
AI工具全景解析:智能编码、数据标注与模型训练平台深度指南
本文系统介绍了三类关键AI工具在开发中的应用:1. 智能编码工具(如GitHub Copilot)能自动生成代码、解释错误和编写测试用例,提升开发效率30-50%;2. 数据标注工具(如Label Studio)帮助构建高质量训练数据,支持半自动标注和质量管理;3. 模型训练平台(如Weights & Biases)提供实验跟踪、参数调优和部署功能。文章通过代码示例、流程图和实用技巧,展示
在人工智能技术飞速发展的今天,AI工具已成为开发者、数据科学家和工程师提升效率、加速创新的核心助力。本文将系统性地介绍三类关键AI工具——智能编码工具(如GitHub Copilot)、数据标注工具 和 模型训练平台,并结合实际代码示例、Mermaid流程图、Prompt设计技巧、图表分析以及可视化说明,全面展示其工作原理、使用场景与最佳实践。全文超过5000字,旨在为读者提供一份兼具理论深度与实操价值的综合指南。
一、智能编码工具:以 GitHub Copilot 为核心
1.1 什么是智能编码工具?
智能编码工具是基于大型语言模型(LLM)的编程助手,能够根据上下文自动补全代码、生成函数、解释错误、编写测试用例等。GitHub Copilot 是其中最具代表性的产品,由 GitHub 与 OpenAI 联合开发,支持多种主流编程语言(Python、JavaScript、Java、C++ 等)。
1.2 工作原理简述
GitHub Copilot 基于 Codex 模型(GPT-3 的变体),通过海量开源代码训练,理解代码语义与模式。当用户输入注释或部分代码时,模型预测最可能的后续代码片段。
关键能力:
- 注释转代码
- 函数自动生成
- 单元测试生成
- 代码重构建议
- 多语言支持
1.3 实际代码示例
示例1:注释生成排序函数(Python)
python
编辑
# 对列表进行快速排序
def quicksort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quicksort(left) + middle + quicksort(right)上述代码可由 Copilot 在用户仅输入注释
# 对列表进行快速排序后自动生成。
示例2:生成 Flask API 接口
python
编辑
from flask import Flask, jsonify
