
【必收藏】2025大模型开源全景图深度解析:从外滩大会洞察生态演进与核心突破
《全球大模型开源开发生态全景图》揭示了中美路线分化、项目迭代加速、开源定义模糊的三大格局。核心技术包括MoE架构、三类推理部署、AI Agent三大方向和综合评测体系。未来趋势将聚焦多模态融合、效率优化和AI编程工具爆发。开发者应关注高活性项目、深耕垂直领域、布局新技术并参与生态建设,把握开源大模型机遇。
在2025年inclusionAI外滩大会现场,蚂蚁开源技术委员会副主席王旭发布的《全球大模型开源开发生态全景图》引发行业震动。
这份包含114个核心项目以及22个技术领域的报告,不单用数据把开源大模型的当下格局给勾勒出来了,还暗藏着技术演进的重要信号呢。
接下来我们从生态的整个局面、核心的技术以及未来的走向这三个方面去剖析那些有价值的东西,给大家提供能够实际运用的参考。
生态全局:外滩大会揭示的3个核心格局

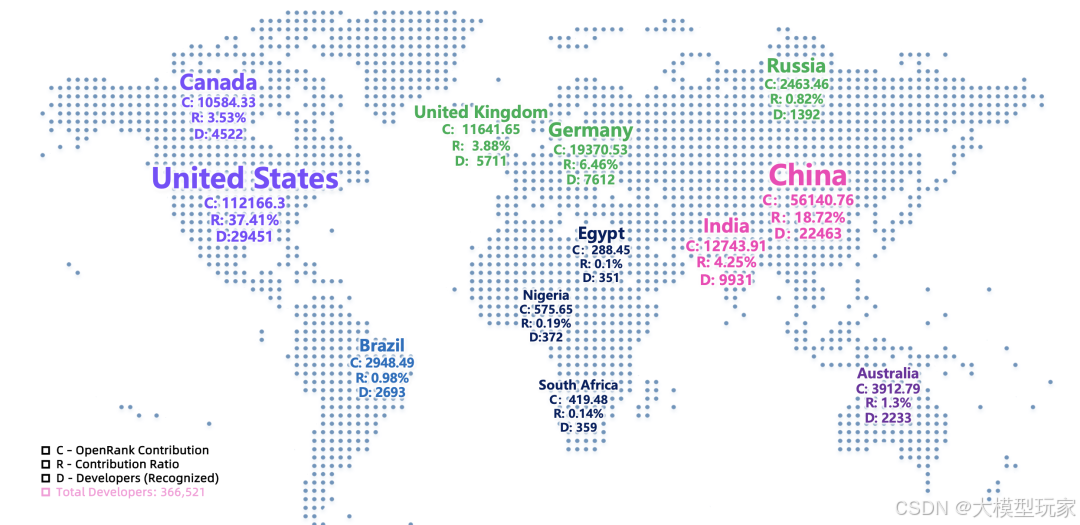
首先我们一起看看这张全景图,从数据综合起来看,有三个方面的特点特别重要,对技术的发展方向和项目选择的逻辑有着直接的影响:
1.中美路线分化:中国开源主导生态,国外闭源聚焦商业
全世界的开源大模型呈现出“阵营化”的特点:
-
中国阵营:以阿里云Qwen、智谱GLM、深度求索DeepSeek为核心坚持“全开源+工具链配套”策略。
Qwen2.5ax这种多模态模型跟DeepSeek-R1这个语言模型都是依据Apache2.0协议来开源的,与此同时还推出了LLaMA-Factory和XorbitsInference,搭建起了从模型研发到实际运用的完整技术链条。新版全景图增加了39个项目,其中有28%的项目是由中国团队完成的,在全球所占比例是第一。
-
国外阵营:OpenAI GPT-5、Google Gemini 2.5、Anthropic ClaudeOpus4.1坚守闭源路线;即使早期推动开源的Meta,也传出Llama系列“基础版开源、高级版闭源”的转型计划。
国外只是在那些基础的工具方面(像PyTorch、TensorRT-LLM这类)一直保持着开源状态,而它们的核心模型全部是以商业授权这种方式来为企业客户提供服务的。
这种分化在开发者贡献方面表现得很明显:全世界有36.6万参与开发的人员,其中美国占24%,中国占18%,这两个国家的贡献比例加起来超出了40%;而且中国的开发者在AIAgent这类新出现的领域投入更主动,贡献度达到了21.5%比传统的AIInfra领域提升了8个百分点。

2.项目迭代加速:2年半寿命周期,62%诞生于GPT时代后
开源大模型项目的“生命周期数据”对行业“迭代速度”的看法:
-
生态内所有项目“年龄中位数仅30个月”(约2年半),远低于传统AI框架(如TensorFlow寿命超8年
-
62%的项目诞生于2022年10月“GPT时刻”后,其中12个是2025年新发起(如字节DeepResearch框架)
-
淘汰率非常高:由于OpenRank(开源影响力指标)低于50而被剔除,其中一些已经进入“AI墓园”了比如早期的端侧部署工具MLC-LLM、文本生成推理引擎TGI,它们的性能不如Ollama、vLLM,开发者的活跃度急剧下降了90%,代码提交量从每周十多次变为每月不到一次。
典型案例:2024年超火的KVCache.AI推理优化框架,以前凭借“单机能部署千亿参数模型”的本领收获了1.4万颗Star,不过在2025年更新频率从每周5次降到每月1次,OpenRank评分也从89降至34,最终未被新版全景图收录,成为“快速走红、快速沉寂”的典型案例。
3.开源定义模糊:协议创新与平台异化并存
