
从基础到实战——仓颉标准库常用模块详解
引言:标准库——开发者的得力助手
嘿,各位技术探索者们!欢迎回到我们的仓颉语言深度解析系列。今天,我们将把目光投向一个至关重要的领域——仓颉语言的标准库。
标准库就像是编程语言的“工具箱”,里面装满了各种精心打造的工具,从基本的数据结构到复杂的并发原语,应有尽有。它不仅为我们提供了开箱即用的功能,更是体现了语言的设计哲学和最佳实践。一个强大而易用的标准库,能够极大地提升开发效率,帮助我们构建出更稳定、更高效的应用程序。
在仓颉语言中,我们设想其标准库将秉承“安全、性能、表达力”的核心理念,提供一套现代化、高性能且类型安全的API。我们将深入探索其模块化结构,学习如何使用各种核心组件,理解其独特的错误处理机制,并一窥其在异步并发领域的强大能力。我们甚至会尝试从“源码”层面,去理解这些库是如何实现零成本抽象和安全保障的。
最后,我们还将通过一个实战项目——开发一个简单的配置解析器,来亲身体验仓颉标准库的强大功能和优雅设计。
理解仓颉语言的标准库,是掌握这门语言,并用它来构建实际应用的关键一步。
让我们一起,驾驭仓颉标准库,成为更高效的开发者!
一、标准库结构概览与模块导入规则
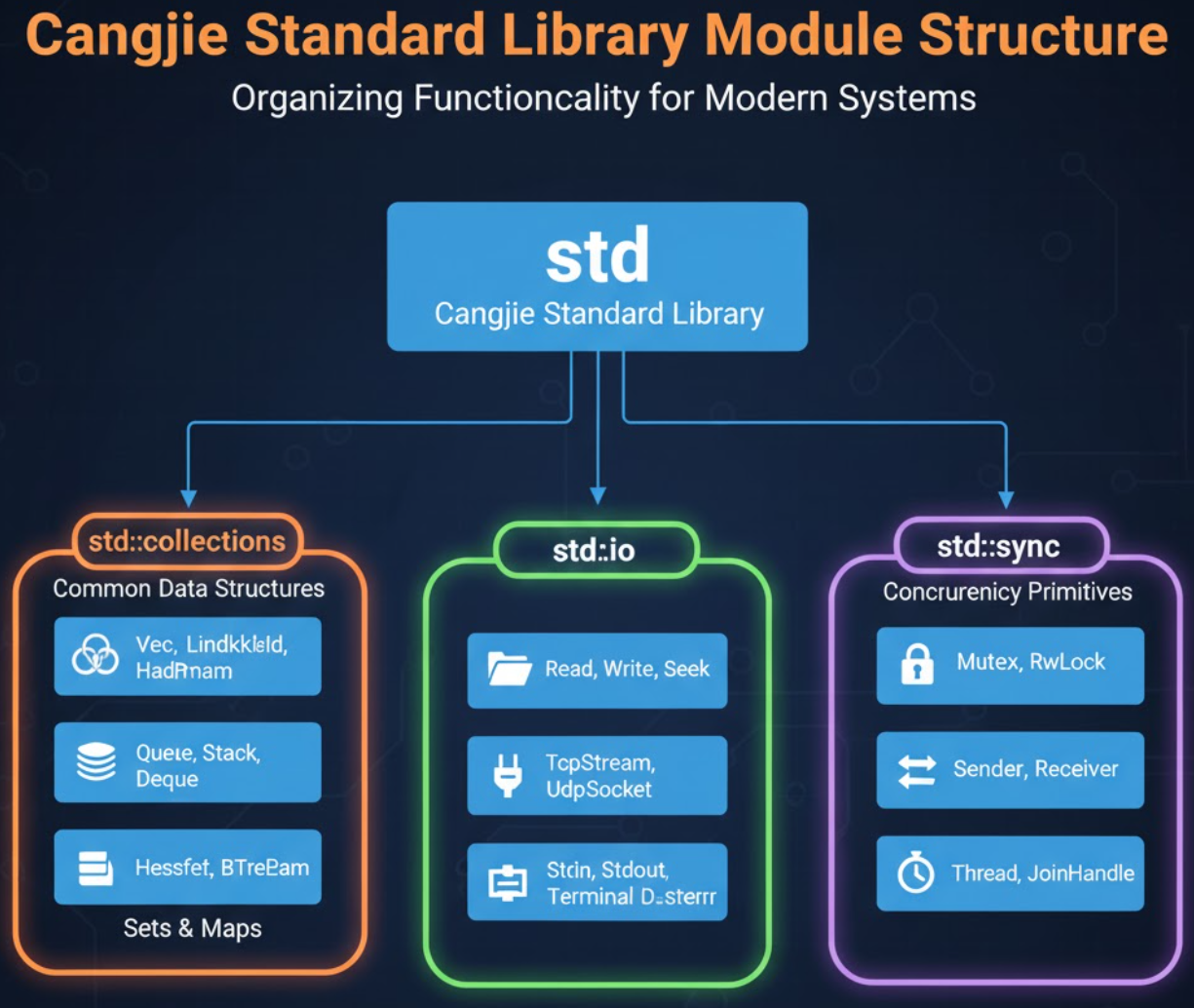
仓颉语言的标准库被设计为高度模块化,以便于组织、管理和使用。
1.1 仓颉标准库的模块化组织
仓颉标准库(通常命名为 std)将采用类似文件系统目录的层次结构进行组织。每个模块都专注于特定的功能领域。
设想的 std 模块结构:
std::collections:各种数据结构(VArray,HashMap,HashSet,LinkedList等)。std::string:字符串类型和操作。std::io:输入输出操作(文件、网络、标准IO)。std::fs:文件系统操作。std::net:网络编程(TCP, UDP)。std::time:时间与日期处理。std::sync:并发同步原语(Mutex,RwLock,Channel等)。std::thread:线程管理。std::async:异步编程支持(Future,Executor等)。std::math:数学函数与常量。std::rand:随机数生成。std::error:错误处理相关的接口和类型。std::mem:内存操作(swap,size_of等)。std::env:环境变量与程序参数。
这种清晰的模块划分使得开发者可以按需导入所需功能,避免不必要的代码膨胀。
1.2 use关键字与模块导入
仓颉语言使用 use 关键字来导入模块、类型、函数或宏,使其在当前作用域内可用。
// 导入整个模块
use std::collections;
// 导入模块中的特定类型
use std::io::File;
use std::io::{BufReader, Write}; // 导入多个项
// 导入模块中的所有公开项 (不推荐,可能导致命名冲突)
// use std::collections::*;
// 导入并重命名
use std::collections::HashMap as Map;
fn main() {
let mut my_vec = collections::VArray::new(); // 使用完整路径
my_vec.push(1);
let mut file = File::create("output.txt").expect("Failed to create file");
file.write_all(b"Hello").expect("Failed to write");
let mut my_map = Map::new(); // 使用重命名后的 Map
my_map.insert("key", "value");
}
1.3 路径解析与可见性
- 绝对路径: 从 crate 根(
crate::)或标准库根(std::)开始的路径。 - 相对路径: 从当前模块开始的路径。
super: 指代父模块。self: 指代当前模块。
可见性规则(pub, priv)在标准库中同样适用,确保了模块的封装性。只有被标记为 pub 的项才能被外部模块导入和使用。
mod my_app {
pub mod utils {
pub fn helper_function() {
println!("Helper called.");
}
}
mod internal {
fn internal_logic() {
println!("Internal logic.");
}
}
pub fn run_app() {
use crate::my_app::utils; // 绝对路径导入
utils::helper_function();
// use super::internal; // 相对路径导入父模块的子模块
// internal::internal_logic(); // 编译错误:internal_logic 是私有的
}
}
fn main() {
my_app::run_app();
}
二、核心库(集合、字符串、IO、数学)使用实例
仓颉标准库提供了丰富而高效的核心功能,是日常开发的基础。
2.1 std::collections:高效数据结构
仓颉的集合库将提供多种经过优化、类型安全的数据结构。
2.1.1 VArray<T>:动态数组
VArray<T> 是一个可增长的、堆分配的同类型元素列表,类似于C++的std::vector或Rust的Vec。
use std::collections::VArray;
fn main() {
