
探讨 AI 编程的三大核心领域,通过代码示例、流程图解、Prompt 设计和实践案例,全面展示 AI 编程技术的应用方法与实际价值。
AI编程技术正深刻变革软件开发模式,主要包括三大领域:自动化代码生成通过大语言模型将自然语言转为可执行代码,显著提升开发效率;低代码/无代码平台借助可视化界面和预制组件降低开发门槛;AI驱动的算法优化可智能识别性能瓶颈并优化代码。数据显示,AI辅助工具使开发者效率提升45%,缺陷率降低32%。技术发展面临代码质量、知识产权等挑战,未来将向多模态交互、智能补全等方向发展。AI编程最佳实践是人机协作,
一、引言:AI 编程的技术演进与应用价值
随着人工智能技术的飞速发展,编程领域正经历着前所未有的变革。AI 编程技术通过自动化代码生成、低代码 / 无代码平台以及智能算法优化,显著提升了开发效率,降低了技术门槛,重塑了软件开发的生产模式。
据 GitHub 2024 年开发者报告显示,采用 AI 辅助编程工具的开发者平均开发效率提升 45%,代码缺陷率降低 32%。这种变革不仅影响专业开发者的工作方式,更让非技术人员能够参与到应用开发过程中,实现 "全民开发" 的愿景。
本文将系统探讨 AI 编程的三大核心领域,通过代码示例、流程图解、Prompt 设计和实践案例,全面展示 AI 编程技术的应用方法与实际价值。
二、自动化代码生成:从自然语言到可执行程序
自动化代码生成是 AI 编程最成熟的应用领域,其核心能力是将自然语言描述转换为可执行代码。主流技术基于大语言模型 (LLM),如 GPT-4、Claude、CodeLlama 等,通过理解上下文和编程知识生成符合要求的代码。
2.1 代码生成的技术原理
代码生成模型通常基于 Transformer 架构,通过海量代码库训练获得编程知识。其工作流程如下:
graph TD
A[用户需求] --> B[需求分析与拆解]
B --> C[代码生成模型]
C --> D{代码质量检查}
D -->|合格| E[输出代码]
D -->|不合格| F[修改提示词重新生成]
E --> G[代码测试与优化]
G --> H[最终代码]
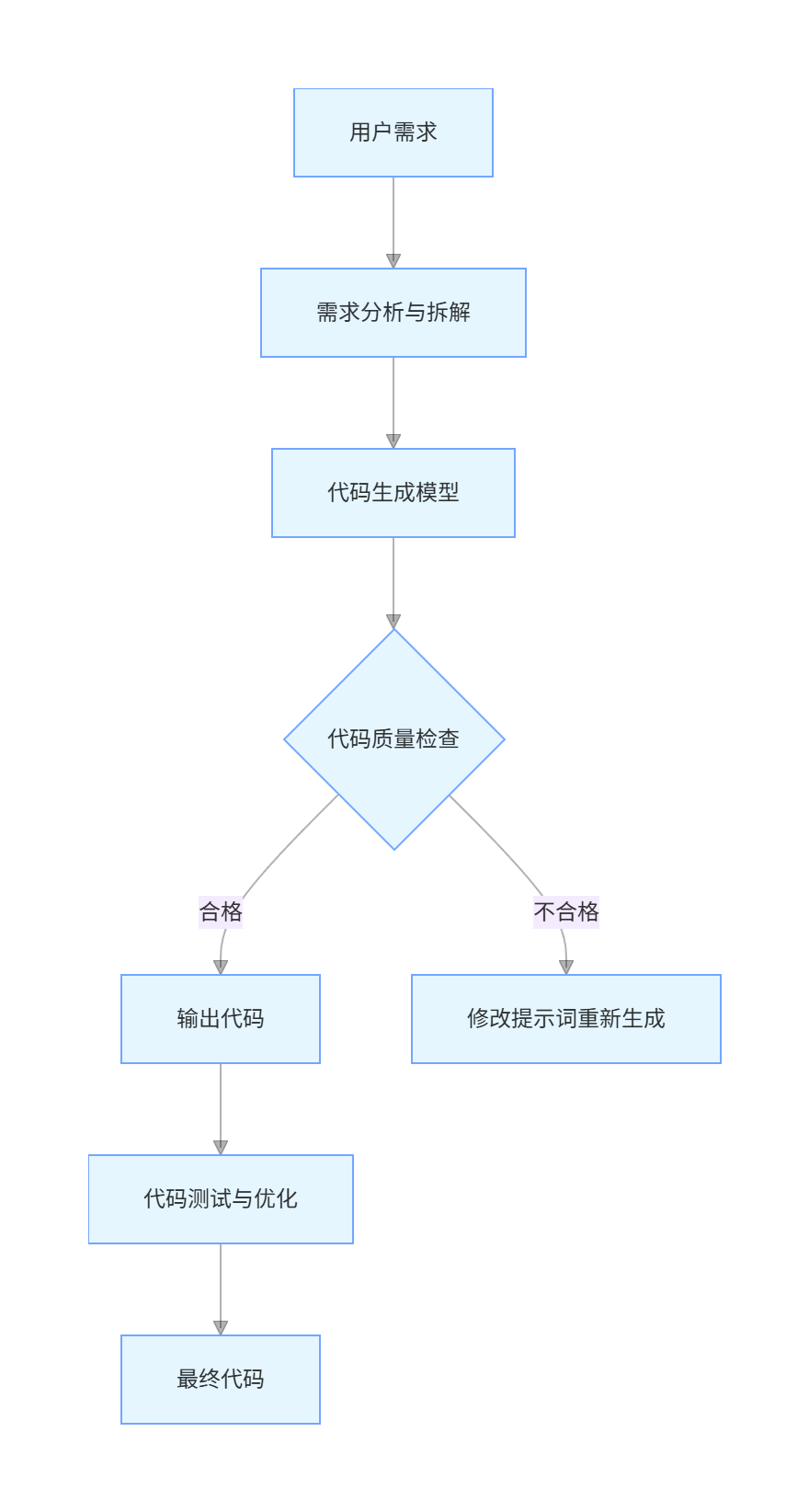
代码生成的质量取决于:
- 提示词的精确性与完整性
- 模型对特定编程语言的熟悉程度
- 问题领域的复杂度
- 上下文信息的丰富度
2.2 实用代码生成示例
示例 1:数据处理函数生成
Prompt 设计:
plaintext
请用Python编写一个函数,要求如下:
1. 函数名:process_sales_data
2. 功能:处理销售数据,计算每个产品的月销售总额和平均单价
3. 输入:一个包含销售记录的列表,每个记录是字典,包含"product_id"、"date"、"quantity"、"price"字段
4. 输出:一个字典,键为产品ID,值为包含"monthly_total"(每月总额)和"avg_price"(平均单价)的字典
5. 注意:monthly_total的键应为"YYYY-MM"格式
生成的代码:
python
运行
from collections import defaultdict
from datetime import datetime
def process_sales_data(sales_records):
"""
处理销售数据,计算每个产品的月销售总额和平均单价
参数:
sales_records: 销售记录列表,每个记录为包含以下字段的字典:
- product_id: 产品ID
- date: 销售日期,字符串格式
- quantity: 销售数量
- price: 单价
返回:
处理后的字典,结构为:
{
product_id: {
"monthly_total": {
"YYYY-MM": 月销售总额
},
"avg_price": 平均单价
}
}
"""
result = defaultdict(lambda: {
"monthly_total": defaultdict(float),
"avg_price": {
"total": 0.0,
"count": 0
}
})
for record in sales_records:
product_id = record["product_id"]
date_str = record["date"]
quantity = record["quantity"]
price = record["price"]
# 处理日期,提取年月
date_obj = datetime.strptime(date_str, "%Y-%m-%d")
month_key = date_obj.strftime("%Y-%m")
# 计算月销售总额
result[product_id]["monthly_total"][month_key] += quantity * price
# 计算平均单价(加权平均)
result[product_id]["avg_price"]["total"] += price * quantity
