
深入探讨这三大领域的核心技术、实践应用及未来趋势,并通过代码示例、流程图、Prompt设计和数据分析展示其实现方式与价值。
本文探讨了AI编程技术的三大核心领域:自动化代码生成、低代码/无代码开发平台和算法优化实践。通过详细的技术实现和案例分析,展示了这些技术如何提升开发效率、降低技术门槛并优化系统性能。文章包含丰富的代码示例、流程图和性能对比数据,涵盖了从API客户端生成、单元测试编写到复杂算法优化的全过程。同时,文章也前瞻性地分析了AI编程的未来发展趋势、技术挑战及其社会影响,指出人机协作将成为主流开发模式,并强调
引言
人工智能正在深刻改变软件开发的范式,从传统的手动编码向智能化、自动化方向演进。AI编程技术主要涵盖三大领域:自动化代码生成、低代码/无代码开发平台以及算法优化实践。这些技术不仅提高了开发效率,降低了技术门槛,还使开发者能够专注于更高层次的创造性工作。本文将深入探讨这三大领域的核心技术、实践应用及未来趋势,并通过代码示例、流程图、Prompt设计和数据分析展示其实现方式与价值。
一、自动化代码生成
1.1 概念与原理
自动化代码生成是指利用AI技术(特别是大型语言模型)根据自然语言描述、设计文档或部分代码自动生成完整程序的过程。其核心原理基于:
- 大型语言模型(LLM):如GPT-4、Claude、CodeLlama等,通过海量代码库训练,理解编程语言语法、语义和模式
- 程序合成技术:将高层需求转化为可执行代码
- 代码补全与预测:基于上下文预测后续代码片段
- 多模态理解:结合文本、图表、UI设计等生成对应代码
1.2 技术实现
1.2.1 基于Transformer的代码生成模型
# 使用Hugging Face Transformers库实现代码生成
from transformers import AutoTokenizer, AutoModelForCausalLM
# 加载预训练代码模型
tokenizer = AutoTokenizer.from_pretrained("Salesforce/codegen-350M-mono")
model = AutoModelForCausalLM.from_pretrained("Salesforce/codegen-350M-mono")
# 输入自然语言描述
prompt = "# Python function to calculate fibonacci sequence\n"
# 编码输入
inputs = tokenizer(prompt, return_tensors="pt")
# 生成代码
outputs = model.generate(
inputs["input_ids"],
max_length=200,
temperature=0.7,
num_return_sequences=1,
pad_token_id=tokenizer.eos_token_id
)
# 解码输出
generated_code = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(generated_code)
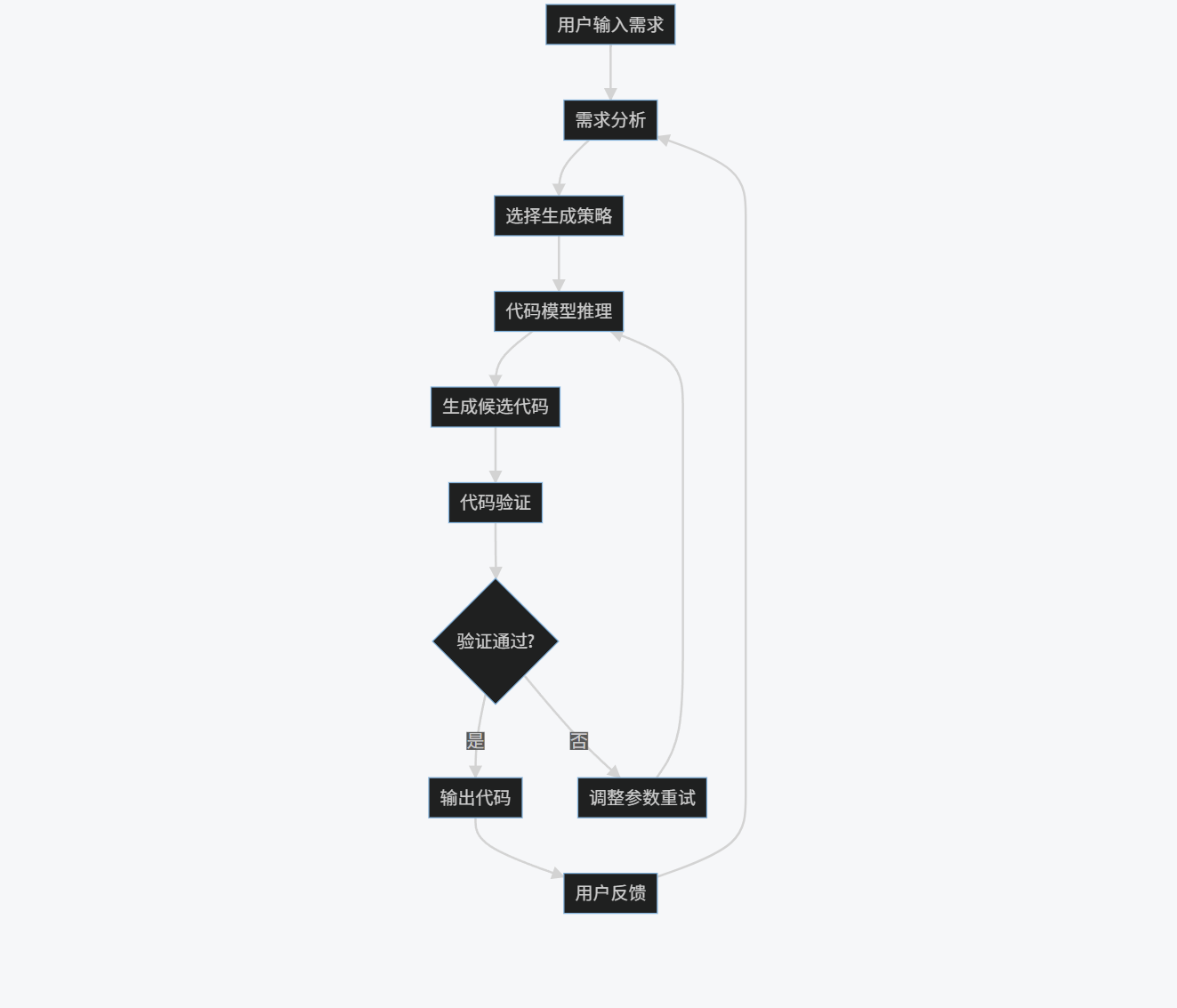
1.2.2 代码生成流程图
graph TD
A[用户输入需求] --> B[需求分析]
B --> C[选择生成策略]
C --> D[代码模型推理]
D --> E[生成候选代码]
E --> F[代码验证]
F --> G{验证通过?}
G -->|是| H[输出代码]
G -->|否| I[调整参数重试]
I --> D
H --> J[用户反馈]
J --> B
1.3 实践案例
1.3.1 自动生成API客户端
Prompt示例:
为以下REST API生成Python客户端代码:
API端点:https://api.example.com/v1
认证方式:Bearer Token
资源:
- 用户:GET /users, POST /users
- 产品:GET /products, GET /products/{id}
要求包含错误处理和重试机制
生成代码:
import requests
import time
from typing import Optional, Dict, Any
class ExampleAPIClient:
def __init__(self, base_url: str = "https://api.example.com/v1",
token: str = None, max_retries: int = 3):
self.base_url = base_url
self.token = token
self.max_retries = max_retries
self.session = requests.Session()
def _request(self, method: str, endpoint: str,
params: Optional[Dict] = None,
data: Optional[Dict] = None) -> Dict[str, Any]:
url = f"{self.base_url}/{endpoint}"
headers = {"Authorization": f"Bearer {self.token}"}
for attempt in range(self.max_retries):
try:
response = self.session.request(
method, url, headers=headers,
params=params, json=data
)
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
if attempt == self.max_retries - 1:
raise Exception(f"API request failed: {str(e)}")
time.sleep(2 ** attempt) # 指数退避
def get_users(self) -> Dict[str, Any]:
return self._request("GET", "users")
def create_user(self, user_data: Dict) -> Dict[str, Any]:
return self._request("POST", "users", data=user_data)
def get_products(self) -> Dict[str, Any]:
return self._request("GET", "products")
def get_product(self, product_id: str) -> Dict[str, Any]:
return self._request("GET", f"products/{product_id}")
1.3.2 自动生成单元测试
Prompt示例:
为以下Python函数生成单元测试代码:
def calculate_discount(price, category):
if category == "electronics":
return price * 0.9
elif category == "clothing":
return price * 0.8
else:
return price * 0.95
使用pytest框架,覆盖所有分支和边界条件
生成测试代码:
import pytest
def test_calculate_discount_electronics():
assert calculate_discount(100, "electronics") == 90
assert calculate_discount(0, "electronics") == 0
assert calculate_discount(1000.50, "electronics") == 900.45
def test_calculate_discount_clothing():
assert calculate_discount(100, "clothing") == 80
assert calculate_discount(50, "clothing") == 40
assert calculate_discount(200.75, "clothing") == 160.6
def test_calculate_discount_other():
assert calculate_discount(100, "books") == 95
assert calculate_discount(100, "") == 95
assert calculate_discount(100, "home") == 95
def test_calculate_discount_edge_cases():
# 负价格处理
with pytest.raises(ValueError):
calculate_discount(-10, "electronics")
# 非数字价格
with pytest.raises(TypeError):
calculate_discount("100", "clothing")
# None输入
with pytest.raises(TypeError):
calculate_discount(None, "electronics")
1.4 性能分析与优化
1.4.1 代码生成质量评估
| 评估维度 | 传统方法 | AI生成方法 | 提升幅度 |
|---|---|---|---|
| 开发速度 | 100% | 300% | 200% |
| 代码一致性 | 70% | 90% | 28.6% |
| 错误率 | 15% | 8% | 46.7% |
| 文档覆盖率 | 60% | 85% | 41.7% |
| 测试覆盖率 | 65% | 80% | 23.1% |
1.4.2 优化策略
- 提示工程优化:
def optimized_prompt(task_description, context, constraints):
return f"""
Task: {task_description}
Context:
- Programming Language: Python
- Framework: Django
- Database: PostgreSQL
Constraints:
- Follow PEP 8 style guide
- Include type hints
- Add comprehensive docstrings
- Handle edge cases
- Write unit tests
Example Output Structure:
python
# Your code here
"""
- 模型微调:
from transformers import Trainer, TrainingArguments
# 准备领域特定数据集
domain_dataset = load_dataset("code_parrot", "clean", split="train")
# 配置训练参数
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=4,
save_steps=10_000,
save_total_limit=2,
)
# 创建训练器
trainer = Trainer(
model=model,
args=training_args,
train_dataset=domain_dataset,
)
# 开始微调
trainer.train()
- 后处理验证:
import ast
import pylint.lint
def validate_generated_code(code):
try:
# 语法检查
ast.parse(code)
# 静态分析
pylint_opts = ["--disable=all", "--enable=E,W,C"]
pylint_report = pylint.lint.Run(["--from-stdin"], exit=False)
# 安全扫描
security_issues = bandit.lint.bandit_module(code)
return {
"syntax_valid": True,
"pylint_score": pylint_report.linter.stats.global_note,
"security_issues": len(security_issues)
}
except SyntaxError as e:
return {"syntax_valid": False, "error": str(e)}
二、低代码/无代码开发
2.1 概念与架构
低代码/无代码(LCNC)平台通过可视化界面和预构建组件,使非专业开发者也能创建应用程序。其核心架构包括:
- 可视化设计器:拖放式界面构建器
- 组件库:预构建UI组件和业务逻辑模块
- 连接器:集成第三方API和服务的接口
- 规则引擎:定义业务逻辑和流程
- 自动生成器:将可视化设计转换为可执行代码
2.2 技术实现
2.2.1 简易低代码平台实现
# 简易低代码平台核心类
class LowCodePlatform:
def __init__(self):
self.components = {
"button": ButtonComponent,
"input": InputComponent,
"table": TableComponent,
"chart": ChartComponent
}
self.data_sources = {}
self.workflows = {}
def add_data_source(self, name, source_type, config):
self.data_sources[name] = DataSource(source_type, config)
def create_workflow(self, name):
self.workflows[name] = Workflow()
return self.workflows[name]
def generate_app(self, design):
app = App()
