
国产大模型成本与性能的双重胜利:揭秘如何以8%成本超越Claude,AI工程师的必学策略!
文章介绍了2025年中国三家AI公司发布的新一代大模型,在编程场景逼近甚至超越Claude Sonnet 4.5,而API定价仅为Claude的8%。这些模型仅用美国顶级实验室1/100的资源,通过"资源约束下的工程创新"路径实现突破,包括工程优化、算法效率优先和数据层创新。国产模型已通过商业验证,达到主流AI编程工具可用标准,标志着中国AI从"技术追赶"到"商业验证"的转变。
2025年秋天,中国AI圈发生了一件不太寻常的事。
9月30日,智谱AI发布GLM-4.6,在中文编程benchmark(CC-Bench)上对比Claude Sonnet 4的胜率达到48.6%,接近打平。
一个月后的10月27日,MiniMax发布M2模型,在LMSys Arena的WebDev Leaderboard上位列开源模型第一、总排名第四(前三是Claude、GPT-5、Gemini)。
又过了10天,11月6日,月之暗面发布Kimi-K2-Thinking,在软件工程任务benchmark(SWE-Bench Verified)上拿下71.3%的成绩,超越了Claude Sonnet 4.5的69.8%。
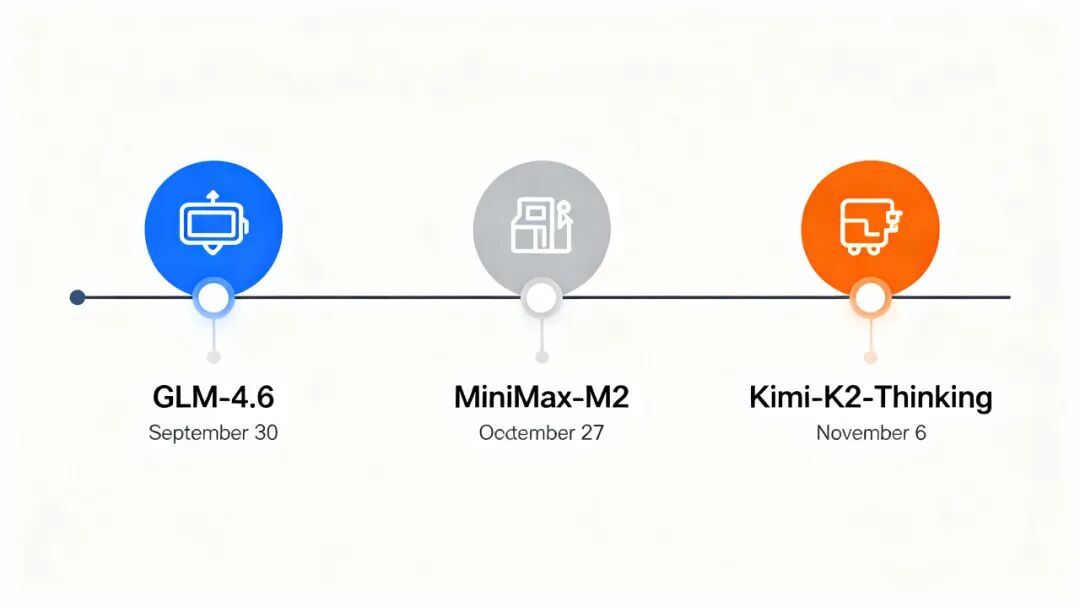
三个模型,在两个月内密集发布,都在编程和Agent场景展现出了接近甚至超越Claude的能力。更让人意外的是价格。
MiniMax-M2的API定价为每百万tokens输入0.50美元、输出2.20美元,而Claude Sonnet 4.5的定价是3美元和15美元。
算下来,MiniMax-M2的成本仅为Claude的8%。
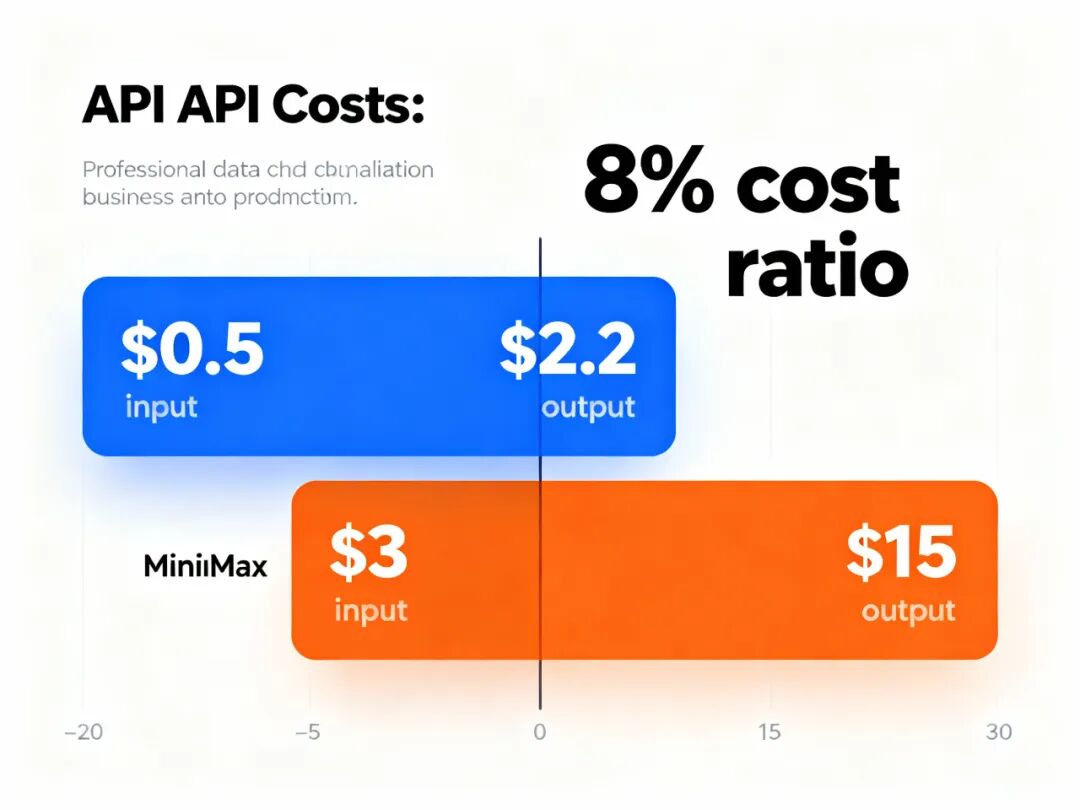
这个数字让硅谷的AI圈都炸了。
X上,前Google工程师@deedydas(21.5万粉丝)直接评论:“Cursor和Windsurf的新模型,疑似采用了国产基座。”
知名AI专家Sebastian Raschka(36.6万粉丝)在他的权威技术文档《The Big LLM Architecture Comparison》中新增了MiniMax-M2条目,评价:“性能好到无法忽视。”
AI评测平台Artificial Analysis认证GLM-4.6 Reasoning为"最智能的开源模型之一,智能水平接近GPT-OSS-120b和DeepSeek V3.2"。
一个问题浮现出来:国产大模型是怎么做到的?
