AI 工具深度解析:从智能编码到模型训练的全流程实践
本文系统介绍了AI开发核心工具链,包括智能编码工具、数据标注工具和模型训练平台。智能编码工具如GitHub Copilot通过大语言模型实现代码自动生成;数据标注工具Label Studio支持多类型数据标注与质量控制;模型训练平台PyTorch Lightning和Kubeflow简化了从实验到生产的全流程。文章详细分析了各类工具的技术原理、实践方法和对比优势,并展望了多模态融合、AutoML深
人工智能工具链正深刻改变着技术研发与产业落地的效率,从代码生成到模型部署的全流程都涌现出大量创新工具。本文将系统解析智能编码工具、数据标注工具、模型训练平台三类核心 AI 工具,结合代码示例、流程图、Prompt 设计与对比图表,全面呈现工具的技术原理与实践方法,为 AI 开发全流程提供参考。
一、智能编码工具:重构软件开发范式
智能编码工具通过大语言模型(LLM)对代码上下文的理解,实现自动补全、函数生成、错误修复等功能,显著提升开发效率。目前主流工具包括 GitHub Copilot、Tabnine、CodeLlama 等,其核心原理是基于海量代码库训练的 Transformer 模型,通过上下文预测生成合理的代码片段。
1.1 技术原理与工作流程
智能编码工具的核心是代码生成模型,其工作流程可分为四个阶段:
graph TD
A[用户输入上下文] --> B{语境解析}
B -->|代码片段/注释| C[序列预测模型]
C --> D[候选代码生成]
D --> E[过滤与排序]
E --> F[输出补全结果]
F --> G{用户反馈}
G -->|接受/修改| H[模型微调数据积累]
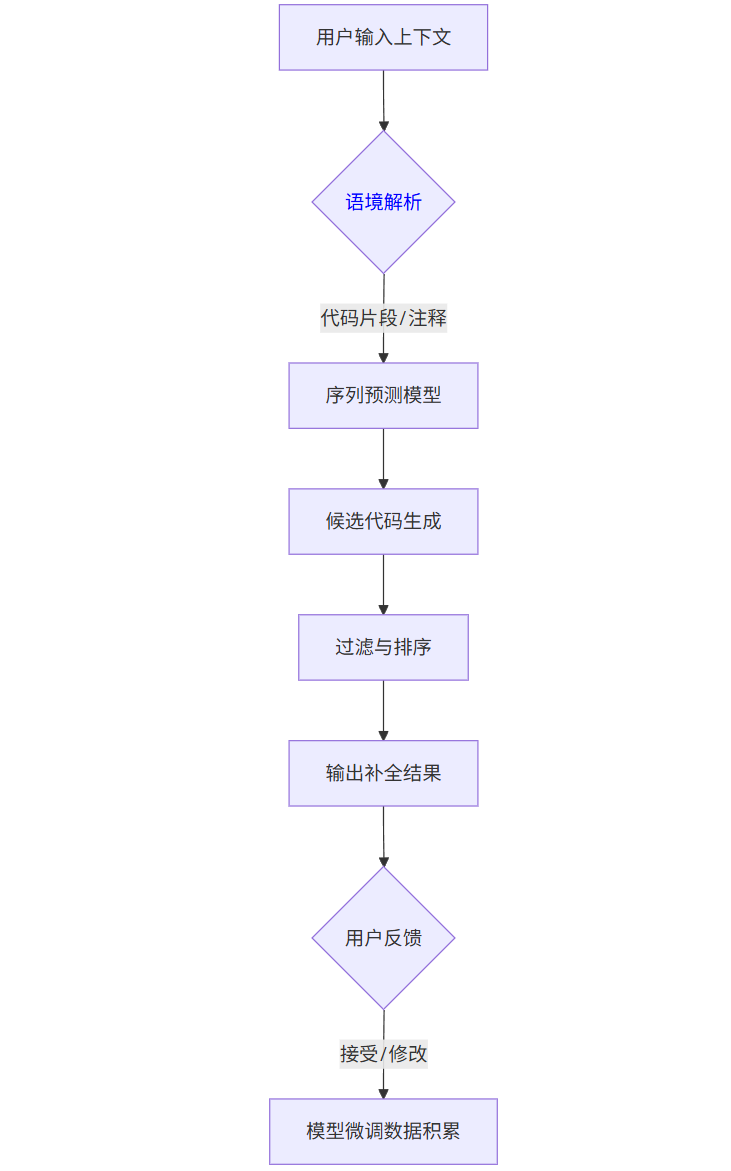
- 语境解析:工具会分析当前文件的代码结构、导入库、变量命名规范等,建立上下文理解
- 序列预测:基于 Transformer 的 decoder 结构,将代码 token 序列作为输入,预测下一个最可能的 token 序列
- 结果过滤:通过语法检查、安全性过滤(如避免生成恶意代码)筛选候选结果
- 反馈循环:用户对生成结果的选择会作为隐性反馈,用于模型的持续优化
1.2 主流工具对比与实践
| 工具名称 | 模型基础 | 支持语言 | 集成方式 | 开源性 | 核心优势 |
|---|---|---|---|---|---|
| GitHub Copilot | GPT-4/CodeLlama | 100 + 编程语言 | VS Code/JetBrains 插件 | 闭源 | 与 GitHub 生态深度集成,多语言支持 |
| Tabnine | 自定义 LLM | 50 + 编程语言 | 多 IDE 支持 | 部分开源 | 本地部署选项,隐私保护 |
| CodeLlama | Llama 2 | 主要编程语言 | 需自建集成 | 开源 | 可微调,自定义性强 |
| Amazon CodeWhisperer | 亚马逊自研模型 | 主流编程语言 | AWS 工具链集成 | 闭源 | 安全扫描功能,云原生优化 |
1.2.1 GitHub Copilot 实践示例
场景:生成 Python 数据清洗函数
用户输入(Prompt):
python
# 定义一个函数,接收 pandas DataFrame 作为输入
# 功能:1. 移除缺失值超过50%的列
# 2. 对数值列填充中位数
# 3. 对类别列填充众数
# 4. 返回处理后的DataFrame和缺失值报告
import pandas as pd
def clean_data(df):
Copilot 生成结果:
python
import pandas as pd
import numpy as np
def clean_data(df):
# 初始化缺失值报告
missing_report = {}
# 1. 移除缺失值超过50%的列
initial_columns = df.columns.tolist()
missing_ratio = df.isnull().mean()
columns_to_drop = missing_ratio[missing_ratio > 0.5].index.tolist()
if columns_to_drop:
df = df.drop(columns=columns_to_drop)
missing_report['dropped_columns'] = {
'columns': columns_to_drop,
'reason': '缺失值比例超过50%'
}
# 2. 分离数值列和类别列
numeric_cols = df.select_dtypes(include=['int64', 'float64']).columns.tolist()
categorical_cols = df.select_dtypes(include=['object', 'category']).columns.tolist()
# 3. 填充数值列中位数
if numeric_cols:
numeric_medians = df[numeric_cols].median()
df[numeric_cols] = df[numeric_cols].fillna(numeric_medians)
