
自动化代码生成、低代码/无代码开发与算法优化实践
AI编程技术正在推动软件开发领域的革命性变革。文章从自动化代码生成、低代码/无代码开发和算法优化三大方向,全面阐述了AI编程的技术原理与应用实践。通过案例代码展示了注释生成代码、智能补全等技术实现,并详细解析了低代码平台的架构设计和可视化开发流程。在算法优化方面,重点介绍了超参数调优、神经网络架构搜索等自动化技术。文章还探讨了智能客服系统等综合应用案例,并分析了未来发展趋势与面临的代码质量、安全性
1. 引言:AI编程的革命性变革
在人工智能技术飞速发展的今天,编程领域正在经历一场深刻的革命。AI编程不仅改变了传统软件开发的方式,更在自动化代码生成、低代码/无代码开发以及算法优化等领域展现出巨大潜力。根据Gartner的预测,到2025年,70%的新应用程序将由低代码或无代码技术开发,而其中50%将集成AI能力。
1.1 AI编程的定义与范畴
AI编程是指利用人工智能技术辅助或自动化软件开发过程的方法论和实践。它涵盖三个主要方向:
-
自动化代码生成:通过AI模型根据需求描述、示例或规范自动生成可执行代码
-
低代码/无代码开发:通过可视化界面和配置代替传统编码,降低开发门槛
-
算法优化实践:利用AI技术自动优化现有算法性能,提高效率和资源利用率
这些技术的融合正在重新定义软件开发的边界,使更多人能够参与创造数字解决方案,同时提高专业开发者的生产力。
2. 自动化代码生成:从理论到实践
2.1 自动化代码生成的技术原理
自动化代码生成基于深度学习中的序列到序列(Seq2Seq)模型和Transformer架构。这些模型通过分析海量代码库学习编程语言的语法、语义和常见模式。
python
import torch
import torch.nn as nn
from transformers import GPT2LMHeadModel, GPT2Tokenizer
class CodeGenerator:
def __init__(self, model_name="microsoft/CodeGPT-py"):
self.tokenizer = GPT2Tokenizer.from_pretrained(model_name)
self.model = GPT2LMHeadModel.from_pretrained(model_name)
self.model.eval()
def generate_code(self, prompt, max_length=100, temperature=0.7):
inputs = self.tokenizer.encode(prompt, return_tensors="pt")
with torch.no_grad():
outputs = self.model.generate(
inputs,
max_length=max_length,
temperature=temperature,
num_return_sequences=1,
pad_token_id=self.tokenizer.eos_token_id,
do_sample=True
)
generated_code = self.tokenizer.decode(outputs[0], skip_special_tokens=True)
return generated_code
# 使用示例
generator = CodeGenerator()
prompt = """
# 使用Python实现快速排序算法
def quicksort(arr):
"""
generated_code = generator.generate_code(prompt, max_length=150)
print(generated_code)
2.2 自动化代码生成的典型应用
2.2.1 基于注释的代码生成
python
# 使用OpenAI Codex API生成代码示例
import openai
def generate_function_from_docstring(description):
response = openai.Completion.create(
engine="code-davinci-002",
prompt=f"\"\"\"\n{description}\n\"\"\"\n",
max_tokens=150,
temperature=0.5
)
return response.choices[0].text.strip()
# 示例:根据描述生成函数
description = """
计算斐波那契数列的第n项
参数:
n: 整数,要计算的项数
返回:
斐波那契数列的第n项
"""
generated_function = generate_function_from_docstring(description)
print(generated_function)
2.2.2 代码补全与建议
javascript
// 智能代码补全示例 - 使用VS Code API
class IntelligentCodeCompletion {
constructor() {
this.suggestions = [];
this.context = {};
}
async getCompletions(document, position) {
const textBeforeCursor = document.getText(
new Range(new Position(0, 0), position)
);
// 分析上下文,获取智能建议
const context = this.analyzeContext(textBeforeCursor);
this.suggestions = await this.fetchAICompletions(context);
return this.suggestions.map(suggestion => ({
label: suggestion.code,
kind: suggestion.type,
detail: suggestion.description,
insertText: suggestion.code
}));
}
analyzeContext(code) {
// 解析代码结构,识别当前上下文
return {
imports: this.extractImports(code),
variables: this.extractVariables(code),
functions: this.extractFunctionCalls(code),
currentScope: this.determineScope(code)
};
}
async fetchAICompletions(context) {
// 调用AI服务获取代码补全建议
const response = await fetch('https://api.codeai.com/completions', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ context })
});
return await response.json();
}
}
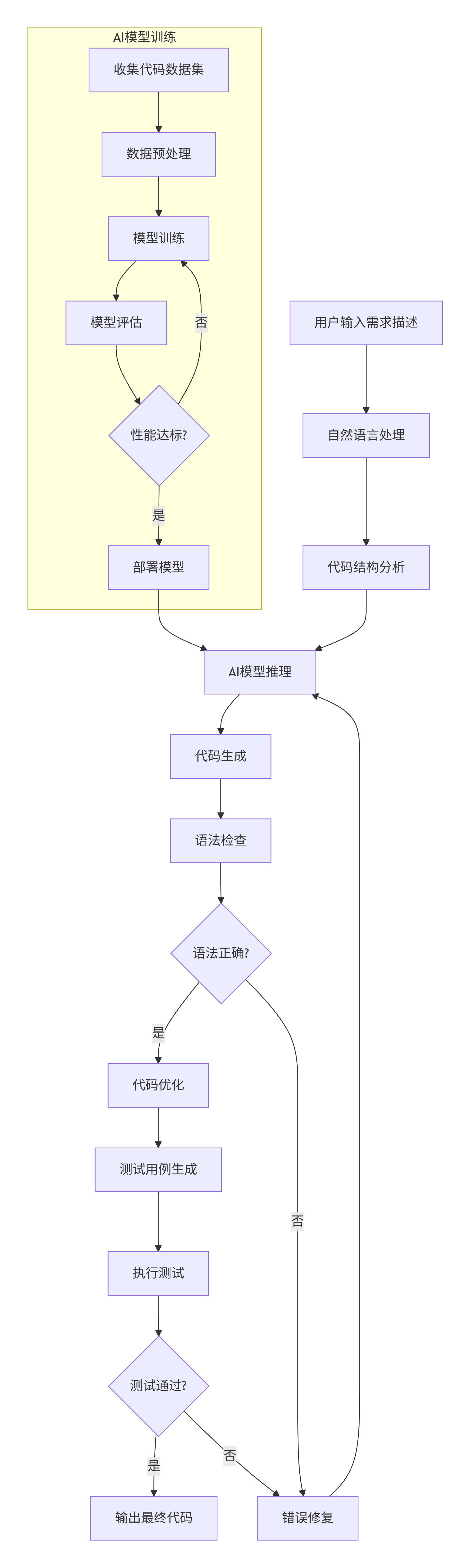
2.3 自动化代码生成的流程图
graph TD
A[用户输入需求描述] --> B[自然语言处理]
B --> C[代码结构分析]
C --> D[AI模型推理]
D --> E[代码生成]
E --> F[语法检查]
F --> G{语法正确?}
G -->|是| H[代码优化]
G -->|否| I[错误修复]
I --> D
H --> J[测试用例生成]
J --> K[执行测试]
K --> L{测试通过?}
L -->|是| M[输出最终代码]
L -->|否| I
subgraph AI模型训练
N[收集代码数据集] --> O[数据预处理]
O --> P[模型训练]
P --> Q[模型评估]
Q --> R{性能达标?}
R -->|是| S[部署模型]
R -->|否| P
end
S --> D
2.4 自动化代码生成的挑战与解决方案
挑战1:代码质量保证
-
解决方案:集成静态代码分析工具
python
def validate_generated_code(code):
"""验证生成的代码质量"""
checks = [
check_syntax,
check_security,
check_performance,
check_best_practices
]