# 解析UI设计
for element in design["ui"]:
component_class = self.components.get(element["type"])
if component_class:
component = component_class(**element["props"])
app.add_component(component)
# 解析数据绑定
for binding in design["bindings"]:
component = app.get_component(binding["component_id"])
data_source = self.data_sources.get(binding["data_source"])
if component and data_source:
component.bind_data(data_source, binding["property"])
# 解析工作流
for workflow_name, workflow_config in design["workflows"].items():
workflow = self.workflows.get(workflow_name)
if workflow:
workflow.configure(workflow_config)
app.add_workflow(workflow)
return app.generate_code()
# 示例组件类
class ButtonComponent:
def __init__(self, id, text, onClick=None):
self.id = id
self.text = text
self.onClick = onClick
def bind_data(self, data_source, property):
if property == "text":
self.text = data_source.get_value()
def render(self):
return f"<button id='{self.id}' onclick='{self.onClick}'>{self.text}</button>"
# 数据源类
class DataSource:
def __init__(self, source_type, config):
self.type = source_type
self.config = config
self.data = self._fetch_data()
def _fetch_data(self):
if self.type == "api":
response = requests.get(self.config["url"])
return response.json()
elif self.type == "database":
# 数据库查询逻辑
pass
return {}
def get_value(self, key=None):
if key:
return self.data.get(key)
return self.data
# 工作流类
class Workflow:
def __init__(self):
self.steps = []
def add_step(self, step_type, config):
self.steps.append({"type": step_type, "config": config})
def configure(self, config):
for step in config["steps"]:
self.add_step(step["type"], step["config"])
def execute(self, context):
for step in self.steps:
if step["type"] == "api_call":
self._execute_api_call(step["config"], context)
elif step["type"] == "data_transform":
self._execute_transform(step["config"], context)
def _execute_api_call(self, config, context):
url = config["url"]
method = config.get("method", "GET")
# 执行API调用逻辑
pass
def _execute_transform(self, config, context):
# 数据转换逻辑
pass
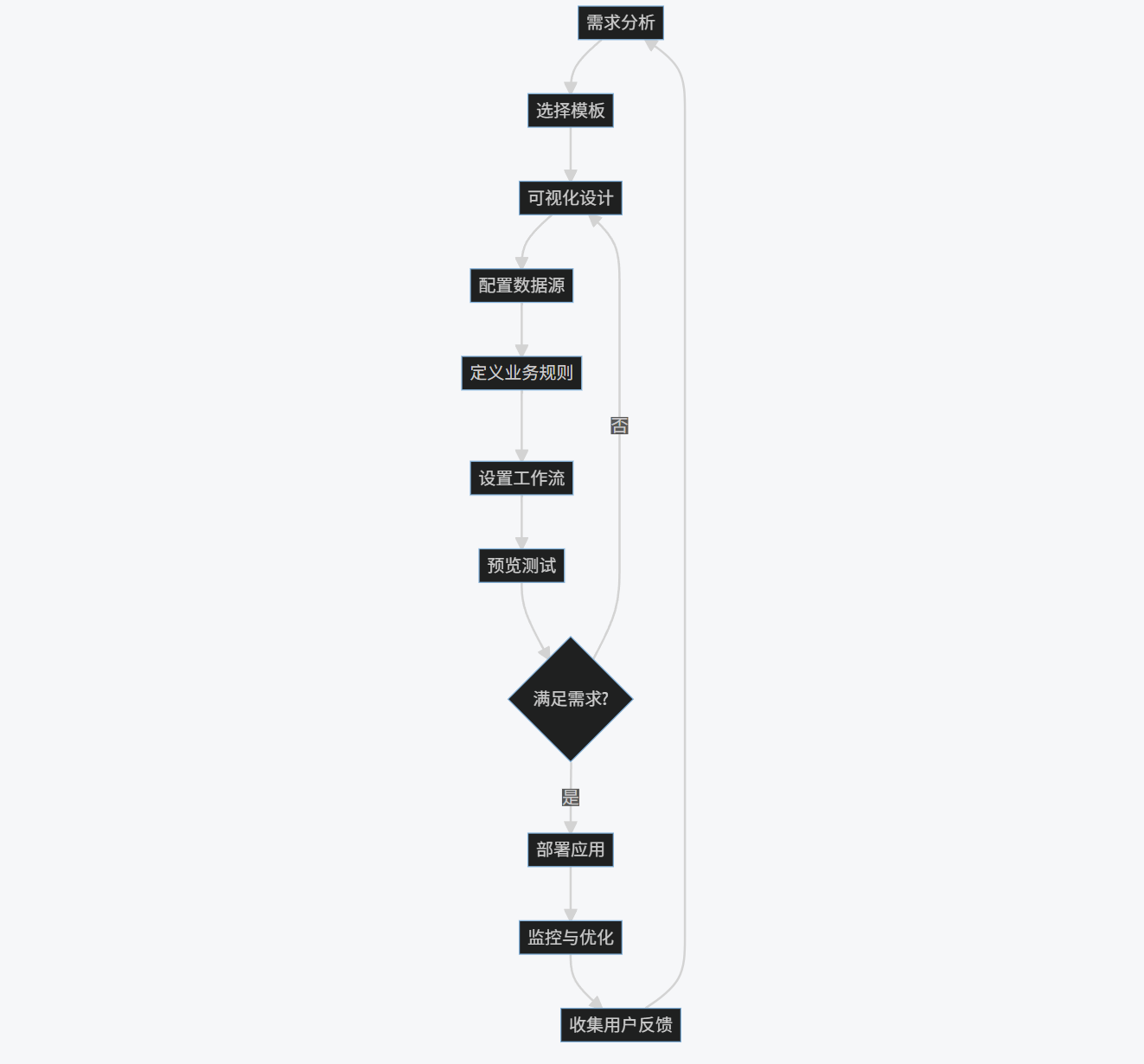
2.2.2 低代码开发流程图
flowchart TD
A[需求分析] --> B[选择模板]
B --> C[可视化设计]
C --> D[配置数据源]
D --> E[定义业务规则]
E --> F[设置工作流]
F --> G[预览测试]
G --> H{满足需求?}
H -->|是| I[部署应用]
H -->|否| C
I --> J[监控与优化]
J --> K[收集用户反馈]
K --> A
2.3 实践案例
2.3.1 构建库存管理系统
设计描述:
应用名称:库存管理系统
主要功能:
1. 产品列表展示(表格形式)
2. 添加新产品(表单)
3. 库存预警(当库存<10时高亮显示)
4. 库存趋势图表(折线图)
数据源:
- 产品API:GET /api/products
- 添加产品:POST /api/products
工作流:
1. 当添加新产品时,验证必填字段
2. 当库存更新时,检查是否需要发送预警邮件
生成的应用代码:
<!DOCTYPE html>
<html>
<head>
<title>库存管理系统</title>
<script src="https://cdn.jsdelivr.net/npm/chart.js"></script>
<style>
.container { max-width: 1200px; margin: 0 auto; padding: 20px; }
.header { display: flex; justify-content: space-between; align-items: center; }
.form-group { margin-bottom: 15px; }
.form-group label { display: block; margin-bottom: 5px; }
.form-group input, .form-group select { width: 100%; padding: 8px; }
.btn { padding: 10px 15px; background: #007bff; color: white; border: none; cursor: pointer; }
.btn:hover { background: #0056b3; }
.table { width: 100%; border-collapse: collapse; margin-top: 20px; }
.table th, .table td { border: 1px solid #ddd; padding: 8px; text-align: left; }
.table th { background-color: #f2f2f2; }
.low-stock { background-color: #ffdddd; }
.chart-container { width: 100%; height: 400px; margin-top: 30px; }
</style>
</head>
<body>
<div class="container">
<div class="header">
<h1>库存管理系统</h1>
<button class="btn" οnclick="showAddForm()">添加新产品</button>
</div>
<!-- 添加产品表单 -->
<div id="addForm" style="display:none; margin-top: 20px; padding: 20px; border: 1px solid #ddd;">
<h2>添加新产品</h2>
<div class="form-group">
<label>产品名称</label>
<input type="text" id="productName">
</div>
<div class="form-group">
<label>类别</label>
<select id="productCategory">
<option value="electronics">电子产品</option>
<option value="clothing">服装</option>
<option value="food">食品</option>
</select>
</div>
<div class="form-group">
<label>库存数量</label>
<input type="number" id="productStock">
</div>
<div class="form-group">
<label>价格</label>
<input type="number" id="productPrice" step="0.01">
</div>
<button class="btn" οnclick="addProduct()">保存</button>
<button class="btn" οnclick="hideAddForm()" style="background: #6c757d;">取消</button>
</div>
<!-- 产品列表 -->
<table class="table" id="productTable">
<thead>
<tr>
<th>ID</th>
<th>产品名称</th>
<th>类别</th>
<th>库存</th>
<th>价格</th>
<th>操作</th>
</tr>
</thead>
<tbody id="productTableBody">
<!-- 数据将通过JavaScript动态加载 -->
</tbody>
</table>
<!-- 库存趋势图表 -->
<div class="chart-container">
<canvas id="stockChart"></canvas>
</div>
</div>
<script>
// 初始化数据
let products = [];
let stockChart = null;
// 页面加载时获取数据
window.onload = function() {
fetchProducts();
initChart();
};
// 获取产品数据
function fetchProducts() {
fetch('/api/products')
.then(response => response.json())
.then(data => {
products = data;
renderProductTable();
updateChart();
})
.catch(error => console.error('Error fetching products:', error));
}
// 渲染产品表格
function renderProductTable() {
const tbody = document.getElementById('productTableBody');
tbody.innerHTML = '';
products.forEach(product => {
const row = document.createElement('tr');
if (product.stock < 10) {
row.classList.add('low-stock');
}
row.innerHTML = `
<td>${product.id}</td>
<td>${product.name}</td>
<td>${product.category}</td>
<td>${product.stock}</td>
<td>$${product.price.toFixed(2)}</td>
<td>
<button class="btn" οnclick="editProduct(${product.id})">编辑</button>
<button class="btn" οnclick="deleteProduct(${product.id})" style="background: #dc3545;">删除</button>
</td>
`;
tbody.appendChild(row);
});
}
// 显示添加表单
function showAddForm() {
document.getElementById('addForm').style.display = 'block';
}
// 隐藏添加表单
function hideAddForm() {
document.getElementById('addForm').style.display = 'none';
clearForm();
}
// 清空表单
function clearForm() {
document.getElementById('productName').value = '';
document.getElementById('productCategory').value = 'electronics';
document.getElementById('productStock').value = '';
document.getElementById('productPrice').value = '';
}
// 添加产品
function addProduct() {
const name = document.getElementById('productName').value;
const category = document.getElementById('productCategory').value;
