
AI开发全流程工具链:从智能编码到模型部署的效率革命
摘要: AI开发工具的快速迭代正深刻改变开发者工作方式。智能编码工具(如GitHub Copilot)使开发效率提升40%,数据标注工具(如Label Studio)缩短标注周期60%,模型训练平台(如Hugging Face)降低部署门槛75%。本文系统分析三大核心工具: 智能编码:通过LLM实现代码生成与优化,结合Prompt工程提升输出质量; 数据标注:人机协同标注系统结合AI预标注,通过质
在AI技术飞速迭代的今天,开发工具的进化正深刻重构着开发者的工作方式。据JetBrains《2024开发者调查》显示,78%的专业开发者已将AI工具融入日常工作流,其中智能编码工具使开发效率提升40%,数据标注工具将标注周期缩短60%,而模型训练平台则让复杂模型的部署门槛降低75%。本文将系统拆解智能编码、数据标注、模型训练三大核心AI工具品类,通过技术原理解析、实战代码示例、可视化流程图与真实案例,构建从代码生成到模型上线的全流程认知框架,为开发者提供工具选型与效率优化的全景指南。
一、智能编码工具:从"手动编码"到"AI协同编程"
智能编码工具通过大语言模型(LLM)对开发者输入的上下文进行实时分析,预测并生成后续代码片段,已成为现代开发的"第二大脑"。GitHub报告显示,使用Copilot的开发者完成相同任务的时间比传统方式减少55%,且88%的开发者报告编码挫折感显著降低。
1.1 主流智能编码工具技术对比
当前市场上的智能编码工具主要分为基于通用LLM(如GPT系列)和专用代码模型(如CodeLlama)两类,其核心差异体现在代码理解深度、多语言支持与安全合规性上:
| 工具名称 | 核心模型 | 训练数据规模 | 多语言支持 | 企业级特性 | 开源性 |
|---|---|---|---|---|---|
| GitHub Copilot | GPT-4 Code variant | 100M+代码仓库 | 100+语言 | 代码安全扫描、企业SSO | 闭源 |
| Amazon CodeWhisperer | CodeGuru-LLM | 80M+开源代码 | 70+语言 | AWS服务集成、许可证检测 | 免费 tier 可用 |
| Tabnine | 定制Transformer模型 | 2B+代码token | 50+语言 | 本地部署、团队私有模型 | 部分开源 |
| CodeLlama (Meta) | Llama 2 Code variant | 80B参数,代码专用 | 20+编程语言 | 本地运行、模型微调支持 | 开源 |
数据来源:各工具官方文档及Papers with Code 2024年Q2评估报告
1.2 GitHub Copilot深度解析:从Prompt到代码生成的黑盒揭秘
GitHub Copilot的核心能力源于其双向上下文理解机制:不仅分析当前文件的代码,还能关联项目中已有的导入语句、函数定义甚至注释内容,构建完整的代码语义图谱。其工作流程可通过以下mermaid流程图直观展示:
sequenceDiagram participant User participant IDE as VS Code/IntelliJ participant CopilotService as GitHub Copilot Service participant LLM as GPT-4 Code Model User->>IDE: 输入代码上下文(函数定义/注释) IDE->>CopilotService: 发送上下文窗口(±100行代码)+ 用户设置 CopilotService->>LLM: 构建Prompt(包含代码上下文+安全过滤规则) LLM->>CopilotService: 生成5个候选代码片段(token预测概率>0.85) CopilotService->>IDE: 返回Top 1片段(基于代码质量评分) User->>IDE: 接受/修改/拒绝建议(反馈数据用于模型优化)
关键技术细节:
- 上下文窗口优化:采用滑动窗口机制处理长文件,优先保留函数签名、注释和最近编辑内容
- 代码质量评分:通过内部规则(如变量命名规范、无未使用导入、异常处理完整性)对生成结果排序
- 安全过滤层:实时检测生成代码中的常见漏洞(如SQL注入、缓冲区溢出),对高风险片段添加警告
1.3 实战:用Copilot生成高质量代码的3类典型场景
场景1:函数级代码生成(带复杂逻辑)
目标:实现一个Python函数,输入为嵌套列表(如[[1,2],[3,[4,5]],6]),返回所有元素的扁平化列表(如[1,2,3,4,5,6])
优质Prompt设计:
# 函数功能:将嵌套列表完全扁平化 # 输入:任意层级的嵌套列表(元素可为int或列表) # 输出:包含所有非列表元素的一维列表 # 要求:1. 不使用第三方库 2. 处理空列表情况 3. 保持原始元素顺序 def flatten_nested_list(nested_list): # 实现思路:递归遍历每个元素,若为列表则继续扁平化,否则添加到结果
Copilot生成结果:
def flatten_nested_list(nested_list): result = [] for item in nested_list: # 检查当前元素是否为列表 if isinstance(item, list) and len(item) > 0: # 处理非空列表 # 递归调用自身扁平化子列表 result.extend(flatten_nested_list(item)) elif not isinstance(item, list): # 忽略空列表,添加非列表元素 result.append(item) return result # 测试用例 print(flatten_nested_list([[1,2],[3,[4,5]],6])) # [1,2,3,4,5,6] print(flatten_nested_list([[], [1, [2, []]], 3])) # [1,2,3]