results = {}
for check in checks:
results[check.__name__] = check(code)
return all(results.values()), results
def check_syntax(code):
"""检查语法正确性"""
try:
ast.parse(code)
return True
except SyntaxError:
return False
def check_security(code):
"""检查安全漏洞"""
# 使用Bandit等工具进行安全检查
import bandit
# 实现安全检查逻辑
return True
挑战2:上下文理解
-
解决方案:增强上下文感知能力
python
class ContextAwareCodeGenerator:
def __init__(self):
self.context_analyzer = ContextAnalyzer()
self.code_generator = CodeGenerator()
def generate_with_context(self, prompt, project_context):
# 分析项目上下文
context_features = self.context_analyzer.analyze(project_context)
# 基于上下文增强提示
enhanced_prompt = self.enhance_prompt(prompt, context_features)
# 生成代码
return self.code_generator.generate(enhanced_prompt)
def enhance_prompt(self, prompt, context):
enhanced = f"""
项目上下文:
- 使用的框架: {context.frameworks}
- 代码风格: {context.coding_style}
- 已有模块: {context.existing_modules}
原始需求: {prompt}
请根据以上上下文生成合适的代码:
"""
return enhanced
3. 低代码/无代码开发平台
3.1 低代码平台架构设计
低代码平台通过可视化开发环境大幅降低编程门槛,使业务专家也能创建应用程序。
python
class LowCodePlatform:
def __init__(self):
self.components = ComponentRegistry()
self.workflow_engine = WorkflowEngine()
self.data_connectors = DataConnectorManager()
def create_application(self, blueprint):
"""根据蓝图创建应用程序"""
# 解析可视化设计
design = self.parse_design(blueprint)
# 生成前端代码
frontend_code = self.generate_frontend(design)
# 生成后端API
backend_code = self.generate_backend(design)
# 配置数据库
database_config = self.generate_database_config(design)
return {
'frontend': frontend_code,
'backend': backend_code,
'database': database_config,
'deployment': self.generate_deployment_config(design)
}
def parse_design(self, blueprint):
"""解析可视化设计文件"""
# 将拖拽生成的JSON转换为应用结构
return ApplicationDesign(blueprint)
def generate_frontend(self, design):
"""生成前端代码"""
template_engine = FrontendTemplateEngine()
return template_engine.render(design)
def generate_backend(self, design):
"""生成后端API代码"""
api_generator = APIGenerator()
return api_generator.generate(design)
class ComponentRegistry:
"""组件注册表 - 管理可重用的UI和逻辑组件"""
def __init__(self):
self.ui_components = {}
self.business_components = {}
self.connectors = {}
def register_component(self, component_type, component):
"""注册新组件"""
if component_type == 'ui':
self.ui_components[component.name] = component
elif component_type == 'business':
self.business_components[component.name] = component
def get_component(self, name):
"""获取组件定义"""
return self.ui_components.get(name) or self.business_components.get(name)
3.2 可视化业务流程设计器
javascript
class VisualWorkflowDesigner {
constructor(containerId) {
this.container = document.getElementById(containerId);
this.nodes = [];
this.connections = [];
this.initDesigner();
}
initDesigner() {
// 初始化画布
this.canvas = new Canvas(this.container);
// 加载组件面板
this.loadComponentPalette();
// 绑定事件处理
this.bindEvents();
}
loadComponentPalette() {
const components = [
{ type: 'start', name: '开始', icon: '▶️' },
{ type: 'input', name: '数据输入', icon: '📥' },
{ type: 'process', name: '数据处理', icon: '⚙️' },
{ type: 'decision', name: '条件判断', icon: '🤔' },
{ type: 'output', name: '结果输出', icon: '📤' },
{ type: 'end', name: '结束', icon: '⏹️' }
];
const palette = new ComponentPalette(components);
palette.render(this.container);
}
addNode(componentType, position) {
const node = new WorkflowNode(componentType, position);
this.nodes.push(node);
this.canvas.addNode(node);
return node;
}
connectNodes(sourceNode, targetNode, condition = null) {
const connection = new NodeConnection(sourceNode, targetNode, condition);
this.connections.push(connection);
this.canvas.addConnection(connection);
}
generateCode() {
const codeGenerator = new WorkflowCodeGenerator();
return codeGenerator.generate(this.nodes, this.connections);
}
}