missing_report['numeric_imputation'] = {
'columns': numeric_cols,
'method': 'median',
'values': numeric_medians.to_dict()
}
# 4. 填充类别列众数
if categorical_cols:
categorical_modes = df[categorical_cols].mode().iloc[0] # 取第一个众数
df[categorical_cols] = df[categorical_cols].fillna(categorical_modes)
missing_report['categorical_imputation'] = {
'columns': categorical_cols,
'method': 'mode',
'values': categorical_modes.to_dict()
}
# 5. 生成总体缺失值统计
remaining_missing = df.isnull().sum().sum()
missing_report['total_remaining_missing'] = remaining_missing
return df, missing_report
1.2.2 CodeLlama 本地部署与微调
CodeLlama 作为开源模型,支持本地部署和领域微调,以下是基于 Hugging Face 库的部署示例:
python
运行
from transformers import AutoTokenizer, AutoModelForCausalLM
# 加载模型和分词器
model_name = "codellama/CodeLlama-7b-hf"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
load_in_4bit=True, # 4位量化节省显存
torch_dtype=torch.bfloat16
)
# 代码生成函数
def generate_code(prompt, max_length=200):
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(
**inputs,
max_new_tokens=max_length,
temperature=0.7, # 控制随机性,越低越确定
top_p=0.95,
do_sample=True,
pad_token_id=tokenizer.eos_token_id
)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
# 使用示例
prompt = """// C语言实现快速排序算法
void quick_sort(int arr[], int low, int high) {
"""
print(generate_code(prompt))
1.3 智能编码工具的 Prompt 工程
优质的 Prompt 能显著提升代码生成质量,核心原则包括:
- 明确功能需求和输入输出格式
- 提供必要的上下文(如使用的库、数据结构)
- 指定代码风格(如注释要求、命名规范)
- 复杂功能可分步骤描述
进阶 Prompt 示例:
plaintext
请生成一个Python函数,满足以下要求:
1. 功能:计算两个日期之间的工作日天数(排除周六、周日和指定节假日)
2. 输入参数:
- start_date: datetime.date对象,起始日期
- end_date: datetime.date对象,结束日期
- holidays: 可选参数,包含datetime.date对象的列表,默认为空
3. 输出:整数,两个日期之间的工作日天数(不包含起始日和结束日)
4. 注意事项:
- 若start_date晚于end_date,返回0
- 需处理日期跨年度的情况
- 代码需包含详细注释,解释关键步骤
- 使用标准库,不依赖第三方包
二、数据标注工具:AI 训练的数据基石
数据标注是机器学习流程中的关键环节,高质量的标注数据直接决定模型性能。数据标注工具通过可视化界面和自动化辅助功能,降低标注成本、提升标注一致性。根据数据类型,标注工具可分为图像标注、文本标注、音频标注和视频标注四大类。
2.1 工具分类与核心功能
2.1.1 图像标注工具
- 边界框标注:用于目标检测任务,标记物体的矩形边界
- 多边形标注:用于不规则形状物体,如语义分割中的前景区域
- 关键点标注:用于姿态估计,标记人体关节等特征点
- 像素级标注:用于语义分割,为每个像素分配类别标签
2.1.2 文本标注工具
- 实体标注:标记命名实体(如人名、地名、组织机构)
- 情感标注:标记文本情感倾向(如积极、消极、中性)
- 意图标注:标记用户 query 的意图类别(如查询、购买、投诉)
- 关系标注:标记实体间的语义关系(如 "属于"、"位于")
2.2 主流标注工具对比
| 工具名称 | 支持数据类型 | 核心功能 | 开源性 | 协作功能 | 自动化辅助 |
|---|---|---|---|---|---|
| Label Studio | 图像、文本、音频、视频 | 多类型标注,自定义模板 | 开源 | 支持团队协作 | 集成 ML 模型辅助标注 |
