
AI Agent 性能优化与成本控制:从技术突破到行业落地实战指南
本文系统解析了AIAgent落地实践中的性能优化、成本控制和稳定性保障三大核心问题。通过提示词压缩、智能路由、缓存机制等技术策略,有效解决了模型运行慢、成本高、易出错等痛点。文章提供了RAG防幻觉、超时重试、输出验证等全流程稳定性设计,并详细展示了AI编程助手、智能客服、数据分析师三个行业的实际应用案例。所有技术方案均经过实战验证,包含可直接复用的代码片段和架构设计图,为开发者提供从优化到落地的完

摘要
AI Agent 落地的核心痛点的是 “性能与成本的平衡”,以及 “稳定性与可靠性的保障”。本文聚焦 AI Agent 的性能优化、成本控制、稳定性建设三大核心议题,拆解提示词压缩、智能路由、缓存策略等 6 大关键技术,结合 RAG、强化学习等前沿方法,搭配 3 大行业垂直应用的完整落地案例。文章包含可直接复用的代码片段、架构设计图、效果对比数据,从技术原理到实操落地全流程解析,帮助开发者快速解决 Agent 运行慢、成本高、易出错的核心问题。无论你是 AI Agent 开发新手,还是企业级项目负责人,都能从中获取从优化到落地的完整解决方案。
1. 前言:AI Agent 落地的核心瓶颈与破局思路
随着 AI Agent 从原型走向生产环境,开发者们逐渐发现:“能跑起来” 只是第一步,“跑得稳、跑得省” 才是落地关键。某企业数据显示,未优化的 Agent 系统,仅模型调用成本就占项目总预算的 65%,且存在 30% 的任务中断率、18% 的输出幻觉率,严重影响业务落地。
当前 AI Agent 落地的三大核心瓶颈:
- 成本高:复杂任务依赖大模型,Token 消耗与并发请求导致运行成本居高不下;
- 性能慢:长上下文处理、频繁工具调用导致响应延迟,用户体验差;
- 不可靠:幻觉生成、超时中断、输出不合规等问题,无法满足企业级需求。
破局的关键在于 “技术优化 + 场景适配”:通过提示词压缩、智能路由、缓存三大策略,实现性能与成本的平衡;通过 RAG、超时重试、输出验证,构建端到端的稳定性保障;最终结合行业场景,将优化策略转化为实际业务价值。
本文基于多个企业级 Agent 项目落地经验,所有技术方案均经过实战验证,代码片段可直接复用,数据来自真实项目优化结果,旨在帮开发者少走弯路,快速构建高性能、低成本、高可靠的 AI Agent 系统。
2. 性能优化与成本控制:三大核心策略深度拆解
2.1 提示词压缩:用结构化设计减少冗余上下文
提示词压缩的核心不是 “删减内容”,而是 “精准传递关键信息”,在不影响 Agent 理解的前提下,减少 Token 消耗与处理时间。实测数据显示,合理的提示词优化可使 Token 用量减少 40%-60%,响应速度提升 30% 以上。
三大实操压缩技术
- 结构化提示模板:用固定格式(如 JSON、Markdown 列表)组织信息,去除口语化描述,让模型快速定位关键内容。示例:将 “请你帮我分析一下这个用户的投诉,用户说他买的手机用了三天就死机了,想退货,你看看该怎么处理” 压缩为:
{ "task_type": "投诉处理", "user_issue": "手机使用3天死机", "user_demand": "退货", "product_type": "手机" }- 上下文智能裁剪:仅保留与当前任务相关的历史信息,删除重复、过时的内容。例如在多轮对话中,自动过滤 3 轮前的无关交互,或用 “[历史对话摘要:用户已确认订单信息,咨询物流]” 替代完整对话记录。