外滩大会的圆桌讨论里,“开源边界”成了有争议的重点。现在的生态当中存在着两种“非传统开源”的现象这是开发者需要提高警惕的事情:
-
协议层面:出现“商业保护型许可”,如Dify的OpenSourceLicense(限制未经许可的多租户环境运营)、n8n SustainableUseLicense(仅限企业内部或非商业用途使用)、CherryStudio的User-SegmentedDualLicense(10人以上组织需商业授权。这些协议带有一些限制条件,没有得到OSI(开源促进会)的认可不过在全景图收录项目里占了15%。
-
平台方面:GitHub慢慢从原本的“代码托管平台”变成了“运营的地方像Claude-Code、Cursor这类闭源产品,它们在GitHub上创建仓库来收集用户的反馈(这些仓库的Star数都超过了8万),但却没有把核心源代码开放出来,结果有23%的开发者错误地把它们当作“开源项目”,把开源的核心定义给弄混了。
核心技术拆解:全景图聚焦的4个突破方向

2025年开源大模型的技术突破集中在四大领域,每个方向均有明确的技术方案、性能数据与落地案例支撑:
1.模型架构:MoE成万亿参数标配,混合推理平衡速度与精度
2025年,所有的旗舰开源模型都换成了MoE(混合专家系统)架构把“参数规模等于性能”这个传统观念完全给改变了:
-
MoE架构得到了广泛的应用:像DeepSeek-R1、Qwen3、KimiK2这样的旗舰模型都使用了MoE设计,而且它们的参数规模达到了以万亿作为单位的程度。拿Qwen3来说,凭借“1.2万亿参数加16专家层”这样的配置,在AIME2025数学评测里拿到了85分,比相同参数的dense模型精度提高了25%,并且在这个过程中训练成本降低了60%——这种架构通过“只激活部分专家层”,把大模型训练中“成本与效率”的矛盾给解决了。
-
混合推理模式落地:为解决“推理速度慢”的核心痛点,Qwen3、ClaudeOpus41等模型推出“双模式推理”:
- 快速模式时,会调动1到2个专家层去处理简单的问答,像是“天气查询”或者“基础语法解析”这类的问题。在这样的情形下,响应时间可以小于100毫秒,很适宜那些高频且低复杂度的场景;
- 深度模式:把专家层级的功能以及工具调用都全部打开,这是专门为了处理那些复杂的任务而设计的,像数学方面的证明还有代码的重新构建之类的,它能让准确率提高30%,很适合在企业的核心业务场景中使用。
技术实操:开源项目OPENRLHF提供可复用的MoE训练框架,支持自定义专家数量(16128)、激活阈值,且兼容PyTorch、PaddlePaddle等主流框架。开发者可通过以下步骤快速搭建千亿级MoE模型:
克隆仓库:git clone https://github.com/openrlhf/openrlhf.git
配置专家层:修改configs/moe_config.yaml中num_experts参数(如设为 16)
启动训练:python train.py --config configs/moe_config.yaml
目前该项目 Star 达 1.6 万,被 30 + 企业用于大模型训练。
2.推理部署:三类方案覆盖全场景,Ollama成端侧标杆
“推理部署”清楚地分成了“集群、端侧、边缘”这三种类别,增添了具体的性能数据以及落地的场景,从而构建出涵盖“企业个人设备”的全方位场景方案:
| 部署场景 | 核心技术 | 开源项目 | 性能指标 | 适用场景 |
|---|---|---|---|---|
| 企业级集群 | 多模型调度、GPU路由优化 | NVIDIA Dynamo | 支持100+模型并发,GPU利用率提升40% | 云服务API、企业私有部署 |
