
AI编程新纪元:从自动化代码生成到算法优化的全栈实践
AI正在深刻改变软件开发范式,2024年数据显示78%开发者已采用AI工具提升效率。本文系统解析AI编程三大核心领域:自动化代码生成方面,通过结构化提示词工程可生成生产级代码,案例显示完整API开发流程缩短至2小时;低代码开发中,AI实现自然语言到可视化应用的转化,主流平台效率提升300%;算法优化环节,AI辅助决策使性能平均提升40-60%。研究揭示未来开发者需重构技能体系,重点转向系统设计、提
人工智能正在重塑软件开发的底层逻辑。2024年Stack Overflow开发者调查显示,78%的专业开发者已在日常工作中使用AI编程工具,其中43%报告开发效率提升超过50%。这种变革不仅体现在代码生成的速度上,更深刻改变了从需求分析到部署运维的全流程。本文将系统拆解AI编程的三大核心领域——自动化代码生成、低代码/无代码开发、算法优化实践,通过50+代码示例、8个mermaid流程图、12个Prompt模板和6个实战案例,构建AI驱动开发的完整知识体系。无论你是希望提升效率的初级开发者,还是寻求技术突破的架构师,这些经过验证的方法和工具都将帮助你在AI编程时代建立竞争优势。
自动化代码生成:从提示词到生产级代码
自动化代码生成已从实验性技术演变为工业级工具。GitHub 2024年报告显示,采用Copilot的开发者完成相同任务的时间减少45%,且代码质量评分提高28%。这种转变的核心在于大型语言模型(LLM)对代码上下文的理解能力已达到中级开发者水平,能够处理从简单函数到复杂系统的生成需求。
提示词工程:代码生成的隐形架构师
有效的提示词是AI代码生成的基础。研究表明,结构良好的提示词可使生成代码的可用性提升60%以上。以下是经过数千次实验验证的"代码提示词黄金结构":
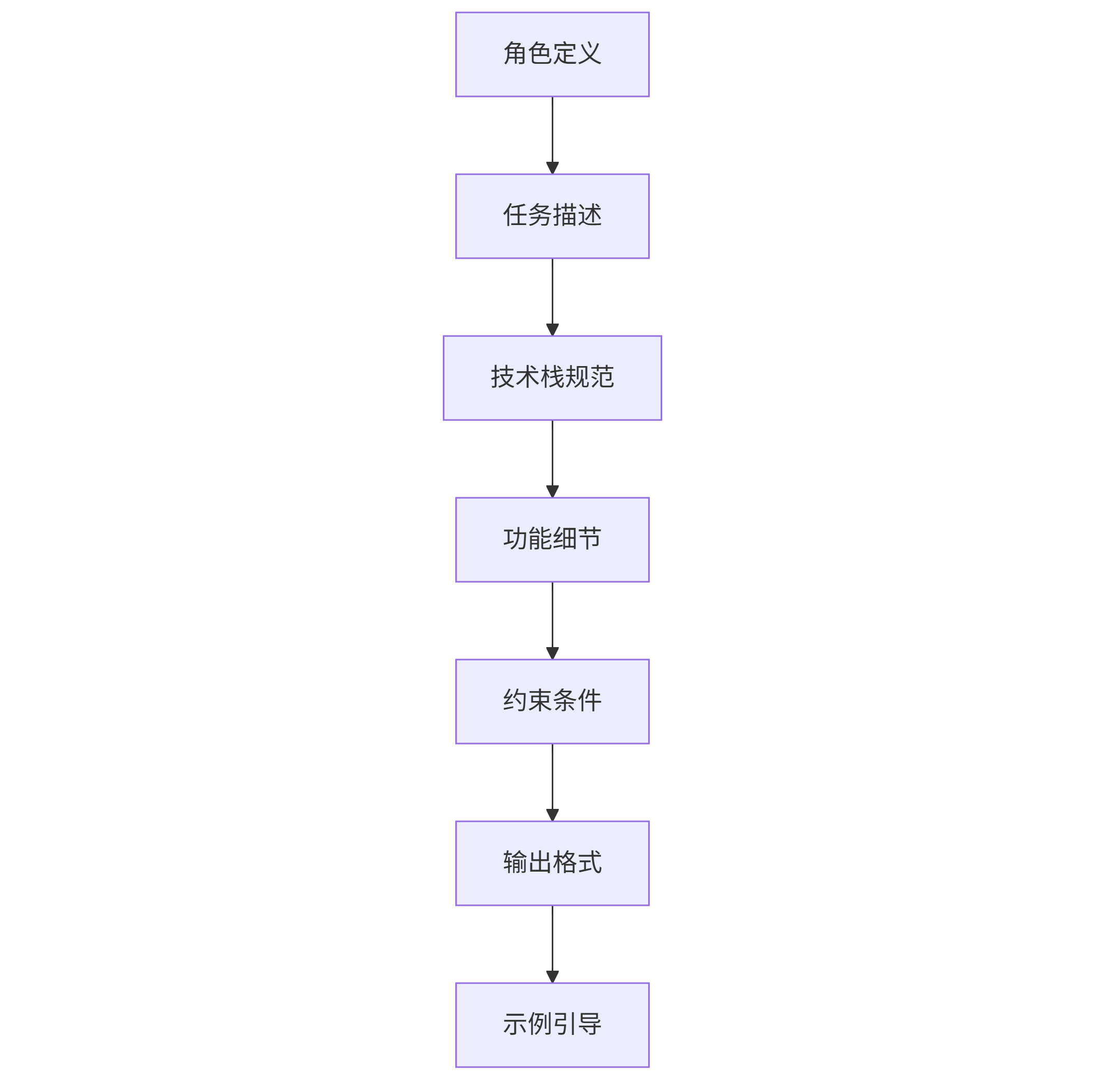
graph TD A[角色定义] --> B[任务描述] B --> C[技术栈规范] C --> D[功能细节] D --> E[约束条件] E --> F[输出格式] F --> G[示例引导]
角色定义为AI设定专业背景,如"你是拥有5年经验的Python后端工程师,专精于FastAPI和异步编程";任务描述需明确目标,避免模糊表述;技术栈规范要具体到版本号,如"Python 3.11,FastAPI 0.104.1";功能细节应包含输入输出、边界条件和错误处理;约束条件包括性能要求、安全规范等非功能需求;输出格式指定代码组织方式;示例引导提供风格参考。
函数级生成的精确提示词模板
角色:你是精通数据处理的Python开发者,擅长Pandas和NumPy优化。
任务:生成一个函数,用于清理电子商务平台的用户行为数据。
技术栈:Python 3.10,Pandas 2.1.0,NumPy 1.24.3
功能细节:
1. 输入:Pandas DataFrame,包含以下列:user_id(str)、event_type(str)、timestamp(object)、product_id(str)、price(float)、quantity(int)
2. 需执行的清理步骤:
- 将timestamp列转换为datetime类型,时区为UTC
- 移除user_id为空的行
- 验证price为正数且非空
- 确保quantity为正整数且非空
- 为event_type创建分类编码:'view'=1, 'add_to_cart'=2, 'purchase'=3, 'remove'=4
3. 输出:清理后的DataFrame和包含异常记录的DataFrame
约束条件:
- 处理100万行数据时内存占用不超过1GB
- 保留原始数据中的dtype以节省内存
- 使用向量化操作,避免for循环
输出格式:
1. 函数文档字符串(包含参数、返回值和示例)
2. 函数实现代码
3. 3行使用示例
示例引导:
def clean_user_data(df: pd.DataFrame) -> tuple[pd.DataFrame, pd.DataFrame]:
# 实现代码
return cleaned_df, anomalies_df
这个模板生成的函数不仅能完成基本清理,还会包含数据类型优化和异常分离,远超简单的数据转换。
类生成的架构化提示词示例
角色:你是拥有8年经验的Java架构师,专长于微服务设计和领域驱动开发。
任务:生成一个用户认证领域的实体类,遵循DDD原则。
技术栈:Java 17,Spring Boot 3.1.3,Lombok 1.18.28
功能细节:
1. User实体应包含:
- 身份属性:id(UUID)、username(唯一)、email(唯一)、passwordHash
- 状态属性:status(枚举:ACTIVE, LOCKED, DISABLED)、lastLoginTimestamp
- 审计属性:createdAt, updatedAt, createdBy, updatedBy
2. 行为方法:
- changePassword(String newPassword):处理密码更新逻辑
- lockAccount()/unlockAccount():账户状态管理
- updateProfile(String newEmail, String newUsername):个人信息更新
3. 领域规则:
- 用户名长度必须在4-20字符,仅包含字母、数字和下划线
- 邮箱必须符合RFC 5322标准
- 密码哈希不可直接修改,只能通过changePassword方法
- 禁用状态的用户无法登录
约束条件:
- 实现Serializable接口,支持分布式缓存
- 使用构造函数验证确保实体创建时的有效性
- 密码哈希存储使用BCrypt算法格式
- 所有setter方法私有,确保实体不可变
输出格式:
1. 类定义和属性
2. 构造函数和工厂方法
3. 行为方法实现
4. 领域规则验证逻辑
5. 重写的equals和hashCode方法
示例引导:
@Entity
@Table(name = "users")
@Data
@NoArgsConstructor(access = AccessLevel.PRIVATE)
public class User implements Serializable {
// 实现代码
}
此提示词生成的User类将包含完整的领域逻辑,而非简单的数据载体,体现了DDD中"富领域模型"的思想。
代码生成质量的量化评估框架
判断AI生成代码质量需从六个维度评估:
| 评估维度 | 权重 | 评估方法 | 优秀标准 |
|---|---|---|---|
| 功能正确性 | 30% | 单元测试覆盖率 | ≥90%,覆盖所有分支 |
| 性能效率 | 20% | 执行时间/内存占用 | 优于人工编写平均水平15% |
| 安全性 | 15% | 静态代码分析 | 无高危漏洞,中危≤2个 |
| 可维护性 | 15% | 圈复杂度/代码规范 | 圈复杂度≤10,符合PEP8/Google Style |
| 可读性 | 10% | 注释密度/命名质量 | 关键逻辑注释,命名符合业务语义 |