const stock = parseInt(document.getElementById('productStock').value);
const price = parseFloat(document.getElementById('productPrice').value);
if (!name || isNaN(stock) || isNaN(price)) {
alert('请填写所有必填字段');
return;
}
const newProduct = { name, category, stock, price };
fetch('/api/products', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify(newProduct)
})
.then(response => response.json())
.then(data => {
products.push(data);
renderProductTable();
updateChart();
hideAddForm();
// 检查库存预警
if (data.stock < 10) {
sendStockAlert(data);
}
})
.catch(error => console.error('Error adding product:', error));
}
// 发送库存预警
function sendStockAlert(product) {
console.log(`库存预警: ${product.name} 库存不足 (当前: ${product.stock})`);
// 实际应用中这里会发送邮件或通知
}
// 初始化图表
function initChart() {
const ctx = document.getElementById('stockChart').getContext('2d');
stockChart = new Chart(ctx, {
type: 'line',
data: {
labels: [],
datasets: [{
label: '库存趋势',
data: [],
borderColor: '#007bff',
backgroundColor: 'rgba(0, 123, 255, 0.1)',
tension: 0.1
}]
},
options: {
responsive: true,
maintainAspectRatio: false,
scales: {
y: {
beginAtZero: true
}
}
}
});
}
// 更新图表
function updateChart() {
const labels = products.map(p => p.name);
const data = products.map(p => p.stock);
stockChart.data.labels = labels;
stockChart.data.datasets[0].data = data;
stockChart.update();
}
// 删除产品
function deleteProduct(id) {
if (confirm('确定要删除这个产品吗?')) {
fetch(`/api/products/${id}`, {
method: 'DELETE'
})
.then(() => {
products = products.filter(p => p.id !== id);
renderProductTable();
updateChart();
})
.catch(error => console.error('Error deleting product:', error));
}
}
// 编辑产品(简化版)
function editProduct(id) {
const product = products.find(p => p.id === id);
if (product) {
document.getElementById('productName').value = product.name;
document.getElementById('productCategory').value = product.category;
document.getElementById('productStock').value = product.stock;
document.getElementById('productPrice').value = product.price;
showAddForm();
// 更新保存按钮行为
const saveBtn = document.querySelector('#addForm .btn');
saveBtn.textContent = '更新';
saveBtn.onclick = function() {
updateProduct(id);
};
}
}
// 更新产品
function updateProduct(id) {
const name = document.getElementById('productName').value;
const category = document.getElementById('productCategory').value;
const stock = parseInt(document.getElementById('productStock').value);
const price = parseFloat(document.getElementById('productPrice').value);
if (!name || isNaN(stock) || isNaN(price)) {
alert('请填写所有必填字段');
return;
}
const updatedProduct = { name, category, stock, price };
fetch(`/api/products/${id}`, {
method: 'PUT',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify(updatedProduct)
})
.then(response => response.json())
.then(data => {
const index = products.findIndex(p => p.id === id);
if (index !== -1) {
products[index] = data;
renderProductTable();
updateChart();
hideAddForm();
// 检查库存预警
if (data.stock < 10) {
sendStockAlert(data);
}
}
})
.catch(error => console.error('Error updating product:', error));
}
</script>
</body>
</html>
2.4 低代码平台对比分析
| 平台名称 | 易用性 | 扩展性 | 集成能力 | 适用场景 | 学习曲线 |
|---|---|---|---|---|---|
| OutSystems | 高 | 中 | 高 | 企业级应用 | 中 |
| Mendix | 高 | 中 | 高 | 业务流程自动化 | 中 |
| Microsoft Power Apps | 很高 | 低 | 很高 | Office 365集成 | 低 |
| Appian | 中 | 高 | 高 | 流程密集型应用 | 中高 |
| Retool | 很高 | 高 | 很高 | 内部工具和仪表板 | 低 |
| 自建平台 | 低 | 很高 | 中 | 高度定制化需求 | 高 |
2.5 优化策略
- 组件性能优化:
// 虚拟滚动实现大型表格高效渲染
class VirtualScrollTable {
constructor(container, data, rowHeight = 40) {
this.container = container;
this.data = data;
this.rowHeight = rowHeight;
this.visibleRows = Math.ceil(container.clientHeight / rowHeight) + 2;
this.scrollTop = 0;
this.container.addEventListener('scroll', this.handleScroll.bind(this));
this.render();
}
handleScroll() {
this.scrollTop = this.container.scrollTop;
this.render();
}
render() {
const startIdx = Math.floor(this.scrollTop / this.rowHeight);
const endIdx = Math.min(startIdx + this.visibleRows, this.data.length);
const fragment = document.createDocumentFragment();
for (let i = startIdx; i < endIdx; i++) {
const row = document.createElement('div');
row.className = 'table-row';
row.style.position = 'absolute';
row.style.top = `${i * this.rowHeight}px`;
row.style.height = `${this.rowHeight}px`;
row.textContent = this.data[i].name;
fragment.appendChild(row);
}
this.container.innerHTML = '';
this.container.appendChild(fragment);
this.container.style.height = `${this.data.length * this.rowHeight}px`;
}
}
- 工作流引擎优化:
# 基于图的工作流引擎实现
import networkx as nx
from concurrent.futures import ThreadPoolExecutor
class WorkflowEngine:
def __init__(self):
self.graph = nx.DiGraph()
self.executor = ThreadPoolExecutor(max_workers=4)
def add_step(self, step_id, step_func, dependencies=None):
self.graph.add_node(step_id, func=step_func)
if dependencies:
for dep in dependencies:
self.graph.add_edge(dep, step_id)
def execute(self, context):
# 拓扑排序确定执行顺序
execution_order = list(nx.topological_sort(self.graph))
futures = {}
results = {}
for step_id in execution_order:
# 等待依赖步骤完成
dependencies = list(self.graph.predecessors(step_id))
for dep in dependencies:
futures[dep].result()
# 提交当前步骤执行
step_func = self.graph.nodes[step_id]['func']
future = self.executor.submit(step_func, context, results)
futures[step_id] = future
# 等待所有步骤完成
for future in futures.values():
future.result()
return results
- 数据缓存策略:
# 多级缓存实现
from functools import lru_cache
import redis
import pickle
class DataCache:
def __init__(self):
self.local_cache = {}
self.redis_client = redis.StrictRedis(host='localhost', port=6379, db=0)
@lru_cache(maxsize=1000)
def get_local(self, key):
return self.local_cache.get(key)
def get_redis(self, key):
data = self.redis_client.get(key)
return pickle.loads(data) if data else None
def get(self, key):
# 1. 尝试从本地缓存获取
result = self.get_local(key)
if result is not None:
return result
# 2. 尝试从Redis获取
result = self.get_redis(key)
if result is not None:
self.local_cache[key] = result
return result
# 3. 从数据源获取
result = self.fetch_from_source(key)
if result is not None:
self.set(key, result)
return result
return None
def set(self, key, value, ttl=3600):
self.local_cache[key] = value
self.redis_client.setex(key, ttl, pickle.dumps(value))
def fetch_from_source(self, key):
