AI工具全景深度解析:从代码助手到模型训练的全链路实践
AI工具链正成为推动人工智能应用落地的关键力量。本文系统介绍了三大核心AI工具:智能编码工具GitHub Copilot基于Codex模型实现代码自动生成与补全;数据标注工具Label Studio支持多模态数据标注并提升数据质量;云端训练平台如Colab和SageMaker提供一站式模型开发环境。通过工具链整合,可构建从数据标注到模型部署的自动化流水线,显著提升AI开发效率。这些工具降低了AI应
引言
人工智能(AI)已不再是遥不可及的未来科技,而是渗透到各行各业的核心生产力工具。这一变革的背后,是一系列强大且易用的AI工具链的成熟。它们极大地降低了AI技术应用的门槛,使开发者、数据科学家甚至业务专家都能高效地构建和部署智能应用。本文将深入探讨三大关键领域的AI工具:智能编码工具(以GitHub Copilot为例)、数据标注工具 和 模型训练平台。我们将通过理论阐述、代码实战、流程图解和丰富示例,为您呈现一幅完整的AI工具应用图谱。
第一章:智能编码工具 - GitHub Copilot 深度探秘
智能编码工具,通常基于大型语言模型(如OpenAI的Codex),能够理解自然语言注释和代码上下文,为开发者提供代码补全、函数建议、甚至生成整个代码块的能力。它们就像是坐在你身边的资深编程专家,时刻准备提供帮助。
1.1 核心原理与技术栈
GitHub Copilot 的核心是OpenAI的Codex模型,该模型是在数十亿行公开代码上进行训练的。其工作流程可以概括为:
-
上下文感知: Copilot 会读取你当前编辑的文件内容,包括注释、函数名、变量名以及已编写的代码。
-
模式识别: 基于训练数据,模型识别出你的编程意图和当前代码所遵循的模式。
-
代码生成: 模型生成最有可能的代码续写方案,通常提供多个选项供开发者选择。
下面的Mermaid流程图清晰地展示了开发者与Copilot的交互过程:
graph TD
A[开发者编写代码/注释] --> B(Copilot 分析上下文)
B --> C{模型生成建议}
C --> D[显示灰色建议文本]
D --> E{开发者选择}
E -->|接受 (Tab)| F[代码插入编辑器]
E -->|拒绝 (Esc)| G[建议被忽略]
E -->|查看备选 (Alt+[ / ])| H[循环显示其他建议]
H --> E
F --> A
G --> A
1.2 实战演练:Copilot 在多种场景下的应用
让我们通过几个具体的代码示例来感受Copilot的强大。
Prompt 示例 1: 从注释生成函数
假设我们需要一个Python函数来验证电子邮件地址的格式。
-
开发者输入(注释):
python
# Write a function to validate an email address using regex
-
Copilot 可能生成的建议:
python
import re def validate_email(email): pattern = r'^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$' if re.match(pattern, email): return True else: return False只需按下
Tab键,这段完整的、符合标准的正则表达式验证函数就生成了。
Prompt 示例 2: 代码补全与逻辑推断
当你开始编写一个常见模式(如循环)时,Copilot 能快速补全。
-
开发者输入:
python
numbers = [1, 2, 3, 4, 5] squared_numbers = [] for num in numbers:
-
Copilot 可能生成的建议:
python
squared_numbers.append(num ** 2)
它准确地推断出你想计算每个数的平方。
Prompt 示例 3: 单元测试生成
Copilot 不仅可以写实现代码,还能生成测试代码。
-
开发者输入(在
test_email.py文件中):python
from email_validator import validate_email # Test the validate_email function
-
Copilot 可能生成的建议:
python
def test_valid_email(): assert validate_email('test@example.com') == True def test_invalid_email_no_at(): assert validate_email('invalid.example.com') == False def test_invalid_email_no_domain(): assert validate_email('invalid@') == False
