
大模型新手必备AI基础有哪些?AI基础知识、Hugging Face 工具库等
摘要:大模型学习需要扎实的AI基础,主要包括四大模块:1.数学理论(线性代数、概率统计、最优化理论);2.机器学习核心(数据划分、性能评估、经典算法思想);3.深度学习基础(神经网络组件、Transformer架构);4.编程工具链(Python、PyTorch、HuggingFace等)。建议学习路径:先补数学基础,再学机器学习思维,深入理解Transformer架构,最后通过实践项目巩固。掌握
对于大模型领域的新手而言,扎实的 AI 基础是后续深入研究(如模型训练、微调、应用开发)的核心前提。这些基础可分为数学理论、机器学习核心、深度学习基础、编程与工具链四大模块,每个模块都有明确的核心知识点和学习重点,具体如下:
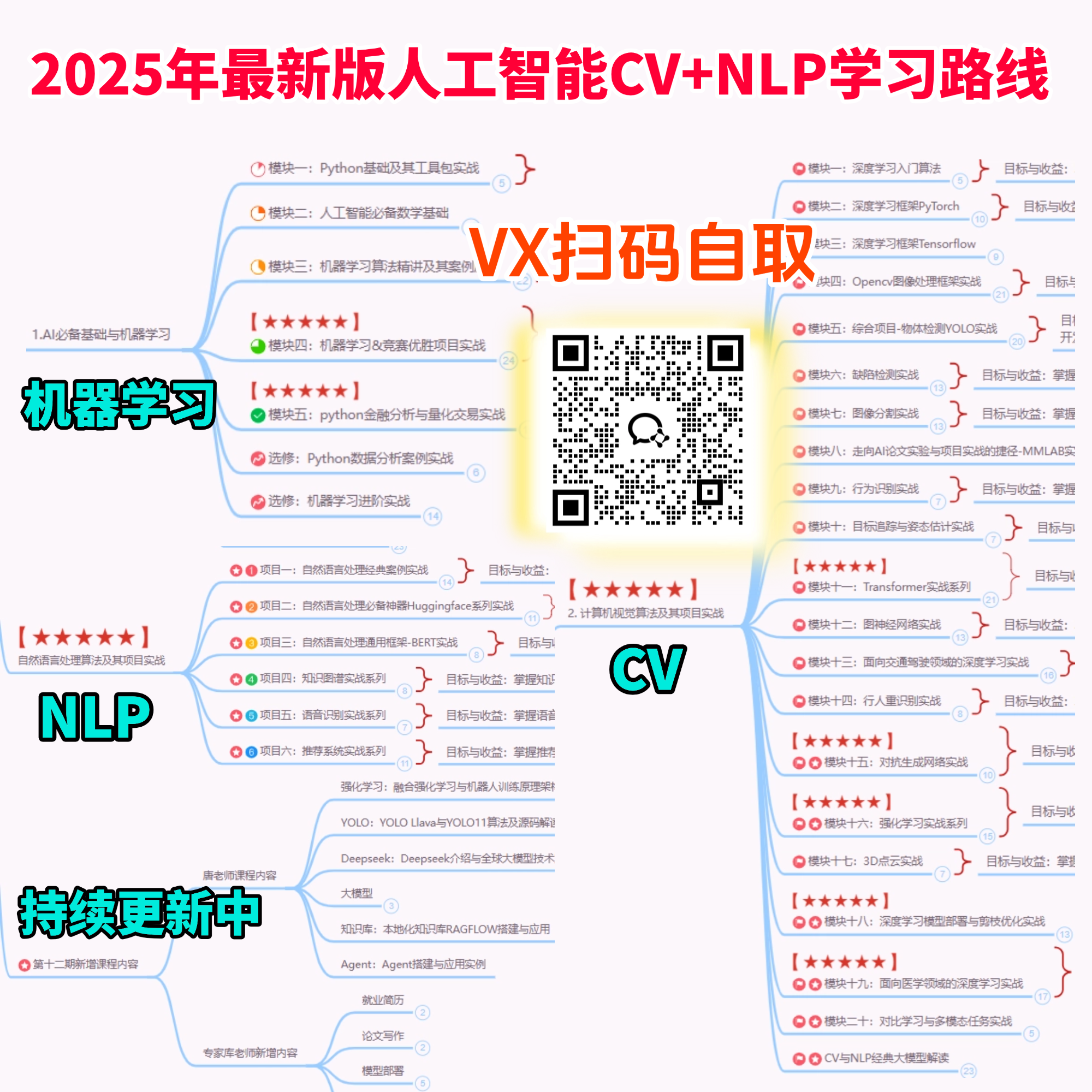

需要大模型全栈学习路线和人工智能入门到实战路线的扫码加助理不要米获取
一、数学理论基础:大模型的 “底层逻辑语言”
数学是 AI 算法设计、模型优化、结果解释的底层支撑,无需追求纯数学的深度,但需掌握 “能用数学解决 AI 问题” 的能力,核心知识点如下:
-
线性代数
- 核心内容:向量(如文本 / 图像的特征向量)、矩阵(如模型权重矩阵)、张量(大模型中多维度数据的存储形式,如
[batch, seq_len, hidden_dim])、矩阵运算(乘法、转置、逆)、特征值与特征向量(PCA 降维、模型特征提取的理论基础)、奇异值分解(SVD,用于数据压缩和特征简化)。 - 为什么重要:大模型的输入处理(如词嵌入向量)、层间计算(如注意力机制中的矩阵乘法)、参数更新(如权重矩阵优化)全依赖线性代数,不懂矩阵运算就无法理解 “模型如何处理数据”。