class WorkflowCodeGenerator {
generate(nodes, connections) {
// 将可视化工作流转换为可执行代码
const workflow = this.buildWorkflow(nodes, connections);
return this.generatePythonCode(workflow);
}
buildWorkflow(nodes, connections) {
// 构建工作流执行图
const workflow = {
start: this.findStartNode(nodes),
steps: {}
};
nodes.forEach(node => {
workflow.steps[node.id] = {
type: node.type,
action: node.config.action,
next: this.findNextSteps(node.id, connections)
};
});
return workflow;
}
generatePythonCode(workflow) {
// 生成Python代码
return `
from typing import Any, Dict
class WorkflowEngine:
def execute(self, data: Dict[str, Any]) -> Dict[str, Any]:
current_step = "${workflow.start}"
result = data
while current_step:
step = self.steps[current_step]
result = self.execute_step(step, result)
current_step = self.get_next_step(step, result)
return result
def execute_step(self, step, data):
# 执行具体步骤
${this.generateStepCode(workflow.steps)}
def get_next_step(self, step, result):
# 确定下一步
${this.generateNextStepLogic(workflow.steps)}
`;
}
}
3.3 低代码平台数据模型设计
python
from django.db import models
from django.contrib.postgres.fields import JSONField
class Application(models.Model):
"""应用定义"""
name = models.CharField(max_length=200)
description = models.TextField(blank=True)
created_at = models.DateTimeField(auto_now_add=True)
updated_at = models.DateTimeField(auto_now=True)
blueprint = JSONField() # 存储可视化设计
def generate_code(self):
"""生成应用代码"""
generator = CodeGenerator()
return generator.generate(self.blueprint)
class DataModel(models.Model):
"""数据模型定义"""
application = models.ForeignKey(Application, on_delete=models.CASCADE)
name = models.CharField(max_length=100)
fields = JSONField() # 字段定义
def create_database_table(self):
"""创建对应的数据库表"""
# 动态创建数据表
sql = self.generate_create_table_sql()
# 执行SQL...
return sql
def generate_create_table_sql(self):
"""生成建表SQL"""
field_definitions = []
for field_name, field_config in self.fields.items():
field_def = self.map_field_type(field_config)
field_definitions.append(f"{field_name} {field_def}")
return f"CREATE TABLE {self.name} ({', '.join(field_definitions)})"
class Page(models.Model):
"""页面定义"""
application = models.ForeignKey(Application, on_delete=models.CASCADE)
name = models.CharField(max_length=100)
layout = JSONField() # 页面布局配置
components = JSONField() # 组件配置
def render_html(self):
"""渲染页面HTML"""
renderer = PageRenderer()
return renderer.render(self.layout, self.components)
class BusinessLogic(models.Model):
"""业务逻辑定义"""
application = models.ForeignKey(Application, on_delete=models.CASCADE)
name = models.CharField(max_length=100)
trigger = JSONField() # 触发条件
actions = JSONField() # 执行动作
def generate_python_code(self):
"""生成Python业务逻辑代码"""
code_generator = BusinessLogicGenerator()
return code_generator.generate(self.trigger, self.actions)
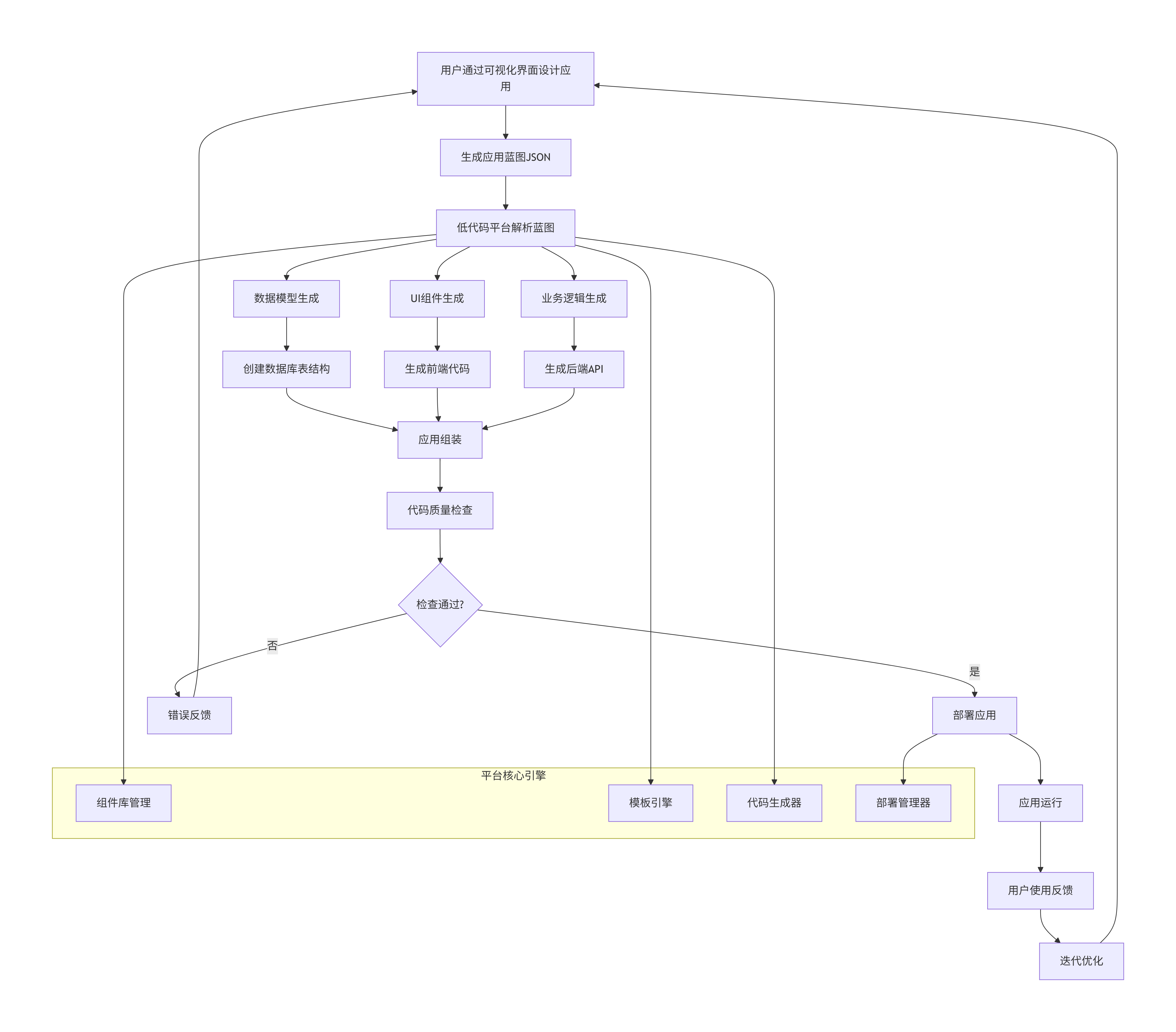
3.4 低代码平台流程图
flowchart TD
A[用户通过可视化界面设计应用] --> B[生成应用蓝图JSON]
B --> C[低代码平台解析蓝图]
C --> D[数据模型生成]
D --> E[创建数据库表结构]
C --> F[UI组件生成]
F --> G[生成前端代码]
C --> H[业务逻辑生成]
H --> I[生成后端API]
E --> J[应用组装]
G --> J
I --> J
J --> K[代码质量检查]
K --> L{检查通过?}
L -->|是| M[部署应用]
L -->|否| N[错误反馈]
N --> A
M --> O[应用运行]
O --> P[用户使用反馈]
P --> Q[迭代优化]
Q --> A
subgraph 平台核心引擎
R[组件库管理]
S[模板引擎]
T[代码生成器]
U[部署管理器]
end
C --> R
C --> S
C --> T
M --> U
3.5 无代码AI模型训练平台
python
class NoCodeAIPlatform:
"""无代码AI平台 - 让业务用户也能训练AI模型"""
def __init__(self):
self.data_processors = DataProcessorRegistry()
self.model_zoo = ModelZoo()
self.trainers = TrainerRegistry()
def create_ai_project(self, config):
"""创建AI项目"""
project = AIProject(config)
# 自动化数据处理
processed_data = self.auto_process_data(project)
# 自动选择模型
model = self.auto_select_model(project, processed_data)
# 自动化训练
trained_model = self.auto_train(model, processed_data)