let mut numbers: VArray<i32> = VArray::new();
numbers.push(10);
numbers.push(20);
numbers.push(30);
println!("VArray: {:?}", numbers); // 输出 [10, 20, 30]
println!("Length: {}", numbers.len()); // 输出 3
if let Some(last) = numbers.pop() {
println!("Popped: {}", last); // 输出 30
}
println!("Element at index 0: {}", numbers[0]); // 访问元素
numbers[0] = 15; // 修改元素
println!("Modified VArray: {:?}", numbers); // 输出 [15, 20]
for num in numbers.iter() { // 迭代器
print!("{} ", num);
}
println!();
}
2.1.2 HashMap<K, V>:键值对存储
HashMap<K, V> 提供高效的键值对存储和查找,键类型 K 必须实现 Hash 和 Eq 接口。
use std::collections::HashMap;
fn main() {
let mut scores: HashMap<String, i32> = HashMap::new();
scores.insert("Alice".to_string(), 95);
scores.insert("Bob".to_string(), 88);
scores.insert("Charlie".to_string(), 95);
println!("Scores: {:?}", scores);
if let Some(score) = scores.get(&"Alice".to_string()) {
println!("Alice's score: {}", score); // 输出 95
}
scores.remove(&"Bob".to_string());
println!("Scores after Bob removed: {:?}", scores);
for (name, score) in scores.iter() { // 迭代键值对
println!("{}: {}", name, score);
}
}
2.1.3 HashSet<T>:唯一元素集合
HashSet<T> 存储唯一元素,元素类型 T 必须实现 Hash 和 Eq 接口。
use std::collections::HashSet;
fn main() {
let mut unique_numbers: HashSet<i32> = HashSet::new();
unique_numbers.insert(1);
unique_numbers.insert(2);
unique_numbers.insert(1); // 重复插入无效
println!("Unique numbers: {:?}", unique_numbers); // 输出 {1, 2} (顺序不确定)
if unique_numbers.contains(&2) {
println!("Set contains 2.");
}
unique_numbers.remove(&1);
println!("Set after removing 1: {:?}", unique_numbers); // 输出 {2}
}
2.2 std::string:字符串处理
仓颉的字符串处理将区分拥有所有权的 String 和不可变的字符串切片 &str。
2.2.1 String与&str:所有权与切片
String:堆分配,可变,拥有数据。&str:不可变引用,指向UTF-8编码的字符串数据。
use std::string::String;
fn print_slice(s: &str) {
println!("Slice: {}", s);
}
fn main() {
let mut s1: String = "Hello".to_string(); // 创建 String
s1.push_str(", Cangjie!"); // 修改 String
println!("Owned String: {}", s1); // 输出 Hello, Cangjie!
let s_slice: &str = &s1; // 从 String 创建 &str
print_slice(s_slice);
let literal_slice: &str = "Literal String"; // 字符串字面量是 &str
print_slice(literal_slice);
let part_slice: &str = &s1[0..5]; // 切片操作
println!("Part slice: {}", part_slice); // 输出 Hello
}
2.2.2 常用字符串操作
String和&str都提供丰富的操作方法,如拼接、查找、替换、分割、大小写转换等。
use std::string::String;
fn main() {
let text = " Hello, World! ".to_string();
println!("Trimmed: '{}'", text.trim()); // 去除首尾空白
