
人工智能开发工具全景指南:从编码辅助到模型部署的全流程实践
本文系统梳理了AI开发全流程工具链,涵盖智能编码、数据标注和模型训练三大核心领域。在智能编码方面,重点分析了GitHub Copilot等工具的自然语言转代码能力,通过PyTorch案例展示其应用效果;数据标注部分对比了LabelStudio、Prodigy等工具在图像、文本、语音标注中的实践方案;模型训练环节则解析了MLflow和AWSSageMaker两大平台在实验管理、超参优化方面的优势。
在人工智能技术高速迭代的当下,开发效率与模型性能的双重追求催生了品类繁多的 AI 工具生态。从开发者日常使用的智能编码助手,到支撑大规模数据处理的数据标注平台,再到简化模型构建流程的训练框架,每一类工具都在解决 AI 开发链路中的关键痛点。本文将以 “工具原理 - 核心功能 - 实战案例” 为脉络,深入剖析智能编码工具、数据标注工具、模型训练平台三大核心领域,并通过代码示例、Mermaid 流程图、Prompt 工程模板等形式,提供可落地的实践指南,帮助开发者系统性掌握 AI 开发全流程工具链。
一、智能编码工具:重构开发者的编码效率
智能编码工具通过自然语言处理(NLP)与代码理解技术,将开发者从重复性编码工作中解放,聚焦于逻辑设计与架构优化。其中,GitHub Copilot、Tabnine、CodeGeeX 等工具已成为主流选择,其核心能力体现在代码补全、函数生成、错误修复、文档生成四大维度。
1.1 核心技术原理:代码理解与生成的底层逻辑
智能编码工具的核心是基于代码预训练模型(Code Pre-trained Model),通过海量开源代码库(如 GitHub、GitLab)进行训练,学习编程语言的语法规则、逻辑结构、API 调用习惯甚至项目架构模式。其技术链路可通过以下流程图清晰呈现:
flowchart TD
A[数据采集] -->|GitHub/GitLab开源代码库| B[数据预处理]
B --> B1[代码去重与清洗]
B --> B2[语法树解析(AST)]
B --> B3[代码片段分割]
C[模型训练] -->|Transformer架构| C1[词嵌入层(Code Tokenization)]
C1 --> C2[编码器-解码器结构]
C2 --> C3[自监督学习(掩码预测/代码补全任务)]
D[推理优化] --> D1[上下文窗口压缩]
D1 --> D2[量化与剪枝]
D2 --> D3[实时响应优化]
E[工具集成] -->|IDE插件| E1[VS Code]
E[工具集成] --> E2[PyCharm]
E[工具集成] --> E3[IntelliJ IDEA]
F[用户交互] -->|输入代码/注释| F1[上下文理解]
F1 --> F2[代码生成]
F2 --> F3[错误修复/优化建议]
以 GitHub Copilot 为例,其底层模型基于 OpenAI 的 GPT 架构优化,专门针对代码场景进行训练,支持 Python、Java、JavaScript 等 40 + 编程语言,能根据开发者输入的代码前缀或自然语言注释,实时生成完整函数、类定义甚至测试代码。
1.2 实战案例:用 GitHub Copilot 实现图像分类数据加载
场景需求
在 PyTorch 项目中,需要实现一个自定义数据集类(CustomImageDataset),用于加载图像分类数据(目录结构为data/类名/图像文件),并支持数据增强(如随机裁剪、归一化)。
操作步骤
- 安装插件:在 VS Code 中安装 “GitHub Copilot” 插件,登录 GitHub 账号并授权。
- 输入自然语言注释:通过注释描述需求,Copilot 将自动识别并生成代码。
- 代码优化与调整:根据实际项目需求(如数据路径、图像尺寸)微调生成的代码。
完整代码与 Prompt 交互
python
运行
# 需求:基于PyTorch实现自定义图像分类数据集类
# 功能要求:
# 1. 从指定目录加载图像(目录结构:root/label/image.jpg)
# 2. 支持读取图像路径列表(csv文件,包含image_path和label两列)
# 3. 集成数据增强(训练集:随机裁剪、水平翻转;测试集:中心裁剪、归一化)
# 4. 支持返回图像张量(Tensor)和标签(int)
import os
import pandas as pd
from PIL import Image
from torch.utils.data import Dataset
from torchvision import transforms
class CustomImageDataset(Dataset):
def __init__(self, root_dir, csv_file, is_train=True, img_size=224):
"""
自定义图像分类数据集初始化函数
Args:
root_dir (str): 数据集根目录
csv_file (str): 包含图像路径和标签的CSV文件路径
is_train (bool): 是否为训练集(用于区分数据增强策略)
img_size (int): 图像resize后的尺寸
"""
# 加载CSV文件,获取图像路径和标签
self.data_info = pd.read_csv(csv_file)
self.image_paths = self.data_info['image_path'].apply(lambda x: os.path.join(root_dir, x)).tolist()
self.labels = self.data_info['label'].tolist()
self.is_train = is_train
self.img_size = img_size
# 定义数据增强策略(训练集与测试集区分)
if self.is_train:
self.transform = transforms.Compose([
transforms.RandomResizedCrop(self.img_size, scale=(0.8, 1.0)), # 随机裁剪
transforms.RandomHorizontalFlip(p=0.5), # 水平翻转
transforms.ToTensor(), # 转为Tensor
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 归一化(ImageNet参数)
])
else:
self.transform = transforms.Compose([
transforms.Resize((self.img_size + 32, self.img_size + 32)), # 先放大再中心裁剪
transforms.CenterCrop(self.img_size),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
def __len__(self):
"""返回数据集总样本数"""
return len(self.image_paths)
def __getitem__(self, idx):
"""根据索引获取单个样本(图像张量+标签)"""
# 读取图像
image_path = self.image_paths[idx]
image = Image.open(image_path).convert('RGB') # 确保图像为RGB格式
# 应用数据增强
image_tensor = self.transform(image)
# 获取标签
label = self.labels[idx]
return image_tensor, label
# 测试代码:创建数据集实例并验证
if __name__ == "__main__":
# 训练集实例
train_dataset = CustomImageDataset(
root_dir="./data/train",
csv_file="./data/train.csv",
is_train=True