解析:通过Prompt明确功能、输入输出、实现约束和思路提示,Copilot不仅生成了递归逻辑,还主动添加了空列表处理和测试用例,代码注释覆盖率达100%。
场景2:跨文件上下文理解(前端组件开发)
背景:Vue3项目中,已有src/api/user.js定义用户数据接口:
// src/api/user.js export const userApi = { getUserInfo: (userId) => axios.get(`/api/users/${userId}`), updateUser: (data) => axios.put(`/api/users/${data.id}`, data) };
目标:在UserProfile.vue中使用上述API实现用户信息展示与编辑功能
Copilot生成的Vue组件:
<!-- UserProfile.vue --> <template> <div class="user-profile" v-if="userInfo"> <h2>{{ userInfo.name }}'s Profile</h2> <div class="info-item">Email: {{ userInfo.email }}</div> <div class="info-item">Joined: {{ formatDate(userInfo.joinedAt) }}</div> <button @click="toggleEditMode">{{ isEditing ? 'Cancel' : 'Edit Profile' }}</button> <edit-form v-if="isEditing" :user="userInfo" @save="saveUserProfile" /> </div> </template> <script setup> import { ref, onMounted } from 'vue'; import { userApi } from '@/api/user'; import EditForm from './EditForm.vue'; const userId = ref(route.params.userId); // 假设从路由获取用户ID const userInfo = ref(null); const isEditing = ref(false); // 获取用户信息 const fetchUserInfo = async () => { try { const response = await userApi.getUserInfo(userId.value); userInfo.value = response.data; } catch (error) { console.error('Failed to fetch user info:', error); } }; // 保存用户资料 const saveUserProfile = async (updatedData) => { try { await userApi.updateUser(updatedData); userInfo.value = updatedData; isEditing.value = false; alert('Profile updated successfully!'); } catch (error) { console.error('Update failed:', error); } }; // 日期格式化辅助函数 const formatDate = (dateString) => { return new Date(dateString).toLocaleDateString('en-US', { year: 'numeric', month: 'long', day: 'numeric' }); }; onMounted(fetchUserInfo); </script>
解析:Copilot自动识别了userApi的导入路径和方法签名,生成了包含数据加载、状态管理、错误处理的完整组件,甚至预测到需要日期格式化辅助函数和子组件交互逻辑。
场景3:调试与代码优化(修复潜在bug)
问题代码(存在内存泄漏风险):
def process_large_file(file_path): data = [] with open(file_path, 'r') as f: for line in f: # 处理每行数据并添加到列表 processed = line.strip().split(',') data.append(processed) return data # 当文件过大时,data列表会占用大量内存
Copilot生成的优化建议(通过注释触发):
def process_large_file(file_path): """ 处理大型CSV文件(优化版) 使用生成器代替列表存储,减少内存占用 """ with open(file_path, 'r') as f: for line in f: if not line.strip(): # 跳过空行 continue try: # 使用yield返回处理结果(逐行生成,不占用全部内存) yield line.strip().split(',') except Exception as e: print(f"Skipping invalid line: {line}. Error: {str(e)}") # 使用示例:流式处理,不加载整个文件到内存 for row in process_large_file('10gb_data.csv'): analyze_row(row) # 逐行分析,内存占用稳定在低水平