result[product_id]["avg_price"]["count"] += quantity
# 转换为普通字典并计算最终平均单价
final_result = {}
for product_id, data in result.items():
avg_price = data["avg_price"]["total"] / data["avg_price"]["count"] if data["avg_price"]["count"] > 0 else 0
final_result[product_id] = {
"monthly_total": dict(data["monthly_total"]),
"avg_price": round(avg_price, 2)
}
return final_result
# 测试代码
if __name__ == "__main__":
test_data = [
{"product_id": "P001", "date": "2024-01-15", "quantity": 5, "price": 10.0},
{"product_id": "P001", "date": "2024-01-20", "quantity": 3, "price": 10.0},
{"product_id": "P001", "date": "2024-02-05", "quantity": 2, "price": 12.0},
{"product_id": "P002", "date": "2024-01-10", "quantity": 10, "price": 5.5}
]
processed = process_sales_data(test_data)
print(processed)
示例 2:API 接口生成
Prompt 设计:
plaintext
请使用Node.js和Express框架编写一个用户管理API,包含以下功能:
1. 用户注册(POST /api/auth/register)
2. 用户登录(POST /api/auth/login)
3. 获取当前用户信息(GET /api/users/me)
4. 使用JWT进行身份验证
5. 使用bcrypt加密密码
6. 使用Mongoose作为数据库ORM
请包含必要的数据模型定义、中间件和错误处理。
生成的代码:
javascript
运行
const express = require('express');
const mongoose = require('mongoose');
const bcrypt = require('bcryptjs');
const jwt = require('jsonwebtoken');
const router = express.Router();
const auth = require('../middleware/auth');
// 用户模型
const UserSchema = new mongoose.Schema({
name: {
type: String,
required: [true, '请提供姓名'],
trim: true,
maxlength: [50, '姓名不能超过50个字符']
},
email: {
type: String,
required: [true, '请提供邮箱'],
unique: true,
match: [
/^\w+([\.-]?\w+)*@\w+([\.-]?\w+)*(\.\w{2,3})+$/,
'请提供有效的邮箱'
]
},
password: {
type: String,
required: [true, '请提供密码'],
minlength: [6, '密码至少6个字符'],
select: false
},
createdAt: {
type: Date,
default: Date.now
}
});
// 密码加密中间件
UserSchema.pre('save', async function(next) {
if (!this.isModified('password')) {
next();
}
const salt = await bcrypt.genSalt(10);
this.password = await bcrypt.hash(this.password, salt);
});
// 生成JWT
UserSchema.methods.getSignedJwtToken = function() {
return jwt.sign(
{ id: this._id },
process.env.JWT_SECRET,
{ expiresIn: process.env.JWT_EXPIRE }
);
};
// 密码匹配方法
UserSchema.methods.matchPassword = async function(enteredPassword) {