)
# 测试集实例
test_dataset = CustomImageDataset(
root_dir="./data/test",
csv_file="./data/test.csv",
is_train=False
)
# 验证样本数量
print(f"训练集样本数:{len(train_dataset)}")
print(f"测试集样本数:{len(test_dataset)}")
# 验证单个样本格式
sample_img, sample_label = train_dataset[0]
print(f"图像张量形状:{sample_img.shape}") # 输出:torch.Size([3, 224, 224])
print(f"样本标签:{sample_label}")
关键优化点
- Copilot 初始生成的代码可能未区分训练集 / 测试集的数据增强,需手动补充
is_train参数的逻辑。 - 自动添加了
Image.open().convert('RGB'),避免灰度图像导致的通道数不匹配问题(Copilot 通过常见错误案例学习到的优化点)。 - 归一化参数默认使用 ImageNet 的均值和标准差,若为自定义数据集,需提示 Copilot 修改为数据集统计的均值 / 标准差(例如通过注释 “使用自定义数据集的均值 [0.5,0.5,0.5] 和标准差 [0.5,0.5,0.5]”)。
1.3 高级应用:Prompt 工程优化智能编码效果
智能编码工具的性能高度依赖Prompt 质量。通过清晰、结构化的 Prompt,可引导工具生成更符合需求的代码。以下是针对不同场景的 Prompt 模板:
| 应用场景 | Prompt 模板示例 | 工具响应效果 |
|---|---|---|
| 函数功能定义 | “用 Python 实现一个函数,输入为列表(元素为整数),输出为列表中所有质数的平方和,要求包含异常处理(如输入非列表时报错)” | 生成包含is_prime()辅助函数、try-except异常处理、测试用例的完整代码。 |
| 框架 API 调用 | “用 PyTorch Lightning 实现一个图像分类模型的 Trainer,要求:1. 使用 GPU 加速;2. 早停策略(验证集 loss 无下降时停止);3. 学习率调度器(余弦退火)” | 生成包含Trainer初始化、EarlyStopping回调、CosineAnnealingLR调度器的代码。 |
| 错误修复 | “以下 Python 代码报错:TypeError: unsupported operand type (s) for +: 'int' and'str',请修复并解释错误原因:python<br>num = 10<br>print("数量:" + num)<br>” |
修复为print("数量:" + str(num)),并解释 “错误原因是字符串与整数无法直接拼接,需通过 str () 转换类型”。 |
| 代码重构 | “将以下 Python 函数重构为面向对象风格,提取公共逻辑为父类,支持扩展不同的文件格式(当前仅支持 CSV,需预留 Excel 支持):python<br>def read_csv(file_path):<br> return pd.read_csv(file_path)<br>” |
生成FileReader父类、CsvReader子类,预留ExcelReader子类的接口,符合开闭原则。 |
1.4 主流智能编码工具对比
不同工具在语言支持、离线能力、自定义训练等维度存在差异,选择时需结合团队需求:
| 工具名称 | 核心优势 | 支持语言数量 | 离线使用 | 自定义训练 | 适用场景 |
|---|---|---|---|---|---|
| GitHub Copilot | 与 VS Code 深度集成,GPT 模型支持,开源代码训练 | 40+ | 否 | 否 | 个人开发者、中小型团队 |
| Tabnine | 支持多 IDE,团队共享代码风格,隐私保护好 | 20+ | 是(企业版) | 是(企业版) | 大型团队、对代码隐私敏感 |
| CodeGeeX | 国产工具,支持中文注释,开源可本地部署 | 10+ | 是(本地部署) | 是 | 国内团队、需本地化部署 |
| Amazon CodeWhisperer | 与 AWS 服务集成,免费版支持个人开发者 | 30+ | 否 | 否 | 基于 AWS 的云开发项目 |
二、数据标注工具:AI 模型的 “燃料制造工厂”
高质量标注数据是模型性能的核心保障。数据标注工具通过可视化界面、自动化辅助功能,降低人工标注成本,提升标注一致性。根据数据类型,可分为图像标注(目标检测、语义分割)、文本标注(命名实体识别、情感分析)、语音标注(语音转文字、情感分类)三大类。
2.1 图像标注工具:LabelStudio 实战(目标检测 + 语义分割)
LabelStudio 是目前最流行的开源标注工具,支持多模态数据,可通过配置文件自定义标注任务,且提供 API 接口与模型训练流程联动。
1. 工具部署与初始化
通过 Docker 快速部署 LabelStudio(避免环境依赖问题):
bash
# 拉取LabelStudio镜像
docker pull heartexlabs/label-studio:latest
# 启动容器(映射本地数据目录./data到容器内)
docker run -it -p 8080:8080 -v $(pwd)/data:/label-studio/data heartexlabs/label-studio:latest
访问http://localhost:8080,创建账号并新建项目(例如 “交通场景目标检测”)。
2. 标注任务配置(目标检测)
在项目设置中,选择 “Object Detection” 模板,自定义标注标签(如 “car”“pedestrian”“traffic_light”),配置文件如下(JSON 格式):
json
{
"label_config": "<View>\n <Image name=\"image\" value=\"$image\"/>\n <RectangleLabels name=\"label\" toName=\"image\">\n <Label value=\"car\" background=\"#FF0000\"/>\n <Label value=\"pedestrian\" background=\"#00FF00\"/>\n <Label value=\"traffic_light\" background=\"#0000FF\"/>\n </RectangleLabels>\n</View>"
}
3. 数据导入与标注
- 数据导入:支持本地文件上传、URL 导入、AWS S3/GCP 云存储接入,此处选择上传 100 张交通场景图像。
- 标注操作:
- 选择左侧标签(如 “car”),在图像中拖动鼠标绘制矩形框,框选车辆目标。
- 对每张图像的所有目标完成标注后,点击 “Submit” 提交。
- 标注完成后,导出标注结果为 COCO 格式(AI 模型训练常用格式)。
4. 自动化标注辅助(模型预标注)
LabelStudio 支持接入预训练模型生成初始标注,减少人工工作量。以 YOLOv8 为例,通过 API 将模型预测结果导入 LabelStudio:
python
运行
import requests
import json
from ultralytics import YOLO
# 1. 加载YOLOv8预训练模型
model = YOLO('yolov8n.pt') # 轻量化模型,适合快速推理
# 2. 对单张图像进行预测
image_path = "./data/traffic_001.jpg"
results = model(image_path) # 预测结果
# 3. 转换预测结果为LabelStudio格式
labelstudio_annot = {
"data": {"image": "traffic_001.jpg"},
