
快手KAT-Coder模型实战:从实验页面到权限系统,AI编程能力全面解析!
文章介绍了快手KAT-Coder模型的三个版本及三阶段训练过程,通过N-Back实验、合同信息抽取和登录权限验证等实际场景测试了模型性能。结果表明,该模型在日常代码开发和demo演示中表现良好,适合快速实现功能,但复杂代码仍需人工架构设计。作者认为快手在大模型领域发展迅速,值得期待。
这两天看到不少好友都分享了快手的新KAT-Coder模型,也有群友问了,周六正好有时间咱们测测看。
我是上个月的时候,其实,有测过他们一个版本模型的效果,当时还不太支持Cline、Roo Code,只能Claude Code,
没想到一个月不到的时间,又更新了新的版本。
感觉最近老铁厂,真是猛猛在发力,各个方向都在卷呀,前段时间刚搞了多模态理解模型,见Keye-VL1.5 8B多模态模型,然后又卷起Coding模型来了。
先来说一些快手的Coding模型,有三个,KAT-Coder-Pro V1是闭源版本模型,KAT-Coder-Air V1和KAT-Coder-EXP-72B是前阵子开源的两个模型,分别是KAT-Dev-32B和KAT-Dev-72B。
PS:KAT-Coder-Air V1这个模型免费随便用,KAT-Coder-Pro V1送2000万 Tokens。
咱们还是老规矩,先看看模型中的一些细节,再来点实测给大家看看。
模型的整体训练分为3个阶段,Mid-Training、SFT&RFT、Agentic RL Scaling。
- Mid-Training:主要增强了模型Agent相关的综合能力,例如:指令遵循、工具使用、多轮交互、代码知识注入、Git提交&PR、通用&推理能力。
- SFT&RFT:在SFT阶段,收集了8种用户常用任务以及8种常见的code场景;在RFT阶段,引入多个ground truth,提高 rollout 的效率,提升 RL 阶段的效率与稳定性。

- Agentic RL Scaling:通过熵引导树剪枝 + SeamlessFlow 异构调度,先海量轨迹压成前缀树,按熵与访问概率排序,在预算内只展开高信号节点,同时把训练与智能体逻辑彻底解耦,零气泡跑满集群,提高整体训练效率。
SWE榜单效果如下:
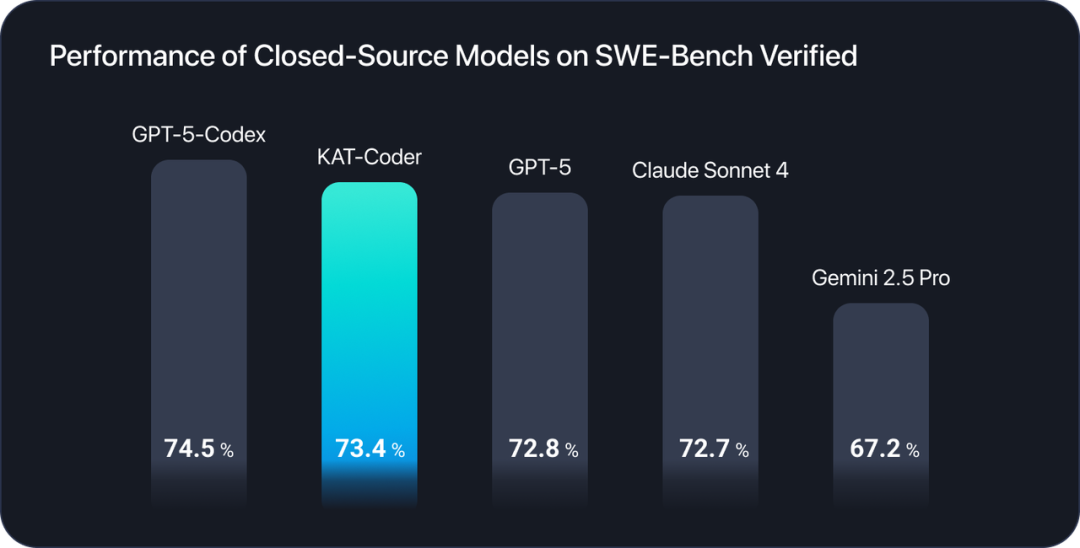
下面开始测试,
怎么配置Claude Code啥的我就不讲了,基本上都一致,可以看看我之前的文章,或者直接看官方配置文档也可以,
https://www.streamlake.com/document/WANQING/me6ymdjrqv8lp4iq0o9
我上周在好友@卡兹克的“一起AI交个朋友”的交流会上,分享了一些心得,
当时有一个内容就提到,我之前做脑电信号,研究阿尔兹海默症的时候,有过做过一个N-Back实验,当时实现七七八八花了一个月。
咱们看看KAT-Coder效果怎么样,提示词如下:
你需要实现一个N-Back实验页面,N-Back实验的原理是,每隔1s闪烁一张图片,让用户判断当前的图片与前面第N张图片是否一致,一致选择是,不一致选择否。其中,图片为常见的10个中文汉字,["国", "火", "道", "市", "天", "家", "理", "态", "至", "心"]界面需要每次开始时,选N的值,选择为2,3,4,三种。需要用户点击30次,也就是不同N值时展现的图片个数不同,例如N=2,则需要32张图片,当第三张出现时,提醒用户开始点击。你需要记录两个内容,一个是用户点击是否准确,一个是出现图像到用户点击之间的时间,最后给出点击准确率和反应时间。注意:图片展示只有15次是N-back正确内容,防止实验过难或过于简单。实验过程,如果正确让用户点击“A”键,错误让用户点击“L”键。同时界面必须符合现代审美,实验结果可以导出下载。
整体来看效果很不错,代码是一边成,整体的校验逻辑,计时、准确率都没问题,真羡慕现在的学生。10年前,谁敢想现在ai coding能这么强呀。
还有,前两天,有个真实需求,就是要做合同的关键信息抽取,核心模块是抽取,这个是我的强项,但是只给用户excel表格的话,在这个ai时代,太low了。
所以但是就vibe了一个,我们来看看KAT-Coder效果如何。
帮我实现一个合同信息抽取功能页面,你需要支持上传一个合同文件,这里包括docx和pdf格式,然后抽取文件中的甲方、乙方、甲方地址、乙方地址、合同编号、合同签署日期、合同签署地点、合同总金额等信息,所以抽取内容需要在文件展示的右侧进行逐条展示,核心是要支持原文关键信息定位,点击抽取信息即可定位对照原文,原文处高亮显示,如抽取错误可框选校正或手动编辑校正。
有点东西的,还帮我把抽取内容和原文内容做了链接,让我没想到,整体美观度啥的还不错,作为demo演示来说足够用了
我们再增加点难度,在写一套登录权限验证机制。
你需要增加权限登录机制,有注册和登录,同时你需要后台存储注册信息,注册需要邮箱和密码,登录也是需要邮箱和密码。
整体登录没有问题,有注册、有登录、有登出,很完美,我只需要写好prompt,然后等着就好了。
当然还有一些其他的case,我在这里就不过多展示了。
比如生成的网页版 Windows,记事本、画板、计算器啥的都能用,还是很强的。
这次快手的升级,比我前一个月体验下来,体感提高了很多,用起来也很丝滑,一些日常的代码开发任务、写写demo演示,这都足够了,
vibe一时爽,一直vibe一直爽,哈哈哈~
不过,太复杂的代码,本身现在vibe coding就存在一些问题,
我也经常被问一些问题,比如,
debug时候最痛苦,经常一顿操作猛如虎,花了很多token,但核心问题不解决,而是解决test脚本,
程序内重复和冗余非常大,核心代码几十行,却配着上千行的容错
逻辑不清晰,像几十个员工依次接手一个项目 等等等。
PS:这不是一家模型的问题,针对的是在座的各位,哈哈哈!复杂代码还是需要实现做好架构的,你可以理解为模型是一个实习生,帮你快速实现一些东西,不要过度依赖。
最后,快手最近的变化也是蛮快的,
回想一下,貌似2023年的大模型厂,依然坚挺的只剩下那么几个,其他的几乎没有什么声音了,
反而是2025年,冒出了一些新厂商,而且再搞大模型的时候,都具有不同的特色,
不知道,后面快手还有什么动作,反正我蛮期待的!
0基础怎么学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 15
15 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)