
AI编程入门终极指南:从理论到实践
问题类型:多分类问题(监督学习)数据模块中自带的鸢尾花数据集。特征:4个数值特征。花萼长度 (sepal length)花萼宽度 (sepal width)花瓣长度 (petal length)花瓣宽度 (petal width)目标标签:3个类别 (0: Setosa, 1: Versicolour, 2: Virginica)python# 损失函数:对于多分类问题,常用交叉熵损失# 优化器:
引言:欢迎来到AI的新纪元
我们正站在一场技术革命的开端。人工智能(AI)不再是科幻小说的专属概念,它已经渗透到我们生活的方方面面,从手机上的语音助手到 Netflix 的推荐算法,再到自动驾驶汽车。而这场革命的核心驱动力,正是AI编程。
AI编程是一门将人类智慧转化为机器可执行指令的艺术与科学。它使计算机能够从数据中学习、识别模式、做出预测甚至自主决策。本指南将作为您的全方位路线图,系统性地引导您从零开始,逐步掌握AI编程的核心概念、工具和实践技能。
无论您是渴望转型的传统程序员、充满好奇的学生,还是希望将AI融入业务的创业者,这份指南都将为您提供坚实的起点和清晰的前进方向。
第一部分:思想启蒙 - 理解AI、机器学习与深度学习
在编写第一行代码之前,我们必须建立正确的认知框架。
1.1 核心概念辨析
-
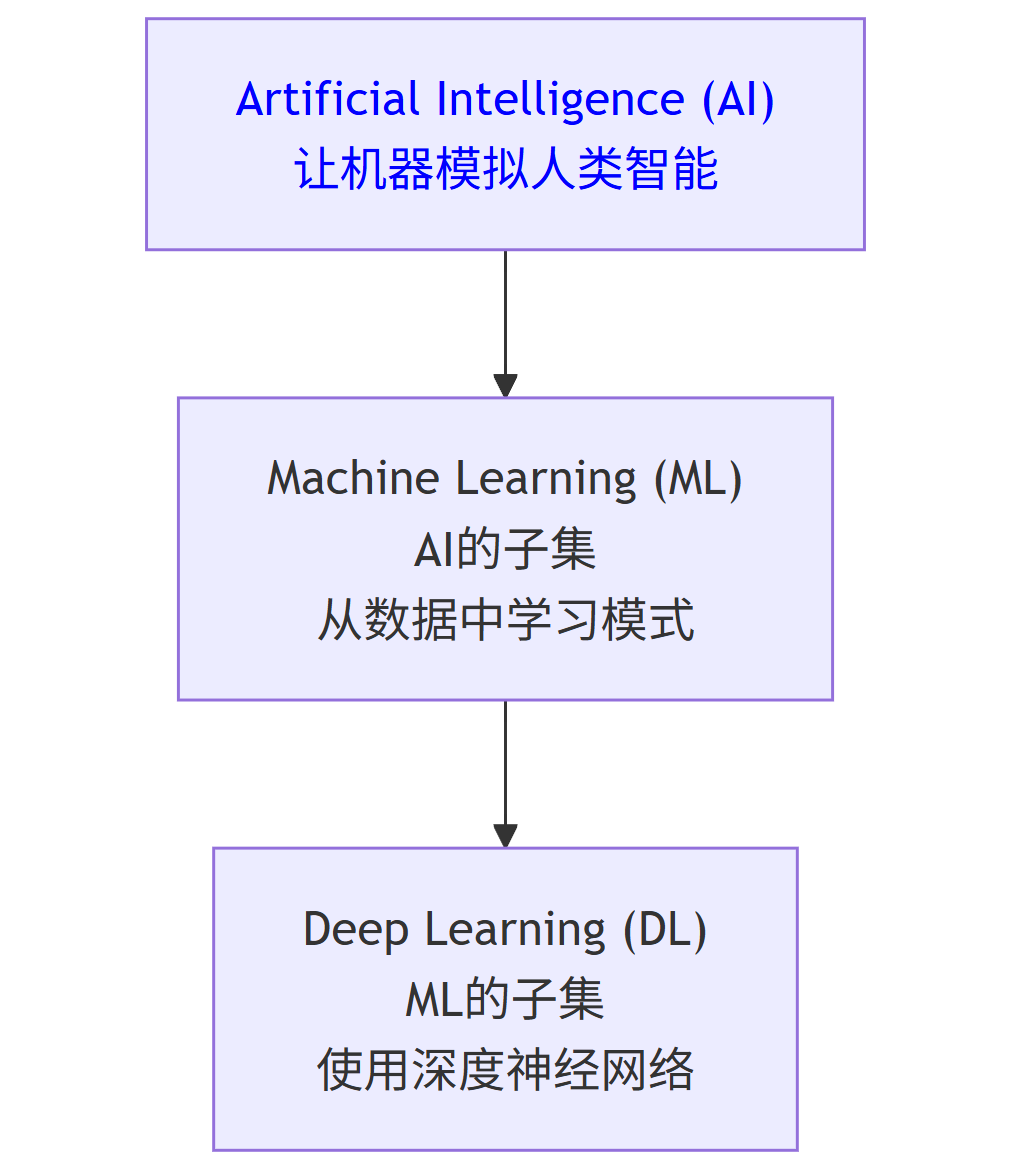
人工智能 (Artificial Intelligence, AI):一个广阔的领域,目标是让机器能够模拟人类的智能行为,如学习、推理、解决问题、感知和理解语言。它是一个宏观概念。
-
机器学习 (Machine Learning, ML):实现AI的一种主要方法。它的核心思想是:计算机无需通过显式编程,而是通过从数据中学习,来提升处理任务的性能。ML是AI的子集和最重要的实现手段。
-
深度学习 (Deep Learning, DL):机器学习的一个特定分支,它使用被称为人工神经网络 (Artificial Neural Networks, ANNs) 的复杂结构,尤其是多层的“深度”网络。它在图像识别、自然语言处理等领域取得了突破性成就。DL是ML的子集。
它们的关系可以用以下韦恩图清晰地表示:
flowchart TD
AI["Artificial Intelligence (AI)<br>让机器模拟人类智能"]
ML["Machine Learning (ML)<br>AI的子集<br>从数据中学习模式"]
DL["Deep Learning (DL)<br>ML的子集<br>使用深度神经网络"]
AI --> ML
ML --> DL
1.2 机器学习的三大范式
机器学习主要分为三种类型,理解它们至关重要。
-
监督学习 (Supervised Learning):
-
概念:模型从已标注的训练数据中学习。即,每个输入样本都对应一个已知的输出结果(标签)。
-
目标:学习输入到输出之间的映射关系,以便对新的、未见过的数据做出预测。
-
类比:就像学生通过大量“题目-答案”对来学习,最终目的是为了解答新的考题。
-
示例:
-
分类:判断邮件是垃圾邮件还是正常邮件(输出是类别)。
-
回归:预测房子的价格(输出是连续数值)。
-
-
-
无监督学习 (Unsupervised Learning):
-
概念:模型从未标注的数据中学习,寻找数据内在的结构和模式。
-
目标:发现数据中隐藏的分组、关联或降维表示。
-
类比:给你一堆不同的水果但没有标签,让你根据颜色、形状等特征自行将它们分成几堆。
-
示例:
-
聚类:根据用户行为对客户进行分组。
-
降维:将高维数据可视化在二维平面上。
-
-
-
强化学习 (Reinforcement Learning):
-
概念:智能体(Agent)通过与环境互动,根据获得的奖励或惩罚来学习最佳行为策略。
-
目标:学习一系列行动,以最大化长期累积奖励。