- 核心内容:向量(如文本 / 图像的特征向量)、矩阵(如模型权重矩阵)、张量(大模型中多维度数据的存储形式,如
-
概率论与数理统计
- 核心内容:概率分布(正态分布、伯努利分布,大模型中初始化参数、噪声处理的依据)、期望与方差(评估模型预测的稳定性)、极大似然估计(模型参数学习的核心思想,如逻辑回归的参数求解)、贝叶斯定理(小样本学习、不确定性量化的基础,如贝叶斯大模型)、熵与交叉熵(损失函数设计的核心,如大模型常用的交叉熵损失)。
- 为什么重要:大模型的本质是 “基于概率的预测模型”(如预测下一个 token 的概率),统计思维能帮助理解 “模型为何会出错”“如何评估模型的置信度”。
-
最优化理论
- 核心内容:梯度下降(大模型训练的核心优化算法,包括 SGD、Adam、AdamW 等变种)、梯度消失 / 爆炸(大模型层数加深后面临的核心问题,理解 BatchNorm、残差连接的设计动机)、凸优化基础(局部最优与全局最优,大模型非凸优化的简化分析)、正则化(L1/L2、Dropout,防止大模型过拟合的关键)。
- 为什么重要:大模型训练的本质是 “最小化损失函数”,最优化理论直接决定 “如何高效、稳定地更新模型参数”,不懂梯度下降就无法理解 “微调大模型时学习率为何不能乱设”。
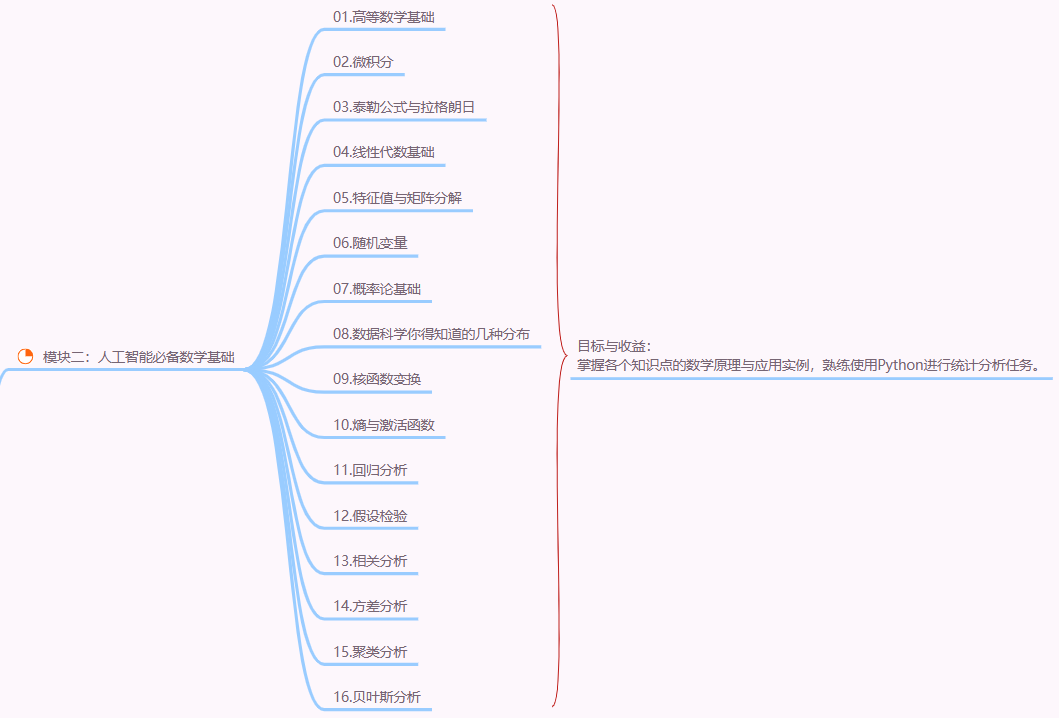
二、机器学习核心:大模型的 “前置方法论”
大模型是机器学习的 “进阶产物”,很多核心思想(如泛化性、过拟合、特征工程)均源自传统机器学习,需先掌握基础框架:
-
核心概念与流程
- 数据划分:训练集、验证集、测试集的作用(避免过拟合,评估模型泛化性)、交叉验证(小样本场景的常用策略)。
- 模型性能指标:分类任务(准确率、 precision、 recall、 F1-score、 AUC-ROC)、回归任务(MAE、 MSE、 RMSE)、大模型特有的指标(Perplexity 困惑度、BLEU、ROUGE,用于文本生成评估)。