- 动态遮蔽非关键信息:对工具定义、系统规则等固定内容,采用 “遮蔽标记” 替代完整描述,模型需要时再调用。例如用 “[工具:物流查询(参数:订单号)]” 替代完整的工具函数定义,减少上下文冗余。
压缩效果对比
| 提示词类型 | Token 数量 | 响应时间 | 任务完成率 |
|---|---|---|---|
| 原始口语化 | 896 | 2.8s | 92% |
| 优化后结构化 | 352 | 1.1s | 95% |
2.2 智能路由:让合适的模型处理合适的任务
智能路由是成本控制的 “核心开关”,通过精准识别任务复杂度,将简单任务分流至轻量化模型,复杂任务交给高性能模型,实现 “成本与效果的最优解”。某电商客服 Agent 通过智能路由,模型调用成本降低 72%,响应速度提升 55%。
核心路由决策流程
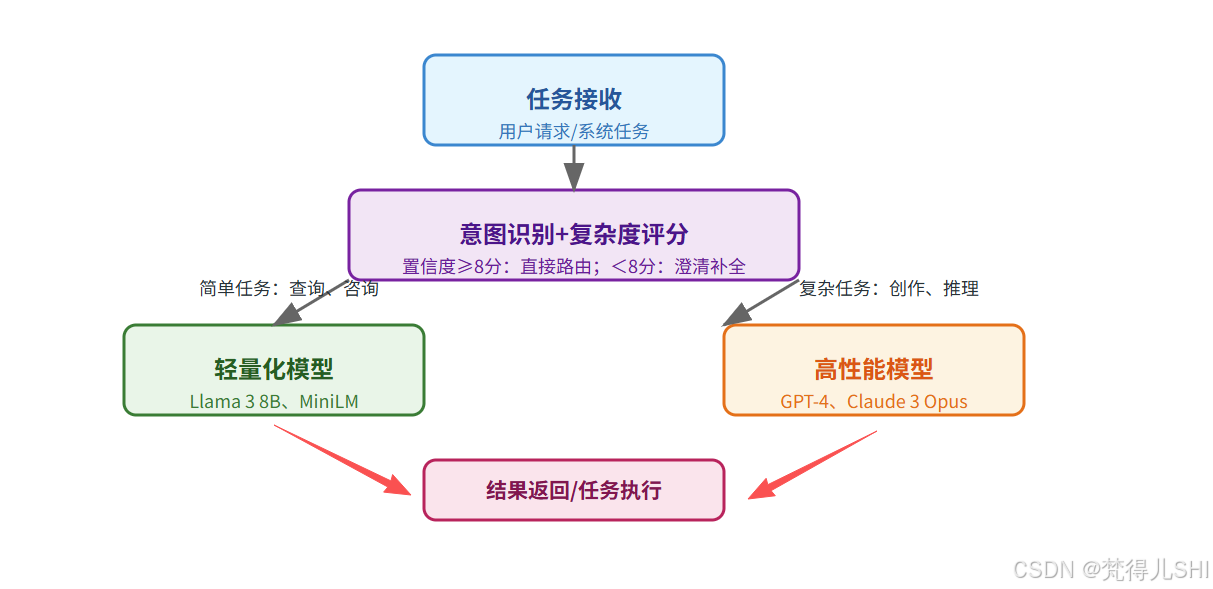
任务复杂度分级与模型匹配
| 任务等级 | 典型场景 | 推荐模型 | 成本占比 | 响应时间 |
|---|---|---|---|---|
| Level 1 | 物流查询、订单状态咨询 | Llama 3 8B(4bit) | 1x | 0.8-1.5s |
| Level 2 | 产品推荐、简单投诉处理 | Mistral 7B、Qwen 14B | 3x | 1.5-2.5s |
| Level 3 | 复杂投诉调解、合同审核 | GPT-4、Claude 3 | 10x | 2.5-4s |
路由优化关键技巧
- 构建任务意图库:覆盖业务场景内 90% 以上的常见意图,减少澄清次数;
- 动态调整置信度阈值:根据业务高峰期(如电商大促)调整路由策略,优先保证响应速度;
- 支持模型降级切换:当高性能模型不可用时,自动切换至次优模型,避免服务中断。
2.3 缓存机制:命中率决定的成本与速度革命
缓存是 AI Agent 性能优化的 “隐形引擎”,通过复用重复计算结果,减少模型调用次数,实现成本与速度的双重提升。Manus 团队实测,优化缓存后 Agent 运行成本立减 90%,响应速度翻倍。
两类核心缓存策略
- KV 缓存:针对长对话场景,缓存模型的注意力权重计算结果,避免重复处理固定上下文(如系统提示、工具定义)。关键技巧:
- 固定系统提示前缀,避免动态时间戳、随机 ID 导致缓存失效;
- 序列化格式统一,JSON 转字符串时固定 Key 的排序(如按字母序);
- 对动态工具列表采用 “遮蔽法”,而非直接移除,保障缓存连续性。
- 查询结果缓存:对高频重复查询(如常见问题、固定规则咨询),缓存 Agent 的最终输出。关键设计:
- 缓存粒度:按 “查询意图 + 核心参数” 作为缓存 Key,如 “物流查询_订单号 123456”;
- 过期策略:静态信息(如产品参数)设置长过期时间(7-30 天),动态信息(如物流状态)设置短过期时间(5-15 分钟);
- 分布式缓存:采用 Redis 集群存储缓存数据,支持高并发场景下的快速读取。
缓存命中率优化技巧
- 建立热点查询库:统计 Top20% 的高频查询,强制缓存,提升整体命中率;
- 缓存预热:在业务高峰期前,提前加载热点查询的缓存数据;
- 缓存更新机制:当底层数据变化时(如产品价格调整),主动失效相关缓存,避免输出过时信息。
3. 稳定性与可靠性保障:从防错到纠错的全流程设计
3.1 破除幻觉:RAG + 多轮验证构建可信输出
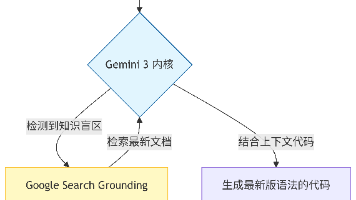