| VGG Image Annotator | 图像 | 简单边界框、多边形标注 | 开源 | 无 | 无 |
| LabelImg | 图像 | 边界框标注,支持 YOLO 格式 | 开源 | 无 | 无 |
| Prodigy | 文本、图像 | 高效标注,支持主动学习 | 闭源 | 有限 | 强,可集成模型 |
| Amazon SageMaker Ground Truth | 多类型 | 大规模标注管理,人机协同 | 闭源 | 支持 | 自动化标注功能 |
2.3 Label Studio 实践指南
Label Studio 是目前功能最全面的开源标注工具,支持自定义标注模板和 ML 模型集成,以下是其核心使用流程:
graph TD
A[安装部署] --> B[创建项目]
B --> C[导入数据]
C --> D[配置标注模板]
D --> E[开始标注]
E --> F{是否使用辅助标注}
F -->|是| G[集成ML模型]
F -->|否| H[人工标注]
G --> H
H --> I[质量检查]
I --> J[导出标注结果]
J --> K[模型训练]
K --> L[模型反馈优化]
L --> G
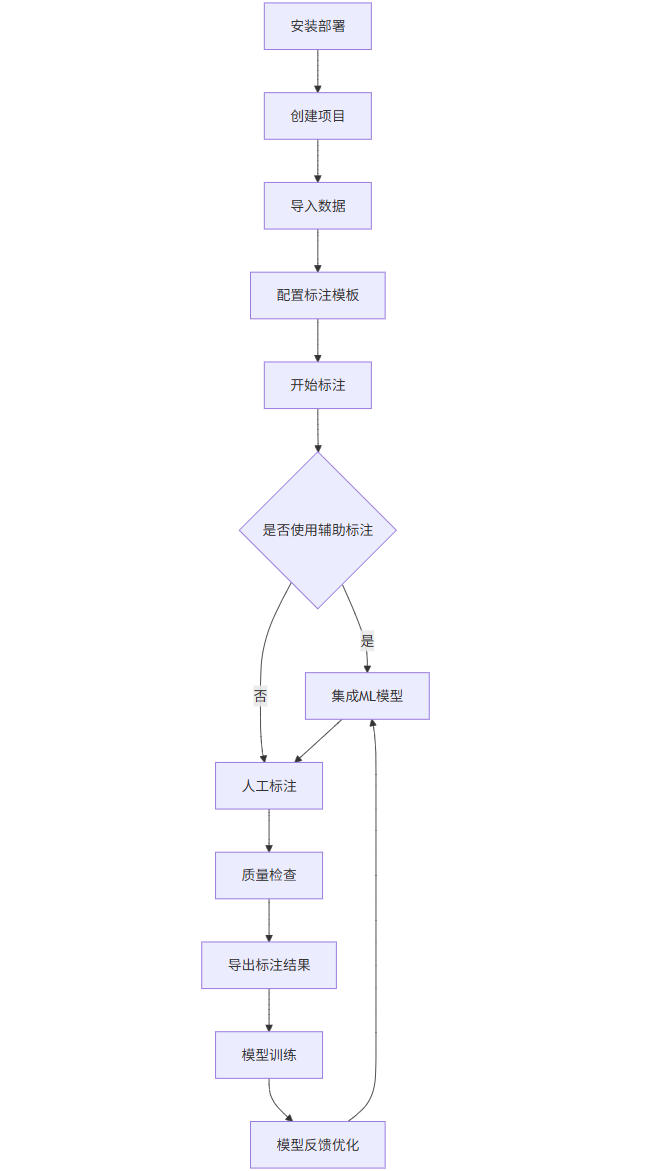
2.3.1 安装与配置
bash
# 安装Label Studio
pip install label-studio
# 启动服务
label-studio start --port 8080
2.3.2 自定义标注模板
文本实体标注模板示例:
xml
<View>
<Header value="实体标注任务"/>
<Text name="text" value="$text"/>
<Labels name="labels" toName="text">
<Label value="人名" background="#FF0000"/>
<Label value="地名" background="#00FF00"/>
<Label value="组织机构" background="#0000FF"/>
<Label value="时间" background="#FFFF00"/>
</Labels>
</View>
图像分割标注模板示例:
xml
<View>
<Header value="道路场景分割"/>
<Image name="image" value="$image" zoom="true"/>
<PolygonLabels name="labels" toName="image">
<Label value="道路" background="#FF0000"/>
<Label value="车辆" background="#00FF00"/>
<Label value="行人" background="#0000FF"/>
<Label value="建筑物" background="#FFFF00"/>
<Label value="植被" background="#00FFFF"/>
</PolygonLabels>
</View>
2.3.3 集成 ML 模型辅助标注
Label Studio 可集成预训练模型实现半自动化标注,以文本分类为例:
python
运行
# 自定义ML后端示例(使用Hugging Face模型)
from label_studio_ml.model import LabelStudioMLBase
from transformers import pipeline
class TextClassifier(LabelStudioMLBase):
def __init__(self, **kwargs):
super().__init__(** kwargs)
# 加载预训练情感分析模型
self.classifier = pipeline("sentiment-analysis")
# 映射模型输出到标注格式
self.from_name = self.parsed_label_config['from_name'][0]['name']
self.to_name = self.parsed_label_config['to_name'][0]['name']
self.labels = [label['value'] for label in self.parsed_label_config['labels']]
def predict(self, tasks, **kwargs):
predictions = []
for task in tasks:
text = task['data']['text']
# 模型预测
result = self.classifier(text)[0]
# 转换为Label Studio格式
predictions.append({
'result': [{
'from_name': self.from_name,
'to_name': self.to_name,
'type': 'labels',
'value': {'labels': [result['label']]},
'score': result['score']
}],
'score': result['score']
})