1.3 最佳实践与注意事项
-
编写清晰的注释: 意图越明确,生成代码的质量越高。使用类似“写一个函数...”、“计算...”等清晰指令。
-
迭代式优化: 不要期望第一次生成就完美。可以接受初步建议,然后通过更具体的注释进行修正。例如,生成函数后,再写注释
# now add a docstring to this function。 -
代码审查至关重要: Copilot 生成的代码可能包含过时的API、安全漏洞或不完全符合项目规范。必须像审查人类代码一样仔细审查AI生成的代码。
-
注意许可证问题: Copilot 可能生成与训练数据中相似甚至相同的代码片段。对于敏感项目,需注意潜在的版权问题。
第二章:数据标注工具 - 模型训练的基石
如果说模型是AI的大脑,那么高质量的数据就是其营养。数据标注是为原始数据(如图片、文本、音频)打上标签的过程,是监督学习不可或缺的一环。数据标注工具旨在提升这一过程的效率和一致性。
2.1 工具分类与核心功能
数据标注工具多种多样,主要分为以下几类:
-
计算机视觉: 用于图像和视频的标注,支持边界框、多边形、关键点、语义分割等。
-
代表工具:LabelImg, CVAT, LabelStudio, VGG Image Annotator (VIA)
-
-
自然语言处理: 用于文本分类、命名实体识别(NER)、情感分析、关系抽取等。
-
代表工具:LabelStudio, Prodigy, Doccano, BRAT
-
-
音频处理: 用于语音转写、声音事件检测、说话人识别等。
-
代表工具:Audacity, Praat, LabelStudio
-
一个优秀的标注工具通常具备以下功能:
-
直观的用户界面: 降低标注人员的操作难度。
-
项目管理: 支持多用户、多项目协作。
-
标签管理: 方便地创建和管理标签体系。
-
自动化辅助: 集成预训练模型进行预标注,大幅提升效率。
-
数据导出: 支持多种格式(如COCO, Pascal VOC, JSONL)以适配不同训练框架。
2.2 实战演练:使用 LabelStudio 进行文本分类
我们以功能强大且开源的 LabelStudio 为例,演示如何搭建一个文本情感分类的标注项目。
步骤 1: 安装与启动
bash
pip install label-studio label-studio start
访问 http://localhost:8080 即可看到Web界面。
步骤 2: 创建项目
-
点击 "Create Project"。
-
输入项目名称,如 "Movie Review Sentiment Analysis"。
-
在 "Data Import" 选项卡中,上传一个包含电影评论的文本文件(每行一条评论),或直接粘贴文本。
步骤 3: 配置标注模板
这是核心步骤。在 "Labeling Setup" 中,选择 "Custom Template" 并输入以下XML格式的配置代码:
xml
<View>
<Header value="Please read the text and choose its sentiment:"/>
<Text name="text" value="$review"/>
<Choices name="sentiment" toName="text" choice="single">
<Choice value="Positive"/>
<Choice value="Negative"/>
<Choice value="Neutral"/>
</Choices>
</View>
这个界面定义了一个简单的文本分类任务,标注者需要从 Positive, Negative, Neutral 三个单选项中选择一个。
步骤 4: 进行标注
保存模板后,进入标注界面。系统会逐条展示未标注的评论,标注员阅读后点击相应选项即可提交。
步骤 5: 导出数据
标注完成后,在 "Data Manager" 中可以选择已完成的任务,并导出为JSON、CSV等格式。导出的JSON格式可能如下:
json
{
"id": 1,
"annotations": [
{
"result": [
{
"value": {
"choices": ["Positive"]
},
"from_name": "sentiment",
"to_name": "text",
"type": "choices"
}
]
}
],
"data": {
"review": "This movie is a fantastic masterpiece with brilliant performances!"