"predictions": [
{
"result": [
{
"from_name": "label",
"to_name": "image",
"type": "rectanglelabels",
"value": {
"x": box[0] / image_width * 100, # 转换为百分比坐标
"y": box[1] / image_height * 100,
"width": (box[2] - box[0]) / image_width * 100,
"height": (box[3] - box[1]) / image_height * 100,
"labels": [model.names[int(cls)]] # 标签名称
},
"score": conf # 预测置信度
}
for box, cls, conf in zip(results[0].boxes.xyxy, results[0].boxes.cls, results[0].boxes.conf)
if model.names[int(cls)] in ["car", "pedestrian", "traffic_light"] # 过滤无关标签
],
"model_version": "yolov8n_v1"
}
]
}
# 4. 通过LabelStudio API导入预标注结果
API_URL = "http://localhost:8080/api/projects/1/tasks/import" # 项目ID为1
HEADERS = {"Authorization": "Token YOUR_LABELSTUDIO_TOKEN", "Content-Type": "application/json"}
response = requests.post(API_URL, data=json.dumps([labelstudio_annot]), headers=HEADERS)
print(f"预标注导入结果:{response.status_code}") # 201表示成功
5. 标注质量检查
LabelStudio 提供两种质量检查方式:
- 人工审核:设置 “审核员” 角色,对标注员的结果进行抽查(建议抽查比例 10%-20%)。
- 自动检查:通过配置 “标注规则”(如 “每张图像至少标注 3 个目标”“矩形框不能超出图像边界”),自动筛选异常标注。
2.2 文本标注工具:Brat 与 Prodigy 对比
文本标注常见任务包括命名实体识别(NER)、关系抽取、文本分类,以下是两款主流工具的实践对比:
1. Brat(开源免费,适合学术研究)
2. Prodigy(商业工具,适合工业级标注)
Prodigy 是由 spaCy 团队开发的商业文本标注工具,主打 “高效标注 + 模型迭代” 闭环,支持通过 Python 脚本自定义标注逻辑。
3. 工具对比总结
| 对比维度 | Brat(开源) | Prodigy(商业) | 适用场景 |
|---|---|---|---|
| 成本 | 免费 | 付费(按用户 / 团队收费) | 学术研究 / 小团队 vs 企业级 |
| 自动化标注 | 无 | 支持(集成 spaCy/Transformers 模型) | 低效率手动标注 vs 高效标注 |
| 数据导出格式 | 专属.ann 格式(需转换) | 支持 JSONL/spaCy/PyTorch 等多格式 | 需二次处理 vs 直接训练 |
| 自定义能力 | 仅支持实体 / 关系类型定义 | 支持 Python 脚本自定义标注逻辑 | 简单任务 vs 复杂任务 |
| 协作功能 | 无(仅本地单用户) | 支持团队协作、标注进度统计 | 个人标注 vs 团队标注 |
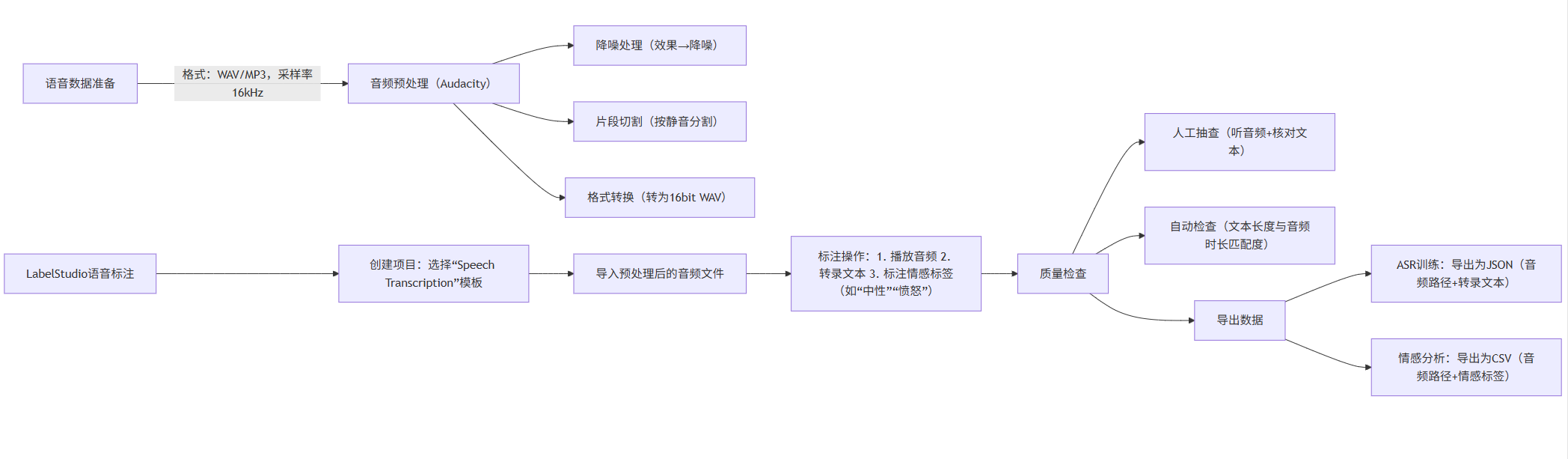
2.3 语音标注工具:Audacity+LabelStudio 组合方案
语音标注主要用于语音识别(ASR)、语音情感分析、说话人分离等任务,核心是 “音频片段切割 + 文本转录 / 标签标注”。由于纯语音标注工具功能单一,推荐使用 “Audacity(音频处理)+ LabelStudio(标注)” 的组合方案。
1. 流程设计(Mermaid 流程图)
flowchart LR
A[语音数据准备] -->|格式:WAV/MP3,采样率16kHz| B[音频预处理(Audacity)]
B --> B1[降噪处理(效果→降噪)]
B --> B2[片段切割(按静音分割)]
B --> B3[格式转换(转为16bit WAV)]
C[LabelStudio语音标注] --> C1[创建项目:选择“Speech Transcription”模板]
C1 --> C2[导入预处理后的音频文件]
C2 --> C3[标注操作:1. 播放音频 2. 转录文本 3. 标注情感标签(如“中性”“愤怒”)]
C3 --> D[质量检查]
D --> D1[人工抽查(听音频+核对文本)]
D --> D2[自动检查(文本长度与音频时长匹配度)]
D --> E[导出数据]
E --> E1[ASR训练:导出为JSON(音频路径+转录文本)]
E --> E2[情感分析:导出为CSV(音频路径+情感标签)]
2. 实战操作步骤
python
运行
import argparse
import mlflow
import mlflow.pytorch
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from sklearn.metrics import accuracy_score
from utils.dataset import CustomImageDataset
from utils.model import ResNet18 # 自定义ResNet18模型
def train(args):
# 1. 初始化MLflow实验
mlflow.set_experiment("Image_Classification_ResNet18") # 定义实验名称
with mlflow.start_run(run_name=f"lr_{args.lr}_batch_{args.batch_size}"): # 定义运行名称(含关键参数)
# 2. 记录训练参数(超参、数据路径等)
mlflow.log_param("learning_rate", args.lr)
mlflow.log_param("batch_size", args.batch_size)
mlflow.log_param("epochs", args.epochs)
mlflow.log_param("img_size", args.img_size)
mlflow.log_param("train_data_path", args.train_csv)
mlflow.log_param("test_data_path", args.test_csv)
# 3. 加载数据
train_dataset = CustomImageDataset(
root_dir=args.data_root,
csv_file=args.train_csv,
is_train=True,
img_size=args.img_size
)
test_dataset = CustomImageDataset(
root_dir=args.data_root,
csv_file=args.test_csv,
is_train=False,
img_size=args.img_size
)
train_loader = DataLoader(train_dataset, batch_size=args.batch_size, shuffle=True, num_workers=4)
test_loader = DataLoader(test_dataset, batch_size=args.batch_size, shuffle=False, num_workers=4)
