又又又双叒叕一款AI IDE发布,国内第五款国产AI IDE Qoder来了
阿里推出第五款国产AI IDE工具Qoder,定位为"代理编码平台",支持Windows/macOS系统,目前免费开放预览。Qoder强调工程化协作能力,提供聊天模式和任务模式两种形态,支持长期项目演进。其核心特点包括:知识可见性、执行透明、增强上下文工程和自动模型路由,适用于新项目开发、老项目维护等场景。随着AI编程从代码补全向半/全托管开发演进,Qoder试图解决软件开发中
又又又双叒叕一款AI IDE发布,国内第五款国产AI IDE Qoder来了
导语|猫头虎碎碎念
最近 AI 编程赛道又起浪。腾讯有 CodeBuddy、字节有 Trae、百度推了 文心快码、阿里这边本来就有 Lingma IDE,而今天又出现一条新动向:据爆料,阿里推出了 Qoder(谐音 Coder)。从公开页面看,支持 Windows / macOS,目前处于“免费公开预览”。
官网直达:https://qoder.com/

一口气看完(TL;DR)
-
Qoder 是啥:定位成“用于真实软件的代理编码平台”,不是只写几行小函数,而是面向长期演进的工程项目。
-
两种协作形态:
- 聊天模式:边聊边改,我盯着流程走;
- 任务模式:写好 Spec(规范)后一键托管,AI 自主推进、遇阻再询问。
-
方法论关键词:知识可见性、执行透明、增强上下文工程(记忆 + 图谱 + 索引)、自动模型路由。
-