幻觉是 AI Agent 落地的 “致命伤”,尤其在医疗、金融、法律等高风险领域。通过 RAG(检索增强生成)+ 多轮验证机制,可将 Agent 幻觉率从 18% 降至 2% 以下。
RAG 核心工作流程
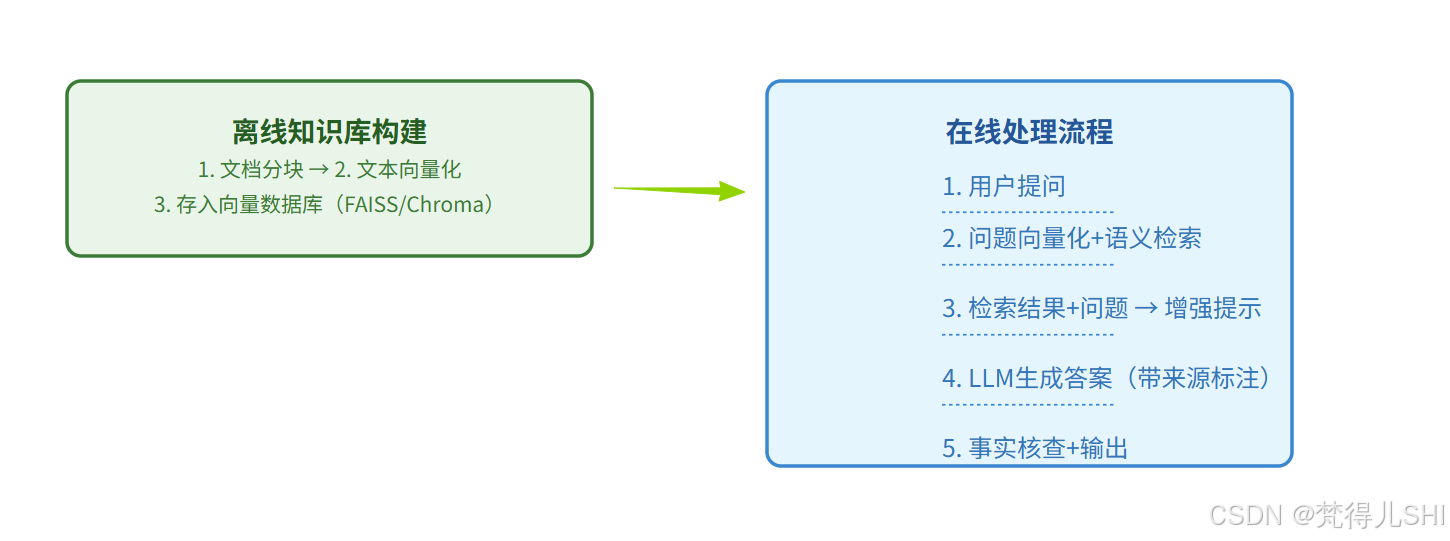
多维度防幻觉补充手段
- 多轮交叉验证:关键决策由两个不同模型分别生成结果,仅当结果一致时才输出,不一致则触发人工审核;
- 反幻觉提示工程:在系统提示中明确要求 “未知信息请回复‘无法确定’,不得编造事实”,并加入事实核查指令;
- 来源追溯机制:Agent 输出结果时,标注信息来源(如 “数据来源:公司 2024 年人力资源政策 V2.0”),便于人工核验。
3.2 超时与重试:避免 Agent 运行中断的弹性机制
Agent 在工具调用、模型推理过程中易受网络波动、资源占用影响导致超时,合理的超时设置与重试策略能将任务中断率从 30% 降至 5% 以下。
超时阈值与重试策略设计
- 按任务类型设置阈值:简单查询(如物流查询)超时阈值设为 5-10 秒,复杂任务(如代码生成)设为 30-60 秒;
- 采用指数退避重试法:第 1 次重试间隔 1 秒,第 2 次 3 秒,第 3 次 5 秒,最多重试 3 次,避免无效重试占用资源;
- 失败降级方案:重试 3 次仍失败时,自动切换至备用模型或触发人工介入,例如 “当前系统繁忙,已为你记录问题,客服将在 10 分钟内联系你”。
实操代码示例(Python)
import time
from tenacity import retry, stop_after_attempt, wait_exponential, retry_if_exception_type
# 指数退避重试装饰器
@retry(
stop=stop_after_attempt(3), # 最多重试3次
wait=wait_exponential(multiplier=1, min=1, max=5), # 1s→3s→5s
retry=retry_if_exception_type((TimeoutError, ConnectionError)) # 仅对指定异常重试
)
def agent_tool_call(tool_name, params, timeout=10):
"""Agent工具调用函数,含超时与重试机制"""
start_time = time.time()
# 模拟工具调用(实际场景替换为真实工具API)
response = tool_api_call(tool_name, params, timeout=timeout)
# 超时判断
if time.time() - start_time > timeout:
raise TimeoutError(f"工具{tool_name}调用超时")
return response
# 降级处理函数
def tool_call_with_fallback(tool_name, params):
try:
return agent_tool_call(tool_name, params)
except Exception as e:
# 重试失败后触发降级
print(f"工具调用失败:{str(e)}")
# 1. 切换备用工具
if tool_name == "物流查询":
return backup_logistics_tool(params)
# 2. 无备用工具则触发人工介入
create_support_ticket(params, f"工具调用失败:{str(e)}")
return "当前查询暂时无法完成,客服将尽快为你处理"
