
AI开发全链路核心工具详解:从数据标注到标注到智能编程
AI工具生态全景与开发实践 本文系统梳理了AI工具生态的发展现状和应用实践。1)AI工具分类:包括基础架构层工具(TensorFlow、PyTorch)、开发效率工具(智能编程助手)和专业领域工具(计算机视觉标注平台)。2)GitHub Copilot深度解析:基于OpenAI Codex模型,提供上下文感知的代码补全,支持多语言开发。3)数据标注技术:重点探讨图像标注(LabelImg)和文本标
1 人工智能工具生态全景
1.1 AI工具的分类与演进
人工智能技术正以前所未有的速度发展,而支撑这一发展的正是日益完善的AI工具生态系统。按照功能和应用场景,现代AI工具主要可分为三大类别:
基础架构层工具包括深度学习框架(TensorFlow、PyTorch)、数据处理库(Pandas、NumPy)和分布式分布式计算平台。这些工具构成了AI开发的底层基础设施,为上层应用提供计算能力和算法支持。
开发效率工具涵盖智能编程助手、自动化测试工具和模型调试平台。这类工具专注于提升开发者的工作效率,通过AI技术辅助完成重复性编码任务,让开发者更专注于创造性工作。
专业领域工具针对特定应用场景设计,如计算机视觉中的标注工具、自然语言处理中的语料处理平台和语音和语音识别中的数据清洗软件。这些工具通常具有高度的专业性,能够解决特定领域的独特挑战。
过去五年间,AI工具经历了从"专家专用"向"大众化普及"的显著转变。早期的AI开发需要深厚的数学基础和编程能力,而现在随着工具链的完善,更多领域的专业人士能够利用这些工具解决本行业的问题。
Python
# AI工具演进时间线可视化 import matplotlib.pyplot as plt import numpy as np years = [2015, 2016, 2017, 2018, 2019, 2020, 2021, 2022, 2023, 2024] tool_maturity = { 'Deep Learning Frameworks': [3, 4, 5, 6, 7, 8, 8, 9, 9, 9], 'AutoML Platforms': [1, 2, 3, 4, 5, 6, 7, 7, 8, 8], 'Data Annotation Tools': [2, 3, 4, 5, 5, 6, 7, 8, 8, 9], 'AI Coding Assistants': [1, 1, 2, 3, 4, 5, 6, 7, 8, 9] } plt.figure(figsize=(12, 8)) for tool, scores in tool_maturity.items(): plt.plot(years, scores, marker='o', linewidth=2.5, markersize=8, label=tool) plt.xlabel('Year', fontsize=12) plt.ylabel('Tool Maturity Maturity (1-10)', fontsize=12) plt.title('Evolution of AI Tool Ecosystem (2015-2024)', fontsize=14) plt.grid(True, alpha=0.3) plt.legend() plt.tight_layout() plt.show()
1.2 AI项目开发工作流
完整的AI项目开发遵循系统化的流程,每个阶段都有相应的工具支持。典型的工作流包括以下几个关键阶段:
数据收集与预处理是项目起点,起点,涉及原始数据的获取、清洗和初步整理。这一阶段的输出是可供标注的干净数据集。
数据标注与验证将原始数据转化为机器学习可用的训练样本。高质量的标注数据对模型性能至关重要,此阶段通常需要专业的标注工具和严格的质量控制。
模型选择与训练基于任务需求选择合适的模型架构,使用标注数据进行训练。此阶段需平衡模型复杂度、训练成本和性能要求。
模型评估与优化通过多种指标评估模型表现,识别问题并进行针对性优化,包括超参数调优、架构调整等。
部署与监控将训练好的模型投入实际应用,并持续监控其表现,确保在实际环境中保持预期性能。
以下Mermaid流程图展示了完整的AI项目开发工作流:
ermaid graph TD A[业务需求分析] --> B[数据收集] B --> C[数据清洗与预处理] C --> D[数据标注] D --> E[特征工程] E --> F[模型选择] F --> G[模型训练] G --> H{模型评估} H -->|不达标| G H -->|达标| I[模型优化] I --> J[模型部署] J --> K[性能监控] K --> L[反馈收集] L --> A M[数据存储与管理] -.-> B M -.-> C M -.-> D N[实验跟踪] -.-> G N -.-> H N -.-> I O[自动化流水线] -.-> J O -.-> K
2 智能 智能编程助手:GitHub Copilot深度解析
2.1 GitHub1 GitHub Copilot的技术原理与架构
GitHub Copilot作为当前最先进的AI编程助手,其核心技术建立在OpenAI的Codex模型之上。Codex是基于GPT-3专门针对代码生成进行微调的大型语言模型,在数十亿行公开代码上进行了训练。
核心技术栈:
- Transformer架构:采用基于注意力机制的神经网络结构,能够理解长距离的代码依赖关系
- 代码特定训练:在Python、JavaScript、Go、Java等主流编程语言的海量代码库上进行预训练
- 上下文感知:能够分析当前文件的代码上下文,提供与现有代码风格一致的补全建议
工作流程:
- 上下文提取:Copilot分析当前编辑器中光标周围的代码,包括导入语句、函数定义、变量声明和注释
- 语义理解:模型理解代码的语义结构和程序员的意图
- 候选生成:生成多个可能的代码补全方案,按概率排序
- 过滤与排名:根据代码质量、相关性和实用性对候选项进行过滤和重新排名
- 结果呈现:将最佳建议呈现给用户,用户可以接受、忽略或查看替代方案
Python
# 模拟Copilot代码生成过程的简化示例 class MockCopilot: def __init__(self): self.context_window = 1024 # 上下文窗口大小 self.max_generated_tokens = 100 # 最大 最大生成token数 def extract_context(self, file_content, cursor_position): """提取光标周围的代码上下文""" start = max(0, cursor, cursor_position - self.context_window // 2) end = min(len(file_content), cursor_position + self.context_window // 2) return file_content[start:end] def understand_intent(self, context): """分析程序员意图(简化版)""" intent_keywords = { 'test': ['test', 'assert', 'check'], 'loop': ['for', 'while', 'iterate'], 'condition': ['if', 'else', 'switch'], 'function': ['def ', 'function', 'method'] } detected_intents = [] for intent, keywords in intent_keywords.items(): if any(keyword in context.lower() for keyword in keywords): detected detected_intents.append(intent) return detected_intents def generate_candidates(self, context, intents): """生成代码补全候选(模拟)""" base_suggestions = { 'test': [ "def test_function():\n assert True == True", "def test_example():\n expected = 5\n actual = calculate()\n assert expected == actual" ], 'loop': [ "for i in range(10):\n print(i)", "while condition:\n do_something()" ], 'function': [ "def new_function(param1, param2 param2):\n result = param1 + param2\n return result" ] } candidates = [] for intent in intents: if intent in base_suggestions: candidates.extend(base_suggestions[intent]) return candidates[:3] # 返回前3个候选 def rank_candidates(self, candidates, context): """根据相关性对候选进行排名(模拟)""" # 简化的排名逻辑:优先选择与上下文有共同关键词的建议 context_words = set(context.lower().split()) ranked = [] for candidate in candidates: score = 0 candidate_words = set(candidate.lower().split()) common_words = context_words.intersection(candidate_words) score = len(common_words) ranked.append((candidate, score)) ranked.sort(key=lambda x: x[1], reverse=True) return [item[0] for item in ranked] # 使用示例 mock_copilot = MockCopilot() context_code = """ import pandas as pd def process_data(data_file): df = pd.read_csv(data_file) # 清理数据 cleaned_df = df.dropna() # 接下来应该写测试代码 """ cursor_pos = len(context_code) extracted_context = mock_copilot.extract_context(context_code, cursor_pos) intents = mock_copilot.understand_intent(extracted_context) candidates = mock_copilot.generate_candidates(extracted_context, intents) ranked_suggestions = mock_copilot.rank_candidates(candidates, extracted_context) print("检测到的编程意图:", intents) print("生成的代码建议:") for i, suggestion in enumerate(ranked_suggestions, 1): ): print(f"{i}. {suggestion}")
2.2 GitHub2 GitHub Copilot的高级用法与技巧
要充分发挥GitHub Copilot的潜力,需要掌握一系列高级使用技巧。这些技巧可以帮助开发者获得更准确、更有用的代码建议。
编写有效的提示注释: Copilot严重依赖代码注释来理解开发者的意图。清晰、具体的注释能大幅提升建议质量。
Python
# 不好的注释示例 # 做计算 def calculate(a, b): # 好的注释示例 # 计算两个数字的最大公约数 using Euclidean algorithm # 参数: a - 第一个正整数, b - 第二个正整数 # 返回: a和b的最大公约数 def gcd(a, b): # Copilot会根据详细注释生成准确的实现 while b: a, b = b, a % b return a # 另一个好注释的例子 # 从URL下载JSON数据并解析为Python字典 # 参数: url - 要下载数据的URL地址 # 返回: 解析后的字典,如果失败则返回None def fetch_json_data(url): import requests try: response = requests.get(url) response.raise_for_status() return response.json() except requests.exceptions.RequestException as e: print(f"下载数据时出错:出错: {e}") return None
利用上下文增强功能: Copilot会考虑整个文件的上下文,因此合理的代码组织能帮助它更好地理解你的需求。
JavaScript