}
}
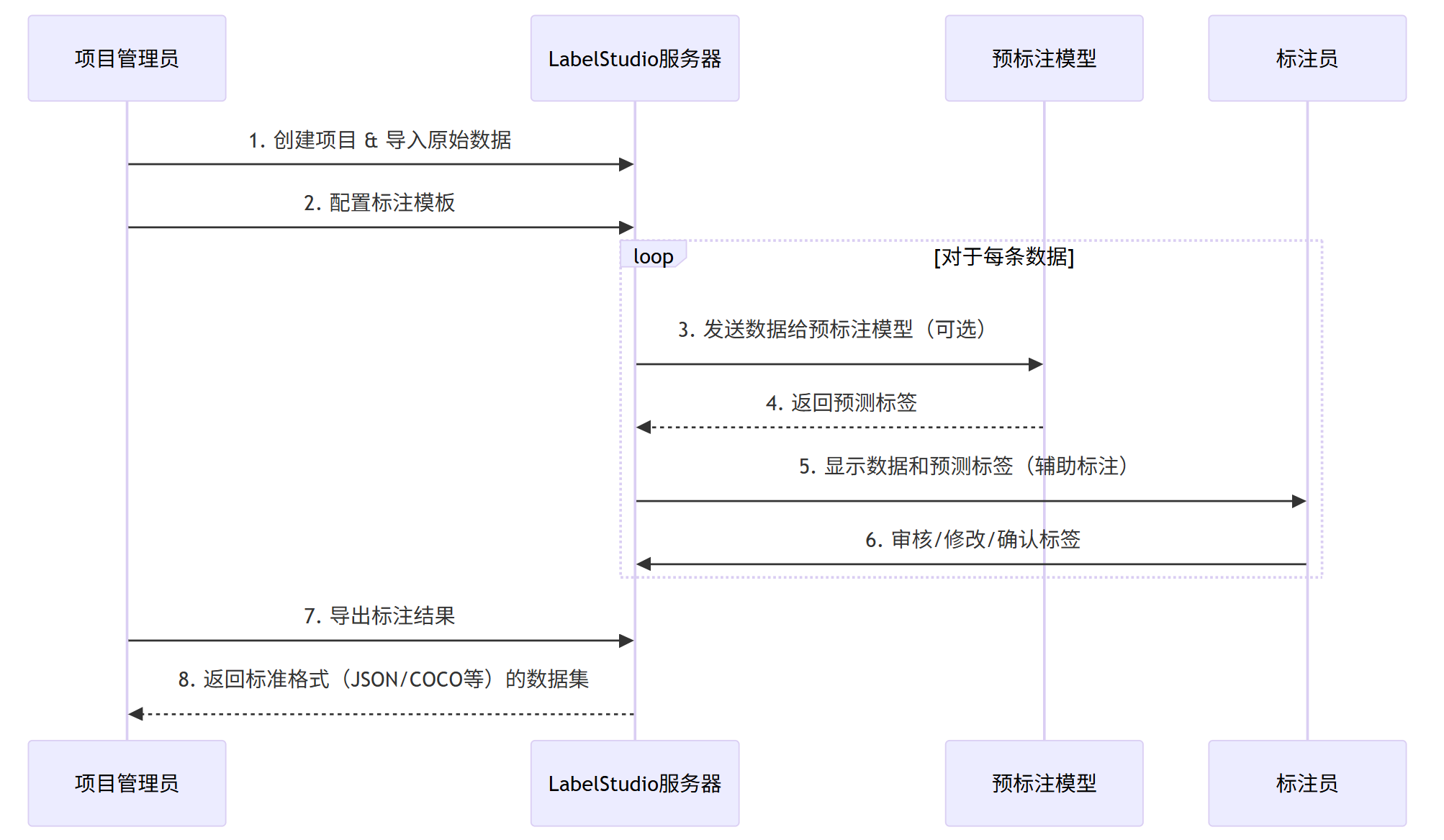
下面的Mermaid序列图展示了一个完整的、可能集成预标注模型的标注流水线:
sequenceDiagram
participant A as 项目管理员
participant LS as LabelStudio服务器
participant M as 预标注模型
participant L as 标注员
A->>LS: 1. 创建项目 & 导入原始数据
A->>LS: 2. 配置标注模板
loop 对于每条数据
LS->>M: 3. 发送数据给预标注模型(可选)
M-->>LS: 4. 返回预测标签
LS->>L: 5. 显示数据和预测标签(辅助标注)
L->>LS: 6. 审核/修改/确认标签
end
A->>LS: 7. 导出标注结果
LS-->>A: 8. 返回标准格式(JSON/COCO等)的数据集
2.3 提升标注效率的策略
-
预标注(Pre-annotation): 利用一个已有的、哪怕是精度不高的模型对数据进行初步标注,标注员只需进行修正,可比从零开始快数倍。LabelStudio 支持接入 Hugging Face 等模型的API。
-
清晰的标注指南: 避免歧义。例如,明确界定“Neutral”和“Positive”的界限。
-
质量监控与交叉验证: 将同一份数据分给多个标注员,通过计算Kappa系数等指标评估标注一致性,及时发现并解决问题。
第三章:模型训练平台 - 云端算力与自动化流水线
当数据和算法准备就绪后,我们需要强大的计算资源来训练模型。模型训练平台提供了从环境配置、实验管理、大规模训练到模型部署的一站式解决方案。
3.1 平台类型与核心价值
-
本地框架: 如 PyTorch, TensorFlow。提供最大灵活性,但需要自行配置硬件和环境。
-
云端Notebook平台: 如 Google Colab, Kaggle Notebooks。提供开箱即用的环境,适合快速原型设计和学习。
-
成熟的MLOps平台: 如 Amazon SageMaker, Google Vertex AI, Azure Machine Learning, Hugging Face Spaces。提供端到端的机器学习生命周期管理。
核心价值:
-
可扩展性: 轻松使用多GPU、多节点进行分布式训练。
-
可复现性: 精确记录每次实验的代码、数据、参数和结果。
-
自动化: 自动化超参数调优、模型选择和部署。
-
协作性: 团队共享数据集、模型和实验记录。
3.2 实战演练:在 Google Colab 上微调 Hugging Face transformers 模型
我们将以一个经典的文本分类任务为例,展示如何在Colab上快速微调一个预训练模型。假设我们已有一个关于新闻标题的数据集,需要将其分类到“体育”、“科技”、“财经”等类别。
步骤 1: 环境设置
在Colab中,首先确保使用GPU运行时(Runtime -> Change runtime type -> GPU)。
python
# 安装必要的库
!pip install transformers datasets torch
# 检查GPU
import torch
print(f"GPU available: {torch.cuda.is_available()}")
print(f"GPU name: {torch.cuda.get_device_name(0)}")
步骤 2: 加载与预处理数据
我们使用 Hugging Face datasets 库来加载数据。这里假设数据已准备好。
python
from datasets import load_dataset
# 示例:从本地JSON文件加载
dataset = load_dataset('json', data_files='news_data.json')
# 或者从Hugging Face Hub加载示例数据集
# dataset = load_dataset('ag_news')
# 查看数据集结构
print(dataset['train'][0])