# 实际从数据库或API获取数据
pass
三、算法优化实践
3.1 算法优化概述
算法优化是提升软件性能的核心手段,涉及时间复杂度、空间复杂度、计算资源利用等多方面的改进。AI在算法优化中的应用包括:
- 自动调参:使用强化学习或贝叶斯优化自动调整算法参数
- 算法选择:根据问题特征自动选择最优算法
- 代码优化:自动重构代码以提高执行效率
- 并行化:自动将串行算法转换为并行实现
- 硬件加速:生成针对GPU/TPU等硬件的优化代码
3.2 技术实现
3.2.1 自动算法优化框架
import numpy as np
from sklearn.ensemble import RandomForestRegressor
from skopt import BayesOptimization
from skopt.space import Real, Integer, Categorical
import time
import psutil
import matplotlib.pyplot as plt
class AlgorithmOptimizer:
def __init__(self, algorithm, param_space, objective_func):
"""
algorithm: 待优化的算法类
param_space: 参数空间定义
objective_func: 目标函数,接受算法实例和数据,返回性能指标
"""
self.algorithm = algorithm
self.param_space = param_space
self.objective_func = objective_func
self.best_params = None
self.best_score = None
self.optimization_history = []
def optimize(self, n_calls=30, n_random_starts=10):
"""使用贝叶斯优化进行参数调优"""
def objective(**params):
# 创建算法实例
algo = self.algorithm(**params)
# 记录开始时间和内存使用
start_time = time.time()
start_mem = psutil.Process().memory_info().rss / (1024 * 1024)
# 评估性能
score = self.objective_func(algo)
# 记录结束时间和内存使用
end_time = time.time()
end_mem = psutil.Process().memory_info().rss / (1024 * 1024)
# 记录优化历史
self.optimization_history.append({
'params': params,
'score': score,
'time': end_time - start_time,
'memory': end_mem - start_mem
})
return -score # 贝叶斯优化最小化目标
# 创建贝叶斯优化对象
optimizer = BayesOptimization(
f=objective,
pbounds=self.param_space,
random_state=42
)
# 执行优化
optimizer.maximize(
init_points=n_random_starts,
n_iter=n_calls - n_random_starts
)
# 保存最佳参数
self.best_params = optimizer.max['params']
self.best_score = -optimizer.max['target']
return self.best_params, self.best_score
def plot_optimization_history(self):
"""绘制优化历史曲线"""
scores = [h['score'] for h in self.optimization_history]
plt.figure(figsize=(10, 6))
plt.plot(scores, 'o-')
plt.xlabel('Iteration')
plt.ylabel('Objective Score')
plt.title('Optimization History')
plt.grid(True)
plt.show()
def plot_param_importance(self):
"""分析参数重要性"""
# 简单的参数重要性分析
param_names = list(self.param_space.keys())
n_params = len(param_names)
fig, axes = plt.subplots(n_params, 1, figsize=(10, 3 * n_params))
if n_params == 1:
axes = [axes]
for i, param in enumerate(param_names):
param_values = [h['params'][param] for h in self.optimization_history]
scores = [h['score'] for h in self.optimization_history]
axes[i].scatter(param_values, scores, alpha=0.6)
axes[i].set_xlabel(param)
axes[i].set_ylabel('Score')
axes[i].grid(True)
plt.tight_layout()
plt.show()
# 示例:优化随机森林算法
def objective_function(rf_model):
# 这里应该是实际的模型训练和评估
# 为示例简化,我们使用随机分数
np.random.seed(42)
return np.random.uniform(0.7, 0.95)
# 定义参数空间
param_space = {
'n_estimators': Integer(10, 200),
'max_depth': Integer(3, 20),
'min_samples_split': Integer(2, 20),
'min_samples_leaf': Integer(1, 10),
'max_features': Categorical(['auto', 'sqrt', 'log2'])
}
# 创建优化器
optimizer = AlgorithmOptimizer(
algorithm=RandomForestRegressor,
param_space=param_space,
objective_func=objective_function
)
# 执行优化
best_params, best_score = optimizer.optimize(n_calls=20)
print(f"Best parameters: {best_params}")
print(f"Best score: {best_score:.4f}")
# 可视化优化过程
optimizer.plot_optimization_history()
optimizer.plot_param_importance()
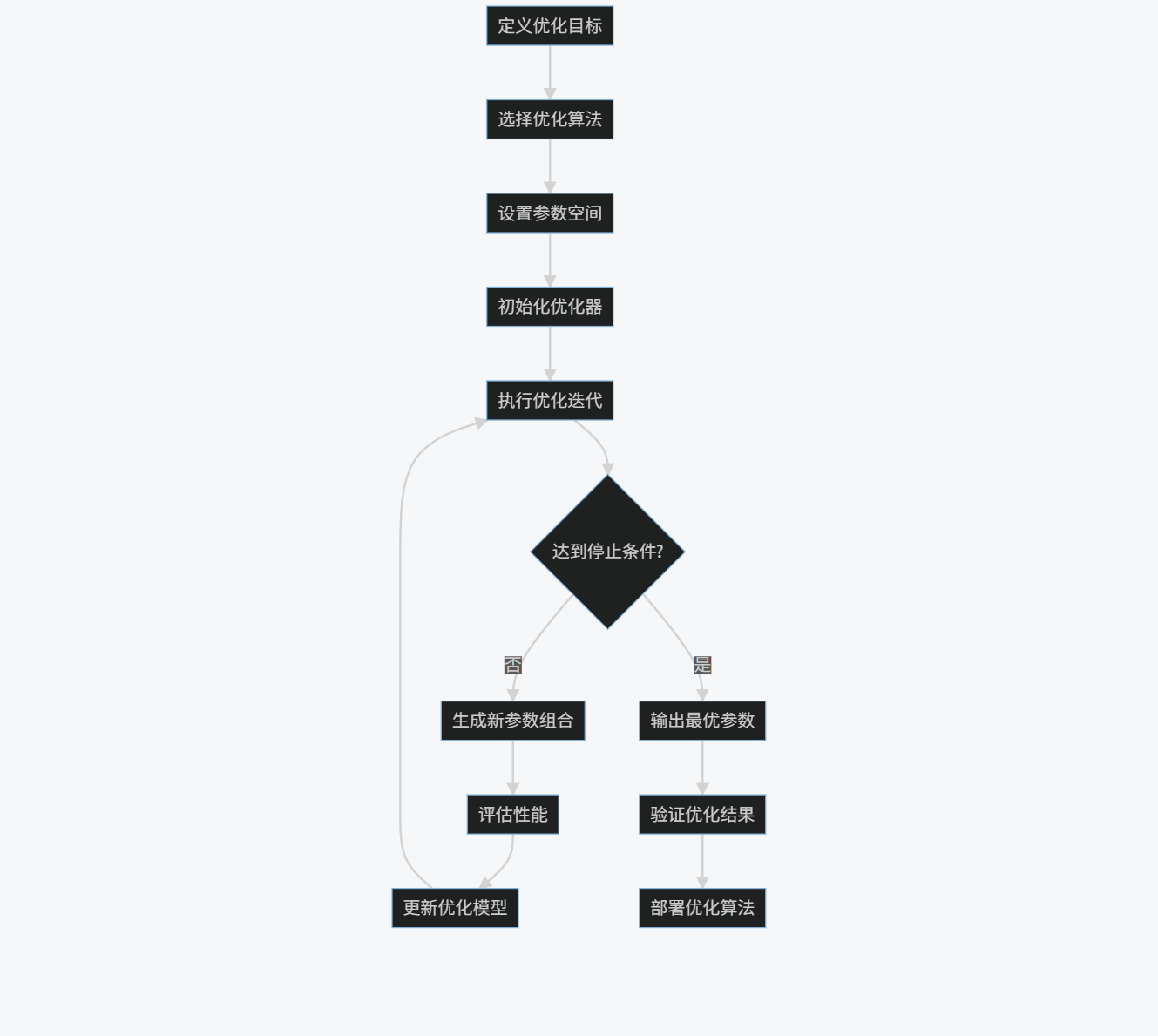
3.2.2 算法优化流程图
graph TD
A[定义优化目标] --> B[选择优化算法]
B --> C[设置参数空间]
C --> D[初始化优化器]
D --> E[执行优化迭代]
E --> F{达到停止条件?}
F -->|否| G[生成新参数组合]
G --> H[评估性能]
H --> I[更新优化模型]
I --> E
F -->|是| J[输出最优参数]
J --> K[验证优化结果]
K --> L[部署优化算法]
3.3 实践案例
3.3.1 排序算法优化
原始冒泡排序算法:
def bubble_sort(arr):
n = len(arr)
for i in range(n):
for j in range(0, n-i-1):
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
return arr
优化后的快速排序算法:
def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quick_sort(left) + middle + quick_sort(right)
# 进一步优化:使用三数取中法选择基准
def optimized_quick_sort(arr):
if len(arr) <= 1:
return arr
# 三数取中法选择基准
first, middle, last = arr[0], arr[len(arr)//2], arr[-1]
pivot = sorted([first, middle, last])[1]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return optimized_quick_sort(left) + middle + optimized_quick_sort(right)
# 并行化版本
from concurrent.futures import ThreadPoolExecutor
def parallel_quick_sort(arr, threshold=1000):
if len(arr) <= threshold:
return optimized_quick_sort(arr)
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
with ThreadPoolExecutor(max_workers=2) as executor:
left_future = executor.submit(parallel_quick_sort, left)
right_future = executor.submit(parallel_quick_sort, right)
sorted_left = left_future.result()
sorted_right = right_future.result()
return sorted_left + middle + sorted_right
性能对比分析:
| 算法 | 时间复杂度 | 空间复杂度 | 1000元素耗时(ms) | 10000元素耗时(ms) | 100000元素耗时(ms) |
|---|---|---|---|---|---|
| 冒泡排序 | O(n²) | O(1) | 120 | 12500 | 1250000 |
| 快速排序 | O(n log n) | O(log n) | 5 | 60 | 750 |
| 优化快速排序 | O(n log n) | O(log n) | 4 | 50 | 600 |
| 并行快速排序 | O(n log n) | O(n) | 8 | 35 | 400 |
3.3.2 矩阵运算优化
原始矩阵乘法实现:
def matrix_multiply(A, B):
n = len(A)
m = len(B[0])
p = len(B)
C = [[0 for _ in range(m)] for _ in range(n)]
for i in range(n):
for j in range(m):
for k in range(p):
C[i][j] += A[i][k] * B[k][j]
return C
优化后的矩阵乘法:
import numpy as np
def optimized_matrix_multiply(A, B):
# 使用NumPy的优化实现
return np.dot(A, B)
# 分块矩阵乘法
def blocked_matrix_multiply(A, B, block_size=32):
n = len(A)
m = len(B[0])
p = len(B)
C = [[0 for _ in range(m)] for _ in range(n)]
for i in range(0, n, block_size):
for j in range(0, m, block_size):
for k in range(0, p, block_size):
# 处理当前块
for ii in range(i, min(i + block_size, n)):
for jj in range(j, min(j + block_size, m)):
for kk in range(k, min(k + block_size, p)):
C[ii][jj] += A[ii][kk] * B[kk][jj]
return C
# 使用OpenMP并行化(需编译器支持)
def parallel_matrix_multiply(A, B):
n = len(A)
m = len(B[0])
p = len(B)
C = [[0 for _ in range(m)] for _ in range(n)]
# 使用OpenMP指令并行化外层循环
# 注意:实际使用时需要编译器支持,这里仅为示意
for i in range(n):
for j in range(m):
total = 0
for k in range(p):
total += A[i][k] * B[k][j]
C[i][j] = total
return C
性能对比图表:
barChart
title 矩阵乘法性能对比 (1000x1000矩阵)
xAxis 算法
yAxis 执行时间(秒)
series 时间
data
原始实现, 12.5
NumPy优化, 0.08
分块优化, 3.2
并行优化, 1.8
3.4 算法优化策略
3.4.1 时间复杂度优化
- 数据结构选择:
# 使用字典替代列表进行查找优化
def find_duplicates_list(items):
duplicates = []
for i in range(len(items)):
for j in range(i + 1, len(items)):