要知道,据X社区观察者arctotherium分析,中国AI实验室的资源规模仅为美国顶级实验室的1/100。
OpenAI训练GPT-4据说花了超过1亿美元,Anthropic训练Claude系列也在数千万美元级别。
而月之暗面训练Kimi K2基座模型使用15.5T tokens,估计成本约460万美元。
智谱AI训练GLM-4.5使用23T tokens,估计成本500-1000万美元。
算力差距10-20倍,性能却持平甚至局部超越,成本还便宜92%。
这不科学。
除非——国产大模型找到了一条完全不同的路径。
不是"算力堆叠",而是"工程优化"
美国AI公司的路径很直接:
算力堆叠→规模扩张→涌现能力。
GPT-4采用约1.8T密集参数,Claude系列也走大规模预训练路线。
这种路径依赖三个前提:
充足算力资源、顶尖AI人才、海量高质量数据。
但中国模型厂商面临的现实是:
受限于芯片供应和数据中心规模,无法进行千亿美元级别的算力投入;
技术迭代速度极快,留给追赶的窗口期很短;
即便在benchmark上表现优异,仍需通过真实商业场景验证。
这种困境迫使国产模型必须找到"非对称"的突破路径——不与美国比拼算力和规模,而在"效率"和"成本"上寻找突破口。
这条路径的核心贡献来自四个维度:
工程层的多层次优化栈贡献了40%,商业落地验证贡献了30%,算法层的效率优先策略贡献了20%,数据层的合成数据新范式虽然仍是黑盒但也贡献了10%。
56倍内存压缩的工程奇迹
让我们从最"卷"的技术细节说起。
Kimi K2采用的Multi-head Latent Attention(MLA)机制,实现了14倍的KV Cache压缩。
传统的Multi-head Attention(MHA)中,每个head独立计算Query、Key、Value。
但MLA采用了"Latent Space Compression"策略:
先把Token从7168维压缩到512维,再计算注意力。
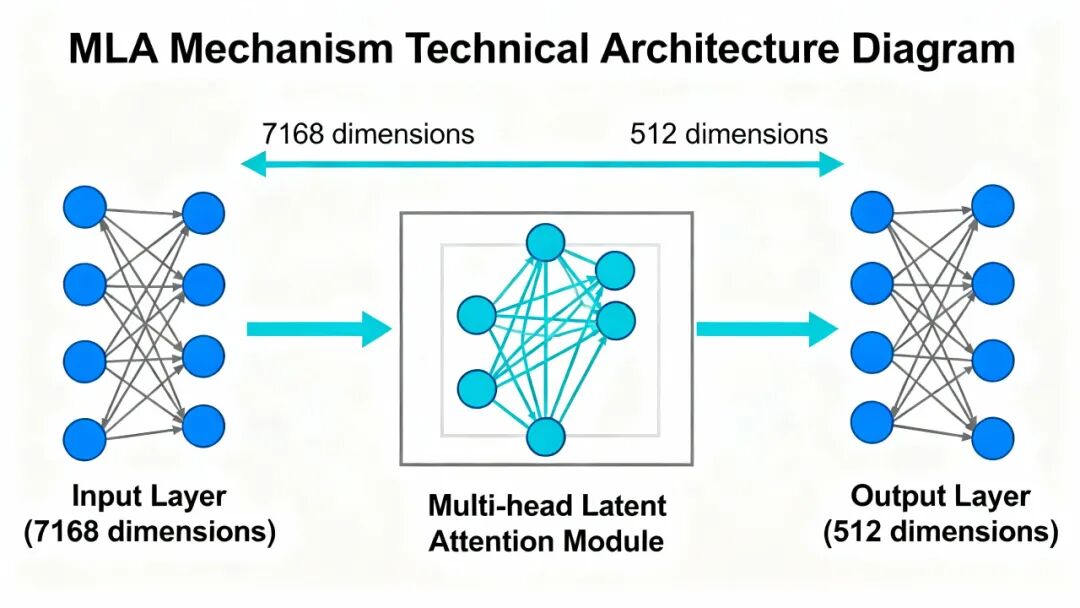
这有什么用?
