
AI工具全景:智能编码、数据标注与模型训练平台的深度解析
本文系统介绍了AI工具生态系统的三大核心组件:智能编码工具、数据标注工具和模型训练平台。以GitHub Copilot为代表的智能编码工具显著提升了开发效率,数据标注工具为AI模型提供高质量训练数据,而分布式训练平台则支持大规模模型开发。文章通过代码示例、流程图和详细分析,展示了各类工具的架构、工作流程及应用场景,并探讨了AI工具集成、安全伦理考量及未来发展趋势。AI工具正在重塑技术开发范式,其演
引言
人工智能正在重塑技术世界的格局,而AI工具则是这一变革的核心驱动力。从智能编码助手到数据标注平台,再到模型训练基础设施,这些工具正在大幅降低AI应用的门槛,加速技术创新步伐。本文将深入探讨三大类关键AI工具:智能编码工具(以GitHub Copilot为代表)、数据标注工具和模型训练平台,通过代码示例、流程图、Prompt案例和详细分析,全面展现现代AI工具生态的全貌。
一、智能编码工具:GitHub Copilot深度解析
1.1 GitHub Copilot技术架构
GitHub Copilot是基于OpenAI Codex模型的AI编程助手,它通过分析代码上下文提供智能建议。其核心技术原理如下:
技术架构核心组件:
-
代码理解引擎:基于Transformer架构,训练于数十亿行公开代码
-
上下文分析器:实时解析当前文件的代码语义和结构
-
多语言支持层:支持Python、JavaScript、Java等主流编程语言
-
安全过滤系统:防止生成不安全或不适当的代码建议
python
# Copilot代码生成示例:快速实现一个二叉树类
class TreeNode:
def __init__(self, val=0, left=None, right=None):
self.val = val
self.left = left
self.right = right
class BinaryTree:
def __init__(self):
self.root = None
def insert(self, val):
"""插入节点到二叉树中"""
if not self.root:
self.root = TreeNode(val)
else:
self._insert_recursive(self.root, val)
def _insert_recursive(self, node, val):
if val < node.val:
if node.left is None:
node.left = TreeNode(val)
else:
self._insert_recursive(node.left, val)
else:
if node.right is None:
node.right = TreeNode(val)
else:
self._insert_recursive(node.right, val)
def inorder_traversal(self):
"""中序遍历二叉树"""
result = []
self._inorder_recursive(self.root, result)
return result
def _inorder_recursive(self, node, result):
if node:
self._inorder_recursive(node.left, result)
result.append(node.val)
self._inorder_recursive(node.right, result)
# 使用Copilot生成的测试代码
def test_binary_tree():
tree = BinaryTree()
values = [5, 3, 7, 1, 9, 6]
for val in values:
tree.insert(val)
print("中序遍历结果:", tree.inorder_traversal())
# 预期输出: [1, 3, 5, 6, 7, 9]
if __name__ == "__main__":
test_binary_tree()
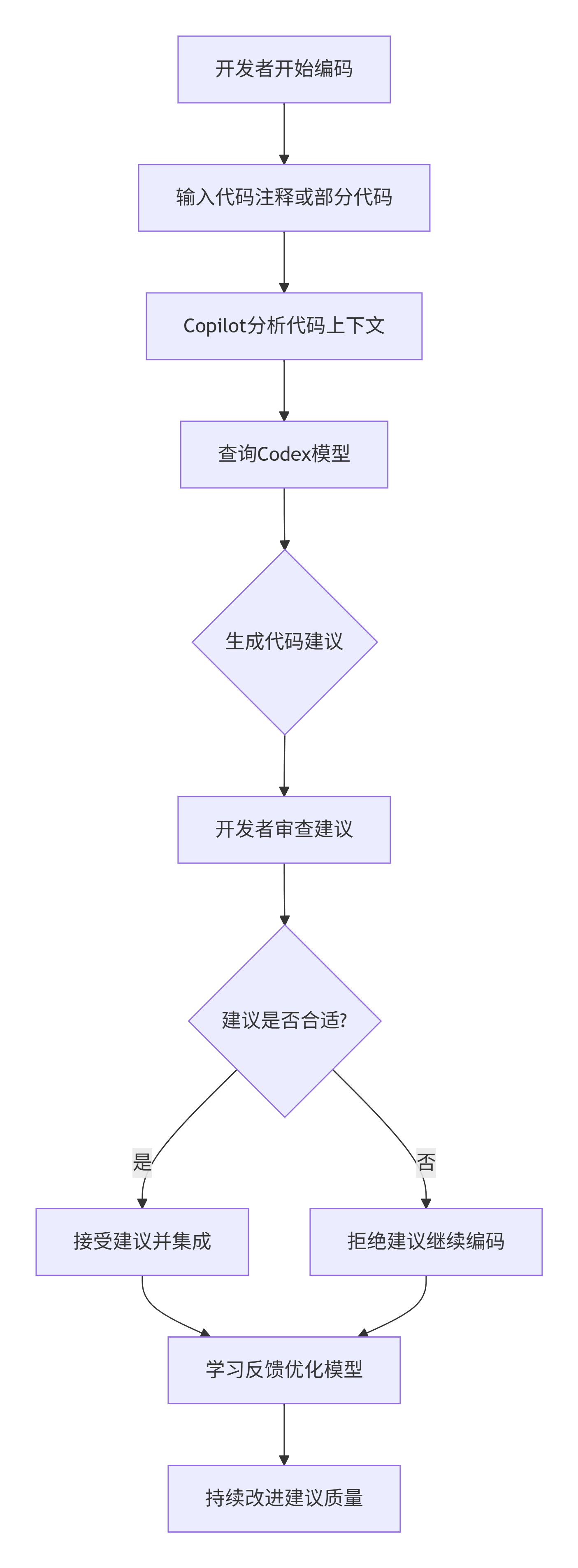
1.2 Copilot工作流程详解
graph TD
A[开发者开始编码] --> B[输入代码注释或部分代码]
B --> C[Copilot分析代码上下文]
C --> D[查询Codex模型]
D --> E{生成代码建议}
E --> F[开发者审查建议]
F --> G{建议是否合适?}
G -->|是| H[接受建议并集成]
G -->|否| I[拒绝建议继续编码]
H --> J[学习反馈优化模型]
I --> J
J --> K[持续改进建议质量]
1.3 Copilot Prompt工程实践
有效的Prompt编写技巧:
python
# 好的Prompt示例:清晰的注释描述需求
def calculate_portfolio_risk(portfolio):
"""
计算投资组合风险指标
输入: portfolio - 字典格式 {'股票代码': {'权重': 0.3, '波动率': 0.2, '相关性': 矩阵}}
输出: 包含以下指标的字典:
- 组合波动率
- 在险价值(VaR) - 95%置信水平
- 预期短缺(ES)
- 夏普比率(假设无风险利率3%)
"""
# Copilot基于详细注释生成专业金融计算代码
pass
# 另一个优秀Prompt示例:提供完整函数签名和类型提示
from typing import List, Dict, Tuple
import numpy as np
from dataclasses import dataclass
@dataclass
class RiskMetrics:
volatility: float
var_95: float
expected_shortfall: float
sharpe_ratio: float
def compute_risk_metrics(weights: List[float],
volatilities: List[float],
correlation_matrix: np.ndarray,
risk_free_rate: float = 0.03) -> RiskMetrics:
"""
计算现代投资组合理论下的风险指标
Args:
weights: 各资产权重列表,总和为1
volatilities: 各资产年化波动率
correlation_matrix: 资产相关性矩阵
risk_free_rate: 无风险利率,默认3%
Returns:
RiskMetrics: 包含各项风险指标的数据类
"""
# Copilot会生成专业的投资组合风险计算代码
pass
1.4 Copilot在不同场景下的应用
Web开发场景:
javascript
// Copilot快速生成React组件
import React, { useState, useEffect } from 'react';
// 输入: "创建一个用户管理面板,包含搜索、列表和分页功能"
const UserManagementPanel = () => {
const [users, setUsers] = useState([]);
const [searchTerm, setSearchTerm] = useState('');
const [currentPage, setCurrentPage] = useState(1);
const [totalPages, setTotalPages] = useState(1);
// Copilot自动生成数据获取逻辑
useEffect(() => {
const fetchUsers = async () => {
try {
const response = await fetch(`/api/users?search=${searchTerm}&page=${currentPage}`);
const data = await response.json();
setUsers(data.users);
setTotalPages(data.totalPages);
} catch (error) {
console.error('获取用户数据失败:', error);
}
};
fetchUsers();
}, [searchTerm, currentPage]);
// Copilot生成搜索处理函数