| 端侧部署 | llama.cpp内核、一键启动 | Ollama | 单机部署70B模型,内存占用<16GB | 个人PC、开发者调试 |
| 边缘计算 | 轻量化量化、硬件适配 | OpenVINO | 移动端部署13B模型,功耗降低50% | 物联网设备、嵌入式系统 |
实操案例:Ollama凭借“极简部署+OpenAI兼容API”,2025年OpenRank从352升至637,成为端侧部署“事实标准”。开发者只需3步即可在本地启动Qwen3-7B模型:
安装 Ollama:curl https://ollama.com/install.sh | sh(Linux/macOS,Windows 可下载安装包)
拉取并启动模型:ollama run qwen3:7b
调用 API:curl http://localhost:11434/api/generate -d '{"model":"qwen3:7b","prompt":"用Python写一个快速排序算法"}'
目前 Ollama 用户超 50 万,已集成到 VS Code、PyCharm 等 IDE 插件。
3.AI Agent:从工具调用到工作流自动化,三大方向落地
文档把AIAgent详细分成了“记忆、工具、工作流”这三种类别,给出了具体在实际中落实的例子以及效率方面的数据,这就表明AI Agent从仅仅是个“概念”转变为了可以实际使用的东西:
-
记忆能力:LangChainMemory通过“向量数据库+图数据库”实现长时记忆,支持跨会话存储用户偏好与历史交互在客服场景中,该功能使对话连贯性提升60%,用户满意度从75%升至92%;
-
工作流编排:n8n的AgentWorkflow支持串联“文档解析→知识检索→报告生成”全流程某咨询公司用其将“行业报告撰写”时间从8小时缩短至1小时,效率提升87.5%;
-
浏览器自动化:Pyppeteer-Agent突破了传统爬虫的限制,它能够支持对动态网页进行互动操作,像填写表单以及提取通过JS渲染的数据之类的。在电商数据监控方面得到了应用,其准确率达到了95%,比传统爬虫提高了30%。
技术干货:开源项目AutoGen提供多Agent协作框架,支持定义“管理者Agent(拆分任务)+执行者Agent(执行子任务)”。开发者只需简单配置,即可实现复杂任务自动化,示例代码如下:
from autogen import AssistantAgent, UserProxyAgent
# 定义管理者Agent:拆分任务并分配
manager = AssistantAgent(
name="task_manager",
system_message="将复杂任务拆分为子任务,分配给对应执行者,监控任务进度"
)
# 定义代码生成Agent:执行代码编写子任务
coder = AssistantAgent(
name="code_generator",
system_message="根据子任务生成可运行的Python代码,包含注释与异常处理"
)
# 定义测试Agent:执行代码测试子任务
tester = AssistantAgent(
name="code_tester",
system_message="为生成的代码编写单元测试,验证功能正确性"
)
# 启动协作:用户发起任务
user_proxy = UserProxyAgent(name="user")
user_proxy.initiate_chat(
manager,
message="生成一个读取Excel文件并可视化销售数据的完整流程(含代码与测试)"
)
AutoGen当前Star达12.6万被用于金融、教育等领域的企业级任务。
4.评测体系:主观客观结合,6大评测集覆盖核心场景