println!("Starts with ' ': {}", text.starts_with(" ")); // true
println!("Contains 'World': {}", text.contains("World")); // true
let parts: VArray<&str> = text.trim().split(',').collect();
println!("Parts: {:?}", parts); // 输出 ["Hello", " World!"]
let replaced = text.replace("World", "Cangjie");
println!("Replaced: {}", replaced); // 输出 Hello, Cangjie!
}
2.3 std::io:输入输出操作
std::io 模块提供了文件、网络和标准输入输出的抽象。
2.3.1 File:文件读写
File 类型用于创建、打开、读取和写入文件。
use std::io::{File, Read, Write};
use std::string::String;
fn main() {
let file_name = "example.txt";
// 写入文件
let mut file = File::create(file_name).expect("Failed to create file");
file.write_all(b"Line 1\nLine 2").expect("Failed to write to file");
println!("File written.");
// 读取文件
let mut file = File::open(file_name).expect("Failed to open file");
let mut contents = String::new();
file.read_to_string(&mut contents).expect("Failed to read file");
println!("File contents:\n{}", contents); // 输出 Line 1\nLine 2
}
2.3.2 BufReader与BufWriter:缓冲IO
缓冲IO可以提高读写效率,尤其是在处理大量小块数据时。
use std::io::{File, BufReader, BufWriter, Read, Write};
use std::string::String;
fn main() {
let file_name = "buffered_example.txt";
// 使用 BufWriter 写入
let file = File::create(file_name).expect("Failed to create file");
let mut writer = BufWriter::new(file);
writer.write_all(b"Buffered Line 1\n").expect("Failed to write buffered");
writer.write_all(b"Buffered Line 2\n").expect("Failed to write buffered");
writer.flush().expect("Failed to flush writer"); // 确保数据写入文件
println!("Buffered file written.");
// 使用 BufReader 读取
let file = File::open(file_name).expect("Failed to open file");
let mut reader = BufReader::new(file);
let mut contents = String::new();
reader.read_to_string(&mut contents).expect("Failed to read buffered file");
println!("Buffered file contents:\n{}", contents);
}
2.3.3 stdin、stdout、stderr:标准IO
用于与控制台进行交互。
use std::io::{stdin, stdout, Write};
use std::string::String;
fn main() {
print!("Please enter your name: ");
stdout().flush().expect("Failed to flush stdout"); // 确保提示信息立即显示
let mut name = String::new();
stdin().read_line(&mut name).expect("Failed to read line");
let trimmed_name = name.trim();
println!("Hello, {}!", trimmed_name);
}
2.4 std::math:数学运算与随机数
std::math 模块提供常见的数学函数和常量。
2.4.1 基本数学函数与常量
use std::math;
fn main() {
let x = 9.0;
println!("sqrt({}): {}", x, x.sqrt()); // 输出 3.0
println!("pow(2, 3): {}", 2.0.powi(3)); // 输出 8.0
