
AI 开发核心工具全景指南:编码、标注与训练全流程实战
人工智能技术的爆发式增长,离不开三大核心工具支柱的支撑:智能编码工具、数据标注工具与模型训练平台。这三类工具构成了 AI 开发的 "铁三角"—— 智能编码工具提升开发效率,数据标注工具保障数据质量,模型训练平台提供算力与算法支持,三者环环相扣,共同推动 AI 项目从概念走向落地。本文将以实战为核心,深度解析 GitHub Copilot、LabelStudio、TensorFlow 等主流工具的技
引言
人工智能技术的爆发式增长,离不开三大核心工具支柱的支撑:智能编码工具、数据标注工具与模型训练平台。这三类工具构成了 AI 开发的 "铁三角"—— 智能编码工具提升开发效率,数据标注工具保障数据质量,模型训练平台提供算力与算法支持,三者环环相扣,共同推动 AI 项目从概念走向落地。
本文将以实战为核心,深度解析 GitHub Copilot、LabelStudio、TensorFlow 等主流工具的技术原理、应用场景与进阶技巧。文中融入大量可直接复用的代码示例、mermaid 流程图、Prompt 工程案例与可视化图表,帮助开发者系统性掌握 AI 开发全流程工具链,提升项目交付效率。
第一部分:智能编码工具 ——AI 驱动的开发效率革命
1.1 核心工具:GitHub Copilot 深度解析
GitHub Copilot 是 OpenAI 与 GitHub 联合推出的智能编码助手,基于 GPT 系列模型优化训练,支持数十种编程语言与主流开发环境。其核心优势在于能够理解上下文语义,实时生成代码建议、补全函数逻辑、修复语法错误,甚至根据自然语言描述生成完整代码块。
1.1.1 技术原理与工作流程
GitHub Copilot 的工作流程可概括为 "上下文解析 - 意图识别 - 代码生成 - 反馈优化" 四个阶段:
graph TD
A[开发者输入上下文] -->|代码/注释/自然语言| B[Copilot解析语义]
B --> C[识别开发意图]
C --> D[检索训练库相似场景]
D --> E[生成多版代码候选]
E --> F[开发者选择/修改]
F --> G[反馈至模型优化]
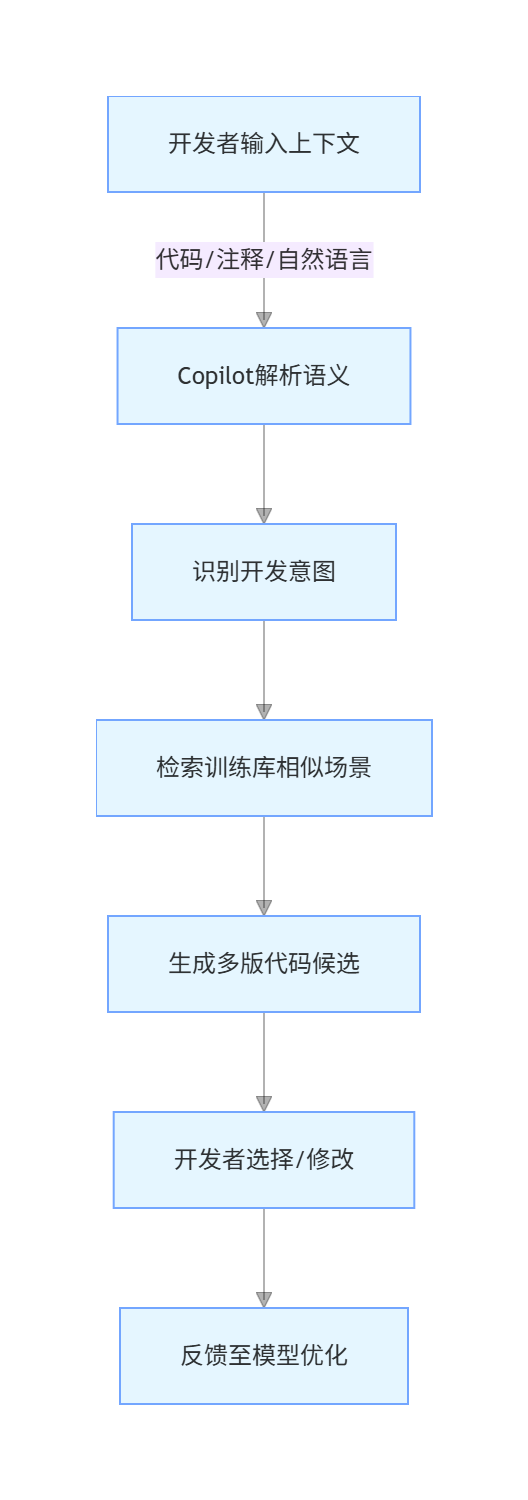
其核心技术亮点包括:
- 上下文窗口扩展:支持分析当前文件及关联文件的代码结构,理解跨文件依赖关系
- 多模态输入支持:同时接收代码、注释、自然语言三种输入形式,灵活适配不同开发场景
- 领域模型微调:针对特定编程语言(如 Python、Java)和框架(如 TensorFlow、PyTorch)进行专项优化
1.1.2 基础使用示例(Python 实战)
以下通过三个典型场景,展示 GitHub Copilot 的实战应用:
场景 1:根据自然语言生成函数输入注释(Prompt):
python
运行
# 定义一个函数,接收列表和目标值,返回目标值在列表中的所有索引(支持重复元素)
Copilot 自动生成代码:
python
运行
def find_all_indices(lst, target):
"""
查找目标值在列表中的所有索引位置
:param lst: 输入列表
:param target: 目标值
:return: 包含所有索引的列表
"""
indices = []
for idx, value in enumerate(lst):
if value == target:
indices.append(idx)
return indices
# 测试示例
test_list = [1, 3, 5, 3, 7, 3, 9]
print(find_all_indices(test_list, 3)) # 输出: [1, 3, 5]
场景 2:补全复杂算法逻辑输入部分代码:
python
运行
# 实现快速排序算法
def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
Copilot 补全剩余逻辑:
python
运行
# 实现快速排序算法
def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quick_sort(left) + middle + quick_sort(right)
# 测试示例
test_arr = [6, 3, 8, 5, 2, 9, 1]
print(quick_sort(test_arr)) # 输出: [1, 2, 3, 5, 6, 8, 9]
场景 3:修复代码错误输入存在 bug 的代码:
python
运行
# 计算斐波那契数列第n项(存在逻辑错误)
def fibonacci(n):
if n <= 0:
return 0
elif n == 1:
return 1
else:
return fibonacci(n) + fibonacci(n-1) # 递归调用错误
print(fibonacci(5)) # 会导致无限递归
Copilot 识别错误并给出修复建议:
python
运行
# 计算斐波那契数列第n项(已修复递归调用错误)
def fibonacci(n):
if n <= 0:
return 0
elif n == 1:
return 1
else:
return fibonacci(n-1) + fibonacci(n-2) # 修复为正确的递归关系
print(fibonacci(5)) # 输出: 5
1.1.3 进阶技巧:Prompt 工程优化
要充分发挥 GitHub Copilot 的能力,需要掌握针对性的 Prompt 设计技巧。以下是四类高频场景的优化 Prompt 示例:
| 应用场景 | 普通 Prompt | 优化后 Prompt | 效果差异 |
|---|---|---|---|
| 数据处理 | "写一个处理 CSV 的代码" | "使用 pandas 读取 data.csv,过滤掉空值行,按 date 列排序,计算 value 列的平均值并保存到 result.csv" | 普通 Prompt 生成通用代码,优化后直接生成可执行的目标代码 |
| 机器学习 | "写一个分类模型" | "使用 scikit-learn 构建逻辑回归模型,对 iris 数据集进行分类,包含数据划分(8:2)、标准化、模型训练、准确率评估步骤" | 优化后明确工具、数据集、流程,生成完整可运行的训练代码 |
| API 开发 | "写一个 Flask 接口" | "使用 Flask 框架编写 POST 接口 /api/user,接收 JSON 格式的 name 和 age 参数,验证参数合法性,返回 200 状态码和成功信息" | 明确框架、请求方式、参数要求,生成带参数验证的规范接口 |
| 异常处理 | "写一个文件读取函数" | "写一个读取文本文件的函数,包含文件不存在、权限不足的异常处理,返回读取内容或错误信息,使用 with 语句保证文件正确关闭" | 优化后包含异常处理和最佳实践,代码更健壮 |
1.2 其他主流智能编码工具对比
除 GitHub Copilot 外,还有多款优秀的智能编码工具,各自具备独特优势:
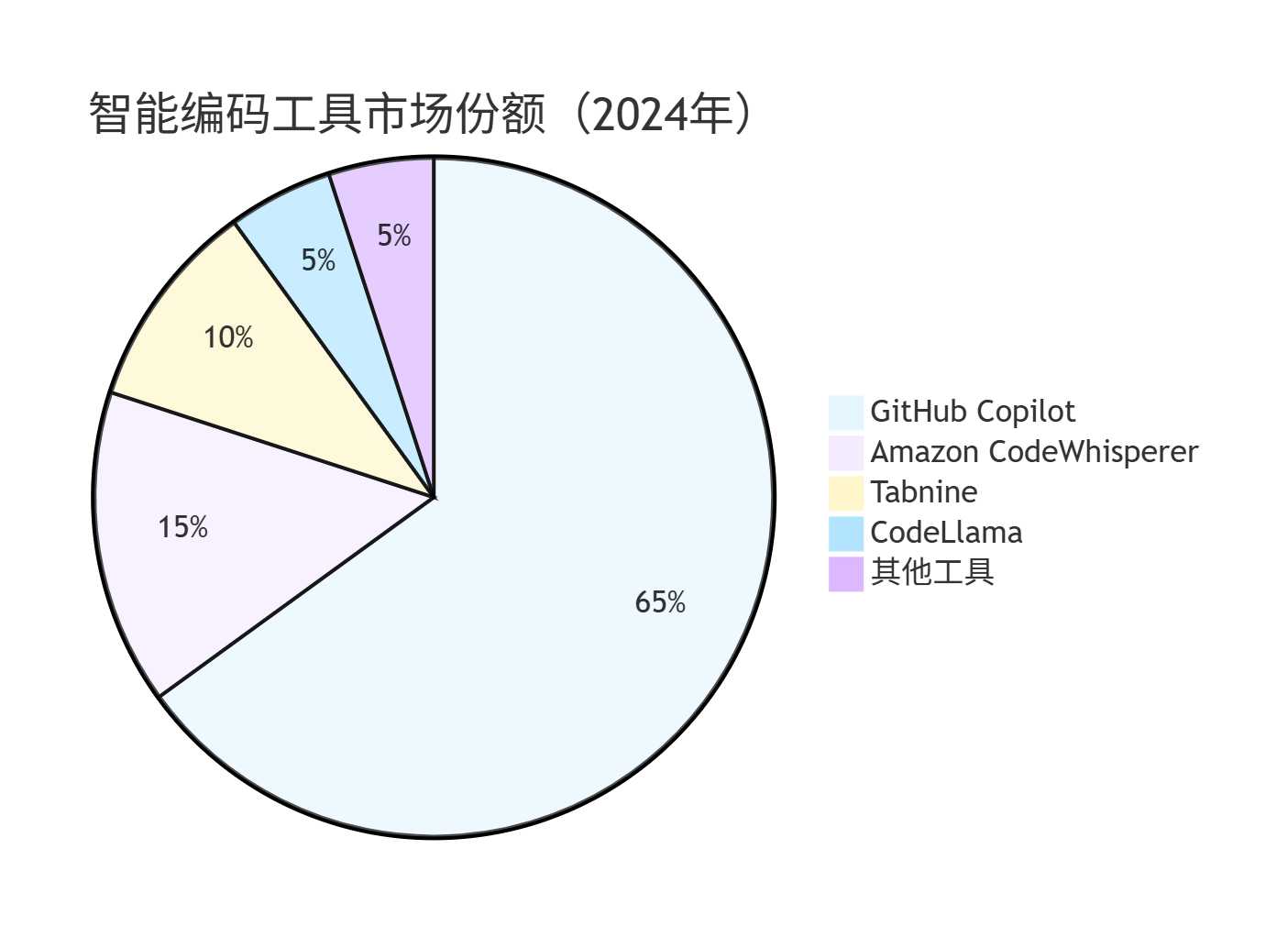
1.2.1 工具对比图表
pie
title 智能编码工具市场份额(2024年)
"GitHub Copilot" : 65
"Amazon CodeWhisperer" : 15
"Tabnine" : 10
"CodeLlama" : 5
"其他工具" : 5
1.2.2 核心工具特性对比
| 工具名称 | 核心优势 | 支持语言 | 集成环境 | 收费模式 | 适用场景 |
|---|---|---|---|---|---|
| GitHub Copilot | 上下文理解强,代码质量高 | 50 + 种 | VS Code、JetBrains、Neovim | 免费版(基础功能)、Pro 版($19 / 月) | 全场景开发,尤其适合 AI/ML 项目 |
| Amazon CodeWhisperer | 与 AWS 生态深度集成 | 40 + 种 | VS Code、JetBrains、Cloud9 | 免费(个人开发者)、按使用量收费(企业) | 云原生、AWS 相关开发 |
| Tabnine | 本地部署支持,隐私性好 | 30 + 种 | 主流 IDE 全覆盖 | 免费版、Pro 版($12 / 月)、企业版 | 对代码隐私要求高的团队 |
| CodeLlama | 开源免费,可自定义微调 | 20 + 种 | 支持主流 IDE 插件 | 完全免费 | 研究场景、自定义开发需求 |
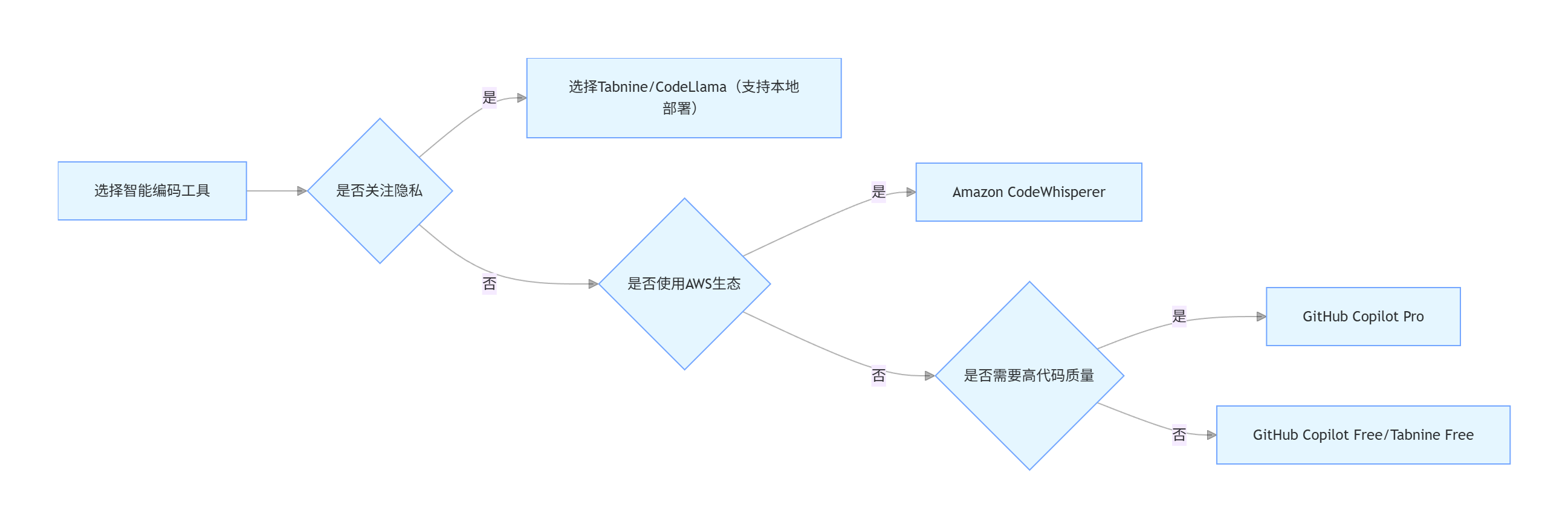
1.2.3 工具选择决策流程图
graph LR
A[选择智能编码工具] --> B{是否关注隐私}
B -->|是| C[选择Tabnine/CodeLlama(支持本地部署)]
B -->|否| D{是否使用AWS生态}
D -->|是| E[Amazon CodeWhisperer]
D -->|否| F{是否需要高代码质量}
F -->|是| G[GitHub Copilot Pro]
F -->|否| H[GitHub Copilot Free/Tabnine Free]
1.3 智能编码工具在 AI 项目中的实战案例
以一个图像分类项目为例,展示智能编码工具如何贯穿数据预处理、模型构建、训练评估全流程:
1.3.1 数据预处理代码生成
Prompt:
python
运行
# 使用OpenCV和numpy预处理图像数据集
# 步骤:1.读取指定文件夹下所有.jpg图片 2.调整尺寸为224x224 3.归一化像素值到[0,1] 4.划分训练集和测试集(8:2) 5.保存为.npy文件
生成代码:
python
运行
import cv2
import numpy as np
import os
from sklearn.model_selection import train_test_split
def preprocess_image_dataset(data_dir, img_size=(224, 224), test_size=0.2):
"""
预处理图像数据集
:param data_dir: 数据集文件夹路径(子文件夹为类别)
:param img_size: 目标图像尺寸
:param test_size: 测试集比例
:return: X_train, X_test, y_train, y_test
"""
X = []
y = []
class_labels = os.listdir(data_dir)
for label_idx, class_name in enumerate(class_labels):
class_dir = os.path.join(data_dir, class_name)
if not os.path.isdir(class_dir):
continue
for img_name in os.listdir(class_dir):
if img_name.endswith('.jpg'):
img_path = os.path.join(class_dir, img_name)
# 读取图像并调整尺寸
img = cv2.imread(img_path)
img = cv2.resize(img, img_size)
# 归一化
img = img / 255.0
X.append(img)
y.append(label_idx)
# 转换为numpy数组
X = np.array(X)
y = np.array(y)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size, random_state=42, stratify=y)
# 保存处理后的数据
np.save('X_train.npy', X_train)
np.save('X_test.npy', X_test)
np.save('y_train.npy', y_train)
np.save('y_test.npy', y_test)
print(f"数据预处理完成!")
print(f"训练集:{X_train.shape}, 测试集:{X_test.shape}")
return X_train, X_test, y_train, y_test
# 调用函数
preprocess_image_dataset('image_dataset')
1.3.2 模型构建代码生成
Prompt:
python
运行
# 使用TensorFlow/Keras构建CNN图像分类模型
# 要求:输入尺寸224x224x3,包含3个卷积块(每个卷积块2个Conv2D层+MaxPooling2D),1个全连接层,输出层为类别数
# 加入Dropout防止过拟合,使用Adam优化器,交叉熵损失函数
生成代码:
python
运行
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout, BatchNormalization
def build_cnn_model(input_shape=(224, 224, 3), num_classes=10):
"""
构建CNN图像分类模型
:param input_shape: 输入图像尺寸
:param num_classes: 分类类别数
:return: Keras模型
"""
model = Sequential([
# 第一个卷积块
Conv2D(32, (3, 3), activation='relu', padding='same', input_shape=input_shape),
BatchNormalization(),
Conv2D(32, (3, 3), activation='relu', padding='same'),
BatchNormalization(),
MaxPooling2D((2, 2), strides=2),
Dropout(0.25),
# 第二个卷积块
Conv2D(64, (3, 3), activation='relu', padding='same'),
BatchNormalization(),
Conv2D(64, (3, 3), activation='relu', padding='same'),
BatchNormalization(),
MaxPooling2D((2, 2), strides=2),
Dropout(0.25),
# 第三个卷积块
Conv2D(128, (3, 3), activation='relu', padding='same'),
BatchNormalization(),
Conv2D(128, (3, 3), activation='relu', padding='same'),
BatchNormalization(),
MaxPooling2D((2, 2), strides=2),
Dropout(0.25),
# 全连接层
Flatten(),
Dense(512, activation='relu'),
BatchNormalization(),
Dropout(0.5),
Dense(num_classes, activation='softmax')
])
# 编译模型
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=1e-3),
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy']
)
model.summary()
return model
# 构建模型(假设类别数为5)
model = build_cnn_model(num_classes=5)
第二部分:数据标注工具 ——AI 模型的 "燃料加工厂"
2.1 数据标注的核心价值与流程
数据是 AI 模型的 "燃料",而标注数据则是经过精炼的 "优质燃料"。高质量的标注数据直接决定模型的训练效果 —— 即使是最先进的算法,在劣质数据上也难以发挥作用。数据标注的核心价值体现在:
- 为监督学习提供标签参考
- 帮助模型理解数据特征与模式
- 验证模型预测结果的准确性
- 发现数据集中的偏差与异常
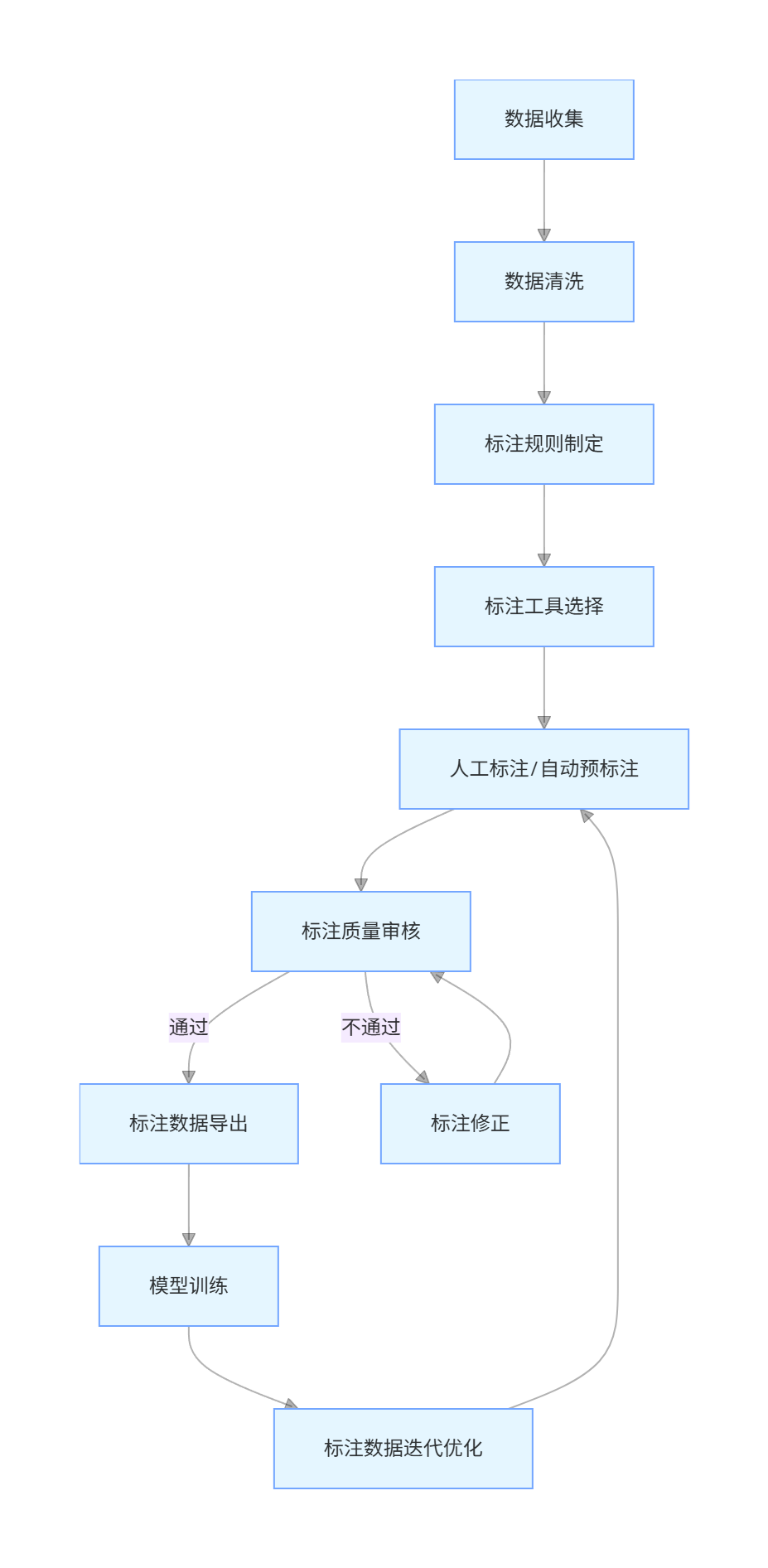
数据标注的标准流程如下:
graph TD
A[数据收集] --> B[数据清洗]
B --> C[标注规则制定]
C --> D[标注工具选择]
D --> E[人工标注/自动预标注]
E --> F[标注质量审核]
F -->|通过| G[标注数据导出]
F -->|不通过| H[标注修正]
H --> F
G --> I[模型训练]
I --> J[标注数据迭代优化]
J --> E
2.2 核心工具:Label Studio 全功能解析
Label Studio 是一款开源的全功能数据标注工具,支持图像、文本、音频、视频等多类型数据标注,覆盖分类、分割、实体识别、情感分析等 20 + 标注场景。其模块化架构允许自定义标注界面和集成机器学习模型实现半自动化标注。
2.2.1 安装与基础配置
bash
# 安装Label Studio
pip install label-studio
# 启动Label Studio服务
label-studio start
# 输出信息
# Label Studio running at http://localhost:8080
# Login with username: admin, password: xxxxxxxx
登录后创建项目的流程:
- 点击 "Create Project" 输入项目名称和描述
- 选择数据类型(Images、Text、Audio 等)
- 配置标注界面(可使用预置模板或自定义)
- 上传数据文件或连接数据源
- 开始标注工作
2.2.2 标注配置文件示例(图像目标检测)
Label Studio 使用 XML 格式的配置文件定义标注界面,以下是一个图像目标检测的配置示例:
xml
<View>
<!-- 图像显示区域 -->
<Image name="image" value="$image" zoom="true"/>
<!-- 标注控件:矩形框工具 -->
<RectangleLabels name="label" toName="image">
<Label value="Person" background="red"/>
<Label value="Car" background="blue"/>
<Label value="Bicycle" background="green"/>
<Label value="Traffic Light" background="yellow"/>
</RectangleLabels>
<!-- 标注说明 -->
<Header value="标注说明:请用矩形框标记图像中的目标,并选择正确类别"/>
</View>
2.2.3 集成 Python 脚本实现自动预标注
Label Studio 支持通过 API 集成机器学习模型实现自动预标注,大幅提高标注效率:
python
运行
import requests
import json