适用场景:新项目起步、老项目加功能、日常多文件联动修改、复杂仓库“找上下文”、应急排障。
-
当前状态:官网显示“公开预览,免费”。(一切以官方实际页面为准)
Qoder 是什么?(用我的话讲)
Qoder 把 AI 当成可委托的“座席”,核心目标是:在真实代码库里,连续、可追踪地完成工程任务,而不是只在编辑器里抛几段补全。
原话:Qoder,专为真实软件开发打造的Agentic 编程平台!
下载页大概长这样:
当前标注的是免费公开预览:
小贴士:预览期功能和条款可能调整,以官网为准。
背景:AI 编程趋势到底在变啥?
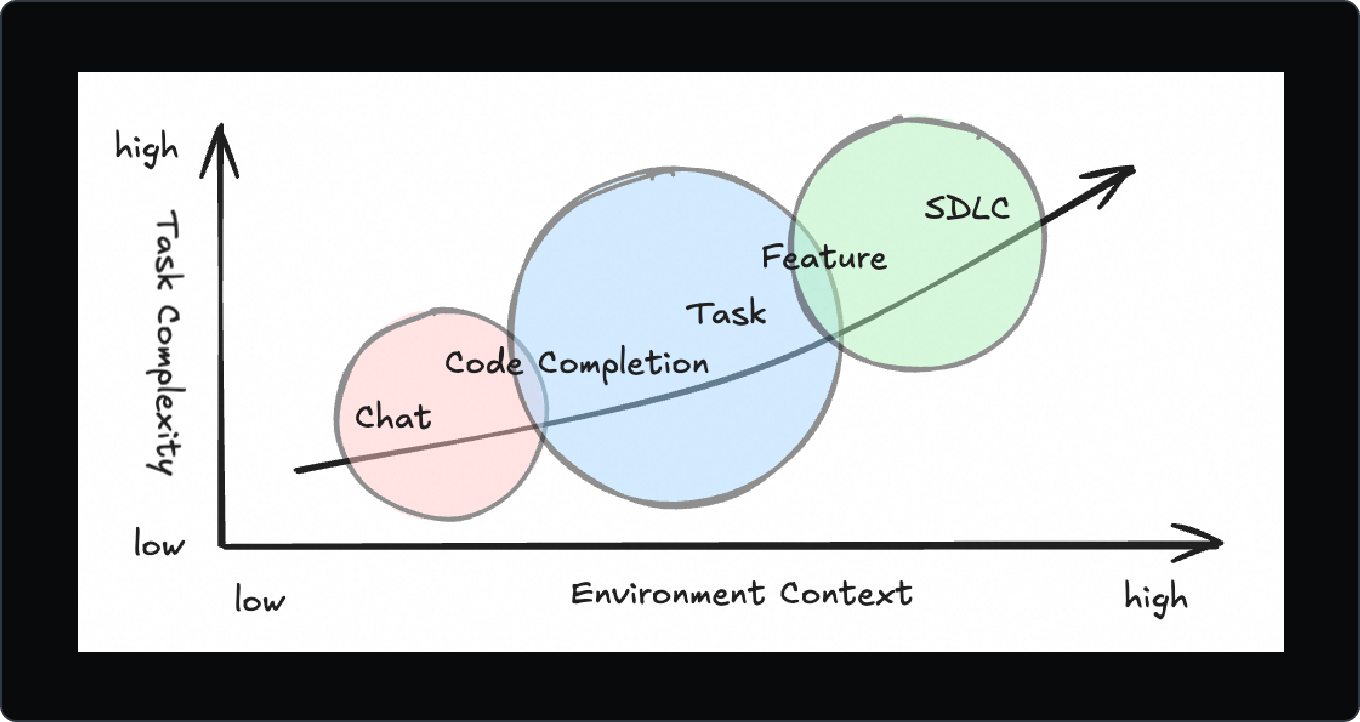
随着大模型的升级,AI 编码经历了三段进化:
- 辅助写代码:自动补全、片段生成;
- 对话式改造:聊天驱动重构与修修补补;
- 半/全托管开发:给 AI 明确目标与边界,让它自己跑流程。
AI 的身份从“工具”变成“同事”,逐步承担多步、长期的工程任务。
工程现实不讲情怀:几件老大难
Brooks 在《人月神话》里归纳过软件的四宗硬伤:复杂 / 一致性 / 可变性 / 隐形。到了 AI 时代,这些痛点并没有自动消失,反而可能被放大:
- 知识太抽象 → 新人接手困难,技术债容易滚雪球;
- 沉迷“自动多写点” → 设计与需求澄清被忽略,后期维护更心累;
- 强同步沟通 → 人机来回确认,AI 很难“长距离奔跑”。
Qoder 的解法(我理解的 4 个关键词)
① 让不可见变可见:知识与执行的透明度