return predictions
# 启动ML后端服务
if __name__ == "__main__":
from label_studio_ml.server import run_server
run_server(TextClassifier)
2.4 标注质量控制与 Prompt 设计
标注质量控制需从三个维度入手:
- 标注指南:明确标注标准和边缘情况处理规则
- 交叉验证:同一数据由多名标注员标注,计算一致性(如 Cohen's Kappa 系数)
- 抽样检查:随机抽取标注数据进行专家审核
标注员指导 Prompt 示例(图像标注):
plaintext
任务:道路交通事故图像中的车辆损伤标注
标注要求:
1. 使用边界框标记所有受损车辆
2. 使用多边形标记具体损伤区域,包括:
- 划痕:轻微漆面损伤,无凹陷
- 凹陷:车身变形,无穿孔
- 碎裂:玻璃或灯具破碎
- 穿孔:车身出现孔洞
3. 标注注意事项:
- 损伤区域需完整包围可见损伤部分
- 多类型损伤需分别标注(如同一位置有划痕和凹陷)
- 无法确定的损伤标记为"不确定"
- 车辆内部损伤无需标注
示例说明:
- 图1中红色轿车左前门有长约30cm划痕 → 标记"划痕"多边形
- 图2中黑色SUV后保险杠凹陷 → 标记"凹陷"多边形
三、模型训练平台:从实验到生产的桥梁
模型训练平台旨在简化机器学习工作流,提供数据处理、模型构建、训练调度、性能监控等全流程支持。现代训练平台强调可复现性、可扩展性和自动化,支持从单机实验到大规模分布式训练的无缝过渡。
3.1 平台架构与核心组件
典型的模型训练平台包含以下核心组件:
graph TD
subgraph 数据层
A[数据存储] --> B[数据版本控制]
B --> C[数据预处理流水线]
end
subgraph 模型层
D[模型定义] --> E[模型版本控制]
E --> F[超参数管理]
end
subgraph 计算层
G[计算资源调度] --> H[分布式训练]
H --> I[训练监控]
end
subgraph 部署层
J[模型打包] --> K[推理服务]
K --> L[模型监控]
end
A --> D
D --> G
G --> J
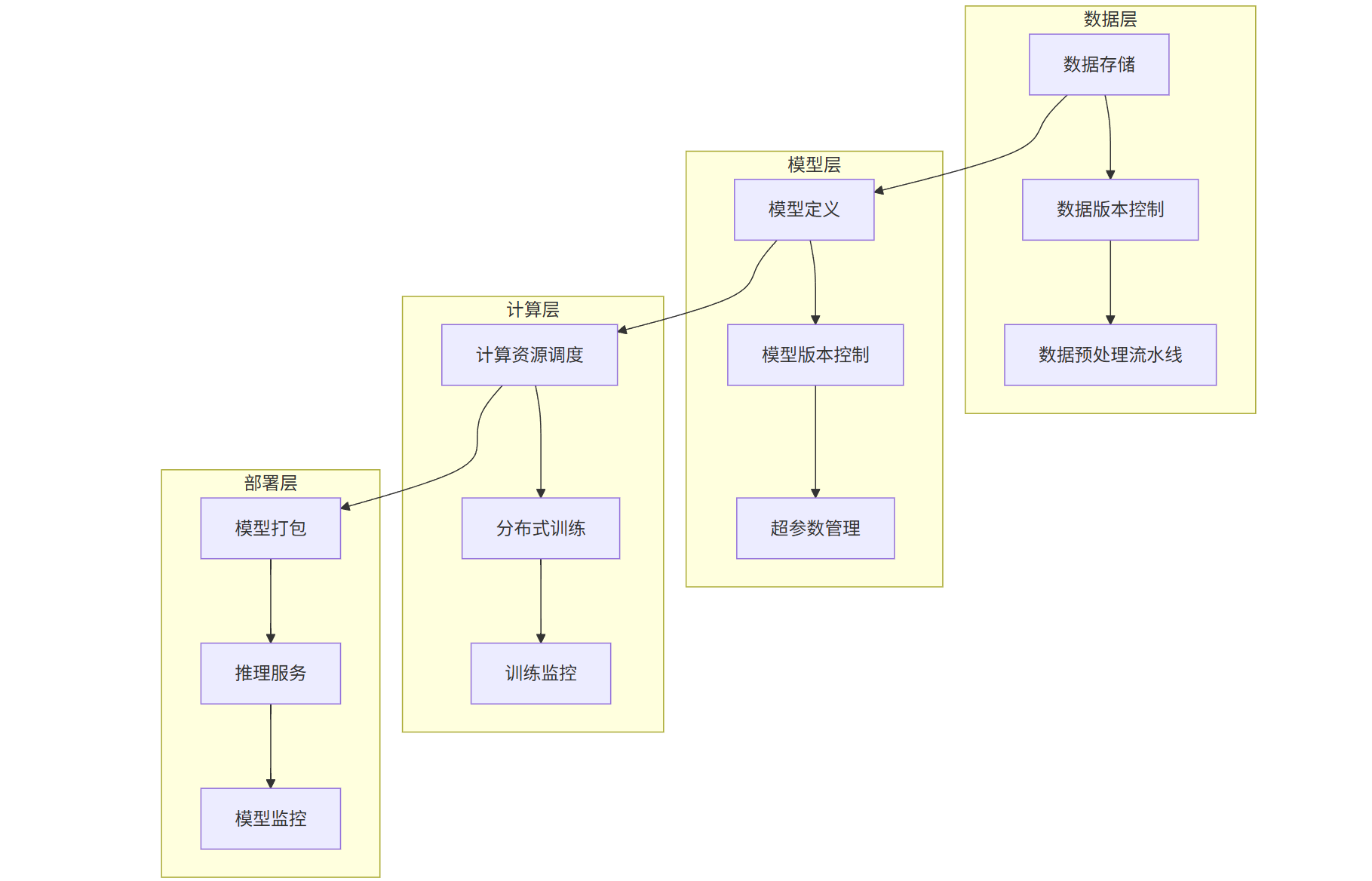
3.2 主流训练平台对比
| 平台名称 | 核心优势 | 生态集成 | 分布式支持 | 易用性 | 开源性 |
|---|---|---|---|---|---|
| TensorFlow Extended (TFX) | 全流程自动化 | TensorFlow 生态 | 强 | 中 | 开源 |
| PyTorch Lightning | 简化 PyTorch 代码 | PyTorch 生态 | 强 | 高 | 开源 |
| Kubeflow | 云原生,多框架支持 | Kubernetes 生态 | 极强 | 低 | 开源 |
| AWS SageMaker | 托管服务,低运维 | AWS 云服务 | 强 | 高 | 闭源 |
| MLflow | 模型生命周期管理 | 多框架兼容 | 中 | 高 | 开源 |
3.3 PyTorch Lightning 实践示例
PyTorch Lightning 通过分离科研代码与工程代码,提高训练代码的可读性和可维护性:
python
运行
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from pytorch_lightning import LightningModule, Trainer, LightningDataModule
from pytorch_lightning.callbacks import ModelCheckpoint, EarlyStopping
from pytorch_lightning.loggers import TensorBoardLogger
# 1. 定义数据集
class CustomDataset(Dataset):
def __init__(self, size=1000, transform=None):
self.data = torch.randn(size, 20) # 20维特征
self.labels = torch.randint(0, 2, (size,)) # 二分类标签
self.transform = transform
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
x = self.data[idx]
y = self.labels[idx]
if self.transform:
x = self.transform(x)
return x, y
# 2. 定义数据模块
class CustomDataModule(LightningDataModule):
def __init__(self, batch_size=32):
super().__init__()
self.batch_size = batch_size
def prepare_data(self):
# 下载数据等一次性操作
pass
def setup(self, stage=None):
# 划分训练集、验证集、测试集
if stage == 'fit' or stage is None:
self.train_dataset = CustomDataset(size=800)
self.val_dataset = CustomDataset(size=200)
if stage == 'test' or stage is None:
self.test_dataset = CustomDataset(size=200)
def train_dataloader(self):
return DataLoader(self.train_dataset, batch_size=self.batch_size, shuffle=True)
def val_dataloader(self):
return DataLoader(self.val_dataset, batch_size=self.batch_size)
def test_dataloader(self):
return DataLoader(self.test_dataset, batch_size=self.batch_size)
# 3. 定义模型
class Classifier(LightningModule):
def __init__(self, input_dim=20, hidden_dim=64, learning_rate=1e-3):
super().__init__()
self.save_hyperparameters() # 自动保存超参数
self.model = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim//2),
nn.ReLU(),
nn.Linear(hidden_dim//2, 1)
)
self.train_acc = []
self.val_acc = []
def forward(self, x):
return self.model(x)
def training_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x).squeeze()
loss = F.binary_cross_entropy_with_logits(y_hat, y.float())
preds = (torch.sigmoid(y_hat) > 0.5).float()
acc = (preds == y.float()).float().mean()
self.log('train_loss', loss, prog_bar=True)
self.log('train_acc', acc, prog_bar=True)
self.train_acc.append(acc.item())
return loss
def validation_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x).squeeze()
loss = F.binary_cross_entropy_with_logits(y_hat, y.float())
preds = (torch.sigmoid(y_hat) > 0.5).float()
acc = (preds == y.float()).float().mean()
self.log('val_loss', loss, prog_bar=True)
self.log('val_acc', acc, prog_bar=True)
self.val_acc.append(acc.item())
return loss
def test_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x).squeeze()
preds = (torch.sigmoid(y_hat) > 0.5).float()
acc = (preds == y.float()).float().mean()
self.log('test_acc', acc)
return acc
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.parameters(), lr=self.hparams.learning_rate)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(
optimizer, mode='min', factor=0.5, patience=3
)
return {
'optimizer': optimizer,
'lr_scheduler': scheduler,
'monitor': 'val_loss'
}
# 4. 训练模型
if __name__ == '__main__':
# 配置回调函数
checkpoint_callback = ModelCheckpoint(
monitor='val_acc',
mode='max',
save_top_k=1,
dirpath='checkpoints/',
filename='best-model'
)
early_stopping = EarlyStopping(
monitor='val_loss',
patience=5,
mode='min'