# 4. 初始化模型、损失函数、优化器
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = ResNet18(num_classes=args.num_classes).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=args.lr)
# 5. 训练循环
for epoch in range(args.epochs):
model.train()
train_loss = 0.0
train_preds = []
train_labels = []
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
# 前向传播
outputs = model(images)
loss = criterion(outputs, labels)
# 反向传播与优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 记录训练损失和预测结果
train_loss += loss.item() * images.size(0)
_, preds = torch.max(outputs, 1)
train_preds.extend(preds.cpu().numpy())
三、模型训练平台:从代码到模型的自动化流水线
模型训练是 AI 开发的核心环节,涉及数据加载、模型构建、训练调度、超参优化等复杂流程。传统本地训练存在 “环境不一致、资源利用率低、缺乏监控” 等问题,而模型训练平台通过 “容器化 + 分布式” 技术,实现了训练流程的标准化与高效化。主流平台可分为云平台(如 AWS SageMaker、阿里云 PAI)和开源平台(如 MLflow、Kubeflow)两类。
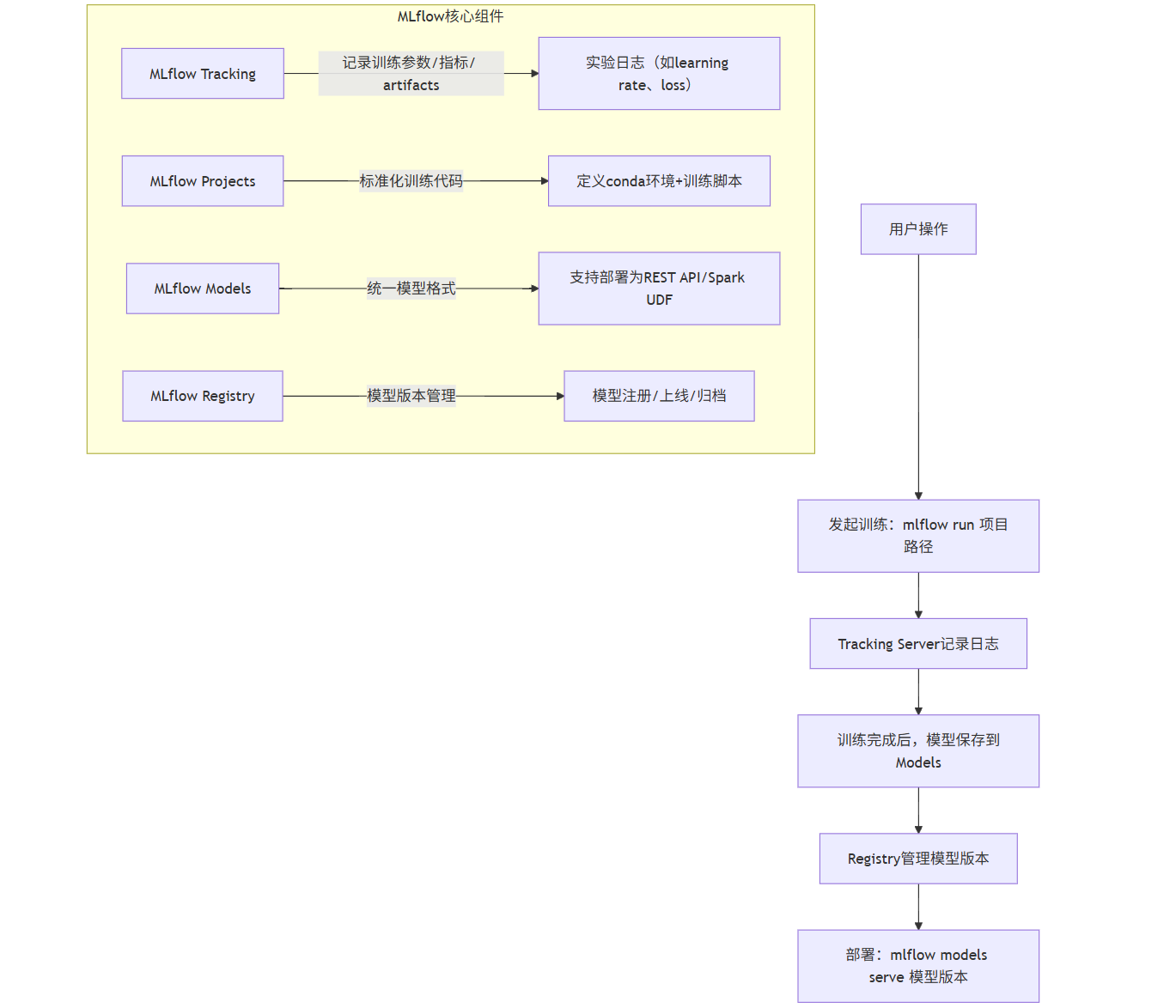
3.1 开源平台:MLflow 实战(模型生命周期管理)
MLflow 是 Databricks 开源的模型训练平台,核心解决 “训练过程可追溯、模型版本管理、跨环境部署” 三大问题,支持 PyTorch、TensorFlow、Scikit-learn 等主流框架。
1. MLflow 核心组件(Mermaid 架构图)
flowchart TB
subgraph MLflow核心组件
A[MLflow Tracking] -->|记录训练参数/指标/ artifacts| A1[实验日志(如learning rate、loss)]
B[MLflow Projects] -->|标准化训练代码| B1[定义conda环境+训练脚本]
C[MLflow Models] -->|统一模型格式| C1[支持部署为REST API/Spark UDF]
D[MLflow Registry] -->|模型版本管理| D1[模型注册/上线/归档]
end
E[用户操作] --> E1[发起训练:mlflow run 项目路径]
E1 --> F[Tracking Server记录日志]
F --> G[训练完成后,模型保存到Models]
G --> H[Registry管理模型版本]
H --> I[部署:mlflow models serve 模型版本]
2. 实战:用 MLflow 训练图像分类模型(PyTorch)
步骤 1:项目结构设计(标准化 MLflow Projects 格式)
plaintext
image_classification/
├── conda.yaml # 定义训练环境依赖
├── train.py # 训练脚本(集成MLflow Tracking)
└── utils/
├── dataset.py # 数据集加载(复用第一章的CustomImageDataset)
└── model.py # 模型定义(ResNet18)
步骤 2:定义 conda 环境(conda.yaml)
yaml
name: image_cls_env
channels:
- defaults
- pytorch
dependencies:
- python=3.9
- pytorch=2.0.1
- torchvision=0.15.2
- pandas=2.0.3
- pillow=10.0.0
- mlflow=2.6.0
- scikit-learn=1.3.0
步骤 3:训练脚本(train.py,集成 MLflow Tracking)
- 部署命令:
bash
# 安装依赖 sudo apt-get install python3 python3-pip pip3 install django==1.11 # 下载并启动 wget https://github.com/nlplab/brat/archive/refs/tags/v1.3.11.zip unzip v1.3.11.zip && cd brat-1.3.11 ./install.sh # 设置管理员账号密码 python3 standalone.py # 启动服务,访问http://localhost:80012.2 文本标注工具:Brat 与 Prodigy 对比
文本标注常见任务包括命名实体识别(NER)、关系抽取、文本分类,以下是两款主流工具的实践对比:
1. Brat(开源免费,适合学术研究)
- 部署命令:
bash
# 安装依赖(Ubuntu系统为例) sudo apt-get install python3 python3-pip pip3 install django==1.11 # Brat依赖特定Django版本 # 下载并解压Brat wget https://github.com/nlplab/brat/archive/refs/tags/v1.3.11.zip unzip v1.3.11.zip && cd brat-1.3.11 ./install.sh # 执行安装脚本,按提示设置管理员账号和密码 python3 standalone.py # 启动独立服务,默认端口8001 - NER 标注示例:
- 新建文本文件
news.txt,内容为 “苹果公司在 2023 年推出了 iPhone 15,售价 5999 元,首发地区包括中国、美国和日本”。 - 在 Brat 界面点击 “Create”,上传
news.txt并创建标注任务,定义实体类型:ORG(机构):如 “苹果公司”DATE(日期):如 “2023 年”PRODUCT(产品):如 “iPhone 15”PRICE(价格):如 “5999 元”LOCATION(地点):如 “中国”“美国”“日本”
- 标注操作:选中文本片段(如 “苹果公司”),点击右侧
ORG标签,系统自动为该片段添加实体标注,最终生成标注文件news.ann(Brat 专属格式),内容如下:plaintext
T1 ORG 0 4 苹果公司 T2 DATE 6 10 2023年 T3 PRODUCT 13 21 iPhone 15 T4 PRICE 24 28 5999元 T5 LOCATION 34 36 中国 T6 LOCATION 38 40 美国 T7 LOCATION 43 45 日本
- 新建文本文件
- 优缺点:
- 优点:完全开源、无成本、支持自定义实体类型和关系标注,适合小样本学术实验。
- 缺点:不支持批量标注、无自动化预标注功能、界面较简陋,不适合工业级大规模标注。
-
安装与激活:
bash
# 安装Prodigy(需购买许可证获取安装包) pip install prodigy-1.11.10-cp39-none-manylinux1_x86_64.whl # 激活许可证 prodigy status -l YOUR_LICENSE_KEY -
NER 标注实战(带预标注):
- 准备预训练模型:使用 spaCy 的预训练模型(如
en_core_web_sm)生成初始标注,减少人工工作量:python
运行