import base64
from PIL import Image
import io
# Label Studio配置
LABEL_STUDIO_URL = "http://localhost:8080"
API_KEY = "your_api_key_here"
PROJECT_ID = 1
# 加载预训练的目标检测模型(示例使用简化版模型)
def detect_objects(image_path):
"""模拟目标检测模型,返回检测结果"""
# 实际应用中替换为真实模型推理代码
return [
{"label": "Person", "x": 100, "y": 150, "width": 80, "height": 160},
{"label": "Car", "x": 300, "y": 200, "width": 120, "height": 80}
]
# 获取未标注任务
def get_unlabeled_tasks():
headers = {"Authorization": f"Token {API_KEY}"}
response = requests.get(
f"{LABEL_STUDIO_URL}/api/projects/{PROJECT_ID}/tasks",
headers=headers,
params={"page_size": 10, "labeled": "false"}
)
return response.json()
# 提交预标注结果
def submit_predictions(task_id, predictions):
headers = {
"Authorization": f"Token {API_KEY}",
"Content-Type": "application/json"
}
# 转换预测结果为Label Studio格式
results = []
for pred in predictions:
results.append({
"from_name": "label",
"to_name": "image",
"type": "rectanglelabels",
"value": {
"rectanglelabels": [pred["label"]],
"x": pred["x"],
"y": pred["y"],
"width": pred["width"],
"height": pred["height"]
},
"score": 0.85 # 预测置信度
})
payload = {
"task": task_id,
"result": results,
"model_version": "v1.0"
}
response = requests.post(
f"{LABEL_STUDIO_URL}/api/predictions",
headers=headers,
data=json.dumps(payload)
)
return response.json()
# 处理未标注任务并添加预标注
def process_unlabeled_tasks():
tasks = get_unlabeled_tasks()
for task in tasks:
task_id = task["id"]
image_url = task["data"]["image"]
# 下载图像并进行目标检测
image_data = requests.get(image_url).content
# 这里简化处理,实际应保存图像后调用detect_objects
predictions = detect_objects("temp_image.jpg")
# 提交预标注结果
submit_predictions(task_id, predictions)
print(f"已为任务 {task_id} 添加预标注")
if __name__ == "__main__":
process_unlabeled_tasks()
2.2.4 标注质量控制方法
Label Studio 提供多种质量控制机制:
- 标注共识(Annotation Agreement):
python
运行
# 计算标注者间的一致性
import pandas as pd
from sklearn.metrics import cohen_kappa_score
# 加载多个标注者对同一批数据的标注结果
annotator1 = [0, 1, 2, 0, 1, 2, 0]
annotator2 = [0, 1, 1, 0, 1, 2, 0]
annotator3 = [0, 1, 2, 0, 2, 2, 0]
# 计算Cohen's Kappa系数(两人之间)
kappa12 = cohen_kappa_score(annotator1, annotator2)
kappa13 = cohen_kappa_score(annotator1, annotator3)
print(f"标注者1与2的一致性: {kappa12:.3f}")
print(f"标注者1与3的一致性: {kappa13:.3f}")
- 黄金样本测试:在标注任务中混入已知正确答案的样本,评估标注者准确率
- 实时标注审核:配置审核流程,标注结果需经审核通过后才能使用
2.3 其他主流数据标注工具对比
不同场景需要选择不同的标注工具,以下是主流工具的特性对比:
| 工具名称 | 支持数据类型 | 开源性 | 特色功能 | 适用场景 | 价格 |
|---|---|---|---|---|---|
| Label Studio | 图像、文本、音频、视频等 | 开源免费 | 支持 ML 模型集成、自定义界面 | 全场景标注,尤其是需要定制化的团队 | 免费(自托管)/ 企业版收费 |
| VGG Image Annotator | 图像 | 开源免费 | 轻量级,支持多种图像标注类型 | 小型图像标注项目 | 免费 |
| Prodigy | 文本、图像 | 商业软件 | 与 spaCy 深度集成,适合 NLP 任务 | NLP 领域专业标注 | 起价 $800 / 年 |
| Amazon SageMaker Ground Truth | 多类型数据 | 商业服务 | 自动标注、人机协同 | 大规模标注项目,AWS 用户 | 按标注量收费 |
| Labelbox | 多类型数据 | 商业软件 | 高级分析、团队协作 | 企业级标注项目 | 定制化报价 |
barChart
title 数据标注工具功能评分(1-10分)
xAxis 工具名称
yAxis 评分
series
易用性
6, 8, 7, 5, 6
功能性
9, 6, 8, 9, 10
协作性
8, 3, 6, 9, 10
成本效益
10, 10, 5, 6, 4
xAxis 标签
Label Studio, VGG Annotator, Prodigy, SageMaker, Labelbox
2.4 数据标注实战案例:构建自动驾驶图像数据集
以自动驾驶场景的图像标注为例,展示完整的标注流程与工具应用:
- 数据准备:收集包含道路场景的图像数据,约 10,000 张
- 标注目标:标记车辆、行人、交通信号灯、交通标志、车道线等目标
- 标注配置:使用 Label Studio 的自定义配置文件
xml
<View>
<Image name="image" value="$image" zoom="true" zoomControl="true"/>
<!-- 目标检测(矩形框) -->
<RectangleLabels name="objects" toName="image">
<Label value="Car" background="#FF0000"/>
<Label value="Truck" background="#FFA500"/>
<Label value="Pedestrian" background="#00FF00"/>
<Label value="Cyclist" background="#00FFFF"/>
</RectangleLabels>
<!-- 交通灯检测(多边形) -->
<PolygonLabels name="traffic_lights" toName="image">
<Label value="Red Light" background="#FF0000"/>
<Label value="Green Light" background="#00FF00"/>
<Label value="Yellow Light" background="#FFFF00"/>
</PolygonLabels>
<!-- 车道线检测(线条) -->
<LineLabels name="lane_lines" toName="image">
<Label value="Solid Line" background="#0000FF"/>
<Label value="Dashed Line" background="#800080"/>
</LineLabels>
<!-- 场景分类 -->
<Choices name="scene" toName="image" choice="single">
<Choice value="Highway"/>
<Choice value="Urban Road"/>
<Choice value="Residential"/>
<Choice value="Intersection"/>
</Choices>
</View>
-
半自动化标注:
- 使用预训练的 YOLO 模型进行车辆和行人的自动检测
- 集成车道线检测算法生成初始标注
- 人工修正自动标注结果