# 定义标签映射
id2label = {0: "Sports", 1: "Tech", 2: "Finance"}
label2id = {"Sports": 0, "Tech": 1, "Finance": 2}
步骤 3: 数据预处理(Tokenization)
使用预训练模型对应的分词器将文本转换为模型可接受的数字ID。
python
from transformers import AutoTokenizer
model_ckpt = "distilbert-base-uncased" # 选择一个轻量级模型,适合Colab环境
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True, max_length=128)
# 应用分词函数到整个数据集
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# 格式化以适配PyTorch
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
tokenized_datasets.set_format("torch", columns=["input_ids", "attention_mask", "labels"])
步骤 4: 加载预训练模型并配置训练器
python
from transformers import AutoModelForSequenceClassification, TrainingArguments, Trainer
# 加载模型,指定分类标签数量
model = AutoModelForSequenceClassification.from_pretrained(
model_ckpt,
num_labels=len(id2label),
id2label=id2label,
label2id=label2id
)
# 定义训练参数
training_args = TrainingArguments(
output_dir="./news_classifier_results", # 输出目录
evaluation_strategy="epoch", # 每个epoch后评估
save_strategy="epoch", # 每个epoch后保存
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=3,
weight_decay=0.01,
logging_dir='./logs', # 日志目录
report_to="none", # 在Colab中禁用wandb等
)
# 定义评估指标
from sklearn.metrics import accuracy_score
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return {"accuracy": accuracy_score(labels, predictions)}
# 创建Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"], # 确保数据集中有验证集
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
步骤 5: 开始训练与评估
python
# 开始训练!
trainer.train()
# 训练完成后,在测试集上评估
eval_results = trainer.evaluate(tokenized_datasets['test'])
print(eval_results)
# 保存模型
trainer.save_model("./my_final_news_classifier")
3.3 进阶:MLOps平台的核心概念 - 流水线(Pipeline)
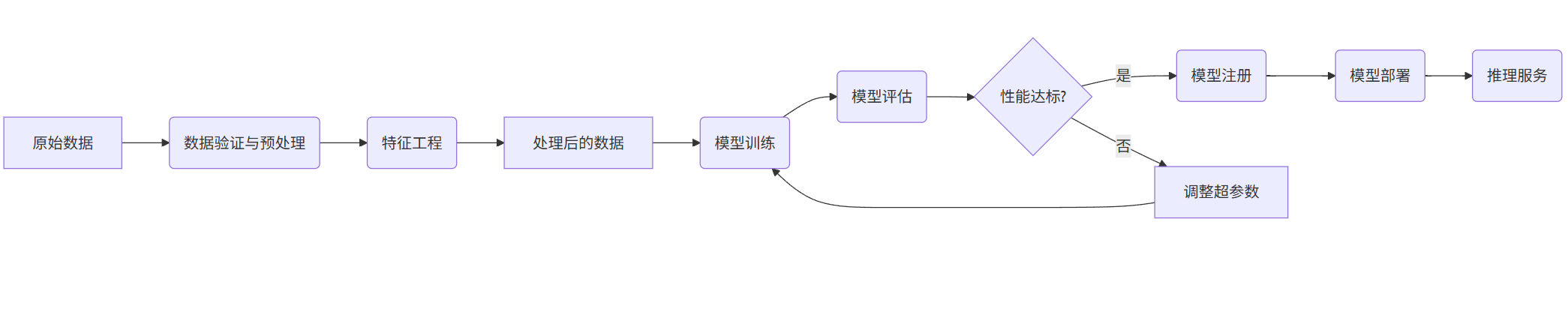
在SageMaker、Vertex AI等平台上,工作流通常被抽象为可重复执行的流水线。下图展示了一个典型的ML流水线架构:
graph LR
A[原始数据] --> B(数据验证与预处理)