2025年开源大模型评测不会再运用“单一指标论”,而是构建了“主观投票加上客观标准”这样一个综合性的体系,该体系的核心评测集涵盖了数学、代码、多模态等重要的场景:
| 评测集 | 面向领域 | 核心特点 | 代表模型表现(Top 3) |
|---|---|---|---|
| AIME 2025 | 数学 | 复杂推理(微积分、线性代数) | GPT-5(89分)、Qwen3-2507(85分) |
| SWE-bench verified | 代码 | 真实软件工程任务(Bug修复、重构) | Kimi K2(81分)、GPT-5(79分) |
| MMMU | 多模态 | 跨模态理解(图文问答、视频分析) | Gemini 2.5(86分)、GPT-5(84分) |
| GPQA Diamond | 数学 | 高阶数学问题(数论、拓扑学) | GPT-5(87分)、Kimi K2(83分) |
| LiveCode Bench v6 | 代码 | 实时代码生成(多语言适配) | Qwen3-2507(80分)、Kimi K2(78分) |
| BrowseComp | Agentic | 浏览器自动化任务(信息抓取) | DeepSeek-V3.1(84分)、GPT-5(82分) |
要注意的是,企业在挑选开源模型的时候,那种通过LMArena人类投票之类的主观评测所具有的参考权重,从20%提升到了45%。客观的数据能决定“基础性能”,而主观的体验则能决定“落地效果”,把这两者结合起来,就成了模型选型的关键依据。
未来趋势:2025-2026年技术方向
结合“趋势预测”与“新兴领域”,未来1-2年开源大模型将向三个方向深度演进,其中AI编程工具作为报告中最引人注目的增长领域,其发展路径与落地价值尤为突出:
1.多模态融合:视频生成成下一个突破点,多场景交互能力升级
现在开源的多模态模型主要是“文本图像语音”这种类型的(像Qwen-VL、DeepSeek-VL等),视频生成以及跨模态之间的协同合作会成为接下来的突破方向:
-
技术方向:基于“扩散模型+3D重建”技术实现“文本生成高清视频”,预计2026年将出现开源模型,支持1080P分辨率、10秒以上时长,适配广告制作、教育培训等场景
-
生态准备:文档已收录Pipecat、LiveKitAgents等语音模态工具链,未来将扩展至视频处理模块形成“文本图像语音视频”的全模态工具生态
-
挑战:训练数据稀缺(高清视频数据集不足10TB)、计算成本高(训练1个视频模型需1000+A100GPU小时),需依赖社区协作解决数据与算力问题
2.效率优化:从“大参数”到“高效模型”,轻量化与适配性提升
因为企业越来越关注部署成本了,那种“小参数高性能”的高效模型会变成主流,在文档的“效率优化”那部分就清楚地写明了有三大技术路径:
-
量化技术:从4bit量化向2bit、1bit演进,开源项目GPTQfor-LLaMa已实现2bit量化,模型体积缩小80%,精度损失<5%,可在中端PC上运行70B模型
-
蒸馏技术中,DistilLLM也就是DistilBERT的升级版,能够把70B这样大的模型蒸馏成7B这么小的模型,这样一来,推理的速度就加快了3倍呢,而且还能适配像物联网网关以及嵌入式开发板这类的边缘设备;
-
硬件适配:针对ARM、RISC-V等架构优化,开源项目TVM-LLM在ARM架构上部署7B模型,性能较通用方案提升50%,已被收录至“边缘计算”分类
3.AI编程工具:爆发式增长成新引擎,形态与生态持续完善
AI编程工具已经成为开源社区里增长速度最快的领域之一啦,它的核心价值就是“自动生成并且修改代码,能大大提高开发效率”,以后呢会展现出两个发展趋势:
-