-
质量控制:
- 随机抽取 10% 数据进行二次标注
- 计算标注者间一致性(目标检测 IoU > 0.8)
- 建立错误案例库用于标注规则优化
-
标注结果导出与应用:导出 COCO 格式的标注文件,用于训练自动驾驶感知模型:
python
运行
# 示例:将Label Studio标注结果转换为COCO格式 import json import os def labelstudio_to_coco(labelstudio_json, output_dir): """转换Label Studio标注结果为COCO格式""" with open(labelstudio_json, 'r') as f: data = json.load(f) coco = { "info": {}, "licenses": [], "categories": [], "images": [], "annotations": [] } # 定义类别 categories = { "Car": 1, "Truck": 2, "Pedestrian": 3, "Cyclist": 4, "Red Light": 5, "Green Light": 6, "Yellow Light": 7, "Solid Line": 8, "Dashed Line": 9 } for name, id in categories.items(): coco["categories"].append({"id": id, "name": name}) # 处理图像和标注 annotation_id = 1 for item in data: image_id = item["id"] image_name = os.path.basename(item["data"]["image"]) # 添加图像信息 coco["images"].append({ "id": image_id, "file_name": image_name, "width": 1920, # 实际应从图像获取 "height": 1080 }) # 处理标注 for annotation in item["annotations"][0]["result"]: label = annotation["value"][list(annotation["value"].keys())[0]][0] category_id = categories[label] # 根据标注类型处理坐标 if annotation["type"] == "rectanglelabels": x = annotation["value"]["x"] y = annotation["value"]["y"] width = annotation["value"]["width"] height = annotation["value"]["height"] # 转换为COCO格式(绝对坐标) coco["annotations"].append({ "id": annotation_id, "image_id": image_id, "category_id": category_id, "bbox": [x, y, width, height], "area": width * height, "iscrowd": 0 }) annotation_id += 1 # 保存COCO格式文件 with open(os.path.join(output_dir, "coco_annotations.json"), 'w') as f: json.dump(coco, f) print(f"转换完成,生成COCO格式标注文件") # 调用转换函数 labelstudio_to_coco("labelstudio_annotations.json", "coco_dataset")
第三部分:模型训练平台 ——AI 模型的 "锻造工厂"
3.1 模型训练平台的核心架构与功能
模型训练平台是 AI 开发的基础设施,负责提供算力资源、训练环境、实验管理和模型部署等全生命周期支持。其核心架构包括:
graph TD
A[用户接口层] -->|Web/CLI/SDK| B[任务调度层]
B --> C[资源管理层]
C --> D[计算资源池]
C --> E[存储资源池]
B --> F[实验管理层]
F --> G[模型版本控制]
F --> H[训练日志管理]
F --> I[指标可视化]
B --> J[环境隔离层]
J --> K[容器化环境]
J --> L[虚拟环境]
B --> M[模型部署层]
M --> N[API服务]
M --> O[边缘部署]
M --> P[云服务集成]
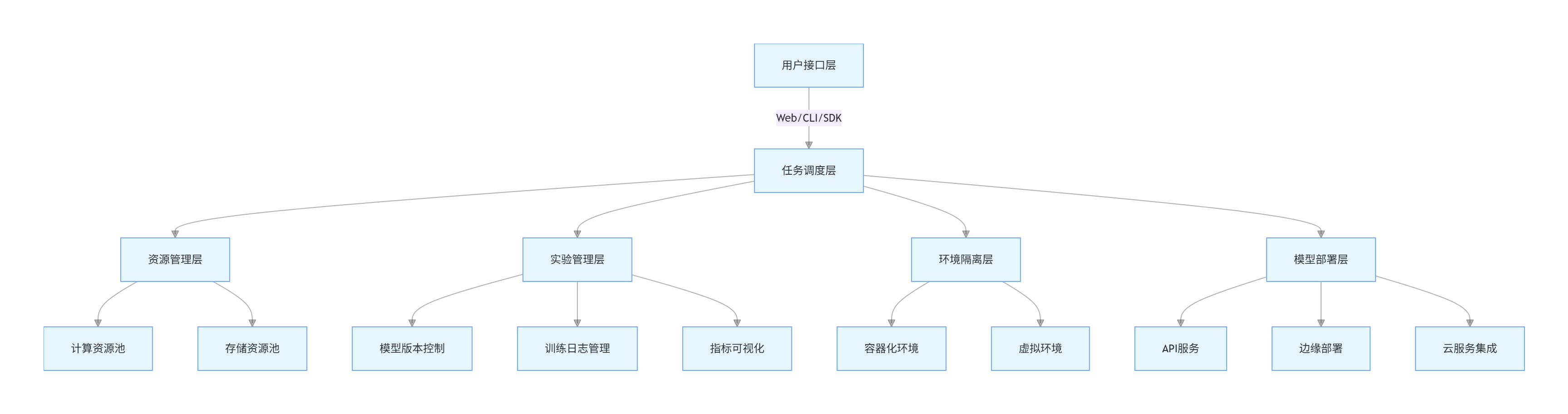
核心功能模块:
- 算力管理:GPU/TPU 资源分配、弹性扩展
- 实验跟踪:参数记录、指标对比、版本管理
- 分布式训练:数据并行、模型并行支持
- 自动化工具:超参数搜索、自动模型选择
- 部署集成:模型打包、API 生成、监控告警
3.2 主流训练框架与平台对比
3.2.1 框架对比
| 框架 | 开发方 | 优势领域 | 分布式支持 | 生态系统 | 学习曲线 |
|---|---|---|---|---|---|
| TensorFlow | 生产部署、移动端 | 强 | 丰富,预训练模型多 | 较陡 | |
| PyTorch | Meta | 研究、快速原型 | 强 | 活跃,社区支持好 | 平缓 |
| MXNet | Apache | 灵活性与性能平衡 | 强 | 中等 | 中等 |
| JAX | 高性能数值计算 | 极强 | 快速增长 | 较陡 | |
| scikit-learn | 社区 | 传统机器学习 | 弱 | 成熟稳定 | 平缓 |
radarChart
title 深度学习框架能力雷达图
axis 易用性, 性能, 分布式, 部署能力, 社区支持, 文档质量
TensorFlow
6, 9, 9, 10, 9, 9
PyTorch
9, 8, 8, 7, 10, 8
MXNet
7, 8, 9, 7, 6, 7
JAX
5, 10, 10, 6, 7, 6
3.2.2 云训练平台对比
| 平台 | 核心优势 | 算力类型 | 特色功能 | 价格模式 |
|---|---|---|---|---|
| AWS SageMaker | 全托管,与 AWS 生态集成 | GPU/TPU/ 自定义芯片 | 自动模型调优、管道部署 | 按需付费 / 预留实例 |
| Google Vertex AI | 与 Google Cloud 深度集成 | TPU 优势明显 | 端到端 MLOps 支持 | 按需付费 / 承诺使用折扣 |
| Microsoft Azure ML | 与 Office/Teams 集成 | 多元化算力选择 | 低代码界面、AutoML | 按需付费 / 企业协议 |
| Alibaba PAI | 国内访问速度快 | GPU 资源丰富 | 针对中文场景优化 | 按需付费 / 包年包月 |
| 开源替代方案(MLflow+Kubeflow) | 灵活定制,无厂商锁定 | 自建 / 任意云厂商 | 完全开源可控 | 自建成本 |
3.3 TensorFlow 训练平台实战
以图像分类模型为例,展示基于 TensorFlow 的完整训练流程:
3.3.1 分布式训练配置
python
运行
# TensorFlow分布式训练配置示例
import tensorflow as tf
import numpy as np
# 定义分布式策略(多GPU训练)
strategy = tf.distribute.MirroredStrategy()
print(f"使用 {strategy.num_replicas_in_sync} 个GPU进行训练")
# 数据集路径
TRAIN_DATA_PATH = 'coco_dataset/train'
VAL_DATA_PATH = 'coco_dataset/val'
BATCH_SIZE_PER_REPLICA = 32
BATCH_SIZE = BATCH_SIZE_PER_REPLICA * strategy.num_replicas_in_sync
# 数据加载与预处理
def load_dataset(path, batch_size):
datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1./255,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True
)
dataset = datagen.flow_from_directory(
path,
target_size=(224, 224),
batch_size=batch_size,
class_mode='categorical'
)
return dataset
train_dataset = load_dataset(TRAIN_DATA_PATH, BATCH_SIZE)
val_dataset = load_dataset(VAL_DATA_PATH, BATCH_SIZE)
# 在分布式策略下构建模型
with strategy.scope():
# 使用预训练模型作为基础
base_model = tf.keras.applications.ResNet50(
weights='imagenet',
include_top=False,
input_shape=(224, 224, 3)
)