B --> C(特征工程)
C --> D[处理后的数据]
D --> E(模型训练)
E --> F(模型评估)
F --> G{性能达标?}
G -->|是| H(模型注册)
G -->|否| I[调整超参数] --> E
H --> J(模型部署)
J --> K(推理服务)
-
自动化: 一旦流水线定义完成,只需触发即可自动运行所有步骤。
-
条件执行: 如上图,只有当模型性能达标时,才会推进到注册和部署阶段。
-
版本控制: 流水线的每次运行、产生的模型和数据都有版本记录,确保完全可追溯。
第四章:工具链整合 - 构建高效的AI工作流
单独使用每个工具已经能带来效率提升,但将它们整合成一个自动化工作流,才能发挥最大威力。
4.1 一个整合的AI项目生命周期
-
构思与原型设计:
-
工具: GitHub Copilot。
-
活动: 开发者利用Copilot快速编写数据加载、模型原型和评估脚本。Prompt示例:
# Write code to load a CSV dataset using pandas and split it into train and test sets.
-
-
数据准备与标注:
-
工具: LabelStudio。
-
活动: 如果数据需要标注,在LabelStudio中创建项目,组织团队完成标注。利用预标注模型加速。导出为标准格式。
-
-
模型训练与实验:
-
工具: 模型训练平台(如Colab用于实验,SageMaker用于生产)。
-
活动: 将标注好的数据上传至平台,运行训练脚本(可能由Copilot辅助生成)。系统记录所有实验参数和结果。
-
-
模型部署与监控:
-
工具: MLOps平台(如SageMaker, Vertex AI)。
-
活动: 将最佳模型部署为API端点。监控其线上性能(如预测延迟、准确率漂移)。
-
4.2 整合示例:从标注到部署的简化流水线
假设我们有一个项目:构建一个识别商品图片中品牌的模型。
-
数据标注(LabelStudio): 标注员在LabelStudio中为商品图片绘制边界框并选择品牌标签。导出为COCO格式的
annotations.json。 -
代码开发(VS Code + Copilot): 开发者编写训练脚本。
-
Prompt:
# Using PyTorch and torchvision, load a COCO format dataset for object detection. -
Copilot 可能会生成使用
torchvision.datasets.CocoDetection的代码片段。
-
-
模型训练(Google Colab / SageMaker): 将
annotations.json和图片上传到训练平台,运行训练脚本。平台自动分配GPU资源,输出训练好的模型文件(.pth)。 -
模型部署(SageMaker): 将模型文件打包成一个Docker镜像,并部署为可调用的推理服务。
这个流程中的每一步都可以通过脚本和API调用串联起来,形成自动化流水线。
结论
AI工具生态的繁荣是AI民主化进程的关键。GitHub Copilot 等智能编码工具将开发者从重复性编码中解放出来,专注于架构和逻辑;LabelStudio 等数据标注工具确保了模型“食粮”的质量与供给效率;而 Colab、SageMaker 等模型训练平台则提供了强大且便捷的算力与流程管理支持。
这些工具各自独立强大,但它们的真正潜力在于协同工作。通过将智能编码、高效标注和规模化训练无缝衔接,我们能够构建起一条敏捷、可靠、可复现的AI生产流水线。这不仅极大地加快了从想法到产品的迭代速度,也使得更多缺乏顶尖技术背景的团队能够拥抱和应用人工智能,最终推动整个社会的智能化转型。
未来,随着多模态模型、低代码/无代码平台的进一步发展,AI工具链将变得更加智能、集成和易用,进一步模糊技术与应用之间的界限,释放出前所未有的创造力。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 7
7 0
0- 0



 已为社区贡献54条内容
已为社区贡献54条内容

所有评论(0)