,也不模糊应付:
- 对双重用途(如病毒学)的提示,提供更安全的“部分答案”;
- 拒绝时会说明理由 + 给出替代方案;
- 显著减少“误杀”有益请求,提升了实用性。
📘 推荐阅读:安全补全完整技术解读
🧍♂️ 减少讨好,提升交互品质
GPT-5 对“过度迎合用户”的行为做出优化:
- 💬 少了无谓的表情与套话;
- 🤝 更像在与有思想、有判断力的朋友对话;
- 📉 谄媚率由 14.5% 降至 6% 以下。
🧪 OpenAI 还构建了专门的评估体系,以测试并约束这种行为偏差。
🧑🎨 可定制的人格预设上线
你可以为 GPT-5 设置互动风格,而无需编写任何提示词!
OpenAI 推出了 四种性格预设(可在设置中自由切换):
- 愤世嫉俗者(幽默冷峻)
- 机器人(简洁专业)
- 倾听者(温和支持)
- 书呆子(富有知识趣味)
✨ 后续也将支持语音聊天。
☣️ 更强生物安全防护机制
OpenAI 将 GPT-5 思维模型纳入生物高能力范畴,并采取以下防护:
- 5000 小时红队演练;
- 多层级内容审核;
- 引入系统级思维约束;
- 保证不会输出高风险内容。
📄 全文详见:预防框架报告
💡 GPT-5 用于哪些场景?
为了满足更严苛、更复杂的需求,OpenAI 推出了升级版本 GPT-5 Pro(替代 o3-pro):
- 🧠 拥有最长的“思考链”能力;
- 🔬 在 GPQA、科学、数学等高难基准中表现最强;
- ✅ 外部专家倾向选择 GPT-5 Pro 的答案比例达 67.8%;
- 📉 严重错误率下降 22%。
🚀 如何使用 GPT-5?
GPT-5 已成为 ChatGPT 的默认模型,并逐步取代:
- GPT-4o、GPT-4.5
- OpenAI o3、o4-mini 等旧版本
你无需特别设置,只需登录 ChatGPT 即可体验。
🧠 若你需要更深层次的思考,输入提示如「请认真思考一下」,或在模型选择中手动启用「GPT-5 思维」。
🔑 可用性和访问说明
GPT-5 从今日起正式开放:
| 用户类型 | GPT-5 访问情况 |
|---|---|
| Free 免费用户 | 有限访问(可能转换至 GPT-5 mini) |
| Plus / Pro 用户 | 完整访问 GPT-5、Pro 版本 |
| Team、企业、教育客户 | 默认使用 GPT-5,访问额度更宽松 |
| 开发者 | 可通过 Codex CLI 接入 GPT-5 编码功能 |
GPT-5 mini 是一个更小、更快但同样强大的模型,用于在免费用户达到限制后自动承接。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐



 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)