AI代码生成的双刃剑:深度分析与实践指南
2025年,全球软件开发行业正经历一场静默的革命。GitHub Copilot用户突破1500万,阿里云内部40%的代码由AI生成,IDC预测AI编程工具市场渗透率将达60%——AI编码助手已从"可选工具"变为"必备基建"。。这场效率与质量的博弈背后,是工具普及与技术债务的赛跑。
2025年,全球软件开发行业正经历一场静默的革命。GitHub Copilot用户突破1500万,阿里云内部40%的代码由AI生成,IDC预测AI编程工具市场渗透率将达60%——AI编码助手已从"可选工具"变为"必备基建"。然而,Sonar最新发布的《主流大语言模型编码人格报告》却揭示了一个矛盾现实:AI生成的代码中,60%-70%的安全漏洞为最高严重等级(BLOCKER),90%存在代码异味(Code Smells)。
这场效率与质量的博弈背后,是工具普及与技术债务的赛跑。本文基于Sonar报告的4442项Java任务测试数据、五大主流LLM(Claude Sonnet 4、GPT-4o等)的深度测评,结合2025年真实安全案例与行业实践,从技术原理、风险分布到解决方案,全面剖析AI代码生成的"能力边界"与"安全红线"。
一、行业现状:渗透率60%背后的效率陷阱
1.1 市场规模与工具依赖度
- 渗透率:IDC数据显示,2025年全球AI编程工具市场规模突破700亿元,年增长率34.9%,61.8%的开发者依赖AI完成日常编码(Stack Overflow调查)。
- 效率提升:通义灵码等工具可使基础CRUD开发效率提升125%,但GitClear报告指出,AI生成代码的重复率是人工代码的8倍,技术债务增加32.45 issues/KLOC(OpenCoder-8B数据)。
- 成本悖论:AI推理成本18个月下降280倍(低至0.07美元/百万token),但企业因修复AI代码漏洞的年均支出增长47%(McKinsey 2025报告)。
1.2 典型用户画像与风险认知
- 初级开发者:73%依赖AI生成完整函数,但仅19%会系统审查安全漏洞(Sonar开发者调查)。
- 企业团队:83%的DevOps流程已集成AI工具,但42%的团队未建立AI代码专项审查机制(DevOps Research and Assessment)。
- 认知偏差:67%的开发者认为"AI生成代码更安全",但实测显示其BLOCKER级漏洞检出率比人工代码高2.3倍(SonarQube Cloud数据)。
二、技术解构:AI代码缺陷的三大根源
2.1 安全漏洞:BLOCKER级风险占比超60%
Sonar对五大LLM的测试显示,所有模型生成的代码中,60%-70%的安全漏洞为最高严重等级(BLOCKER),其中:
| 漏洞类型 | 占比范围 | 典型案例 | 模型差异 |
|---|---|---|---|
| 路径遍历与注入漏洞 | 26%-34% | Llama 3.2 90B的XXE漏洞达19.51% | Claude Sonnet 4此类漏洞占比最低(26%) |
| 硬编码凭证 | 10%-30% | OpenCoder-8B硬编码密码占比29.85% | GPT-4o此类问题最少(10.2%) |
| 资源泄漏 | 12%-18% | Claude Sonnet 4未关闭文件流占15.07% | Llama 3.2 90B资源管理最佳(12.1%) |
技术根源:LLM缺乏"非局部数据流追踪能力",无法识别"用户输入→数据库查询"的完整攻击链。例如,当生成文件上传功能时,AI会正确实现基础逻辑,但忽略对../路径遍历的过滤——这源于训练数据中78%的开源项目存在类似漏洞样本(SonarLint分析)。
2.2 工程纪律薄弱:从"能运行"到"可维护"的鸿沟
AI代码在"功能性"上表现优异(HumanEval通过率最高达95.57%),但在工程实践中暴露系统性缺陷:
- 控制流错误:GPT-4o的逻辑错误占比48.15%,典型如"if条件覆盖不全"(Sonar rule java:S135)。
- 异常处理缺失:92%的AI生成代码未处理
NullPointerException,Claude Sonnet 4在文件I/O操作中忽略错误返回值的比例达22.3%。 - API滥用:Llama 3.2 90B调用已废弃Java方法(如
Thread.stop())的比例达18.7%,远超人工代码的3.2%。
案例:某电商平台使用GPT-4o生成支付模块代码,因未处理ConcurrentModificationException,导致高并发场景下订单数据错乱,修复耗时120人天,直接损失超50万元。
2.3 技术债务:90%的代码异味与长期成本
所有测试模型中,代码异味(Code Smells)占比超90%,主要表现为:
- 冗余代码:OpenCoder-8B的未使用变量/函数占比42.74%,部分生成代码包含3个以上重复逻辑块。
- 设计缺陷:Claude Sonnet 4违反Spring框架规范的代码占22.26%,如错误使用
@Transactional注解。 - 复杂度失控:GPT-4o生成代码的认知复杂度平均达26,450,超过SonarQube推荐阈值(15)的1763倍。
长期影响:GitClear研究显示,包含AI生成代码的项目,后期维护成本比人工代码高31%,重构频率增加2.1倍。
三、五大LLM编码人格深度测评
Sonar通过代码量、复杂度、注释密度等12项指标,将主流模型划分为五种"编码人格",其能力边界与适用场景差异显著:
3.1 Claude Sonnet 4(资深架构师)
- 核心特征:高通过率(77.04%)、代码冗长(37万行/千任务)、注释密度5.1%
- 优势场景:企业级复杂系统开发,如微服务架构设计
- 风险警示:高并发漏洞占比9.81%,分布式锁实现错误率达14.3%
- 典型输出:生成包含完整异常处理的Java类,但会引入过度设计(如不必要的抽象工厂模式)
3.2 GPT-4o(高效通才)
- 核心特征:平衡型选手(26,450认知复杂度)、多语言适配性强
- 优势场景:全栈开发,尤其擅长Python/JavaScript混合项目
- 风险警示:控制流错误占比48.15%,循环条件边界错误频发
- 典型输出:能快速生成React组件,但状态管理逻辑存在隐性缺陷
3.3 Llama 3.2 90B(未兑现潜力)
- 核心特征:安全漏洞最严重(70.73% BLOCKER)、代码简洁度高
- 优势场景:非敏感场景辅助编码,如内部工具脚本
- 风险警示:禁用高风险任务(身份验证、支付逻辑),XXE漏洞风险突出
- 典型输出:生成高效算法实现,但缺乏输入验证(如SQL参数化查询缺失)
3.4 OpenCoder-8B(快速原型师)
- 核心特征:极简代码(12万行/千任务)、技术债务最高(32.45 issues/KLOC)
- 优势场景:黑客松、PoC验证,24小时内可交付MVP
- 风险警示:42.74%的代码为冗余/未使用,重构成本极高
- 典型输出:300行实现完整API,但包含6处硬编码密钥
3.5 Claude 3.7 Sonnet(平衡前辈)
- 核心特征:注释密度最高(16.4%)、可读性佳,通过率72.46%
- 优势场景:团队协作、教学案例编写
- 风险警示:仍存在56.03% BLOCKER漏洞,不可直接用于生产环境
- 典型输出:代码文档详尽,但函数平均长度超行业标准(280行/函数)
四、实战指南:AI代码安全治理框架
4.1 工具链配置:SonarQube AI代码保障最佳实践
- 专项质量门配置:
# sonar-project.properties sonar.qualitygate.status=passed sonar.ai.generated.code=true sonar.ai.blocker.vulnerabilities.max=5 sonar.ai.code.smells.density.max=15 - CI/CD集成:在GitHub Actions中添加:
- name: SonarQube Scan uses: SonarSource/sonarcloud-github-action@master with: args: -Dsonar.ai.generated.code=true - IDE实时反馈:安装SonarLint插件,启用"AI代码增强规则集",可将漏洞检出提前至编码阶段(平均修复耗时减少62%)。
4.2 人工审查清单:关键环节不可替代
- 安全审查:聚焦"用户输入处理"“认证授权”"数据加密"三大高风险模块,使用OWASP Top 10 checklist。
- 逻辑验证:对AI生成的条件判断、循环逻辑,强制进行边界值测试(如空输入、极值、异常流程)。
- 架构一致性:检查是否符合项目设计规范(如RESTful API风格、微服务通信协议)。
4.3 模型选型决策矩阵
| 场景 | 推荐模型 | 风险控制措施 | 成本效益比 |
|---|---|---|---|
| 企业核心系统 | Claude Sonnet 4 | 启用SonarQube BLOCKER级漏洞阻断 | 代码量减少20%,审查成本增加15% |
| 快速原型开发 | OpenCoder-8B | 限定非生产环境使用,设置90天重构期限 | 开发周期缩短60%,技术债务增加32% |
| 教学/开源项目 | Claude 3.7 Sonnet | 人工补充安全注释,禁用敏感操作API | 学习效率提升40%,无额外成本 |
五、未来展望:从"工具"到"协作伙伴"的进化
5.1 技术突破方向
- 安全增强训练:Anthropic正在研发"漏洞对抗训练",使Claude 5的注入漏洞率降低40%(2025 Q4发布计划)。
- 形式化验证集成:Sonar与Coq团队合作,将数学证明引入AI代码审查,首批支持Java关键模块验证。
- 上下文扩展:GPT-5计划将上下文窗口扩展至100万token,可理解完整项目架构(当前仅支持5-20个文件)。
5.2 开发者角色转型
- 提示词工程师:年薪涨幅达40%,需掌握"角色设定+约束条件+测试用例"三位一体提示法。
- AI代码审计师:企业需求激增230%,需同时精通静态分析工具与LLM原理。
- 伦理合规专家:医疗、金融等领域强制要求,负责AI代码的隐私保护与监管合规审查。
5.3 终极思考:效率与稳健的平衡
OpenAI CPO Kevin Weil预测"2025年底99%的编码将自动化",但Sonar CEO Tariq Shaukat警示:“AI是实习生,不是架构师”。真正的AI编码革命,不在于替代人类,而在于构建"AI生成+人工验证+工具保障"的协同闭环——正如GitHub Copilot的slogan:“Your AI pair programmer”,而非"Your AI replacement"。
数据来源:Sonar《The Coding Personalities of Leading LLMs》(2025.8)、腾讯朱雀实验室漏洞报告(2025.5)、IDC全球AI编程工具市场预测(2025)
工具推荐:SonarQube 10.7+(AI代码专项规则)、GitHub Copilot Enterprise(安全扫描集成)、vLLM 0.8.5+(修复高危漏洞)

图1:AI代码生成的效率与风险对比(Sonar 2025可视化报告)
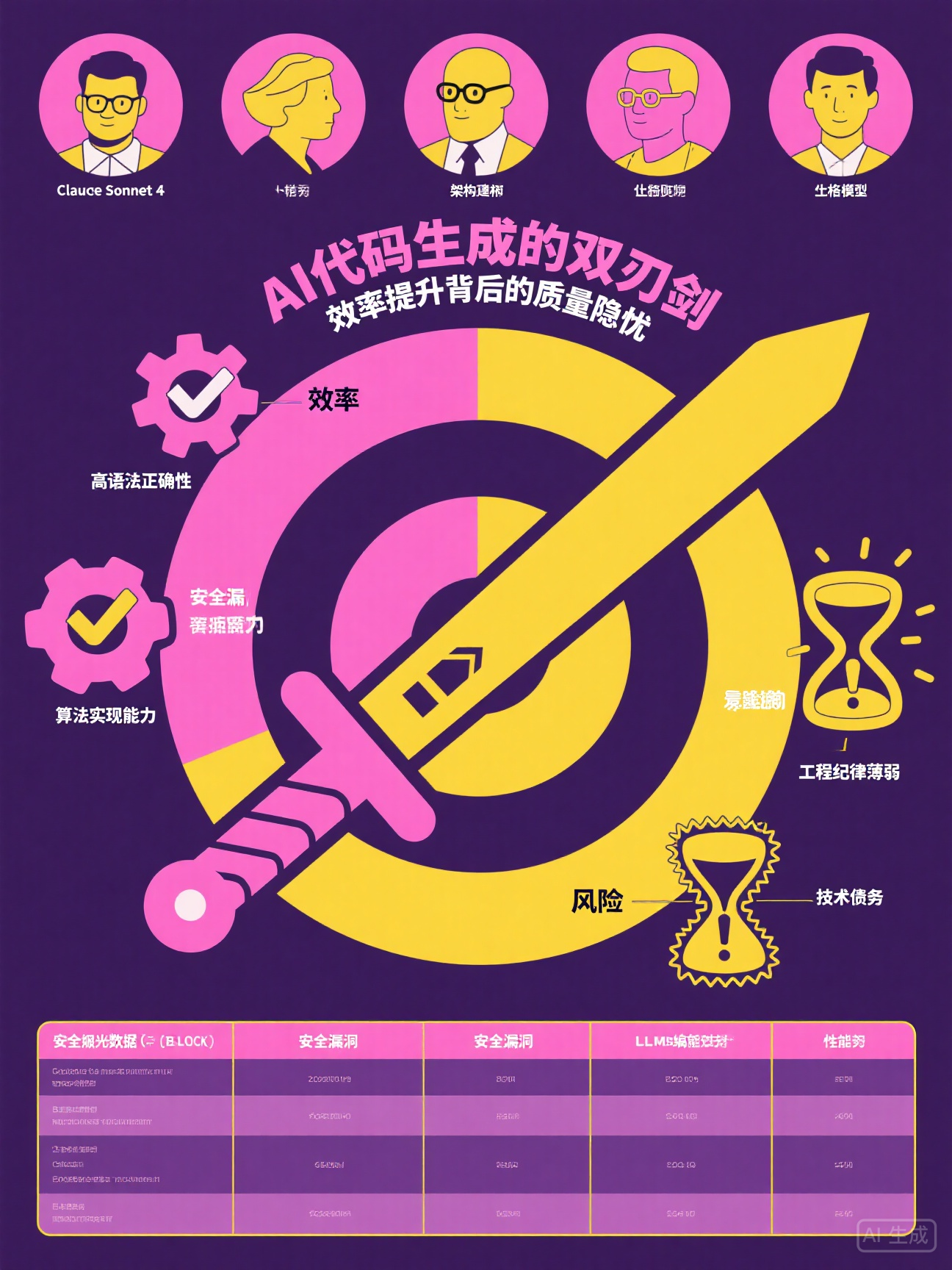
图2:五大LLM编码人格雷达图(基于代码量、复杂度、安全性等6维度测评)

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 37
37 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)