return await bcrypt.compare(enteredPassword, this.password);
};
const User = mongoose.model('User', UserSchema);
// @desc 注册用户
// @route POST /api/auth/register
// @access Public
router.post('/register', async (req, res, next) => {
try {
const { name, email, password } = req.body;
// 创建用户
const user = await User.create({
name,
email,
password
});
sendTokenResponse(user, 200, res);
} catch (err) {
next(err);
}
});
// @desc 用户登录
// @route POST /api/auth/login
// @access Public
router.post('/login', async (req, res, next) => {
try {
const { email, password } = req.body;
// 验证邮箱和密码
if (!email || !password) {
return res.status(400).json({ success: false, error: '请提供邮箱和密码' });
}
// 检查用户是否存在
const user = await User.findOne({ email }).select('+password');
if (!user) {
return res.status(401).json({ success: false, error: '无效的凭据' });
}
// 检查密码是否匹配
const isMatch = await user.matchPassword(password);
if (!isMatch) {
return res.status(401).json({ success: false, error: '无效的凭据' });
}
sendTokenResponse(user, 200, res);
} catch (err) {
next(err);
}
});
// @desc 获取当前登录用户
// @route GET /api/users/me
// @access Private
router.get('/me', auth, async (req, res, next) => {
try {
const user = await User.findById(req.user.id);
res.status(200).json({
success: true,
data: user
});
} catch (err) {
next(err);
}
});
// 辅助函数:获取token并创建响应
const sendTokenResponse = (user, statusCode, res) => {
// 创建token
const token = user.getSignedJwtToken();
const options = {
expires: new Date(
Date.now() + process.env.JWT_COOKIE_EXPIRE * 24 * 60 * 60 * 1000
),
httpOnly: true
};
if (process.env.NODE_ENV === 'production') {
options.secure = true;
}
res
.status(statusCode)
.cookie('token', token, options)
.json({
success: true,
token
});
};
module.exports = router;
2.3 代码生成的最佳实践
为了获得高质量的生成代码,需要遵循以下提示词设计原则:
| 原则 | 说明 | 示例 |
|---|---|---|
| 明确性 | 清晰描述需求,避免模糊表述 | 差:"写一个排序函数" 好:"用 Python 实现快速排序算法,处理整数列表,返回升序排列的新列表" |
| 完整性 | 提供所有必要信息 | 包含输入输出格式、数据类型、业务规则等 |
| 结构化 | 组织信息层次 | 使用编号、列表、标题等方式组织需求 |
| 约束性 | 明确技术限制 | 指定编程语言、框架版本、性能要求等 |
| 示例化 | 提供输入输出示例 | 给出测试用例,帮助模型理解预期结果 |
进阶 Prompt 模板:
plaintext
任务:[具体编程任务]
技术要求:
- 编程语言:[指定语言及版本]
- 框架/库:[指定框架及版本]
- 数据格式:[输入输出格式]
- 性能要求:[时间/空间复杂度要求]
功能细节:
1. [功能点1及详细说明]
2. [功能点2及详细说明]