const handleSearch = (event) => {
setSearchTerm(event.target.value);
setCurrentPage(1); // 重置到第一页
};
// Copilot生成分页组件
const Pagination = () => {
const pageNumbers = [];
for (let i = 1; i <= totalPages; i++) {
pageNumbers.push(
<button
key={i}
onClick={() => setCurrentPage(i)}
className={`px-3 py-1 mx-1 ${currentPage === i ? 'bg-blue-500 text-white' : 'bg-gray-200'}`}
>
{i}
</button>
);
}
return <div className="flex justify-center mt-4">{pageNumbers}</div>;
};
return (
<div className="p-6">
<h2 className="text-2xl font-bold mb-4">用户管理</h2>
<input
type="text"
placeholder="搜索用户..."
value={searchTerm}
onChange={handleSearch}
className="w-full p-2 border border-gray-300 rounded mb-4"
/>
<div className="bg-white shadow overflow-hidden rounded-lg">
<table className="min-w-full divide-y divide-gray-200">
<thead className="bg-gray-50">
<tr>
<th className="px-6 py-3 text-left text-xs font-medium text-gray-500 uppercase tracking-wider">
用户名
</th>
<th className="px-6 py-3 text-left text-xs font-medium text-gray-500 uppercase tracking-wider">
邮箱
</th>
<th className="px-6 py-3 text-left text-xs font-medium text-gray-500 uppercase tracking-wider">
角色
</th>
</tr>
</thead>
<tbody className="bg-white divide-y divide-gray-200">
{users.map(user => (
<tr key={user.id}>
<td className="px-6 py-4 whitespace-nowrap">{user.username}</td>
<td className="px-6 py-4 whitespace-nowrap">{user.email}</td>
<td className="px-6 py-4 whitespace-nowrap">{user.role}</td>
</tr>
))}
</tbody>
</table>
</div>
<Pagination />
</div>
);
};
export default UserManagementPanel;
二、数据标注工具:AI的数据基石
2.1 数据标注工具技术架构
数据标注工具是AI模型训练的前提,现代标注平台采用多层次架构:
python
# 数据标注系统核心组件示例
import asyncio
from enum import Enum
from typing import List, Dict, Any, Optional
from dataclasses import dataclass
from PIL import Image, ImageDraw
import json
class AnnotationType(Enum):
BOUNDING_BOX = "bounding_box"
POLYGON = "polygon"
SEGMENTATION = "segmentation"
CLASSIFICATION = "classification"
@dataclass
class Annotation:
id: str
type: AnnotationType
data: Dict[str, Any]
label: str
confidence: Optional[float] = None
class DataAnnotationPlatform:
def __init__(self):
self.projects = {}
self.datasets = {}
self.annotations = {}
def create_project(self, name: str, annotation_type: AnnotationType, labels: List[str]):
"""创建标注项目"""
project_id = f"project_{len(self.projects) + 1}"
project = {
'id': project_id,
'name': name,
'annotation_type': annotation_type,
'labels': labels,
'created_at': '2024-01-01',
'status': 'active'
}
self.projects[project_id] = project
return project
def upload_dataset(self, project_id: str, images: List[str]):
"""上传数据集到项目"""
dataset_id = f"dataset_{len(self.datasets) + 1}"
dataset = {
'id': dataset_id,
'project_id': project_id,
'images': images,
'annotation_count': 0
}
self.datasets[dataset_id] = dataset
return dataset
def add_annotation(self, image_id: str, annotation: Annotation):
"""添加标注到图像"""
if image_id not in self.annotations:
self.annotations[image_id] = []
self.annotations[image_id].append(annotation)
def export_annotations(self, project_id: str, format: str = "COCO"):
"""导出标注数据"""
project_annotations = {}
for image_id, annotations in self.annotations.items():
if any(ann for ann in annotations if self._belongs_to_project(ann, project_id)):
project_annotations[image_id] = annotations
if format == "COCO":
return self._export_to_coco(project_annotations)
elif format == "YOLO":
return self._export_to_yolo(project_annotations)
else:
return self._export_to_json(project_annotations)
def _export_to_coco(self, annotations: Dict) -> Dict:
"""导出为COCO格式"""
coco_format = {
"images": [],
"annotations": [],
"categories": []
}
# 实现COCO格式转换逻辑
return coco_format
def _export_to_yolo(self, annotations: Dict) -> str:
"""导出为YOLO格式"""
yolo_lines = []
# 实现YOLO格式转换逻辑
return "\n".join(yolo_lines)
# 使用示例
platform = DataAnnotationPlatform()
project = platform.create_project(
"车辆检测",
AnnotationType.BOUNDING_BOX,
["car", "truck", "motorcycle", "bus"]
)
dataset = platform.upload_dataset(project['id'], ["image1.jpg", "image2.jpg"])
# 添加标注示例
car_annotation = Annotation(
id="ann_1",
type=AnnotationType.BOUNDING_BOX,
data={"x": 100, "y": 150, "width": 200, "height": 80},
label="car",
confidence=0.95
)
platform.add_annotation("image1.jpg", car_annotation)
# 导出标注
coco_data = platform.export_annotations(project['id'], "COCO")
print("COCO格式数据:", json.dumps(coco_data, indent=2))
2.2 数据标注平台工作流程
graph LR
A[原始数据收集] --> B[数据清洗与预处理]
B --> C[创建标注任务]
C --> D[分配标注人员]
D --> E[进行数据标注]
E --> F[质量审核]
F --> G{质量是否合格?}
G -->|否| E
G -->|是| H[标注数据导出]
H --> I[模型训练使用]
I --> J[模型预测反馈]
J --> K[主动学习优化]
K --> A

2.3 智能标注技术:AI辅助标注
python
# 基于预训练模型的智能标注辅助系统
import torch
import torchvision
from torchvision.models.detection import fasterrcnn_resnet50_fpn
from PIL import Image, ImageDraw
import numpy as np
class SmartAnnotationAssistant:
def __init__(self, model_path: Optional[str] = None):
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 加载预训练模型
if model_path:
self.model = self._load_custom_model(model_path)
else:
self.model = fasterrcnn_resnet50_fpn(pretrained=True)
self.model.to(self.device)
self.model.eval()
def _load_custom_model(self, model_path: str):
"""加载自定义训练模型"""
model = fasterrcnn_resnet50_fpn(num_classes=91) # COCO类别数
model.load_state_dict(torch.load(model_path, map_location=self.device))
return model
def predict_annotations(self, image_path: str, confidence_threshold: float = 0.7):
"""预测图像中的目标标注"""
# 图像预处理
image = Image.open(image_path).convert('RGB')
transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
])
image_tensor = transform(image).unsqueeze(0).to(self.device)
# 模型预测
with torch.no_grad():
predictions = self.model(image_tensor)
# 解析预测结果
pred = predictions[0]
boxes = pred['boxes'].cpu().numpy()
scores = pred['scores'].cpu().numpy()
labels = pred['labels'].cpu().numpy()
# 过滤低置信度预测
high_conf_indices = scores >= confidence_threshold
boxes = boxes[high_conf_indices]
scores = scores[high_conf_indices]
labels = labels[high_conf_indices]
# 转换为标注格式
annotations = []
for i, (box, score, label) in enumerate(zip(boxes, scores, labels)):
annotation = Annotation(
id=f"pred_{i}",
type=AnnotationType.BOUNDING_BOX,
data={
"x_min": box[0],
"y_min": box[1],
"x_max": box[2],
"y_max": box[3]
},
label=self._get_class_name(label),
confidence=float(score)
)
annotations.append(annotation)
return annotations, image
def _get_class_name(self, label_id: int) -> str:
"""将标签ID转换为类别名称"""
coco_classes = [
'__background__', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'N/A', 'stop sign',
'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'N/A', 'backpack', 'umbrella', 'N/A', 'N/A',
'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball',
'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket',
'bottle', 'N/A', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana',
'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut',
'cake', 'chair', 'couch', 'potted plant', 'bed', 'N/A', 'dining table', 'N/A', 'N/A',
'toilet', 'N/A', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'N/A', 'book',
'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush'
]
return coco_classes[label_id] if label_id < len(coco_classes) else "unknown"
def visualize_annotations(self, image, annotations, output_path: str):
"""可视化标注结果"""
draw = ImageDraw.Draw(image)
for ann in annotations:
if ann.type == AnnotationType.BOUNDING_BOX:
box = ann.data
# 绘制边界框
draw.rectangle(
[box['x_min'], box['y_min'], box['x_max'], box['y_max']],