// React组件示例 - Copilot能理解组件结构并提供匹配的建议 import React, { useState, useEffect } from 'react'; // 用户配置界面组件 const UserProfile = () => { const [userData, setUserData] = useState(null); const [loading, setLoading] = useState(true); // Copilot会根据React惯例生成useEffect实现 useEffect(() => { // 从API获取用户数据 const fetchUserData = async () => { try { setLoading(true); const response = await fetch('/api/user/profile'); if (response.ok) { const data = await response.json(); setUserData(data); } else { throw new Error('Failed to fetch user data'); } } catch (error) { console.error('Error fetching user data:', error); } finally { setLoading(false); } }; fetchUserData(); }, []); []); // 保存用户配置的处理函数 const handleSaveProfile = async (updatedData) => { // Copilot会生成完整的API调用实现 try { const response = await fetch('/api/user/profile', { method: 'PUT', headers: { 'Content-Type': 'application/json', }, body: JSON.stringify(updatedData), }); if (response.ok) { const result = await response.json(); setUserData(result); alert('Profile updated successfully!'); } else { throw new Error('Failed to update profile'); } } catch (error) { console.error('Error updating profile:', error); alert('Error updating profile. Please try again.'); } }; if (loading) { return <div>Loading user profile...</div>; } return ( <div className="user-profile"> <h2>User Profile</h2> {/* Copilot会根据状态结构生成表单JSX */} <form onSubmit={(e) => { e.preventDefault(); const formData = new FormData(e.target); const updatedData = Object.fromEntries(formData); handleSaveProfile(updatedData); }}> <div> <label htmlFor="username">Username:</label> <input type="text" id="username" name="username" defaultValue defaultValue={userData?.username || ''} /> </div> <div> <label htmlFor="email">Email:</label> <input type="email" id="email" name="email" defaultValue defaultValue={userData?.email || ''} /> </div> <button type="submit">Save Changes</button> </form> </div> ); }; export default UserProfile;
2.3 Copilot实战:完整项目示例
让我们通过一个完整的项目实例来展示Copilot在实际开发中的应用。我们将创建一个简单的任务管理Web应用,包含后端API和前端界面。
后端Flask API开发:
Python
# app.py - 任务管理API from flask import Flask, request, jsonify from flask_sqlalchemy import SQLAlchemy from datetime import datetime import os app = Flask(__name__) app.config['SQLALCHEMY_DATABASEATABASE_URI'] = os.environ.get('DATABASE_URL', 'sqlite:///tasks.db') app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False db = SQLAlchemy(app) # 数据库模型 - Copilot会根据字段说明生成适当的模型定义 class Task(db.Model): __tablename__ = 'tasks' id = db.Column(db.Integer, primary_key=True) title = db.Column(db.String(100), nullable=False) description = db.Column(db.Text, nullable=True) completed = db.Column(db.Boolean, default=False) created_at = db.Column(db.DateTime, default=datetime.utcnow) due_date = db.Column(db.DateTime, nullable=True) def to_dict(self): """将任务对象转换为字典格式""" return { 'id': self.id self.id, 'title': self.title, 'description': self.description, 'completed': self.completed, 'created_at': self.created_at.isoformat(), 'due_date': self.due_date.isoformat() if self.due_date else None } # 创建数据库表 @app.before_first_request def create_tables(): db.create_all() # API路由定义 # 获取所有任务 @app.route('/api/tasks', methods=['GET']) def get_tasks(): tasks = Task.query.all() return jsonify([task.to_dict() for task in tasks]) # 获取单个任务详情 @app.route('/api/tasks/<int:task_id>', methods=['GET']) def get_task(task_id): task = Task.query.get_or_404(task_id) return jsonify(task.to_dict()) # 创建新任务 @app.route('/api/tasks', methods=['POST']) def create_task(): data = request.get_json() # 验证必要字段 if not data or 'title' not in data: return jsonify({'error': 'Title isTitle is required'}), 400 new_task = Task( title=data['title'], description=data.get('description', ''), completed=data.get('completed', False) ) # 处理截止日期 if 'due_date' in data and data['due_date']: new_task.due_date = datetime.fromisoformat(data['due_date']) db.session.add(new_task) db.session.commit() return jsonify(new_task.to_dict()), 201 # 更新任务 @app.route('/api/tasks/<int:task_id>', methods=['PUT']) def update_task(task_id): task = Task.query.get_or_404(task404(task_id) data = request.get_json() if 'title' in data: task.title = data['title'] if 'description' in data: data: task.description = data['description'] if 'completed' in data: task.completed = data['completed'] if 'due_date' in data: data: task.due_date = datetime.fromisoformat(data['due_date']) if data['due_date'] else None db.session.commit() return jsonify(task.to_dict()) # 删除任务 @app.route('/api/tasks/<int:task_id>', methods=['DELETE']) def delete_task(task_id): task = Task.query.get_or_404(task_id(task_id) db.session.delete(task) db.session.commit() return '', 204 # 批量操作 @app.route('/api/tasks/batch', methods=['POST']) def batch_operations(): data = request.get_json() operation = data.get('operation') task_ids = data.get('task_ids', []) if operation == 'delete': Task.query.filter(Task.id.in_(task_ids)).delete(synchronize_session=False) db.session.commit() return '', 204 elif operation == 'complete': tasks = Task.query.filter(Task.id.in_(task_ids)).all() for task in tasks: task.completed = True db.session.commit() return jsonify({'message': f'{len(tasks)} tasks marked as complete'}) else: return jsonify({'error': 'Invalid operation'}), 400 if __name__ == '__main__': app.run(debug=True)
配套测试文件:
Python
# test_app.py - API测试用例 import pytest import json from app import app, db, Task from datetime import datetime @pytest.fixture def client(): app.config['TESTING'] = True app.config['SQLALCHEMY_DATABASEATABASE_URI'] = 'sqlite:///:memory:' with app.test_client() as client: with app.app_context(): db.create_all() yield client def test_create_task(client): """测试创建新任务""" task_data = { 'title': '学习Python', 'description': '完成Copilot教程', 'completed': False } response = client.post('/api/tasks', data=json.dumps(task_data), content_type='application/json') assert response.status_code == 201 data = json.loads(response.data) assert data['title'] == '学习Python' assert data['completed'] is False assert 'id' in data def test_get_tasks(client): """测试获取任务列表""" # 先创建几个测试任务 task1 = Task(title='任务1') task2 = Task(title='任务2', completed=True) db.session.add_all([task1, task2]) db.session.commit() response = client.get('/api/tasks') assert response.status_code == 200 data = json.loads(response.data) assert len(data) == 2 assert data[0]['title'] == '任务1' def test_update_task(client): """测试更新任务""" task = Task(title='原始标题') db.session.add(task) db.session.commit() update_data = { 'title': '更新后的标题', 'completed': True } response = client.put(f'/api/tasks/{task.id}', data=json.dumps(update_data), content_type='application/json') assert response.status_code == 200 data = json.loads(response.data) assert data['title'] == '更新后的标题' assert data['completed'] is True def test_delete_task(client): """测试删除任务""" task = Task(title='要删除的任务') db.session.add(task) db.session.commit() response = client.delete(f'/api/tasks/{task.id}') assert response.status_code == 204 # 确认任务已被删除 deleted_task = Task.query.get(task.id) assert deleted_task is None
3 数据标注工具与技术实践