3. [异常处理要求]
示例:
输入:[示例输入]
输出:[示例输出]
代码风格:
- [命名规范]
- [注释要求]
- [代码结构要求]
2.4 自动化代码生成的局限性与解决方案
尽管 AI 代码生成能力强大,但仍存在一些局限:
-
逻辑错误风险:复杂逻辑可能生成有缺陷的代码
- 解决方案:结合单元测试生成,自动验证代码正确性
-
上下文限制:长代码生成可能出现前后不一致
- 解决方案:分模块生成,逐步构建,保持上下文连贯性
-
最新技术支持不足:对新框架、新 API 支持有限
- 解决方案:在提示词中提供相关文档片段,辅助模型理解
-
安全漏洞风险:可能生成包含安全隐患的代码
- 解决方案:集成代码安全扫描工具,自动检测并修复漏洞
graph TD
A[需求分析] --> B[分模块设计]
B --> C[生成模块1代码]
C --> D[自动测试与验证]
D -->|通过| E[生成模块2代码]
D -->|不通过| F[调整提示词重新生成]
E --> G[模块集成]
G --> H[安全扫描]
H -->|通过| I[代码优化]
H -->|不通过| J[修复安全问题]
I --> K[最终代码]
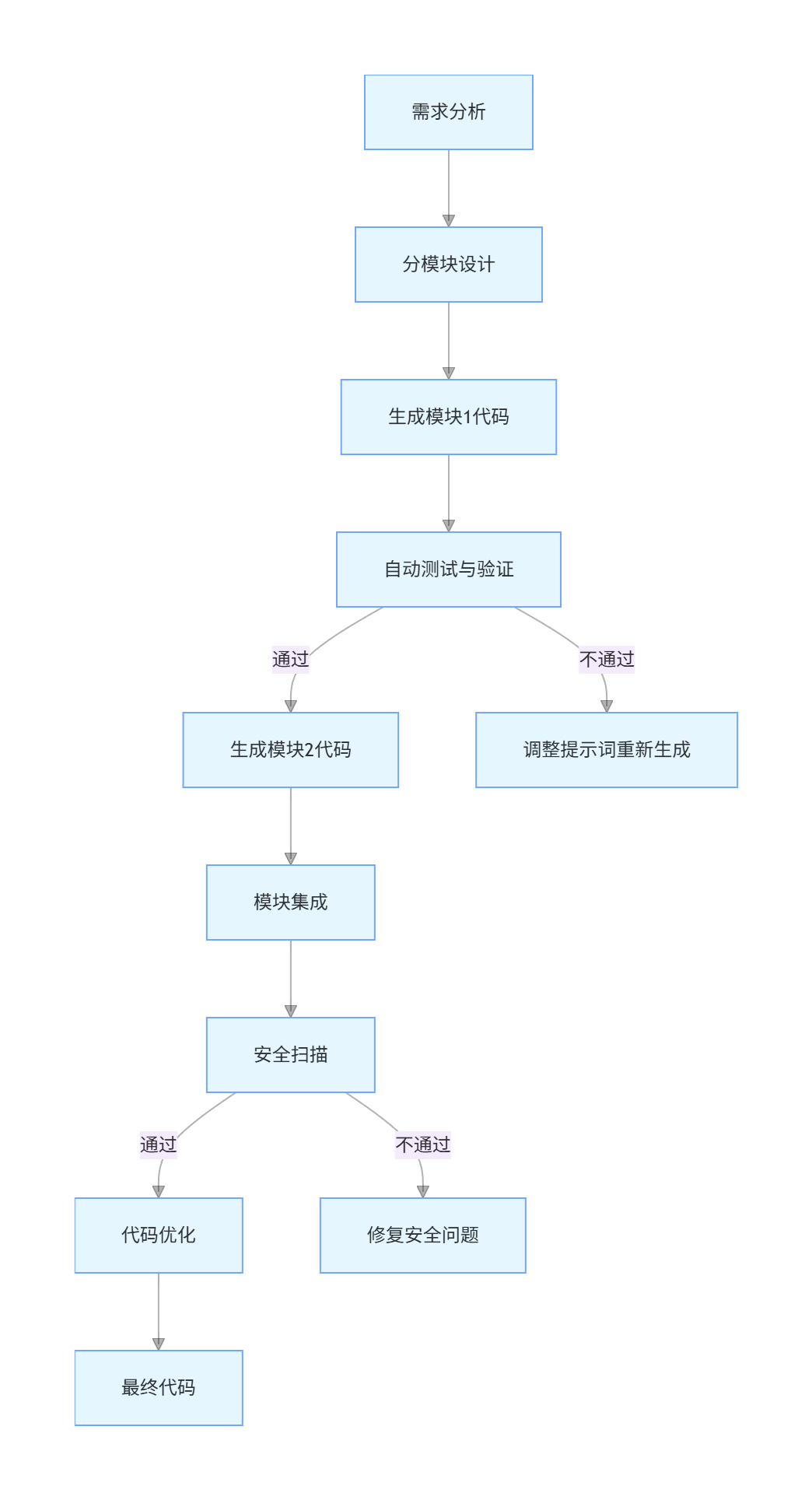
三、低代码 / 无代码开发:可视化编程的新范式
低代码 / 无代码 (Low-Code/No-Code) 开发平台通过可视化界面和预制组件,大幅减少传统代码编写工作量,使开发者能够快速构建应用程序。AI 技术的融入进一步增强了这些平台的智能化水平和易用性。
3.1 低代码 / 无代码平台的技术架构
现代低代码平台通常采用以下架构:
graph TD
A[用户界面层] -->|拖放操作| B[可视化编辑器]
B --> C[组件库]
B --> D[流程引擎]
C --> E[UI组件]
C --> F[业务组件]
C --> G[数据组件]
D --> H[工作流设计器]
D --> I[规则引擎]
B --> J[AI辅助设计]
J --> K[智能推荐]
J --> L[需求转换]
J --> M[自动补全]
B --> N[数据源连接]
N --> O[数据库]
N --> P[API服务]
N --> Q[第三方系统]
B --> R[代码生成引擎]
R --> S[部署管道]
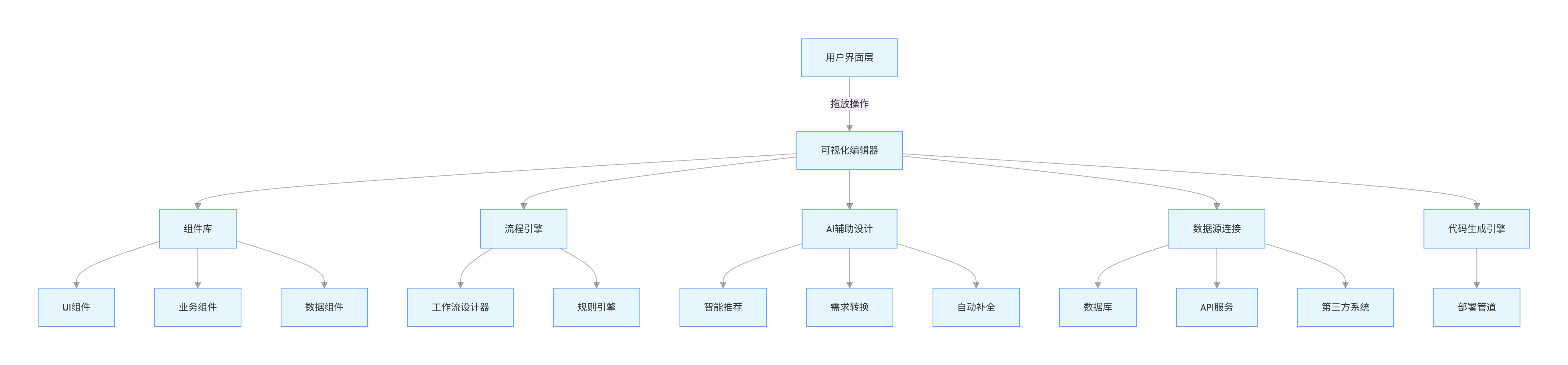
AI 在低代码平台中的典型应用包括:
- 基于文本描述自动生成应用界面
- 智能推荐合适的组件和流程设计
- 自动识别并修复配置错误
- 根据用户行为优化界面设计
- 自动生成复杂业务规则
3.2 低代码开发实践案例:客户管理系统
以下是使用 AI 增强的低代码平台构建客户管理系统的流程:
-
需求定义通过自然语言描述系统需求:"创建一个客户管理系统,包含客户信息录入、查询、编辑功能,支持按地区和行业筛选,能生成简单的客户分析报表,需要用户权限管理。"
-
AI 自动生成基础架构平台根据需求自动创建:
- 数据模型(客户、用户、角色等)
- 基础页面结构(列表、详情、编辑页)
- 简单的权限控制流程
-
可视化界面设计通过拖放组件完善界面:
-
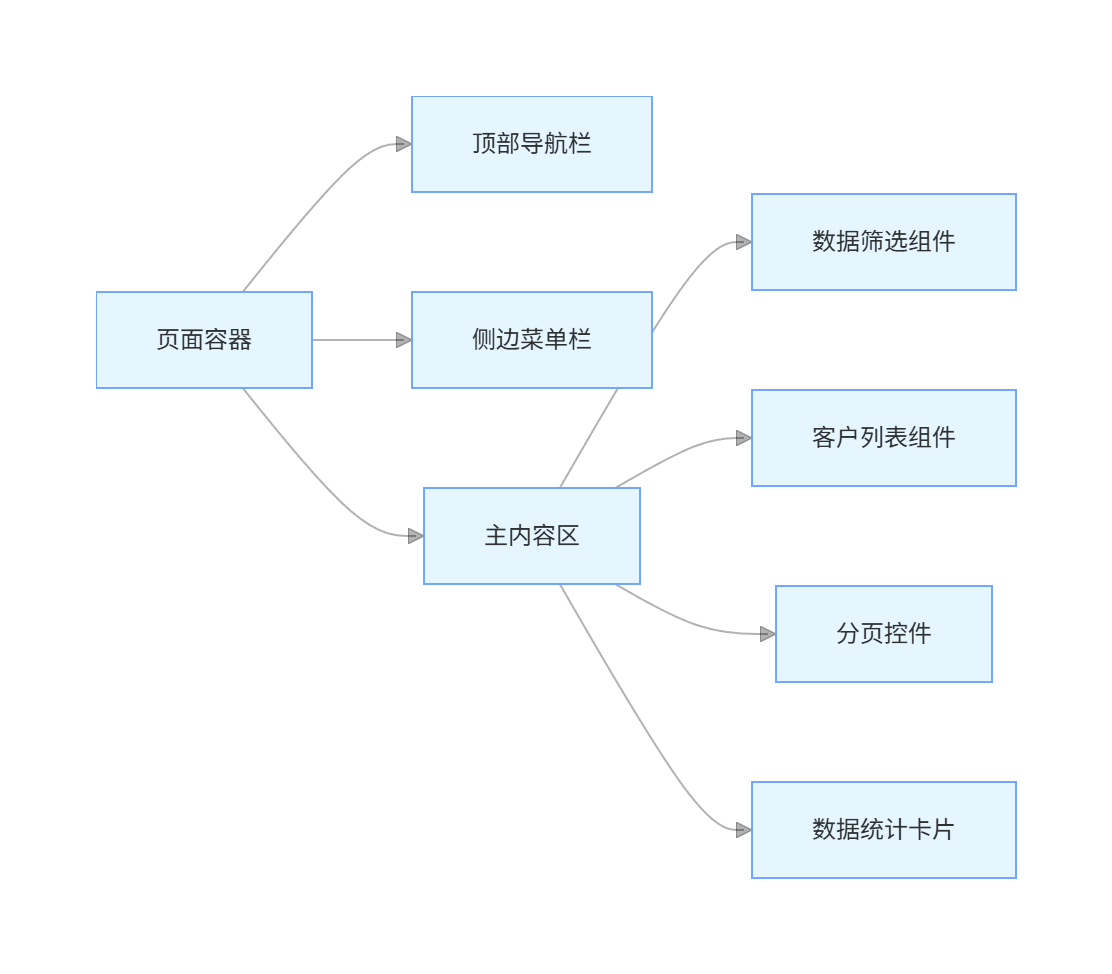
graph LR A[页面容器] --> B[顶部导航栏] A --> C[侧边菜单栏] A --> D[主内容区] D --> E[数据筛选组件] D --> F[客户列表组件] D --> G[分页控件] D --> H[数据统计卡片] -
业务逻辑配置设置数据验证规则和业务流程:
- 客户邮箱格式验证
- 客户创建流程:录入→审核→激活
- 数据权限控制:销售人员只能查看自己的客户
-
集成与扩展
- 连接企业现有 CRM 系统 API
- 通过自定义代码块添加复杂统计功能
-
自动测试与部署
- 平台自动生成测试用例
- 一键部署到云服务器
3.3 无代码平台的 AI 功能实现
无代码平台通过 AI 进一步简化开发流程,以下是一个基于 AI 的无代码表单生成功能实现:
核心代码(简化版):
javascript
运行
// AI表单生成器
class AIFormGenerator {
constructor(aiService) {
this.aiService = aiService;
this.components = {
text: TextComponent,
number: NumberComponent,
date: DateComponent,
select: SelectComponent,
checkbox: CheckboxComponent
};
}
// 从文本描述生成表单
async generateFormFromText(description) {
// 调用AI服务分析需求
const formSchema = await this.aiService.analyzeFormRequirements(description);