-
类比:训练狗做动作,做对了就给零食(奖励),做错了就无视(惩罚)。狗通过试错学习哪些行为能获得奖励。
-
示例:AlphaGo,自动驾驶,游戏AI。
-
1.3 典型工作流程
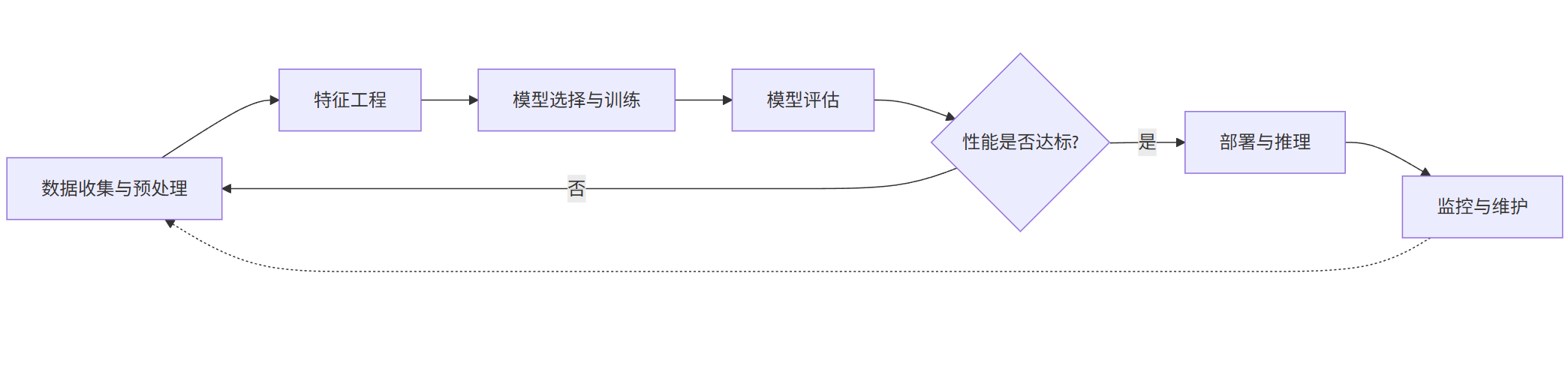
一个经典的机器学习项目遵循一个可迭代的循环流程,如下图所示:
flowchart LR
A[数据收集与预处理] --> B[特征工程]
B --> C[模型选择与训练]
C --> D[模型评估]
D --> E{性能是否达标?}
E -- 是 --> F[部署与推理]
E -- 否 --> A
F --> G[监控与维护]
G -.-> A
第二部分:装备你的武器库 - 工具与环境搭建
工欲善其事,必先利其器。Python是AI领域的绝对主流语言,因其简洁的语法和强大的生态库而备受青睐。
2.1 核心Python库
-
NumPy:科学计算的基础包,提供高性能的多维数组对象和数学函数。一切皆基于NumPy数组。
-
Pandas:数据处理和分析的神器。提供了DataFrame这种表格型数据结构,使得数据清洗、转换、分析变得异常简单。
-
Matplotlib & Seaborn:最流行的数据可视化库,用于创建静态、交互式和动态的图表。
-
Scikit-Learn:机器学习领域的“瑞士军刀”。提供了简单高效的数据挖掘和数据分析工具,涵盖了几乎所有经典机器学习算法(监督、无监督)。
-
TensorFlow & PyTorch:两大深度学习框架。提供了构建和训练神经网络所需的全部功能。PyTorch因其更Python化的设计和动态图特性,更受研究人员和初学者欢迎。
2.2 环境搭建:强烈推荐Anaconda
Anaconda是一个集成的Python数据科学平台,它帮你管理了Python环境和大部份常用的数据科学库,避免了复杂的依赖问题。
-
下载安装:访问 Anaconda官网 下载并安装适合你操作系统的版本。
-
创建虚拟环境(最佳实践):
bash
# 创建一个名为ai_starter的环境,并安装Python 3.9 conda create -n ai_starter python=3.9 # 激活环境 (Windows) conda activate ai_starter # 激活环境 (macOS/Linux) source activate ai_starter # 在激活的环境中安装核心库 conda install numpy pandas matplotlib seaborn scikit-learn jupyter conda install pytorch torchvision torchaudio -c pytorch # 安装PyTorch (CPU版本)
-
启动Jupyter Notebook/Lab:
bash
# 在终端中,进入你的项目目录后输入 jupyter lab
Jupyter提供了一个交互式的编程环境,非常适合进行数据探索和实验。
第三部分:实战入门 - 你的第一个机器学习项目
让我们用一个经典的鸢尾花分类项目来实践监督学习。这个问题旨在根据鸢尾花的花萼和花瓣的测量数据来预测其品种(Setosa, Versicolour, Virginica)。
3.1 项目概述与数据理解
-
问题类型:多分类问题(监督学习)
-
数据:
sklearn.datasets模块中自带的鸢尾花数据集。 -
特征:4个数值特征。
-
花萼长度 (sepal length)
-
花萼宽度 (sepal width)
-
花瓣长度 (petal length)
-
花瓣宽度 (petal width)
-
-
目标标签:3个类别 (0: Setosa, 1: Versicolour, 2: Virginica)
3.2 代码逐步实现
以下代码应在你的Jupyter Notebook中运行。
步骤1:导入必要的库