# 生成部署包
deployment_package = self.generate_deployment_package(trained_model)
return deployment_package
def auto_process_data(self, project):
"""自动化数据处理"""
processor = self.data_processors.get_processor(project.data_type)
return processor.process(project.data)
def auto_select_model(self, project, data):
"""自动选择适合的模型"""
# 基于问题类型和数据特征选择模型
problem_type = project.problem_type # 分类、回归、聚类等
data_characteristics = self.analyze_data_characteristics(data)
return self.model_zoo.recommend_model(problem_type, data_characteristics)
def auto_train(self, model, data):
"""自动化训练"""
trainer = self.trainers.get_trainer(model.type)
return trainer.train(model, data)
def generate_deployment_package(self, model):
"""生成部署包"""
return {
'model': model,
'inference_code': self.generate_inference_code(model),
'api_server': self.generate_api_server(model),
'documentation': self.generate_documentation(model)
}
class DataProcessorRegistry:
"""数据处理器注册表"""
def get_processor(self, data_type):
processors = {
'csv': CSVProcessor(),
'image': ImageProcessor(),
'text': TextProcessor(),
'time_series': TimeSeriesProcessor()
}
return processors.get(data_type, GenericProcessor())
class ModelZoo:
"""模型库"""
def recommend_model(self, problem_type, data_characteristics):
models = {
'classification': self.recommend_classification_model,
'regression': self.recommend_regression_model,
'clustering': self.recommend_clustering_model
}
recommender = models.get(problem_type)
return recommender(data_characteristics) if recommender else None
def recommend_classification_model(self, characteristics):
if characteristics['sample_count'] < 1000:
return RandomForestModel()
elif characteristics['feature_count'] > 100:
return XGBoostModel()
else:
return NeuralNetworkModel()
4. 算法优化实践
4.1 自动化超参数优化
python
import optuna
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
from sklearn.datasets import load_iris
class AutomatedHyperparameterOptimization:
"""自动化超参数优化"""
def __init__(self, model_class, X, y):
self.model_class = model_class
self.X = X
self.y = y
self.study = None
def objective(self, trial):
"""定义优化目标函数"""
# 定义超参数搜索空间
if self.model_class == RandomForestClassifier:
params = {
'n_estimators': trial.suggest_int('n_estimators', 50, 500),
'max_depth': trial.suggest_int('max_depth', 3, 15),
'min_samples_split': trial.suggest_int('min_samples_split', 2, 20),
'min_samples_leaf': trial.suggest_int('min_samples_leaf', 1, 10),
'max_features': trial.suggest_categorical('max_features', ['auto', 'sqrt', 'log2'])
}
model = self.model_class(**params)
# 使用交叉验证评估模型性能
score = cross_val_score(model, self.X, self.y, cv=5, scoring='accuracy').mean()
return score
def optimize(self, n_trials=100):
"""执行优化"""
self.study = optuna.create_study(direction='maximize')
self.study.optimize(self.objective, n_trials=n_trials)
return self.study.best_params, self.study.best_value
def visualize_optimization(self):
"""可视化优化过程"""
if self.study:
# 绘制优化历史
optuna.visualization.plot_optimization_history(self.study)
# 绘制参数重要性
optuna.visualization.plot_param_importances(self.study)
# 绘制平行坐标图
optuna.visualization.plot_parallel_coordinate(self.study)
# 使用示例
iris = load_iris()
X, y = iris.data, iris.target
optimizer = AutomatedHyperparameterOptimization(RandomForestClassifier, X, y)
best_params, best_score = optimizer.optimize(n_trials=50)
print(f"最佳参数: {best_params}")
print(f"最佳准确率: {best_score:.4f}")
optimizer.visualize_optimization()
4.2 神经网络架构搜索(NAS)
python
import tensorflow as tf
from tensorflow.keras import layers, models
class NeuralArchitectureSearch:
"""神经网络架构搜索"""
def __init__(self, input_shape, num_classes, max_layers=10):
self.input_shape = input_shape
self.num_classes = num_classes
self.max_layers = max_layers
self.performance_history = []