- 过拟合与欠拟合:成因(模型复杂度过高 / 过低、数据量不足)、解决方案(正则化、数据增强、早停 Early Stopping)。
-
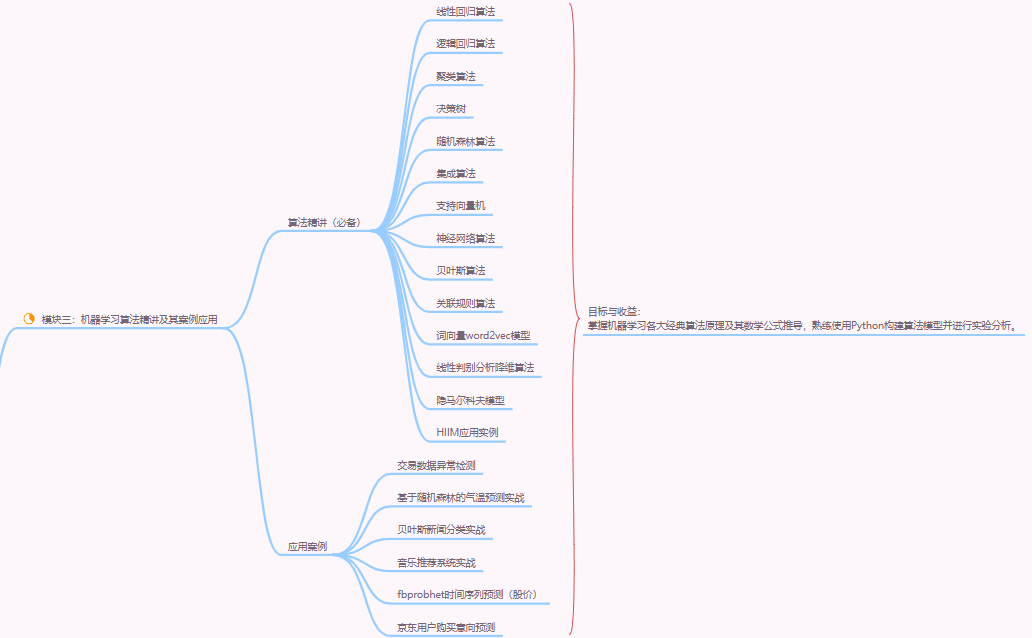
经典算法思想
- 无需深入实现,但需理解 “思想如何迁移到大模型”:
- 决策树 / 随机森林:“特征选择” 思想→大模型中 “注意力权重分配”(关注重要特征);
- 支持向量机(SVM):“最大化分类间隔”→大模型中 “Margin-based 学习”(如对比学习);
- 聚类算法(K-Means):“相似性分组”→大模型中 “文本聚类、模态对齐”(如 CLIP 的图文对齐)。
- 无需深入实现,但需理解 “思想如何迁移到大模型”:
三、深度学习基础:大模型的 “架构与组件”
大模型(如 Transformer、LLaMA、GPT)本质是 “复杂的深度学习网络”,需先掌握深度学习的核心组件和经典架构,再理解大模型的演进:
-
基础网络组件
- 神经网络基本单元:神经元(激活函数的作用,如 ReLU 解决梯度消失、Sigmoid 用于二分类、Softmax 用于多分类)、全连接层(参数过多的问题,理解大模型为何用 “稀疏连接” 优化)。
- 特征提取组件:卷积神经网络(CNN,图像领域的特征提取核心,理解 “局部感受野”→大模型中 “局部注意力”)、循环神经网络(RNN/LSTM/GRU,文本时序数据的早期处理方式,理解 “梯度消失” 问题→Transformer 的设计动机)。
-
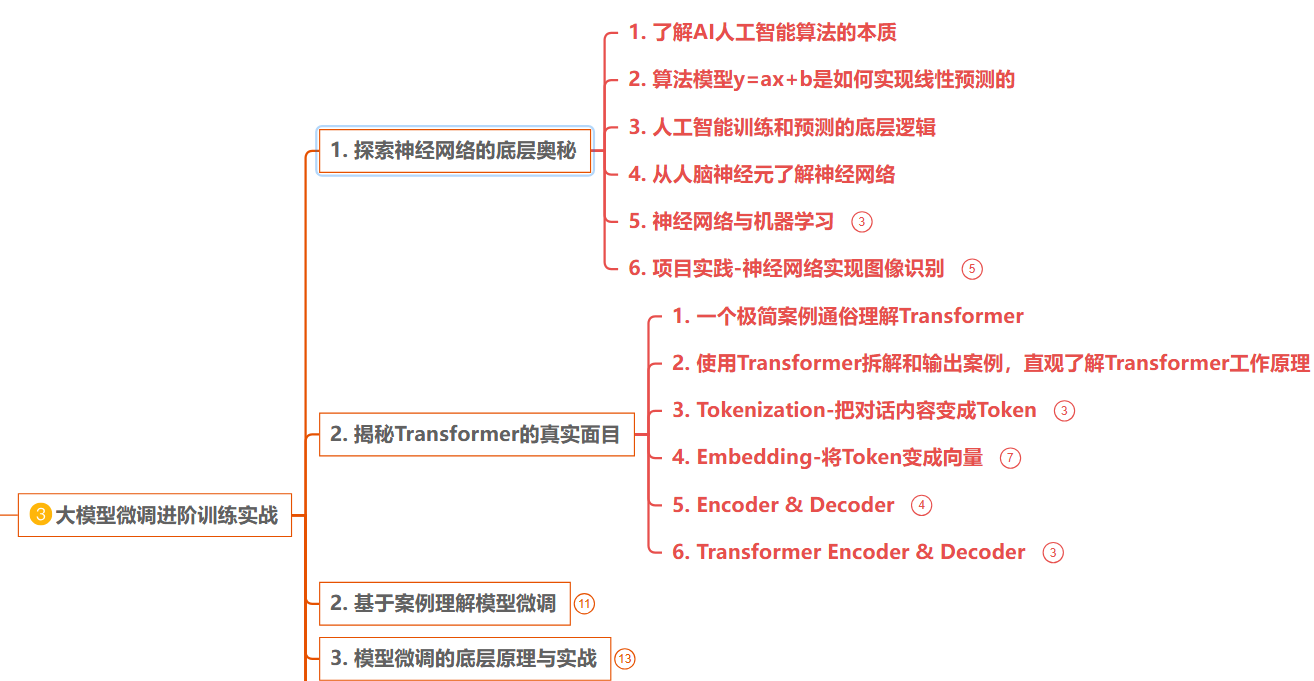
大模型的核心架构:Transformer
- 这是所有现代大模型(GPT、BERT、LLaMA、Diffusion)的基础,必须吃透:
- 注意力机制(Attention):核心是 “计算 Query 与 Key 的相似度,为 Value 分配权重”,解决 RNN “长序列依赖” 问题;重点理解自注意力(Self-Attention)(同一序列内的特征交互,如文本中 “上下文关联”)和多头注意力(Multi-Head Attention)(从多个维度捕捉特征关联)。
- Transformer Encoder/Decoder:Encoder(双向注意力,如 BERT 用于理解任务)、Decoder(单向注意力 + 掩码机制,如 GPT 用于生成任务),以及层归一化(LayerNorm)、残差连接(Residual Connection)的作用(稳定训练,解决深层网络梯度问题)。
- 位置编码(Positional Encoding):Transformer 无时序信息,通过正弦 / 余弦编码或可学习编码,让模型感知序列顺序(如文本中 “词的先后关系”)。
- 这是所有现代大模型(GPT、BERT、LLaMA、Diffusion)的基础,必须吃透:
-
经典预训练模型思想
- 大模型的核心范式是 “预训练 - 微调(Pre-train & Fine-tune)”,需理解早期预训练模型的设计逻辑:
- BERT(双向预训练):通过 “掩码语言模型(MLM)” 和 “下一句预测(NSP)” 学习通用语言表示,为后续大模型的预训练任务(如 GPT 的 “自回归语言建模”)奠定基础。
- CLIP(跨模态预训练):通过 “图文对匹配” 学习跨模态特征对齐,是多模态大模型(如 DALL-E、GPT-4V)的核心思想。
- 大模型的核心范式是 “预训练 - 微调(Pre-train & Fine-tune)”,需理解早期预训练模型的设计逻辑:
四、编程与工具链:大模型的 “实践工具”