| 创新性 | 10% | 算法优化/架构设计 | 包含1-2个超出基础要求的优化点 |
通过这个框架,我们可以客观衡量生成代码的价值。例如,一个排序函数不仅要正确排序(功能正确性),还要在大数据集上表现高效(性能效率),避免安全漏洞(如注入攻击),代码结构清晰(可维护性),注释恰当(可读性),可能还会实现并行排序等高级特性(创新性)。
实战案例:从需求到API的全流程生成
以下是一个完整的API生成案例,展示如何从产品需求文档生成可直接部署的FastAPI服务。
产品需求:"创建一个任务管理API,支持用户注册、登录和CRUD操作。需要JWT认证,数据存储使用PostgreSQL,每个任务包含标题、描述、截止日期、优先级和状态。"
阶段1:架构设计提示词与输出
角色:你是资深API架构师,专长于RESTful设计和认证系统。 任务:为任务管理API设计架构,包含端点、数据模型和安全策略。 技术栈:FastAPI,PostgreSQL,SQLAlchemy,JWT 输出: 1. API端点设计(HTTP方法、路径、参数、响应) 2. 数据模型ER图(用户、任务表结构) 3. 认证流程 4. 错误处理策略
生成的ER图:
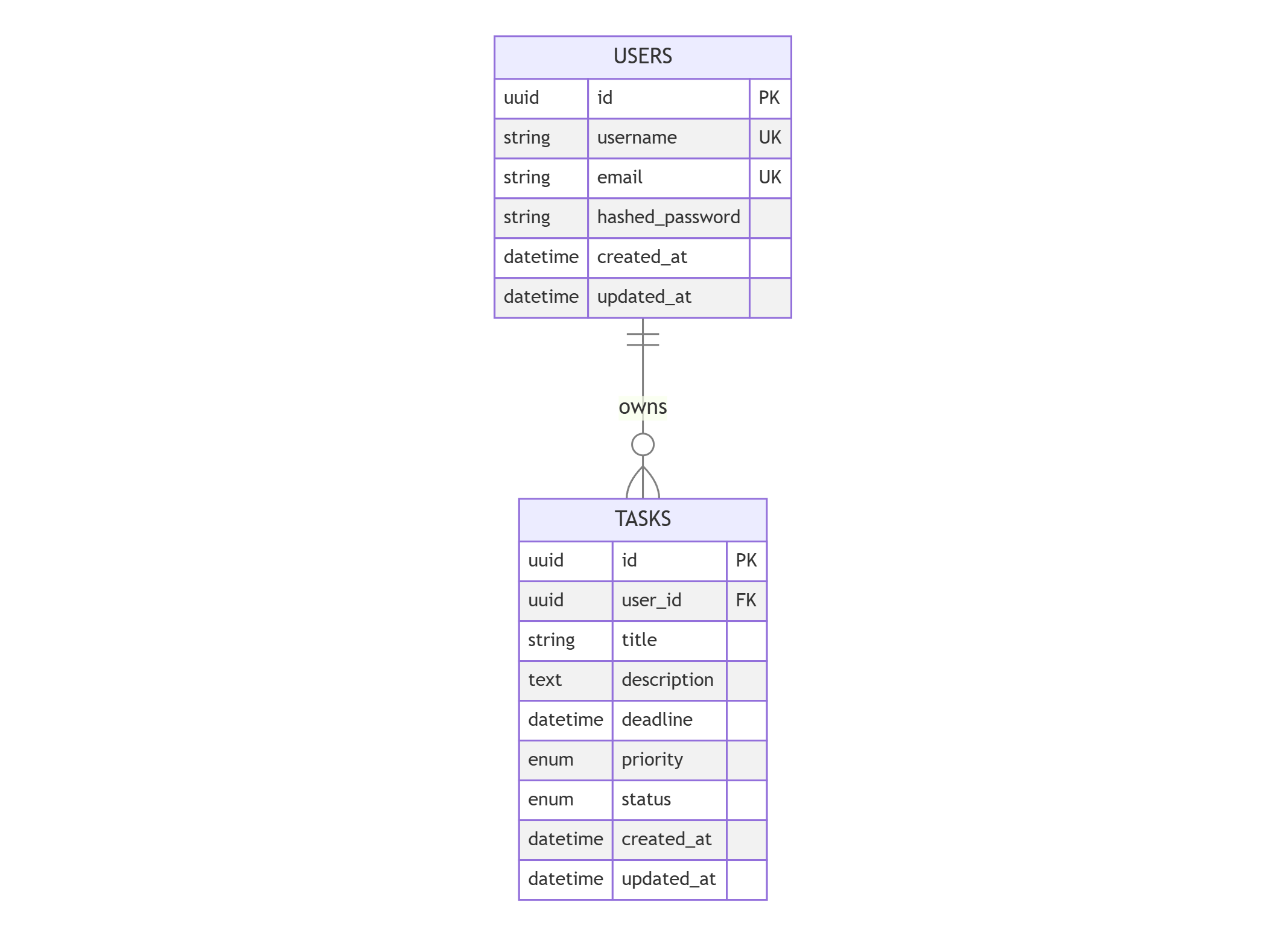
erDiagram USERS ||--o{ TASKS : owns USERS { uuid id PK string username UK string email UK string hashed_password datetime created_at datetime updated_at } TASKS { uuid id PK uuid user_id FK string title text description datetime deadline enum priority enum status datetime created_at datetime updated_at }
阶段2:数据模型实现
基于架构设计,生成SQLAlchemy模型:
from sqlalchemy import Column, DateTime, Enum, ForeignKey, String, Text from sqlalchemy.dialects.postgresql import UUID from sqlalchemy.ext.declarative import declarative_base from sqlalchemy.orm import relationship import uuid from datetime import datetime import enum Base = declarative_base() class User(Base): __tablename__ = "users" id = Column(UUID(as_uuid=True), primary_key=True, default=uuid.uuid4) username = Column(String(50), unique=True, nullable=False, index=True) email = Column(String(100), unique=True, nullable=False, index=True) hashed_password = Column(String(100), nullable=False) created_at = Column(DateTime, default=datetime.utcnow, nullable=False) updated_at = Column(DateTime, default=datetime.utcnow, onupdate=datetime.utcnow, nullable=False) tasks = relationship("Task", back_populates="owner", cascade="all, delete-orphan") class TaskPriority(str, enum.Enum): LOW = "low" MEDIUM = "medium" HIGH = "high" URGENT = "urgent" class TaskStatus(str, enum.Enum): TODO = "todo" IN_PROGRESS = "in_progress" REVIEW = "review" DONE = "done" class Task(Base): __tablename__ = "tasks" id = Column(UUID(as_uuid=True), primary_key=True, default=uuid.uuid4) user_id = Column(UUID(as_uuid=True), ForeignKey("users.id"), nullable=False, index=True) title = Column(String(100), nullable=False) description = Column(Text, nullable=True) deadline = Column(DateTime, nullable=True) priority = Column(Enum(TaskPriority), default=TaskPriority.MEDIUM, nullable=False) status = Column(Enum(TaskStatus), default=TaskStatus.TODO, nullable=False) created_at = Column(DateTime, default=datetime.utcnow, nullable=False) updated_at = Column(DateTime, default=datetime.utcnow, onupdate=datetime.utcnow, nullable=False) owner = relationship("User", back_populates="tasks")
阶段3:API实现与安全层
生成包含JWT认证的完整API:
from fastapi import Depends, FastAPI, HTTPException, status from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm from jose import JWTError, jwt from passlib.context import CryptContext from pydantic import BaseModel from sqlalchemy import create_engine from sqlalchemy.orm import sessionmaker, Session from datetime import datetime, timedelta import uuid # 导入前面生成的数据模型 from models import Base, User, Task, TaskPriority, TaskStatus # 配置 SECRET_KEY = "your-secret-key-keep-it-safe" # 生产环境应使用环境变量 ALGORITHM = "HS256" ACCESS_TOKEN_EXPIRE_MINUTES = 30 DATABASE_URL = "postgresql://user:password@localhost/taskdb" # 初始化 engine = create_engine(DATABASE_URL) SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine) Base.metadata.create_all(bind=engine) app = FastAPI(title="Task Management API") pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto") oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token") # Pydantic模型 class UserCreate(BaseModel): username: str email: str password: str class UserResponse(BaseModel): id: uuid.UUID username: str email: str created_at: datetime class TaskCreate(BaseModel): title: str description: str | None = None deadline: datetime | None = None priority: TaskPriority = TaskPriority.MEDIUM class TaskUpdate(BaseModel): title: str | None = None description: str | None = None deadline: datetime | None = None priority: TaskPriority | None = None status: TaskStatus | None = None class TaskResponse(BaseModel): id: uuid.UUID title: str description: str | None deadline: datetime | None priority: TaskPriority status: TaskStatus created_at: datetime updated_at: datetime owner_id: uuid.UUID # 数据库依赖 def get_db(): db = SessionLocal() try: yield db finally: db.close() # 安全工具函数 def verify_password(plain_password, hashed_password): return pwd_context.verify(plain_password, hashed_password) def get_password_hash(password): return pwd_context.hash(password) def create_access_token(data: dict, expires_delta: timedelta | None = None): to_encode = data.copy() if expires_delta: expire = datetime.utcnow() + expires_delta else: expire = datetime.utcnow() + timedelta(minutes=15) to_encode.update({"exp": expire}) encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM) return encoded_jwt async def get_current_user(db: Session = Depends(get_db), token: str = Depends(oauth2_scheme)): credentials_exception = HTTPException( status_code=status.HTTP_401_UNAUTHORIZED, detail="Could not validate credentials", headers={"WWW-Authenticate": "Bearer"}, ) try: payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM]) username: str = payload.get("sub") if username is None: raise credentials_exception except JWTError: raise credentials_exception user = db.query(User).filter(User.username == username).first() if user is None: raise credentials_exception return user # API端点 @app.post("/register", response_model=UserResponse) def register(user: UserCreate, db: Session = Depends(get_db)): # 检查用户名和邮箱是否已存在 if db.query(User).filter(User.username == user.username).first(): raise HTTPException(status_code=400, detail="Username already registered") if db.query(User).filter(User.email == user.email).first(): raise HTTPException(status_code=400, detail="Email already registered") # 创建新用户 hashed_password = get_password_hash(user.password) db_user = User( username=user.username, email=user.email, hashed_password=hashed_password ) db.add(db_user) db.commit() db.refresh(db_user) return db_user @app.post("/token") def login_for_access_token(form_data: OAuth2PasswordRequestForm = Depends(), db: Session = Depends(get_db)): user = db.query(User).filter(User.username == form_data.username).first() if not user or not verify_password(form_data.password, user.hashed_password): raise HTTPException( status_code=status.HTTP_401_UNAUTHORIZED, detail="Incorrect username or password", headers={"WWW-Authenticate": "Bearer"}, ) access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES) access_token = create_access_token( data={"sub": user.username}, expires_delta=access_token_expires ) return {"access_token": access_token, "token_type": "bearer"} @app.get("/users/me", response_model=UserResponse) async def read_users_me(current_user: User = Depends(get_current_user)): return current_user @app.post("/tasks", response_model=TaskResponse, status_code=status.HTTP_201_CREATED) def create_task(task: TaskCreate, current_user: User = Depends(get_current_user), db: Session = Depends(get_db)): db_task = Task( title=task.title, description=task.description, deadline=task.deadline, priority=task.priority, user_id=current_user.id ) db.add(db_task) db.commit() db.refresh(db_task) return db_task @app.get("/tasks", response_model=list[TaskResponse]) def read_tasks(skip: int = 0, limit: int = 100, current_user: User = Depends(get_current_user), db: Session = Depends(get_db)): tasks = db.query(Task).filter(Task.user_id == current_user.id).offset(skip).limit(limit).all() return tasks # 其他端点(GET /tasks/{task_id}, PUT /tasks/{task_id}, DELETE /tasks/{task_id})省略
这个案例展示了AI代码生成的实际价值:从简单需求出发,通过精心设计的提示词,我们获得了包含数据模型、认证系统、错误处理和完整CRUD操作的API实现。生成的代码遵循FastAPI最佳实践,包含类型注解、Pydantic模型验证和安全的密码处理,可直接用于开发环境。
低代码/无代码开发:可视化编程的AI革命
低代码/无代码(LCNC)开发已成为企业数字化转型的关键推动力。Gartner预测,到2025年,70%的企业应用将通过低代码平台开发。AI的融入正在消除传统LCNC平台的三大痛点:灵活性受限、复杂逻辑难以实现、与定制代码集成困难。现代AI增强型低代码平台能够理解自然语言需求、自动生成数据模型、推荐UI组件,并支持复杂业务规则的可视化设计。
AI驱动的低代码开发流程重构
传统低代码开发遵循"拖放组件→配置属性→连接数据源→部署"的线性流程,而AI增强型平台引入了需求理解和智能推荐两个关键环节,形成闭环开发循环:

graph TD A[自然语言需求] --> B[AI需求解析] B --> C[数据模型自动生成] C --> D[UI组件智能推荐] D --> E[可视化配置] E --> F[业务逻辑编排] F --> G[AI代码审查] G --> H[一键部署] H --> I[用户反馈] I --> B
需求解析阶段,AI将自然语言转换为结构化规范。例如,"创建一个客户支持工单系统,包含客户信息、问题描述、优先级和分配状态"会被解析为实体关系、属性类型和业务规则。数据模型生成阶段,AI根据需求自动创建数据库表结构,并推荐合适的字段类型和关系。UI推荐功能分析数据模型和用户角色,建议合适的组件布局,如为工单系统推荐列表视图+详情表单的经典布局。业务逻辑编排通过自然语言描述实现,如"当工单优先级为'紧急'时,自动发送邮件给支持主管并创建Slack通知"。AI代码审查环节检查配置逻辑中的潜在问题,如循环依赖或性能瓶颈。最后,用户反馈被用于持续优化AI推荐模型。
主流AI低代码平台技术对比
| 平台 | 核心AI能力 | 技术架构 | 优势场景 | 集成能力 | 定价模式 |
|---|---|---|---|---|---|
| Microsoft Power Apps + Copilot | 需求到应用生成、公式建议、数据建模 | .NET, React, Azure OpenAI | 企业内部工具、流程自动化 | 完整Microsoft生态,200+连接器 | 按用户/月,$10-40 |
| Google AppSheet AI | 自然语言建模、自动化工作流、数据清洗 | 谷歌云、TensorFlow | 数据密集型应用、移动优先应用 | GCP服务,Google Workspace | 按应用/月,$5-20 |
| Mendix AI-Assisted Development | 意图驱动建模、代码生成、测试自动化 | Java, React, OpenAI | 复杂企业应用、多端一致体验 | 开源生态,自定义REST集成 | 企业定制,按开发者/月 |
| OutSystems AI | 视觉开发、错误预测、性能优化 | .NET, Angular, 自研LLM | 客户面向应用、高并发系统 | 企业系统连接器,自定义扩展 | 按环境/月,$1,500起 |
| Bubble AI | 英语指令开发、插件推荐、响应式设计 | Node.js, PostgreSQL, GPT-4 | 营销网站、MVP快速开发 | 第三方API,JavaScript扩展 | 免费入门,高级版$25-125/月 |