outline='red',
width=3
)
# 绘制标签
label_text = f"{ann.label}: {ann.confidence:.2f}"
draw.text(
(box['x_min'], box['y_min'] - 15),
label_text,
fill='red'
)
image.save(output_path)
return image
# 使用智能标注助手
assistant = SmartAnnotationAssistant()
annotations, image = assistant.predict_annotations("sample_image.jpg")
assistant.visualize_annotations(image, annotations, "annotated_image.jpg")
print(f"检测到 {len(annotations)} 个目标")
for ann in annotations:
print(f"- {ann.label}: 置信度 {ann.confidence:.2f}")
三、模型训练平台:规模化AI开发基础设施
3.1 分布式训练平台架构
现代模型训练平台需要支持大规模分布式训练、自动超参数优化和实验管理:
python
# 分布式训练平台核心组件
import os
import json
import time
from datetime import datetime
from typing import Dict, List, Any, Optional
import torch
import torch.distributed as dist
import torch.nn as nn
from torch.utils.data import DataLoader, DistributedSampler
import argparse
class ExperimentTracker:
"""实验跟踪器"""
def __init__(self, experiment_name: str):
self.experiment_name = experiment_name
self.metrics = {}
self.start_time = datetime.now()
def log_metrics(self, epoch: int, metrics: Dict[str, float]):
"""记录训练指标"""
if epoch not in self.metrics:
self.metrics[epoch] = {}
self.metrics[epoch].update(metrics)
self._save_metrics()
def _save_metrics(self):
"""保存指标到文件"""
os.makedirs('experiments', exist_ok=True)
filename = f"experiments/{self.experiment_name}_{self.start_time.strftime('%Y%m%d_%H%M%S')}.json"
with open(filename, 'w') as f:
json.dump({
'experiment_name': self.experiment_name,
'start_time': self.start_time.isoformat(),
'metrics': self.metrics
}, f, indent=2)
class DistributedTrainingPlatform:
"""分布式训练平台"""
def __init__(self, backend: str = 'nccl'):
self.backend = backend
self.initialized = False
def init_distributed(self, rank: int, world_size: int):
"""初始化分布式训练环境"""
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
dist.init_process_group(
backend=self.backend,
rank=rank,
world_size=world_size
)
self.initialized = True
def cleanup(self):
"""清理分布式训练环境"""
if self.initialized:
dist.destroy_process_group()
class HyperparameterOptimizer:
"""超参数优化器"""
def __init__(self, search_space: Dict[str, List[Any]]):
self.search_space = search_space
self.completed_trials = []
self.best_trial = None
def suggest_parameters(self, algorithm: str = "random") -> Dict[str, Any]:
"""建议下一组超参数"""
if algorithm == "random":
return self._random_search()
elif algorithm == "grid":
return self._grid_search()
else:
raise ValueError(f"不支持的算法: {algorithm}")
def _random_search(self) -> Dict[str, Any]:
"""随机搜索"""
params = {}
for param_name, values in self.search_space.items():
params[param_name] = values[torch.randint(0, len(values), (1,)).item()]
return params
def _grid_search(self) -> Dict[str, Any]:
"""网格搜索 - 简化实现"""
# 实际实现需要考虑所有参数组合
pass
def update_trial_result(self, params: Dict[str, Any], metric: float):
"""更新试验结果"""
trial = {
'params': params,
'metric': metric,
'timestamp': datetime.now()
}
self.completed_trials.append(trial)
# 更新最佳试验
if self.best_trial is None or metric > self.best_trial['metric']:
self.best_trial = trial
# 示例训练脚本
def train_model(rank, world_size, config):
"""分布式训练函数"""
platform = DistributedTrainingPlatform()
platform.init_distributed(rank, world_size)
# 设置设备
torch.cuda.set_device(rank)
device = torch.device(f'cuda:{rank}')
# 创建模型并移至设备
model = config['model_class'](**config['model_params'])
model = model.to(device)
model = nn.parallel.DistributedDataParallel(model, device_ids=[rank])
# 准备数据
train_dataset = config['dataset_class'](**config['dataset_params'])
train_sampler = DistributedSampler(
train_dataset,
num_replicas=world_size,
rank=rank,
shuffle=True
)
train_loader = DataLoader(
train_dataset,
batch_size=config['batch_size'],
sampler=train_sampler,