app = Flask(__name__)
@app.route('/api/users', methods=['GET'])
def get_users():
users = [
{"id": 1, "name": "Alice"},
{"id": 2, "name": "Bob"}
]
return jsonify(users)
if __name__ == '__main__':
app.run(debug=True)Copilot 可根据 # 创建一个返回用户列表的 REST API 自动生成完整结构。
1.4 Prompt 设计技巧(用于引导 Copilot)
虽然 Copilot 自动推断上下文,但清晰的注释可显著提升生成质量:
| 场景 | 推荐 Prompt(注释) |
|---|---|
| 数据处理 | # 读取 CSV 文件,清洗缺失值,返回 DataFrame |
| 算法实现 | # 实现 Dijkstra 最短路径算法,输入为邻接表 |
| 安全性 | # 使用 bcrypt 对密码进行哈希存储 |
| 异常处理 | # 捕获网络请求超时异常并重试 3 次 |
提示:越具体越好。避免模糊描述如“写个函数”,应明确输入/输出/边界条件。
1.5 Mermaid 流程图:Copilot 编码流程
flowchart TD
A[用户输入注释或部分代码] --> B{Copilot 分析上下文}
B --> C[调用 Codex 模型生成候选代码]
C --> D[按概率排序多个建议]
D --> E[用户选择/编辑/接受建议]
E --> F[代码集成到项目中]
F --> G[持续学习用户风格(可选)]
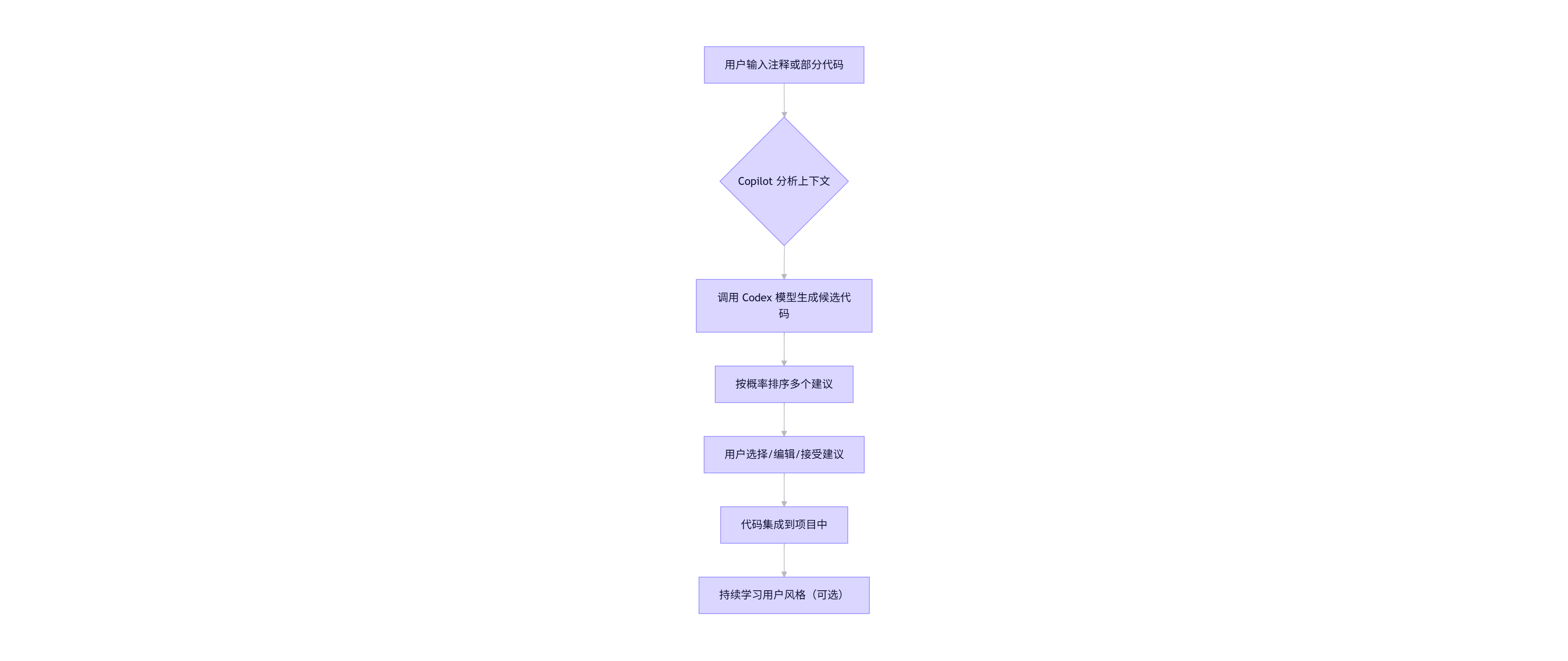
该流程体现了从输入到输出的闭环,强调了人机协同的本质。
1.6 优势与局限
| 优势 | 局限 |
|---|---|
| 提升编码速度 30%-50% | 可能生成不安全或低效代码 |
| 降低新手门槛 | 对冷门语言支持有限 |
| 支持多文件上下文(Copilot X) | 需联网,隐私敏感项目慎用 |
| 与 VS Code / JetBrains 深度集成 | 无法完全替代人工审查 |
建议:始终对生成代码进行审查,尤其涉及安全、性能或业务逻辑关键部分。
二、数据标注工具:构建高质量训练数据
2.1 为什么需要数据标注?