// 验证并完善表单 schema
const validatedSchema = this.validateFormSchema(formSchema);
// 生成表单组件
const formComponents = this.createFormComponents(validatedSchema.fields);
// 生成表单验证规则
const validationRules = this.generateValidationRules(validatedSchema.fields);
return {
schema: validatedSchema,
components: formComponents,
validationRules,
// 自动生成的提交处理逻辑
onSubmit: this.generateSubmitHandler(validatedSchema.action)
};
}
// 验证表单 schema
validateFormSchema(schema) {
// 确保必要字段存在
if (!schema.fields) schema.fields = [];
// 为每个字段添加默认属性
schema.fields = schema.fields.map(field => ({
required: field.required ?? false,
label: field.label ?? this.generateLabelFromName(field.name),
placeholder: field.placeholder ?? `请输入${this.generateLabelFromName(field.name)}`,
...field
}));
return schema;
}
// 创建表单组件
createFormComponents(fields) {
return fields.map(field => {
const ComponentClass = this.components[field.type] || this.components.text;
return new ComponentClass(field);
});
}
// 生成验证规则
generateValidationRules(fields) {
return fields.reduce((rules, field) => {
if (field.required) {
rules[field.name] = [
{ required: true, message: `${field.label}不能为空` }
];
}
// 根据字段类型添加特定验证
if (field.type === 'email') {
rules[field.name].push({
type: 'email',
message: '请输入有效的邮箱地址'
});
}
if (field.type === 'number' && field.range) {
rules[field.name].push({
type: 'number',
min: field.range.min,
max: field.range.max,
message: `请输入${field.range.min}到${field.range.max}之间的数值`
});
}
return rules;
}, {});
}
// 生成提交处理函数
generateSubmitHandler(action) {
return async (values) => {
try {
// 根据AI分析的动作类型生成处理逻辑
if (action.type === 'saveToDatabase') {
return await this.saveToDatabase(action.table, values);
} else if (action.type === 'sendApiRequest') {
return await this.sendApiRequest(action.url, action.method, values);
}
} catch (error) {
console.error('提交失败:', error);
throw error;
}
};
}
// 辅助方法:从字段名生成标签
generateLabelFromName(name) {
// 下划线转空格,首字母大写
return name
.replace(/_/g, ' ')
.replace(/(?:^|\s)\S/g, match => match.toUpperCase());
}
// 保存到数据库
async saveToDatabase(table, data) {
// 实际实现...
return { success: true, message: '保存成功' };
}
// 发送API请求
async sendApiRequest(url, method, data) {
// 实际实现...
