
毕业设计-基于计算机视觉的智能建筑工人防护装备检测 YOLO python 深度学习 人工智能
毕业设计-基于计算机视觉的智能建筑工人防护装备检测系统。该系统利用图像处理和深度学习技术,对建筑工人佩戴的安全帽、防护眼镜、手套等装备进行自动识别和检测。研究首先构建了包含多种防护装备的图像数据集,并采用卷积神经网络(CNN)进行特征提取与分类模型的训练。实验结果表明,该系统在防护装备检测的准确率上具有显著优势,能够实时监控工人的安全装备佩戴情况。通过本研究,期望为建筑行业提供一种高效、安全的智能
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于计算机视觉的智能建筑工人防护装备检测
设计思路
一、课题背景与意义
在建筑行业中,工人安全是至关重要的。建筑工地常常存在高风险的工作环境,工人必须佩戴合适的防护装备以确保安全。然而,传统的安全监督往往依赖人工检查,存在主观性强、效率低下等问题,难以实时监控和保证每位工人的防护装备是否符合安全标准。通过智能检测系统,可以显著提高建筑工地的安全管理效率,降低人工检查的工作负担,确保每位工人都能及时佩戴必要的防护装备。准确的防护装备检测能够有效减少工伤事故的发生,提高工人的安全感和工作积极性。智能化的安全监控系统还能够实时记录和分析防护装备佩戴情况,为建筑企业的安全管理提供数据支持,帮助其优化安全管理策略,形成良好的安全文化。

二、算法理论原理
2.1 目标检测
在建筑工地环境中,监控设备通常被安装在较高的位置,这导致画面中的目标(即工人)相对较小。这种情况下,主流的目标检测算法在检测小目标时常常面临漏检或置信度低的问题。对YOLOv5的骨干网络(Backbone)和头部网络(Head)进行了针对性的设计和修改,以提升小目标的检测能力。通过改进模型结构,使其能够更有效地处理小尺寸目标,从而提高检测准确性和可靠性。
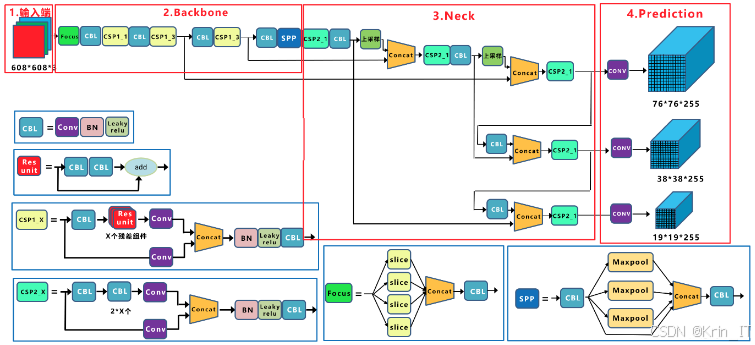
Backbone负责在不同图像细粒度上聚合并形成图像特征。YOLOv5的原始模型在Head层设置了三个尺寸的检测特征图,分别为80×80、40×40和20×20,这用于检测大小在8×8、16×16和32×32以上的目标。然而,这样的特征图尺寸对于更小目标的检测能力有限。为了改善这一状况,本文在Head层增加了一个160×160的检测特征图,以便于检测尺寸更小的目标(如4×4),从而减少特征丢失的风险,增强模型对小目标的捕捉能力。
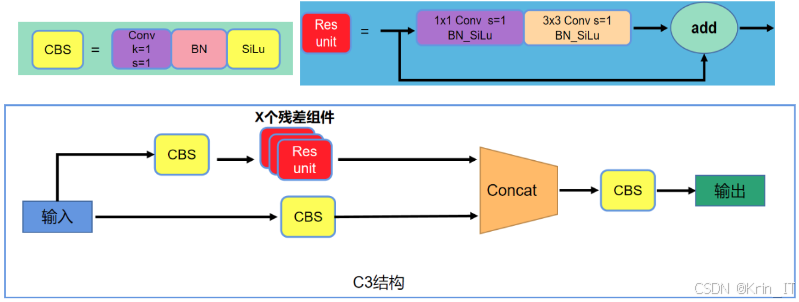
Head模块在目标检测中主要负责对图像特征进行预测,生成边界框并预测目标类别。在YOLOv5中,Backbone和Head使用的是C3模块,该模块包含了多个标准卷积层和Bottleneck模块。然而,C3模块经历的卷积层较多,可能会导致小目标特征的丢失。将C3模块替换为BottleneckCSP模块,并在残差输出后增加了Conv模块,以保留更多的特征信息。此外,标准卷积模块中的激活函数选择了SiLU,这增加了模型的平滑性和非单调性,有助于提高网络的表达能力。
选择合适的损失函数对模型的收敛效果和识别效果至关重要。采用了GIoU_Loss作为损失函数。GIoU_Loss引入了一种更准确的边界框相交度量方式,能够更好地解决边界框不重合的问题。通过精确计算预测框与真实框之间的重合度,GIoU_Loss能够有效提升模型的训练效果,从而提高小目标的识别精度。