# 冻结基础模型
base_model.trainable = False
# 添加分类头
model = tf.keras.Sequential([
base_model,
tf.keras.layers.GlobalAveragePooling2D(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(10, activation='softmax') # 10个类别
])
# 编译模型
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=1e-4),
loss='categorical_crossentropy',
metrics=['accuracy']
)
# 定义回调函数
callbacks = [
tf.keras.callbacks.ModelCheckpoint(
'best_model.h5',
monitor='val_accuracy',
save_best_only=True,
mode='max'
),
tf.keras.callbacks.TensorBoard(
log_dir='./logs',
histogram_freq=1
),
tf.keras.callbacks.ReduceLROnPlateau(
monitor='val_loss',
factor=0.2,
patience=5,
min_lr=1e-6
)
]
# 训练模型
history = model.fit(
train_dataset,
epochs=30,
validation_data=val_dataset,
callbacks=callbacks
)
# 微调模型(解冻部分层)
base_model.trainable = True
fine_tune_at = 100 # 从第100层开始解冻
for layer in base_model.layers[:fine_tune_at]:
layer.trainable = False
# 降低学习率进行微调
with strategy.scope():
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=1e-5), # 学习率降低10倍
loss='categorical_crossentropy',
metrics=['accuracy']
)
# 继续训练
history_fine = model.fit(
train_dataset,
epochs=50, # 总epochs数
initial_epoch=history.epoch[-1],
validation_data=val_dataset,
callbacks=callbacks
)
# 保存最终模型
model.save('final_model.h5')
3.3.2 实验跟踪与可视化(使用 TensorBoard)
bash
# 启动TensorBoard查看训练过程
tensorboard --logdir=./logs --port=6006
TensorBoard 可可视化的关键指标:
- 训练 / 验证损失与准确率曲线
- 模型计算图结构
- 各层激活值分布
- 权重直方图与梯度分布
- 嵌入向量可视化
3.3.3 超参数优化(使用 Keras Tuner)
python
运行
# 使用Keras Tuner进行超参数搜索
import kerastuner as kt
from tensorflow.keras.applications import ResNet50, MobileNetV2
def build_model(hp):
# 选择基础模型
base_model_choice = hp.Choice(
'base_model',
values=['resnet50', 'mobilenetv2']
)
if base_model_choice == 'resnet50':
base_model = ResNet50(
weights='imagenet',
include_top=False,
input_shape=(224, 224, 3)
)
else:
base_model = MobileNetV2(
weights='imagenet',
include_top=False,
input_shape=(224, 224, 3)
)
base_model.trainable = False
# 构建模型
model = tf.keras.Sequential()
model.add(base_model)
model.add(tf.keras.layers.GlobalAveragePooling2D())
# 可调参数: dense层单元数
hp_units = hp.Int('units', min_value=256, max_value=1024, step=256)
model.add(tf.keras.layers.Dense(units=hp_units, activation='relu'))
# 可调参数: dropout率
hp_dropout = hp.Float('dropout', min_value=0.3, max_value=0.7, step=0.1)
model.add(tf.keras.layers.Dropout(hp_dropout))
model.add(tf.keras.layers.Dense(10, activation='softmax'))
# 可调参数:学习率
hp_learning_rate = hp.Choice('learning_rate', values=[1e-3, 1e-4, 1e-5])
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=hp_learning_rate),
loss='categorical_crossentropy',
metrics=['accuracy']
)
return model
# 初始化调优器
tuner = kt.Hyperband(
build_model,
objective='val_accuracy',
max_epochs=20,
factor=3,
directory='hyperband_logs',
project_name='image_classification'
)
# 搜索最佳超参数
tuner.search(
train_dataset,
epochs=20,
validation_data=val_dataset,
callbacks=[tf.keras.callbacks.EarlyStopping(patience=5)]
)
# 获取最佳模型
best_model = tuner.get_best_models(num_models=1)[0]
# 评估最佳模型
val_loss, val_acc = best_model.evaluate(val_dataset)
print(f"最佳模型验证准确率: {val_acc:.4f}")
# 保存最佳模型
best_model.save('best_tuned_model.h5')
# 输出最佳超参数
best_hps = tuner.get_best_hyperparameters(num_trials=1)[0]
print(f"最佳超参数:")
print(f"基础模型: {best_hps.get('base_model')}")
print(f" dense层单元数: {best_hps.get('units')}")
print(f" dropout率: {best_hps.get('dropout')}")
print(f" 学习率: {best_hps.get('learning_rate')}")
3.4 云平台训练实战(AWS SageMaker)
使用 AWS SageMaker 进行大规模模型训练的流程:
- 准备数据:将数据集上传至 S3 存储桶
bash
# 上传数据到S3
aws s3 cp ./coco_dataset s3://my-ai-dataset/coco/ --recursive
- 定义训练脚本(train.py):
python
运行
import argparse
import os
import tensorflow as tf
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.layers import Dense, GlobalAveragePooling2D, Dropout
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
def parse_args():
parser = argparse.ArgumentParser()
# SageMaker默认参数
parser.add_argument('--model_dir', type=str, default=os.environ.get('SM_MODEL_DIR'))
parser.add_argument('--train', type=str, default=os.environ.get('SM_CHANNEL_TRAIN'))
parser.add_argument('--validation', type=str, default=os.environ.get('SM_CHANNEL_VALIDATION'))
# 超参数
parser.add_argument('--epochs', type=int, default=30)