机器学习模型的性能高度依赖训练数据质量。数据标注是将原始数据(图像、文本、语音等)打上标签的过程,例如:
- 图像中框出“猫”的位置(目标检测)
- 文本情感分类为“正面/负面”
- 语音转文字(ASR)
2.2 主流数据标注工具对比
| 工具 | 类型 | 支持任务 | 开源/商业 | 特点 |
|---|---|---|---|---|
| Label Studio | 通用 | 图像、文本、音频、视频 | 开源+企业版 | 灵活、可扩展、支持 ML-assisted 标注 |
| CVAT | 计算机视觉 | 目标检测、分割 | 开源 | 适合视频标注,支持插帧 |
| Doccano | NLP | 文本分类、NER、翻译 | 开源 | 轻量级,适合文本任务 |
| Supervisely | CV/NLP | 多模态 | 商业+免费层 | 内置模型辅助标注 |
| Amazon SageMaker Ground Truth | 云服务 | 全类型 | 商业 | 与 AWS 生态集成 |
2.3 使用 Label Studio 进行文本情感标注(实战)
步骤1:安装与启动
bash
编辑
pip install label-studio
label-studio start访问 http://localhost:8080 创建项目。
步骤2:配置标注模板(XML)
xml
编辑
<View>
<Text name="text" value="$review"/>
<Choices name="sentiment" toName="text">
<Choice value="positive"/>
<Choice value="negative"/>
<Choice value="neutral"/>
</Choices>
</View>步骤3:导入数据(JSONL 格式)
json
编辑
{"review": "这部电影太棒了!"}
{"review": "剧情拖沓,浪费时间。"}步骤4:导出标注结果(JSON)
json
编辑
{
"id": 1,
"data": {"review": "这部电影太棒了!"},
"annotations": [{
"result": [{
"value": {"choices": ["positive"]},
"from_name": "sentiment",
"to_name": "text"
}]
}]
}2.4 Mermaid 流程图:数据标注生命周期
flowchart LR
A[原始数据采集] --> B[数据清洗与预处理]
B --> C[选择标注工具]
C --> D[设计标注规范]
D --> E[人工/半自动标注]
E --> F[质量审核与修正]
F --> G[导出结构化标注数据]