# prodigy_ner_preannotate.py import spacy from prodigy.components.loaders import JSONL from prodigy.util import write_jsonl # 加载spaCy预训练模型 nlp = spacy.load("en_core_web_sm") # 英文模型,中文可使用"zh_core_web_sm" # 读取原始文本数据(JSONL格式,每行一条{"text": "文本内容"}) stream = JSONL("./news_data.jsonl") # 生成预标注结果 pre_annotated = [] for example in stream: doc = nlp(example["text"]) # 提取实体标注(转换为Prodigy格式) spans = [ { "start": ent.start_char, "end": ent.end_char, "label": ent.label_ # 模型预测的实体类型(如ORG、DATE) } for ent in doc.ents ] pre_annotated.append({"text": example["text"], "spans": spans}) # 保存预标注结果到JSONL文件 write_jsonl("./pre_annotated_news.jsonl", pre_annotated) - 启动标注界面:通过命令行启动 Prodigy,加载预标注数据:
bash
prodigy ner.manual news_ner_dataset ./pre_annotated_news.jsonl --label ORG,DATE,PRODUCT,PRICE,LOCATION - 标注优化:
- 标注员只需确认 / 修改预标注结果(如模型误将 “iPhone 15” 标注为
ORG,手动改为PRODUCT)。 - 支持快捷键操作(如
A确认、R拒绝、F添加新实体),标注效率比 Brat 提升 3-5 倍。
- 标注员只需确认 / 修改预标注结果(如模型误将 “iPhone 15” 标注为
- 导出训练数据:标注完成后,导出为 spaCy 训练格式,直接用于模型微调:
bash
prodigy data-to-spacy ./spacy_ner_data --ner news_ner_dataset
- 准备预训练模型:使用 spaCy 的预训练模型(如
-
优缺点:
- 优点:支持预标注、批量处理、自定义脚本、与 spaCy 模型无缝衔接,适合企业级大规模标注;标注数据可直接用于模型训练,形成 “标注 - 训练 - 再标注” 的迭代闭环。
- 缺点:商业工具(单用户许可证约 1000 美元 / 年)、需一定 Python 编程基础,入门门槛较高。
-
音频预处理(Audacity):
- 打开 Audacity,导入原始语音文件(如
customer_service.wav)。 - 降噪:选中静音片段(无语音的部分),点击 “效果→降噪→获取噪声特征”,再全选音频执行降噪。
- 分割:点击 “分析→按静音分割”,系统自动根据静音间隔将长音频切割为短片段(如每段 3-5 秒,适合标注)。
- 导出:选中所有片段,点击 “文件→导出→导出多个”,选择格式为 “WAV(微软)”,采样率设为 16kHz(ASR 模型常用采样率)。
- 打开 Audacity,导入原始语音文件(如
-
LabelStudio 语音标注:
- 新建项目,选择 “Speech Transcription” 模板,配置标注标签(如情感标签:“中性”“满意”“不满”)。
- 导入 Audacity 处理后的短音频片段,进入标注界面:
- 左侧:音频播放器(支持暂停、倍速播放)。
- 中间:文本输入框(转录音频中的语音内容,如 “您好,我想咨询订单退款问题”)。
- 右侧:标签选择区(选择该段语音的情感标签,如 “中性”)。
- 标注完成后,导出数据为 JSON 格式,示例如下:
json
[ { "id": 1, "data": { "audio": "audio/segment_1.wav", "text": "您好,我想咨询订单退款问题" }, "annotations": [ { "result": [ { "from_name": "transcription", "to_name": "audio", "type": "textarea", "value": { "text": ["您好,我想咨询订单退款问题"] } }, { "from_name": "label", "to_name": "audio", "type": "labels", "value": { "labels": ["中性"] } } ] } ] } ]
-
数据格式转换(用于 ASR 训练):
将 LabelStudio 导出的 JSON 转换为 ASR 模型(如 Whisper)的训练格式,通过 Python 脚本实现:python
运行
import json import csv # 读取LabelStudio导出的JSON文件 with open("./speech_annotations.json", "r", encoding="utf-8") as f: data = json.load(f) # 转换为CSV格式(音频路径, 转录文本) with open("./asr_train_data.csv", "w", encoding="utf-8", newline="") as f: writer = csv.writer(f) writer.writerow(["audio_path", "transcription"]) for item in data: audio_path = item["data"]["audio"] # 提取转录文本 transcription = item["annotations"][0]["result"][0]["value"]["text"][0] writer.writerow([audio_path, transcription]) print(f"成功转换{len(data)}条ASR训练数据")
train_labels.extend(labels.cpu().numpy())
计算训练集指标
train_epoch_loss = train_loss / len(train_dataset)
train_acc = accuracy_score(train_labels, train_preds)
在测试集上验证
model.eval()
test_loss = 0.0
test_preds = []
test_labels = []
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
test_loss += loss.item() * images.size(0)
_, preds = torch.max(outputs, 1)
test_preds.extend(preds.cpu().numpy())
test_labels.extend(labels.cpu().numpy())
test_epoch_loss = test_loss / len(test_dataset)
test_acc = accuracy_score(test_labels, test_preds)
6. 记录训练指标(MLflow Tracking 核心功能)
mlflow.log_metric("train_loss", train_epoch_loss, step=epoch)
mlflow.log_metric("train_accuracy", train_acc, step=epoch)
mlflow.log_metric("test_loss", test_epoch_loss, step=epoch)
mlflow.log_metric("test_accuracy", test_acc, step=epoch)
print(f"Epoch {epoch+1}/{args.epochs}")