def generate_architecture(self, trial):
"""生成神经网络架构"""
model = models.Sequential()
model.add(layers.Input(shape=self.input_shape))
# 随机生成网络层
n_layers = trial.suggest_int('n_layers', 1, self.max_layers)
for i in range(n_layers):
# 选择层类型
layer_type = trial.suggest_categorical(f'layer_{i}_type',
['conv', 'dense', 'lstm'])
# 选择激活函数
activation = trial.suggest_categorical(f'layer_{i}_activation',
['relu', 'sigmoid', 'tanh'])
if layer_type == 'conv':
filters = trial.suggest_int(f'layer_{i}_filters', 16, 128)
kernel_size = trial.suggest_int(f'layer_{i}_kernel_size', 3, 7)
model.add(layers.Conv2D(filters, kernel_size, activation=activation))
elif layer_type == 'dense':
units = trial.suggest_int(f'layer_{i}_units', 32, 512)
model.add(layers.Dense(units, activation=activation))
elif layer_type == 'lstm':
units = trial.suggest_int(f'layer_{i}_lstm_units', 32, 128)
model.add(layers.LSTM(units, activation=activation))
# 随机添加Dropout层
if trial.suggest_categorical(f'layer_{i}_dropout', [True, False]):
dropout_rate = trial.suggest_float(f'layer_{i}_dropout_rate', 0.1, 0.5)
model.add(layers.Dropout(dropout_rate))
# 输出层
model.add(layers.Dense(self.num_classes, activation='softmax'))
return model
def evaluate_architecture(self, model, trial):
"""评估架构性能"""
# 编译模型
learning_rate = trial.suggest_float('learning_rate', 1e-5, 1e-2, log=True)
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
model.compile(optimizer=optimizer,
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 训练模型(简化版,实际使用验证集)
history = model.fit(self.X_train, self.y_train,
epochs=10, batch_size=32, verbose=0,
validation_split=0.2)
# 返回验证准确率
return history.history['val_accuracy'][-1]
def search(self, X_train, y_train, n_trials=100):
"""执行架构搜索"""
self.X_train = X_train
self.y_train = y_train
study = optuna.create_study(direction='maximize')
study.optimize(self._objective, n_trials=n_trials)
self.best_architecture = self.generate_architecture(study.best_trial)
return self.best_architecture, study.best_value
def _objective(self, trial):
"""优化目标函数"""
model = self.generate_architecture(trial)
performance = self.evaluate_architecture(model, trial)
self.performance_history.append(performance)
return performance
# 使用示例(简化版)
# nas = NeuralArchitectureSearch(input_shape=(28, 28, 1), num_classes=10)
# best_model, best_score = nas.search(X_train, y_train, n_trials=50)
4.3 自动化特征工程
python
import pandas as pd
import numpy as np
from sklearn.feature_selection import SelectKBest, f_classif
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
class AutomatedFeatureEngineering:
"""自动化特征工程"""
def __init__(self, target_column):
self.target_column = target_column
self.transformations = []
self.feature_importance = {}
def auto_engineer_features(self, df):
"""自动化特征工程主函数"""
original_features = [col for col in df.columns if col != self.target_column]
engineered_df = df.copy()
# 数值型特征变换
engineered_df = self.numerical_transformations(engineered_df, original_features)
# 类别型特征编码
engineered_df = self.categorical_encoding(engineered_df, original_features)
# 时间特征提取(如果存在时间列)
engineered_df = self.temporal_feature_engineering(engineered_df)
# 特征交互
engineered_df = self.feature_interactions(engineered_df, original_features)
# 多项式特征
engineered_df = self.polynomial_features(engineered_df, original_features)
return engineered_df
def numerical_transformations(self, df, original_features):
"""数值型特征变换"""
numerical_features = df[original_features].select_dtypes(include=[np.number]).columns
for feature in numerical_features:
# 对数变换
if (df[feature] > 0).all():
df[f'{feature}_log'] = np.log1p(df[feature])
self.transformations.append(f'log({feature})')
# 平方和平方根
df[f'{feature}_squared'] = df[feature] ** 2
df[f'{feature}_sqrt'] = np.sqrt(np.abs(df[feature]))