python
# 基础数据与可视化库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 机器学习库:从sklearn中导入数据集、模型、评估工具
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# 设置图表风格
sns.set_style("whitegrid")
%matplotlib inline
步骤2:加载和探索数据
python
# 加载数据集
iris = load_iris()
# 通常我们会将数据转换为Pandas DataFrame以便更好地探索
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['target'] = iris.target # 添加目标列
df['species'] = df['target'].apply(lambda x: iris.target_names[x]) # 添加物种名称列
# 查看数据前5行
print("数据前5行:")
print(df.head())
# 查看数据集的基本信息:样本数、特征数、类型等
print("\n数据集形状:", df.shape)
print("\n数据基本信息:")
print(df.info())
# 查看统计摘要
print("\n统计摘要:")
print(df.describe())
# 检查类别分布
print("\n类别分布:")
print(df['species'].value_counts())
输出分析:你会发现数据有150个样本,4个特征,没有缺失值,且3个类别的样本数量相等(各50个),这是一个非常干净的数据集。
步骤3:数据可视化
可视化是理解数据的关键步骤。
python
# 1. 特征分布直方图
df.hist(figsize=(12, 8), bins=20)
plt.suptitle('特征分布直方图')
plt.show()
# 2. 散点图矩阵,按物种着色 (非常强大!)
sns.pairplot(df, hue='species', height=2.5, palette='viridis')
plt.suptitle('按物种着色的散点图矩阵', y=1.02)
plt.show()
# 3. 相关性热力图
plt.figure(figsize=(8, 6))
correlation_matrix = df.drop(['target', 'species'], axis=1).corr()
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', center=0)
plt.title('特征相关性热力图')
plt.show()
图表分析:从散点图矩阵中,你可以清晰地看到petal length和petal width对于区分Setosa和其他两种类型非常有效。Virginica和Versicolour在有些特征上有重叠,这预示着模型可能在这两类上会出现一些错误。
步骤4:数据预处理
数据预处理是ML流程中至关重要的一环,直接影响模型性能。
python
# 分离特征(X)和目标标签(y)
X = df.drop(['target', 'species'], axis=1)
y = df['target']
# 将数据集划分为训练集和测试集
# test_size=0.2: 20%的数据用作测试,80%用于训练
# random_state=42: 设置随机种子,确保每次划分的结果一致,便于复现结果
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
# 特征缩放:很多算法对特征的尺度敏感,将其标准化为均值为0,方差为1。
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train) # 在训练集上计算均值和方差,并应用转换