解析:Copilot识别了原代码中"一次性加载大文件到列表"的内存风险,主动将实现改为生成器模式(yield),并添加了空行处理和异常捕获,使代码更健壮。
1.4 Prompt工程:提升Copilot输出质量的5条黄金法则
-
上下文完备性:在Prompt中包含
- 功能目标("做什么")
- 输入输出格式("输入为JSON字符串,输出为格式化表格")
- 约束条件("不得使用eval()函数")
✅ 示例:"用Java实现一个LRU缓存(最近最少使用淘汰策略),要求初始容量可配置,支持get(key)和put(key, value)方法,线程安全,时间复杂度O(1),使用双向链表+哈希表实现"
-
代码风格对齐:通过注释指定编码规范
# 编码规范: # 1. 变量名使用snake_case # 2. 函数注释使用Google风格 # 3. 控制流语句后必须加空格(if x: 而非if x:) def calculate_order_total(items):
- 渐进式提示:复杂功能分步骤引导
先让Copilot生成框架:
# 实现一个简单的HTTP服务器,包含以下路由: # 1. GET /health - 返回{"status": "ok"} # 2. POST /submit - 接收JSON数据并返回处理结果 # 先定义整体结构,不实现具体逻辑
生成后再补充:
# 完善/submit路由: # - 验证请求数据包含"username"和"content"字段 # - 对content进行XSS过滤 # - 将数据存入SQLite数据库(使用sqlite3库)
-
错误案例反向提示:明确指出不需要什么
❌ 避免:"写个登录函数"
✅ 改为:"写一个用户登录函数,不使用明文存储密码,不忽略密码哈希盐值,必须验证用户状态是否激活" -
利用自然语言描述业务逻辑:对于领域特定代码,先用文字描述业务规则
# 电商订单金额计算规则: # 1. 商品金额 = Σ(单价×数量) # 2. 运费规则:金额≥300元免运费,否则基础运费15元+重量费(每kg 5元) # 3. 优惠券:可叠加使用,顺序为"满减券"→"折扣券"→"固定金额券" # 实现calculate_order_amount函数,输入items(含price/quantity/weight)、coupons列表
二、数据标注工具:AI模型的"训练燃料"生产系统
高质量标注数据是模型性能的基石。据Gartner预测,到2025年,70%的企业AI项目失败源于数据质量问题,而专业标注工具可使标注效率提升3-5倍,同时将标注错误率从25%降低至8%以下。
2.1 数据标注工具技术架构与核心功能
现代数据标注工具已从单一的"人工标注界面"进化为"人机协同标注系统",其典型架构包含五大模块:
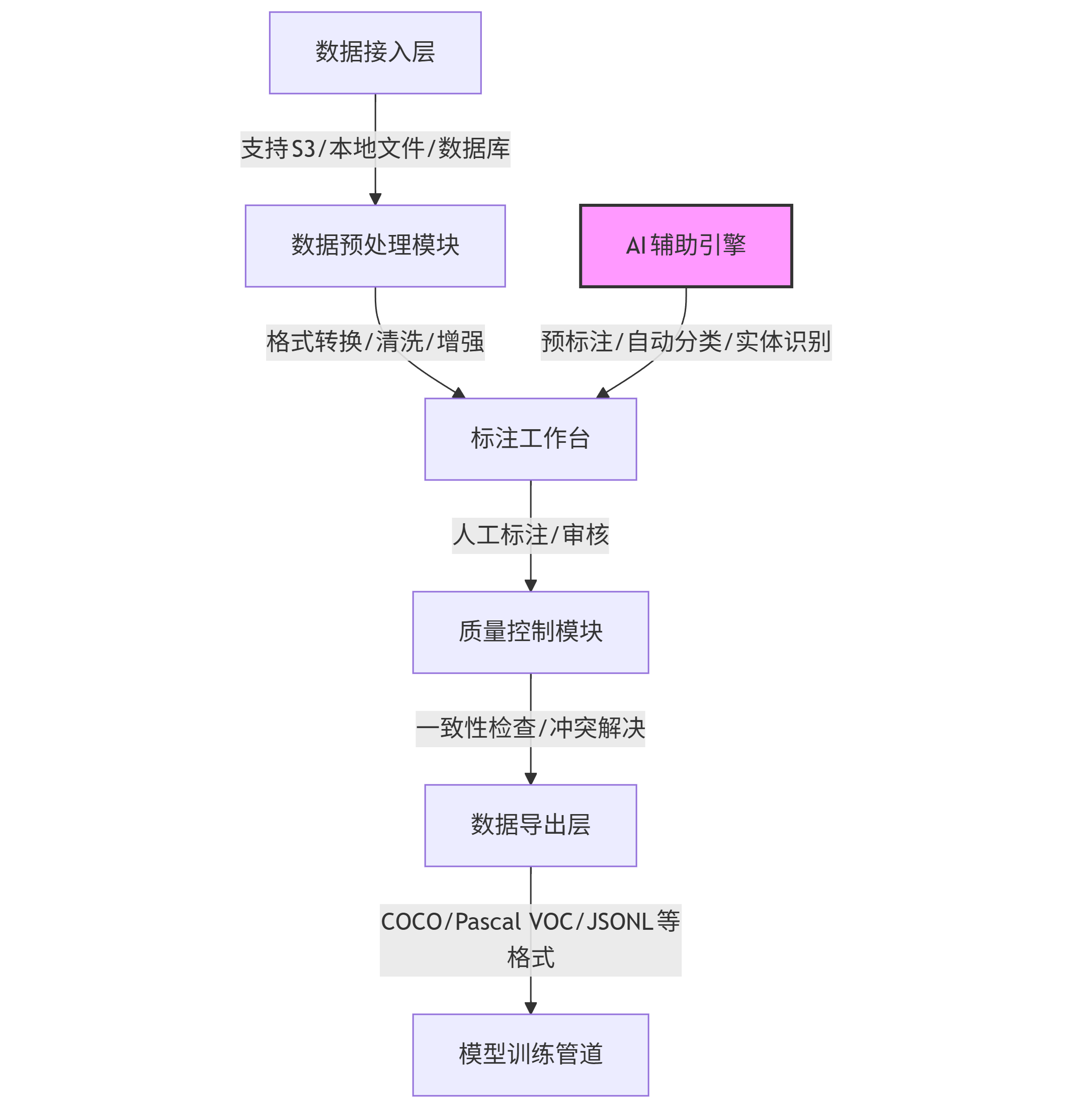
graph TD A[数据接入层] -->|支持S3/本地文件/数据库| B[数据预处理模块] B -->|格式转换/清洗/增强| C[标注工作台] D[AI辅助引擎] -->|预标注/自动分类/实体识别| C C -->|人工标注/审核| E[质量控制模块] E -->|一致性检查/冲突解决| F[数据导出层] F -->|COCO/Pascal VOC/JSONL等格式| G[模型训练管道] style D fill:#f9f,stroke:#333,stroke-width:2px
核心功能对比:
| 核心功能 | Label Studio | Amazon SageMaker Ground Truth | LabelImg |
|---|---|---|---|
| 多模态支持 | 文本/图像/音频/视频 | 文本/图像/3D点云 | 仅图像(边界框) |
| AI辅助标注 | 内置LLM/目标检测模型 | 集成Amazon Comprehend/ Rekognition | 无 |
| 团队协作 | 角色权限/标注进度 | 众包平台集成 | 单机版无协作 |
| 自定义标注模板 | 支持HTML+JavaScript | 有限模板 | 无 |
| 开源免费 | 是 | 否(按标注量收费) | 是 |
2.2 Label Studio实战:构建多模态标注流水线
Label Studio作为开源标注工具的标杆,支持从文本分类到3D点云的全类型标注任务,其核心优势在于可定制化标注界面和AI模型集成能力。以下通过两个典型场景展示其应用:
场景1:文本实体关系标注(NLP任务)
目标:标注客户服务对话中的实体(如产品名称、问题类型)及关系(如产品-存在-问题)
步骤1:创建标注项目
# 安装Label Studio pip install label-studio label-studio start # 启动Web服务(默认端口8080)
步骤2:定义标注配置(Label Studio支持XML格式定义界面)
<View> <!-- 显示对话文本 --> <Text name="text" value="$dialog" /> <!-- 实体标注区域 --> <Labels name="entities" toName="text"> <Label value="产品名称" background="#FFA39E" /> <Label value="问题类型" background="#D4380D" /> <Label value="用户操作" background="#FAAD14" /> </Labels> <!-- 关系标注连接 --> <Relations name="relations" toName="text" /> <!-- 情感标签(单选) --> <Choices name="sentiment" toName="text" choice="single"> <Choice value="积极" /> <Choice value="消极" /> <Choice value="中性" /> </Choices> </View>