num_workers=4
)
# 优化器
optimizer = torch.optim.Adam(
model.parameters(),
lr=config['learning_rate'],
weight_decay=config['weight_decay']
)
criterion = nn.CrossEntropyLoss()
# 实验跟踪
tracker = ExperimentTracker(config['experiment_name'])
# 训练循环
for epoch in range(config['epochs']):
train_sampler.set_epoch(epoch)
model.train()
running_loss = 0.0
correct_predictions = 0
total_samples = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = torch.max(output.data, 1)
total_samples += target.size(0)
correct_predictions += (predicted == target).sum().item()
if batch_idx % 100 == 0 and rank == 0:
print(f'Epoch: {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)}]')
# 计算指标
epoch_loss = running_loss / len(train_loader)
epoch_accuracy = 100. * correct_predictions / total_samples
# 记录指标
if rank == 0:
tracker.log_metrics(epoch, {
'loss': epoch_loss,
'accuracy': epoch_accuracy,
'learning_rate': config['learning_rate']
})
print(f'Epoch {epoch}: Loss: {epoch_loss:.4f}, Accuracy: {epoch_accuracy:.2f}%')
platform.cleanup()
# 配置示例
training_config = {
'experiment_name': 'resnet_cifar10',
'model_class': torchvision.models.resnet50,
'model_params': {'num_classes': 10},
'dataset_class': torchvision.datasets.CIFAR10,
'dataset_params': {
'root': './data',
'train': True,
'download': True,
'transform': torchvision.transforms.ToTensor()
},
'batch_size': 64,
'learning_rate': 0.001,
'weight_decay': 1e-4,
'epochs': 50
}
# 超参数搜索空间
hyperparam_space = {
'learning_rate': [0.1, 0.01, 0.001, 0.0001],
'batch_size': [32, 64, 128, 256],
'weight_decay': [0, 1e-4, 1e-3, 1e-2],
'optimizer': ['adam', 'sgd', 'rmsprop']
}
# 启动训练
if __name__ == "__main__":
# 单机多GPU训练示例
world_size = torch.cuda.device_count()
torch.multiprocessing.spawn(
train_model,
args=(world_size, training_config),
nprocs=world_size,
join=True
)
3.2 自动化机器学习(AutoML)平台
python
# AutoML系统实现
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
import numpy as np
import pandas as pd
class AutoMLSystem:
"""自动化机器学习系统"""
def __init__(self):
self.models = {}
self.results = {}
self.best_model = None
def register_model(self, name, model_class, param_grid):
"""注册模型和参数网格"""
self.models[name] = {
'class': model_class,
'param_grid': param_grid
}
def automated_feature_engineering(self, X, y):
"""自动化特征工程"""
# 数值特征处理
numerical_features = X.select_dtypes(include=[np.number]).columns
categorical_features = X.select_dtypes(include=['object']).columns
# 自动化特征变换
from sklearn.feature_selection import SelectKBest, f_classif
from sklearn.preprocessing import OneHotEncoder
transformations = []
# 数值特征标准化
if len(numerical_features) > 0:
transformations.append(('scaler', StandardScaler()))
# 分类特征编码
if len(categorical_features) > 0:
transformations.append(('encoder', OneHotEncoder(handle_unknown='ignore')))
# 特征选择
transformations.append(('feature_selector', SelectKBest(f_classif, k=min(50, X.shape[1]))))
return transformations
def optimize_hyperparameters(self, X, y, cv=5, scoring='accuracy'):
"""超参数优化"""
from sklearn.model_selection import GridSearchCV
best_score = -np.inf
best_model_info = None
feature_pipeline = Pipeline(self.automated_feature_engineering(X, y))
X_processed = feature_pipeline.fit_transform(X, y)
for model_name, model_info in self.models.items():
print(f"优化模型: {model_name}")
grid_search = GridSearchCV(
model_info['class'](),
model_info['param_grid'],
cv=cv,
scoring=scoring,
n_jobs=-1,
verbose=1
)
grid_search.fit(X_processed, y)
self.results[model_name] = {
'best_score': grid_search.best_score_,
'best_params': grid_search.best_params_,
'best_estimator': grid_search.best_estimator_
}
if grid_search.best_score_ > best_score:
best_score = grid_search.best_score_
best_model_info = {
'name': model_name,
'model': grid_search.best_estimator_,