X_test_scaled = scaler.transform(X_test) # 使用训练集的参数对测试集进行转换
print(f"训练集大小: {X_train_scaled.shape}")
print(f"测试集大小: {X_test_scaled.shape}")
步骤5:选择模型并训练
我们选择逻辑回归(Logistic Regression)作为第一个模型。尽管名字里有“回归”,但它实际上是解决分类问题的经典线性模型。
python
# 创建模型实例
# random_state同样是为了确保结果可复现
model = LogisticRegression(random_state=42, multi_class='ovr')
# 在训练数据上训练模型 (拟合)
model.fit(X_train_scaled, y_train)
# 查看模型学到的参数(权重和偏置)
print("模型系数 (Weights):", model.coef_)
print("模型截距 (Bias):", model.intercept_)
步骤6:模型评估与推理
训练完成后,我们需要在测试集(模型从未见过的数据)上评估其泛化能力。
python
# 使用训练好的模型对测试集进行预测
y_pred = model.predict(X_test_scaled)
y_pred_prob = model.predict_proba(X_test_scaled) # 获取预测概率
# 1. 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"模型准确率: {accuracy:.4f}") # 通常能达到~0.97
# 2. 打印详细的分类报告
print("\n分类报告:")
print(classification_report(y_test, y_pred, target_names=iris.target_names))
# 3. 绘制混淆矩阵
plt.figure(figsize=(8, 6))
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
xticklabels=iris.target_names,
yticklabels=iris.target_names)
plt.ylabel('真实标签')
plt.xlabel('预测标签')
plt.title('混淆矩阵')
plt.show()
# 4. 对新数据进行推理示例
new_flower_measurements = [[5.1, 3.5, 1.4, 0.2]] # 一个新样本的特征
new_flower_scaled = scaler.transform(new_flower_measurements) # 必须使用相同的缩放器!
prediction = model.predict(new_flower_scaled)
predicted_species = iris.target_names[prediction][0]
print(f"\n对新花的预测种类是: {predicted_species}")
3.3 分析与下一步
-
结果分析:逻辑回归在这个数据集上表现非常好,准确率通常超过95%。混淆矩阵可以显示具体哪些类别容易被混淆。
-
下一步尝试:
-
尝试其他模型:用相同的流程试试
sklearn中的其他模型,如K近邻(KNeighborsClassifier)、支持向量机(SVC)或决策树(DecisionTreeClassifier)。比较它们的性能。 -
超参数调优:使用
GridSearchCV或RandomizedSearchCV来寻找模型的最佳参数组合。 -
回到数据:如果准确率不理想,可能需要回到数据预处理和特征工程的步骤。