3.1 数据标注的核心挑战与方法论
高质量的数据标注是成功AI项目的基石。数据标注面临多个核心挑战,需要有系统的方法论来应对。
主要挑战:
- 标注一致性:不同标注员对同一数据的标注结果可能存在差异
- 标注标准制定:需要明确定义各类别的边界条件,特别是对于边缘案例
- 质量控制:如何有效检测和纠正标注错误
- 成本与效率平衡:在保证质量的前提下控制标注时间和成本
标注方法论原则:
- 分层抽样检查:对不同标注员、不同批次的数据进行定期抽样检查
- 交叉验证机制:关键数据由多名标注员独立标注并通过共识机制确定最终结果
- 渐进式标准细化:在标注过程中不断细化和完善标注指南
- 主动学习集成:利用模型不确定性指导下一步标注重点,提高标注效率
Python
# 数据标注质量管理框架 import pandas as pd import numpy as np from sklearn.metrics import cohen_kappa_score from typing import List, Dict, Any class DataAnnotationQualityManager: def __init__(self, annotation_guidelines: Dict[str, Any]): self.guidelines = annotation_guidelines self.annotation_history = [] quality_threshold = 0.85 # 质量标准阈值 def add_annotation(self, annotator_id: str, data_id: str, labels: Dict[str, Any]): """记录标注结果""" annotation_record = { 'annotator_id': annotator_id, 'data_id': data_id, 'labels': labels, 'timestamp': pd.Timestamp.now() } self.annotation_history.append(annotation_record) def calculate_agreement(self, data_ids: List[str], reference_annotator: str = None): """计算标注者间一致性""" annotations_df = self = self._prepare_agreement_data(data_ids) if reference_annotator: # 与参考标注者比较 比较 reference_labels = annotations_df[annotations_df['annotator_id'] == reference_annotator] agreement_scores = {} for annotator in annotations_df['annotator_id'].unique(): if annotator == reference_annotator: continue annotator_labels = annotations_df[annotations_df['annotator_id'] == annotator] merged = pd.merge(reference_labels, annotator_labels, on='data_id', suffixes=('_ref', '_ann')) ')) # 计算Kappa系数 kappa = cohen_kappa_score(merged['labels_ref'], merged['labels_ann']) agreement_scores[annotator] = kappa return agreement_scores else: # 计算所有标注者间的平均一致性 annotators = annotations_df['annotator_id'].unique() kappa_scores = [] for i in range(len(annotators)): for j in range(i+1, len(annotators)): ann1 = annotations_df[annotations_df['annotator_id'] == annotators[i]] ann2 = annotations_df[annotations_df['annotator_id'] == annotators[j]] merged = pd.merge(ann1, ann2, on='data_id', suffixes=('_1', '_2')) if len(merged) > 1: kappa = cohen_kappa_score(merged['labels_1'], merged['labels_2']) kappa_scores.append(kappa) return np.mean(kappa_scores) if kappa_scores else 0.0 def _prepare_agreement_data(self, data_ids: List[str]) -> pd.DataFrame: """准备用于一致性分析的数据""" records = [] for record in self.annotation_history: if record['data_id'] in data_ids: records records.append({ 'annotator_id': record['annotator_id'], 'data_id': record['data_id'], 'labels': record['labels']['primary_category'] # 假设我们关注主分类的一致性 }) }) return pd.DataFrame(records) def identify_problematic_annotators(self, threshold: float = 0.7) -> List[str]: """识别标注质量低于阈值的标注员""" all_data_ids = list(set([record['data_id'] for record in self.annotation_history])) agreement_scores = self.calculate_agreement(all_data_ids) problematic = [] if isinstance(agreement_scores, dict): for annotator, score in agreement_scores.items(): if score < threshold: problematic.append(annotator) return problematic def generate_quality_report(self) -> Dict[str, Any]: """生成数据标注质量报告""" all_data_ids = list(set([record['data_id'] for record in self.annotation_history])) total_annotations = len(self.annotation_history) unique_data_points = len(all_data_ids) avg_agreement = self.calculate_agreement(all_data_ids) problematic_annotators = self.identify_problematic_annotators() report = { 'total_annotations': total_annotations, 'unique_data_points': unique_data_points, 'average_agreement': avg_agreement, 'problematic_annotators': problematic_annotators, 'annotation_distribution': self._get_annotation_distribution(), 'timeline_analysis': self._analyze_timeline_trends() } return report def _get_annotation_distribution(self) -> Dict[str, int]: """获取标注分布情况""" distribution = {} for record in self.annotation_history: label = record['labels']['primary_category'] distribution distribution[label] = distribution.get(label, 0) + 1 return distribution def _analyze_timeline_trends(self) -> Dict[str, Any]: """分析标注质量的时间趋势""" # 简化的趋势分析实现 timeline_data = pd.DataFrame(self.annotation_history) timeline_data['date'] = timeline_data['timestamp'].dt.date daily_counts = timeline_data.groupby('date').size() weekly_avg = daily_counts.rolling(7).mean() return { 'daily_volume': daily_counts.to_dict(), 'weekly_trend': weekly_avg.fillna(0).to_dict() } # 使用示例 guidelines = { 'categories': ['cat', 'dog', 'bird', 'other'], 'confidence_levels': ['high ['high', 'medium', 'low'], 'special_cases': { 'blurry_images': '标记为uncertain', 'multiple_objects': '标记主导对象' } } quality_manager = DataAnnotationQualityManager(guidelines) # 模拟添加一些标注记录 sample_annotations = [ ('annotator_1', 'img_001', {'primary_category': 'cat', 'confidence': 'high'}), ('annotator_2', 'img_001', {'primary_category': 'cat', 'confidence': 'medium'}), ('annotator_1', 'img_002', {'primary_category': 'dog', 'confidence': 'high'}), ('annotator_3', 'img_002', {'primary_category': 'cat', 'confidence': 'high'}), ] for annotator_id, data_id, labels in sample_annotations: quality_manager.add_annotation(annotator_id, data_id, labels) # 生成质量报告 report = quality_manager.generate_quality_report() print("数据标注质量报告:") for key, value in report.items(): print(f"{key}: {value}")
3.2 图像标注工具与实践
图像标注是计算机视觉项目的基础环节。以下是使用流行标注工具LabelImg和自定义标注系统的实践示例。
LabelImg XML标注格式处理:
Python