# 标准化
scaler = StandardScaler()
df[f'{feature}_standardized'] = scaler.fit_transform(df[[feature]])
return df
def categorical_encoding(self, df, original_features):
"""类别型特征编码"""
categorical_features = df[original_features].select_dtypes(include=['object']).columns
for feature in categorical_features:
# 频率编码
freq_encoding = df[feature].value_counts().to_dict()
df[f'{feature}_freq'] = df[feature].map(freq_encoding)
# 目标编码(如果目标变量可用)
if self.target_column in df.columns:
target_mean = df.groupby(feature)[self.target_column].mean().to_dict()
df[f'{feature}_target_encoded'] = df[feature].map(target_mean)
return df
def feature_selection(self, df, k=20):
"""自动化特征选择"""
X = df.drop(columns=[self.target_column])
y = df[self.target_column]
# 选择k个最佳特征
selector = SelectKBest(score_func=f_classif, k=min(k, X.shape[1]))
X_selected = selector.fit_transform(X, y)
# 获取特征重要性
selected_features = X.columns[selector.get_support()]
scores = selector.scores_[selector.get_support()]
self.feature_importance = dict(zip(selected_features, scores))
selected_df = pd.DataFrame(X_selected, columns=selected_features)
selected_df[self.target_column] = y.values
return selected_df
def dimensionality_reduction(self, df, n_components=0.95):
"""降维"""
X = df.drop(columns=[self.target_column])
y = df[self.target_column]
# 标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# PCA
pca = PCA(n_components=n_components)
X_pca = pca.fit_transform(X_scaled)
# 创建新的DataFrame
pca_columns = [f'PC_{i+1}' for i in range(X_pca.shape[1])]
pca_df = pd.DataFrame(X_pca, columns=pca_columns)
pca_df[self.target_column] = y.values
print(f"原始特征数: {X.shape[1]}, 降维后特征数: {X_pca.shape[1]}")
print(f"解释方差比例: {pca.explained_variance_ratio_.sum():.3f}")
return pca_df
# 使用示例
# feature_engineer = AutomatedFeatureEngineering(target_column='price')
# engineered_data = feature_engineer.auto_engineer_features(raw_data)
# selected_features = feature_engineer.feature_selection(engineered_data, k=30)
4.4 算法优化流程图
graph TB
A[原始算法/模型] --> B[性能分析]
B --> C{识别瓶颈}
C -->|计算密集型| D[并行化优化]
C -->|内存密集型| E[内存优化]
C -->|I/O密集型| F[I/O优化]
C -->|模型性能| G[超参数优化]
D --> H[GPU加速]
D --> I[多核并行]
D --> J[分布式计算]
E --> K[内存复用]
E --> L[数据压缩]
E --> M[缓存策略]
F --> N[异步I/O]
F --> O[批量处理]
F --> P[数据预加载]
G --> Q[自动化调参]
G --> R[架构搜索]
G --> S[特征工程]
H --> T[优化后算法]
I --> T
J --> T
K --> T
L --> T
M --> T
N --> T
O --> T
P --> T
Q --> T
R --> T
S --> T
T --> U[性能评估]
U --> V{达到目标?}
V -->|是| W[部署优化方案]
V -->|否| B
subgraph AI优化技术
Q --> Q1[贝叶斯优化]
Q --> Q2[遗传算法]
Q --> Q3[强化学习]
R --> R1[神经网络搜索]
R --> R2[模型剪枝]
R --> R3[量化压缩]
S --> S1[自动化特征工程]
S --> S2[特征选择]
S --> S3[维度削减]
end
5. 综合应用案例:智能客服系统开发
5.1 系统架构设计
python
class IntelligentCustomerService:
"""智能客服系统 - 综合应用AI编程技术"""
def __init__(self):
self.nlp_engine = NLPEngine()
self.dialogue_manager = DialogueManager()
self.knowledge_base = KnowledgeBase()
self.sentiment_analyzer = SentimentAnalyzer()
self.code_generator = CodeGenerator()
def process_customer_query(self, query, context=None):
"""处理客户查询"""
# 自然语言理解
intent, entities = self.nlp_engine.understand(query)
# 情感分析
sentiment = self.sentiment_analyzer.analyze(query)
# 对话管理
response_plan = self.dialogue_manager.plan_response(
intent, entities, sentiment, context
)
# 知识检索
if response_plan.need_knowledge:
knowledge = self.knowledge_base.retrieve(
intent, entities, response_plan.topic
)
response_plan.add_knowledge(knowledge)
# 生成响应
response = self.generate_response(response_plan)
return response, response_plan
def generate_response(self, response_plan):
"""生成响应"""
if response_plan.response_type == 'text':
return self.generate_text_response(response_plan)
elif response_plan.response_type == 'code':
return self.generate_code_response(response_plan)