parser.add_argument('--batch_size', type=int, default=32)
parser.add_argument('--learning_rate', type=float, default=1e-4)
return parser.parse_args()
def load_dataset(data_dir, batch_size):
datagen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255)
return datagen.flow_from_directory(
data_dir,
target_size=(224, 224),
batch_size=batch_size,
class_mode='categorical'
)
def build_model(num_classes):
base_model = ResNet50(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
x = base_model.output
x = GlobalAveragePooling2D()(x)
x = Dense(512, activation='relu')(x)
x = Dropout(0.5)(x)
predictions = Dense(num_classes, activation='softmax')(x)
model = Model(inputs=base_model.input, outputs=predictions)
for layer in base_model.layers:
layer.trainable = False
return model
def main():
args = parse_args()
# 加载数据
train_dataset = load_dataset(args.train, args.batch_size)
val_dataset = load_dataset(args.validation, args.batch_size)
num_classes = len(train_dataset.class_indices)
# 构建模型
model = build_model(num_classes)
model.compile(
optimizer=Adam(learning_rate=args.learning_rate),
loss='categorical_crossentropy',
metrics=['accuracy']
)
# 训练模型
model.fit(
train_dataset,
epochs=args.epochs,
validation_data=val_dataset
)
# 保存模型
model.save(os.path.join(args.model_dir, 'model.h5'))
if __name__ == '__main__':
main()
- 使用 SageMaker SDK 启动训练:
python
运行
import sagemaker
from sagemaker.tensorflow import TensorFlow
# 初始化SageMaker会话
sagemaker_session = sagemaker.Session()
role = sagemaker.get_execution_role()
# 定义训练器
estimator = TensorFlow(
entry_point='train.py',
role=role,
instance_count=1,
instance_type='ml.p3.8xlarge', # 使用GPU实例
framework_version='2.8',
py_version='py37',
hyperparameters={
'epochs': 30,
'batch_size': 32,
'learning_rate': 1e-4
},
output_path='s3://my-ai-models/output/'
)
# 启动训练
estimator.fit({
'train': 's3://my-ai-dataset/coco/train',
'validation': 's3://my-ai-dataset/coco/val'
})
# 部署模型为预测端点
predictor = estimator.deploy(
initial_instance_count=1,
instance_type='ml.t2.medium'
)
- 模型推理与评估:
python
运行
import numpy as np
from PIL import Image
import io
def preprocess_image(image_path):
img = Image.open(image_path).resize((224, 224))
img_array = np.array(img) / 255.0
return np.expand_dims(img_array, axis=0)
# 测试图像预处理
test_image = preprocess_image('test_image.jpg')
# 模型预测
result = predictor.predict(test_image)
predicted_class = np.argmax(result['predictions'][0])
print(f"预测类别: {predicted_class}")
print(f"置信度: {result['predictions'][0][predicted_class]:.4f}")
第四部分:工具链整合与实战案例
4.1 AI 开发全流程工具链整合
将智能编码、数据标注与模型训练工具整合,形成端到端的 AI 开发流程:
graph LR
A[项目需求分析] --> B[数据收集]
B --> C[数据标注]
C -->|使用Label Studio| D[标注数据导出]
D --> E[数据预处理]
E -->|使用GitHub Copilot生成代码| F[特征工程]
F --> G[模型选择与构建]
G -->|使用Copilot辅助编码| H[模型训练]
H -->|使用TensorFlow/SageMaker| I[模型评估]
I -->|不达标| J[数据增强/模型调整]
J --> G
I -->|达标| K[模型部署]
K --> L[模型监控与更新]
L --> M[新数据收集]
M --> C

整合关键点:
- 数据管道:Label Studio 标注结果直接对接训练数据格式
- 代码管理:Copilot 生成的代码纳入版本控制,确保可追溯性
- 实验跟踪:训练参数、数据集版本、模型性能关联记录
- 反馈循环:模型预测错误案例自动回流至标注系统
4.2 实战案例:文本情感分析系统开发
完整展示从数据标注到模型部署的全流程:
4.2.1 数据标注阶段
使用 Label Studio 标注情感分析数据:
xml
<View>
<Text name="text" value="$text"/>
<Choices name="sentiment" toName="text" choice="single" showInLine="true">
<Choice value="Positive" background="green"/>
<Choice value="Negative" background="red"/>
<Choice value="Neutral" background="gray"/>
</Choices>
<TextArea name="explanation" toName="text" placeholder="解释标注原因(可选)"/>
</View>
标注完成后导出 CSV 格式数据,包含 text 和 sentiment 列。
4.2.2 代码生成与模型训练
使用 GitHub Copilot 生成文本分类代码:
Prompt:
python
运行
# 使用PyTorch实现文本情感分析模型
# 步骤:1.加载标注的CSV数据 2.文本预处理(分词、转ID、padding)
# 3.构建LSTM模型 4.训练与评估 5.保存模型
生成代码:
python
运行
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from collections import Counter
import re
import string
# 设置随机种子
SEED = 42
torch.manual_seed(SEED)
np.random.seed(SEED)
# 数据加载
class SentimentDataset(Dataset):
def __init__(self, texts, labels, tokenizer, max_len):
self.texts = texts
self.labels = labels
self.tokenizer = tokenizer
self.max_len = max_len
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
text = str(self.texts[idx])
label = self.labels[idx]
# 文本编码
encoding = self.tokenizer.encode_plus(
text,
add_special_tokens=True,