-
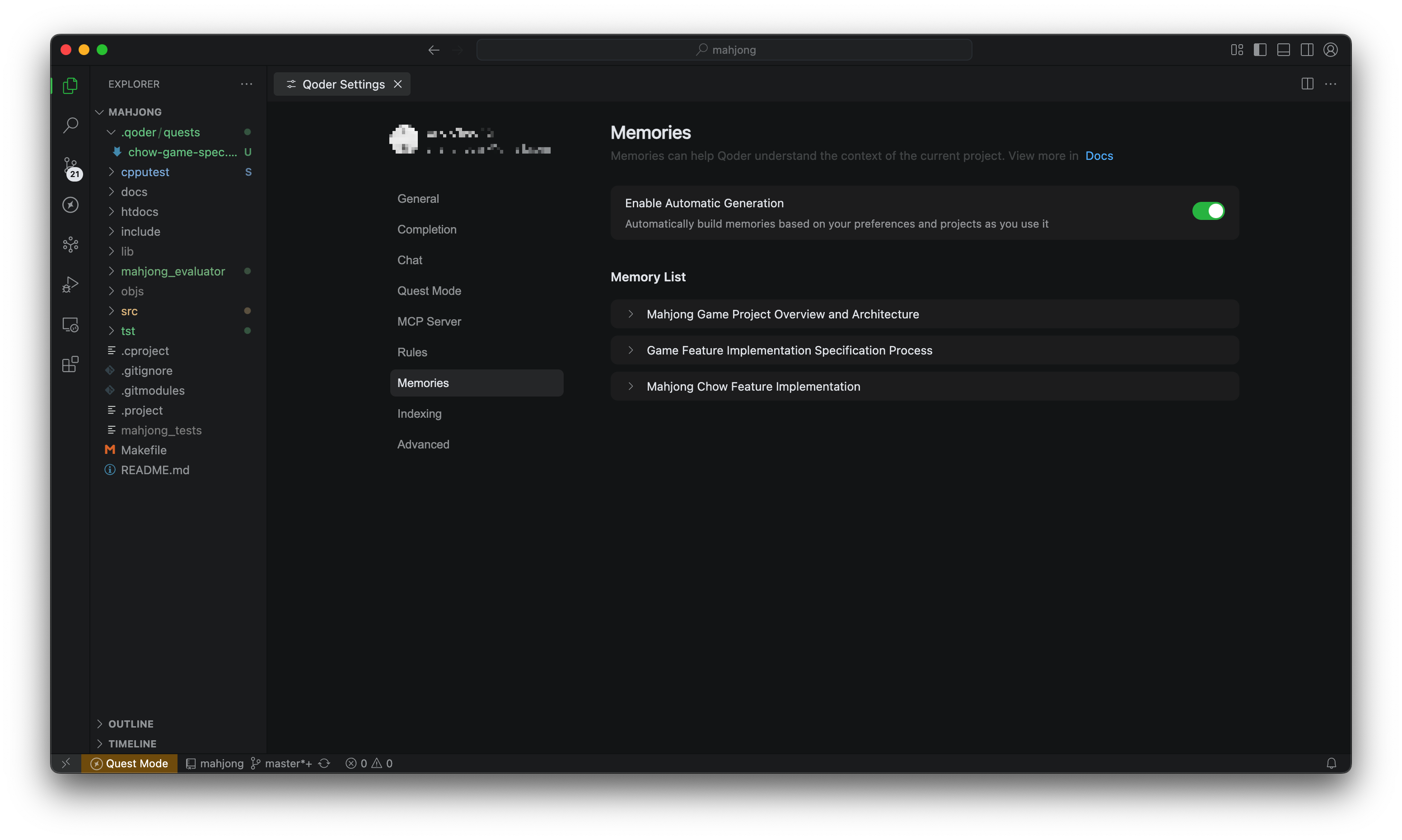
知识可见性:不止会写代码,还要帮人看清项目——架构、设计、债务、决策脉络。
-
执行透明:
- To-Do 清单:任务拆解、优先级、预估路径;
- Action Flow:过程跟踪与关键决策记录。
目的很简单:让开发者始终“心里有数”,而不是黑箱托管。
② 增强上下文工程(Enhanced Context Engineering)
口号版:上下文越厚,建议越准。
- 深度理解代码库:结构、依赖、设计意图,而非只看文本相似;
- 持久记忆:项目历史、用户操作、对话上下文都能被“记住”。
③ 规范驱动 + 任务委托:把“意图”讲明白
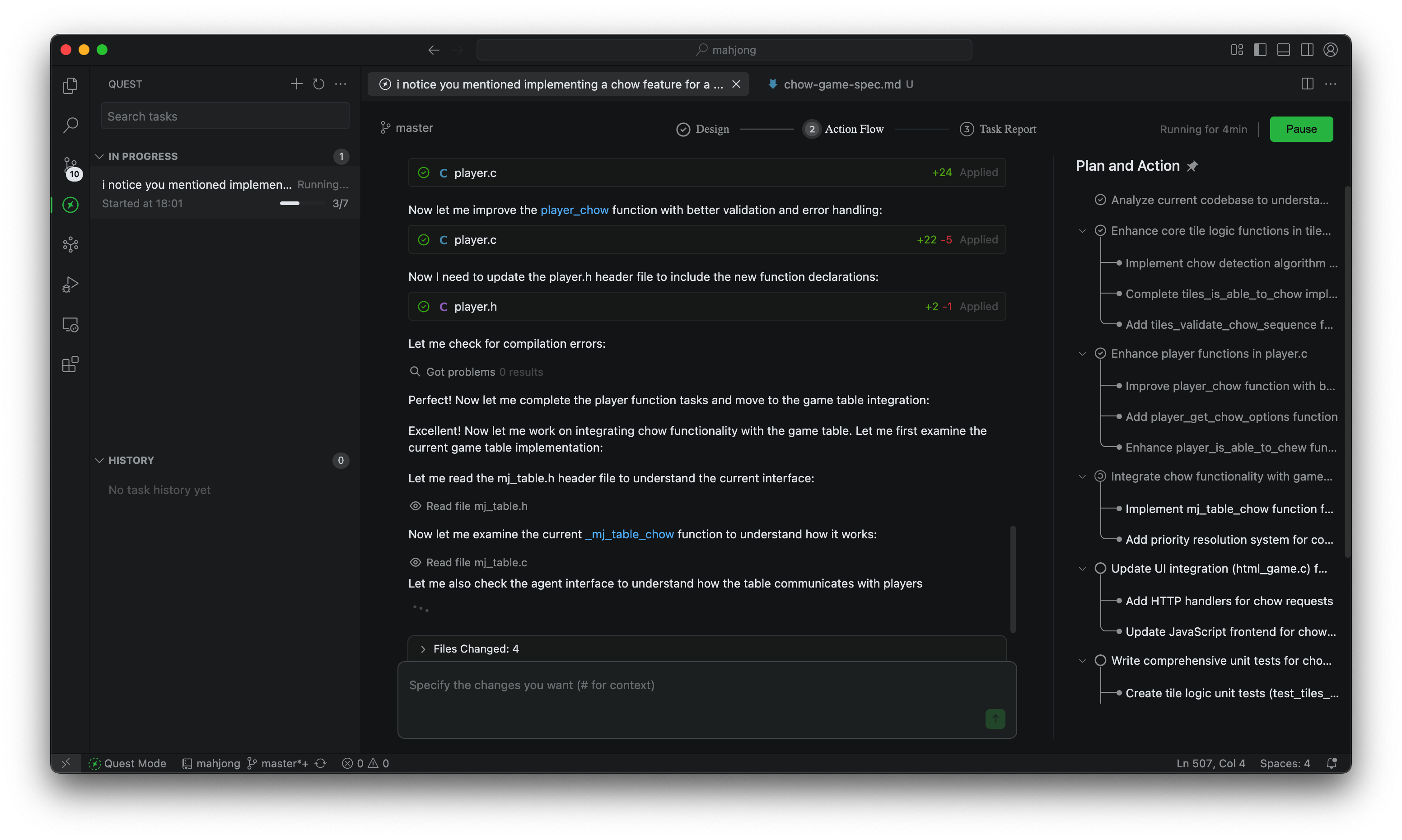
有两种协作姿势:
- 聊天模式:我通过对话驱动修改,随改随审,适合短平快;
- 任务模式:我写好 Spec(尽量把目标、边界、验收说清楚),然后托管给 AI,适合长任务。
对比表(压缩版):
| 聊天代理模式 | 任务模式 |
|---|---|
| 聊天迭代 | 规格优先 |
| 通过对话进行编码 | 将任务委托给 AI 代理 |
| 短期任务 | 长期任务 |
| 你盯流程 | 你定目标 |
我理想的一天:
上午对齐需求 → 下午和 AI 一起打磨 Spec → 下班前托管 → 第二天早上验收+重构。
④ 模型“自动路由”:别再让我比参数