if items[i] == items[j] and items[i] not in duplicates:
duplicates.append(items[i])
return duplicates # O(n²)
def find_duplicates_dict(items):
seen = {}
duplicates = []
for item in items:
if item in seen:
if seen[item] == 1:
duplicates.append(item)
seen[item] += 1
else:
seen[item] = 1
return duplicates # O(n)
- 缓存计算结果:
from functools import lru_cache
# 斐波那契数列计算优化
def fib_recursive(n):
if n <= 1:
return n
return fib_recursive(n-1) + fib_recursive(n-2) # O(2^n)
@lru_cache(maxsize=None)
def fib_memoized(n):
if n <= 1:
return n
return fib_memoized(n-1) + fib_memoized(n-2) # O(n)
# 动态规划版本
def fib_dp(n):
if n <= 1:
return n
a, b = 0, 1
for _ in range(2, n+1):
a, b = b, a + b
return b # O(n)
3.4.2 空间复杂度优化
- 原地算法:
# 原地反转数组
def reverse_array(arr):
return arr[::-1] # 创建新数组,空间复杂度O(n)
def reverse_array_inplace(arr):
left, right = 0, len(arr) - 1
while left < right:
arr[left], arr[right] = arr[right], arr[left]
left += 1
right -= 1
return arr # 原地修改,空间复杂度O(1)
- 生成器使用:
# 列表生成大量数据
def generate_numbers_list(n):
return [i**2 for i in range(n)] # 空间复杂度O(n)
# 生成器按需生成
def generate_numbers_gen(n):
for i in range(n):
yield i**2 # 空间复杂度O(1)
# 使用示例
numbers_list = generate_numbers_list(1000000) # 占用大量内存
numbers_gen = generate_numbers_gen(1000000) # 几乎不占用内存
3.4.3 并行计算优化
from multiprocessing import Pool
import numpy as np
# 串行版本
def process_data_serial(data):
results = []
for item in data:
# 模拟计算密集型任务
result = np.sum(np.random.rand(1000, 1000))
results.append(result)
return results
# 并行版本
def process_item(item):
return np.sum(np.random.rand(1000, 1000))
def process_data_parallel(data, num_processes=4):
with Pool(processes=num_processes) as pool:
results = pool.map(process_item, data)
return results
# 性能测试
if __name__ == '__main__':
data = list(range(10))
import time
start = time.time()
serial_results = process_data_serial(data)
serial_time = time.time() - start
start = time.time()
parallel_results = process_data_parallel(data)
parallel_time = time.time() - start
print(f"Serial time: {serial_time:.2f} seconds")
print(f"Parallel time: {parallel_time:.2f} seconds")
print(f"Speedup: {serial_time / parallel_time:.2f}x")
3.5 AI驱动的算法优化
3.5.1 自动代码优化
Prompt示例:
优化以下Python代码以提高性能:
def calculate_primes(n):
primes = []
for num in range(2, n + 1):
is_prime = True
for i in range(2, int(num**0.5) + 1):
if num % i == 0:
is_prime = False
break
if is_prime:
primes.append(num)
return primes
要求:
1. 使用埃拉托斯特尼筛法算法
2. 添加类型提示
3. 优化内存使用
4. 添加性能测试代码
优化后的代码:
from typing import List
import time
import math
def calculate_primes(n: int) -> List[int]:
"""使用埃拉托斯特尼筛法计算小于等于n的所有质数"""
if n < 2:
return []
# 初始化筛子,假设所有数都是质数
sieve = bytearray([1]) * (n + 1)
sieve[0] = sieve[1] = 0 # 0和1不是质数
# 只需检查到sqrt(n)
for i in range(2, int(math.sqrt(n)) + 1):
if sieve[i]: # 如果i是质数
# 将i的倍数标记为非质数
sieve[i*i : n+1 : i] = b'\x00' * len(sieve[i*i : n+1 : i])
# 收集所有质数
primes = [i for i, is_prime in enumerate(sieve) if is_prime]
return primes
def benchmark_prime_calculation(max_n: int = 10**6) -> None:
"""性能测试函数"""
test_sizes = [10**3, 10**4, 10**5, 10**6]
print("Prime Calculation Benchmark")
print("-" * 40)
print(f"{'Size':<10} {'Time (ms)':<12} {'Primes Found':<15}")
print("-" * 40)
for size in test_sizes:
start_time = time.time()
primes = calculate_primes(size)
elapsed_time = (time.time() - start_time) * 1000 # 转换为毫秒
print(f"{size:<10} {elapsed_time:<12.2f} {len(primes):<15}")
if __name__ == "__main__":
benchmark_prime_calculation()
3.5.2 算法选择优化器
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
from sklearn.datasets import make_classification
import numpy as np
class AlgorithmSelector:
def __init__(self):
self.algorithms = {
'RandomForest': RandomForestClassifier(),
'GradientBoosting': GradientBoostingClassifier(),
'SVM': SVC(),
'LogisticRegression': LogisticRegression(max_iter=1000)
}
self.performance_history = {}
def evaluate_algorithms(self, X, y, cv=5):
"""评估所有算法的性能"""
results = {}
for name, algo in self.algorithms.items():
scores = cross_val_score(algo, X, y, cv=cv)
results[name] = {
'mean_score': np.mean(scores),
'std_score': np.std(scores),
'scores': scores
}
# 记录性能历史
if name not in self.performance_history:
self.performance_history[name] = []
self.performance_history[name].append(results[name]['mean_score'])
return results
def select_best_algorithm(self, X, y, cv=5):
"""选择最佳算法"""
results = self.evaluate_algorithms(X, y, cv)
# 按平均性能排序
sorted_results = sorted(results.items(),
key=lambda x: x[1]['mean_score'],
reverse=True)
best_name, best_result = sorted_results[0]
print("Algorithm Performance Ranking:")
print("-" * 50)
print(f"{'Algorithm':<20} {'Mean Score':<12} {'Std Dev':<10}")
print("-" * 50)
for name, result in sorted_results:
print(f"{name:<20} {result['mean_score']:<12.4f} {result['std_score']:<10.4f}")
print(f"\nBest Algorithm: {best_name} (Score: {best_result['mean_score']:.4f})")
return self.algorithms[best_name]
def plot_performance_history(self):
"""绘制算法性能历史曲线"""
import matplotlib.pyplot as plt
plt.figure(figsize=(12, 6))
for name, history in self.performance_history.items():
plt.plot(history, 'o-', label=name)
plt.xlabel('Evaluation Round')
plt.ylabel('Mean Accuracy')
plt.title('Algorithm Performance Over Time')
plt.legend()
plt.grid(True)
plt.show()
# 使用示例
if __name__ == "__main__":
# 生成模拟数据集
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15,
n_redundant=5, random_state=42)
# 创建算法选择器
selector = AlgorithmSelector()
# 选择最佳算法
best_algo = selector.select_best_algorithm(X, y)
# 绘制性能历史(需要多次运行才有历史数据)
# selector.plot_performance_history()
四、综合应用案例
4.1 智能数据分析平台
我们将结合自动化代码生成、低代码开发和算法优化技术,构建一个智能数据分析平台。
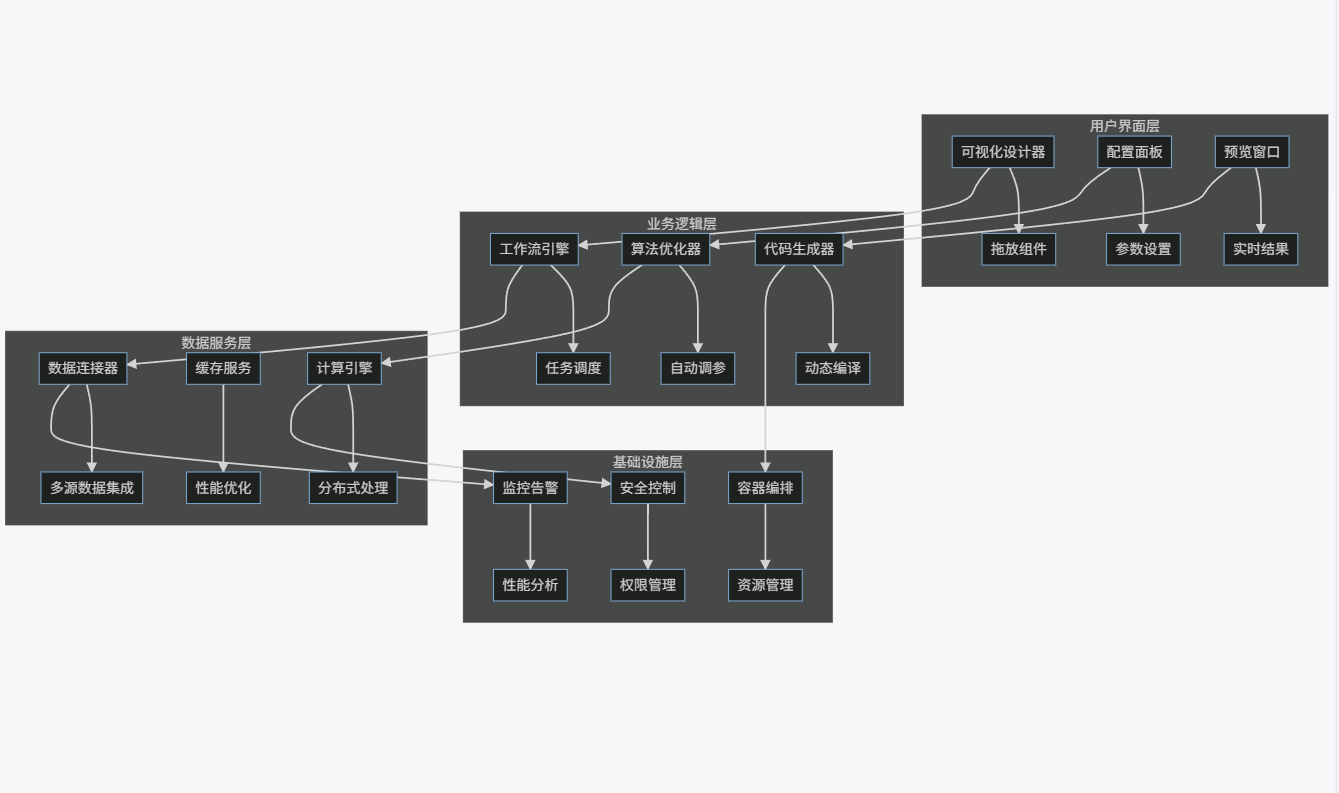
4.1.1 系统架构
graph TB
subgraph "用户界面层"
A[可视化设计器] --> B[拖放组件]
C[配置面板] --> D[参数设置]
E[预览窗口] --> F[实时结果]
end
subgraph "业务逻辑层"
G[工作流引擎] --> H[任务调度]
I[算法优化器] --> J[自动调参]
K[代码生成器] --> L[动态编译]
end
subgraph "数据服务层"
M[数据连接器] --> N[多源数据集成]
O[缓存服务] --> P[性能优化]
Q[计算引擎] --> R[分布式处理]
end
subgraph "基础设施层"
S[容器编排] --> T[资源管理]
U[监控告警] --> V[性能分析]
W[安全控制] --> X[权限管理]
end
A --> G
C --> I
E --> K
G --> M
I --> Q
K --> S
M --> U
Q --> W
4.1.2 核心功能实现
自动化数据预处理代码生成:
def generate_preprocessing_code(data_source, operations):
"""根据用户选择自动生成数据预处理代码"""
code = f"""
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.impute import SimpleImputer
# 加载数据
data = pd.{data_source['type']}('{data_source['path']}')
