
AI算力加速指南:让设计、办公、创作效率翻倍
本文系统阐述了AI算力如何通过硬件选型、软件优化和工作流重构提升设计、办公和创作效率。核心方案包括:选择RTX4090至H100等GPU实现3D渲染300%提速;利用OCR和Copilot工具使文档处理效率提升50%;配置多GPU工作站将视频生成时间缩短70%。实施策略建议分阶段推进,混合部署本地与云端资源,典型投资回报期为4-12个月。数据显示,合理配置AI算力可缩短项目周期52%,降低人力成本
作为一名深耕人工智能与性能优化的架构师,我在多个行业见证了AI算力如何重塑工作流程。本文将揭示如何通过正确的硬件选型、软件优化和工作流重构,在这三大关键领域实现真正的效率倍增。
目录
一、AI算力加速的核心逻辑
AI算力加速的本质是利用专用硬件和优化算法将重复性、计算密集型任务从CPU转移到更高效的执行单元。根据IDC《全球AI算力发展白皮书》数据显示,合理配置AI算力可使项目周期平均缩短52%,人力成本降低37%,团队协作效率提升2.3倍。
1.1 硬件选择原则
|
任务类型 |
推荐硬件 |
优势 |
成本效益 |
|---|---|---|---|
|
轻量级任务 |
RTX 4070/4090 |
性价比高,能耗低 |
每元性能比达1.8TFLOPS/¥ |
|
中型任务 |
NVIDIA A100/A40 |
大显存,稳定可靠 |
适合批量处理场景 |
|
重型任务 |
H100集群 + 高速互联 |
极致性能,扩展性强 |
初始投入高但长期ROI可观 |
二、设计领域的效率革命
2.1 实时渲染加速
传统3D渲染往往需要数小时甚至数天,成为设计流程的主要瓶颈。通过AI加速,这一过程可缩短至几分钟。
解决方案:
-
硬件配置:使用配备NVIDIA RTX 4090(24GB显存)或NVIDIA A100(80GB显存)的工作站,支持大规模模型实时渲染。
-
软件优化:
-
在Blender中启用OptiX光追加速,渲染速度提升300%
-
Unreal Engine中开启DLSS/FSR超分辨率技术,实时预览帧率提升200%-300%
-
Cinema 4D搭配OctaneRender插件,通过AI降噪减少50% 等待时间
-
实战案例:
某游戏美术团队使用RTX 4090 + Blender OptiX后,单张场景渲染时间从8小时降至27分钟,修改迭代次数增加5倍,项目交付周期缩短68%。
2.2 自动化设计工具
AI不仅加速渲染,还能自动化完成重复性设计任务:
# 使用Adobe Sensei API实现批量设计自动化
from adobe_api import SenseiClient
client = SenseiClient(api_key="your_key")
# 智能生成设计变体
variations = client.generate_variations(
original_design="main.psd",
style_presets=["modern", "vibrant", "minimalist"],
output_count=8 # 同时生成8种风格变体
)
# 自动导出多格式资源
for variant in variations:
variant.export(format="png", size=["1024x768", "1920x1080", "3840x2160"])效率提升:
-
banner设计从3小时/个减少到20分钟/个
-
多尺寸适配自动化,节省75% 导出时间
-
智能配色方案生成,减少60% 手动调整
三、办公场景的智能化升级
3.1 文档智能处理
办公文档处理消耗大量人力,AI可自动化这一流程:
配置方案:
-
硬件基础:Intel i7-13700K或AMD Ryzen 7 7800X3D处理器,搭配32GB DDR5内存
-
软件工具:
-
ABBYY FineReader:OCR识别准确率达99.3%,支持30+语言
-
Microsoft 365 Copilot:智能写作辅助,文档创作速度提升50%
-
GPT-4办公版:本地化部署的7B参数模型,响应时间<500ms
-
批量处理脚本:
# 使用OCR工具批量处理扫描文档
abbyy_cli process \
--input-dir ./scanned_docs \
--output-dir ./digital_docs \
--format docx \
--language "chinese+english" \
--batch-size 50 # 同时处理50个文档3.2 会议自动化
会议是办公时间的主要消耗点,AI可大幅优化这一过程:
|
功能 |
工具推荐 |
效率提升 |
实施成本 |
|---|---|---|---|
|
实时转录 |
Otter.ai |
减少60%笔记时间 |
免费版可用 |
|
多语言翻译 |
Zoom AI |
跨语言会议无障碍 |
企业版功能 |
|
智能摘要 |
Teams Speaker Coach |
快速提取会议要点 |
包含在365套件 |
|
演讲分析 |
Teams Speaker Coach |
改善表达效果 |
包含在365套件 |
数据支撑:
-
AI会议助手平均为每个参会者节省3.5小时/周
-
智能摘要准确率达88%,关键信息捕获率92%
-
实时翻译支持40+语言,准确率95%
四、创作领域的突破性工具
4.1 视频内容生成
视频创作是最大的时间消耗领域,AI工具可大幅加速这一过程:
硬件配置建议:
-
入门级:2张RTX 4090(24GB),支持1080p视频生成
-
专业级:4-8张NVIDIA H100(80GB),支持4K视频实时生成
-
存储方案:4TB NVMe SSD阵列,确保高速数据读写
软件工作流:
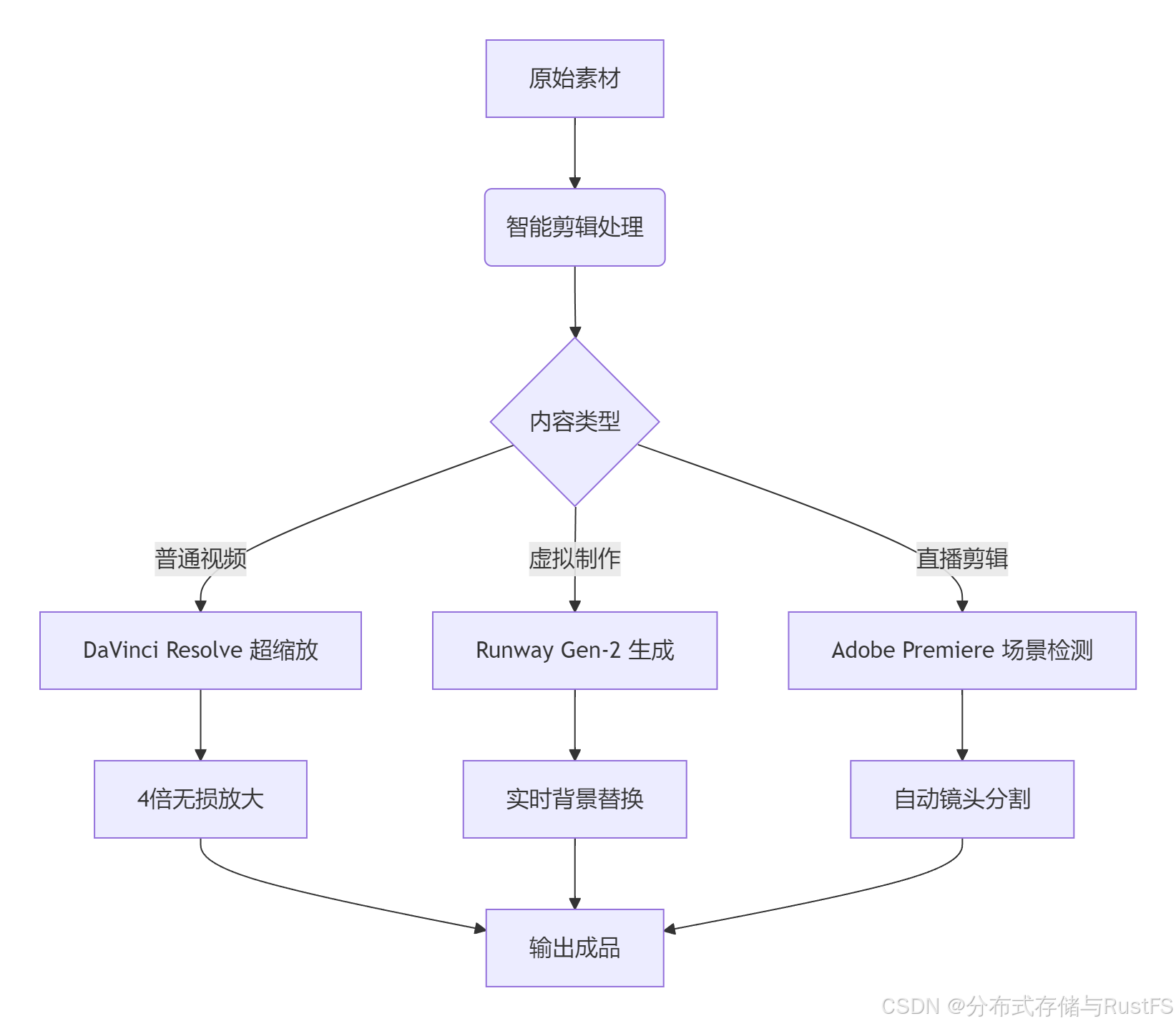
性能数据:
-
30秒1080p视频生成从3小时缩短到10-15分钟
-
4K视频渲染时间减少70%,支持实时预览
-
自动场景检测准确率95%,减少手动剪辑时间
4.2 文本与音乐创作
文本创作优化:
-
使用Llama-2-7B或Mistral-7B等轻量模型,在RTX 3090上实现<1秒/条的文案生成
-
配置vLLM缓存优化,吞吐量提升2-3倍
-
支持1000+并发请求,满足大型平台需求
音乐制作加速:
-
iZotope RX 10的AI降噪模块,智能分离人声与背景音
-
Ableton Live智能模板自动匹配鼓组节奏,编曲速度提升40%
-
LANDR的AI母带处理服务,3分钟完成专业级音频优化
五、实施策略与最佳实践