# image_annotation_utils.py - 图像标注数据处理工具 import xml.etree.ElementTree as ET import os import cv2 import json from typing import List, Dict, Tuple from dataclasses import dataclass from pathlib import Path @dataclass class BoundingBox: label: str xmin: float ymin: float xmax: float ymax: float confidence: float = 1.0 @property def width(self): return self.xmax - self.xmin @property def height(self): return self.ymax - self.ymin @property def area(self): return self.width * self.height def intersection_area(self, other: 'BoundingBox') -> float: """计算两个边界框的交集面积""" dx = min(self.xmax, other.xmax) - max(self.xmin, other.xmin) dy = min(self.ymax, other, other.ymax) - max(self.ymin, other.ymin) return dx * dy if dx > 0 and dy > 0 else 0.0 def iou(self, other: 'BoundingBox') -> float: """计算IoU(交并比)""" intersection = self.intersection_area(other) union = self.area + other.area - intersection return intersection / union if union > 0 else 0.0 class LabelImgAnnotationProcessor: """处理LabelImg生成的XML标注文件""" def __init__(self, classes: List[str]): self.classes = classes self.class_to_idx = {cls_namecls_name: idx for idx, cls_name in enumerate(classes)} def parse_xml_annotation(self, xml_path: str) -> Dict[str, any]: """解析单个XML标注文件""" tree = ET.parse(xml_path) root = tree.getroot() annotation_data = { 'filename': root.find('filename').text, 'size': { 'width': int(root.find('size/width').text), 'height': int(root.find('size/height').text), 'depth': int(root.find('size/depth').text) }, 'objects': [] } for obj in root.findall('object'): label = obj.find('name').text bndbox = obj.find('bndbox') bounding_box = BoundingBox( label=label, xmin=float(bndbox.find('xmin').text), ymin=float(bndbox.find('ymin').text').text), xmax=float(bndbox.find('xmax').text), ymax=float(bfloat(bndbox.find('ymax').text) ) annotation_data['objects'].append(bounding_box) return annotation_data def convert_to_coco_format(self, xml_dir: str, output_path: str): """将LabelImg XML标注转换为COCO格式""" coco_data = { 'images': [], 'annotations': [], 'categories': [{'id': i+1, 'name': cls} for i, cls in enumerate(self.classes)] } annotation_id = 1 image_id = 1 for xml_file in Path(xml_dir).glob('*.xml'): annotation = self.parse_xml_annotation(str(xml_file)) # 添加图像信息 image_info = { 'id': image_id, 'file_name': annotation['filename'], 'width': annotation['size']['width'], 'height': annotation['size']['height'] } coco_data['images'].append(image_info) # 添加标注信息 for obj in annotation['objects']: annotation_info = { 'id': annotation_id, 'image_id': image_id, 'category_id': self.class_to_idx[obj.label] + 1, 'bbox': [obj.xmin, obj.ymin, obj.width, obj.height], 'area': obj.area, 'iscrowd': 0 } coco_data['annotations'].append(annotation_info) annotation_id += 1 image_id += 1 # 保存为JSON文件 with open(output_path, 'w') as f: json.dump(coco_data, f, indent=2) print(f"已转换 {image_id-1} 张图像的标注信息") def visualize_annotations(self, image_path: str, xml_path: str, output_path: str = None): """可视化图像及其标注""" annotation = self.parse_xml_annotation(xml_path) image = cv2.imread(image_path) if image is None: raise ValueError(f"无法读取图像: {image_path}") colors = { 'person': (255, 0, 0), # 红色 'car': (0, 255, 0), ), # 绿色 'bicycle': (0, 0, 255), # 蓝色 'default': (128, 128, 128) # 灰色 } for obj in annotation['objects']: color = colors.get(obj.label, colors['default']) # 绘制边界框 cv2.rectangle(image, (int(obj.xmin), int(obj.ymin)), (int(obj.xmax), int(obj.ymax)), color, 2) # 添加标签文本 label_text = f"{obj.label}" text_size = cv2.getTextSize(label_text, cv2.FONT_HERSHEY_SIMPLEX, 0.5, 2)[0] cv2.rectangle(image, (int(obj.xmin), int(obj.ymin) - text_size[1] - 5), (int(obj.xmin) + text_size[0] + 5, int(obj int(obj.ymin))), color, -1) cv2.putText(image, label_text, (int(obj.xmin), int(obj.ymin) - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255), 2) if output_path: cv2.imwrite(output_path, image) print(f"可视化结果已保存至: {output_path}") else: cv2.imshow('Annotations', image) cv2.waitKey(0) cv2.destroyAllWindows() # 自定义web-based标注工具后端示例 from flask import Flask, render_template, request, send_from_directory import shutil app = Flask(__name__) class WebAnnotationTool: def __init__(self, image_dir: str, output_dir: str): self.image_dir = Path(image_dir) self.output_dir = Path(output_dir) self.output_dir.mkdir(exist_ok=True) self.current_index = 0 self.image_files = list(self.image_dir.glob('*.jpg')) + list(self.image_dir.glob('*.png')) self.annotations = {} def save_annotation(self, image_name: str, boxes: List[BoundingBox]): """保存标注结果""" annotation_file = self.output_dir / f"{image_name}.json" annotation_data = { 'image_name': image_name, 'boxes': [ { 'label': box.label, 'xmin': box.xmin, 'ymin': box.ymin, 'xmax': box.xmax, 'ymax': box.ymax } for box in boxes ] } with open(annotation_file, 'w') as f: json.dump(annotation_data, f, indent=2) def load_next_image(self): """加载下一张待标注图像""" if self.current_index >= len(self.image_files): return None next_image = self.image_files[self.current_index] self.current_index += 1 return next_image.name # 使用示例 classes = ['person', 'car', 'bicycle', 'motorcycle'] processor = LabelImgAnnotationProcessor(classes) # 转换单个XML文件 xml_example = """ <annotation> <folder>images</folder> <filename>example.jpg</filename> <path>/home/user/images/example.jpg</path> <source> <database>Unknown</database> </source> <size> <width>800</width> <height>600</height> <depth>3</depth> </size> <segmented>0</segmented> <object> <name>person</name> <pose>Unspecified</pose> <truncated>0</truncated> <difficult>0</difficult> <bndbox> <xmin>100</xmin> <ymin>150</ymin> <xmax>300</xmax> <ymax>500</ymax> </bndbox> </object> <object> <name>car</name> <pose>Unspecified</pose> <truncated>0</truncated> <difficult>0</difficult> <bndbox> <xmin>400</xmin> <ymin>200</ymin> <xmax>700</xmax> <ymax>400</ymax> </bndbox> </object> </annotation> """ # 写入示例XML文件 with open('example.xml', 'w') as f: f.write(xml_example) # 处理示例 annotation_data = processor.parse_xml_annotation('example.xml') print("解析的标注数据:") print(json.dumps(annotation_data, default=str, indent=2))
3.3 文本数据标注技术
文本数据标注在自然语言处理项目中至关重要。以下展示了文本分类、命名实体识别等任务的标注实践。
Python