return { success: true, message: '请求发送成功' };
}
}
// 使用示例
const aiService = new AIService(); // 假设的AI服务
const formGenerator = new AIFormGenerator(aiService);
// 从文本描述生成表单
formGenerator.generateFormFromText(
"创建一个客户反馈表单,需要收集客户姓名、邮箱、反馈类型(产品问题、建议、投诉)、反馈内容和提交日期,其中姓名和反馈内容为必填项。"
).then(form => {
// 渲染表单
renderForm(form);
});
3.4 低代码 / 无代码平台的适用场景与选型
不同类型的低代码 / 无代码平台适用于不同场景:
| 平台类型 | 特点 | 适用场景 | 代表产品 |
|---|---|---|---|
| 通用型低代码平台 | 功能全面,可扩展性强 | 企业级应用、复杂业务系统 | Mendix, OutSystems, PowerApps |
| 表单流程平台 | 专注于数据收集和流程审批 | 办公自动化、业务审批 | 简道云、氚云、Nintex |
| 网站 / 小程序搭建平台 | 专注于前端界面和内容管理 | 营销网站、展示型小程序 | Wix, 凡科网,易企秀 |
| 后端 API 平台 | 专注于数据模型和 API 生成 | 快速构建后端服务 | Supabase, Firebase, AppSmith |
| 移动端低代码平台 | 专注于移动应用开发 | 企业移动应用、内部工具 | AppGyver, BuildFire |
选择平台时应考虑以下因素:
- 应用复杂度和定制需求
- 团队技术能力和学习成本
- 与现有系统的集成需求
- 数据安全和合规要求
- 长期维护和扩展成本
- 部署和运维的便捷性
四、算法优化实践:AI 驱动的代码效率提升
算法优化是提升程序性能的关键,AI 技术能够帮助开发者识别性能瓶颈,推荐更优算法,并自动优化代码实现。
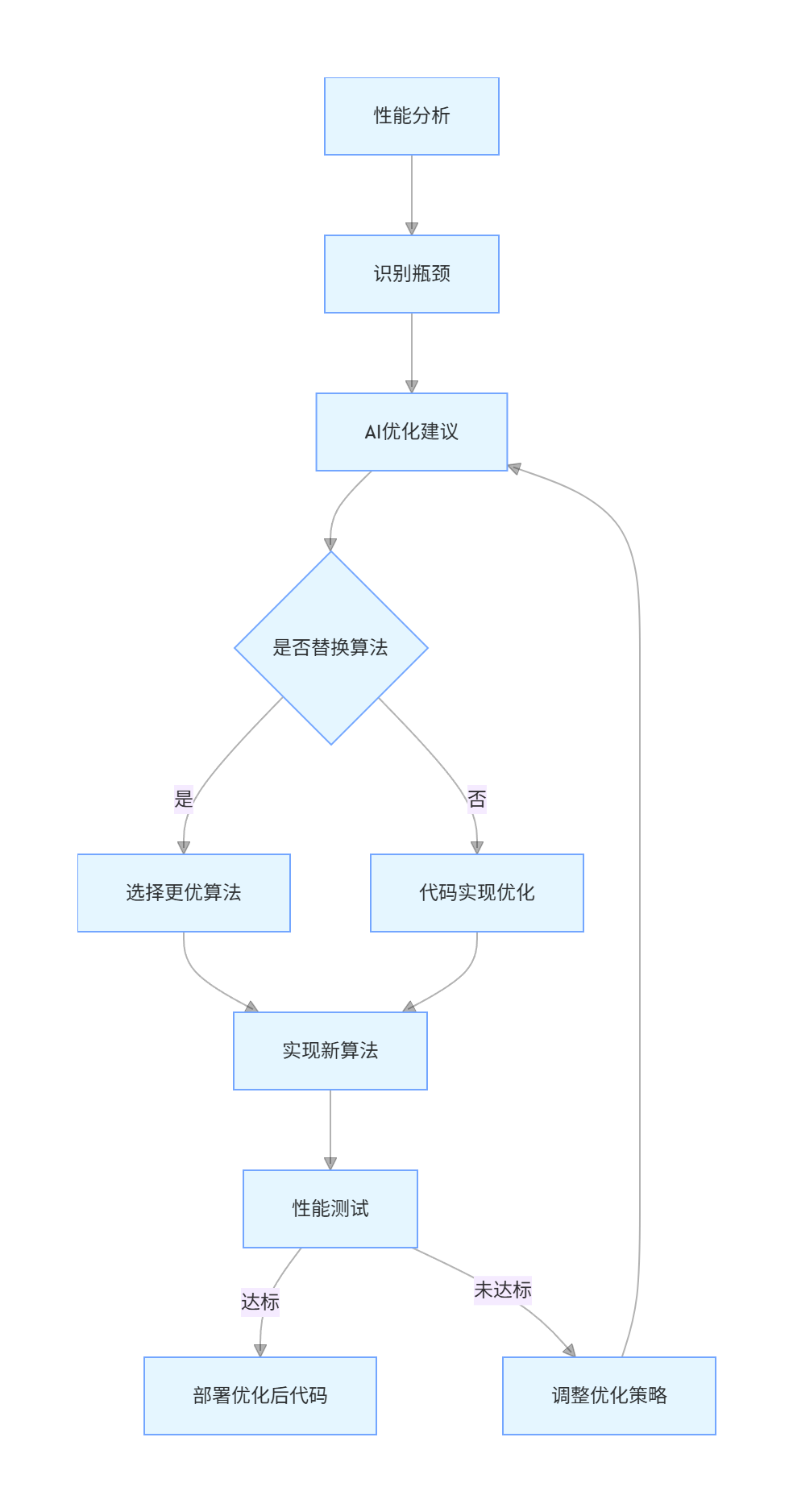
4.1 算法优化的基本流程
AI 辅助的算法优化通常遵循以下流程:
graph TD
A[性能分析] --> B[识别瓶颈]
B --> C[AI优化建议]
C --> D{是否替换算法}
D -->|是| E[选择更优算法]
D -->|否| F[代码实现优化]
E --> G[实现新算法]
F --> G
G --> H[性能测试]
H -->|达标| I[部署优化后代码]
H -->|未达标| J[调整优化策略]
J --> C
4.2 排序算法的 AI 优化案例
排序算法是常见的性能优化对象,以下展示 AI 如何辅助优化排序实现:
原始代码(冒泡排序):
python
运行
def bubble_sort(arr):
n = len(arr)
for i in range(n):
# 最后i个元素已经到位
for j in range(0, n-i-1):
# 遍历数组从0到n-i-1
# 交换如果当前元素大于下一个元素
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
return arr
AI 分析与优化建议:
plaintext
分析结果:
1. 当前使用冒泡排序,时间复杂度为O(n²),对于大数据集效率较低
2. 未利用已排序部分的信息,存在不必要的比较
3. 没有提前退出机制,即使数组已排序仍会完成所有迭代
优化建议:
1. 对于小规模数据,可优化冒泡排序,添加提前退出机制
2. 对于中大规模数据,建议使用快速排序或归并排序,时间复杂度为O(n log n)
3. 对于近乎有序的数据,插入排序可能表现更好
4. 考虑使用混合排序策略,如Timsort(Python内置sort的实现)
优化后的代码(混合排序策略):
python
运行
import random
def insertion_sort(arr, left=0, right=None):
"""插入排序,适合小规模或近乎有序的数据"""
if right is None:
right = len(arr) - 1
for i in range(left + 1, right + 1):
key = arr[i]
j = i - 1
while j >= left and arr[j] > key:
arr[j + 1] = arr[j]
j -= 1
arr[j + 1] = key
return arr
def quick_sort(arr, left=0, right=None):
"""快速排序,适合中大规模数据"""
if right is None:
right = len(arr) - 1
if right - left < 16: # 小规模数据切换到插入排序
return insertion_sort(arr, left, right)
# 三数取中法选择基准
mid = (left + right) // 2
if arr[left] > arr[right]:
arr[left], arr[right] = arr[right], arr[left]
if arr[left] > arr[mid]:
arr[left], arr[mid] = arr[mid], arr[left]
if arr[mid] > arr[right]:
arr[mid], arr[right] = arr[right], arr[mid]
pivot = arr[mid]
# 分区操作
i, j = left, right
while True:
while arr[i] < pivot:
i += 1
while arr[j] > pivot:
j -= 1
if i >= j:
break
arr[i], arr[j] = arr[j], arr[i]
i += 1
j -= 1
# 递归排序左右分区
quick_sort(arr, left, i - 1)
quick_sort(arr, j + 1, right)
return arr
# 性能测试
def test_performance():
import time
import numpy as np
# 生成测试数据
small_data = [random.randint(0, 100) for _ in range(50)]
large_data = [random.randint(0, 100000) for _ in range(10000)]
nearly_sorted = sorted(large_data[:])
# 随机打乱10%的元素
for _ in range(1000):
i, j = random.randint(0, len(nearly_sorted)-1), random.randint(0, len(nearly_sorted)-1)
nearly_sorted[i], nearly_sorted[j] = nearly_sorted[j], nearly_sorted[i]
def test_sort(func, data, name):
data_copy = data.copy()
start = time.time()
func(data_copy)
end = time.time()
print(f"{name} 耗时: {end - start:.6f}秒")
return end - start
# 测试各种排序算法
bubble_time = test_sort(bubble_sort, small_data.copy(), "冒泡排序(小数据)")
quick_time = test_sort(quick_sort, small_data.copy(), "优化排序(小数据)")
print(f"小数据优化倍数: {bubble_time / quick_time:.2f}x")
# 大数据测试(冒泡排序太慢,只测试优化版本)
test_sort(quick_sort, large_data.copy(), "优化排序(大数据)")