在256K上下文下,传统MHA每层需要约3.67GB KV Cache,MLA仅需262MB。
对于Kimi K2的61层架构,传统MHA需要224GB KV Cache,MLA仅需16GB。
再加上INT4量化(8倍压缩),最终实现从224GB到4GB的总压缩比——56倍。
56倍内存压缩,意味着原本需要多GPU分布式部署的超长上下文(256K tokens),现在单GPU(H100 80GB)就能跑。
部署成本直接降到原来的1/10。
但这里有个trade-off。
据X社区分析,采用MLA的模型(Kimi K2、DeepSeek-V3)速度仅为Full Attention模型(MiniMax-M2)的20%,也就是说MiniMax-M2快5倍。
Sebastian Raschka也在推文中确认:“MiniMax M2使用Full Attention模块,这解释了为什么它比MLA模型快5倍。”
这揭示了架构选择的权衡:
MLA策略牺牲速度换内存,适合长上下文、内存受限场景;
Full Attention策略牺牲内存换速度,适合推理速度优先、并发能力要求高的场景。
不同场景,不同选择。
这就是"工程优化"的精髓。
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
三层优化叠加:吞吐量提升5倍
内存压缩只是第一步。
真正让国产模型"能打"的,是推理优化栈的叠加效应。
LMSYS部署Kimi K2使用128块H200 GPU,通过三层优化实现5倍吞吐量提升。
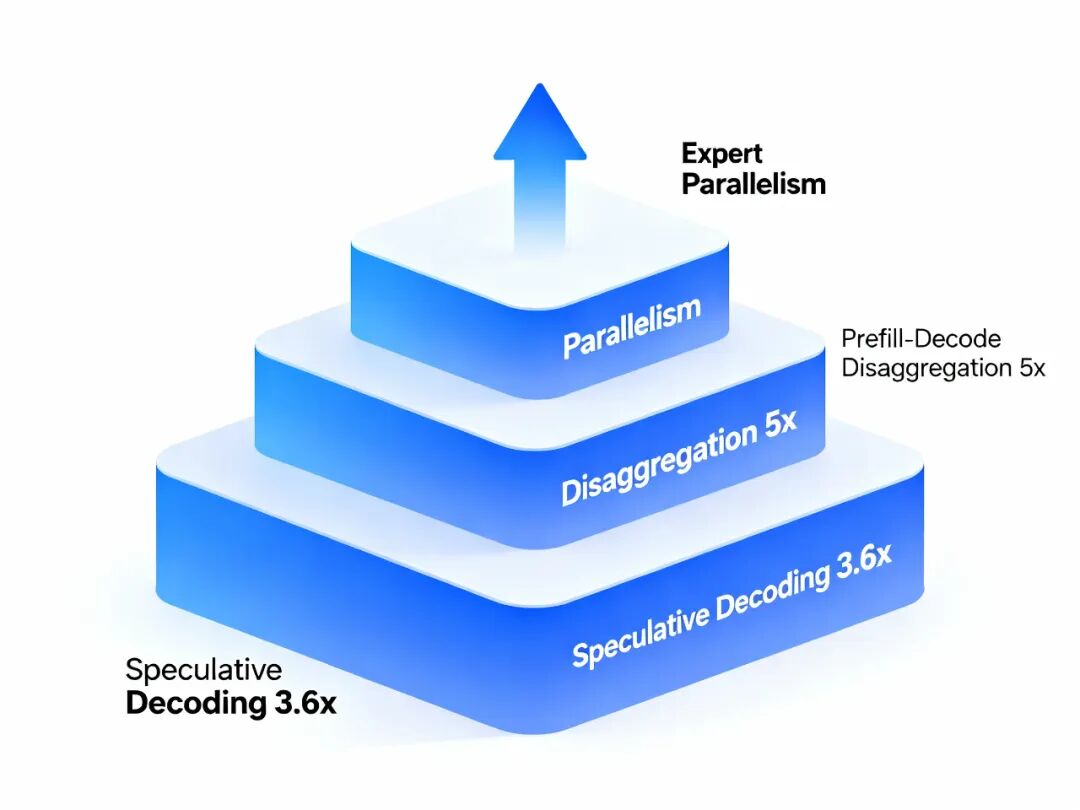
第一层是Speculative Decoding(投机解码)。
传统的大模型推理是逐token生成的,每次只生成1个token。
Speculative Decoding的思路是:
先用一个小型Draft Model预测4个候选tokens,再用大型Target Model一次性验证这4个tokens。
如果前3个都对,就直接接受,节省了2次大模型调用。
TensorRT-LLM实测显示,吞吐量提升最高3.6倍。
第二层是Prefill-Decode Disaggregation(PD分离)。
大模型推理分两个阶段:
Prefill阶段处理输入prompt,计算密集,需要大批量;
Decode阶段逐token生成,内存密集,延迟敏感。传统方案把两者放在同一GPU上执行,效率低。
PD Disaggregation将两者分离到不同GPU集群:
64块GPU专门处理Prefill生成KV Cache,另外64块GPU专门处理Decode逐token生成。
基于DeepSeek R1经验,PD Disaggregation实现5倍吞吐量提升。
第三层是Expert Parallelism(专家并行)。
Kimi K2采用MoE架构,总参数1T但每次只激活32B(384个expert中选8个)。
384个expert分布到128块GPU,每块GPU负责3个expert,通过高速互联实现专家并行。
综合效果是:
内存压缩56倍(MLA + INT4),吞吐量提升3.6倍(Speculative Decoding)再叠加5倍(PD Disaggregation),并发支持384个expert跨128 GPU部署。
这就是国产模型能以8%成本实现性能持平的技术底座。
商业验证:从"实验室产品"到"主流工具可用"
Benchmark高分只能证明技术潜力,真实使用场景的验证才能证明技术可靠性。
国产模型已经通过了最严格的商业验证。
实测显示,Kimi-K2-Thinking在Claude Code中的表现已接近Sonnet 4.5水平。