max_length=self.max_len,
return_token_type_ids=False,
padding='max_length',
truncation=True,
return_attention_mask=True,
return_tensors='pt',
)
return {
'text': text,
'input_ids': encoding['input_ids'].flatten(),
'attention_mask': encoding['attention_mask'].flatten(),
'labels': torch.tensor(label, dtype=torch.long)
}
# 简单分词器实现
class SimpleTokenizer:
def __init__(self, texts, min_freq=2):
self.word2id = {'<PAD>': 0, '<UNK>': 1}
self.id2word = {0: '<PAD>', 1: '<UNK>'}
self.min_freq = min_freq
self.build_vocab(texts)
def build_vocab(self, texts):
word_counts = Counter()
for text in texts:
tokens = self.tokenize(text)
word_counts.update(tokens)
# 添加满足最小频率的词
for word, count in word_counts.items():
if count >= self.min_freq:
self.word2id[word] = len(self.word2id)
self.id2word[len(self.id2word)] = word
def tokenize(self, text):
# 简单文本清洗和分词
text = text.lower()
text = re.sub(f'[{string.punctuation}]', '', text)
return text.split()
def encode_plus(self, text, max_length, add_special_tokens=True,
return_token_type_ids=False, padding='max_length',
truncation=True, return_attention_mask=True, return_tensors='pt'):
tokens = self.tokenize(text)
if add_special_tokens:
tokens = ['<CLS>'] + tokens + ['<SEP>']
# 截断
if truncation and len(tokens) > max_length:
tokens = tokens[:max_length]
# 转换为ID
input_ids = [self.word2id.get(token, self.word2id['<UNK>']) for token in tokens]
# 填充
if padding == 'max_length' and len(input_ids) < max_length:
input_ids += [self.word2id['<PAD>']] * (max_length - len(input_ids))
# 注意力掩码
attention_mask = [1 if id != self.word2id['<PAD>'] else 0 for id in input_ids]
result = {'input_ids': np.array(input_ids)}
if return_attention_mask:
result['attention_mask'] = np.array(attention_mask)
if return_tensors == 'pt':
for key in result:
result[key] = torch.tensor(result[key], dtype=torch.long)
return result
# LSTM模型
class SentimentLSTM(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim, n_layers,
bidirectional, dropout, pad_idx):
super().__init__()
self.embedding = nn.Embedding(
vocab_size,
embedding_dim,
padding_idx=pad_idx
)
self.lstm = nn.LSTM(
embedding_dim,
hidden_dim,
num_layers=n_layers,
bidirectional=bidirectional,
dropout=dropout if n_layers > 1 else 0,
batch_first=True
)
self.fc = nn.Linear(hidden_dim * 2 if bidirectional else hidden_dim, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, text, attention_mask=None):
# text shape: [batch_size, seq_len]
embedded = self.dropout(self.embedding(text)) # [batch_size, seq_len, emb_dim]
# LSTM输出
lstm_out, _ = self.lstm(embedded) # [batch_size, seq_len, hid_dim * num_dirs]
# 取最后一个时间步的输出
if self.lstm.bidirectional:
# 双向LSTM取最后一个前向和第一个后向输出拼接
last_forward = lstm_out[:, -1, :self.lstm.hidden_size]
last_backward = lstm_out[:, 0, self.lstm.hidden_size:]
hidden = self.dropout(torch.cat((last_forward, last_backward), dim=1))
else:
hidden = self.dropout(lstm_out[:, -1, :]) # [batch_size, hid_dim]
return self.fc(hidden) # [batch_size, output_dim]
# 训练函数
def train_model(model, train_loader, val_loader, criterion, optimizer, device, epochs=10):
best_val_acc = 0.0
for epoch in range(epochs):
model.train()
train_loss = 0.0
train_correct = 0
for batch in train_loader:
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
optimizer.zero_grad()
outputs = model(input_ids, attention_mask)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item() * input_ids.size(0)
_, predicted = torch.max(outputs.data, 1)
train_correct += (predicted == labels).sum().item()
# 计算训练集指标
train_loss = train_loss / len(train_loader.dataset)
train_acc = train_correct / len(train_loader.dataset)
# 验证
model.eval()
val_loss = 0.0
val_correct = 0
all_preds = []
all_labels = []
with torch.no_grad():
for batch in val_loader:
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
outputs = model(input_ids, attention_mask)
loss = criterion(outputs, labels)
val_loss += loss.item() * input_ids.size(0)
_, predicted = torch.max(outputs.data, 1)
val_correct += (predicted == labels).sum().item()
all_preds.extend(predicted.cpu().numpy())
all_labels.extend(labels.cpu().numpy())
val_loss = val_loss / len(val_loader.dataset)
val_acc = val_correct / len(val_loader.dataset)