-
第四部分:迈向深度 - 神经网络与深度学习初探
当数据更复杂(如图像、声音、文本)时,传统机器学习模型可能力不从心,这时就需要深度学习。
4.1 核心概念:人工神经网络
神经网络受人类大脑启发,由相互连接的“神经元”层组成。
-
输入层:接收原始数据。
-
隐藏层:介于输入和输出层之间,进行复杂的特征变换和提取。层数越多,“深度”越深。
-
输出层:产生最终的预测结果。
-
权重与偏置:连接强度,是模型需要学习的参数。
-
激活函数:为网络引入非线性,使其能够学习更复杂的模式。常用ReLU, Sigmoid, Tanh, Softmax。
4.2 使用PyTorch构建一个图像分类器
我们将使用著名的Fashion-MNIST数据集,它包含10个类别的灰度服装图像,是入门深度学习的好选择。
步骤1:导入PyTorch相关库
python
import torch
from torch import nn, optim
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
# 检查是否有可用的GPU(如NVIDIA的CUDA),优先使用GPU训练,速度极快
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device")
步骤2:准备数据
python
# 定义数据转换:将图像数据转换为PyTorch张量(Tensor)并标准化
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,)) # 将灰度值从[0,1]归一化到[-1,1]
])
# 下载训练和测试数据
train_data = datasets.FashionMNIST(root='./data', train=True, download=True, transform=transform)
test_data = datasets.FashionMNIST(root='./data', train=False, download=True, transform=transform)
# 创建数据加载器 (DataLoader),用于批量加载数据和打乱数据
batch_size = 64
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_data, batch_size=batch_size, shuffle=False)
# 定义类别名称
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
步骤3:构建神经网络模型
我们构建一个简单的前馈神经网络。
python
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
# 定义网络层
self.flatten = nn.Flatten() # 将28x28的图像展平为784个像素点
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512), # 全连接层,输入784,输出512
nn.ReLU(), # 激活函数
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10) # 输出层,10个神经元对应10个类别
)
def forward(self, x):
# 定义数据如何通过网络
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
model = NeuralNetwork().to(device)
print(model)
步骤4:定义损失函数和优化器
python