这意味着,国产模型的技术成熟度已达到主流AI编程工具的可用标准。
Claude Code是Anthropic官方的AI编程工具,对模型的要求极其严苛:
推理速度用户等不了太久,并发能力要同时处理数百万次代码生成请求,稳定性任何一次失败都会影响用户体验,成本可控API调用成本不能太高。
能在Claude Code中"能用",说明Kimi-K2-Thinking在所有维度都达到了商业级标准。
更有趣的是,2025年10月,X技术社区观察到一个现象:
Cursor和Windsurf的新版本中出现了中文推理痕迹。
前Google工程师@deedydas(21.5万粉丝)分析:“Cursor和Windsurf的新模型,疑似基于中国基座模型构建!Windsurf的SWE-1.5似乎是在Cerebras上运行的智谱GLM 4.6定制版本(微调/RL)。Cursor Composer有中文推理痕迹。”
虽然官方未确认,但从侧面反映了国产模型已具备商业产品集成的潜力。
不是推测,而是真实发生的集成还有很多。
Quora旗下AI聊天平台Poe官方宣布上线MiniMax-M2,强调其"在编程和agent工作流中表现出色"。
TRAE IDE集成了GLM-4.5和GLM-4.6,支持BYOK(Bring Your Own Key)模式。
去中心化GPU网络io.net(45.8万粉丝)让GLM-4.6上线,宣传"优越的编程benchmark,更智能的agent推理和工具使用,更好的前端生成"。
Baseten、GMI、Parasail、Novita、Deepinfra等多家API提供商都提供GLM-4.6服务。
其中,Baseten实测GLM-4.6达到114 TPS(Tokens Per Second),是其他供应商的2倍,TTFT(Time To First Token)小于18秒。
Baseten在推文中宣布:“我们非常激动地成为今天在Artificial Analysis上最快的提供商,114 TPS(是第二名的2倍),TTFT小于18秒(是第二名的2倍)。”
开发者社区的真实反馈也验证了性能和成本优势。
X用户@shydev69(2.6万粉丝)分享了一个超低成本方案:“如何用GLM 4.6以3美元成本实现’Claude Code unlimited’的指南(中国SOTA编程LLM)”。
X用户@TheAhmadOsman(2.9万粉丝)分享了最佳实践:“Codex CLI搭配GPT-5 High做规划,Claude Code搭配GLM-4.6执行,这是Agentic编程的终极配方。”
算法创新:不是"更大更强",而是"更高效"
国产模型在算法层的创新不是追求"更大更强"(如GPT-4 1.8T密集参数),而是"在资源约束下如何做到更好"。
MuonClip优化器的突破
Kimi K2使用MuonClip优化器(Muon + QK-Clip),实现了15.5T tokens零损失峰值训练,token效率比AdamW提升2-3倍。
核心创新有两个机制。
第一个是Muon的正交更新。
不同于AdamW的逐参数更新,Muon保持权重矩阵的正交性,防止奇异值扭曲。
AdamW对每个参数w独立更新,问题是独立更新破坏权重矩阵的几何结构;
Muon对权重矩阵W整体更新保持正交性,优势是保持矩阵形状防止奇异值失控。
Fireworks官方博客提供了交互式可视化,展示AdamW和Muon的奇异值演化:
AdamW的奇异值随训练扭曲,部分奇异值趋近于0导致"softmax崩溃";
Muon的奇异值保持稳定,权重矩阵的几何结构完美。
第二个是QK-Clip的动态裁剪。
限制Query和Key矩阵的注意力分数,防止softmax崩溃。