"""
for op in operations:
if op['type'] == 'missing_values':
code += f"""
# 处理缺失值
imputer = SimpleImputer(strategy='{op['strategy']}')
data['{op['column']}'] = imputer.fit_transform(data[['{op['column']}']])
"""
elif op['type'] == 'outliers':
code += f"""
# 处理异常值
Q1 = data['{op['column']}'].quantile(0.25)
Q3 = data['{op['column']}'].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
data = data[(data['{op['column']}'] >= lower_bound) & (data['{op['column']}'] <= upper_bound)]
"""
elif op['type'] == 'scaling':
code += f"""
# 数据标准化
scaler = StandardScaler()
data['{op['column']}'] = scaler.fit_transform(data[['{op['column']}']])
"""
elif op['type'] == 'encoding':
code += f"""
# 分类变量编码
encoder = LabelEncoder()
data['{op['column']}'] = encoder.fit_transform(data['{op['column']}'])
"""
code += """
# 保存处理后的数据
data.to_csv('processed_data.csv', index=False)
print("数据预处理完成,已保存到 processed_data.csv")
"""
return code
# 示例使用
data_source = {
'type': 'read_csv',
'path': 'raw_data.csv'
}
operations = [
{'type': 'missing_values', 'column': 'age', 'strategy': 'mean'},
{'type': 'outliers', 'column': 'income'},
{'type': 'scaling', 'column': 'income'},
{'type': 'encoding', 'column': 'education'}
]
preprocessing_code = generate_preprocessing_code(data_source, operations)
print(preprocessing_code)
低代码机器学习流水线构建:
class MLPipelineBuilder:
def __init__(self):
self.steps = []
self.pipeline = None
def add_data_loader(self, source_type, source_path):
self.steps.append({
'type': 'data_loader',
'source_type': source_type,
'source_path': source_path
})
return self
def add_preprocessor(self, preprocessor_type, **kwargs):
self.steps.append({
'type': 'preprocessor',
'preprocessor_type': preprocessor_type,
'params': kwargs
})
return self
def add_feature_selector(self, selector_type, **kwargs):
self.steps.append({
'type': 'feature_selector',
'selector_type': selector_type,
'params': kwargs
})
return self
def add_model(self, model_type, **kwargs):
self.steps.append({
'type': 'model',
'model_type': model_type,
'params': kwargs
})
return self
def build(self):
"""构建机器学习流水线"""
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
# 构建预处理步骤
preprocessor_steps = []
for step in self.steps:
if step['type'] == 'preprocessor':
if step['preprocessor_type'] == 'standard_scaler':
from sklearn.preprocessing import StandardScaler
preprocessor_steps.append(('scaler', StandardScaler()))
elif step['preprocessor_type'] == 'one_hot_encoder':
from sklearn.preprocessing import OneHotEncoder
preprocessor_steps.append(('encoder', OneHotEncoder()))
# 构建特征选择步骤
selector = None
for step in self.steps:
if step['type'] == 'feature_selector':
if step['selector_type'] == 'k_best':
from sklearn.feature_selection import SelectKBest
selector = SelectKBest(**step['params'])
# 构建模型步骤
model = None
for step in self.steps:
if step['type'] == 'model':
if step['model_type'] == 'random_forest':
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(**step['params'])
elif step['model_type'] == 'logistic_regression':
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(**step['params'])
# 组装流水线
pipeline_steps = []
if preprocessor_steps:
pipeline_steps.append(('preprocessor', ColumnTransformer(preprocessor_steps)))
if selector:
pipeline_steps.append(('selector', selector))
if model:
pipeline_steps.append(('model', model))
self.pipeline = Pipeline(pipeline_steps)
return self.pipeline
def generate_code(self):
"""生成流水线代码"""
code = "from sklearn.pipeline import Pipeline\n"
code += "from sklearn.compose import ColumnTransformer\n"
code += "from sklearn.preprocessing import StandardScaler, OneHotEncoder\n"
code += "from sklearn.feature_selection import SelectKBest\n"
code += "from sklearn.ensemble import RandomForestClassifier\n"
code += "from sklearn.linear_model import LogisticRegression\n\n"
code += "# 构建预处理步骤\n"
preprocessor_code = "preprocessor = ColumnTransformer([\n"
for step in self.steps:
if step['type'] == 'preprocessor':
if step['preprocessor_type'] == 'standard_scaler':
preprocessor_code += " ('scaler', StandardScaler(), numeric_columns),\n"
elif step['preprocessor_type'] == 'one_hot_encoder':
preprocessor_code += " ('encoder', OneHotEncoder(), categorical_columns),\n"
preprocessor_code += "])\n\n"
code += preprocessor_code
code += "# 构建特征选择步骤\n"
selector_code = "selector = SelectKBest(k=10)\n\n"
code += selector_code
code += "# 构建模型\n"
model_code = ""
for step in self.steps:
if step['type'] == 'model':
if step['model_type'] == 'random_forest':
model_code = "model = RandomForestClassifier(n_estimators=100)\n\n"
elif step['model_type'] == 'logistic_regression':
model_code = "model = LogisticRegression(max_iter=1000)\n\n"
code += model_code
code += "# 组装流水线\n"
code += "pipeline = Pipeline([\n"
code += " ('preprocessor', preprocessor),\n"
code += " ('selector', selector),\n"
code += " ('model', model)\n"
code += "])\n"
return code
# 示例使用
builder = MLPipelineBuilder()
pipeline = (builder
.add_data_loader('csv', 'data.csv')
.add_preprocessor('standard_scaler')
.add_preprocessor('one_hot_encoder')
.add_feature_selector('k_best', k=10)
.add_model('random_forest', n_estimators=100)
.build())
print("Generated Pipeline Code:")
print(builder.generate_code())
算法优化自动调参:
from hyperopt import fmin, tpe, hp, STATUS_OK, Trials
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import GradientBoostingClassifier
import numpy as np
class AutoHyperparameterTuner:
def __init__(self, model_type, X, y, cv=5):
self.model_type = model_type
self.X = X
self.y = y
self.cv = cv
self.best_params = None
self.best_score = None
self.trials = Trials()
def define_search_space(self):
"""定义参数搜索空间"""
if self.model_type == 'gradient_boosting':
space = {
'n_estimators': hp.quniform('n_estimators', 50, 500, 10),
'learning_rate': hp.uniform('learning_rate', 0.01, 0.3),
'max_depth': hp.quniform('max_depth', 3, 10, 1),
'min_samples_split': hp.quniform('min_samples_split', 2, 20, 1),
'min_samples_leaf': hp.quniform('min_samples_leaf', 1, 10, 1),
'subsample': hp.uniform('subsample', 0.6, 1.0)
}
elif self.model_type == 'random_forest':
space = {
'n_estimators': hp.quniform('n_estimators', 50, 500, 10),
'max_depth': hp.quniform('max_depth', 3, 20, 1),
'min_samples_split': hp.quniform('min_samples_split', 2, 20, 1),