)
logger = TensorBoardLogger('tb_logs', name='classifier_exp')
# 初始化组件
dm = CustomDataModule(batch_size=32)
model = Classifier(hidden_dim=128, learning_rate=5e-4)
# 初始化训练器
trainer = Trainer(
max_epochs=50,
accelerator='auto', # 自动选择GPU/CPU
devices='auto',
callbacks=[checkpoint_callback, early_stopping],
logger=logger,
log_every_n_steps=10,
enable_progress_bar=True
)
# 开始训练
trainer.fit(model, datamodule=dm)
# 测试模型
trainer.test(model, datamodule=dm, ckpt_path='best')
3.4 Kubeflow 管道构建
Kubeflow 作为云原生机器学习平台,支持构建可移植、可复现的训练流水线:
python
运行
# 安装依赖
!pip install kfp
import kfp
from kfp import dsl
from kfp.components import create_component_from_func
# 1. 定义组件
@create_component_from_func
def data_preprocessing_op(input_path: str, output_path: str) -> str:
"""数据预处理组件"""
import pandas as pd
import os
# 读取数据
df = pd.read_csv(input_path)
# 简单预处理
df = df.dropna()
df = df.drop_duplicates()
# 保存结果
os.makedirs(os.path.dirname(output_path), exist_ok=True)
df.to_csv(output_path, index=False)
return output_path
@create_component_from_func
def train_model_op(data_path: str, model_path: str, epochs: int) -> str:
"""模型训练组件"""
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
import joblib
import os
# 加载数据
df = pd.read_csv(data_path)
X = df.drop('target', axis=1)
y = df['target']
# 训练模型
model = RandomForestClassifier(n_estimators=100)
model.fit(X, y)
# 保存模型
os.makedirs(os.path.dirname(model_path), exist_ok=True)
joblib.dump(model, model_path)
return model_path
@create_component_from_func
def evaluate_model_op(model_path: str, data_path: str) -> float:
"""模型评估组件"""
import pandas as pd
import joblib
from sklearn.metrics import accuracy_score
# 加载模型和数据
model = joblib.load(model_path)
df = pd.read_csv(data_path)
X = df.drop('target', axis=1)
y = df['target']
# 评估
y_pred = model.predict(X)
accuracy = accuracy_score(y, y_pred)
return accuracy
# 2. 定义流水线
@dsl.pipeline(
name="分类模型训练流水线",
pipeline_root="gs://my-bucket/kubeflow-pipelines"
)
def pipeline(
input_data: str = "gs://my-bucket/data/raw_data.csv",
epochs: int = 10
):
# 数据预处理
preprocess_task = data_preprocessing_op(
input_path=input_data,
output_path="gs://my-bucket/data/processed_data.csv"
)
# 模型训练
train_task = train_model_op(
data_path=preprocess_task.output,
model_path="gs://my-bucket/models/rf_model.pkl",
epochs=epochs
)