# text_annotation_system.py - 文本数据标注系统 import spacy import re from typing import List, Tuple, Dict, Any from collections import defaultdict import json class TextAnnotatornotator: """文本数据标注基类""" def __init__(self): self.nlp = spacy.load("en_core_web_sm") def preprocess_text(self, text: str) -> str: """文本预处理""" # 移除多余空白字符 text = re.sub(r'\s+', ' ', text.strip()) return text def validate_annotation(self, text: str, annotation: Dict[str, Any]) -> bool: """验证标注结果的合理性""" if not text or not annotation: return False return True class TextClassificationAnnotator(TextAnnotator): """文本分类标注器""" def __init__(self, categories: List[str]): super().__init__() self.categories = categories def annotate_single_text(self, text: str, category: str, confidence: float = 1.0) -> Dict[str, Any]: """单文本分类标注""" processed_text = self.preprocess_text(text) annotation = { 'text': processed_text, 'category': category, 'confidence': confidence, 'metadata': { 'length': len(processed_text), 'word_count': len(processed_text.split()) } } if not self.validate_annotation(processed_text, annotation): raise ValueError("无效的标注") return annotation def batch_annotate(self, texts: List[str], categories: List[str]) -> List[Dict[str, Any]]: """批量文本分类标注""" annotations = [] for text, category in zip(texts, categories): annotation = self.annotate_single_text(text, category) annotations.append(annotation) return annotations def analyze_class_distribution(self, annotations: List[Dict[str, Any]]) -> Dict[str, int]: """分析类别分布""" distribution = defaultdict(int) for annotation in annotations: category = annotation['category'] distribution[category] += 1 return dict(distribution) class NERAnnotator(TextAnnotator): """命名实体识别标注器""" def __init__(self, entity_types: List[str]): super().__init__() self.entity_types = entity_types def annotate_entities(self, text: str, entities: List[Tuple[int, int, str]]) -> Dict[str, Any]: """标注命名实体""" processed_text = self.preprocess_text(text) annotation = { 'text': processed_text, 'entities': [], 'metadata': { 'total_entities': len(entities) } } for start, end, entity_type in entities: if entity_type not in self.entity_types: raise ValueError(f"不支持实体类型: {entity_type}") entity_text = processed_text[start:end] entity_info = { 'text': entity_text, 'start_pos': start, 'end_pos': end, 'type': entity_type } annotation['entities'].append(entity_info) return annotation def auto_detect_entities(self, text: str) -> List[Tuple[int, int, str]]: """自动检测实体(基于规则+模型)""" entities = [] # 基于spacy的模型预测 doc = self.nlp(text) for ent in doc.ents: if ent.label_ in self.entity_types: entities.append((ent.start_char, ent.end_char, ent.label_.lower())) return entities # 高级文本标注项目管理 class TextAnnotationProject: """文本标注项目管理类""" def __init__(self, project_name: str, annotators: List[TextAnnotator]): self.project_name = project_name self.annotators = annotators self.dataset = [] = [] self.annotation_guidelines = {} def add_annotation_guidelines(self, guidelines: Dict[str, Any]): """添加标注指南""" self.annotation_guidelines.update(guidelines) def import_text_data(self, file_path: str): """导入文本数据""" with open(file_path, 'r', encoding='utf-8') as f: texts = [line.strip() for line in f if line.strip()] self.dataset.extend([ {'text': text, 'status': 'pending', 'annotations': []} for text in texts ]) def assign_annotation_task(self, annotator_id: str, text_indices: List[int]): """分配标注任务""" assignments = [] for idx in text_indices: if idx < len(self.dataset): assignment = { 'annotator_id': annotator_id, 'text_index': idx, 'assigned_at': pd.Timestamp.now() } assignments.append(assignment) return assignments def export_annotations(self, format_type: str = 'json') -> str: """导出标注结果""" completed_annotations = [ item for item in self.dataset if item['status'] == 'completed' ] if format_type == 'json': return json.dumps(completed_annotations, ensure_ascii=False, indent=2) elif format_type == 'csv': # 简化的CSV导出逻辑 csv_lines = ['text,category,entities'] for annotation in completed_annotations: latest_anno = annotation['annotations'][-1] if annotation['annotations'] else {} csv_line = f"\"{annotation['text']}\",\"{latest_anno.get('category', '')}\",\"{json.dumps(latest_anno.get('entities', []))}" csv_lines.append(csv_line) return '\n'.join(csv_lines) else: raise ValueError(f"不支持的导出格式: {format_type}") # 使用示例 # 文本分类标注 categories = ['positive', 'negative', 'neutral'] classifier = TextClassificationAnnotator(categories) texts = [ "I love this product! It's amazing.", "This is the worst thing I've ever bought.", "The product arrived on time and works fine." predicted_categories = ['positive', 'negative', 'neutral'] classification_annotations = classifier.batch_annotate(texts, predicted_categories) print("文本分类标注结果:") for annotation in classification_annotations: print(f"文本: {annotation['text'][:50]}... | 类别: {annotation['category']}") # 命名实体识别标注 entity_types = ['person', 'organization', 'location', 'date'] ner_annotator = NERAnnotator(entity_types) sample_text = "Apple Inc. was founded by Steve Jobs in Cupertino on April 1, 1976." auto_entities = ner_annotator.auto_detect_entities(sample_text) ner_annotation = ner_annotator.annotate_entities(sample_text, auto_entities) print("\nNER标注结果:") print(json.dumps(ner_annotation, indent=2)) # 创建标注项目 project = TextAnnotationProject( "产品评论情感分析", [classifier, ner_annotator] ) project.add_annotation_guidelines({ 'positive': '表达满意、喜欢、推荐的情感', 'negative': '表达不满、批评、失望的情感', 'neutral': '无明显情感倾向的事实陈述' }) print("\n标注项目信息:") print(f"项目名称: {project.project_name}") print(f"标注器数量: {len(project.annotators)}")
4 模型训练平台与应用实践
4.1 云端模型训练平台比较
现代模型训练平台大大降低了AI开发的门槛。以下是主要云端平台的对比分析和实践指南。
Python
# model_training_platforms.py - 主流训练平台接口封装 from abc import ABC, abstractmethod import time from typing import Dict, List, Optional, Any import subprocess import sys class TrainingPlatform(ABC): """训练平台抽象基类""" @abstractmethod def setup_environment(self, requirements: List[str]): """设置训练环境""" pass @abstractmethod def upload_dataset(self, dataset_path: str): """上传数据集""" pass @abstractmethod def start_training(self, config: Dict[str, Any]): """开始训练""" pass @abstractmethod def monitor_progress(self, job_id: str) -> Dict[str, Any]: pass @abstractmethod def download_model(self, job_id: str, output_path: str): pass class GoogleColabWrapper(TrainingPlatform): """Google Colab平台封装""" def __init__(self): self.connected = False self.jobs = [] def setup_environment(self, requirements: List[str]): """设置Colab环境""" print("正在设置Google Colab环境...") # 安装依赖 for package in requirements: print(f"安装 {package}...") # 实际环境中会使用!pip install time.sleep(0.5) print("环境设置完成") self.connected = True def upload_dataset(self, dataset_path: str): """上传数据集到Google Drive""" print(f"正在上传数据集: {dataset_path}") # 模拟上传过程 time.sleep(1) print("数据集上传完成") def start_training(self, config: Dict[str, Any]): """启动训练任务""" print("在Google Colab中启动训练...") job_id = f"colab_job_{len(self.jobs)+1}" self.jobs.append(job_id) training_script = f""" # Google Colab训练脚本 import tensorflow as tf from tensorflow import keras import numpy as np # 数据加载和预处理 def load_data(): # 这里应该是实际的数据加载逻辑 return train_data, val_data def create_model(input_shape, num_classes): model = keras.Sequential([ keras.layers.Dense(128, activation='relu', input_shape=input_shape), keras.layers.Dropout(0.3), keras.layers.Dense(64, activation='relu'), keras.layers.Dense(num_classes, activation='softmax') ]) return model # 训练配置 epochs = {config.get('epochs', 50)} batch_size = {config.get('batch_size', 32)} # 开始训练 train_data, val_data = load_data() model = create_model({config.get('input_shape', (784,))}, {config.get('num_classes', 10)}) model.compile( optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'] ) history = model.fit( train_data, validation_data=val_data, epochs=epochs, batch_size=batch_size, verbose=1 ) # 保存模型 model.save('trained_model.h5') print("训练完成!") """ print(f"训练作业ID: {job_id}") return job_id def monitor_progress(self, job_id: str): """监控训练进度""" print(f"监控作业 {job_id} 的进度...") progress = { 'job_id': job_id, 'status': 'running', 'current_epoch': 25, 'training_acc': 0.92, 'validation_acc': 0.89 } return progress class AWSSageMakerWrapper(TrainingPlatform): """AWS SageMaker平台封装""" def __init__(self, role_arn: str, bucket_name: str): self.role_arn = role_arn self.bucket_name = bucket_name self.jobs = [] def setup_environment(self, requirements: List[str]): """设置SageMaker环境""" print("正在配置AWS SageMaker环境...") print(f"IAM角色: {self.role_arn}") print(f"S3存储桶: {self.bucket_name}") # 模拟环境配置 time.sleep(1.5) print("SageMaker环境就绪") def upload_dataset(self, dataset_path: str): """上传数据集到S3""" print(f"正在上传 {dataset_path} 到S3...") time.sleep(1) print("数据集上传完成") def start_training(self, config: Dict[str, Any]): """启动SageMaker训练作业""" print("启动SageMaker训练作业...") job_id = f"sagemaker_job_{len(self.jobs)+1}" self.jobs.append(job_id) print(f"训练作业ID: {job_id}") return job_id # 平台比较和选择工具 class PlatformComparator: """训练平台比较器""" def __init__(self): self.platforms = { 'colab': { 'name': 'Google Colab', 'cost': '免费(GPU限制)', 'gpu_support': '有限', 'scalability': '中等', 'best_for': '原型开发、教育和实验' }, 'sagemaker': { 'name': 'AWS SageMaker', 'cost': '按使用付费', 'gpu_support': '优秀', 'scalability': '高', 'best_for': '生产级模型训练和企业应用' }, 'azure_ml': { 'name': 'Azure Machine Learning', 'cost': '按使用付费', 'gpu_support': '优秀', 'scalability': '高', 'best_for': '企业集成和微软生态' } } def compare_platforms(self, criteria: Dict[str, float]) -> Dict[str, float]: """根据指定标准比较平台""" scores = {} for platform_id, platform_info in self.platforms.items(): score = 0 for criterion, weight in criteria.items(): if criterion in platform_info: # 简化的评分逻辑 if platform_info[criterion] in ['优秀', '高']: score += weight * 10 elif platform_info[criterion] in ['中等']: : score += weight * 7 elif criterion in ['免费(GPU限制)', '有限']: : score += weight * 5 scores[platform_id] = round(score, 2) return dict(sorted(scores.items(), key=lambda x: x[1], reverse=True)) def recommend_platform(self, use_case: str, budget: str, team_size: str) -> str: """根据使用场景推荐平台""" recommendations = { '个人研究': 'colab', '初创公司': 'colab', '中小企业': 'sagemaker', '大型企业': 'sagemaker', '学术项目': 'colab', '生产部署': 'sagemaker' } return recommendations.get(use_case, 'colab') # 使用示例 comparator = PlatformComparator() # 定义评分标准 criteria = { 'cost': 0.35, 'gpu_support': 0.30, 'scalability': 0.20, 'integration': 0.15 } platform_scores = comparator.compare_platforms(criteria) print("平台综合评分:") for platform_id, score in platform_scores.items(): print(f"{comparator.platforms[platform_id]['name']}: {score}") # 获取推荐 recommended = comparator.recommend_platform('中小企业', '中低预算', '3-5人')) print(f"\n推荐平台: {recommended}")
4.2 自动化机器学习流水线
构建端到端的自动化机器学习流水线是现代AI工程的最佳实践。以下展示了一个完整的AutoML流水线实现。
Python
# automl_pipeline.py - 自动化机器学习自动化机器学习流水线 from sklearn.model_selection import train_test_split, cross_val_score from sklearn.preprocessing import StandardScaler, LabelEncoder from sklearn.ensemble import RandomForestClassifier from sklearn.svm import SVC from sklearn.metrics import accuracy_score, classification_report import pandas as pd import numpy as np from typing import Tuple, List, Dict, Any import joblib import warnings warnings.filterwarnings('ignore') class AutoMLPipeline: """自动化机器学习自动化机器学习流水线""" def __init__(self, target_column: str, problem_type: str = 'classification'): self.target_column = target_column self.problem_type = problem_type self.models = {} self.best_model = None self.feature_importance = None def load_data(self, data_path: str) -> pd.DataFrame: """加载数据""" if data_path.endswith('.csv'): data = pd.read_csv(data_path) elif data_path.endswith('.parquet'): data = pd.read_parquet(data_path) else: raise ValueError("不支持的数据格式") print(f"数据加载完成,形状: {data.shape}") return data def preprocess_data(self, data: pd.DataFrame) -> Tuple[pd.DataFrame, Dict[str, Any]]: """数据预处理""" preprocessing preprocessing_steps = {} # 分离特征和目标变量 X = data.drop(columns=[self.target_column]) y = data[self.target_column] # 处理数值型特征 numeric_features = X.select_dtypes(include=[np.number]).columns.tolist() if numeric_features: scaler = StandardScaler() X[numeric_features] = scaler.fit_transform(X[numeric_features]) preprocessing_steps['scaler'] = scaler # 处理分类型特征 categorical_features categorical_features = X.select_dtypes(include=['object']).columns.tolist() label_encoders = {} for feature in categorical_features: le = LabelEncoder() X[feature] = le.fit_transform(X[feature]) label_encoders[feature] = le preprocessing_steps['label_encoders'] = label_encoders print("数据预处理完成") return X, y, preprocessing_steps def train_multiple_models(self, X: pd.DataFrame, y: pd.Series) -> Dict[str, Any]: """训练多个模型进行比较""" models = { 'random_forest': RandomForestClassifier(n_estimators=100, random_state=42), 'svm': SVC(probability=True, random_state=42) } trained_models = {} for name, model in models.items(): print(f"训练 {name}...") model.fit(X, y) trained_models[name] = model self.models = trained_models return trained_models def evaluate_models(self, X_test: pd.DataFrame, y_test: pd.Series) -> Dict[str, float]: """评估模型性能""" evaluation_results = {} for name, model in self.models.items(): y_pred = model.predict(X_test) accuracy = accuracy_score(y_test, y_pred) evaluation evaluation_results[name] = accuracy # 选择最佳模型 best_model_name = max(evaluation_results, key=evaluation_results.get) self.best_model = self.models[best_model_name] print(f"最佳模型: {best_model_name}, 准确率: {accuracy:.4f}") return evaluation_results def hyperparameter_tuning(self, model, param_grid: Dict[str, List[Any]], X: pd.DataFrame, y: pd.Series): """超参数调优""" from sklearn.model_selection import GridSearchCV grid_search = GridSearchCV( estimator=model, param_grid=param_grid, cv=5, scoring='accuracy', n_jobs=-1 ) grid_search.fit(X, y) print(f"最佳参数: {grid_search.best_params_}") return grid_search.best_estimator_ def run_complete_pipeline(self, data_path: str, test_size: float = 0.2) -> Dict[str, Any]: """运行完整流水线""" pipeline_results = {} # 1. 数据加载 data = self.load_data(data_path) pipeline_results['data_shape'] = data.shape # 2. 数据预处理 X, y, preprocessor = self.preprocess_data(data) pipeline_results['preprocessing'] = { 'numeric_features_scaled': len(preprocessor.get('scaler', {})) > 0, 'categorical_features_encoded': len(preprocessor.get('label_encoders', {}))) # 3. 划分划分训练测试集 X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=test_size, random_state=42, stratify=y ) # 4. 模型训练 trained_models = self.train_multiple_models(X_train, y_train) # 5. 模型评估 eval_results = self.evaluate_models(X_test, y_test) pipeline_results['evaluation'] = eval_results # 6. 特征重要性分析 if hasattr(self.best_model, 'feature_importances_'): self.feature_importance = dict(zip(X.columns, self.best_model.feature_importances_)) # 7. 保存最佳模型 model_filename = 'best_model.pkl' joblib.dump(self.best_model, model_filename) pipeline_results['best_model_saved'] = model_filename return pipeline_results # 扩展:深度学习专用流水线 class DeepLearningPipeline(AutoMLPipeline): """深度学习专用流水线""" def __init__(self, target_column: str, problem_type: str = 'classification'): super().__init__(target_column, problem_type) self.tensorboard_logdir = None def build_neural_network(self, input_dim: int, num_classes: int) -> Any: """构建神经网络模型""" from tensorflow import keras model = keras.Sequential([ keras.layers.Dense(256, activation='relu', input_shape=(input_dim,))), keras.layers.BatchNormalization(), keras.layers.Dropout(0.3), 3), keras.layers.Dense(128, activation='relu')), keras.layers.Dropout(0.2), keras.layers.Dense(num_classes, activation='softmax' if num_classes > 2 else 'sigmoid')), ]) return model def train_with_callbacks(self, model, X_train, y_train, X_val, y_val): """带回调函数的训练""" callbacks = [ keras.callbacks.EarlyStopping(patience=10, restore_best_weights=True), keras.callbacks.ReduceLROnPlateau(factor=0.5, patience=5)) ] history = model.fit( X_train, y_train, validation validation_data=(X_val, y_val), epochs=100, batch_size=32, callbacks=callbacks, verbose=1 ) return history # 使用示例 pipeline = AutoMLPipeline(target_column='species') # 运行完整流水线 results = pipeline.run_complete_pipeline('iris.csv') # 假设有这个数据集 print("\n流水线执行结果:") for key, value in results.items(): print(f"{key}: {value}")
以下Mermaid流程图展示了自动化机器学习流水线的完整架构:
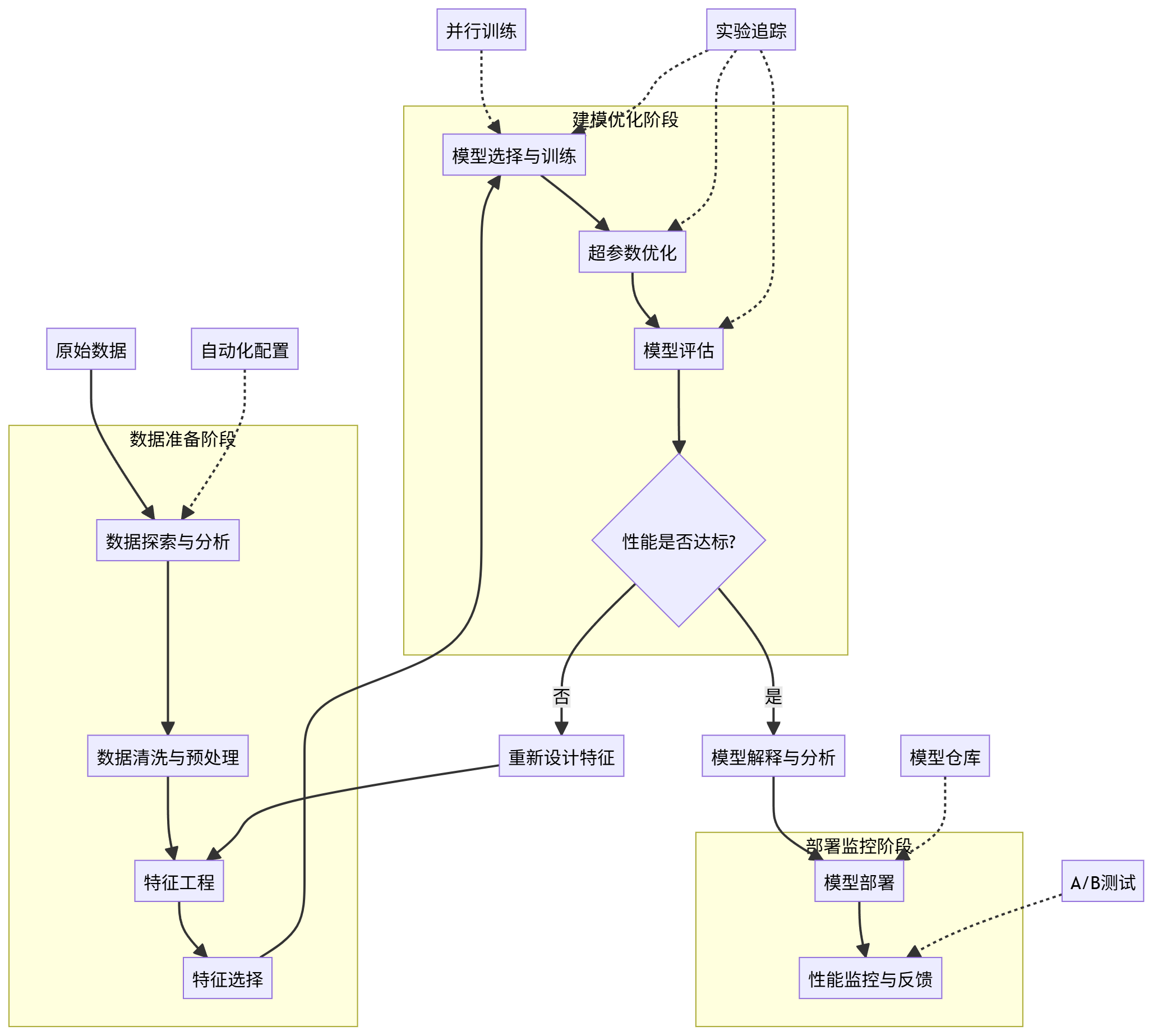
graph TB A[原始数据] --> B[数据探索与分析] B --> C[数据清洗与预处理] C --> D[特征工程] D --> E[特征选择] E --> F[模型选择与训练] F --> G[超参数优化] G --> H[模型评估] H --> I{性能是否达标?} I -->|否| J[重新设计特征] J --> D I -->|是| K[模型解释与分析] K --> L[模型部署] L --> M[性能监控与反馈] N[自动化配置] -.-> B O[并行训练] -.-> F P[实验追踪] -.-> F P -.-> G P -.-> H Q[模型仓库] -.-> L R[A/B测试] -.-> M subgraph 数据准备阶段 B C D E end subgraph 建模优化阶段 F G H I end subgraph 部署监控阶段 L M end
5 AI工具整合与未来发展趋势
5.1 全链路AI开发平台构建
将前述各种AI工具整合成统一的全链路开发平台是当前的重要趋势。这种平台提供了从数据准备到模型部署的完整解决方案。
Python
# full_stack_ai_platform.py - 全链路AI开发平台 import pandas as pd import numpy as np from datetime import datetime import json from typing import Dict, List, Any, Optional class FullStackAIPlatform: """全链路AI开发平台""" def __init__(self, project_name: str): self.project_name = project_name self.components = { 'data_management': None, 'annotation_tools': None, 'model_training': None, 'deployment': None, 'monitoring': None } self.workflows = {} self.project_metadata = {} def register_component(self, component_type: str, component: Any): """注册平台组件""" if component_type in self.components: self.components[component_type] = component else: raise ValueError(f"未知组件类型: {component_type}") def create_workflow(self, workflow_name: str, steps: List[Dict[str, Any]]): """创建工作流""" workflow = { 'name': workflow_name, 'steps': steps, 'created_at': datetime.now(), 'status': 'active' } self.workflows[workflow_name] = workflow return workflow def execute_workflow(self, workflow_name: str, parameters: Dict[str, Any]) -> Dict[str, Any]: """执行工作流""" if workflow_name not in self.workflows: raise ValueError(f"工作流不存在: {workflow_name}") workflow = self.workflows[workflow_name] execution_log = [] for step in workflow['steps']: step_name = step['name'] step_type = step['type'] print(f"执行步骤: {step_name} ({step_type})") # 模拟步骤执行 start_time = datetime.now() # 根据步骤类型调用相应组件 if step_type == 'data_collection': result result = self._execute_data_collection(step, parameters) execution_log.append({ ' 'step': step_name, 'start_time': start_time, 'result': result }) return { 'workflow': workflow_name, 'execution_log': execution_log, 'completed_at': datetime.now() } def _execute_data_collection(self, step: Dict[str, Any], parameters: Dict[str, Any]) -> Dict[str, Any]: """执行数据收集步骤""" # 模拟数据收集过程 collected_data = { 'sources': step.get('sources', []), 'volume': parameters.get('expected_data_volume', 'unknown')), 'quality_check': True } return result # AI工具效能评估框架 class AIToolsEfficiencyEvaluator: """AI工具效能评估器""" def __init__(self): self.metrics = { 'development_speed':peed': 0.0, 'code_quality': 0.0, 'maintainability': 0.0, 'team_adoption_rate': 0.0 } def evaluate_tool_impact(self, before_metrics: Dict[str, float], after_metrics: Dict[str, float]]) -> Dict[str, float]: """评估工具引入前后的影响""" improvements = {} for metric in