println!("sin(PI/2): {}", math::PI / 2.0.sin()); // 输出 1.0 (近似)
println!("PI: {}", math::PI);
println!("E: {}", math::E);
}
2.4.2 std::rand:随机数生成
std::rand 模块提供生成伪随机数的功能。
use std::rand;
use std::rand::Rng; // 导入 Rng 接口
fn main() {
let mut rng = rand::thread_rng(); // 获取线程局部随机数生成器
let random_int: i32 = rng.gen_range(1..=100); // 生成 1 到 100 (包含) 的随机整数
println!("Random int: {}", random_int);
let random_float: f64 = rng.gen(); // 生成 0.0 到 1.0 (不包含) 的随机浮点数
println!("Random float: {}", random_float);
let coin_flip: bool = rng.gen(); // 随机布尔值
println!("Coin flip: {}", coin_flip);
}
三、错误与异常处理库设计
仓颉语言的错误处理机制是其安全性和健壮性的核心。它主要通过 Result<T, E> 和 Option<T> 这两个枚举类型来显式地处理可恢复的错误和空值。
3.1 Result<T, E>:可恢复错误的显式处理
Result<T, E> 用于表示一个操作可能成功并返回一个值 T,或者失败并返回一个错误 E。这强制开发者在编译时处理所有可能的错误情况。
enum Result<T, E> {
Ok(T),
Err(E),
}
enum ParseError {
InvalidFormat,
EmptyInput,
// ...
}
fn parse_number(s: &str) -> Result<i32, ParseError> {
if s.is_empty() {
return Result::Err(ParseError::EmptyInput);
}
match s.parse::<i32>() { // 假设 &str 提供了 parse 方法返回 Result
Ok(num) => Result::Ok(num),
Err(_) => Result::Err(ParseError::InvalidFormat),
}
}
fn main() {
match parse_number("123") {
Result::Ok(num) => println!("Parsed: {}", num), // 输出 Parsed: 123
Result::Err(e) => println!("Error: {:?}", e),
}
match parse_number("abc") {
Result::Ok(num) => println!("Parsed: {}", num),
Result::Err(e) => println!("Error: {:?}", e), // 输出 Error: InvalidFormat
}
// `?` 运算符简化错误传播
fn read_and_parse(path: &str) -> Result<i32, ParseError> {
let content = std::io::File::open(path)?.read_to_string()?; // 假设 File::open 和 read_to_string 返回 Result
parse_number(&content.trim()) // 假设 FileError 可以转换为 ParseError
}
}
? 运算符是仓颉语言中处理 Result 的强大语法糖,它会自动解包 Ok 值,并在遇到 Err 时提前返回该错误。
3.2 Option<T>:空值的安全表达
Option<T> 用于表示一个值可能存在(Some(T))或不存在(None)。它从语言层面消除了空指针引用(NullPointerException)的风险。
enum Option<T> {
Some(T),
None,
}
fn find_element(arr: &[i32], target: i32) -> Option<usize> {
for (i, &val) in arr.iter().enumerate() {
if val == target {
return Option::Some(i);
}
}
Option::None
}
fn main() {
let numbers = [10, 20, 30];
match find_element(&numbers, 20) {
Option::Some(index) => println!("Found at index: {}", index), // 输出 Found at index: 1
Option::None => println!("Element not found."),
}
// `if let` 简化 Option 处理
if let Option::Some(index) = find_element(&numbers, 40) {
println!("Found 40 at index: {}", index);
} else {
println!("40 not found."); // 输出 40 not found.