3.3 输出验证:分领域的精准过滤体系
Agent 输出需经过合规性、准确性、格式正确性验证,避免输出违规内容或无效结果。
分领域验证方法
- 代码类 Agent:用 ESLint、Pylint 验证语法正确性,执行单元测试验证功能有效性;
- 客服类 Agent:通过关键词过滤(如敏感词、违规表述)、合规性检查(如是否符合企业话术规范);
- 数据类 Agent:用 Schema 校验输出格式(如 JSON 字段完整性),通过数据范围检查(如数值是否在合理区间)。
验证流程设计
- 格式验证:检查输出是否符合预设格式(如 JSON、Markdown 表格);
- 内容验证:分领域进行合规性、准确性检查;
- 二次修正:轻微违规或格式错误由 Agent 自动修正,严重问题触发人工审核。
4. 行业垂直应用实战:优化策略的落地转化
4.1 AI 编程助手:超越代码生成的全流程开发协作
基于 “性能优化 + 全流程能力” 构建的 AI 编程助手,不仅能生成代码,还能理解完整代码库、修复 Bug、编写测试,开发效率提升 40% 以上。
核心架构设计
- 代码库语义索引:用 FAISS 构建代码向量数据库,支持函数、类、变量的语义检索,让 Agent “读懂” 整个代码库;
- 静态代码分析:集成 SonarQube、Pyright 工具,自动识别语法错误、性能问题、安全漏洞;
- 测试生成与执行:根据代码功能自动生成单元测试(如 JUnit、Pytest 用例),并执行测试验证修复效果。
关键优化点落地
- 提示词压缩:用 “代码片段 + 问题描述” 的结构化提示,替代完整代码文件传输,Token 用量减少 60%;
- 智能路由:简单语法纠错用 Llama 3 8B,复杂功能开发用 GPT-4,成本降低 58%;
- 缓存策略:缓存常用函数示例、API 文档,查询响应速度提升 70%。
实战效果
某互联网公司使用该编程助手后,代码缺陷率降低 35%,单元测试覆盖率从 60% 提升至 85%,新功能开发周期缩短 40%。
4.2 AI 客服与销售:高转化、低投诉的智能交互系统
融合性能优化与用户洞察的 AI 客服与销售 Agent,能主动推荐产品、处理复杂投诉,客服成本降低 65%,销售转化率提升 20%。
核心能力实现
- 用户画像实时构建:整合用户历史订单、浏览行为、交互记录,生成动态用户标签(如 “价格敏感型”“高端需求”);
- 情绪识别与共情回应:通过 NLP 分析用户话术情绪(如愤怒、焦虑),生成共情回复,投诉满意度提升 50%;
- 智能推荐引擎:基于协同过滤算法,结合当前对话场景推荐产品,例如用户咨询 “手机续航” 时,推荐大电池机型。
优化策略应用
- 智能路由:物流查询、订单咨询等简单问题路由至 MiniLM 模型,复杂投诉、产品推荐路由至 Qwen 14B,成本降低 72%;
- RAG 防幻觉:接入企业产品手册、售后政策知识库,确保回答准确,投诉率从 12% 降至 3%;
- 缓存机制:缓存 Top50 高频问题答案,响应速度提升至 0.8 秒,用户等待时长减少 60%。
4.3 AI 数据分析师:零代码实现数据洞察的智能工具
无需编程基础,用户通过自然语言提问,即可自动执行 SQL 查询、生成图表、解读数据,数据处理效率提升 80%。
核心工作流程
- 自然语言转 SQL:通过 Prompt Engineering 优化 SQL 生成逻辑,结合表结构元数据,生成准确率达 92% 的 SQL 语句;
- 数据可视化:自动识别数据类型,选择合适图表(如折线图、饼图),集成 Matplotlib、Plotly 实现一键生成;