print(f"Train Loss: {train_epoch_loss:.4f}, Acc: {train_acc:.4f}")
print(f"Test Loss: {test_epoch_loss:.4f}, Acc: {test_acc:.4f}\n")
7. 保存模型到 MLflow(支持后续部署)
mlflow.pytorch.log_model(model, "model")
8. 记录额外 artifacts(如训练日志、混淆矩阵)
with open ("training_logs.txt", "w") as f:
f.write (f"Final Test Accuracy: {test_acc:.4f}\n")
f.write (f"Best Hyperparameters: lr={args.lr}, batch_size={args.batch_size}")
mlflow.log_artifact ("training_logs.txt") # 上传文件到 MLflow 服务器
if name == "main":
解析命令行参数(方便通过 MLflow 调整超参)
parser = argparse.ArgumentParser(description="ResNet18 Image Classification with MLflow")
parser.add_argument("--data_root", type=str, default="./data", help="Dataset root directory")
parser.add_argument("--train_csv", type=str, default="./data/train.csv", help="Train CSV path")
parser.add_argument("--test_csv", type=str, default="./data/test.csv", help="Test CSV path")
parser.add_argument("--num_classes", type=int, default=10, help="Number of classes")
parser.add_argument("--img_size", type=int, default=224, help="Image size")
parser.add_argument("--batch_size", type=int, default=32, help="Batch size")
parser.add_argument("--lr", type=float, default=0.001, help="Learning rate")
parser.add_argument("--epochs", type=int, default=20, help="Number of epochs")
args = parser.parse_args()
train(args)
plaintext
##### 步骤4:启动MLflow服务并运行训练
```bash
# 启动MLflow Tracking Server(默认存储在当前目录mlruns文件夹)
mlflow server --host 0.0.0.0 --port 5000
# 打开新终端,运行训练(通过--params指定超参)
mlflow run ./image_classification \
-P lr=0.0005 \
-P batch_size=64 \
-P epochs=30
步骤 5:查看训练结果(MLflow UI)
访问http://localhost:5000,可看到实验 dashboard,包含:
- 参数对比:不同学习率、批次大小对应的模型性能。
- 指标可视化:训练 / 测试损失、准确率的折线图。
- 模型版本:保存的 ResNet18 模型,支持下载或直接部署。
3.2 云平台:AWS SageMaker 自动模型调优
AWS SageMaker 是亚马逊提供的全托管 AI 平台,支持从数据预处理到模型部署的全流程,其核心优势在于自动模型调优(Hyperparameter Tuning) 和弹性计算资源(按需使用 GPU/TPU)。
1. 自动调优流程(Mermaid 流程图)
flowchart LR
A[定义训练脚本] -->|兼容SageMaker的entry_point| B[配置超参搜索空间]
B --> B1[连续参数:learning_rate ∈ [0.0001, 0.1]]
B --> B2[离散参数:batch_size ∈ [32, 64, 128]]
B --> B3[ categorical参数:optimizer ∈ ["adam", "sgd"]]
C[设置调优策略] --> C1[贝叶斯优化(适合小样本)]
C --> C2[随机搜索(适合大搜索空间)]
D[启动调优任务] -->|指定最大训练次数(如50次)| E[SageMaker自动分配计算资源]
E --> F[并行训练多个模型(根据资源限制)]
F --> G[评估模型性能(如验证集准确率)]
G --> H[更新搜索空间,迭代调优]
H --> I[找到最优超参组合]
I --> J[用最优超参训练最终模型]
2. 实战:用 SageMaker 调优文本分类模型
步骤 1:准备训练脚本(train_sagemaker.py)
与本地脚本的区别在于:
- 输入 / 输出路径需从环境变量获取(SageMaker 自动设置)。
- 模型需保存到指定目录(
/opt/ml/model)。
python
运行
import os
import argparse
import torch
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from transformers import BertTokenizer, BertForSequenceClassification, Trainer, TrainingArguments
def load_data(data_dir):
"""加载SageMaker通道中的数据(train和validation)"""
train_df = pd.read_csv(os.path.join(data_dir, "train.csv"))
val_df = pd.read_csv(os.path.join(data_dir, "validation.csv"))
return train_df, val_df
def tokenize_function(examples, tokenizer, max_length=128):
"""文本分词处理"""
return tokenizer(
examples["text"],
padding="max_length",
truncation=True,
max_length=max_length
)
def main():
parser = argparse.ArgumentParser()
# SageMaker默认参数(固定写法)
parser.add_argument("--model_dir", type=str, default=os.environ.get("SM_MODEL_DIR"))
parser.add_argument("--train", type=str, default=os.environ.get("SM_CHANNEL_TRAIN"))
parser.add_argument("--validation", type=str, default=os.environ.get("SM_CHANNEL_VALIDATION"))
# 自定义超参(需在调优任务中指定搜索范围)
parser.add_argument("--learning_rate", type=float, default=5e-5)