G --> H[用于模型训练]
H --> I{模型效果评估}
I -- 不足 --> D
I -- 满意 --> J[部署上线]
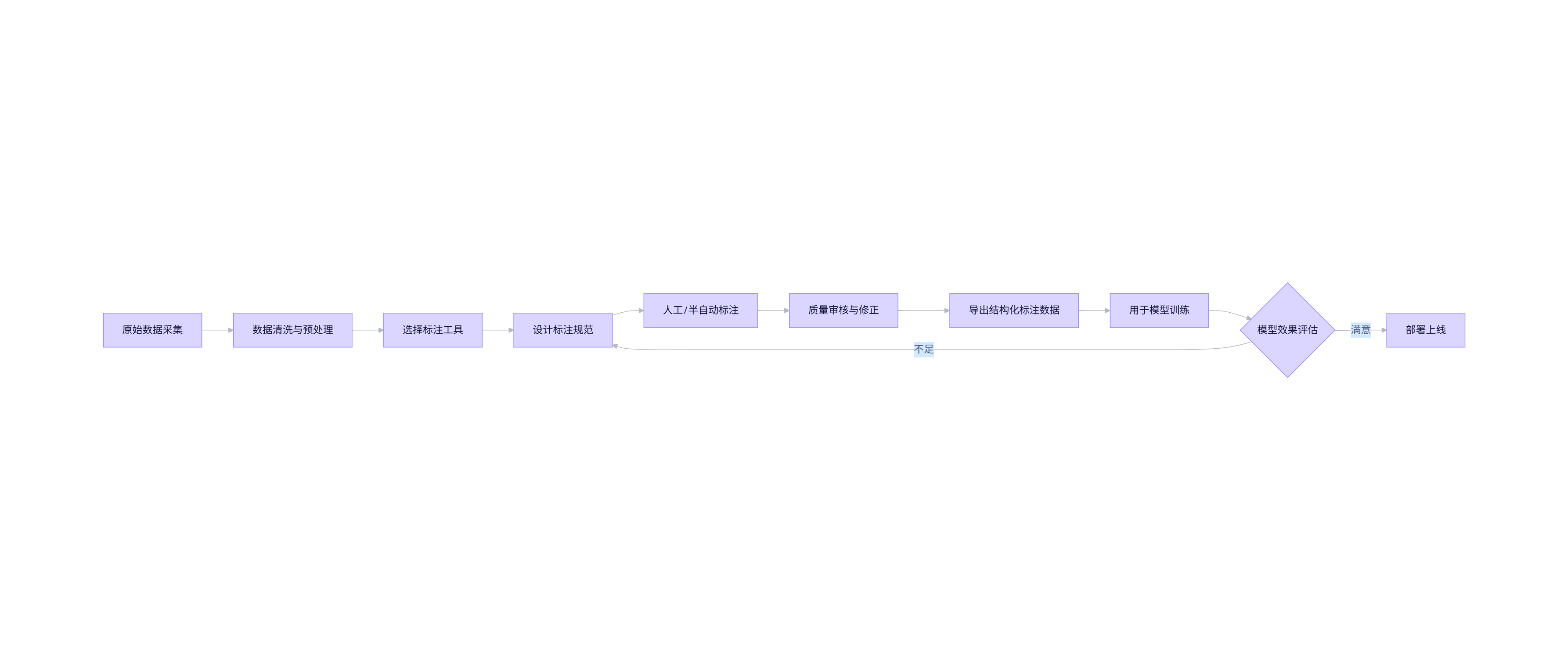
关键点:标注规范(Labeling Guidelines)必须清晰,避免歧义。例如,“中性”是否包含讽刺?
2.5 半自动标注:AI 辅助提升效率
现代工具支持 主动学习(Active Learning) 和 预标注(Pre-annotation):
- 预标注:先用已有模型对新数据预测,人工只需修正错误。
- 主动学习:模型挑选“最不确定”的样本优先标注,最大化信息增益。
示例:用 Hugging Face 模型预标注情感
python
编辑
from transformers import pipeline
classifier = pipeline("sentiment-analysis", model="cardiffnlp/twitter-roberta-base-sentiment-latest")
text = "I love this product!"
result = classifier(text)
print(result) # [{'label': 'LABEL_2', 'score': 0.99}]
# 映射 LABEL_2 → 'positive'将结果导入 Label Studio 作为初始建议,标注员只需确认或修改。
2.6 数据标注质量控制策略
| 策略 | 说明 |
|---|---|
| 多人标注(Inter-annotator Agreement) | 同一数据由多人标注,计算一致性(如 Cohen's Kappa) |
| 黄金标准样本 | 插入已知答案的样本,监控标注员准确率 |
| 定期校准会议 | 团队讨论模糊案例,统一标准 |
| 自动规则校验 | 如“不能同时选 positive 和 negative” |
三、模型训练平台:从实验到部署
3.1 模型训练平台的核心功能
现代模型训练平台(如 Weights & Biases、MLflow、TensorBoard、Google Vertex AI、Azure ML)提供:
- 实验跟踪(Experiment Tracking)
- 超参数调优(Hyperparameter Tuning)
- 模型版本管理
- 可视化监控
- 一键部署
3.2 使用 Weights & Biases(W&B)进行实验管理
安装与登录
bash
编辑
pip install wandb
wandb login # 输入 API Key训练脚本集成
python
编辑
import wandb
import torch