# 损失函数:对于多分类问题,常用交叉熵损失 loss_fn = nn.CrossEntropyLoss() # 优化器:用于更新模型参数(权重),试图最小化损失函数 # model.parameters()表示要优化模型的所有参数,lr是学习率,是一个重要的超参数 optimizer = optim.Adam(model.parameters(), lr=1e-3)
步骤5:训练循环
python
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
model.train() # 将模型设置为训练模式
for batch, (X, y) in enumerate(dataloader):
X, y = X.to(device), y.to(device)
# 计算预测值并计算损失
pred = model(X)
loss = loss_fn(pred, y)
# 反向传播:计算梯度并更新参数
optimizer.zero_grad() # 清空上一步的梯度
loss.backward() # 反向传播,计算当前梯度
optimizer.step() # 根据梯度更新参数
if batch % 100 == 0:
loss, current = loss.item(), batch * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
# 测试循环,评估模型性能
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval() # 将模型设置为评估模式
test_loss, correct = 0, 0
with torch.no_grad(): # 在测试时不计算梯度,节省内存和计算
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
# 开始训练!
epochs = 5
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train(train_loader, model, loss_fn, optimizer)
test(test_loader, model, loss_fn)
print("Done!")
训练几个周期后,你应该能看到测试准确率稳步上升,最终达到约85%左右。
步骤6:使用模型进行预测
python
# 取出一批测试数据
dataiter = iter(test_loader)
images, labels = next(dataiter)
images, labels = images.to(device), labels.to(device)
# 进行预测
model.eval()
with torch.no_grad():
outputs = model(images)
_, predicted = torch.max(outputs, 1)
# 显示图片和预测结果(需要matplotlib)
fig, axes = plt.subplots(4, 4, figsize=(10,10))
for i, ax in enumerate(axes.flat):
ax.imshow(images[i].cpu().squeeze(), cmap='gray') # 将图像从GPU移回CPU并显示
ax.set_title(f"True: {class_names[labels[i]]}\nPred: {class_names[predicted[i]]}")
ax.axis('off')
plt.tight_layout()
plt.show()
第五部分:与AI协作 - 掌握Prompt Engineering
作为现代AI程序员,不仅要会编AI,还要会“问”AI。与大语言模型(如ChatGPT、Claude、Copilot)高效交互的能力至关重要。
5.1 什么是Prompt Engineering?