理论需落地到代码,新手需掌握 “数据处理 - 模型调用 - 微调训练” 的核心工具,无需从底层造轮子,但需能熟练使用成熟框架:
-
编程语言
- 核心:Python(AI 领域的通用语言,语法简洁,库生态完善)。
- 重点掌握:数据结构(列表、字典、数组)、循环与条件判断、函数定义、类与面向对象(理解模型类的封装逻辑)。
-
数据处理工具
- NumPy:数组运算(大模型输入数据的基础处理,如将文本向量转为 numpy 数组)。
- Pandas:表格数据处理(如大模型训练数据的清洗、筛选、格式转换,如从 CSV 文件读取文本数据)。
- 可视化工具(可选):Matplotlib/Seaborn(绘制模型损失曲线、准确率曲线,分析训练过程)。
-
深度学习框架
- 二选一即可,重点是 “用框架调用 / 微调大模型”,而非底层实现:
- PyTorch:动态计算图,调试友好,生态丰富(Hugging Face Transformers 库基于 PyTorch),是大模型研究的主流框架。
- TensorFlow/Keras:静态计算图,适合工程部署,Google 系模型(如 T5)常用,新手可先学 PyTorch 入门。
- 二选一即可,重点是 “用框架调用 / 微调大模型”,而非底层实现:
-
大模型专用工具库
- Hugging Face Transformers:最核心的库,提供预训练模型(GPT、BERT、LLaMA 等)的调用、微调接口,一行代码即可加载模型,新手必学。
- Hugging Face Datasets:处理大模型训练数据的库,提供海量公开数据集(如 GLUE、C4),支持数据加载、预处理、格式转换。
- 加速工具(可选):DeepSpeed/FairScale(解决大模型训练的显存不足问题,实现模型并行、数据并行)。