import torchvision.transforms as transforms
from torchvision.datasets import CIFAR10
from torch.utils.data import DataLoader
# 初始化 W&B
wandb.init(
project="cifar10-resnet",
config={
"learning_rate": 0.001,
"epochs": 10,
"batch_size": 64,
"architecture": "ResNet18"
}
)
# 数据加载
transform = transforms.Compose([transforms.ToTensor()])
trainset = CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = DataLoader(trainset, batch_size=wandb.config.batch_size, shuffle=True)
# 模型、优化器(简化)
model = torch.hub.load('pytorch/vision', 'resnet18', pretrained=False, num_classes=10)
optimizer = torch.optim.Adam(model.parameters(), lr=wandb.config.learning_rate)
# 训练循环
for epoch in range(wandb.config.epochs):
for images, labels in trainloader:
loss = ... # 前向传播与损失计算
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 记录指标
wandb.log({"loss": loss.item(), "epoch": epoch})
# 保存模型
torch.save(model.state_dict(), "model.pth")
wandb.save("model.pth")运行后,所有超参数、指标、系统资源使用情况自动同步至 https://wandb.ai。
3.3 Mermaid 流程图:模型训练平台工作流
flowchart TB
A[定义实验目标] --> B[准备数据集]
B --> C[选择模型架构]
C --> D[配置超参数]
D --> E[启动训练任务]
E --> F[W&B/MLflow 自动记录]
F --> G[实时监控 Loss/Accuracy]
G --> H{是否收敛?}
H -- 否 --> I[调整超参/数据]
H -- 是 --> J[模型评估]