'score': best_score,
'feature_pipeline': feature_pipeline
}
self.best_model = best_model_info
return best_model_info
def create_ensemble(self, top_k=3):
"""创建集成模型"""
from sklearn.ensemble import VotingClassifier
# 选择前k个最佳模型
sorted_models = sorted(
self.results.items(),
key=lambda x: x[1]['best_score'],
reverse=True
)[:top_k]
estimators = []
for model_name, model_info in sorted_models:
estimators.append(
(model_name, model_info['best_estimator'])
)
ensemble = VotingClassifier(
estimators=estimators,
voting='soft'
)
return ensemble
def generate_model_report(self):
"""生成模型比较报告"""
report = "AutoML 模型比较报告\n"
report += "=" * 50 + "\n"
for model_name, result in self.results.items():
report += f"模型: {model_name}\n"
report += f"最佳得分: {result['best_score']:.4f}\n"
report += f"最佳参数: {result['best_params']}\n"
report += "-" * 30 + "\n"
if self.best_model:
report += f"\n🎉 最佳模型: {self.best_model['name']}\n"
report += f"📊 最佳得分: {self.best_model['score']:.4f}\n"
return report
# 使用AutoML系统
def demo_automl():
"""AutoML系统演示"""
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 加载数据
data = load_iris()
X, y = data.data, data.target
# 分割数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建AutoML系统
automl = AutoMLSystem()
# 注册模型
automl.register_model(
'Random Forest',
RandomForestClassifier,
{
'n_estimators': [50, 100, 200],
'max_depth': [3, 5, 7, None],
'min_samples_split': [2, 5, 10]
}
)
automl.register_model(
'SVM',
SVC,
{
'C': [0.1, 1, 10, 100],
'kernel': ['linear', 'rbf', 'poly'],
'gamma': ['scale', 'auto']
}
)
automl.register_model(
'Gradient Boosting',
GradientBoostingClassifier,
{
'n_estimators': [50, 100, 200],
'learning_rate': [0.01, 0.1, 0.2],
'max_depth': [3, 4, 5]
}
)
# 运行AutoML
best_model = automl.optimize_hyperparameters(X_train, y_train)
# 生成报告
report = automl.generate_model_report()
print(report)
# 创建集成模型
ensemble = automl.create_ensemble(top_k=2)
ensemble.fit(X_train, y_train)
ensemble_score = ensemble.score(X_test, y_test)
print(f"集成模型测试准确率: {ensemble_score:.4f}")
return automl, best_model
# 运行演示
if __name__ == "__main__":
automl_system, best_model = demo_automl()
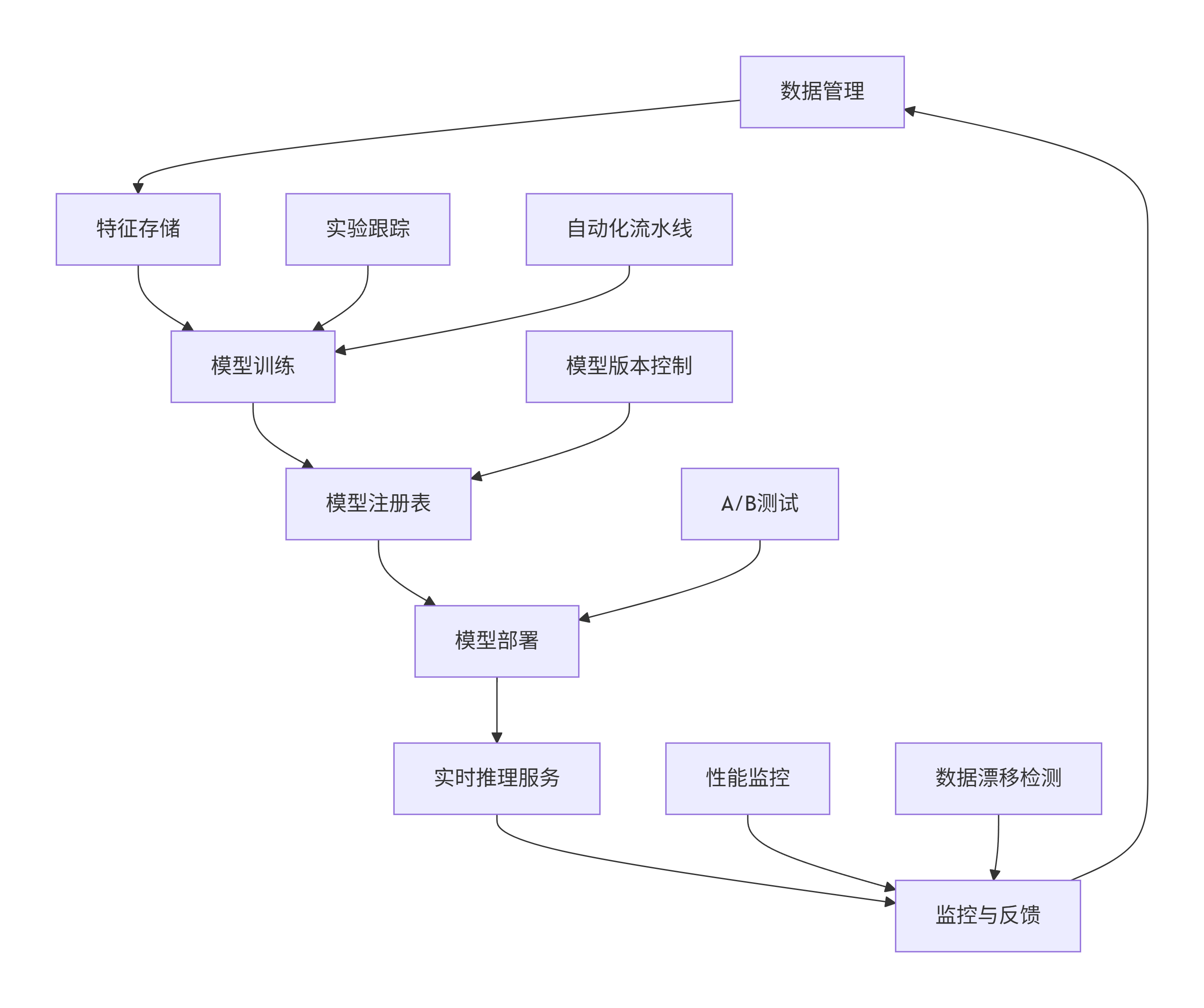
3.3 MLOps平台架构
graph TB
A[数据管理] --> B[特征存储]
B --> C[模型训练]
C --> D[模型注册表]
D --> E[模型部署]
E --> F[实时推理服务]
F --> G[监控与反馈]
G --> A
H[实验跟踪] --> C
I[自动化流水线] --> C
J[模型版本控制] --> D
K[A/B测试] --> E
L[性能监控] --> G
M[数据漂移检测] --> G
四、AI工具集成与最佳实践
4.1 端到端AI开发流水线
python
# 完整的AI开发流水线集成
class EndToEndAIPipeline:
"""端到端AI开发流水线"""
def __init__(self):
self.components = {}
self.pipeline_stages = []
def add_component(self, name, component):
"""添加组件到流水线"""
self.components[name] = component
def define_pipeline(self, stages):
"""定义流水线阶段"""
self.pipeline_stages = stages
def execute_pipeline(self, data_input):
"""执行完整流水线"""
results = {}
current_data = data_input
for stage in self.pipeline_stages:
stage_name = stage['name']
component_name = stage['component']
parameters = stage.get('parameters', {})
print(f"执行阶段: {stage_name}")
# 获取组件
component = self.components[component_name]
# 执行组件
if hasattr(component, 'process'):
current_data = component.process(current_data, **parameters)
else:
current_data = component(current_data, **parameters)
results[stage_name] = current_data
print(f"阶段 {stage_name} 完成")
return results
# 示例组件实现
class DataCollector:
"""数据收集组件"""
def process(self, data_source, **kwargs):
print(f"从 {data_source} 收集数据")
# 实现数据收集逻辑
return {"raw_data": "sample_data", "metadata": {}}
class DataPreprocessor:
"""数据预处理组件"""
def process(self, data, **kwargs):
print("预处理数据...")
# 实现数据清洗和预处理
return {"processed_data": "cleaned_data", "preprocessing_stats": {}}
class FeatureEngineer:
"""特征工程组件"""
def process(self, data, **kwargs):
print("进行特征工程...")