模型层面,Qoder更像是**“根据任务自动选型”**。你只管说目标,怎么做交给系统,兼顾质量与成本。
上手思路(给想试试的同学)
新项目从 0 到 1
一句话描述目标即可,比如:
“用 Spring Boot 做一个图片上传/预览/下载的小应用。”
Qoder 会生成脚手架和核心逻辑;或者先开探索模式写一份可跑的 Spec(技术栈、架构、MVP 功能)。
老项目里加功能
老仓库的痛点是摸不清上下文。Qoder 的 Repo Wiki 会预索引并注入内存,启动任务即带上下文,不再手动挑文件。
日常编辑体验
- 代码补全
- NES(Next Edit Suggestion):给出“下一步修改”建议,跨多行;
- 内联编辑:直接在聊天里就地改补丁。
核心诉求:增强,不打断。
一点使用建议(主观向)
- 适合谁:经常在中大型仓库里做多点联动修改、要频繁追上下文的同学;或小团队想把“工程推进”托给 AI 提速。
- 尽量写清 Spec:别把“需求澄清”偷懒给 AI——写得越清,委托越稳。
- 关注隐私与合规:企业/高校代码要看清数据流向与权限。
- 免费 ≠ 永久:预览期策略可能变,留意官方更新。
愿景
- 把隐形知识显式化,减少沟通摩擦;
- 把重复劳动丢给 AI,人专注在设计与验证;
- 把“上下文”做厚,让 AI 真正“懂项目”,而不是“像懂”。
目前官网写着“公开预览,免费”。有兴趣的话,可以在真实项目里试一试,反馈给社区也欢迎丢给我(猫头虎)。
加餐:代码库感知的“混合检索”到底怎么落地?