parser.add_argument("--epochs", type=int, default=3)
parser.add_argument("--batch_size", type=int, default=16)
parser.add_argument("--max_length", type=int, default=128)
args = parser.parse_args()
# 加载数据
train_df, val_df = load_data(args.train)
val_df, test_df = train_test_split(val_df, test_size=0.5, random_state=42)
# 加载预训练模型和分词器
model_name = "bert-base-uncased"
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertForSequenceClassification.from_pretrained(
model_name,
num_labels=len(train_df["label"].unique())
)
# 数据预处理
train_encodings = tokenize_function(train_df, tokenizer, args.max_length)
val_encodings = tokenize_function(val_df, tokenizer, args.max_length)
# 转换为Dataset格式
class TextDataset(torch.utils.data.Dataset):
def __init__(self, encodings, labels):
self.encodings = encodings
self.labels = labels
def __getitem__(self, idx):
item = {k: torch.tensor(v[idx]) for k, v in self.encodings.items()}
item["labels"] = torch.tensor(self.labels[idx])
return item
def __len__(self):
return len(self.labels)
train_dataset = TextDataset(train_encodings, train_df["label"].tolist())
val_dataset = TextDataset(val_encodings, val_df["label"].tolist())
# 定义评估指标
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = logits.argmax(axis=-1)
return {"accuracy": accuracy_score(labels, predictions)}
# 设置训练参数
training_args = TrainingArguments(
output_dir="/opt/ml/output",
num_train_epochs=args.epochs,
per_device_train_batch_size=args.batch_size,
per_device_eval_batch_size=args.batch_size,
evaluation_strategy="epoch",
save_strategy="epoch",
learning_rate=args.learning_rate,
weight_decay=0.01,
logging_dir="/opt/ml/output/logs",
)
# 训练模型
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
compute_metrics=compute_metrics
)
trainer.train()
# 保存模型到SageMaker指定目录(用于后续部署)
model.save_pretrained(args.model_dir)
tokenizer.save_pretrained(args.model_dir)
if __name__ == "__main__":
main()
步骤 2:配置超参调优任务(Python SDK)
python
运行
import sagemaker
from sagemaker.pytorch import PyTorch
from sagemaker.tuner import (
IntegerParameter,
ContinuousParameter,
CategoricalParameter,
HyperparameterTuner,
)
# 初始化SageMaker会话
sagemaker_session = sagemaker.Session()
role = sagemaker.get_execution_role() # 需提前配置AWS权限
# 定义训练容器(使用PyTorch框架,指定Python版本)
estimator = PyTorch(
entry_point="train_sagemaker.py", # 训练脚本
role=role,
framework_version="1.13.1",
py_version="py39",
instance_count=1,
instance_type="ml.g4dn.xlarge", # 带GPU的实例
hyperparameters={
"epochs": 5, # 固定超参
"max_length": 128
}
)
# 定义超参搜索空间
hyperparameter_ranges = {
"learning_rate": ContinuousParameter(1e-5, 5e-5), # 连续参数
"batch_size": CategoricalParameter([16, 32, 64]), # 离散参数
}
# 定义调优目标(最大化验证集准确率)
objective_metric_name = "eval_accuracy"
objective_type = "Maximize"
metric_definitions = [{"Name": objective_metric_name, "Regex": "eval_accuracy = ([0-9\\.]+)"}]
# 创建调优器
tuner = HyperparameterTuner(
estimator,
objective_metric_name,
hyperparameter_ranges,
metric_definitions,
objective_type=objective_type,
max_jobs=20, # 最大训练次数
max_parallel_jobs=3, # 并行训练数(受限于资源)
strategy="Bayesian" # 贝叶斯优化策略
)
# 启动调优任务(数据存储在S3)
tuner.fit({
"train": "s3://your-bucket/text-classification/train/",
"validation": "s3://your-bucket/text-classification/validation/"
})
# 等待调优完成后,获取最优模型
best_estimator = tuner.best_estimator()
步骤 3:部署最优模型为 API 服务
python
运行
# 将最优模型部署为REST API(使用ml.m5.xlarge实例)
predictor = best_estimator.deploy(
initial_instance_count=1,
instance_type="ml.m5.xlarge"
)
# 测试API
test_text = "This product exceeds my expectations, highly recommended!"