self.metrics.keys(): if metric in before_metrics and metric in after_metrics: improvement = ((after_metrics[metric] - before_metrics[metric]) / before_metrics[metric]) * 100 improvements[metric] = improvement return improvements def calculate_roi(self, implementation_cost: float, time_saved_per_week: float, hourly_rate: float) -> Dict[str, float]: """计算投资回报率""" weeks_to_recoup = implementation_cost / (time_saved_per_week * hourly_rate) annual_savings = time_saved_per_week * hourly_rate * 52 roi = { 'implementation_cost': implementation_cost, 'weekly_time_savings_hours': time_saved_per_week, 'hourly_rate': hourly_rate, 'weeks_to_recoup_investment': weeks_to_recoup, 'annual_savings': annual_savings, 'roi_percentage': (annual_savings - implementation_cost) / implementation_cost * 100 } return roi # 未来趋势分析 class FutureTrendAnalyzer: """AI工具未来趋势分析""" def __init__(self): self.current_trends = [ '低代码/无代码AI平台', '自动化机器学习普及', '多模态学习工具整合', '实时学习和适应系统', '可信AI和可解释性工具' ] def predict_future_developments(self, horizon_years: int = 5) -> List[str]: """预测未来发展""" trends_by_horizon = { 1: [ '更智能的代码补全', '专业化领域工具出现', '协作功能强化' ], 3: [ '自主AI开发代理', '自然语言编程成熟', 'AI驱动的架构设计' ], 5: [ '完全自主的系统开发', '人机协同编程范式确立', 'AI原生开发工具生态成型' ] } return trends_by_horizon.get(horizon_years, []) def assess_technology_readiness(self, technology: str) -> Dict[str, Any]: """评估技术成熟度""" readiness_levels = { '智能代码生成': 8, '自动数据标注': 7, '自适应模型训练': 6, '自主AI系统': 4 } return { 'technology': technology, 'readiness_level': readiness_levels.get(technology, 0), 'adoption_prediction': self._predict_adoption(technology) } def _predict_adoption(self, technology: str) -> float: """预测技术采纳度""" adoption_predictions = { '智能代码生成': 0.75, '自动数据标注': 0.60, '自适应模型训练': 0.45, '自主AI系统': 0.25 } return adoption_predictions.get(technology, 0.0) # 使用示例 platform = FullStackAIPlatform("电商推荐系统升级") # 注册各个组件 platform.register_component('data_management', '高级数据管理系统') platform.register_component('annotation_tools', '智能标注套件') platform.register_component('model_training', '分布式训练平台') platform.register_component('deployment', '云原生部署引擎') platform.register_component('monitoring', '实时性能监控面板') # 创建工作流 recommendation_workflow = platform.create_workflow("用户行为分析模型训练", [ {'name': '数据收集', 'type': 'data_collection'}, {'name': '数据清洗', 'type': 'data_preprocessing'}, {'name': '行为模式标注', 'type': 'annotation'}, {'name': '特征工程', 'type': 'feature_engineering'}, {'name': '模型训练', 'type': 'model_training'}, {'name': '模型评估', 'type': 'evaluation'}, {'name': 'AB测试部署', 'type': 'deployment'} ]) # 执行工作流 execution_result = platform.execute_workflow("用户行为分析模型训练", { 'expected_data_volume': '10GB', 'required_accuracy': 0.85 }) print("工作流执行结果:") print(json.dumps(execution_result, default=str, indent=2)) # 趋势分析 trend_analyzer = FutureTrendAnalyzer() future_trendsrends = trend_analyzer.predict_future_developments(3) print("\n未来3年AI工具发展趋势:") for trend in future_trends: print(f"- {trend}") # 效能评估 evaluator = AIToolsEfficiencyEvaluator() before_stats = { 'development_speed': 40.0, # 单位:功能点/周 'code_quality': 70.0, # 代码质量得分 'maintainability': 60.0, # 可维护性指数 'team_adoption_rate': 50.0 # 团队采纳率百分比 } after_stats = { 'development_speed': 65.0, , 'code_quality': 82.0, 'maintainability': 78.0 } impact_assessment = evaluator.evaluate_tool_impact(before_stats, after_stats) print("\n工具引入影响评估:") for metric, improvement in impact_assessment.items(): print(f"{metric}: {improvement:.1f}%")
5.2 新兴技术与AI工具融合
AI工具正迅速与其他前沿技术融合,创造出更强大的解决方案强大的解决方案。
AI与区块链结合:
Python
# ai_blockchain_integration.py - AI与区块链技术融合 class AITokenEconomy: """基于区块链的AI服务代币经济""" def __init__(self, token_name: str, initial_supply: int): self.token_name = token_name self.total_supply = initial_supply self.transaction_history = [] def reward_data_contributors(self, contributor_address: str, amount: float): """奖励数据贡献者""" transaction = { 'from': 'system', 'to': contributor_address, 'amount': amount, 'timestamp': datetime.now().isoformat()) } self.transaction_history.append(transaction) print(f"奖励 {amount} {self.token_name} 给 {contributor_address}") def create_smart_contract(self, contract_type: str, terms: Dict[str, Any]]) -> str: """创建智能合约""" contract_hash = f"contract_{hash(json.dumps(terms)) % 1000000}" return contract_hash # AI与物联网(IoT)集成 class AIoTIntegration: """AI与物联网设备集成""" def __init__(self): self.device_registry = {} self.ai_models_deployed = {} def deploy_edge_ai_model(self, device_id: str, model_binary: bytes): """在边缘设备部署AI模型""" print(f"在设备 {device_id} 上部署AI模型...") # 模拟边缘部署 deployment_result = { 'device_id': device_id, 'model_size': len(model_binary), 'deployed_at': datetime.now() } self.ai_models_deployed[device_id] = deployment_result return deployment_result # 量子机器学习工具前瞻 class QuantumMLTools: """量子机器学习工具前瞻""" def __init__(self): self.quantum_algorithms = ['QNN', 'VQC', 'QSVM']'} def simulate_quantum_advantage(self, problem_size: int) -> Dict[str, Any]: """模拟量子优势""" classical_complexity = problem_size ** 2 # O(n²) quantum_complexity = problem_size * np.log(problem_size) # O(n log n) advantage_factor = classical_complexity / quantum_complexity return { 'problem_size': problem_size, 'classical_complexity': classical_complexity, 'quantum_complexity': quantum_complexity, 'quantum_advantage': advantage_factor } # 使用示例 token_economy = AITokenEconomy("AI_SERVICE_TOKEN", 1000000) token_economy.reward_data_contributors("0x742...d35", 150.5) aiot_system = AIoTIntegration() edge_deployment = aiot_system.deploy_edge_ai_model("sensor_node_001", b"mock_model_binary")) print(f"边缘AI部署结果: {edge_deployment}") quantum_ml = QuantumMLTools() qa_result = quantum_ml.simulate_quantum_advantage(1000)) print(f"量子优势模拟结果: {qa_result}")
结论
AI工具生态正在经历前所未有的快速发展,从智能编程助手到专业数据标注平台,再到强大的模型训练系统,这些工具极大地降低了AI技术的应用门槛。GitHub Copilot等智能编码工具通过学习海量代码库,能够提供精准的代码补全和建议,显著提升了开发效率。数据标注工具通过标准化流程和质量控制机制,确保了训练数据的可靠性。而现代模型训练平台则通过自动化和云计算技术,让复杂的模型训练变得简单高效。
未来,我们可以预见以下几个重要趋势:
-
工具智能化程度加深:AI工具将从被动辅助转向主动建议,甚至能够自主完成某些开发任务。
-
**全 全链路整合:独立的AI工具将逐渐整合为统一的开发平台,提供端到端的解决方案。
-
专业化与普及化并存:一方面会出现更加专业化的垂直领域工具,另一方面也会有更多面向非专业人士的简易工具。
-
可信AI成为标配:模型可解释性、公平性检测等工具将成为AI开发的标准组成部分。
随着这些技术的发展,AI工具将继续重塑软件开发的方式软件开发的方式,让人工智能技术更好地服务于各行各业。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 28
28 0
0- 0



 已为社区贡献88条内容
已为社区贡献88条内容

所有评论(0)