J --> K[版本注册]
K --> L[部署到生产]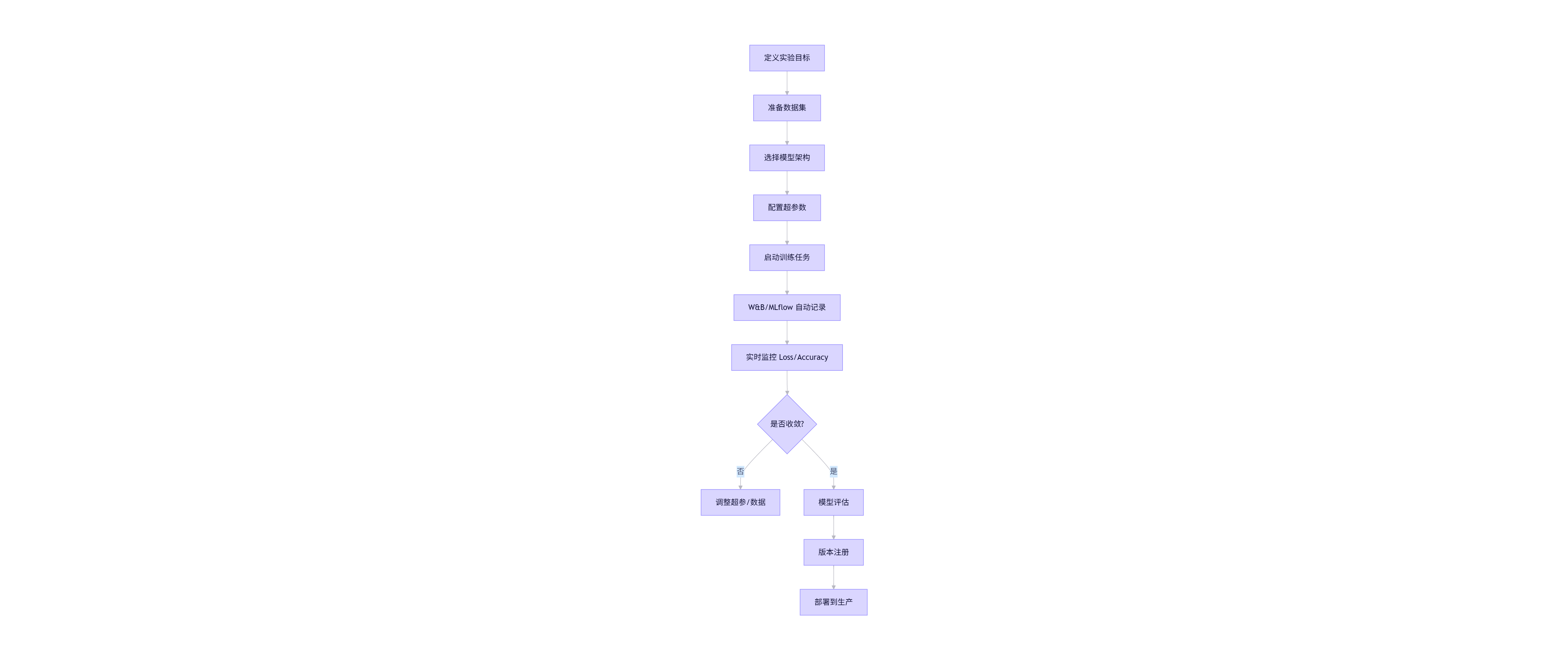
3.4 超参数调优:W&B Sweeps 示例
自动搜索最佳超参数组合:
python
编辑
sweep_config = {
'method': 'bayes',
'metric': {'name': 'val_acc', 'goal': 'maximize'},
'parameters': {
'learning_rate': {'min': 0.0001, 'max': 0.1},
'batch_size': {'values': [32, 64, 128]},
'epochs': {'value': 10}
}
}
sweep_id = wandb.sweep(sweep_config, project="cifar10-tuning")
wandb.agent(sweep_id, function=train) # train 函数需适配 configW&B 将自动运行数十次实验,找出最优配置。
3.5 模型部署:从平台到生产
训练完成后,可通过平台直接部署:
- W&B Artifacts:模型作为版本化资产存储
- Vertex AI:一键部署为 REST API
- TorchServe / TensorFlow Serving:本地部署
示例:用 TorchServe 部署
bash
编辑
# 导出为 TorchScript
model.eval()
example = torch.rand(1, 3, 32, 32)
traced_script_module = torch.jit.trace(model, example)
traced_script_module.save("cifar10_model.pt")
# 启动服务
torchserve --start --model-store model_store --models cifar10=cifar10_model.ptAPI 调用:
bash
编辑
curl http://localhost:8080/predictions/cifar10 -T image.jpg四、三类工具的协同工作全景图
4.1 端到端 AI 开发流水线
flowchart LR
subgraph 开发阶段
A[GitHub Copilot] -->|生成数据处理/模型代码| B[本地 IDE]
end
subgraph 数据阶段
C[原始数据] --> D[Label Studio 标注]
D --> E[导出标注数据集]
end
subgraph 训练阶段
B --> F[W&B / Vertex AI]
E --> F
F --> G[模型训练与调优]