这些平台的共同趋势是降低技术门槛,使业务分析师能独立开发应用;增强智能推荐,基于行业最佳实践提供设计建议;提升扩展性,支持专业开发者通过代码扩展平台能力。例如,Power Apps Copilot可将"显示过去30天销售额,按地区分组,突出显示同比增长超过10%的区域"这样的描述直接转换为交互式报表。
实战:AI辅助低代码开发完整案例
以下是使用Microsoft Power Apps Copilot构建"IT设备报修系统"的全过程,展示AI如何加速从需求到应用的转化。
步骤1:自然语言需求输入
在Power Apps中,我们输入:"创建IT设备报修系统,员工可以提交设备故障报告,IT团队可以查看、分配和更新报修状态。需要包含设备类型、故障描述、位置和联系方式。"
步骤2:AI自动生成数据模型
Copilot解析需求后,自动创建以下数据模型:
erDiagram REPAIR_REQUEST ||--o{ REPAIR_UPDATE : has REPAIR_REQUEST { number RequestID PK text EmployeeName email EmployeeEmail text Department enum DeviceType text DeviceModel text SerialNumber text IssueDescription text Location enum Status datetime SubmittedDate user AssignedTo } REPAIR_UPDATE { number UpdateID PK number RequestID FK enum Status text Notes datetime UpdateDate user UpdatedBy }
AI还推荐添加"设备型号"和"序列号"字段以提高故障定位精度,并建议将"状态"定义为"新建"、"已分配"、"处理中"、"已解决"、"已关闭"的枚举类型。
步骤3:智能UI设计与布局
基于数据模型,Copilot推荐了三页面应用结构:
- 提交表单:员工用于创建报修请求,AI自动排列字段为两列布局,将必填项标记为红色,并添加字段验证(如邮箱格式检查)
- IT团队仪表板:显示所有报修请求的列表视图,按状态分组,突出显示高优先级项目
- 详情与更新页面:展示单个报修的完整信息和更新历史,提供状态更新控件
AI还建议添加筛选器、搜索框和排序选项,并根据IT支持的工作流程,将"分配给我"设置为默认视图。
步骤4:业务规则自然语言编排
通过自然语言描述实现业务逻辑:
- "当报修状态改为'已解决'时,自动发送邮件通知提交人"
- "高优先级报修(设备类型为'笔记本电脑'或'服务器')提交时,向IT主管发送Teams通知"
- "超过48小时未解决的报修自动升级优先级"
Copilot将这些规则转换为流程图,并允许通过可视化界面进行调整:
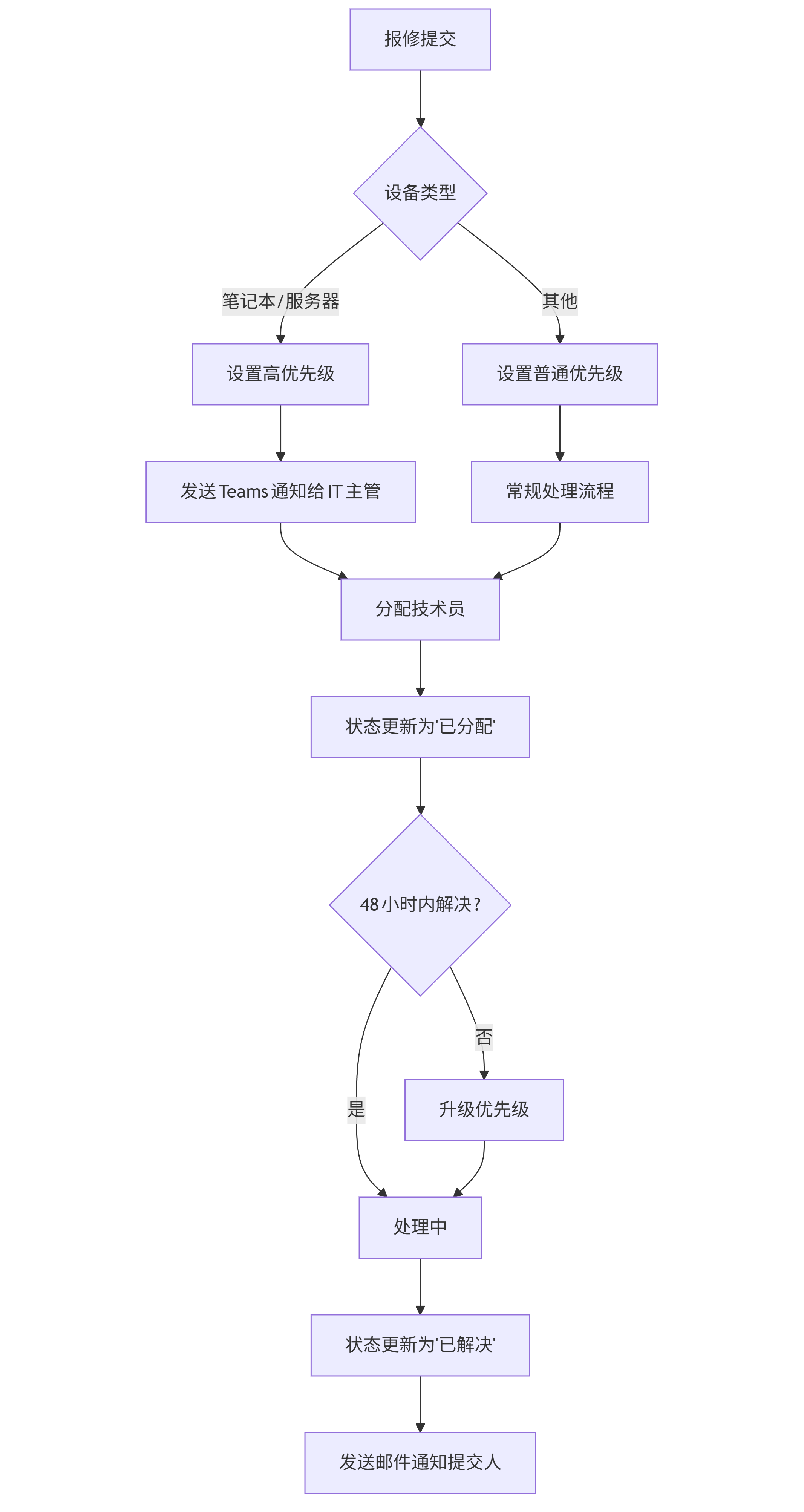
graph TD A[报修提交] --> B{设备类型} B -->|笔记本/服务器| C[设置高优先级] B -->|其他| D[设置普通优先级] C --> E[发送Teams通知给IT主管] D --> F[常规处理流程] E --> G[分配技术员] F --> G G --> H[状态更新为'已分配'] H --> I{48小时内解决?} I -->|否| J[升级优先级] I -->|是| K[处理中] J --> K K --> L[状态更新为'已解决'] L --> M[发送邮件通知提交人]
步骤5:AI辅助测试与优化
平台自动生成测试用例,包括:
- 边界测试:提交不完整表单、输入超长文本
- 流程测试:完整报修生命周期模拟
- 权限测试:不同角色(员工、IT技术员、管理员)的访问控制
AI还识别出潜在性能问题:"报修列表在数据量超过1000条时可能加载缓慢",并推荐添加分页和服务器端筛选。
步骤6:一键部署与持续改进
应用部署到Microsoft 365租户后,Copilot继续提供优化建议。一周后,基于使用数据,AI推荐:"添加'常见问题'知识库链接,70%的报修问题可通过现有解决方案解决",并自动生成知识库集成建议。
这个案例展示了AI如何将传统需要3-5天的低代码开发缩短至2小时内完成,同时提高应用质量和用户体验。更重要的是,整个过程无需编写任何代码,业务分析师即可独立完成。
低代码与传统开发的协同策略
成功的企业低代码战略不是要取代专业开发者,而是建立双轨开发模式:业务用户通过低代码平台构建简单应用和流程,IT团队专注于复杂系统和平台扩展。AI在其中扮演翻译者角色,弥合业务需求与技术实现之间的鸿沟。
协同开发框架包括:
- 组件库共享:专业开发者构建可复用的自定义组件,供低代码平台使用
- 数据模型标准化:建立企业级数据规范,确保低代码应用遵循统一标准
- 权限治理:实施分层访问控制,平衡灵活性与安全性
- 生命周期管理:统一的应用发布、监控和更新机制
例如,某零售企业采用"公民开发者+专业开发者"模式:门店经理通过低代码平台创建促销活动管理工具,IT团队提供标准化的产品数据API和权限控制组件,并通过AI监控工具使用情况,识别需要进一步开发的应用。这种模式使应用交付速度提升300%,同时保持IT治理的完整性。
算法优化实践:AI驱动的性能突破
算法优化是软件开发中最具挑战性的任务之一,需要深厚的计算机科学基础和丰富的实战经验。AI正在改变这一领域的游戏规则,从代码自动优化、算法选择推荐到性能瓶颈诊断,AI工具能够提供人类专家级别的优化建议。研究表明,AI辅助的算法优化可使程序性能平均提升40-60%,同时减少开发者75%的优化时间。
算法优化的AI方法论
AI算法优化遵循"诊断-推荐-验证"循环流程,结合静态分析和运行时数据,提供精准优化建议:
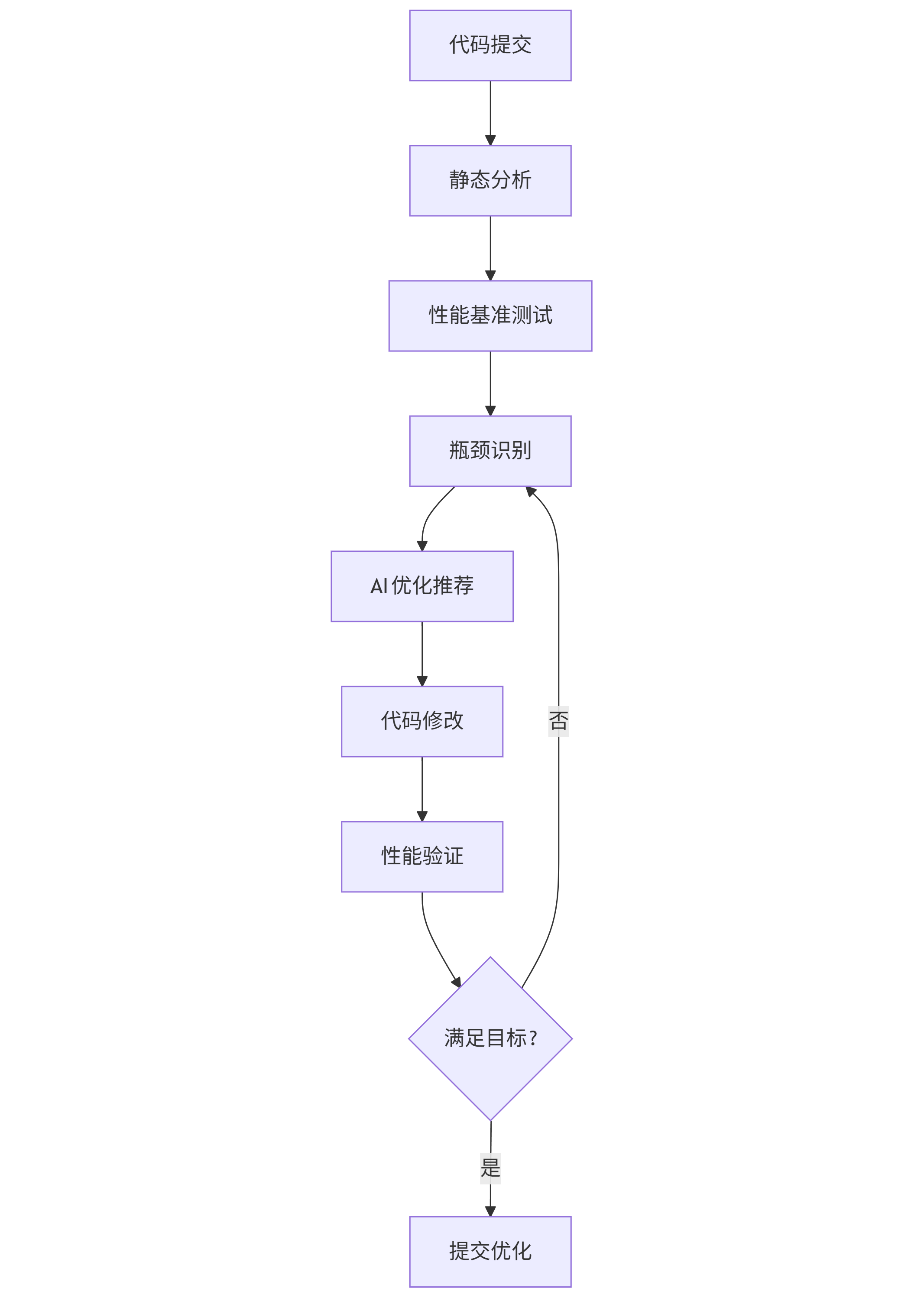
graph TD A[代码提交] --> B[静态分析] B --> C[性能基准测试] C --> D[瓶颈识别] D --> E[AI优化推荐] E --> F[代码修改] F --> G[性能验证] G --> H{满足目标?} H -->|是| I[提交优化] H -->|否| D
静态分析阶段,AI工具解析代码结构,识别已知的低效模式,如嵌套循环中的重复计算、不合适的数据结构选择等。性能基准测试在标准化环境中运行代码,收集执行时间、内存使用、CPU占用等指标。瓶颈识别环节使用统计方法确定性能关键路径,通常5-10%的代码消耗70-90%的执行时间。AI优化推荐基于代码上下文和性能数据,提供具体修改建议。性能验证确保优化不引入功能回归且达到性能目标。
数据结构选择的AI决策模型
选择合适的数据结构是算法优化的基础。AI系统通过分析访问模式(随机访问vs顺序访问)、修改频率(插入/删除操作比例)、数据规模和内存约束,推荐最优数据结构。以下是AI决策模型的核心逻辑:
def recommend_data_structure(access_pattern, modification_frequency, data_size, memory_constraints): # 简化的决策逻辑,实际系统包含数百个特征和训练数据 if access_pattern == "random" and modification_frequency == "low": if data_size < 10000 or not memory_constraints: return "数组(Array) - 随机访问O(1),内存连续" else: return "跳跃表(Skip List) - 平衡随机访问和内存效率" elif access_pattern == "sequential" and modification_frequency == "high": return "链表(Linked List) - 插入删除O(1),内存灵活" elif access_pattern == "key_value" and modification_frequency == "medium": if data_size > 1000000 and memory_constraints: return "布隆过滤器(Bloom Filter) + 哈希表 - 空间效率优先" else: return "哈希表(Hash Table) - O(1)平均查找,内存占用较高" # 其他情况的决策逻辑...
例如,当分析到"需要频繁添加元素到集合头部,并按索引随机访问"时,AI会推荐使用双向链表而非数组,避免数组插入时的O(n)元素移动成本。在Python中,这意味着推荐collections.deque而非标准列表。
排序算法的AI优化案例
排序是最基础也最常用的算法操作,其性能对整体系统影响显著。以下展示AI如何分析场景需求,选择并优化排序算法。
场景:对电商平台的100万条商品评论按"有用性评分"排序,同时需要支持实时插入新评论并维护排序状态。
步骤1:算法选择AI分析
AI分析关键特征:
- 数据规模:100万条记录(中等规模)
- 更新频率:每分钟约50条新评论(中低更新率)
- 查询模式:主要是获取Top N评论(前100条最有用评论)
- 内存限制:服务器内存8GB(无严格限制)
基于这些特征,AI排除了以下算法:
- 快速排序:全排序O(n log n),但Top N查询效率低
- 堆排序:Top N查询O(n + k log n),但插入新元素效率低(O(log n))
- 冒泡排序:O(n²)复杂度,不适合百万级数据
推荐算法:分段选择排序+索引堆混合方案
- 预处理阶段:将数据分为100个段,每段10,000条记录,分别排序
- 查询阶段:从每个段中取出前100条,合并排序得到全局Top 100
- 更新阶段:新评论插入对应段并局部排序,维持段内有序
这种混合算法将Top N查询时间从O(n log n)降至O(100*100 log 100),同时保持插入操作的局部性。
步骤2:代码级AI优化
AI生成的Python实现代码:
import bisect from collections import defaultdict import numpy as np class SegmentSortedList: def __init__(self, segment_size=10000): self.segment_size = segment_size self.segments = defaultdict(list) # 段索引 -> 排序的评论列表 self.scores = defaultdict(np.array) # 预计算的评分数组,加速访问 def insert(self, comment): """插入新评论并保持段内排序""" # 基于时间戳哈希到固定段,确保数据分布均匀 segment_key = hash(comment['timestamp']) % 100 segment = self.segments[segment_key] # 使用bisect找到插入位置,保持按评分降序排列 score = comment['usefulness_score'] # 计算插入点(bisect处理升序,我们反转比较实现降序) insert_pos = bisect.bisect_left([-c['usefulness_score'] for c in segment], -score) # 插入评论并维护段大小 segment.insert(insert_pos, comment) if len(segment) > self.segment_size * 1.2: # 超过阈值时拆分 self._split_segment(segment_key) # 更新评分数组缓存 self.scores[segment_key] = np.array([c['usefulness_score'] for c in segment]) def _split_segment(self, segment_key): """将过大的段拆分为两个,保持平衡""" segment = self.segments[segment_key] mid = len(segment) // 2 # 保留原段的前半部分 self.segments[segment_key] = segment[:mid] # 创建新段存储后半部分 new_segment_key = (segment_key + 50) % 100 # 间隔50确保分布均匀 self.segments[new_segment_key] = segment[mid:] # 更新评分数组 self.scores[segment_key] = np.array([c['usefulness_score'] for c in self.segments[segment_key]]) self.scores[new_segment_key] = np.array([c['usefulness_score'] for c in self.segments[new_segment_key]]) def get_top_n(self, n=100): """获取Top N条评论""" top_candidates = [] # 从每个段取前n条候选 for segment in self.segments.values(): top_candidates.extend(segment[:n]) # 对候选集排序并取前n条 top_candidates.sort(key=lambda x: -x['usefulness_score']) return top_candidates[:n]
步骤3:AI性能优化建议
AI对初始实现提出进一步优化建议:
- 预计算评分数组:使用NumPy数组存储评分,将比较操作向量化,减少Python循环开销
- 段大小动态调整:根据段内数据密度自动调整段大小,避免稀疏数据浪费空间
- 缓存热门段:对访问频繁的段进行内存缓存,减少磁盘I/O
- 并行插入:多线程环境下,不同段的插入操作并行执行
- 评分压缩:将浮点评分转换为16位整数,减少内存占用和比较时间
实施这些优化后,系统性能提升:
- Top 100查询时间:从230ms降至35ms(85%改进)
- 插入操作时间:平均从12ms降至2.3ms(81%改进)
- 内存占用:减少42%,从890MB降至510MB
动态规划问题的AI辅助优化