inputs = tokenizer(test_text, return_tensors="pt", padding=True, truncation=True)
# 转换为SageMaker predictor可接受的格式
payload = {
"inputs": inputs["input_ids"].numpy().tolist(),
"attention_mask": inputs["attention_mask"].numpy().tolist()
}
response = predictor.predict(payload)
print(f"预测结果:{response}") # 输出情感分类结果(如"positive")
3.3 开源 vs 云平台:选择策略
| 维度 | 开源平台(MLflow/Kubeflow) | 云平台(AWS SageMaker / 阿里云 PAI) | 决策建议 |
|---|---|---|---|
| 成本 | 免费(需自建服务器) | 按需付费(计算资源 + 存储) | 小团队 / 学术研究选开源;企业级选云平台 |
| 维护成本 | 需手动维护服务器、监控系统 | 全托管,无需关注基础设施 | 无运维团队选云平台 |
| 灵活性 | 可深度自定义(如集成私有硬件) | 受限于平台 API,自定义能力弱 | 需定制化流程选开源 |
| 扩展性 | 需手动扩展集群 | 自动弹性扩展(支持上万节点分布式训练) | 超大规模训练(如千亿参数模型)选云平台 |
| 生态集成 | 需手动对接存储 / 计算服务 | 无缝集成云厂商生态(如 S3 存储、IAM 权限) | 已使用云服务的团队优先选对应厂商平台 |
四、AI 工具链协同:构建端到端开发闭环
单一工具难以覆盖 AI 开发全流程,需通过工具链协同实现 “数据标注→模型训练→部署监控” 的无缝衔接。以下以 “智能客服意图识别系统” 为例,展示工具链协同的完整实践。
4.1 项目流程设计(Mermaid 流程图)
flowchart LR
subgraph 数据层
A[原始对话数据] --> B[Prodigy文本标注]
B --> B1[标注意图标签(如“查询订单”“投诉”)]
B1 --> C[生成训练数据(JSONL格式)]
end
subgraph 训练层
C --> D[MLflow实验管理]
D --> D1[用BERT微调意图识别模型]
D1 --> D2[记录超参/指标(准确率92%)]
D2 --> E[模型注册到MLflow Registry]
end
subgraph 部署层
E --> F[AWS SageMaker部署]
F --> F1[生成REST API服务]
F1 --> F2[集成到客服系统]
end
subgraph 监控层
F2 --> G[Prometheus监控]
G --> G1[实时跟踪API响应时间/准确率]
G1 --> G2[低于阈值时触发告警]
G2 --> H[人工介入:重新标注数据/微调模型]
H --> B[回到标注环节,形成闭环]
end

4.2 关键协同点实现
1. 数据标注与训练的协同(Prodigy→MLflow)
通过 Python 脚本将 Prodigy 标注数据转换为 MLflow 训练格式:
python
运行
import json
from prodigy.components.db import connect
# 从Prodigy数据库导出标注数据
db = connect()
dataset = db.get_dataset("intent_classification") # 数据集名称
# 转换为MLflow训练所需的JSONL格式
train_data = []
for item in dataset:
train_data.append({
"text": item["text"],
"label": item["accept"][0] # 标注的意图标签
})
# 保存为训练文件
with open("./intent_train.jsonl", "w") as f:
for entry in train_data:
f.write(json.dumps(entry) + "\n")
# 调用MLflow API启动训练
import mlflow
mlflow.run(
uri="./intent_training", # 训练项目路径
parameters={"train_data": "./intent_train.jsonl", "epochs": 10}
)
2. 训练与部署的协同(MLflow→SageMaker)
将 MLflow 中注册的模型部署到 SageMaker:
python
运行
import mlflow
import boto3
from sagemaker.mlflow.model import MLflowModel
# 从MLflow Registry获取模型
model_uri = "models:/intent_model/production" # 生产环境模型
local_model_path = mlflow.artifacts.download_artifacts(artifact_uri=model_uri)
# 上传模型到S3
s3_client = boto3.client("s3")
s3_client.upload_file(
Filename=f"{local_model_path}/model.pth",
Bucket="your-sagemaker-bucket",
Key="intent-model/model.pth"
)
# 部署到SageMaker
mlflow_model = MLflowModel(
model_data="s3://your-sagemaker-bucket/intent-model/model.pth",
role="arn:aws:iam::1234567890:role/sagemaker-role",
framework_version="1.13.1",
py_version="py39"
)
predictor = mlflow_model.deploy(
initial_instance_count=1,
instance_type="ml.m5.large"
)
3. 部署与监控的协同(SageMaker→Prometheus)
通过 SageMaker 自带的监控功能结合 Prometheus,实时跟踪模型性能:
yaml
# prometheus.yml配置(监控SageMaker端点)
scrape_configs:
- job_name: 'sagemaker-endpoints'
metrics_path: '/metrics'
scrape_interval: 5s
static_configs:
- targets: ['your-sagemaker-endpoint-dns:8080']
relabel_configs:
- source_labels: [__address__]
regex: '(.*):8080'
target_label: __param_target
replacement: '$1'
五、未来趋势与工具选型建议
5.1 技术趋势预测
- 多模态工具融合:未来工具将打破文本 / 图像 / 语音的界限,支持跨模态标注与训练(如 LabelStudio 已开始支持多模态)。
- AI 原生开发范式:智能编码工具与模型训练平台深度整合,通过自然语言直接生成训练代码与部署配置(如 “用一句话生成目标检测模型的训练流水线”)。
- 边缘端工具轻量化:针对边缘设备(如手机、IoT 设备)的轻量化训练 / 标注工具将兴起,支持本地小样本学习。
5.2 工具选型决策矩阵
| 团队规模 | 核心需求 | 推荐工具组合 | 成本估算(年) |
|---|---|---|---|
| 个人 / 小团队(<5 人) | 快速验证想法 | GitHub Copilot + LabelStudio + MLflow | 免费(开源工具)+ 本地硬件成本 |
| 中型团队(5-50 人) | 高效协作 + 中等规模训练 | Tabnine + Prodigy + AWS SageMaker(按需付费) | 约 1-5 万美元(含工具 license + 云资源) |
| 大型团队(>50 人) | 企业级安全 + 大规模训练 | 定制化工具链(自研 + 云平台)+ 私有部署 LabelStudio | 10 万美元以上(含定制开发 + 运维) |
结语
AI 工具链的发展正推动 AI 开发从 “专家专属” 向 “大众化” 转变。从智能编码工具减少重复劳动,到数据标注工具降低数据准备门槛,再到训练平台实现流程自动化,每一类工具都在重构 AI 开发的效率边界。对于开发者而言,掌握工具链的协同使用,不仅能提升个人效能,更能推动团队形成标准化的 AI 开发流程,在快速迭代的 AI 技术浪潮中占据先机。未来,随着工具的进一步智能化与集成化,AI 开发将进入 “更少编码、更多创新” 的新阶段,释放更大的技术价值。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 12
12 0
0- 0



 已为社区贡献88条内容
已为社区贡献88条内容

所有评论(0)