
[论文阅读] AI + 软件工程 | 首测GPT-4.1/Claude Sonnet 4适配能力:LLM多智能体在SE领域的潜力与局限
本文开展首个关于LLM-based多智能体系统在软件工程(SE)数据集适配任务的实证研究。为实现SE研究工件跨数据集的自动化适配(提升可扩展性与可复现性),以搭载GPT-4.1和Claude Sonnet 4的GitHub Copilot为研究对象,针对ROCODE、LogHub2.0等基准仓库,设计五阶段评估流程(文件理解、代码编辑、命令生成、验证、最终执行),衡量成功率、分析失败模式,并验证提
首测GPT-4.1/Claude Sonnet 4适配能力:LLM多智能体在SE领域的潜力与局限
论文信息
- 论文原标题:Multi-Agent Systems for Dataset Adaptation in Software Engineering: Capabilities, Limitations, and Future Directions(软件工程中用于数据集适配的多智能体系统:能力、局限与未来方向)
- 主要作者及研究机构:
- JINGYI CHEN(共同第一作者),香港科技大学(The Hong Kong University of Science and Technology, China)
- XIAOYAN GUO(共同第一作者),中国科学技术大学(University of Science and Technology of China, China)
- SONGQIANG CHEN,香港科技大学
- SHING-CHI CHEUNG(通讯作者),香港科技大学
- JIASI SHEN(通讯作者),香港科技大学
- 引文格式(GB/T 7714):
CHEN J, GUO X, CHEN S, et al. Multi-Agent Systems for Dataset Adaptation in Software Engineering: Capabilities, Limitations, and Future Directions[EB/OL]. (2025-11-26)[2025-11-30]. arXiv:2511.21380v1 [cs.SE]. - 其他信息:论文发布于arXiv预印本平台,研究聚焦LLM驱动的多智能体系统在软件工程数据集适配中的应用,是该领域首份实证研究。
一段话总结
这篇论文是首个针对LLM-based多智能体系统在软件工程(SE)数据集适配任务的实证研究:以搭载GPT-4.1和Claude Sonnet 4的GitHub Copilot为研究对象,针对ROCODE、LogHub2.0等基准仓库,通过“文件理解→代码编辑→命令生成→验证→最终执行”五阶段流程评估性能。结果显示,当前系统虽能识别关键文件、生成部分适配代码,但几乎无法产出功能正确的实现;而“提供错误信息”“补充参考代码”等提示干预,能将生成代码与基准真值的结构相似度从7.25%提升至67.14%。研究最终揭示了现有系统的局限,并为构建更可靠的SE多智能体提供了明确方向。
思维导图

研究背景:为什么需要LLM多智能体做SE数据集适配?
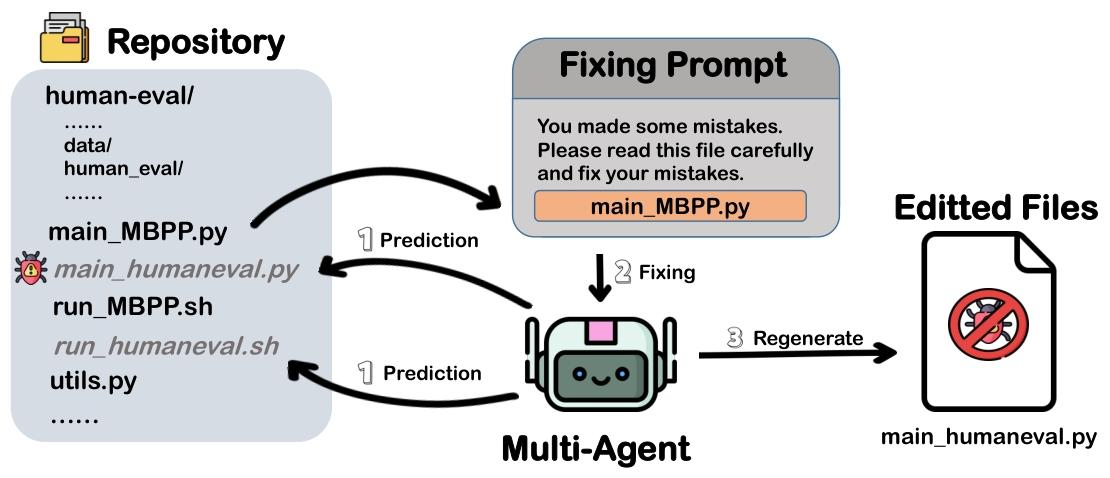
咱们先从软件工程(SE)的研究痛点说起——研究员开发一个新的SE技术(比如代码生成工具、bug修复算法),不能只在一个数据集上测效果,得在多个数据集上验证,才能证明技术“通用”。但问题来了:每个数据集的格式、依赖、执行流程都不一样,要让技术在新数据集上跑起来,得手动改代码、装依赖、调脚本。
举个具体例子:假设研究员开发了一个“代码漏洞检测工具”,先在A数据集(比如HumanEval)上跑通了。现在要测B数据集(比如MBPP),得手动改工具的输入读取代码(因为A和B的代码格式字段不一样)、调整执行脚本(B数据集需要额外的环境变量)、甚至补测试用例——这一套下来,少则几小时,多则几天。如果数据集多了,研究员光在“适配”上花的时间,可能比改进技术本身还多。这就是SE领域的“适配瓶颈”:人工适配效率低、难扩展,严重拖慢研究进度。
后来LLM火了,像GitHub Copilot能写代码、ChatGPT能理解命令,人们发现:把多个LLM智能体组合起来(也就是“多智能体系统”),或许能自动化适配——比如一个智能体读项目结构,一个改代码,一个调命令,分工协作。但问题是:这事儿到底行不行?当前最牛的多智能体系统(比如Copilot的Agent模式),真能搞定数据集适配吗?有没有数据支撑?