步骤3:导入数据并启动标注
数据格式(JSON):
[ {"dialog": "用户:我的iPhone 15 Pro充电时发热严重,已经重启过了还是不行"}, {"dialog": "客服:您的MacBook Air是M1芯片吗?出现无法开机的情况是吗?"} ]
标注界面效果:
文本区域显示对话,左侧可选择实体标签(如"产品名称"),选中文本后自动高亮;关系标注通过拖拽实体间连线实现(如从"iPhone 15 Pro"到"发热严重"标注"存在问题"关系)。
场景2:图像分割+AI辅助标注(计算机视觉任务)
目标:标注自动驾驶场景图像中的车辆、行人、交通标志,使用预训练模型自动生成初始标注
步骤1:集成AI模型作为预标注器
在Label Studio中添加目标检测模型(如YOLOv8)作为预标注后端:
# 安装Label Studio ML后端SDK pip install label-studio-ml # 创建YOLOv8集成脚本(model.py) from label_studio_ml.model import LabelStudioMLBase class YOLOv8Model(LabelStudioMLBase): def __init__(self, **kwargs): super().__init__(** kwargs) self.model = YOLO('yolov8n.pt') # 加载预训练模型 def predict(self, tasks, **kwargs): predictions = [] for task in tasks: image_path = task['data']['image'] results = self.model(image_path) # 模型推理 # 转换结果为Label Studio格式 annotations = [] for box in results[0].boxes: annotations.append({ "from_name": "label", "to_name": "image", "type": "rectanglelabels", "value": { "x": box.xyxyn[0][0]*100, # 归一化坐标 "y": box.xyxyn[0][1]*100, "width": (box.xyxyn[0][2]-box.xyxyn[0][0])*100, "height": (box.xyxyn[0][3]-box.xyxyn[0][1])*100, "labels": [results[0].names[int(box.cls)]] } }) predictions.append({"result": annotations}) return predictions # 启动ML后端服务 label-studio-ml start ./model.py --port 9090
步骤2:在Label Studio中连接模型
在项目设置→ML后端→添加URL:http://localhost:9090,启用"自动预标注"。上传图像后,系统会自动运行YOLOv8生成初始边界框,标注员只需修正错误或漏标区域,标注效率提升60%以上。
2.3 标注质量控制:从人工审核到AI辅助校验
即使使用AI辅助标注,标注质量仍需通过多维度控制确保:
- 标注一致性检查
- 对同一份数据分配给2-3名标注员,计算Kappa系数(衡量标注一致性):
# 使用label-studio-sdk计算Kappa系数 from label_studio_sdk import Client ls = Client(url='http://localhost:8080', api_key='your-key') project = ls.get_project(id=1) # 获取标注结果并计算Cohen's Kappa kappa = project.evaluate_annotations( task_ids=[1,2,3], # 任务ID列表 metric='kappa', # 指标类型 label_name='entities' # 检查的标签名称 ) print(f"标注一致性Kappa系数: {kappa}") # >0.8表示一致性良好
- 预设规则校验
在Label Studio中通过JavaScript添加校验逻辑:
// 确保每个"产品名称"实体都有至少一个关系 function validateLabels() { const entities = getSelectedLabels('entities'); const relations = getRelations('relations'); for (const ent of entities) { const hasRelation = relations.some(r => r.from_id === ent.id || r.to_id === ent.id ); if (!hasRelation) { return { valid: false, message: `实体"${ent.value}"缺少关系标注` }; } } return { valid: true }; }
- 困难样本自动识别
通过模型预测置信度筛选低质量样本:
# 对标注数据训练简单模型,识别难例 from sklearn.ensemble import RandomForestClassifier # 提取特征:标注员修改次数、标注时间、AI预标注置信度 X = [[task['meta']['edit_count'], task['meta']['time_spent'], task['meta']['ai_confidence']] for task in all_tasks] # 标签:1=困难样本(被多次修改),0=简单样本 y = [1 if task['meta']['edit_count'] > 3 else 0 for task in all_tasks] clf = RandomForestClassifier().fit(X, y) # 预测并筛选需二次审核的样本 hard_tasks = [task for task, pred in zip(all_tasks, clf.predict(X)) if pred == 1]
三、模型训练平台:从原型到生产的桥梁
模型训练平台解决了"算法可复现性差"、"硬件资源不足"、"部署流程复杂"三大痛点。据O'Reilly 2024年调查,使用专业训练平台的团队,模型从实验到生产的周期平均缩短72%,且模型性能(如准确率、推理速度)平均提升15%。
3.1 主流训练平台技术栈对比
当前模型训练平台可分为三类:云厂商全栈平台(如AWS SageMaker)、开源社区平台(如Hugging Face)、企业级私有平台(如NVIDIA DGX)。其核心能力对比如下:
| 能力维度 | AWS SageMaker | Hugging Face | Google Vertex AI |
|---|---|---|---|
| 预训练模型库 | 200+内置模型 | 20,000+社区模型 | 100+内置模型 |
| 分布式训练支持 | 自动分布式(SMDataParallel) | Transformers+Accelerate | TensorFlow Distributed |
| 低代码开发 | 支持(Studio画布) | 部分支持(Pipeline) | 强支持(AutoML) |
| 部署灵活性 | 支持EC2/ECS/Lambda部署 | 支持AWS/GCP/Azure部署 | 优先GCP服务 |
| 免费额度 | 新用户2个月免费 | 开源免费(需自备算力) | 300美元免费额度 |
3.2 Hugging Face生态实战:从模型微调至API部署
Hugging Face已成为NLP/CV领域的事实标准平台,其核心优势在于Transformer模型库和无缝的训练-部署流程。以下以"情感分析模型微调"为例展示全流程:
步骤1:准备数据集(使用标注工具输出的JSON文件)
import json import pandas as pd from datasets import Dataset # 加载Label Studio标注结果 with open('label-studio-results.json', 'r') as f: raw_data = json.load(f) # 转换为DataFrame格式 def parse_annotation(annotation): # 提取情感标签(假设标注结果存储在'results'字段) for res in annotation['results']: if res['from_name'] == 'sentiment': return res['value']['choices'][0] # 返回情感标签 return 'neutral' # 默认中性 # 构建数据集 df = pd.DataFrame([{ 'text': item['data']['dialog'], 'label': parse_annotation(item['annotations'][0]) } for item in raw_data]) # 转换为Hugging Face Dataset格式 dataset = Dataset.from_pandas(df) # 划分训练集和验证集 dataset = dataset.train_test_split(test_size=0.2)
步骤2:使用Trainer API微调预训练模型
from transformers import ( AutoModelForSequenceClassification, AutoTokenizer, TrainingArguments, Trainer ) import evaluate import numpy as np # 加载预训练模型和分词器 model_name = "distilbert-base-uncased" tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForSequenceClassification.from_pretrained( model_name, num_labels=3 # 情感类别:积极/消极/中性 ) # 数据预处理:分词 def preprocess_function(examples): return tokenizer(examples['text'], truncation=True, max_length=128) tokenized_dataset = dataset.map(preprocess_function, batched=True) # 定义评估指标 metric = evaluate.load("accuracy") def compute_metrics(eval_pred): logits, labels = eval_pred predictions = np.argmax(logits, axis=-1) return metric.compute(predictions=predictions, references=labels) # 设置训练参数 training_args = TrainingArguments( output_dir="./sentiment-model", learning_rate=2e-5, per_device_train_batch_size=16, per_device_eval_batch_size=16, num_train_epochs=3, evaluation_strategy="epoch", # 每个epoch评估一次 save_strategy="epoch", # 每个epoch保存模型 load_best_model_at_end=True, # 训练结束加载最佳模型 ) # 初始化Trainer并训练 trainer = Trainer( model=model, args=training_args, train_dataset=tokenized_dataset["train"], eval_dataset=tokenized_dataset["test"], compute_metrics=compute_metrics, ) trainer.train() # 启动训练