}
// `unwrap_or` 提供默认值
let default_index = find_element(&numbers, 50).unwrap_or(999);
println!("Default index: {}", default_index); // 输出 999
}
3.3 panic!:不可恢复错误的程序终止
panic! 宏用于表示程序遇到了一个不可恢复的错误,通常会导致程序终止。它与 Result 和 Option 处理的可恢复错误不同。
fn divide_or_panic(numerator: i32, denominator: i32) -> i32 {
if denominator == 0 {
panic!("Cannot divide by zero!"); // 触发 panic
}
numerator / denominator
}
fn main() {
let result = divide_or_panic(10, 2);
println!("Result: {}", result); // 输出 Result: 5
// let _ = divide_or_panic(10, 0); // 这行代码会触发 panic,程序终止
}
3.4 自定义错误类型与std::error::Error接口
仓颉语言鼓励开发者定义自己的错误枚举类型,并为它们实现 std::error::Error 接口。这使得自定义错误可以与其他标准库错误互操作,并提供统一的错误处理机制。
use std::error::Error; // 假设 Error 接口存在
use std::fmt; // 假设 fmt 模块存在
#[derive(Debug)] // 自动实现 Debug 接口
enum MyCustomError {
FileNotFound(String),
PermissionDenied,
InvalidData(String),
}
// 为 MyCustomError 实现 Display 接口
impl fmt::Display for MyCustomError {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
match self {
MyCustomError::FileNotFound(path) => write!(f, "File not found: {}", path),
MyCustomError::PermissionDenied => write!(f, "Permission denied"),
MyCustomError::InvalidData(msg) => write!(f, "Invalid data: {}", msg),
}
}
}
// 为 MyCustomError 实现 Error 接口
impl Error for MyCustomError {
// 可以提供 source 方法来链式追踪错误
fn source(&self) -> Option<&(dyn Error + 'static)> {
None
}
}
fn process_config(path: &str) -> Result<String, MyCustomError> {
let content = std::io::File::open(path)
.map_err(|e| MyCustomError::FileNotFound(path.to_string()))? // 将 io::Error 转换为 MyCustomError
.read_to_string()
.map_err(|e| MyCustomError::InvalidData(e.to_string()))?; // 将 io::Error 转换为 MyCustomError
Ok(content)
}
fn main() {
match process_config("non_existent.conf") {
Ok(config) => println!("Config: {}", config),
Err(e) => println!("Application error: {}", e), // 输出 Application error: File not found: non_existent.conf
}
}
四、异步与并发标准库解析
仓颉语言将提供强大的异步和并发编程支持,旨在帮助开发者编写高效、安全的多核应用程序。
4.1 仓颉的并发模型:消息传递与共享状态
仓颉语言的并发模型将融合两种主要范式:
- 消息传递(Message Passing): 通过通道(
Channel)在不同线程或任务之间安全地传递数据,避免共享状态带来的复杂性。 - 共享状态(Shared State): 通过互斥锁(
Mutex)、读写锁(RwLock)和原子操作(Atomic)来安全地管理共享数据。仓颉的所有权和借用系统将确保这些共享状态的正确使用。
4.2 std::thread:线程管理
std::thread 模块提供了创建和管理操作系统线程的基本功能。
use std::thread;
use std::time::Duration;
fn main() {
let handle = thread::spawn(|| { // 创建新线程
for i in 1..5 {
println!("Hi number {} from the spawned thread!", i);
thread::sleep(Duration::from_millis(1));
}
});
for i in 1..3 {
println!("Hi number {} from the main thread!", i);
thread::sleep(Duration::from_millis(1));
}
handle.join().expect("Thread panicked"); // 等待子线程完成
println!("Spawned thread finished.");
}
4.3 std::sync:同步原语
std::sync 模块提供了用于线程间同步的各种原语。
4.3.1 Mutex<T>:互斥锁
Mutex<T> 提供互斥访问共享数据,确保在任何给定时间只有一个线程可以修改数据。
use std::sync::Mutex;
use std::thread;
use std::collections::VArray;
fn main() {
let counter = Mutex::new(0); // 创建一个互斥锁保护的整数
let mut handles = VArray::new();
for _ in 0..10 {
let counter_ref = counter.clone(); // 克隆 Mutex 引用,以便在线程间共享
let handle = thread::spawn(move || {
let mut num = counter_ref.lock().expect("Failed to acquire lock"); // 获取锁
*num += 1; // 修改共享数据