之前没人做过系统的实证研究,这篇论文就瞄准了这个空白:用真实的SE数据集和技术,测一测LLM多智能体的适配能力,再看看有没有办法帮它们“提分”。
创新点:这篇论文的独特之处在哪?
-
填补领域空白:首份LLM多智能体SE适配实证研究
在此之前,没人系统评估过“LLM多智能体能否做SE数据集适配”,论文第一次用标准化流程(五阶段)、真实数据集(ROCODE/LogHub2.0)、主流系统(Copilot)做实验,给出了量化结果。 -
拆解评估流程:把“适配”拆成可落地的5个步骤
没直接测“端到端能不能成”,而是把适配拆成“读文件→编代码→生命令→验修复→判结果”,每个步骤都有明确的评估标准(比如“读文件”要对比人类标注的必要文件列表),能精准定位系统卡在哪一步。 -
设计实用提示干预:3类提示解决不同痛点
不是乱试提示,而是针对系统的失败模式设计:语法错了给“错误信息”,不懂项目结构给“参考代码”,找不到bug给“位置标注”,层层递进,效果可量化(用JPlag测结构相似度)。 -
对比两大LLM后端:揭示模型差异
同时测了GPT-4.1和Claude Sonnet 4,发现Claude在“读文件”“主动测试”上更优,GPT-4.1常漏关键文件,为后续选择模型提供了参考。
研究方法:怎么测LLM多智能体的适配能力?
论文的研究方法很严谨,咱们拆成4步讲,一看就懂:
第一步:选对“测试素材”——筛选可复用的SE工件
不是随便找个数据集就测,而是按3个标准筛选:
- 来源靠谱:2024-2025年SE顶会(FSE/ICSE/ASE/ISSTA)的论文,且带“可复用工件徽章”(保证能拿到代码);
- 语言统一:只选Python实现的(避免不同语言的环境干扰,聚焦适配本身);
- 适配价值高:要么“一个技术测多个数据集”,要么“多个技术测一个新数据集”(保证有适配需求)。
最后选出两个核心工件:ROCODE(代码生成相关)、LogHub2.0(日志解析相关)。
第二步:造“适配任务”——模拟真实场景
- 整合仓库:把“数据集仓库(R_D)”和“技术仓库(R_T)”合并(比如把ROCODE的数据集复制到技术代码目录);
- 挖个“坑”:删掉针对“目标数据集”的适配代码(比如删掉ROCODE适配MBPP的代码),但保留其他数据集的适配代码(比如ROCODE适配HumanEval的代码,作为参考);
- 定“标准答案”:被删掉的适配代码就是“基准真值”,最后看智能体能不能复原。
第三步:跑“五阶段测试”——评估RQ1
给Copilot发指令,让它完成适配,同时按5个步骤打分:
| 步骤 | 做什么? | 怎么算过? |
|---|---|---|
| Step1:读文件 | 智能体浏览仓库,找必要文件 | 对比人类研究员标注的“必要文件列表”,读全才算过 |
| Step2:编代码 | 改现有文件/建新文件 | ①能找到要改的文件(过子步骤1);②改后的代码功能和基准真值一致(过子步骤2) |
| Step3:生命令 | 生成执行脚本(如bash)并运行 | ①脚本命令和基准真值一致(过子步骤1);②能自动执行脚本(过子步骤2) |
| Step4:验修复 | 找bug、修bug | ①能测出代码问题(过子步骤1);②能修好至少一个问题(过子步骤2) |
| Step5:判结果 | 对比最终输出 | 在相同环境下跑,输出和基准真值完全一致才算过 |
第四步:加“提示干预”——评估RQ2
如果智能体卡壳了,按顺序加3类提示,看能不能救回来:
- Prompt1:给错误信息:把终端报错(比如Python的“语法错误:字符串未闭合”)复制给智能体;
- Prompt2:给参考代码:把“其他数据集的适配代码”(比如ROCODE适配HumanEval的代码)发给智能体;
- Prompt3:标bug位置:人工找到第一个错的代码行,告诉智能体“你这里写错了”。
主要成果和贡献:LLM多智能体到底行不行?