elif response_plan.response_type == 'workflow':
return self.generate_workflow_response(response_plan)
def generate_code_response(self, response_plan):
"""生成代码响应"""
# 根据用户需求生成代码
code_prompt = f"""
用户需求: {response_plan.user_requirement}
技术栈: {response_plan.tech_stack}
生成实现该需求的代码:
"""
generated_code = self.code_generator.generate(code_prompt)
# 验证代码安全性
if self.validate_code_safety(generated_code):
return {
'type': 'code',
'content': generated_code,
'explanation': '这是根据您的需求生成的代码实现',
'language': response_plan.tech_stack
}
else:
return {
'type': 'text',
'content': '抱歉,我无法生成安全的代码来实现您的需求。'
}
def auto_create_workflow(self, business_process):
"""自动创建工作流"""
# 使用低代码平台创建工作流
workflow_design = self.analyze_business_process(business_process)
# 生成工作流代码
workflow_code = self.code_generator.generate_workflow(workflow_design)
# 部署工作流
deployment_result = self.deploy_workflow(workflow_code)
return deployment_result
def analyze_business_process(self, description):
"""分析业务流程描述"""
# 使用NLP解析业务流程
analysis = self.nlp_engine.analyze_process(description)
# 生成工作流设计
design = {
'steps': analysis['steps'],
'decisions': analysis['decisions'],
'actors': analysis['actors'],
'data_flow': analysis['data_flow']
}
return design
class NLPEngine:
"""自然语言处理引擎"""
def understand(self, text):
"""理解用户意图和实体"""
# 使用预训练模型进行意图分类和实体识别
return self.classify_intent(text), self.extract_entities(text)
def classify_intent(self, text):
"""意图分类"""
intents = {
'code_generation': ['代码', '编程', '实现', '开发'],
'bug_fix': ['错误', 'bug', '修复', '问题'],
'explanation': ['解释', '说明', '什么是', '如何'],
'workflow': ['流程', '工作流', '自动化']
}
for intent, keywords in intents.items():
if any(keyword in text for keyword in keywords):
return intent
return 'general_query'
def extract_entities(self, text):
"""实体提取"""
# 简化版实体提取
entities = {}
# 提取编程语言
languages = ['Python', 'JavaScript', 'Java', 'C++', 'Go']
for lang in languages:
if lang.lower() in text.lower():
entities['programming_language'] = lang
# 提取技术概念
concepts = ['机器学习', '数据库', 'API', '前端', '后端']
for concept in concepts:
if concept in text:
entities['technical_concept'] = concept
return entities
class DialogueManager:
"""对话管理器"""
def plan_response(self, intent, entities, sentiment, context):
"""规划响应"""
response_plan = ResponsePlan()
response_plan.intent = intent
response_plan.sentiment = sentiment
if intent == 'code_generation':
response_plan.response_type = 'code'
response_plan.tech_stack = entities.get('programming_language', 'Python')
elif intent == 'workflow':
response_plan.response_type = 'workflow'
else:
response_plan.response_type = 'text'
return response_plan
class ResponsePlan:
"""响应计划"""
def __init__(self):
self.intent = None
self.response_type = 'text'
self.tech_stack = 'Python'
self.user_requirement = ''
self.need_knowledge = False
self.topic = ''
self.knowledge = None
def add_knowledge(self, knowledge):
"""添加知识内容"""
self.knowledge = knowledge
5.2 系统部署与监控
python
class AISystemDeployer:
"""AI系统部署器"""
def __init__(self):
self.monitoring = SystemMonitoring()
self.auto_scaler = AutoScaler()
self.performance_tracker = PerformanceTracker()
def deploy_system(self, system_config):
"""部署AI系统"""
# 生成部署配置
deployment_config = self.generate_deployment_config(system_config)
# 容器化部署
dockerfile = self.generate_dockerfile(system_config)
# 配置监控
monitoring_config = self.setup_monitoring(system_config)
# 部署到云平台
deployment_result = self.deploy_to_cloud(deployment_config, dockerfile)
# 启动自动扩缩容
self.auto_scaler.configure(deployment_result['endpoints'])
return deployment_result
def generate_dockerfile(self, system_config):
"""生成Dockerfile"""
base_image = system_config.get('base_image', 'python:3.9-slim')
dockerfile = f"""
FROM {base_image}
WORKDIR /app
COPY requirements.txt .
RUN pip install -r requirements.txt
COPY . .