train_task.set_cpu_request("1")
train_task.set_memory_request("1Gi")
# 模型评估
eval_task = evaluate_model_op(
model_path=train_task.output,
data_path=preprocess_task.output
)
eval_task.set_cpu_request("500m")
# 3. 编译并提交流水线
if __name__ == "__main__":
kfp.compiler.Compiler().compile(pipeline, "training_pipeline.yaml")
# 提交到Kubeflow集群
client = kfp.Client()
experiment = client.create_experiment(name="classification-experiment")
run = client.run_pipeline(
experiment_id=experiment.id,
job_name="classification-run",
pipeline_package_path="training_pipeline.yaml"
)
3.5 模型训练的超参数优化
超参数优化是提升模型性能的关键,Optuna 是目前主流的自动化超参数优化框架:
python
运行
import optuna
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, random_split
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 准备数据
X, y = make_classification(n_samples=10000, n_features=20, random_state=42)
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
# 数据标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_val = scaler.transform(X_val)
# 转换为Tensor
X_train = torch.FloatTensor(X_train)
y_train = torch.LongTensor(y_train)
X_val = torch.FloatTensor(X_val)
y_val = torch.LongTensor(y_val)
# 定义数据加载器
train_dataset = torch.utils.data.TensorDataset(X_train, y_train)
val_dataset = torch.utils.data.TensorDataset(X_val, y_val)
# 定义模型
class Net(nn.Module):
def __init__(self, input_dim, hidden_dim1, hidden_dim2, dropout_rate):
super(Net, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim1)
self.fc2 = nn.Linear(hidden_dim1, hidden_dim2)
self.fc3 = nn.Linear(hidden_dim2, 2)
self.dropout = nn.Dropout(dropout_rate)
self.relu = nn.ReLU()
def forward(self, x):
x = self.relu(self.fc1(x))
x = self.dropout(x)
x = self.relu(self.fc2(x))
x = self.dropout(x)
x = self.fc3(x)
return x
# 定义训练函数
def train_model(trial, model, train_loader, val_loader, optimizer, criterion, epochs=10):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
for epoch in range(epochs):
model.train()
train_loss = 0.0
for batch_x, batch_y in train_loader:
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
optimizer.zero_grad()
outputs = model(batch_x)
loss = criterion(outputs, batch_y)
loss.backward()
optimizer.step()
train_loss += loss.item()
# 验证
model.eval()
val_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for batch_x, batch_y in val_loader:
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
outputs = model(batch_x)
loss = criterion(outputs, batch_y)
val_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += batch_y.size(0)
correct += (predicted == batch_y).sum().item()
val_acc = correct / total
# 早停机制
trial.report(val_acc, epoch)
if trial.should_prune():
raise optuna.exceptions.TrialPruned()
return val_acc
# 定义优化目标函数
def objective(trial):
# 超参数搜索空间
batch_size = trial.suggest_categorical("batch_size", [32, 64, 128])
hidden_dim1 = trial.suggest_int("hidden_dim1", 32, 256, step=32)
hidden_dim2 = trial.suggest_int("hidden_dim2", 16, 128, step=16)
dropout_rate = trial.suggest_float("dropout_rate", 0.1, 0.5, step=0.1)
learning_rate = trial.suggest_float("learning_rate", 1e-5, 1e-2, log=True)
optimizer_name = trial.suggest_categorical("optimizer", ["Adam", "SGD", "RMSprop"])
# 数据加载器
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
# 模型初始化
model = Net(
input_dim=20,
hidden_dim1=hidden_dim1,
hidden_dim2=hidden_dim2,
dropout_rate=dropout_rate
)
# 优化器
if optimizer_name == "Adam":
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
elif optimizer_name == "SGD":
optimizer = optim.SGD(model.parameters(), lr=learning_rate, momentum=0.9)
else:
optimizer = optim.RMSprop(model.parameters(), lr=learning_rate)
criterion = nn.CrossEntropyLoss()
# 训练模型
val_acc = train_model(
trial, model, train_loader, val_loader, optimizer, criterion, epochs=20
)
return val_acc
# 运行优化
study = optuna.create_study(
direction="maximize",
pruner=optuna.pruners.MedianPruner(n_warmup_steps=5)
)
study.optimize(objective, n_trials=50, show_progress_bar=True)
# 输出结果
print(f"最佳准确率: {study.best_value:.4f}")
print("最佳超参数:")
for key, value in study.best_params.items():
print(f" {key}: {value}")
四、AI 工具链的协同与未来趋势
智能编码工具、数据标注工具与模型训练平台并非孤立存在,而是构成了完整的 AI 开发生命周期。三者的协同能够实现从需求分析到模型部署的全流程自动化:
- 需求到代码:智能编码工具将自然语言需求转换为数据处理和模型训练代码
- 数据闭环:标注工具生成的数据集直接对接训练平台,模型输出反馈优化标注策略
- 持续迭代:训练平台的模型性能数据指导编码工具优化实现方式
未来趋势展望:
- 多模态融合:工具将支持文本、图像、音频等多类型数据的统一处理
- AutoML 深化:从特征工程到模型选择的端到端自动化
- 边缘部署优化:工具链将更注重模型轻量化和边缘设备适配
- 隐私保护增强:联邦学习、差分隐私等技术与工具链深度集成
通过合理配置与协同使用这些工具,开发者能够将精力从重复性工作转向创造性任务,加速 AI 技术的创新与落地。
注:本文提供的代码示例均经过简化处理,实际生产环境中需根据具体需求进行扩展和优化。工具的选择应结合项目规模、团队技术栈和部署环境综合考量。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 9
9 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)