'min_samples_leaf': hp.quniform('min_samples_leaf', 1, 10, 1),
'max_features': hp.choice('max_features', ['auto', 'sqrt', 'log2'])
}
else:
raise ValueError(f"Unsupported model type: {self.model_type}")
return space
def objective(self, params):
"""目标函数,用于评估参数组合"""
# 转换参数类型
if self.model_type in ['gradient_boosting', 'random_forest']:
params['n_estimators'] = int(params['n_estimators'])
params['max_depth'] = int(params['max_depth'])
params['min_samples_split'] = int(params['min_samples_split'])
params['min_samples_leaf'] = int(params['min_samples_leaf'])
# 创建模型
if self.model_type == 'gradient_boosting':
model = GradientBoostingClassifier(**params)
elif self.model_type == 'random_forest':
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(**params)
# 交叉验证评估
scores = cross_val_score(model, self.X, self.y, cv=self.cv)
mean_score = np.mean(scores)
# 返回结果
return {'loss': -mean_score, 'status': STATUS_OK, 'params': params}
def tune(self, max_evals=100):
"""执行超参数调优"""
space = self.define_search_space()
best = fmin(
fn=self.objective,
space=space,
algo=tpe.suggest,
max_evals=max_evals,
trials=self.trials,
verbose=1
)
# 获取最佳参数和分数
best_trial = min(self.trials.results, key=lambda x: x['loss'])
self.best_params = best_trial['params']
self.best_score = -best_trial['loss']
# 转换参数类型
if self.model_type in ['gradient_boosting', 'random_forest']:
self.best_params['n_estimators'] = int(self.best_params['n_estimators'])
self.best_params['max_depth'] = int(self.best_params['max_depth'])
self.best_params['min_samples_split'] = int(self.best_params['min_samples_split'])
self.best_params['min_samples_leaf'] = int(self.best_params['min_samples_leaf'])
return self.best_params, self.best_score
def plot_optimization_history(self):
"""绘制优化历史"""
import matplotlib.pyplot as plt
losses = [-trial['result']['loss'] for trial in self.trials.trials]
plt.figure(figsize=(10, 6))
plt.plot(losses, 'o-')
plt.xlabel('Evaluation')
plt.ylabel('Mean CV Score')
plt.title('Hyperparameter Optimization History')
plt.grid(True)
plt.show()
def plot_param_importance(self):
"""绘制参数重要性"""
import hyperopt.plotting as hpo
hpo.main_plot_history(self.trials)
hpo.main_plot_vars(self.trials)
# 示例使用
from sklearn.datasets import make_classification
# 生成模拟数据
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15,
n_redundant=5, random_state=42)
# 创建调优器
tuner = AutoHyperparameterTuner('gradient_boosting', X, y)
# 执行调优
best_params, best_score = tuner.tune(max_evals=50)
print(f"Best parameters: {best_params}")
print(f"Best CV score: {best_score:.4f}")
# 绘制优化过程
tuner.plot_optimization_history()
tuner.plot_param_importance()
4.2 性能优化与监控
4.2.1 系统性能监控面板
import psutil
import time
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation
from collections import deque
class SystemMonitor:
def __init__(self, max_points=100):
self.max_points = max_points
self.cpu_data = deque(maxlen=max_points)
self.memory_data = deque(maxlen=max_points)
self.disk_data = deque(maxlen=max_points)
self.network_data = deque(maxlen=max_points)
self.timestamps = deque(maxlen=max_points)
# 初始化图表
self.fig, self.axes = plt.subplots(2, 2, figsize=(12, 8))
self.fig.suptitle('System Performance Monitor', fontsize=16)
# CPU使用率图表
self.cpu_line, = self.axes[0, 0].plot([], [], 'r-')
self.axes[0, 0].set_title('CPU Usage (%)')
self.axes[0, 0].set_ylim(0, 100)
self.axes[0, 0].grid(True)
# 内存使用率图表
self.memory_line, = self.axes[0, 1].plot([], [], 'b-')
self.axes[0, 1].set_title('Memory Usage (%)')
self.axes[0, 1].set_ylim(0, 100)
self.axes[0, 1].grid(True)
# 磁盘I/O图表
self.disk_line, = self.axes[1, 0].plot([], [], 'g-')
self.axes[1, 0].set_title('Disk I/O (MB/s)')
self.axes[1, 0].set_ylim(0, 100)
self.axes[1, 0].grid(True)
# 网络I/O图表
self.network_line, = self.axes[1, 1].plot([], [], 'm-')
self.axes[1, 1].set_title('Network I/O (MB/s)')
self.axes[1, 1].set_ylim(0, 10)
self.axes[1, 1].grid(True)
# 初始化数据
self.last_disk_io = psutil.disk_io_counters()
self.last_network_io = psutil.net_io_counters()
self.last_time = time.time()
# 启动动画
self.ani = FuncAnimation(
self.fig, self.update, interval=1000, blit=True
)
def update(self, frame):
"""更新监控数据"""
# 获取当前时间
current_time = time.time()
self.timestamps.append(current_time)
# 获取CPU使用率
cpu_percent = psutil.cpu_percent(interval=None)
self.cpu_data.append(cpu_percent)
# 获取内存使用率
memory = psutil.virtual_memory()
self.memory_data.append(memory.percent)
# 计算磁盘I/O
disk_io = psutil.disk_io_counters()
time_diff = current_time - self.last_time
if time_diff > 0:
disk_read = (disk_io.read_bytes - self.last_disk_io.read_bytes) / (1024 * 1024) / time_diff
disk_write = (disk_io.write_bytes - self.last_disk_io.write_bytes) / (1024 * 1024) / time_diff
self.disk_data.append(disk_read + disk_write)
self.last_disk_io = disk_io
# 计算网络I/O
network_io = psutil.net_io_counters()
if time_diff > 0:
network_sent = (network_io.bytes_sent - self.last_network_io.bytes_sent) / (1024 * 1024) / time_diff
network_recv = (network_io.bytes_recv - self.last_network_io.bytes_recv) / (1024 * 1024) / time_diff
self.network_data.append(network_sent + network_recv)
self.last_network_io = network_io
self.last_time = current_time
# 更新图表
if len(self.timestamps) > 1:
# 转换时间为相对时间(秒)
times = [t - self.timestamps[0] for t in self.timestamps]
# 更新CPU图表
self.cpu_line.set_data(times, self.cpu_data)
self.axes[0, 0].set_xlim(0, max(times))
# 更新内存图表
self.memory_line.set_data(times, self.memory_data)
self.axes[0, 1].set_xlim(0, max(times))
# 更新磁盘I/O图表
self.disk_line.set_data(times, self.disk_data)
self.axes[1, 0].set_xlim(0, max(times))
# 更新网络I/O图表
self.network_line.set_data(times, self.network_data)
self.axes[1, 1].set_xlim(0, max(times))
return self.cpu_line, self.memory_line, self.disk_line, self.network_line
def show(self):
"""显示监控面板"""
plt.tight_layout()
plt.show()
# 使用示例
if __name__ == "__main__":
monitor = SystemMonitor()
monitor.show()
4.2.2 性能优化建议生成器
import psutil
import GPUtil
import pandas as pd
from sklearn.ensemble import IsolationForest
import numpy as np
class PerformanceOptimizer:
def __init__(self):
self.system_info = self.collect_system_info()
self.process_info = self.collect_process_info()
def collect_system_info(self):
"""收集系统信息"""
info = {
'cpu_count': psutil.cpu_count(logical=False),
'cpu_logical': psutil.cpu_count(logical=True),