print(f'Epoch {epoch+1}/{epochs}')
print(f'Train Loss: {train_loss:.4f} | Train Acc: {train_acc:.4f}')
print(f'Val Loss: {val_loss:.4f} | Val Acc: {val_acc:.4f}\n')
# 保存最佳模型
if val_acc > best_val_acc:
best_val_acc = val_acc
torch.save(model.state_dict(), 'best_sentiment_model.pt')
print(f'Saved best model with Val Acc: {best_val_acc:.4f}')
# 输出验证集详细报告
print("Validation Set Classification Report:")
print(classification_report(all_labels, all_preds))
return model
# 主函数
def main():
# 加载数据
df = pd.read_csv('sentiment_annotations.csv')
print(f"数据集大小: {len(df)}")
print(df['sentiment'].value_counts())
# 标签映射
label_map = {'Negative': 0, 'Neutral': 1, 'Positive': 2}
df['label'] = df['sentiment'].map(label_map)
# 划分训练集和验证集
train_texts, val_texts, train_labels, val_labels = train_test_split(
df['text'].tolist(),
df['label'].tolist(),
test_size=0.2,
random_state=SEED,
stratify=df['label']
)
# 初始化分词器
tokenizer = SimpleTokenizer(train_texts)
print(f"词汇表大小: {len(tokenizer.word2id)}")
# 超参数
MAX_LEN = 128
BATCH_SIZE = 32
EMBEDDING_DIM = 100
HIDDEN_DIM = 256
OUTPUT_DIM = 3 # 3种情感
N_LAYERS = 2
BIDIRECTIONAL = True
DROPOUT = 0.5
LEARNING_RATE = 1e-3
EPOCHS = 10
# 创建数据集和数据加载器
train_dataset = SentimentDataset(train_texts, train_labels, tokenizer, MAX_LEN)
val_dataset = SentimentDataset(val_texts, val_labels, tokenizer, MAX_LEN)
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=BATCH_SIZE)
# 设备配置
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"使用设备: {device}")
# 初始化模型
model = SentimentLSTM(
vocab_size=len(tokenizer.word2id),
embedding_dim=EMBEDDING_DIM,
hidden_dim=HIDDEN_DIM,
output_dim=OUTPUT_DIM,
n_layers=N_LAYERS,
bidirectional=BIDIRECTIONAL,
dropout=DROPOUT,
pad_idx=tokenizer.word2id['<PAD>']
).to(device)
# 损失函数和优化器
criterion = nn.CrossEntropyLoss().to(device)
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE)
# 训练模型
model = train_model(model, train_loader, val_loader, criterion, optimizer, device, EPOCHS)
# 保存分词器(实际应用中需要更完善的保存方式)
import pickle
with open('tokenizer.pkl', 'wb') as f:
pickle.dump(tokenizer, f)
if __name__ == '__main__':
main()
4.2.3 模型部署与监控
使用 Flask 部署模型为 API 服务:
python
运行
from flask import Flask, request, jsonify
import torch
import pickle
import re
import string
import numpy as np
app = Flask(__name__)
# 加载模型和分词器
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 定义模型结构(与训练时一致)
class SentimentLSTM(torch.nn.Module):
# 模型结构定义(同上)
pass
# 加载模型
model = SentimentLSTM(
vocab_size=5000, # 实际应与训练时一致
embedding_dim=100,
hidden_dim=256,
output_dim=3,
n_layers=2,
bidirectional=True,
dropout=0.5,
pad_idx=0
).to(device)
model.load_state_dict(torch.load('best_sentiment_model.pt', map_location=device))
model.eval()
# 加载分词器
with open('tokenizer.pkl', 'rb') as f:
tokenizer = pickle.load(f)
# 情感标签映射
label_map = {0: 'Negative', 1: 'Neutral', 2: 'Positive'}
@app.route('/predict', methods=['POST'])
def predict():
data = request.json
if 'text' not in data:
return jsonify({'error': 'Missing text parameter'}), 400
text = data['text']
# 文本预处理和编码
encoding = tokenizer.encode_plus(
text,
add_special_tokens=True,
max_length=128,
return_token_type_ids=False,
padding='max_length',
truncation=True,
return_attention_mask=True,
return_tensors='pt'
)
input_ids = encoding['input_ids'].to(device)
attention_mask = encoding['attention_mask'].to(device)
# 模型预测
with torch.no_grad():
outputs = model(input_ids, attention_mask)
probabilities = torch.softmax(outputs, dim=1).cpu().numpy()[0]
predicted_label = np.argmax(probabilities)
# 返回结果
return jsonify({
'text': text,
'sentiment': label_map[predicted_label],
'confidence': float(probabilities[predicted_label]),
'probabilities': {
'Negative': float(probabilities[0]),
'Neutral': float(probabilities[1]),
'Positive': float(probabilities[2])
}
})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
结论与展望
AI 开发工具链正朝着集成化、自动化、云原生方向快速演进。智能编码工具持续提升开发效率,数据标注工具通过人机协同降低标注成本,模型训练平台则通过分布式计算和自动化技术加速模型迭代。
未来,三类工具将进一步深度融合:编码工具将直接集成标注和训练能力,标注工具将内置更多 AI 辅助功能,训练平台则会提供更简化的端到端工作流。开发者需要持续关注工具生态的发展,掌握跨工具链的整合能力,才能在 AI 开发中保持竞争力。
通过本文介绍的工具链和实战方法,开发者可以显著提升 AI 项目的开发效率和质量,从繁琐的重复性工作中解放出来,更专注于核心业务逻辑和算法创新,推动 AI 技术在各行业的落地应用。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 13
13 0
0- 0



 已为社区贡献88条内容
已为社区贡献88条内容

所有评论(0)