EXPOSE 8000
CMD ["python", "app.py"]
"""
return dockerfile
def setup_monitoring(self, system_config):
"""设置监控"""
monitoring_config = {
'metrics': ['cpu_usage', 'memory_usage', 'response_time', 'error_rate'],
'alerts': self.configure_alerts(system_config),
'logging': self.configure_logging(system_config),
'tracing': self.configure_tracing(system_config)
}
return monitoring_config
def configure_alerts(self, system_config):
"""配置告警规则"""
return {
'high_cpu': {'metric': 'cpu_usage', 'threshold': 80, 'duration': '5m'},
'high_memory': {'metric': 'memory_usage', 'threshold': 85, 'duration': '5m'},
'slow_response': {'metric': 'response_time', 'threshold': 1000, 'duration': '2m'},
'high_error_rate': {'metric': 'error_rate', 'threshold': 5, 'duration': '5m'}
}
class SystemMonitoring:
"""系统监控"""
def __init__(self):
self.metrics_collector = MetricsCollector()
self.alert_manager = AlertManager()
self.log_aggregator = LogAggregator()
def track_performance(self, endpoint, metrics):
"""跟踪性能指标"""
self.metrics_collector.record(endpoint, metrics)
# 检查是否触发告警
alerts = self.alert_manager.check_alerts(endpoint, metrics)
for alert in alerts:
self.notify_alert(alert)
def analyze_trends(self):
"""分析性能趋势"""
trends = {
'usage_patterns': self.analyze_usage_patterns(),
'performance_degradation': self.detect_performance_degradation(),
'resource_optimization': self.suggest_resource_optimization()
}
return trends
def detect_performance_degradation(self):
"""检测性能退化"""
# 使用机器学习检测异常模式
historical_data = self.metrics_collector.get_historical_data()
# 简单阈值检测(实际使用更复杂的异常检测算法)
current_performance = historical_data[-1]
baseline = np.mean(historical_data[:-24]) # 过去24小时平均值
degradation = current_performance['response_time'] > baseline * 1.5
return degradation
class AutoScaler:
"""自动扩缩容"""
def __init__(self):
self.scaling_policies = {}
self.metrics_window = deque(maxlen=10)
def configure(self, endpoints):
"""配置扩缩容策略"""
for endpoint in endpoints:
self.scaling_policies[endpoint] = {
'min_instances': 1,
'max_instances': 10,
'scale_up_threshold': 70, # CPU使用率%
'scale_down_threshold': 30,
'cooldown_period': 300 # 5分钟冷却期
}
def evaluate_scaling(self, current_metrics):
"""评估是否需要扩缩容"""
scaling_decisions = {}
for endpoint, metrics in current_metrics.items():
policy = self.scaling_policies.get(endpoint)
if not policy:
continue
cpu_usage = metrics.get('cpu_usage', 0)
if cpu_usage > policy['scale_up_threshold']:
scaling_decisions[endpoint] = 'scale_up'
elif cpu_usage < policy['scale_down_threshold']:
scaling_decisions[endpoint] = 'scale_down'
return scaling_decisions
def execute_scaling(self, decisions):
"""执行扩缩容决策"""
for endpoint, decision in decisions.items():
if decision == 'scale_up':
self.scale_up(endpoint)
elif decision == 'scale_down':
self.scale_down(endpoint)
6. 未来展望与挑战
6.1 技术发展趋势
AI编程技术正在快速发展,未来将呈现以下趋势:
-
更加智能的代码生成:模型将更好地理解业务逻辑和架构模式
-
跨语言代码转换:实现不同编程语言间的自动转换
-
自我优化的系统:系统能够根据运行时数据自我调整和优化
-
人机协作编程:AI成为编程伙伴,理解开发者意图并提供实时建议
6.2 面临的挑战
python
class AIProgrammingChallenges:
"""AI编程面临的挑战和解决方案"""
challenges = {
'code_quality': {
'description': '生成的代码质量参差不齐',
'solutions': [
'集成代码审查工具',
'强化测试用例生成',
'建立代码质量评估体系'
]
},
'security_concerns': {
'description': '自动生成代码的安全隐患',
'solutions': [
'静态安全扫描',
'漏洞模式识别',
'安全最佳实践集成'
]
},
'intellectual_property': {
'description': '知识产权和代码版权问题',
'solutions': [
'代码来源追踪',
'许可证合规检查',
'原创性验证机制'
]
},
'explainability': {
'description': 'AI决策过程不透明',
'solutions': [
'可解释AI技术',
'决策过程可视化',
'生成代码的文档自动化'
]
}
}
def assess_maturity(self, technology):
"""评估技术成熟度"""
maturity_levels = {
'automated_code_generation': '成长阶段',
'low_code_platforms': '成熟阶段',
'no_code_ai': '早期阶段',
'algorithm_optimization': '研究阶段'
}
return maturity_levels.get(technology, '未知')
def research_directions(self):
"""未来研究方向"""
return [
'代码语义理解',
'跨模态编程',
'自适应优化',
'伦理AI编程',
'量子计算编程'
]
6.3 伦理与社会影响
AI编程技术的发展也带来重要的伦理和社会考量:
-
就业影响:自动化可能改变软件开发就业市场
-
教育变革:编程教育需要适应AI辅助开发的新范式
-
数字鸿沟:确保技术普及不会加剧不平等
-
责任归属:AI生成代码的责任认定问题
7. 结论
AI编程技术正在深刻改变软件开发的本质。自动化代码生成使开发更加高效,低代码/无代码平台 democratize 应用开发,而算法优化实践则不断提升系统性能。这些技术共同推动着软件开发向更智能、更易用、更高效的方向发展。
然而,技术的进步也伴随着挑战。我们需要在推动创新的同时,关注代码质量、安全性、伦理影响等重要问题。未来,人机协作的编程模式将成为主流,开发者将更多地专注于创造性工作和复杂问题解决,而重复性任务将交由AI处理。
随着技术的不断成熟,AI编程有望实现真正的"编程民主化",让更多人能够参与数字世界的创造,推动技术创新和社会进步。这场变革才刚刚开始,其最终形态将取决于我们如何平衡技术创新与人文关怀,如何构建既强大又负责任的AI编程生态系统。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 15
15 0
0- 0



 已为社区贡献88条内容
已为社区贡献88条内容

所有评论(0)