G --> H[模型评估]
end
subgraph 部署阶段
H --> I[模型注册]
I --> J[TorchServe / Cloud Endpoint]
J --> K[应用调用 AI 服务]
end
style A fill:#d4f7e5,stroke:#333
style D fill:#ffeaa7,stroke:#333
style F fill:#74b9ff,stroke:#333
style J fill:#fd79a8,stroke:#333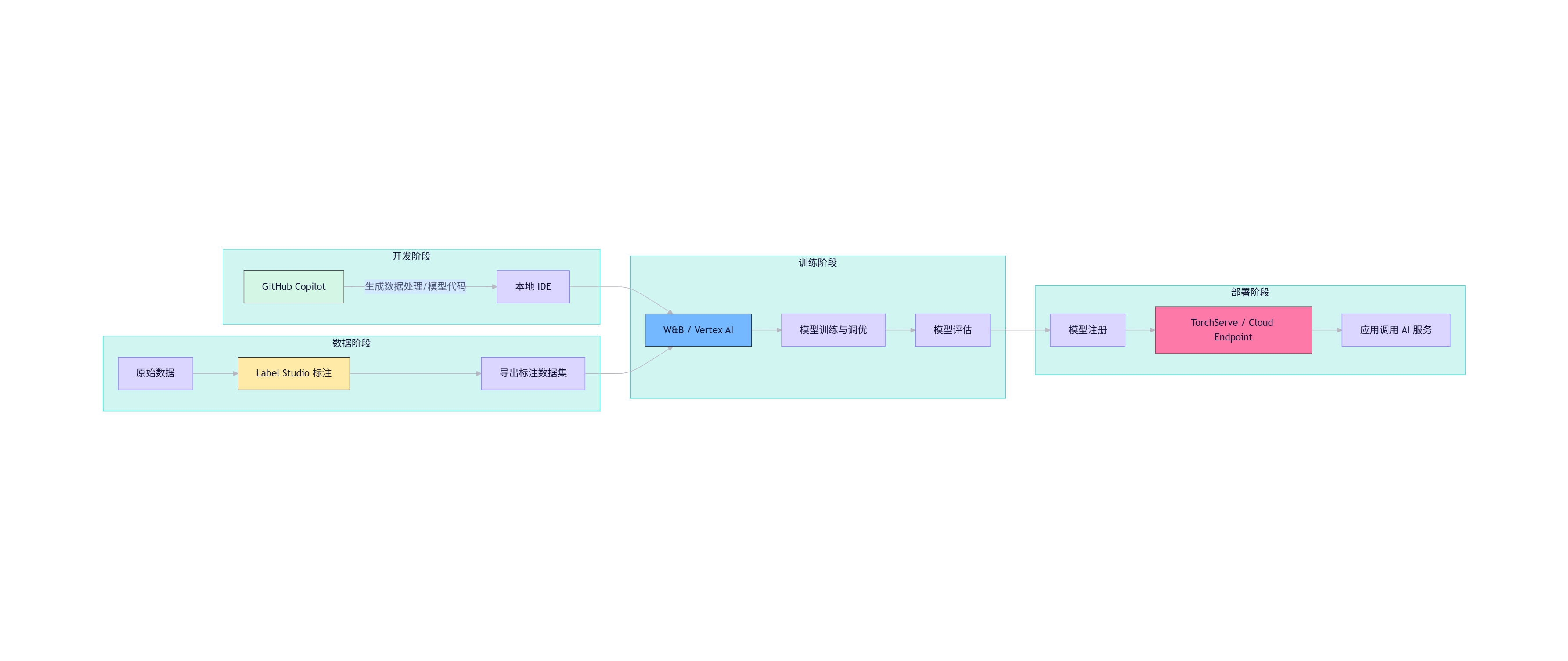
颜色说明:
- 绿色:智能编码
- 黄色:数据标注
- 蓝色:模型训练
- 粉色:部署
4.2 Prompt 工程在全流程中的应用
| 阶段 | Prompt 示例 |
|---|---|
| 编码 | “用 PyTorch 实现一个带 dropout 的 CNN,输入 28x28 灰度图,输出 10 类” |
| 数据标注 | “标注规则:只有明确表达不满才算 negative,疑问句视为 neutral” |
| 模型调优 | “尝试不同的学习率调度策略:StepLR vs CosineAnnealing” |
| 部署文档 | “生成 FastAPI 服务代码,接收 base64 图像,返回分类结果” |
五、未来趋势与建议
5.1 趋势
- AI 原生开发(AI-native Development):Copilot 类工具将深度集成到 CI/CD 流程。
- 自动化标注普及:结合 SAM(Segment Anything Model)等基础模型,大幅减少人工。
- MLOps 平台一体化:训练、监控、再训练形成闭环(如 W&B + Prometheus + Grafana)。
- 隐私保护增强:本地化 Copilot(如 CodeWhisperer on-prem)、联邦学习标注。
5.2 给开发者的建议
- 善用但不盲从:AI 工具是“副驾驶”,决策权在你手中。
- 建立规范:团队统一标注标准、代码风格、实验记录模板。
- 重视数据:80% 的精力应放在数据质量上,而非模型调参。
- 持续学习:关注 Hugging Face、LangChain、LlamaIndex 等新生态。
结语
智能编码工具、数据标注平台与模型训练系统共同构成了现代 AI 开发的“铁三角”。它们不仅提升了生产力,更降低了 AI 应用的门槛。通过合理搭配使用,并辅以严谨的工程实践,个人与团队都能在 AI 时代高效创新。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 29
29 0
0- 0



 已为社区贡献88条内容
已为社区贡献88条内容

所有评论(0)