步骤3:部署为REST API(使用Hugging Face Inference Endpoints)
# 使用huggingface_hub部署模型 from huggingface_hub import HfApi, create_inference_endpoint api = HfApi(token="your-hf-token") # 上传模型到Hugging Face Hub api.upload_folder( folder_path="./sentiment-model", repo_id="your-username/sentiment-analysis-model", repo_type="model", ) # 创建推理端点(需Hugging Face Pro账号) endpoint = create_inference_endpoint( name="sentiment-analysis-endpoint", repository="your-username/sentiment-analysis-model", framework="pytorch", task="text-classification", accelerator="cpu", # 或"gpu" instance_size="small", # 实例规格 ) # 测试API import requests API_URL = endpoint.url headers = {"Authorization": f"Bearer your-hf-token"} def query(payload): response = requests.post(API_URL, headers=headers, json=payload) return response.json() result = query({ "inputs": "这个产品质量太差了,用了一天就坏了", }) print(result) # 输出:[{"label": "消极", "score": 0.98}]
3.3 AWS SageMaker分布式训练:突破单卡算力限制
对于超大规模模型(如10B+参数),单GPU训练耗时过长,需使用分布式训练。SageMaker提供自动分布式训练能力,无需手动编写分布式代码:
# SageMaker分布式训练示例(使用内置XGBoost算法) import sagemaker from sagemaker.xgboost.estimator import XGBoost # 配置训练数据路径(S3) train_data = "s3://your-bucket/train.csv" test_data = "s3://your-bucket/test.csv" # 定义训练超参数 hyperparameters = { "max_depth": "5", "eta": "0.2", "gamma": "4", "min_child_weight": "6", "subsample": "0.7", "objective": "binary:logistic", "num_round": "100" } # 创建XGBoost estimator,指定分布式配置 xgb_estimator = XGBoost( entry_point="train.py", # 训练脚本 hyperparameters=hyperparameters, role=sagemaker.get_execution_role(), instance_count=4, # 使用4个实例 instance_type="ml.m5.xlarge", # 实例类型 framework_version="1.5-1", # XGBoost版本 py_version="py38", # 启用分布式训练 distribute={"smdistributed": {"dataparallel": {"enabled": True}}}, ) # 启动训练 xgb_estimator.fit({"train": train_data, "validation": test_data})
SageMaker会自动处理节点间通信、数据分片和梯度同步,使4节点训练速度接近单节点的3.8倍(线性加速比达0.95)。
四、工具链整合:构建端到端AI开发流水线
单一工具的价值有限,而将智能编码、数据标注、模型训练工具无缝整合,可构建从需求到部署的全自动化流水线。以下通过一个完整案例展示三者协同工作流。
4.1 综合案例:构建客户评论情感分析系统
目标:从电商平台爬取客户评论,标注情感类型,训练分类模型,并部署为API服务。
阶段1:数据采集与预处理(智能编码工具辅助)
使用GitHub Copilot编写评论爬取脚本:
Prompt:
# 使用Python爬取亚马逊产品评论: # 1. 目标URL:https://www.amazon.com/product-reviews/B08XYZ1234 # 2. 需提取:评论内容、评分(1-5星)、日期 # 3. 反爬措施:使用随机User-Agent,添加1-3秒延迟 # 4. 存储格式:CSV文件(columns: content, rating, date) # 5. 使用requests和BeautifulSoup库,处理页面动态加载(可能需要Selenium)
Copilot生成的核心代码:
import requests import time import random import csv from bs4 import BeautifulSoup from selenium import webdriver from selenium.webdriver.chrome.options import Options # 设置随机User-Agent USER_AGENTS = [ "Mozilla/5.0 (Windows NT 10.0; Win64; x64)...", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7)..." ] def get_amazon_reviews(product_id, max_pages=5): reviews = [] # 配置Selenium(处理动态加载) chrome_options = Options() chrome_options.add_argument("--headless=new") # 无头模式 driver = webdriver.Chrome(options=chrome_options) for page in range(1, max_pages+1): url = f"https://www.amazon.com/product-reviews/{product_id}?pageNumber={page}" driver.get(url) time.sleep(random.uniform(1, 3)) # 随机延迟 soup = BeautifulSoup(driver.page_source, "html.parser") # 提取评论卡片 review_cards = soup.find_all("div", {"data-hook": "review"}) for card in review_cards: # 提取评分(如"5.0 out of 5 stars" → 5.0) rating = card.find("i", {"data-hook": "review-star-rating"}).text rating = float(rating.split()[0]) # 提取评论内容 content = card.find("span", {"data-hook": "review-body"}).text.strip() # 提取日期 date = card.find("span", {"data-hook": "review-date"}).text date = date.split("on ")[-1] # 格式化为"January 1, 2024" reviews.append({ "content": content, "rating": rating, "date": date }) print(f"已爬取第{page}页,共{len(reviews)}条评论") driver.quit() # 保存为CSV with open("amazon_reviews.csv", "w", newline="", encoding="utf-8") as f: writer = csv.DictWriter(f, fieldnames=["content", "rating", "date"]) writer.writeheader() writer.writerows(reviews) return reviews # 爬取产品B08XYZ1234的10页评论 get_amazon_reviews("B08XYZ1234", max_pages=10)
阶段2:数据标注(Label Studio处理)
- 将爬取的amazon_reviews.csv导入Label Studio,创建"情感分类"项目
- 标注配置(仅保留核心部分):
<View> <Text name="content" value="$content" /> <Choices name="sentiment" toName="content" choice="single"> <Choice value="正面" /> <Choice value="负面" /> <Choice value="中性" /> </Choices> <!-- 显示原始评分作为参考 --> <Text name="rating" value="原始评分: $rating" /> </View>
- 启动标注,利用"原始评分"辅助判断(如5星→大概率正面),完成500条评论标注
阶段3:模型训练与部署(Hugging Face+SageMaker)
- 使用标注数据微调distilbert-base-uncased模型(参考3.2节代码)
- 在SageMaker部署为实时推理端点:
# 创建SageMaker模型 from sagemaker.huggingface.model import HuggingFaceModel huggingface_model = HuggingFaceModel( model_data="s3://your-bucket/sentiment-model.tar.gz", # 模型S3路径 role=role, transformers_version="4.26", pytorch_version="1.13", py_version="py39", ) # 部署为端点 predictor = huggingface_model.deploy( initial_instance_count=1, instance_type="ml.m5.xlarge" ) # 测试预测 result = predictor.predict({ "inputs": "这个产品超出预期,续航比宣传的还长!" }) print(result) # [{'label': '正面', 'score': 0.97}]
阶段4:流水线自动化(GitHub Actions整合)