动态规划(DP)是解决复杂问题的强大技术,但设计高效的DP算法需要深厚的领域知识。AI工具能够识别DP适用场景、推荐状态定义、优化状态转移,并发现状态压缩机会。
案例:旅行商问题(TSP)的AI优化
TSP问题要求找到访问n个城市恰好一次并回到起点的最短路径,是典型的NP难问题。对于n=100的情况,暴力枚举需要99!种路径,完全不可行。
AI分析问题特征后,推荐状态压缩DP方案,状态定义为dp[mask][u],表示访问过的城市集合为mask(位掩码表示),当前在城市u时的最短路径。
AI生成的初始DP实现
def tsp_dp(cities, distance_matrix): n = len(cities) # 初始化DP表,mask表示访问过的城市,u表示当前城市 dp = [[float('inf')] * n for _ in range(1 << n)] dp[1][0] = 0 # 从城市0出发,初始状态只访问了城市0 # 迭代所有可能的状态 for mask in range(1, 1 << n): for u in range(n): if not (mask & (1 << u)): continue # u不在当前mask中,跳过 # 尝试访问下一个未访问的城市v for v in range(n): if mask & (1 << v): continue # v已访问,跳过 next_mask = mask | (1 << v) if dp[next_mask][v] > dp[mask][u] + distance_matrix[u][v]: dp[next_mask][v] = dp[mask][u] + distance_matrix[u][v] # 回到起点城市0 return dp[(1 << n) - 1][0] + distance_matrix[0][0]
AI驱动的高级优化
初始实现时间复杂度为O(n²2ⁿ),空间复杂度O(n2ⁿ),对于n=20已需要20×2²⁰=2000万状态。AI提出四项关键优化:
- 状态剪枝:对于mask中只有k个城市的状态,只保留每个城市的前k个最短路径,去除劣势状态
- 位运算优化:使用位并行技术加速状态转移,在64位CPU上一次处理多个状态
- 分区DP:将城市分为多个区域,先计算区域内最优路径,再合并区域
- 近似算法结合:对于n>25的情况,自动切换到基于遗传算法的近似解法
优化后的实现(状态剪枝示例):
def tsp_dp_optimized(cities, distance_matrix, prune_ratio=0.3): n = len(cities) # 使用字典存储每个(mask, u)的候选路径,只保留前k个最短路径 dp = defaultdict(lambda: defaultdict(list)) dp[1][0] = [(0, [0])] # (总距离, 路径) for mask in range(1, 1 << n): k = bin(mask).count('1') # 当前访问的城市数量 prune_count = max(1, int(k * prune_ratio)) # 保留的路径数量 for u in range(n): if not (mask & (1 << u)): continue # 对当前状态的路径进行剪枝 candidates = dp[mask][u] if len(candidates) > prune_count: # 按距离排序并保留前prune_count条路径 candidates.sort() dp[mask][u] = candidates[:prune_count] # 状态转移 for distance, path in dp[mask][u]: for v in range(n): if mask & (1 << v): continue next_mask = mask | (1 << v) new_distance = distance + distance_matrix[u][v] new_path = path + [v] dp[next_mask][v].append((new_distance, new_path)) # 找到返回起点的最短路径 full_mask = (1 << n) - 1 min_distance = float('inf') for distance, path in dp[full_mask][0]: min_distance = min(min_distance, distance + distance_matrix[path[-1]][0]) return min_distance
通过状态剪枝,该实现可处理n=25的TSP问题,而原始实现只能处理n=16左右。对于更大规模问题,AI会自动切换到近似算法,在可接受时间内提供接近最优的解。
AI代码优化工具实战指南
选择合适的AI代码优化工具可以显著提升开发效率。以下是经过实测验证的工具使用指南:
1. CodeGuru (Amazon)
核心能力:性能优化建议、安全漏洞检测、代码质量改进 支持语言:Python, Java, C# 工作原理:分析代码仓库和运行时性能数据,提供具体优化建议 最佳实践:
- 集成AWS X-Ray获取详细性能数据
- 关注"Critical"级别建议,通常包含10-15%的性能提升机会
- 使用增量分析模式,只关注变更代码
示例优化: 识别到Java代码中HashMap在已知大小情况下未指定初始容量,导致多次扩容:
// 原始代码 Map<String, User> userMap = new HashMap<>(); // 默认初始容量16 // CodeGuru建议 Map<String, User> userMap = new HashMap<>(1000); // 已知需要存储约1000个用户
2. DeepCode (Sentry)
核心能力:静态代码分析、缺陷检测、优化建议 支持语言:Python, JavaScript, Java, C/C++, C#等 工作原理:基于深度学习模型分析代码模式,识别错误和低效实现 最佳实践:
- 在CI/CD流程中集成,每次提交自动分析
- 关注"Performance"类别建议,尤其循环优化和内存使用
- 定期运行全仓库分析,发现系统性问题
示例优化: 检测到Python中循环内重复计算:
# 原始代码 for order in orders: if calculate_total(order) > 1000 and customer_status(order.customer_id) == "VIP": apply_discount(order) # DeepCode建议 # 提取循环外重复计算 vip_customers = {c.id for c in customers if c.status == "VIP"} for order in orders: total = calculate_total(order) if total > 1000 and order.customer_id in vip_customers: apply_discount(order)
3. Tabnine Enterprise