通过对YOLOv5骨干网络和头部网络的针对性设计与优化,智能建筑工人防护装备检测系统显著提升了小目标的检测能力。增加的特征图尺寸、优化的模块结构和选择的损失函数共同作用,增强了模型对建筑工地环境中工人及其防护装备的识别效果。
2.2 注意力机制
CBMA是一种结合了通道注意力和空间注意力的多重注意力机制,旨在增强深度学习模型对特征的选择性关注。CBMA通过对特征图的通道和空间维度分别进行加权,能够有效提高模型对重要特征的敏感度。具体而言,通道注意力通过计算特征图中各个通道的重要性,来动态调整不同通道的权重,使得网络能够聚焦于对任务有贡献的特征;而空间注意力则关注于特征图中不同位置的重要性,通过加权不同空间位置的特征,帮助模型更好地捕捉关键区域的信息。这种结合方式使得CBMA在处理复杂任务时,能够显著提升模型的表现,尤其是在目标检测和图像分类等任务中。
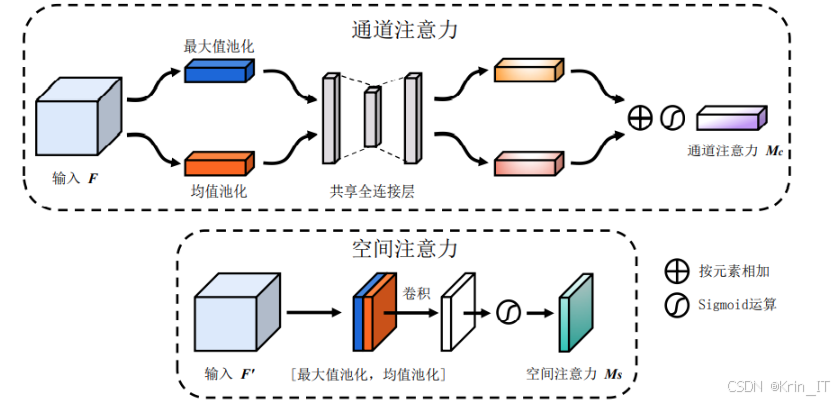
通过将CBMA集成到YOLOv5s的特征提取过程中,模型能够更有效地聚焦于关键特征和重要区域。具体实现过程中,首先在YOLOv5s的特征图上应用通道注意力机制,计算出每个通道的权重,以强化有助于识别工人及其防护装备的特征;然后,通过空间注意力机制,对特征图的空间维度进行加权,使得模型能够更好地识别图像中与目标相关的区域。通过这种方式,CBMA注意力机制能够有效减少背景噪声对检测结果的干扰,提高模型对小目标的检测能力,从而显著提升智能建筑工人防护装备检测系统的整体性能。
三、建筑工人着装检测的实现
3.1 实现环境
深度学习框架为构建、训练、优化和推理深度神经网络提供了必要的基础工具,使开发者能够更高效地进行相关工作。这些框架不仅简化了复杂的计算过程,还提供了丰富的功能和灵活的接口,帮助开发者快速实现各种深度学习算法。在众多深度学习框架中,PyTorch因其高度的扩展性和可移植性而受到广泛欢迎,尤其在学术研究和工业应用中表现出色。它的动态计算图特性使得模型的调试和修改变得更加直观和方便,同时,PyTorch拥有一个活跃的开发者社区,提供了大量的资源和支持,极大地推动了深度学习的研究和应用。