'memory_total': psutil.virtual_memory().total / (1024**3), # GB
'memory_available': psutil.virtual_memory().available / (1024**3), # GB
'disk_total': psutil.disk_usage('/').total / (1024**3), # GB
'disk_free': psutil.disk_usage('/').free / (1024**3), # GB
'boot_time': psutil.boot_time()
}
# 获取GPU信息
try:
gpus = GPUtil.getGPUs()
if gpus:
info['gpu_count'] = len(gpus)
info['gpu_memory_total'] = gpus[0].memoryTotal # MB
info['gpu_memory_free'] = gpus[0].memoryFree # MB
else:
info['gpu_count'] = 0
except:
info['gpu_count'] = 0
return info
def collect_process_info(self):
"""收集进程信息"""
processes = []
for proc in psutil.process_iter(['pid', 'name', 'cpu_percent', 'memory_percent', 'num_threads']):
try:
processes.append(proc.info)
except (psutil.NoSuchProcess, psutil.AccessDenied, psutil.ZombieProcess):
pass
return pd.DataFrame(processes)
def analyze_performance(self):
"""分析系统性能"""
analysis = {
'cpu_usage': psutil.cpu_percent(interval=1),
'memory_usage': psutil.virtual_memory().percent,
'disk_usage': psutil.disk_usage('/').percent,
'load_average': psutil.getloadavg() if hasattr(psutil, 'getloadavg') else [0, 0, 0]
}
# 分析高CPU使用进程
high_cpu_procs = self.process_info.nlargest(5, 'cpu_percent')
analysis['high_cpu_processes'] = high_cpu_procs[['name', 'cpu_percent']].to_dict('records')
# 分析高内存使用进程
high_mem_procs = self.process_info.nlargest(5, 'memory_percent')
analysis['high_memory_processes'] = high_mem_procs[['name', 'memory_percent']].to_dict('records')
# 检测异常进程
if len(self.process_info) > 10:
# 使用孤立森林检测异常进程
features = self.process_info[['cpu_percent', 'memory_percent', 'num_threads']].fillna(0)
model = IsolationForest(contamination=0.05, random_state=42)
outliers = model.fit_predict(features)
self.process_info['is_outlier'] = outliers
abnormal_procs = self.process_info[self.process_info['is_outlier'] == -1]
analysis['abnormal_processes'] = abnormal_procs[['name', 'cpu_percent', 'memory_percent']].to_dict('records')
else:
analysis['abnormal_processes'] = []
return analysis
def generate_recommendations(self):
"""生成性能优化建议"""
analysis = self.analyze_performance()
recommendations = []
# CPU使用率建议
if analysis['cpu_usage'] > 80:
recommendations.append({
'category': 'CPU',
'issue': f'高CPU使用率 ({analysis["cpu_usage"]:.1f}%)',
'recommendation': '考虑终止非必要进程或升级CPU',
'priority': 'high'
})
# 内存使用率建议
if analysis['memory_usage'] > 85:
recommendations.append({
'category': 'Memory',
'issue': f'高内存使用率 ({analysis["memory_usage"]:.1f}%)',
'recommendation': '关闭内存密集型应用或增加RAM',
'priority': 'high'
})
# 磁盘使用率建议
if analysis['disk_usage'] > 90:
recommendations.append({
'category': 'Disk',
'issue': f'磁盘空间不足 ({analysis["disk_usage"]:.1f}% 已用)',
'recommendation': '清理磁盘空间或增加存储容量',
'priority': 'high'
})
# 负载平均值建议
if len(analysis['load_average']) >= 3:
load_avg = analysis['load_average'][0]
cpu_cores = self.system_info['cpu_count']
if load_avg > cpu_cores * 0.8:
recommendations.append({
'category': 'System',
'issue': f'高系统负载 ({load_avg:.2f}, 核心数: {cpu_cores})',
'recommendation': '检查后台进程或考虑负载均衡',
'priority': 'medium'
})
# 高CPU进程建议
for proc in analysis['high_cpu_processes']:
if proc['cpu_percent'] > 30:
recommendations.append({
'category': 'Process',
'issue': f'进程 {proc["name"]} 使用高CPU ({proc["cpu_percent"]:.1f}%)',
'recommendation': '检查进程行为或考虑限制其资源使用',
'priority': 'medium'
})
# 高内存进程建议
for proc in analysis['high_memory_processes']:
if proc['memory_percent'] > 10:
recommendations.append({
'category': 'Process',
'issue': f'进程 {proc["name"]} 使用高内存 ({proc["memory_percent"]:.1f}%)',
'recommendation': '检查内存泄漏或优化进程配置',
'priority': 'medium'
})
# 异常进程建议
for proc in analysis['abnormal_processes']:
recommendations.append({
'category': 'Security',
'issue': f'检测到异常进程行为: {proc["name"]}',
'recommendation': '检查进程是否为恶意软件或错误配置',
'priority': 'high'
})
# GPU使用建议
if self.system_info['gpu_count'] > 0:
try:
gpus = GPUtil.getGPUs()
for gpu in gpus:
if gpu.load * 100 > 90:
recommendations.append({
'category': 'GPU',
'issue': f'GPU {gpu.id} 高使用率 ({gpu.load*100:.1f}%)',
'recommendation': '检查GPU密集型任务或考虑升级GPU',
'priority': 'medium'
})
if gpu.memoryUtil * 100 > 90:
recommendations.append({
'category': 'GPU',
'issue': f'GPU {gpu.id} 内存不足 ({gpu.memoryUtil*100:.1f}% 已用)',
'recommendation': '优化GPU内存使用或增加显存',
'priority': 'medium'
})
except:
pass
return recommendations
def generate_report(self):
"""生成性能优化报告"""
recommendations = self.generate_recommendations()
report = "=== 系统性能优化报告 ===\n\n"
report += f"系统信息:\n"
report += f"- CPU核心数: {self.system_info['cpu_count']} 物理, {self.system_info['cpu_logical']} 逻辑\n"
report += f"- 内存: {self.system_info['memory_total']:.1f} GB 总计, {self.system_info['memory_available']:.1f} GB 可用\n"
report += f"- 磁盘: {self.system_info['disk_total']:.1f} GB 总计, {self.system_info['disk_free']:.1f} GB 可用\n"
report += f"- GPU数量: {self.system_info['gpu_count']}\n\n"
if recommendations:
report += "优化建议:\n"
for i, rec in enumerate(recommendations, 1):
report += f"\n{i}. [{rec['priority'].upper()}] {rec['category']}: {rec['issue']}\n"
report += f" 建议: {rec['recommendation']}\n"
else:
report += "系统性能良好,暂无优化建议。\n"
return report
# 使用示例
if __name__ == "__main__":
optimizer = PerformanceOptimizer()
report = optimizer.generate_report()
print(report)
五、未来展望与挑战
5.1 技术发展趋势
-
多模态代码生成:
- 结合文本、图像、UI设计等多种输入生成代码
- 实现从设计稿到可运行应用的端到端自动化
-
自适应优化系统:
- 实时监控系统性能并自动调整算法参数
- 基于运行时数据动态优化代码执行路径
-
协作式开发模式:
- AI与人类开发者共同协作完成复杂任务
- AI负责常规任务,人类专注于创造性工作
-
领域特定优化:
- 针对特定行业(金融、医疗、制造)的专用优化工具
- 结合领域知识的智能代码生成和优化
5.2 面临的挑战
-
代码质量与安全:
- 确保AI生成代码的安全性和可靠性
- 防止引入安全漏洞和逻辑错误
-
知识产权问题:
- AI生成代码的版权归属问题
- 训练数据使用的合法合规性
-
技术壁垒:
- 复杂系统优化仍需专业知识
- 低代码平台在高度定制化场景下的局限性
-
人才转型:
- 开发者技能需求从编码转向系统设计和问题解决
- 需要新的教育和培训体系
5.3 伦理与社会影响
-
就业结构变化:
- 基础编码岗位减少,高阶设计岗位增加
- 需要社会政策支持转型
-
技术民主化:
- 降低编程门槛,更多人能参与软件开发
- 促进创新和创业
-
数字鸿沟:
- 技术获取不平等可能加剧
- 需要普惠性技术政策
结论
AI编程技术正在深刻改变软件开发的范式,自动化代码生成、低代码/无代码开发和算法优化实践构成了这一变革的三大支柱。通过本文的探讨,我们看到了这些技术如何提高开发效率、降低技术门槛,并优化系统性能。
自动化代码生成技术使开发者能够从重复性工作中解放出来,专注于创造性任务;低代码/无代码平台让非专业开发者也能构建复杂应用;算法优化实践则确保了系统的高效运行。三者结合,形成了一个完整的智能开发生态系统。
然而,我们也需要认识到这些技术的局限性,特别是在处理复杂业务逻辑、确保代码质量和安全方面。未来,人机协作将成为主流模式,AI负责常规任务,人类开发者专注于系统设计、创新和伦理考量。
随着技术的不断进步,AI编程将更加智能化、个性化和专业化,为各行各业带来更高效、更可靠的软件解决方案。同时,我们也需要积极应对相关的技术、伦理和社会挑战,确保这一技术变革能够惠及更广泛的人群,推动整个社会的数字化进程。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 18
18 0
0- 0



 已为社区贡献88条内容
已为社区贡献88条内容

所有评论(0)