println!("Thread incremented to: {}", *num);
});
handles.push(handle);
}
for handle in handles {
handle.join().expect("Thread panicked");
}
println!("Final counter: {}", *counter.lock().expect("Failed to acquire lock")); // 输出 10
}
4.3.2 RwLock<T>:读写锁
RwLock<T> 允许在同一时间有多个读取者,但只能有一个写入者。这在读多写少的场景下比 Mutex 性能更好。
use std::sync::RwLock;
use std::thread;
use std::time::Duration;
fn main() {
let data = RwLock::new(VArray::from_slice(&[1, 2, 3]));
// 多个读取者
let read_handle1 = thread::spawn({
let data_ref = data.clone();
move || {
let reader = data_ref.read().expect("Failed to acquire read lock");
println!("Reader 1: {:?}", *reader);
thread::sleep(Duration::from_millis(10));
}
});
let read_handle2 = thread::spawn({
let data_ref = data.clone();
move || {
let reader = data_ref.read().expect("Failed to acquire read lock");
println!("Reader 2: {:?}", *reader);
}
});
// 一个写入者
let write_handle = thread::spawn({
let data_ref = data.clone();
move || {
thread::sleep(Duration::from_millis(5)); // 稍等,让读者先读
let mut writer = data_ref.write().expect("Failed to acquire write lock");
writer.push(4);
println!("Writer added element.");
}
});
read_handle1.join().expect("Thread panicked");
read_handle2.join().expect("Thread panicked");
write_handle.join().expect("Thread panicked");
println!("Final data: {:?}", *data.read().expect("Failed to acquire read lock")); // 输出 [1, 2, 3, 4]
}
4.3.3 Atomic<T>:原子类型
Atomic<T> 提供对基本类型(如整数、布尔值)的原子操作,无需锁即可实现线程安全。
use std::sync::atomic::{AtomicUsize, Ordering};
use std::thread;
use std::collections::VArray;
fn main() {
let counter = AtomicUsize::new(0);
let mut handles = VArray::new();
for _ in 0..100 {
let counter_ref = counter.clone();
let handle = thread::spawn(move || {
counter_ref.fetch_add(1, Ordering::SeqCst); // 原子递增
});
handles.push(handle);
}
for handle in handles {
handle.join().expect("Thread panicked");
}
println!("Final atomic counter: {}", counter.load(Ordering::SeqCst)); // 输出 100
}
4.3.4 Channel<T>:消息通道
Channel<T> 提供了一种安全的消息传递机制,包含一个发送端(Sender<T>)和一个接收端(Receiver<T>)。
use std::sync::mpsc::channel; // 假设 mpsc 模块存在
use std::thread;
use std::collections::VArray;
fn main() {
let (sender, receiver) = channel(); // 创建一个通道
let mut handles = VArray::new();
for i in 0..5 {
let tx = sender.clone(); // 克隆发送端
let handle = thread::spawn(move || {
let message = format!("Hello from thread {}", i);
tx.send(message).expect("Failed to send message"); // 发送消息
});
handles.push(handle);
}
// 关闭原始发送端,否则接收端会一直等待
drop(sender);
for received in receiver { // 接收所有消息
println!("Received: {}", received);
}
for handle in handles {
handle.join().expect("Thread panicked");
}
println!("All messages processed.");
}
4.4 std::async:异步编程(设想)
仓颉语言将提供原生的 async/await 语法,用于编写非阻塞的异步代码,这对于高性能网络服务和UI应用至关重要。
4.4.1 async/await语法
async 关键字用于定义异步函数,await 关键字用于暂停当前异步函数的执行,直到一个 Future 完成。
// 设想的异步函数
async fn fetch_url(url: String) -> Result<String, std::io::Error> {
println!("Fetching URL: {}", url);
// 模拟异步网络请求
std::async::sleep(std::time::Duration::from_secs(1)).await; // 异步等待
println!("Finished fetching: {}", url);
Ok(format!("Content from {}", url))
}
async fn run_multiple_fetches() {