Prompt Engineering是一门设计和优化输入(称为“Prompt”或“提示”),以引导AI模型产生更准确、相关和有用输出的艺术和科学。
5.2 Prompt构建基础框架与示例
一个强大的Prompt通常包含以下几个元素:
-
角色 (Role):为AI设定一个专家角色。
-
任务 (Task):清晰、具体地说明你要它做什么。
-
上下文/背景 (Context):提供必要的背景信息。
-
要求/约束 (Requirements/Constraints):规定输出的格式、风格、长度等。
-
示例 (Examples)(可选):提供一两个输入输出的例子(少样本学习)。
糟糕的Prompt示例:
“写一个Python代码。”
优化后的Prompt示例:
角色:你是一位资深的Python开发专家,擅长编写清晰、高效且符合PEP8规范的代码。
任务:请为我编写一个Python函数。
上下文:这个函数用于处理机器学习中的特征工程。
要求:
功能:函数名为
handle_outliers,接收一个Pandas DataFrame的某一列(Series)和一个字符串参数method。方法:如果
method为'clip',使用分位数剪裁法(默认上下分位数为0.05和0.95)处理异常值。如果method为'remove',则直接删除异常值所在的行(需在原DataFrame上操作)。输出:返回处理后的Series或DataFrame。
代码要求:包含详细的文档字符串(Docstring),说明参数和返回值。代码要有注释。
格式:只输出代码,不需要任何解释。
另一个用于学习的Prompt示例:
角色:你是一位耐心的机器学习导师。
任务:向我解释逻辑回归(Logistic Regression)的工作原理。
要求:
用比喻和直观的例子来解释,避免过多复杂的数学公式。
将其与线性回归进行对比,说明为什么它虽然叫“回归”却是分类算法。
最后,用1-2句话总结它的核心思想。
输出结构清晰,段落分明。
5.3 AI编程助手实战场景
-
代码生成与补全:如上面的示例,描述清晰功能即可生成代码框架。
-
代码解释与调试:将一段报错的代码粘贴给AI,询问“这段代码为什么报错
[错误信息]?请修复它并解释原因。” -
学习新技术:“用PyTorch实现一个卷积神经网络(CNN)来分类CIFAR-10数据集。请逐步解释代码。”
-
文档和注释生成:写完函数后,提示“为以下函数生成一个PEP8标准的文档字符串:
[你的函数代码]” -
重构与优化:“以下代码如何优化其性能?
[你的代码]”
记住:AI可能会犯错或产生不完美的代码,你必须具备批判性思维,理解和测试它提供的内容,而不是盲目复制粘贴。
第六部分:持续学习之路 - 资源与社区
AI领域日新月异,持续学习是唯一的途径。
-
在线课程:
-
Coursera:吴恩达《机器学习》、《深度学习专项课程》是永恒的经典。
-
Fast.ai:实用的顶层方法,非常适合快速上手做出成果。
-
Udacity:AI纳米学位项目。
-
-
书籍:
-
《Python机器学习基础教程》(Introduction to Machine Learning with Python):Scikit-Learn最佳入门书。
-
《动手学深度学习》(Dive into Deep Learning):内容全面,有交互式Jupyter Notebook支持。
-
《Python深度学习》(Deep Learning with Python):Keras框架作者所写,通俗易懂。
-
-
官方文档:这是最重要、最权威的资源! 遇到问题首先查
Scikit-Learn、PyTorch、TensorFlow的官方文档。 -
社区与竞赛:
-
Kaggle:数据科学和机器学习的顶级社区。参加入门比赛(如Titanic),学习别人的代码(Kernel),是提升最快的办法。
-
GitHub:关注顶级AI项目(如Hugging Face Transformers),阅读开源代码。
-
Stack Overflow:解决具体编码问题的首选。
-
-
论文:关注顶级会议(NeurIPS, ICML, ICLR, CVPR)的最新论文,保持技术嗅觉。
结语
恭喜你完成了这份漫长的AI编程入门指南!你已经从理论到实践,对AI编程的全貌有了一个系统的认识。记住,AI编程不是一个可以“速成”的领域,理论理解、动手实践和持续学习三者缺一不可。
不要畏惧复杂的数学和理论,从解决一个个小问题开始,构建你的项目组合(Portfolio),积极参与社区讨论。最重要的是,保持好奇心和热情。
现在,打开你的编辑器,开始你的第一个AI项目吧!世界正等着你的创造。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 10
10 0
0- 0



 已为社区贡献88条内容
已为社区贡献88条内容

所有评论(0)