从“通用嵌入”走向“实时 + 图谱 + 预索引”的组合拳
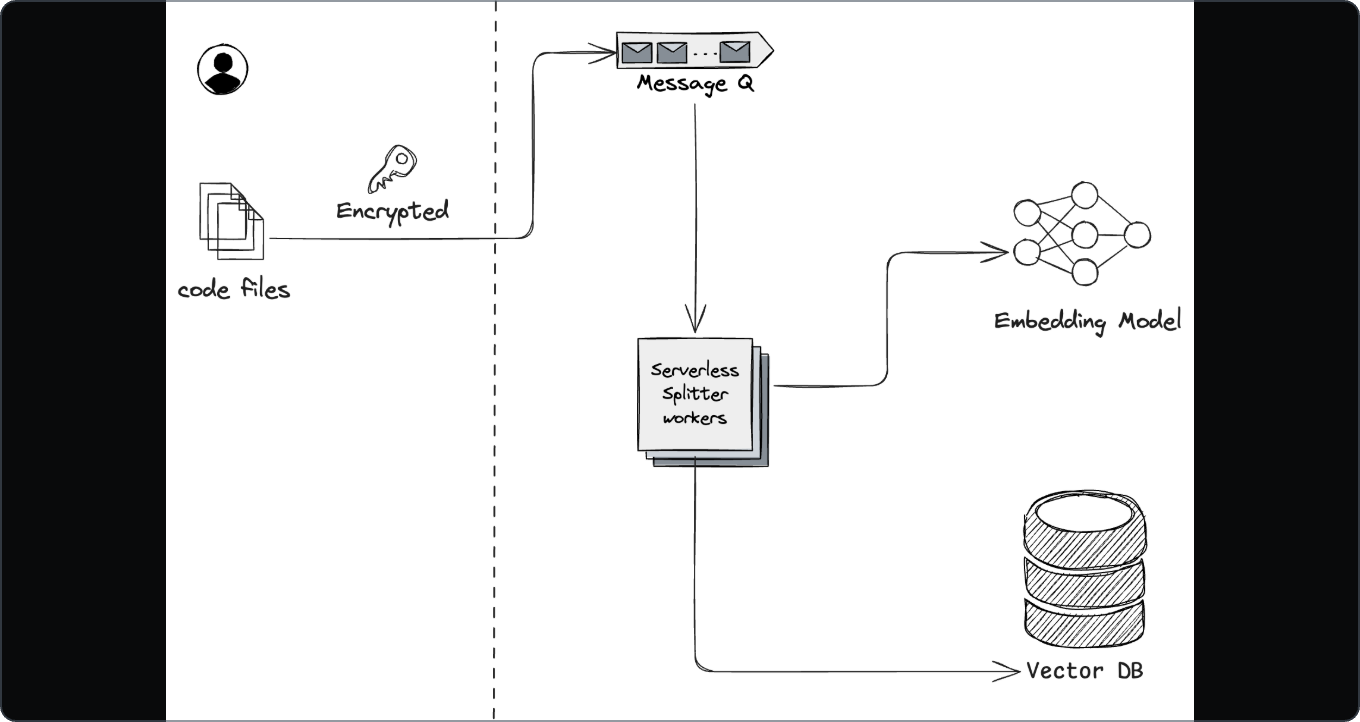
很多号称“懂你代码”的工具,底层主要靠通用嵌入 + 远端向量库:
相似度能算,但结构关系(调用/被调用、跨语言、文档概念与实现映射)容易丢;
索引通常是分钟级刷新,赶不上你本地的分支切换/重命名;
把私有代码送去第三方服务,还会有隐私顾虑。
一个更靠谱的路径,是把三件事拧在一起:
1)服务器端向量搜索(更懂“代码语义”)
后端放一个高性能向量库,存代码片段/文档/工件的嵌入;
嵌入模型针对代码/领域语义做过优化;
索引持续增量,秒级纳入新改动。
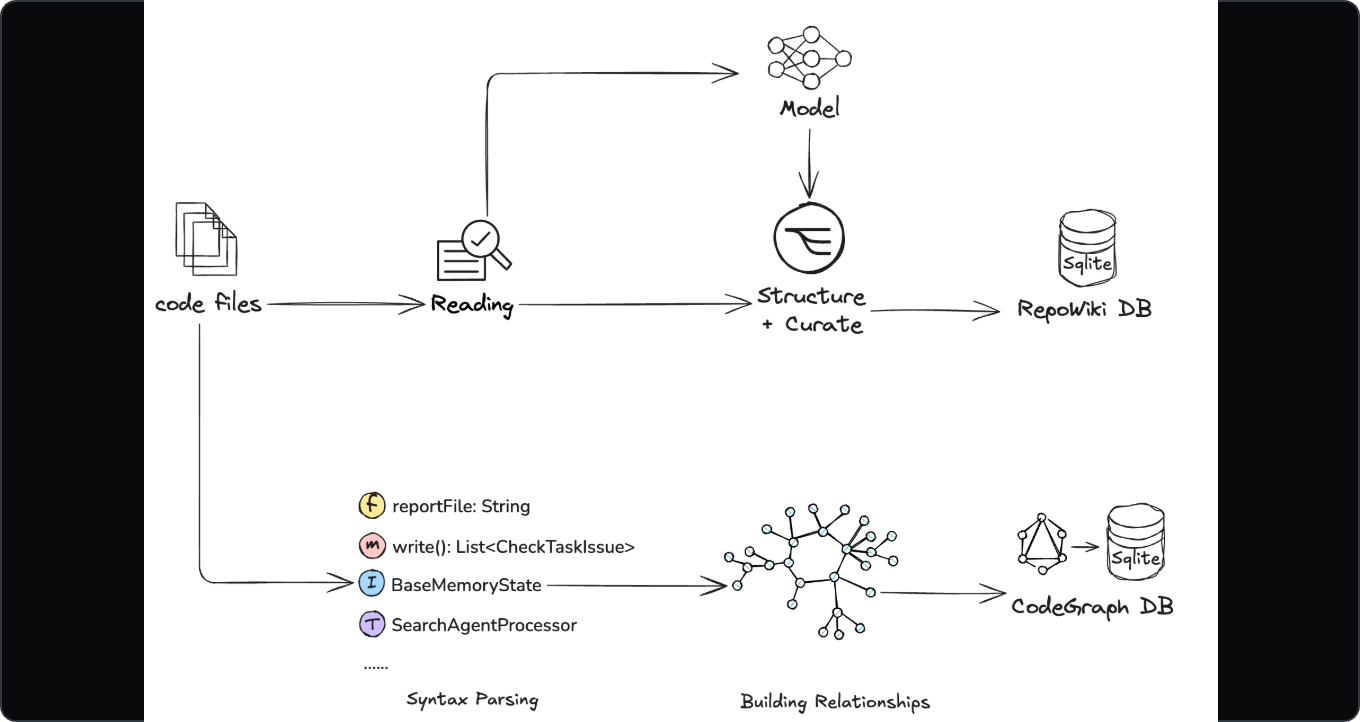
2)代码图谱 + 预索引知识(更懂“结构关系”)
