
24 小时深度体验 Gemini 3:从生成式 UI 到 Antigravity 重构 AI 开发流程,看谷歌模型新突破
全面解析 Gemini 3 Pro 带来的三大能力提升:以 Visual Layout 与 Dynamic View 为代表的生成式 UI 能力、AI 编程工具 Antigravity 的底层机制与系统提示词解析,以及结合系统卡信息与研发团队观点对基础模型训练策略的观察。
作为一个不喜欢追热点的人,Gemini 3 Pro 模型确实给了我太大的惊喜,昨天花了一整天时间在使用,不得不写一篇文章来全方位夸夸了,本文要聊的内容主要涵盖三个方面:一是以 Visual Layout 和 Dynamic View 功能为代表的生成式 UI 能力解析;二是对谷歌 AI 编程工具 Antigravity 的解读,包括对其系统提示词的逆向分析;三是结合官方发布的模型系统卡及主要研发负责人的公开言论,从侧面探讨其在训练方法上的创新之处。
点击原文Gemini 3 带给我的惊喜:从生成式 UI 能力到 AI 原生IED Antigravity 、基础模型的突破,获得更好阅读体验。
生成式 UI 能力 :AI 交互的未来
功能说明
生成式 UI(Generative UI)这个概念不新鲜,不止谷歌在搞,之前的 ChatGPT Pulse 就是一种尝试,已经有很多人认为这代表了未来我们与 AI 互动的新方式,毕竟传统的 AI 交互方式存在很大局限,因为无论语言模型多强大,用户最终看到的仍是线性文本输出,这对于复杂知识、空间关系或交互任务的呈现极为不利。简单来说,就是让 AI 不只是用文字或图片来回答你的问题,而是能直接为你创建一个可以操作的、可视化的界面,就像 DeepMind 研究团队讲的 “如果 AI 可以理解我的问题,为什么不能直接为我生成一个合适的界面去解决它?”