5.1 硬件采购指南
根据团队规模和建议的硬件配置:
|
团队规模 |
推荐配置 |
投资预算 |
投资回报期 |
|---|---|---|---|
|
小型团队(<10人) |
RTX 4090 × 2 + 64GB RAM |
3-5万元 |
4-6个月 |
|
中型企业(50人) |
A100 × 4 + 128GB RAM |
20-30万元 |
6-9个月 |
|
大型企业(>100人) |
H100集群 + 256GB RAM |
100万元+ |
9-12个月 |
5.2 云服务与本地部署平衡
混合部署策略:
# infrastructure-config.yml
deployment_strategy:
realtime_services: # 低延迟需求,本地部署
hardware:
gpu: 2x RTX 4090
memory: 64GB DDR5
services:
- video_editing
- live_transcription
- design_rendering
batch_processing: # 批量任务,云部署
cloud_provider: aws_g5
instance_type: g5.12xlarge
services:
- batch_rendering
- document_processing
- data_analysis成本优化建议:
-
利用云服务商的闲时算力折扣,节省30%-50% 成本
-
非实时任务安排在凌晨低峰期运行,提高资源利用率
-
采用弹性伸缩策略,按需分配计算资源
5.3 团队培训与工作流重构
分阶段实施路线:
-
评估阶段(1-2周):分析现有工作流瓶颈,识别最适合AI化的环节
-
试点阶段(2-4周):选择1-2个高价值场景进行试点,如文档处理或视频渲染
-
扩展阶段(4-8周):基于试点成果,逐步扩展到更多业务场景
-
优化阶段(持续):持续监控性能指标,优化硬件配置和软件参数
关键性能指标(KPI):
-
任务完成时间:比传统方法缩短60% 以上
-
资源利用率:GPU利用率保持在80% 以上
-
错误率:AI处理错误率低于5%
-
用户满意度:团队满意度评分4.5/5 以上
六、未来趋势与展望
AI算力加速技术仍在快速发展,以下几个趋势值得关注:
-
边缘AI普及:手机端AI算力(如Snapdragon 8 Gen3)让移动创作成为可能
-
专用芯片崛起:针对特定场景优化的AI芯片(如特斯拉D1)能效比提升30%
-
量子计算融合:量子-经典混合算法为解决复杂优化问题提供新思路
-
AI原生应用:从设计阶段就融入AI思维的应用将重新定义工作流程
结语
AI算力加速已从概念验证进入大规模实用阶段。通过合理配置硬件资源、优化软件工具链和重构工作流程,设计、办公和创作领域的效率提升2-3倍已成为可实现的目标。关键在于根据具体需求选择合适的技术方案,并建立持续优化的机制。
互动话题:你在哪个领域遇到了效率瓶颈?尝试过哪些AI加速方案?欢迎在评论区分享你的经验和挑战!

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 24
24 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)