工具形态与功能的细分:目前这类工具主要分为“命令行工具”和“IDE插件”两种类型。其中命令行工具以GoogleGeminiCLI为代表,体积小巧、灵活性强,可以快速生成脚本,开源仅三个月,Star数量便突破了6万。而IDE插件则以Cline为典型代表,深度整合进开发流程,覆盖代码生成、测试、重构等多个环节,开源五个月后Star数达到了3.2万目前已在12%的企业开发团队中落地使用。以后的工具在场景划分上会更加细致,比如为嵌入式开发准备的“适用于硬件的编程工具”,以及供前端开发使用的“能够生成UI的编程工具”。
-
生态协同与标准统一:现在的AI编程工具正面临着“碎片化”的问题就如同各种工具所生成的代码格式互不兼容一样。往后将会推进“工具接口标准化”,使命令行工具和IDE插件能够紧密无缝地衔接起来——GeminiCLI生成的代码可以直接导入到Cline中进行编辑和测试。这个时候,这些工具会深入融合AIAgent,打通“需求文档→代码生成→部署上线”的整个流程。互联网公司在进行试点之后的结果显示,这种模式能够将功能开发周期从3天压缩至1天,效率提升了67%。
总结:抓住开源大模型的4个核心机会
开发者和企业能够把注意力集中在四个核心机会上,从而实现短期落地和长期布局的平衡:
- 技术选型:锁定高活性项目,规避“僵尸风险”
优先选择“OpenRank≥50、每月提交≥10次、贡献者100人”的项目——基础工具推荐Ollama(推理、AutoGen(Agent);AI编程工具推荐GeminiCLI(命令行)、Cline(IDE插件)。
可通过蚂蚁开源GitHub仓库(https://github.com/antgroup/llm-oss-landscape)获取项目实时动态,避免投入更新停滞的“僵尸项目”。
- 场景落地:深耕中小模型+垂直领域,平衡成本与性能
尽管万亿参数模型具备很强的性能,不过其部署成本相对较高。对比来看,经过精心调整的中小型模型更能满足垂直场景的应用需求。例如由Qwen7B调整形成的“医疗问答模型”,在专科疾病诊断上的准确率达到了88%,并且部署成本仅是千亿模型的二十分之一。企业能够依据自身的业务需求,诸如金融风控或者工业质检等,挑选合适的专用模型,如此便可避免因“大模型滥用”而引发的资源浪费。
- 长期布局:押注多模态+AI编程,抢占技术高地
多模态技术与AI编程会在未来一到两年里成为关键的发展方向,开发者能够主动投身到开源项目当中,像给多模态模型添加视频处理的功能,又或是为AI编程工具研发相关的插件;企业则可以去发掘“多模态行业应用”所具备的潜力,例如在教育领域完成“文本图像视频”一体化的教学内容生成,亦或是把“AI编程工具+开发流程”进行深度融合,就好比把编程工具融入DevOps体系,以此来构建独特的竞争优势。
- 生态参与:推动标准制定,平衡商业与社区价值
留意Linux基金会、Apache基金会这类机构在搞开源标准制定(像模型接口标准呀、AI编程工具协议之类的),得赶紧把企业需求给反馈上去;并且在挑选开源项目的时候,要留意许可协议(像Apache2.0、MIT这些就比较适合商业使用),可别因为协议受限而招来法律风险,得把商业利益和社区协作的关系给平衡好。
开源大模型的核心价值就是“开放协作”,像inclusion AI外滩大会讲的那样,只有健康的生态才可以支撑技术一直向前发展。2025年仅仅是个开始,以后这些技术会更深地融入各个行业,引发“效率提高、成本下降、创新加快”的新变化——不管是开发者还是企业,只有紧紧跟着趋势、在场景里深耕、参与到协作当中,才能够在开源大模型的浪潮里抓住机会。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 23
23 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)