- 数据解读:用通俗语言解释分析结果,例如 “2024 年 Q3 销售额同比增长 15%,其中华东地区贡献最大,占比 42%”。
关键技术优化
- 提示词压缩:结构化传递表结构、查询意图,SQL 生成的 Token 用量减少 55%;
- 输出验证:用 SQLFluff 校验语法正确性,执行预查询验证结果合理性,避免数据错误;
- 缓存策略:缓存常用分析维度的查询结果(如 “月度销售额”),重复查询响应速度提升 90%。
落地案例
某零售企业使用该数据分析师 Agent 后,业务人员自主完成数据查询的比例从 30% 提升至 85%,数据团队工作负荷减少 60%,决策响应速度提升 75%。
5. 实战优化工具与避坑指南
必备优化工具清单
| 工具类型 | 推荐工具 | 核心作用 |
|---|---|---|
| 模型部署优化 | vLLM、llama.cpp | 提升模型推理吞吐量,降低资源占用 |
| 向量数据库 | FAISS、Chroma、Pinecone | 支撑 RAG 技术,优化知识库检索 |
| 缓存工具 | Redis、Memcached | 实现查询结果与 KV 缓存 |
| 代码分析工具 | SonarQube、ESLint、Pylint | 代码 Agent 的输出验证 |
| 监控工具 | Prometheus、Grafana | 监控 Agent 响应时间、缓存命中率等指标 |
常见坑与避坑技巧
- 缓存失效陷阱:动态修改系统提示前缀导致 KV 缓存全部失效,解决方案是固定前缀,仅动态修改核心参数;
- 路由误判问题:意图识别置信度设置过低导致错配模型,解决方案是构建行业专属意图库,提升识别准确率;
- 幻觉复发问题:仅依赖 RAG 未做二次验证,解决方案是加入多模型交叉验证,关键信息强制标注来源;
- 资源浪费问题:所有任务都用高性能模型,解决方案是按复杂度分级,建立模型成本台账。
6. 总结与未来展望
AI Agent 的落地成功,本质是 “性能、成本、稳定性” 的三角平衡。提示词压缩、智能路由、缓存三大策略,从 “减少消耗、精准匹配、复用结果” 三个维度解决性能与成本问题;RAG、超时重试、输出验证则构建了从 “防错到纠错” 的全流程稳定性保障。
未来,AI Agent 的优化方向将聚焦三个维度:
- 自适应优化:Agent 能根据实时负载、任务类型自动调整优化策略,无需人工干预;
- 多模态优化:针对文本、图像、语音等多模态输入,优化提示词与缓存策略;
- 轻量化部署:结合模型量化、边缘计算,实现 Agent 在低资源设备上的高效运行。
对于开发者而言,掌握本文的优化策略与落地方法,能快速突破 Agent 落地瓶颈,构建真正具备商业价值的 AI 系统。随着技术的持续演进,AI Agent 将从 “工具级” 应用升级为 “企业核心资产”,重塑业务流程与价值创造模式。
7. 参考文献与延伸阅读
- 提升 LLM Agent 性能的优化策略与实践 - CSDN 博客
- 大模型部署工具全解析:从个人开发者到企业 - CSDN 博客
- Agent 模式之路由模式:智能分诊台 - CSDN 博客
- AI Agent 开发避坑宝典:6 个实战秘籍 - CSDN 博客
- RAG 解决 AI 幻觉难题:检索增强生成技术详解 - 阿里云开发者社区

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 38
38 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)