计算预softmax注意力logit的最大值S_max,如果S_max超过阈值100,就自适应重缩放Q/K权重矩阵,让它们保持在安全范围内。
根据官方技术博客,Kimi K2的训练曲线呈现明显的三阶段特征:
0-70k steps时QK scores频繁超过100阈值,MuonClip主动干预重缩放权重,模型学习稳定的注意力模式;
70k+ steps时QK scores稳定在30左右,极少触发QK-Clip干预,模型进入自稳定阶段;
最终结果是平滑的训练曲线,零损失峰值。
为什么重要?
传统AdamW训练经常出现损失峰值(loss spike),需要手动调整学习率或回退checkpoint。
这不仅浪费算力,还增加了训练不确定性。
MuonClip的零损失峰值意味着:
训练成本可预测(460万美元),不需要人工干预,token效率提升2-3倍。
这就是"用更少资源做到更好"的典型案例。
MoE架构的精细化设计
三个模型均采用MoE架构,但激活率极低。
Kimi K2总参数1T激活32B,384个expert每token选8个,激活率3.2%;
GLM-4.5总参数355B激活32B,激活率约9%;MiniMax-M2总参数230B激活10B,激活率4.3%。
Kimi K2的384个expert设计远超常见的8-16个expert,提供了更细粒度的专业化能力。
但这也增加了routing复杂度。
X用户@qubitium分析:“Kimi团队被迫采用QAT,因为他们的MoE routing设计上非常不均衡。GLM 4.6和MiniMax M2的routing更平衡。”
不均衡的routing意味着部分expert激活频率高,部分低。
PTQ(Post-Training Quantization)会严重损害低频expert的性能,而QAT(Quantization-Aware Training)通过训练时调整可以缓解这一问题。
这再次体现了"针对性优化"的思路:
不是盲目追求平衡,而是根据实际情况选择最优方案。
数据层:已知趋势,未知实现
数据层是"已知趋势但未知实现"的黑盒。
各家都在做合成数据+RLHF,但具体怎么做是核心竞争力。
行业趋势已经很明确:
从人类为主到合成为主。
传统RLHF范式是Pre-training用10B-1T tokens,然后SFT用10K指令数据,再训练Reward Model用100K人类偏好数据,最后RL用PPO和1M样本。
新范式变成了Pre-training用10B-1T tokens,然后SFT用百万级合成数据加10K人类数据,训练Reward Model用十万级人类反馈,RL用PPO和百万级合成数据,最后还有Expert Model Iteration针对特定场景。
关键假设有三个:
合成数据质量可超越人类,在困难任务(如数学推理、代码生成)上LLM生成的数据质量可能高于普通标注员;
数据过滤是最重要环节,不是所有合成数据都有用,过滤策略决定最终性能;
多轮训练和生成是必须的,单轮SFT无法达到顶级性能。
GLM-4.5的训练流程公开了部分信息。
Stage 1预训练用23T tokens的多语言和多领域数据;Stage 2 SFT推测用百万级数据(未公开),来源是指令数据(合成为主+人类为辅);
Stage 3 RL推测用百万级数据(未公开),方法是基于奖励模型的强化学习如PPO;
Stage 4 Expert Model Iteration针对特定场景(编程、数学)做垂直场景专项训练。
Kimi K2官方博客提到使用了"Agentic数据合成管道",但具体如何设计Agent、如何生成高质量数据、如何过滤低质量数据,均未详述。
虽然行业趋势明确,但具体实现细节未公开:
Agentic数据合成管道的具体实现——
如何设计Agent生成高质量数据?