生成式 UI 能力首次在 Gemini 应用的两个实验功能中上线,分别是动态视图(Dynamic View)和视觉布局(Visual Layout)(是随机掉落的,我问了周边的朋友,均没有被灰度到 🫠),不过可以在谷歌搜索的 AI 模式(切换为 Thinking 选项)中体验到,但范围也仅限于美国地区的 Google AI Pro 和 Ultra 订阅用户,这里我用的美区谷歌账号和美区 🪜 解决的。
使用体验
视觉布局
首先是视觉布局功能,我体验下来就是结构化组织多模态的内容。 以“上海到成都的行程计划”为例,如截图所示,信息通过图文、表格等形式按最优呈现方式清晰展示(部分案例还包含视频或音频讲解,这个例子不太需要)。最牛的是交通方式部分提供可点击链接,直接跳转至机票或高铁票预订页面;推荐餐馆则标注其在谷歌地图上的位置及店铺评分(这个在国内用处不大)。

动态视图
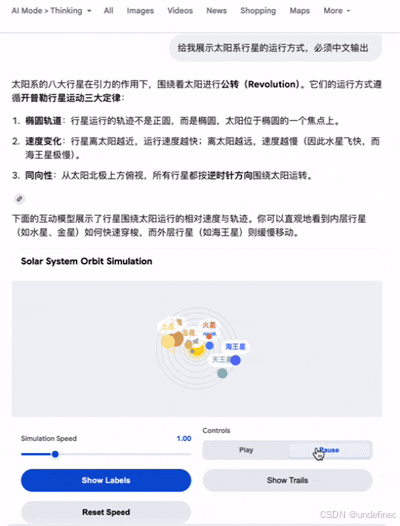
使用动态视图时,Gemini 会利用其编程能力,为每个请求动态生成定制的交互式界面。这里我想了解“太阳系行星的运行方式”,Gemini 自动生成了一个直观的交互工具,支持控制行星名称的显示、运行速度调节,以及是否启用行星运动轨迹的拖尾效果(细节满满,绝了!)。此外,Gemini 能够根据用户的背景和需求调整内容呈现方式:向 5 岁儿童与成年人解释同一概念时,所采用的内容深度和交互形式截然不同;同样,展示企业社交媒体内容与个人内容时,界面设计也各不相同。
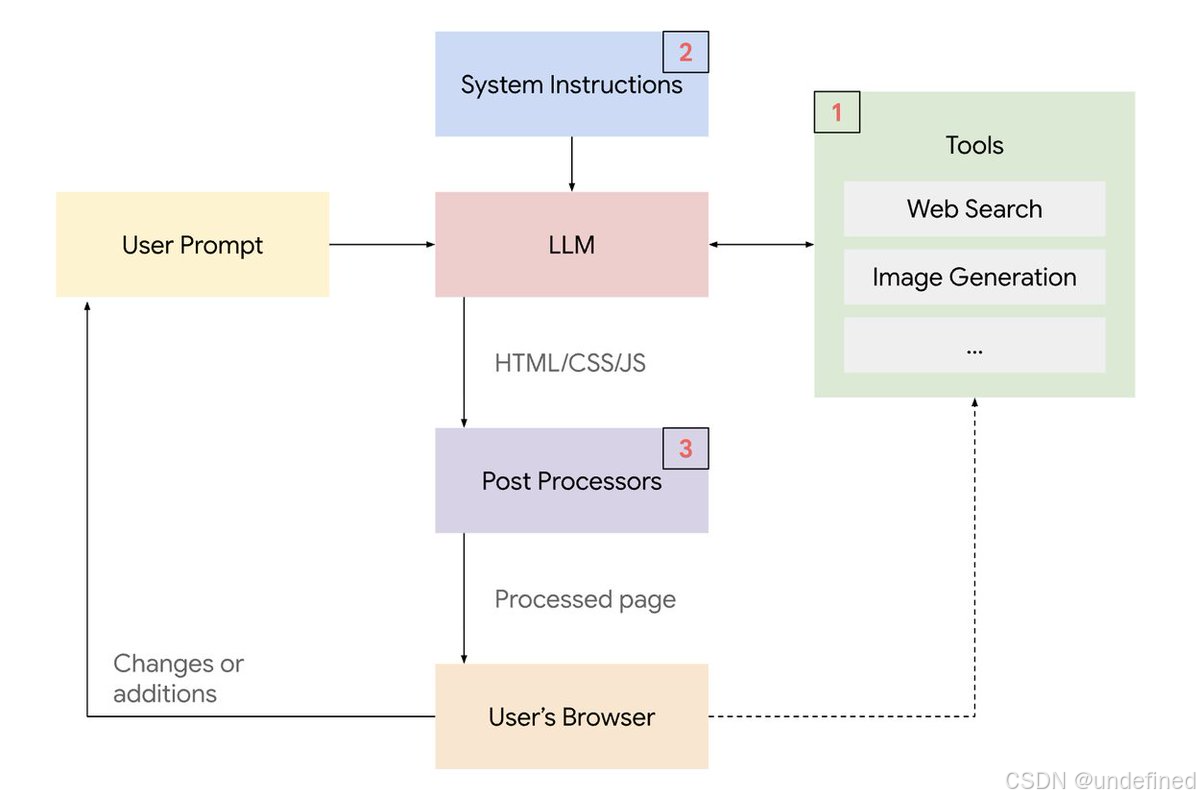