为了确保数据的多样性和代表性,我们采用了两种方式进行图像采集:一方面,通过自主拍摄在实际建筑工地上捕捉工人佩戴防护装备的场景,力求覆盖不同工人、不同装备和不同工作环境的实例;另一方面,利用互联网收集相关的公开数据和图片,以补充自主拍摄的不足。这一阶段的目标是构建一个包含丰富场景和各种防护装备的图像库,为后续的数据标注和模型训练打下坚实基础。使用LabelMe这一开源工具进行数据标注,LabelMe支持多边形标注,能够精确地框定每个工人及其防护装备的轮廓。在标注过程中,我们对每张图像中的防护装备进行分类,如安全头盔、安全手套、安全靴等,并为每个目标分配相应的标签。完成数据标注后,我们对数据集进行划分,以便于模型训练、验证和测试。一般采用70%用于训练,15%用于验证,15%用于测试的比例。

3.2 模型训练
数据集制作包括图像采集、数据标注和数据集划分。数据集的质量直接影响模型的训练效果,因此,选择具有代表性的建筑工地图像,并使用工具进行精确的标注非常重要。标注完成后,数据集通常被划分为训练集、验证集和测试集,以便在不同阶段评估模型的性能。为了提高模型对小目标的检测能力,数据集中应包含多种工人及其防护装备的实例,通过数据增强技术(如旋转、缩放、裁剪等)增加样本多样性。
模型训练需要选择合适的超参数,包括学习率、批次大小和图像分辨率等。为了平衡模型的精确度和预测时间,训练(测试)图像的分辨率通常设置为640×640,而在测试时使用416×416。较高的分辨率可以提高模型的精确度,但也会增加预测时间。因此,选择一个合适的分辨率是至关重要的。通过对YOLOv5模型的骨干网络和头部网络进行针对性的设计和修改,提升小目标的检测能力,确保模型能够有效处理建筑工地环境中的工人和防护装备。
# 示例:设置超参数
learning_rate = 0.001
batch_size = 16
image_size = (640, 640) # 训练时的图像分辨率
# 模型训练函数
def train_model(model, train_loader, optimizer, criterion, epochs):
for epoch in range(epochs):
for images, targets in train_loader:
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()在模型训练的不同批次(epoch)下,使用精确率(Precision)、召回率(Recall)和mAP@.5三个指标来衡量模型的性能。这些指标能够反映模型在检测工人和防护装备时的准确性和稳定性。通过记录每个epoch的性能指标,可以分析模型在训练过程中的表现,寻找最佳的epoch,以便在验证集上获得最高的检测效果。
# 示例:计算性能指标
from sklearn.metrics import precision_score, recall_score
def evaluate_model(outputs, targets):
precision = precision_score(targets, outputs, average='weighted')
recall = recall_score(targets, outputs, average='weighted')
return precision, recall
# 记录每个epoch的性能
performance_metrics = []
for epoch in range(num_epochs):
precision, recall = evaluate_model(outputs, targets)
performance_metrics.append((precision, recall))通常情况下,损失函数会在前100次迭代之前迅速下降并逐渐收敛,反映出模型在学习过程中对数据的适应性。通过观察这些曲线,可以判断模型的训练是否正常,及时调整学习率或其他超参数,以提高训练效果。
# 示例:绘制损失函数变化曲线
import matplotlib.pyplot as plt
def plot_loss_curve(loss_values):
plt.plot(loss_values, label='Training Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Loss Curve')
plt.legend()
plt.show()
loss_values = [] # 假设已经记录每个epoch的损失
plot_loss_curve(loss_values)通过将CBMA(通道和空间注意力机制)集成到YOLOv5s的特征提取过程中,模型能够更有效地聚焦于关键特征和重要区域,进一步提升小目标的检测能力。在评估阶段,结合之前的性能指标,分析模型在实际应用中的表现,确保其在不同场景下的可靠性和准确性。
# 示例:集成CBMA注意力机制
class CBMA(nn.Module):
def __init__(self, in_channels):
super(CBMA, self).__init__()
self.channel_attention = ChannelAttention(in_channels)
self.spatial_attention = SpatialAttention()
def forward(self, x):
x = self.channel_attention(x) * x
x = self.spatial_attention(x) * x
return x
# 假设已经构建了YOLOv5s模型
model = CBMA(yolov5s_model)创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!
最后

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 24
24 0
0- 0



 已为社区贡献92条内容
已为社区贡献92条内容

所有评论(0)