如何控制生成数据的多样性和难度?
如何避免模型"自我强化"偏
RLHF的奖励模型架构——奖励模型的架构是什么?
奖励模型的训练数据来源?
PPO的超参数设置?
数据过滤策略——如何判断合成数据的质量?
如何避免"数据污染"?
如何平衡数据多样性和质量?
技术社区的迫切需求反映了这一点。
如果看数据层的完整度对比,算法层90%完整(架构、优化器、注意力机制公开),工程层95%完整(量化、推理优化、部署架构公开),应用层90%完整(Benchmark、商业集成、用户反馈公开),但数据层只有60%完整(行业趋势明确,但具体实现黑盒)。
数据层仍是国产模型的"秘密武器",也是未来竞争的关键。
从"技术追赶"到"商业验证"的三个阶段
国产模型的发展经历了三个阶段。
实验室阶段(2023-2024)主要是发布benchmark数据,证明技术可行性,但缺乏真实商业验证。
智谱AI发布GLM-4系列,月之暗面发布Kimi基座模型,MiniMax发布早期版本。
这个阶段的特征是主要在学术benchmark上刷榜,缺少真实用户反馈,成本优势不明显。
生态集成阶段(2024-2025)第三方API提供商开始支持,开源协议吸引开发者,技术成熟度逐步提升。
GLM-4.6采用MIT License全开源,MiniMax-M2开源,Baseten、GMI、Parasail等API提供商开始支持。
这个阶段开源策略形成差异化竞争,第三方生态开始形成,成本优势开始显现。
商业验证阶段(2025-now)实测达到主流AI编程工具的可用标准,第三方平台真实集成,业界观察到头部产品的集成可能性。
Kimi-K2-Thinking在Claude Code中表现接近Sonnet 4.5,Poe、TRAE、io.net等平台真实集成,Cursor、Windsurf疑似集成(未官方确认)。
这个阶段技术成熟度达到商业级水平,有真实用户验证,成本优势形成降维打击。
这标志着国产模型已不再是"追赶者",而是"合格的竞争者"。
两种模式的权衡
美国模式走的是规模扩张到涌现能力的路径。
GPT-4约1.8T密集参数,训练成本超过1亿美元;
Claude 3.5 Sonnet参数量未公开,但推测在数百B级别。
这种模式的优势是性能上限高,涌现能力强;
劣势是成本高昂,推理慢,部署复杂。
中国模式走的是效率优化到精准定位的路径。
Kimi K2是1T参数但只激活32B,训练成本460万美元;
GLM-4.5是355B参数但只激活32B,训练成本500-1000万美元。
这种模式的优势是成本低,推理快(Full Attention场景),垂直场景优化;
劣势是通用能力可能不及最顶级闭源模型。
架构选择上,MLA策略速度慢(20%)但内存占用低(14倍压缩),适合长上下文、内存受限、成本敏感的场景;
Full Attention策略速度快(100%)但内存占用高,适合推理速度优先、并发能力要求高的场景。
优化器选择上,MuonClip的token效率是AdamW的2-3倍,训练稳定性达到零损失峰值,但计算开销高(正交投影),适合大规模训练;
AdamW的token效率是基准1倍,训练稳定性会有频繁损失峰值,但计算开销低(逐参数),适合中小规模训练。
这反映了不同场景的最优选择:
Kimi K2针对超长上下文(256K)选择MLA,牺牲速度换内存;
MiniMax-M2针对高并发场景选择Full Attention,牺牲内存换速度;
Kimi K2针对大规模训练选择MuonClip,提升token效率;
GLM-4.5采用"Deeper, not wider"设计哲学,增加深度而非宽度。核心理念是:
没有最好的架构,只有最适合的架构。
可持续性取决于四个边界条件
国产模型的成功不是"技术上全面超越Claude",而是"在资源约束下找到了高效追赶路径"。
其可持续性取决于四个边界条件。
工程优化天花板方面,当前状态是MLA已实现14倍KV Cache压缩(接近理论上限),INT4量化已是极限(INT2会严重损失精度),Speculative Decoding提升3.6倍(理论上限约4-5倍)。