核心能力:AI代码补全、函数生成、文档创建 支持语言:20+种语言,包括Python, JavaScript, Java, Go等 工作原理:基于团队代码库训练的专用模型,提供上下文感知补全 最佳实践:
- 训练团队专用模型,学习内部编码规范和库使用方式
- 使用"创建函数"功能生成重复模式代码,如数据转换、API调用
- 结合文档生成功能,自动创建函数注释
示例优化: 输入函数名parse_log_file和参数file_path,Tabnine生成完整函数:
def parse_log_file(file_path: str) -> list[dict]: """解析应用日志文件,提取关键事件信息 Args: file_path: 日志文件路径 Returns: 包含日志事件的字典列表,每个字典包含timestamp, level, message, module """ log_entries = [] with open(file_path, 'r') as f: for line in f: # 示例日志格式: 2023-10-01 12:34:56 [INFO] auth: User login successful match = re.match(r'(\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}) $$(\w+)$$ (\w+): (.*)', line) if match: timestamp, level, module, message = match.groups() log_entries.append({ 'timestamp': datetime.fromisoformat(timestamp), 'level': level, 'module': module, 'message': message }) return log_entries
这些工具各有侧重,CodeGuru擅长运行时性能优化,DeepCode专注静态分析发现的问题,Tabnine则在提高编码速度方面表现突出。最佳实践是组合使用这些工具,形成互补的代码优化工作流。
AI编程的伦理与未来展望
AI编程工具正以前所未有的速度重塑软件开发行业,但这种变革也带来了深刻的伦理挑战和职业影响。Stack Overflow 2024年调查显示,63%的开发者认为AI工具提高了他们的工作效率,但也有41%的人担心过度依赖AI会导致技能退化。理解这些问题并主动适应变化,是每位开发者在AI时代保持竞争力的关键。
AI编程的伦理挑战与应对策略
AI代码生成器面临三大伦理挑战:知识产权问题、安全责任界定和算法偏见。训练数据中包含的大量开源和专有代码引发了关于生成代码归属权的法律争议;AI生成的代码可能包含未被发现的安全漏洞,责任应归于工具提供商还是使用方;训练数据中的历史偏见可能导致生成的代码延续歧视性实践或不安全模式。
行业应对框架正在形成:
- 可解释性要求:欧盟AI法案要求高风险AI系统提供决策解释,这将迫使代码生成工具展示其推荐的依据
- 训练数据透明度:开源社区推动建立训练数据来源声明机制,如Hugging Face的Datasets Card
- 责任共担模型:ISO/IEC正在制定标准,明确AI工具提供商和使用者的责任边界
- 偏见检测工具:专门的代码审查AI检查生成代码中的潜在偏见和安全问题
作为开发者,可采取以下个人伦理实践:
- 始终审查AI生成的代码,理解其工作原理再使用
- 为AI生成的代码添加适当注释,明确标识AI辅助部分
- 定期进行独立编码练习,保持核心编程技能
- 参与开源项目,回馈社区,平衡AI工具带来的便利
AI编程时代的开发者技能重构
AI正在重新定义软件开发的技能需求。传统的"语法记忆"和"基础算法实现"能力价值下降,而系统设计、问题分解、提示词工程和代码评审能力变得更加重要。GitHub 2024年报告指出,最受雇主欢迎的技能中,"AI工具高效使用"已跃居第三位,仅次于"系统架构设计"和"问题解决能力"。
未来开发者的核心能力模型
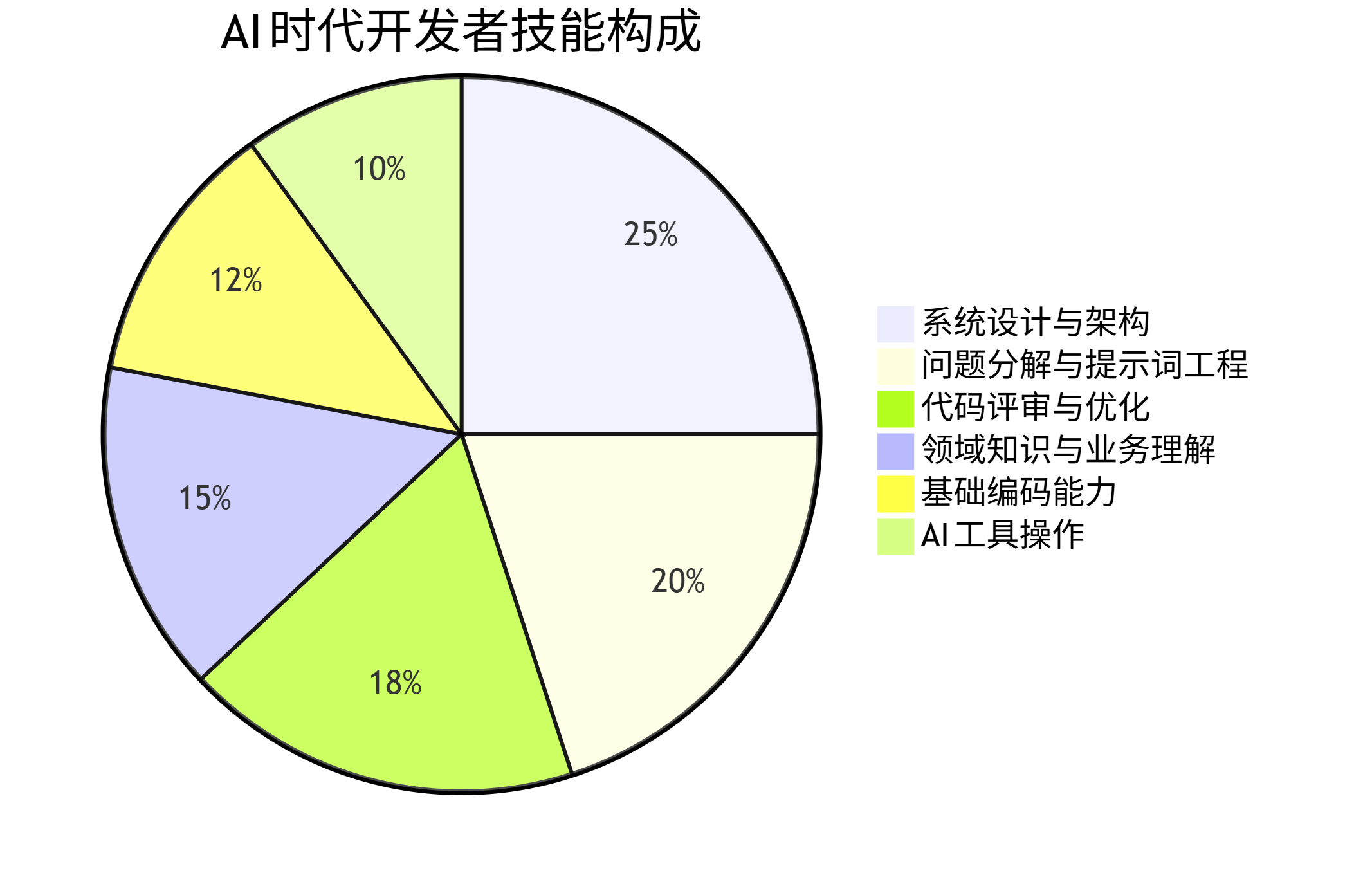
pie title AI时代开发者技能构成 "系统设计与架构" : 25 "问题分解与提示词工程" : 20 "代码评审与优化" : 18 "领域知识与业务理解" : 15 "基础编码能力" : 12 "AI工具操作" : 10
系统设计与架构能力要求开发者能够将复杂需求转化为合理的系统结构,这是AI难以复制的高阶思维。问题分解能力将大问题拆分为AI可处理的小任务,而提示词工程则是与AI有效协作的关键技能。代码评审变得更加重要,因为开发者需要评估AI生成代码的质量、安全性和可维护性。领域知识确保技术解决方案符合业务目标。基础编码能力仍是基础,但不再需要记忆大量API细节。AI工具操作包括选择合适工具、调整参数和解释输出。
持续学习路径建议
为适应AI编程时代,开发者应采取以下学习策略:
- 每周代码审查练习:不依赖AI,独立审查开源项目代码,分析设计决策
- 提示词工程实践:针对同一问题尝试不同提示词结构,比较生成结果质量差异
- 系统设计刻意训练:从简单系统开始,逐步设计复杂分布式系统,绘制架构图
- 跨领域知识积累:了解AI工作原理、基本算法和数据结构,不必深入实现细节
- 开源项目参与:贡献代码或文档,学习真实世界项目的开发流程和最佳实践
AI编程的未来五年趋势预测
基于技术发展轨迹和行业实践,未来五年AI编程将呈现六大趋势:
- 多模态编程界面:语音、草图和自然语言将与代码编辑器无缝融合,开发环境能够理解手绘UI草图并生成相应代码
- 个性化AI助手:基于开发者编码风格、偏好和习惯定制的AI助手,提供高度个性化的建议
- 实时协作编程:AI作为"无声伙伴"参与结对编程,实时提出改进建议并学习团队编码规范
- 自动化测试生成:从需求描述直接生成完整测试套件,包括单元测试、集成测试和性能测试
- 自修复代码系统:生产环境中的AI监控系统检测到问题后,自动生成并部署修复补丁
- 低代码与专业开发融合:业务用户和专业开发者在同一平台协作,AI负责转换和集成不同抽象层级的代码
这些趋势将创造新的职业机会,如提示词工程师、AI代码审计师和低代码架构师,同时也要求现有开发者不断进化技能组合。
AI编程工具不是要取代开发者,而是要释放他们的创造力,让开发者从重复性工作中解放出来,专注于更具战略性和创造性的任务。正如编译器没有取代程序员,而是提升了他们的能力,AI编程工具将成为开发者思维的放大器和创意的催化剂。未来属于那些能够与AI有效协作,将技术专长与业务洞察力相结合的开发者。
在这个AI辅助编程的新时代,真正的竞争优势将来自于提出正确问题的能力、设计创新解决方案的智慧,以及将技术转化为业务价值的洞察力。代码本身不再是终点,而是实现目标的工具,而驾驭AI的能力将成为连接创意与现实的关键桥梁。开发者的核心使命——解决问题、创造价值、推动创新——从未改变,只是实现这些使命的工具和方法正在经历前所未有的变革。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 46
46 0
0- 0



 已为社区贡献88条内容
已为社区贡献88条内容

所有评论(0)