1. RQ1:当前多智能体系统的适配能力——“会开头,难收尾”
论文用表格总结了核心结果(节选关键数据):
| 智能体后端 | 数据集 | Step1(读文件) | Step2(编代码) | Step5(最终适配) |
|---|---|---|---|---|
| GPT-4.1 | 所有 | 全失败 | 全失败 | 全失败 |
| Claude Sonnet 4 | ROCODE-HE | 成功 | 部分成功(能找文件,代码不全对) | 失败 |
| Claude Sonnet 4 | Logparser-AEL | 失败 | 部分成功 | 成功(仅1例) |
关键结论:
- 整体拉胯:仅1例(Claude+Logparser-AEL)完成最终适配;
- 瓶颈明显:Step2(编代码)是最难的——所有案例都没完全写出功能正确的代码(比如把MBPP的“自然语言描述”当成“可执行代码”填进字段);
- 模型差异大:Claude比GPT-4.1强太多——Claude会主动读README(找执行流程)、会生成测试用例,GPT-4.1常漏关键脚本(如run.sh)、写完代码就终止,不验证。
2. RQ2:提示干预的效果——“参考代码最管用”
| 提示类型 | 解决的问题 | 量化效果 |
|---|---|---|
| Prompt1(错误信息) | 语法错、运行时错(如字符串未闭合) | 3次内解决90%以上语法问题,除了缩进错误 |
| Prompt2(参考代码) | 不懂项目结构、漏改文件 | 结构相似度从7.25%→67.14%,修复15个漏改文件中的9个 |
| Prompt3(bug定位) | 找不到具体错在哪 | 效果有限:8次尝试仅3次成功,复杂问题搞不定 |
3. 对SE领域的3大贡献
- 实践指导:想让多智能体做适配?优先用Claude当后端,加“参考代码”提示,能大幅提效;
- 问题诊断:明确了当前系统的3个核心局限——不会协调多文件编码、自主调试弱、对数据集字段理解浅;
- 未来方向:指出要做“执行反馈循环”(让智能体实时看运行结果)、“自适应提示”(按任务难度调提示)、“智能体协作”(分工处理读文件、编代码、验修复)。
注:论文未提及开源代码或数据集,相关实验素材可联系作者获取。
关键问题:你关心的都在这
Q1:当前LLM多智能体在SE数据集适配中,最致命的问题是什么?
A:是“生成代码的功能正确性不足”(Step2的第二个子步骤)。比如在MBPP数据集适配中,智能体明明该填“可执行Python代码”,却填了“自然语言问题描述”,导致最终跑不起来;再比如不会正确调用技术框架——适配ROCODE时,GPT-4.1不用ROCODE的回溯机制,反而用普通LLM生成代码,完全偏离需求。
Q2:为什么“参考代码提示”效果比“bug定位”好?
A:因为“参考代码”能给智能体“全局视角”——不仅告诉它“怎么写”(比如函数参数格式),还告诉它“项目结构是什么”(比如哪个脚本负责执行),从根源上解决“不懂项目”的问题;而“bug定位”只能解决“局部问题”,如果智能体没理解整体逻辑,就算改对了这个bug,还会出其他错(比如改了字段名,却没改引用这个字段的其他文件)。
Q3:这篇研究对普通SE研究员有什么用?
A:有两个直接价值:①如果想自动化适配数据集,现在可以用“Claude+参考代码提示”的组合,能省60%以上的手动改代码时间;②不用再盲目试多智能体——知道了GPT-4.1当前不适合做适配,避免踩坑。
Q4:未来LLM多智能体要怎么改进,才能真正替代人工适配?
A:至少要解决3个问题:①能“全局协调”——改一个文件时,自动同步改其他关联文件;②能“自主迭代”——跑失败后,不用人工给提示,自己分析日志、调代码;③能“理解数据集语义”——不光认字段名,还懂字段的含义(比如知道“prompt”字段在HumanEval里是“输入指令”,在MBPP里是“问题描述”)。
总结
这篇论文是LLM多智能体在SE数据集适配领域的“开山之作”——它没有夸大其词说“多智能体能完全替代人工”,而是用严谨的实验告诉我们:当前系统有潜力(能读文件、生成部分代码),但也有明显局限(功能正确性差、调试弱);而“提示干预”是低成本提效的好办法,尤其是“参考代码”提示。
对SE研究员来说,这篇论文像一张“地图”:既标出了当前能走的“捷径”(Claude+参考代码),也指出了未来要修的“路”(反馈循环、智能体协作)。相信顺着这个方向走,再过1-2年,LLM多智能体或许真能帮研究员把“适配数据集”的时间从几天缩到几小时。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 18
18 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)