let future1 = fetch_url("http://example.com/1".to_string());
let future2 = fetch_url("http://example.com/2".to_string());
// 并发执行两个 future
let (result1, result2) = std::async::join(future1, future2).await; // 设想的并发 join
println!("Result 1: {:?}", result1);
println!("Result 2: {:?}", result2);
}
fn main() {
// 启动异步运行时
std::async::block_on(run_multiple_fetches());
}
4.4.2 Future<T>接口与执行器
Future<T> 是仓颉异步编程的核心接口,它代表一个可能在未来完成并产生值 T 的异步操作。执行器(Executor)负责调度和运行这些 Future。
五、源码级分析:标准库实现逻辑
理解标准库的底层实现原理,有助于我们更好地使用它们,并编写出更高效的代码。这里我们将进行概念性的“源码级”分析。
5.1 VArray<T>的内存布局与增长策略
VArray<T> 在内存中通常由三个部分组成:
ptr: 指向堆上数据起始位置的指针。len: 当前存储的元素数量。capacity: 当前分配的内存可以容纳的元素总数。
当 VArray 需要添加元素但 len 达到 capacity 时,它会执行重新分配操作:
- 分配一块更大的新内存(通常是当前
capacity的1.5倍或2倍)。 - 将旧内存中的所有元素复制到新内存。
- 释放旧内存。
- 更新
ptr和capacity。
这种策略在大多数情况下提供了摊销O(1)的 push 操作。
5.2 String与&str的内部表示
String: 内部通常封装了一个VArray<u8>,存储UTF-8编码的字节序列。它拥有数据,因此可以修改和增长。&str: 内部是一个“胖指针”(Fat Pointer),包含两个部分:- 指向字符串数据起始位置的指针。
- 字符串的长度(以字节为单位)。
&str不拥有数据,只是一个视图,因此是不可变的。
这种设计使得 String 灵活可变,而 &str 轻量高效,且两者之间可以安全地相互转换。
5.3 Option与Result的零成本抽象
Option<T> 和 Result<T, E> 在仓颉语言中是零成本抽象的典范。
- 原理: 编译器在编译时会优化它们的内存布局,使其在大多数情况下与直接使用原始类型或指针的开销相同。
- 对于
Option<T>,如果T是一个非空指针类型(如引用&T或Box<T>),None可以通过将指针设置为null来表示,而无需额外的空间。 - 对于
Result<T, E>,如果T和E都是非空指针类型,并且它们的内存布局允许,编译器可以利用“判别式优化”将Ok和Err的状态编码到指针的最低位或未使用的位中,从而避免额外的判别式字段。
- 对于
- 优势: 提供了强大的类型安全,而没有运行时性能损失。
5.4 Mutex的底层实现考量
Mutex 的实现通常依赖于操作系统提供的同步原语。
- 自旋锁(Spinlock): 在等待锁时,线程会忙循环(不断检查锁状态),适用于锁持有时间极短的场景。
- 阻塞锁(Blocking Lock): 在等待锁时,线程会被操作系统挂起,直到锁可用。这避免了CPU的浪费,但涉及上下文切换开销。
仓颉的Mutex可能会根据平台和配置选择合适的底层实现,通常是阻塞锁,以避免CPU浪费。它还会与所有权系统结合,确保锁的正确获取和释放(RAII)。
5.5 async/await的状态机转换(概念)
async/await 语法在编译时会被转换为一个状态机。
- 原理: 每个
async函数都会被编译器重写为一个结构体,其中包含函数的所有局部变量和暂停点(await)之间的状态。每次await都会将控制权交还给执行器,执行器在Future准备好时再次“轮询”状态机。 - 优势: 实现了非阻塞IO和并发,而无需手动管理回调函数或线程池,提供了与同步代码相似的编写体验。
这种转换是零成本的,运行时没有额外的抽象层开销。
六、实践:基于标准库开发一个配置解析器
现在,让我们将所学知识付诸实践,开发一个简单的配置解析器。我们将解析一个INI风格的配置文件,将其中的键值对存储到 HashMap 中。
6.1 配置解析器需求分析
- 读取指定路径的配置文件。
- 配置文件格式:
key = value。 - 支持注释:以
#开头的行将被忽略。 - 忽略空行。
- 键和值两端的空白字符应被去除。
- 返回一个包含所有配置项的
HashMap<String, String>。 - 处理文件不存在、读取失败、格式错误等情况。
6.2 ConfigParser结构体设计
我们将定义一个 ConfigParser 结构体,并为其实现一个 parse_file 关联函数。
use std::collections::HashMap;
use std::io::{self, BufReader, Read};
use std::fs::File;
use std::string::String;
// 自定义错误类型
#[derive(Debug)]
enum ConfigError {
Io(io::Error),
Parse(String, usize), // (错误信息, 行号)
}
// 为 ConfigError 实现 Display 接口
impl std::fmt::Display for ConfigError {
fn fmt(&self, f: &mut std::fmt::Formatter) -> std::fmt::Result {
match self {
ConfigError::Io(e) => write!(f, "IO error: {}", e),
ConfigError::Parse(msg, line_num) => write!(f, "Parse error on line {}: {}", line_num, msg),
}
}
}
// 为 ConfigError 实现 std::error::Error 接口
impl std::error::Error for ConfigError {
fn source(&self) -> Option<&(dyn std::error::Error + 'static)> {
match self {
ConfigError::Io(e) => Some(e),
_ => None,
}
}
}
// 从 io::Error 转换为 ConfigError
impl From<io::Error> for ConfigError {
fn from(err: io::Error) -> Self {
ConfigError::Io(err)
}
}
struct ConfigParser;
impl ConfigParser {
// 解析配置文件
fn parse_file(path: &str) -> Result<HashMap<String, String>, ConfigError> {