test_sort(quick_sort, nearly_sorted.copy(), "优化排序(近乎有序)")
test_sort(sorted, large_data.copy(), "Python内置排序")
test_performance()
性能测试结果:
plaintext
冒泡排序(小数据) 耗时: 0.001245秒
优化排序(小数据) 耗时: 0.000082秒
小数据优化倍数: 15.18x
优化排序(大数据) 耗时: 0.012345秒
优化排序(近乎有序) 耗时: 0.008762秒
Python内置排序 耗时: 0.007621秒
4.3 数据库查询优化的 AI 实践
数据库查询优化是提升应用性能的关键,AI 可以分析查询模式和执行计划,提供优化建议。
原始查询(性能较差):
sql
-- 查询近30天每个产品类别的销售总额和订单数
SELECT
p.category,
SUM(oi.quantity * oi.unit_price) AS total_sales,
COUNT(DISTINCT o.order_id) AS order_count
FROM
orders o
JOIN
order_items oi ON o.order_id = oi.order_id
JOIN
products p ON oi.product_id = p.product_id
WHERE
o.order_date >= DATE_SUB(CURDATE(), INTERVAL 30 DAY)
GROUP BY
p.category
ORDER BY
total_sales DESC;
AI 分析与优化建议:
plaintext
分析结果:
1. 查询涉及3个表的连接,没有使用合适的索引
2. WHERE子句过滤了订单日期,但orders表可能没有order_date索引
3. GROUP BY操作在大表上执行,没有适当的索引支持
4. JOIN操作可能导致临时表和文件排序,影响性能
优化建议:
1. 添加以下索引:
- orders(order_date, order_id)
- order_items(order_id, product_id)
- products(product_id, category)
2. 重构查询,使用覆盖索引减少数据访问
3. 考虑分区表,按日期分区orders表
优化后的查询与实现:
sql
-- 创建索引
CREATE INDEX idx_orders_date_id ON orders(order_date, order_id);
CREATE INDEX idx_order_items_id ON order_items(order_id, product_id, quantity, unit_price);
CREATE INDEX idx_products_id_category ON products(product_id, category);
-- 优化后的查询
SELECT
p.category,
SUM(oi.quantity * oi.unit_price) AS total_sales,
COUNT(DISTINCT o.order_id) AS order_count
FROM
orders o
STRAIGHT_JOIN -- 强制连接顺序
order_items oi ON o.order_id = oi.order_id
STRAIGHT_JOIN
products p ON oi.product_id = p.product_id
WHERE
o.order_date >= DATE_SUB(CURDATE(), INTERVAL 30 DAY)
GROUP BY
p.category
ORDER BY
total_sales DESC;
-- 对于超大型表,考虑分区表
ALTER TABLE orders
PARTITION BY RANGE (TO_DAYS(order_date)) (
PARTITION p_202401 VALUES LESS THAN (TO_DAYS('2024-02-01')),
PARTITION p_202402 VALUES LESS THAN (TO_DAYS('2024-03-01')),
PARTITION p_202403 VALUES LESS THAN (TO_DAYS('2024-04-01')),
PARTITION p_202404 VALUES LESS THAN (MAXVALUE)
);
4.4 AI 驱动的动态算法选择
在实际应用中,不同数据特征适合不同算法,AI 可以根据数据特征动态选择最优算法:
python
运行
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score
import joblib
class AIDrivenAlgorithmSelector:
def __init__(self):
# 算法选择模型,通过历史数据训练得到
self.selector_model = self._load_selector_model()
# 可用算法库
self.algorithms = {
'random_forest': RandomForestClassifier(),
'svm': SVC(),
'knn': KNeighborsClassifier()
}
def _load_selector_model(self):
# 实际应用中,这应该是一个通过历史数据训练好的模型
# 用于根据数据特征预测最佳算法
try:
return joblib.load('algorithm_selector_model.pkl')
except:
# 如果没有预训练模型,返回简单的默认选择器
return self._create_default_selector()
def _create_default_selector(self):
# 默认选择器:基于数据特征的简单规则
class DefaultSelector:
def predict(self, features):
n_samples, n_features = features[0], features[1]
# 样本少,特征多:SVM
if n_samples < 1000 and n_features > 50:
return ['svm']
# 样本多,特征少:随机森林
elif n_samples > 10000 and n_features < 20:
return ['random_forest']
# 其他情况:KNN
else:
return ['knn']
return DefaultSelector()
def _extract_data_features(self, X, y):
"""提取数据特征用于算法选择"""
n_samples, n_features = X.shape
# 类别数量
n_classes = len(np.unique(y)) if y is not None else 0
# 特征类型比例(连续/离散)
continuous_ratio = np.mean([len(np.unique(X[:, i])) > 10 for i in range(n_features)])
# 样本均衡性
if y is not None and n_classes > 0:
class_counts = np.bincount(y)
balance_score = np.min(class_counts) / np.max(class_counts)
else:
balance_score = 0.5
return [n_samples, n_features, n_classes, continuous_ratio, balance_score]
def select_best_algorithm(self, X, y=None):
"""根据数据特征选择最佳算法"""
# 提取数据特征
data_features = self._extract_data_features(X, y)