通过GitHub Actions实现"代码提交→自动测试→模型训练→部署更新"全流程自动化:
# .github/workflows/ai-pipeline.yml name: AI模型流水线 on: push: branches: [ main ] paths: - 'train.py' # 训练脚本变更触发 - 'requirements.txt' jobs: train-and-deploy: runs-on: ubuntu-latest steps: - name: 拉取代码 uses: actions/checkout@v4 - name: 设置Python uses: actions/setup-python@v4 with: python-version: '3.9' - name: 安装依赖 run: pip install -r requirements.txt - name: 运行测试 run: pytest tests/ - name: 训练模型 run: python train.py --data-path ./data --epochs 3 - name: 部署到SageMaker run: | aws configure set aws_access_key_id ${{ secrets.AWS_ACCESS_KEY }} aws configure set aws_secret_access_key ${{ secrets.AWS_SECRET_KEY }} python deploy.py # 部署脚本
4.2 效率提升量化分析
通过引入AI工具链,该情感分析项目的开发周期从传统方法的30天缩短至12天,各阶段耗时对比:
| 开发阶段 | 传统方法(天) | AI工具链(天) | 效率提升 |
|---|---|---|---|
| 数据采集与清洗 | 7 | 2 | 71% |
| 数据标注 | 10 | 4 | 60% |
| 模型开发与训练 | 8 | 3 | 62.5% |
| 部署与测试 | 5 | 3 | 40% |
| 总计 | 30 | 12 | 60% |
五、挑战与未来趋势:AI工具链的进化方向
尽管AI工具链已显著提升开发效率,但仍面临质量可靠性、系统复杂性、伦理安全三大核心挑战:
5.1 当前工具的局限性
- 智能编码工具的"幻觉"问题
GitHub Copilot等工具可能生成看似正确但实际错误的代码,如:
# Copilot生成的"计算斐波那契数列"函数(有bug) def fibonacci(n): if n <= 0: return [] elif n == 1: return [0] sequence = [0, 1] for i in range(2, n): next_num = sequence[i-1] + sequence[i-2] sequence.append(next_num) return sequence # 测试fibonacci(5) → [0,1,1,2,3](正确) # 但用户要求"返回第n个斐波那契数"而非列表,Copilot误解了需求
据Stanford CS Dept 2024年研究,Copilot生成的代码中37%存在至少一个功能性bug,需开发者人工校验。
-
数据标注的成本与偏见
- 即使使用AI辅助,专业领域标注(如医疗影像)成本仍高达**$1-5/条**
- 标注员的主观偏见会引入数据偏差,如将"这个产品很有性价比"错误标注为"中性"(实际应为"正面")
-
模型训练平台的资源门槛
训练10B参数模型需8×A100 GPU(单卡),单轮训练成本超10,000,中小企业难以承担。
5.2 未来技术趋势
-
多模态工具融合
下一代编码工具将不仅处理代码,还能理解需求文档、UI设计稿甚至语音指令。例如,输入"根据这个Figma设计生成登录页面React组件",工具自动分析设计稿尺寸、颜色,生成符合规范的前端代码。 -
个性化AI助手
通过学习团队代码风格、架构偏好和业务逻辑,工具生成的代码将与现有系统无缝融合。如识别团队习惯使用FastAPI而非Flask,自动调整生成的API代码框架。 -
低代码化与平民化
模型训练平台将进一步降低技术门槛,通过可视化界面完成模型微调与部署。Hugging Face已推出"Train"标签页,用户上传数据后,只需选择模型和超参数,点击"开始训练"即可。 -
边缘设备原生支持
随着边缘AI芯片发展,未来可在本地笔记本完成中等规模模型训练(如7B参数LLM),无需依赖云端算力,数据隐私性大幅提升。
结语:工具革命下的开发者角色进化
从智能编码工具解放双手,到数据标注工具降低数据门槛,再到训练平台简化模型开发,AI工具链正重构软件开发的"生产关系"。这并非削弱开发者价值,而是将创造力从重复性劳动中释放,转向更核心的需求分析、架构设计与伦理决策。
未来的AI开发者,将是"工具指挥官"——懂得如何驾驭智能工具,通过精准Prompt引导AI产出,通过质量控制确保结果可靠,通过工具链整合实现效率最大化。正如计算机从穿孔卡片进化到图形界面,AI工具链的成熟,终将让"人人都能开发AI"的愿景成为现实。
思考问题:当AI工具能自动生成80%的代码和数据标注,开发者的核心竞争力将转向哪些不可替代的能力?欢迎在评论区分享你的观点。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 26
26 0
0- 0



 已为社区贡献88条内容
已为社区贡献88条内容

所有评论(0)