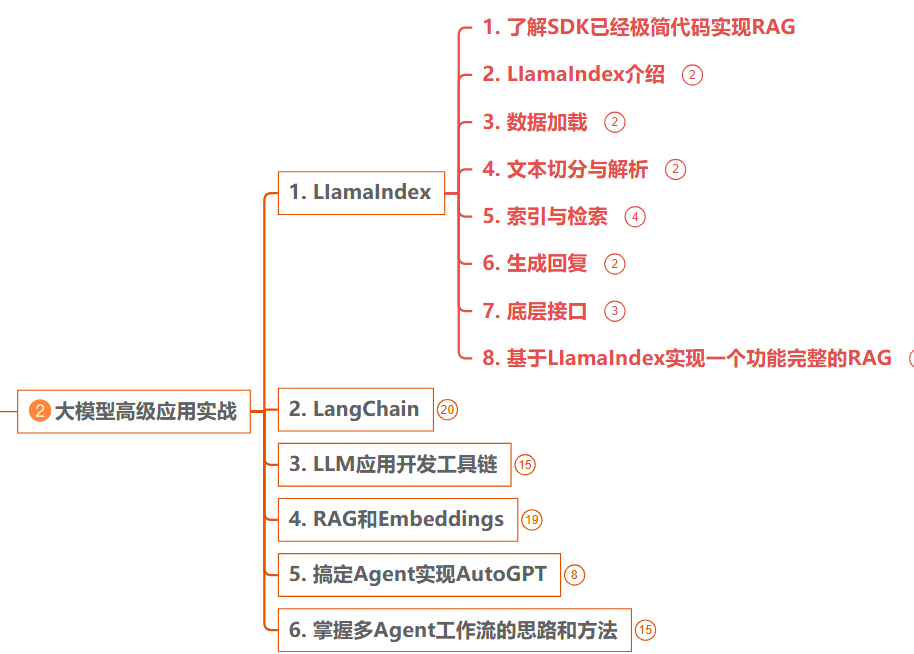
总结:新手的学习路径建议
- 先补数学:重点攻克 “线性代数(矩阵运算)+ 概率论(交叉熵)+ 最优化(梯度下降)”,无需啃纯数学教材,可结合 AI 应用场景学习(如《深度学习数学》)。
- 再学机器学习:理解 “数据划分、过拟合、性能指标”,用 Scikit-learn 库做简单实验(如训练一个逻辑回归模型),建立 “机器学习思维”。
- 深入深度学习:重点吃透 “Transformer 架构(注意力机制、Encoder/Decoder)”,用 PyTorch 实现简单的 Transformer 模块,理解大模型的核心组件。
- 动手实践:用 Hugging Face Transformers 调用预训练模型(如用 GPT-2 生成文本、用 BERT 做文本分类),再尝试微调小模型(如在自定义数据集上微调 BERT),积累实践经验。
通过以上基础的积累,新手能快速理解大模型的原理、训练逻辑和应用场景,为后续深入研究(如大模型优化、多模态大模型、大模型部署)打下坚实基础。
大模型全流程学习路径+60G学习干货包
论文指导+技术答疑+做项目
关zhuV.X服务号:大模型星球 发送:211C 自取
资料包:1、Agent多模态大模型视频及课件
2、ChatGLM、LLM、LangChain、llama3等教程,微调部署落地
3、Transformer、BERT、Huggingface三大基础模型
4、大模型前沿论文+书籍+路线图
5、最新大模型大厂面试题库、转型简历包装
6、李宏毅等名师视频合集

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 10
10 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)