# 实现特征提取和转换
return {"features": "engineered_features", "feature_names": []}
class ModelTrainer:
"""模型训练组件"""
def process(self, data, **kwargs):
print("训练模型...")
# 实现模型训练
return {"model": "trained_model", "training_metrics": {}}
class ModelEvaluator:
"""模型评估组件"""
def process(self, data, **kwargs):
print("评估模型性能...")
# 实现模型评估
return {"evaluation_results": "metrics", "performance_report": {}}
class ModelDeployer:
"""模型部署组件"""
def process(self, data, **kwargs):
print("部署模型...")
# 实现模型部署
return {"deployment_status": "success", "endpoint": "api_endpoint"}
# 构建端到端流水线
def build_complete_pipeline():
"""构建完整AI流水线"""
pipeline = EndToEndAIPipeline()
# 注册组件
pipeline.add_component('data_collector', DataCollector())
pipeline.add_component('preprocessor', DataPreprocessor())
pipeline.add_component('feature_engineer', FeatureEngineer())
pipeline.add_component('model_trainer', ModelTrainer())
pipeline.add_component('model_evaluator', ModelEvaluator())
pipeline.add_component('model_deployer', ModelDeployer())
# 定义流水线阶段
pipeline_stages = [
{
'name': '数据收集',
'component': 'data_collector',
'parameters': {'source_type': 'database'}
},
{
'name': '数据预处理',
'component': 'preprocessor',
'parameters': {'cleaning_method': 'standard'}
},
{
'name': '特征工程',
'component': 'feature_engineer',
'parameters': {'feature_selection': True}
},
{
'name': '模型训练',
'component': 'model_trainer',
'parameters': {'algorithm': 'random_forest'}
},
{
'name': '模型评估',
'component': 'model_evaluator',
'parameters': {'validation_split': 0.2}
},
{
'name': '模型部署',
'component': 'model_deployer',
'parameters': {'deployment_env': 'production'}
}
]
pipeline.define_pipeline(pipeline_stages)
return pipeline
# 执行完整流水线
def run_complete_pipeline():
"""运行完整AI流水线"""
pipeline = build_complete_pipeline()
# 执行流水线
results = pipeline.execute_pipeline("my_data_source")
print("\n" + "="*50)
print("AI流水线执行完成!")
print("="*50)
for stage_name, stage_result in results.items():
print(f"{stage_name}: {stage_result}")
return results
# 运行示例
if __name__ == "__main__":
pipeline_results = run_complete_pipeline()
4.2 AI工具安全与伦理考量
python
# AI工具安全与伦理检查系统
import re
import hashlib
from typing import List, Dict, Set
class AI SafetyChecker:
"""AI工具安全与伦理检查器"""
def __init__(self):
self.sensitive_patterns = [
r'\b(密码|密钥|token|api[_-]?key)\s*[:=]\s*[\w\-]+\b',
r'\b(身份证|手机号|电话|身份证号)\s*[:=]\s*[\d\-]+\b',
r'\b(银行卡|信用卡|账号)\s*[:=]\s*[\d\-]+\b',
r'\b(暴力|仇恨|歧视|偏见|攻击性)\b',
]
self.ethical_guidelines = {
'fairness': '模型应该公平对待所有群体',
'privacy': '保护用户隐私和数据安全',
'transparency': '模型决策应该可解释',
'accountability': '明确模型责任归属'
}
def check_code_safety(self, code: str) -> Dict[str, List[str]]:
"""检查代码安全性"""
issues = {
'security_risks': [],
'ethical_concerns': [],
'bias_alerts': []
}
# 检查安全风险
for pattern in self.sensitive_patterns:
matches = re.findall(pattern, code, re.IGNORECASE)
if matches:
issues['security_risks'].extend(matches)
# 检查偏见相关模式
bias_patterns = [
r'gender.*bias|性别.*偏见',
r'racial.*bias|种族.*偏见',
r'age.*discrimination|年龄.*歧视'
]
for pattern in bias_patterns:
if re.search(pattern, code, re.IGNORECASE):
issues['bias_alerts'].append(f"检测到潜在偏见: {pattern}")
return issues
def validate_data_privacy(self, dataset_info: Dict) -> bool:
"""验证数据隐私合规性"""
required_fields = ['data_usage_consent', 'anonymization_applied', 'gdpr_compliant']
for field in required_fields:
if not dataset_info.get(field):
return False
return True
def generate_ethics_report(self, ai_system: Dict) -> str:
"""生成伦理评估报告"""
report = "AI系统伦理评估报告\n"
report += "=" * 40 + "\n\n"
# 公平性评估
report += "1. 公平性评估:\n"
if ai_system.get('fairness_metrics'):
report += f" ✓ 已实施公平性指标: {ai_system['fairness_metrics']}\n"
else:
report += " ⚠ 缺少公平性评估指标\n"
# 透明度评估
report += "\n2. 透明度评估:\n"