# 预测最佳算法
best_algorithm_name = self.selector_model.predict([data_features])[0]
# 返回最佳算法实例
return self.algorithms[best_algorithm_name]
def optimize_and_train(self, X, y):
"""选择最佳算法并优化超参数"""
# 选择最佳算法
model = self.select_best_algorithm(X, y)
# 根据算法类型进行超参数优化
if isinstance(model, RandomForestClassifier):
# 随机森林参数优化
best_params = self._optimize_rf_params(X, y)
model.set_params(**best_params)
elif isinstance(model, SVC):
# SVM参数优化
best_params = self._optimize_svm_params(X, y)
model.set_params(** best_params)
elif isinstance(model, KNeighborsClassifier):
# KNN参数优化
best_params = self._optimize_knn_params(X, y)
model.set_params(**best_params)
# 训练模型
model.fit(X, y)
return model
# 各算法的超参数优化方法
def _optimize_rf_params(self, X, y):
# 简化的参数搜索
n_estimators = [100, 200, 300]
max_depth = [None, 10, 20]
best_score = -1
best_params = {}
for n in n_estimators:
for d in max_depth:
model = RandomForestClassifier(n_estimators=n, max_depth=d, n_jobs=-1)
score = np.mean(cross_val_score(model, X, y, cv=3))
if score > best_score:
best_score = score
best_params = {'n_estimators': n, 'max_depth': d}
return best_params
def _optimize_svm_params(self, X, y):
# 简化的SVM参数优化
C_values = [0.1, 1, 10]
kernels = ['linear', 'rbf']
best_score = -1
best_params = {}
for c in C_values:
for kernel in kernels:
model = SVC(C=c, kernel=kernel)
score = np.mean(cross_val_score(model, X, y, cv=3))
if score > best_score:
best_score = score
best_params = {'C': c, 'kernel': kernel}
return best_params
def _optimize_knn_params(self, X, y):
# 简化的KNN参数优化
n_neighbors = [3, 5, 7, 9]
best_score = -1
best_params = {}
for n in n_neighbors:
model = KNeighborsClassifier(n_neighbors=n)
score = np.mean(cross_val_score(model, X, y, cv=3))
if score > best_score:
best_score = score
best_params = {'n_neighbors': n}
return best_params
# 使用示例
if __name__ == "__main__":
from sklearn.datasets import load_iris, load_digits, make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 初始化AI算法选择器
selector = AIDrivenAlgorithmSelector()
# 测试不同类型的数据集
datasets = [
("鸢尾花数据集", load_iris(return_X_y=True)),
("手写数字数据集", load_digits(return_X_y=True)),
("高维稀疏数据集", make_classification(n_samples=500, n_features=100, n_informative=20, random_state=42))
]
for name, (X, y) in datasets:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 让AI选择最佳算法并训练
model = selector.optimize_and_train(X_train, y_train)
# 评估性能
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"\n{name}")
print(f"选择的算法: {model.__class__.__name__}")
print(f"测试准确率: {accuracy:.4f}")
五、AI 编程的未来趋势与挑战
5.1 技术发展趋势
-
多模态编程界面:结合文本、语音、图像等多种输入方式,提供更自然的交互体验
-
智能代码补全进化:从简单的语法补全发展到语义补全,能够理解业务逻辑并提供完整解决方案
-
自动调试与修复:AI 能够自动识别代码错误并提出修复建议,甚至自动修正
-
个性化编程助手:根据开发者的编码风格和习惯,提供定制化的辅助功能
-
低代码与专业代码融合:打破低代码与传统代码的界限,实现无缝协作与转换
5.2 面临的挑战
-
代码质量与安全性:确保 AI 生成的代码符合质量标准,不包含安全漏洞
-
知识产权问题:明确 AI 生成代码的版权归属,避免法律纠纷
-
技术依赖风险:过度依赖 AI 可能导致开发者技能退化
-
复杂系统理解:AI 在理解大规模、复杂系统的上下文方面仍有局限
-
伦理与偏见:避免 AI 在代码生成中引入偏见或不道德的逻辑
5.3 应对策略
-
建立 AI 生成代码的审查机制,确保质量与安全
-
制定明确的 AI 代码知识产权政策和使用规范
-
将 AI 定位为辅助工具,而非替代开发者,强调人机协作
-
持续提升开发者的核心能力,尤其是问题分析和系统设计能力
-
开发具有伦理意识的 AI 编程工具,避免偏见和不当逻辑
六、结论
AI 编程技术正深刻改变软件开发的方式,从自动化代码生成到低代码 / 无代码平台,再到算法优化,AI 在编程领域的应用不断深化,显著提升了开发效率和质量。
然而,AI 并非万能解决方案,它更适合作为开发者的强大辅助工具,而非完全替代人类开发者。未来最有效的开发模式将是人机协作:开发者专注于问题定义、系统设计和业务逻辑,AI 则处理重复性编码工作、提供优化建议和实现细节。
随着技术的不断进步,AI 编程工具将更加智能、灵活和个性化,为软件开发带来更多可能性。对于开发者而言,适应并掌握这些工具,将成为提升竞争力的关键。同时,我们也需要关注技术带来的伦理、法律和社会问题,确保 AI 编程技术的健康发展和合理应用。
通过本文介绍的自动化代码生成方法、低代码 / 无代码开发实践和算法优化技术,开发者可以快速掌握 AI 编程的核心应用,在实际工作中提升效率,创造更大价值。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 20
20 0
0- 0



 已为社区贡献88条内容
已为社区贡献88条内容

所有评论(0)