官方在论文《Generative UI: LLMs are Effective UI Generators》中介绍了生成式 UI 能力实现架构,核心由三部分构成:
- 工具访问:AI 可调用外部工具(如图像生成系统、搜索引擎、代码执行模块等),利用其结果生成更高质量的内容,或直接将输出传递至用户浏览器以降低延迟;
- 系统级指令集:AI 在后台接收明确的系统指令,规定界面类型、代码格式、设计风格等要求,确保生成内容结构清晰、风格统一且可正确运行;
- 输出后处理:AI 生成结果后,经多层算法进行修正与安全检查,包括验证代码可执行性、修复常见错误、保持视觉一致性以及确保内容安全。
点击原文 Gemini 3 带给我的惊喜:从生成式 UI 能力到 AI 原生IED Antigravity 、基础模型的突破,获得更好阅读体验。
Antigravity 还引入产物概念,会生成任务列表、实施计划、截图和浏览器录屏等可验证的成果,方便开发者反馈和调整。
系统提示词
Antigravity 系统提示词包括用户设定 (identity,user_information,user_rules),系统功能 (tool_calling,web_application_development,workflows,function_calls)和上下文管理(knowledge_discovery, persistent_context) 三大块 9 个部分,长度在 1 万 token 作用,使用 xml 标签进行区分(完整的提示词后台回复 「Antigravity 系统提示词」 获取),这里就不全贴了,只贴关键的部分。
Antigravity 内置工具