未来空间是MLA+INT4的组合优化尚未完全发挥潜力,Expert Parallelism的调度算法仍可改进,新的优化器(如MuonClip)仍在演进。
判断是短期内(1-2年)仍有优化空间,但长期会触及物理极限。
美国frontier labs跟进速度方面,当前状态是Claude、GPT-4.5主要依赖算力堆叠,未采用激进的工程优化,商业模式依赖高价API(3美元/15美元),短期内难以降价。
潜在变化是如果Claude采用MLA、INT4等优化成本优势会缩小,如果OpenAI开源GPT-4.5生态优势会受挑战。
判断是国产模型有1-2年的窗口期,但需要持续迭代保持领先。
开源生态持续性方面,当前状态是GLM-4.6、MiniMax-M2采用MIT License全开源,Baseten、Poe、TRAE、io.net等第三方平台集成,技术社区反馈积极(Sebastian Raschka、Eric Hartford等)。
潜在挑战是开源模型需要持续社区贡献形成正反馈,第三方API提供商需要持续扩展覆盖更多场景,商业模式需要验证(API服务、企业定制、生态收费)。
判断是MIT License是正确的策略,但需要持续投入和社区运营。
数据层黑盒方面,当前状态是Agentic数据合成管道、RLHF策略、数据过滤方法是黑盒,技术社区迫切需要开源Post-Training Recipe(Eric Hartford推文)。
潜在变化是谁先开源完整Recipe谁就能引爆社区贡献,数据层开源可能形成"囚徒困境"——先开放者获益更大。
判断是数据层是未来竞争的关键,谁率先开源谁占据主动。
历史可能重演:Linux挑战Unix的故事
国产大模型的路径,让人想起Linux挑战Unix的历史。
1990年代的Unix技术领先性能强大,但成本高昂(10万美元以上的工作站),闭源生态封闭。
1990年代的Linux技术不如Unix完善,但成本低(免费),开源社区驱动。
结果是到2010年代,Linux在服务器市场超越Unix,占据70%以上份额。
关键不在于技术的绝对领先,而在于"足够好+成本低+生态强"。
当前的AI市场,Claude/GPT走的是Unix模式:
技术水平顶尖涌现能力强,但成本高昂(3美元/15美元),闭源集成有限,商业模式是高价API。
国产模型走的是Linux模式:
技术水平足够好垂直场景优化,成本低廉(0.5美元/2.2美元,8%成本),开源(MIT License)有第三方支持,商业模式是API服务+企业定制+生态收费。
如果国产模型能形成类似Linux的社区贡献机制,通过众包优化不断提升性能,则"Linux vs Unix"的历史可能重演。
但如果数据层持续黑盒、工程优化触及天花板、美国frontier labs降价,则国产模型的窗口期可能关闭。
结语:一条"资源约束下的工程创新"路径
国产大模型的故事,不仅是中国AI产业的突围,更是全球AI生态从"闭源垄断"向"开源竞争"转变的缩影。
核心启示有四点:
工程优化大于算力堆叠,在资源受限下系统性优化可以实现降维打击;
效率优先大于规模优先,不是最大而是最高效;
商业验证大于Benchmark高分,真实使用场景才是技术成熟度的金标准;
开源生态大于闭源垄断,MIT License加第三方支持等于不可逆的优势。
最后一个问题:
国产大模型能否复制Linux的成功?
答案取决于四个边界条件:
工程优化天花板(短期仍有空间),美国frontier labs跟进速度(1-2年窗口期),开源生态持续性(MIT License是正确策略),数据层黑盒(谁先开源谁占主动)。
国产大模型的成败,将影响未来十年AI产业的格局。
如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 23
23 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)