if ai_system.get('explainable_ai'):
report += " ✓ 包含可解释AI组件\n"
else:
report += " ⚠ 模型决策透明度不足\n"
# 隐私保护
report += "\n3. 隐私保护评估:\n"
if self.validate_data_privacy(ai_system.get('data_policy', {})):
report += " ✓ 数据隐私保护措施完善\n"
else:
report += " ⚠ 数据隐私保护需要加强\n"
return report
# 安全AI代码生成示例
def safe_ai_code_generation(prompt: str, safety_checker: AI SafetyChecker) -> str:
"""安全的AI代码生成"""
# 检查提示词安全性
prompt_issues = safety_checker.check_code_safety(prompt)
if prompt_issues['security_risks'] or prompt_issues['ethical_concerns']:
return f"⚠ 提示词包含安全问题,请修改后重试: {prompt_issues}"
# 模拟AI代码生成(实际中会调用AI模型)
generated_code = f"""
# AI生成的代码 - 已通过安全检查
def safe_implementation():
\"\"\"
安全实现的AI功能
原始需求: {prompt}
\"\"\"
# 这里放置生成的代码
pass
# 数据隐私保护
def protect_user_privacy(data):
\"\"\"保护用户隐私\"\"\"
# 实现数据脱敏逻辑
anonymized_data = anonymize_sensitive_info(data)
return anonymized_data
# 公平性检查
def check_fairness(predictions, protected_attributes):
\"\"\"检查预测结果的公平性\"\"\"
# 实现公平性评估
fairness_metrics = calculate_fairness_metrics(predictions, protected_attributes)
return fairness_metrics
"""
# 检查生成代码的安全性
code_issues = safety_checker.check_code_safety(generated_code)
if code_issues['security_risks']:
return "生成代码包含安全风险,已阻止执行"
return generated_code
# 使用示例
safety_checker = AI SafetyChecker()
# 测试安全代码生成
safe_prompt = "创建一个用户推荐系统,要求公平对待所有用户群体"
safe_code = safe_ai_code_generation(safe_prompt, safety_checker)
print("安全生成的代码:")
print(safe_code)
# 测试有风险的提示词
risky_prompt = "创建一个系统,根据性别和年龄进行歧视性推荐"
risky_result = safe_ai_code_generation(risky_prompt, safety_checker)
print("\n风险提示词处理结果:")
print(risky_result)
五、未来发展趋势与挑战
5.1 AI工具技术演进方向
1. 代码生成工具的智能化提升
-
上下文理解能力增强
-
多模态编程支持
-
实时协作编程功能
2. 数据标注的自动化革命
-
自监督学习减少标注依赖
-
主动学习优化标注效率
-
合成数据生成技术
3. 模型训练平台的云原生演进
-
无服务器架构普及
-
边缘计算集成
-
绿色AI和能效优化
5.2 面临的挑战与解决方案
python
# AI工具挑战分析框架
class AI Tools ChallengesAnalyzer:
"""AI工具挑战分析器"""
def analyze_technical_challenges(self) -> Dict[str, List[str]]:
"""分析技术挑战"""
return {
'数据质量': [
'标注数据一致性',
'数据偏见消除',
'数据隐私保护'
],
'模型可靠性': [
'对抗攻击防护',
'模型可解释性',
'不确定性量化'
],
'系统性能': [
'训练效率优化',
'推理延迟降低',
'资源消耗控制'
]
}
def analyze_ethical_challenges(self) -> Dict[str, List[str]]:
"""分析伦理挑战"""
return {
'公平性': [
'算法偏见检测与消除',
'代表性不足群体保护',
'机会均等确保'
],
'透明度': [
'黑盒模型解释',
'决策过程可追溯',
'责任归属明确'
],
'社会责任': [
'技术滥用防范',
'就业影响评估',
'环境可持续性'
]
}
def generate_roadmap(self) -> str:
"""生成技术发展路线图"""
roadmap = """
AI工具技术发展路线图 (2024-2028)
2024年重点:
✓ 多模态代码生成完善
✓ 自动化数据标注规模化
✓ 绿色AI技术初步应用
2025年目标:
◼ 代码生成准确性达到90%+
◼ 零样本数据标注技术实用化
◼ 边缘AI训练平台成熟
2026年展望:
◼ AI编程助手成为标准配置
◼ 联邦学习广泛部署
◼ AI伦理框架标准化
2028年愿景:
◼ 通用人工智能工具平台
◼ 全自动MLOps流水线
◼ 负责任的AI生态系统
"""
return roadmap
# 挑战分析示例
analyzer = AI Tools ChallengesAnalyzer()
print("技术挑战分析:")
tech_challenges = analyzer.analyze_technical_challenges()
for category, challenges in tech_challenges.items():
print(f"- {category}: {', '.join(challenges)}")
print("\n伦理挑战分析:")
ethical_challenges = analyzer.analyze_ethical_challenges()
for category, challenges in ethical_challenges.items():
print(f"- {category}: {', '.join(challenges)}")
print("\n技术发展路线图:")
roadmap = analyzer.generate_roadmap()
print(roadmap)
结论
AI工具生态正在经历前所未有的快速发展,智能编码工具如GitHub Copilot正在改变开发者的工作方式,数据标注工具为AI模型提供高质量的训练数据,而模型训练平台则使得大规模AI应用成为可能。这些工具相互配合,形成了完整的AI开发和应用生态系统。
通过本文的深度分析,我们可以看到:
-
智能编码工具不仅提高了开发效率,更通过代码建议和自动完成功能,降低了编程门槛,使得更多人可以参与到软件开发中。
-
数据标注工具的智能化和自动化大幅提升了数据准备效率,通过AI辅助标注、质量控制和主动学习等技术,确保了训练数据的质量和多样性。
-
模型训练平台的云原生和分布式特性,使得训练大规模AI模型变得更加 accessible,同时通过AutoML和MLOps技术,实现了AI开发的标准化和自动化。
未来,随着技术的不断进步,AI工具将变得更加智能、易用和可靠。然而,我们也必须正视其中的挑战,特别是在安全性、公平性、透明度和伦理责任方面。只有在技术创新和伦理考量之间找到平衡,才能确保AI工具的健康发展,真正为人类社会带来积极的影响。
AI工具的演进之路才刚刚开始,我们有理由期待一个更加智能、高效和负责任的AI工具生态系统的到来。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 13
13 0
0- 0



 已为社区贡献88条内容
已为社区贡献88条内容

所有评论(0)