点击原文Gemini 3 带给我的惊喜:从生成式 UI 能力到 AI 原生IED Antigravity 、基础模型的突破,获得更好阅读体验。
使用体验
Antigravity 有 Panning 和 Fast 两种模式,支持的模型包括 Gemini 3 Pro 和 Claude Sonnet 4.5 系列,GPT 开源模型(我选用了 Fast 模式和 Gemini 3 Pro(Low)模型用来测试)。
这里我复刻了一个在线的带动效的卡片,我的做法是录屏并转换为 gif 文件后上传,让其参考实现。
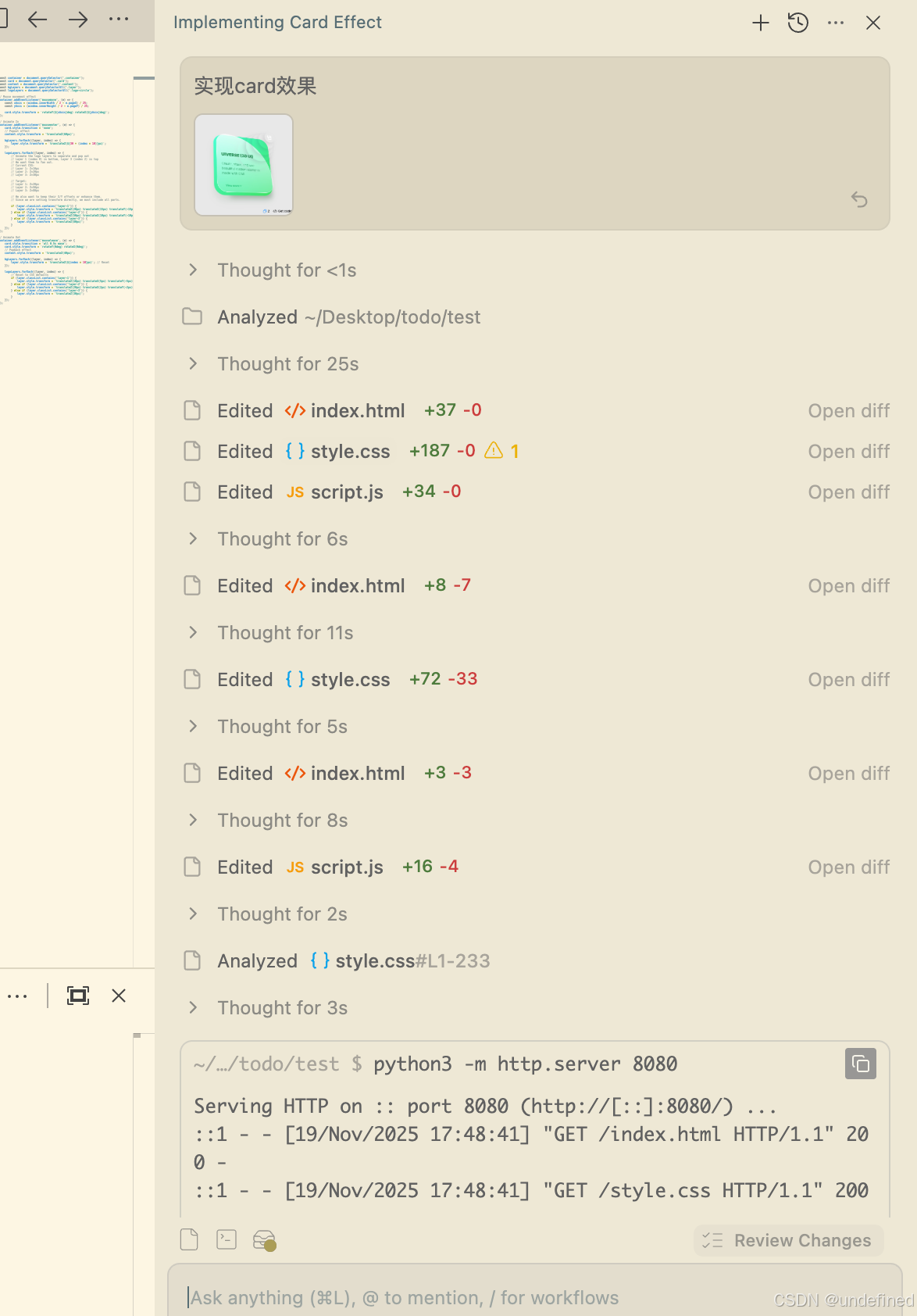
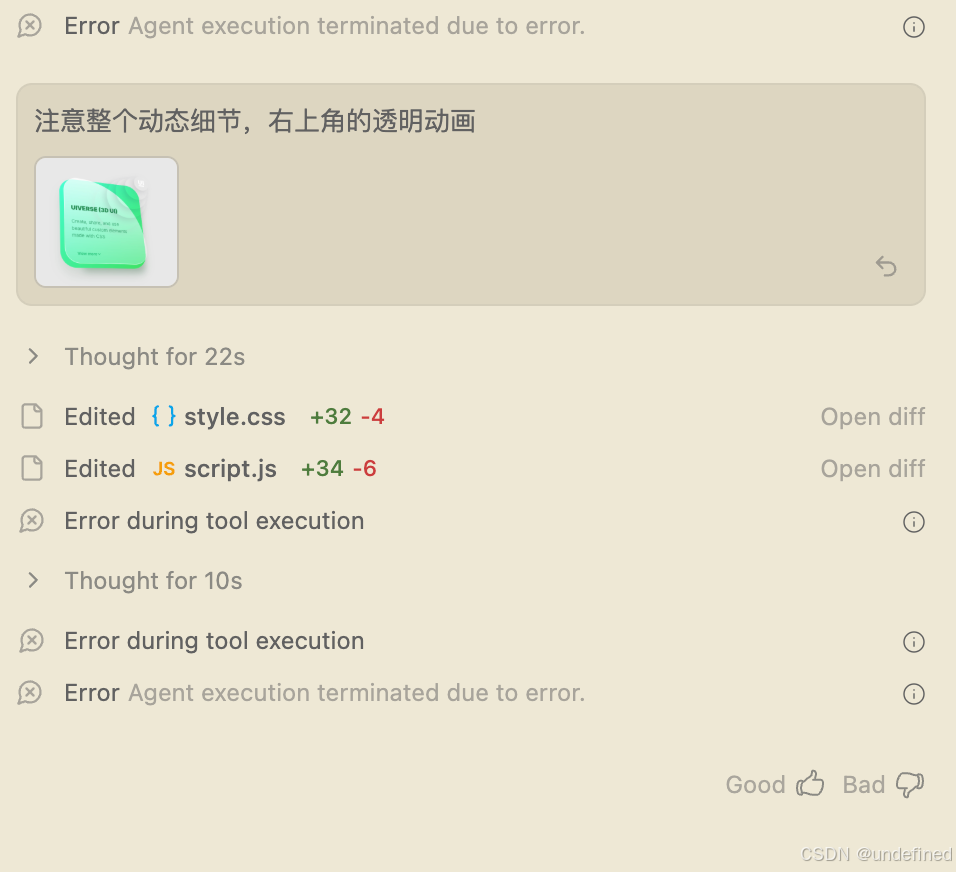
最终实现效果如下,动效细节还原度较高,尤其是表层透明光线的动画效果。后续我发现一个技巧:Antigravity 内置的 read_url_content 工具支持直接读取远程内容。对于复杂的动效实现,可将录屏结果上传至 OSS,并提供文件链接供参考。相比转换为 GIF(存在压缩问题,可能导致复杂动效细节丢失),这种方式能更好地保留原始质量。

至于这里为什么没用常见的测试方式(如直接生成完整的 Windows 操作系统或整个后台页面),我认为 AI 生成结果的可编辑性应优先于一次性输出,编辑能力是核心,关键在于让用户能够精细调整,而非每次推倒重来。因此,将范围限定在 Card 组件级别,不仅便于当前迭代,也为后续优化提供便利。
点击原文Gemini 3 带给我的惊喜:从生成式 UI 能力到 AI 原生IED Antigravity 、基础模型的突破,获得更好阅读体验。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)