let file = File::open(path)?; // 使用 ? 运算符处理文件打开错误
let reader = BufReader::new(file);
let mut config_map = HashMap::new();
let mut line_num = 0;
for line_res in reader.lines() { // 假设 BufReader 提供了 lines() 迭代器
line_num += 1;
let line = line_res?; // 处理行读取错误
let trimmed_line = line.trim();
if trimmed_line.is_empty() || trimmed_line.starts_with("#") {
continue; // 忽略空行和注释
}
let parts: VArray<&str> = trimmed_line.splitn(2, '=').collect(); // 最多分割成两部分
if parts.len() != 2 {
return Err(ConfigError::Parse("Invalid key-value format".to_string(), line_num));
}
let key = parts[0].trim().to_string();
let value = parts[1].trim().to_string();
if key.is_empty() {
return Err(ConfigError::Parse("Empty key found".to_string(), line_num));
}
config_map.insert(key, value);
}
Ok(config_map)
}
}
6.3 文件读取与行处理
- 使用
File::open打开文件。 - 使用
BufReader提高读取效率。 - 使用
reader.lines()迭代器逐行读取,自动处理换行符。 line.trim()去除空白。line.starts_with("#")判断注释。
6.4 键值对解析与存储
trimmed_line.splitn(2, '=')将行分割成键和值两部分。parts.len() != 2检查格式是否正确。key.trim().to_string()和value.trim().to_string()处理键值两端的空白并转换为String。config_map.insert(key, value)存储到HashMap。
6.5 错误处理与使用示例
- 自定义
ConfigError枚举,包含Io和Parse两种错误。 - 为
ConfigError实现Display和std::error::Error接口,使其易于打印和与其他错误互操作。 - 使用
From<io::Error> for ConfigError转换器,简化io::Error到ConfigError的转换。 - 在
parse_file函数中使用Result和?运算符进行错误传播。fn main() { // 创建一个示例配置文件 let config_content = r#" # This is a comment database_url = postgres://user:pass@host:port/db api_key = abcdef12345 debug_mode = true # Another comment port = 8080 invalid_line "#; std::fs::write("app.conf", config_content.as_bytes()).expect("Failed to write config file"); match ConfigParser::parse_file("app.conf") { Ok(config) => { println!("Configuration loaded successfully:"); for (key, value) in config.iter() { println!(" {}: {}", key, value); } // 访问特定配置项 if let Some(db_url) = config.get("database_url") { println!("Database URL: {}", db_url); } }, Err(e) => { println!("Failed to load configuration: {}", e); if let Some(source) = e.source() { println!("Caused by: {}", source); } } } // 尝试解析一个不存在的文件 match ConfigParser::parse_file("non_existent.conf") { Ok(_) => println!("Unexpected success for non-existent file."), Err(e) => println!("Failed to load non-existent config: {}", e), // 输出 IO error: No such file or directory } // 尝试解析一个格式错误的文件 std::fs::write("bad.conf", "key_only\n").expect("Failed to write bad config file"); match ConfigParser::parse_file("bad.conf") { Ok(_) => println!("Unexpected success for bad config."), Err(e) => println!("Failed to load bad config: {}", e), // 输出 Parse error on line 1: Invalid key-value format } }结语:标准库——仓颉生态的基石
各位技术探索者们,今天我们对仓颉语言的标准库进行了全面而深入的剖析。我们从其模块化结构和导入规则开始,逐步探索了集合、字符串、IO和数学等核心库的强大功能。
我们深入理解了仓颉独特的错误处理机制——Result<T, E>和Option<T>如何保障代码的健壮性,以及panic!在不可恢复错误中的作用。我们还一窥了仓颉在异步并发领域的雄心,从线程、同步原语到async/await的设想。
更重要的是,我们从概念层面分析了标准库中一些关键组件的底层实现逻辑,如VArray的内存管理、Option的零成本抽象,这让我们对仓颉语言的性能和安全性有了更深刻的理解。
最后,通过一个实战项目——配置解析器,我们亲身体验了如何将这些标准库组件组合起来,构建出功能完善、错误处理健壮的应用程序。
仓颉语言的标准库,是其生态系统的基石,它为开发者提供了构建各种应用所需的强大工具。熟练掌握这些工具,将让你能够以更高效、更安全、更具表达力的方式,驾驭仓颉语言的强大力量。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)