客户端维护代码图(函数、类、模块,外加调用、继承、跨语言映射);
再把设计文档、架构图、内部 wiki 等做预索引;
查的时候可以超低延迟做图遍历/概念查找。
3)融合检索:向量 × 图谱,双信号重排
一次查询的流程可以是:
- 计算查询嵌入;
- 先跑向量检索拿 Top-N;
- 再用图谱扩展/收敛(把被调用者/调用点、相关配置、参考文档一起拉进来);
- 用相似度 × 结构相关性做融合重排。
好处是:能同时找回语义相近与结构强相关但文本不相似的内容(例如“调用点 ↔ 实现”)。
4)实时与个性化:跟着你的分支走
每个开发者有自己的个人索引:你切分支、批量替换、保存文件,客户端就秒级同步给服务器,向量与图都会跟上。
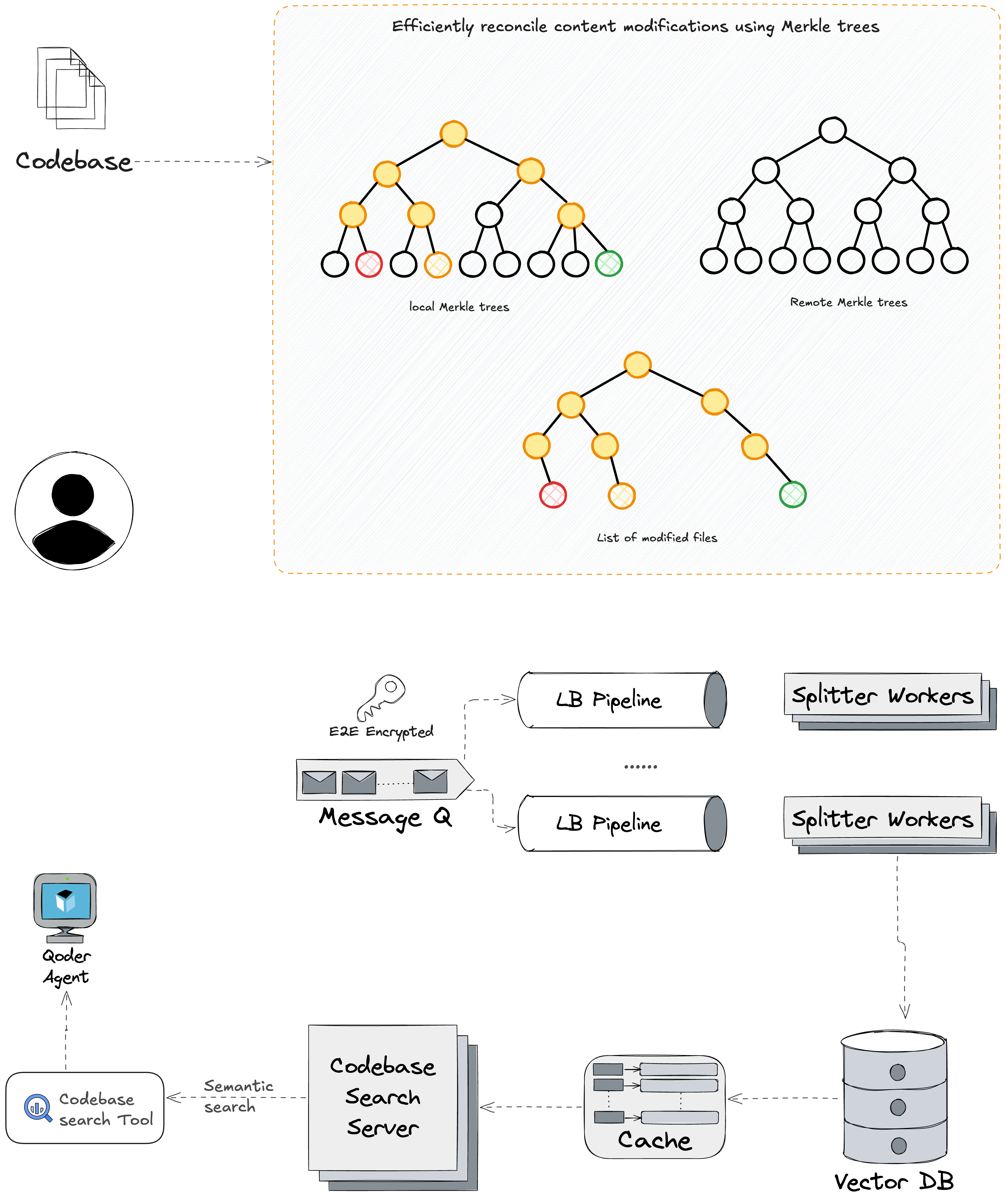
5)安全与隐私
- 不把原始代码上送第三方,嵌入计算与搜索都在自家基础设施;
- 通过加密哈希做内容证明;
- 嵌入传输+存储全加密。
典型应用场景
- 逛大仓库:不仅匹配“名字像”的定义,还顺着调用链/配置/设计文档给你拼全上下文。
- 应急排障:快速覆盖相关代码路径 / 测试 / Runbook,比纯全文检索更快收敛问题范围。
尾声
以上就是我(猫头虎)基于公开资料整理的一个非官方视角:
Qoder 把“AI 写代码”这件事进一步往工程化、可托管方向推了一步。
欢迎留言聊聊你关心的点:性能、插件生态、团队落地、还是和现有 IDE 的协同?也欢迎把你们的使用体验甩给我,后续我会继续跟进更新使用体验。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 6
6 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)