
从Prompt Engineering到DSPy
DSPy是一种创新的AI编程框架,旨在通过代码而非手动调整提示词来构建大模型应用。其核心特点包括:1)使用Signature定义任务结构而非具体指令;2)通过Module(如ChainOfThought)自动处理推理逻辑;3)利用Teleprompter自动优化提示。与传统提示工程相比,DSPy实现了三个范式转移:类定义取代自然语言指令、内置思维链机制、自动编译优化。目前DSPy在学术界应用较少,
DSPy:

(6 条消息) 大模型Agent的核心还是prompt? - 知乎

1.核心理念:Prompt 不应该由人来写
“手动调整 Prompt(提示词工程)就像是在写汇编语言,而 DSPy 就像是 C++。”
-
提示词工程: 开发者需要反复修改提示词,比如把 "You are a helpful assistant" 改成 "You are an expert data scientist",不断试错来寻找效果最好的那句话。
-
DSPy: 它的理念是编程,而不是提示。你不需要写具体的 Prompt,而是定义任务的逻辑。具体的 Prompt 由模型DSPy 的编译器根据你的数据自动生成、优化和迭代。
2. DSPy 的三个关键要素
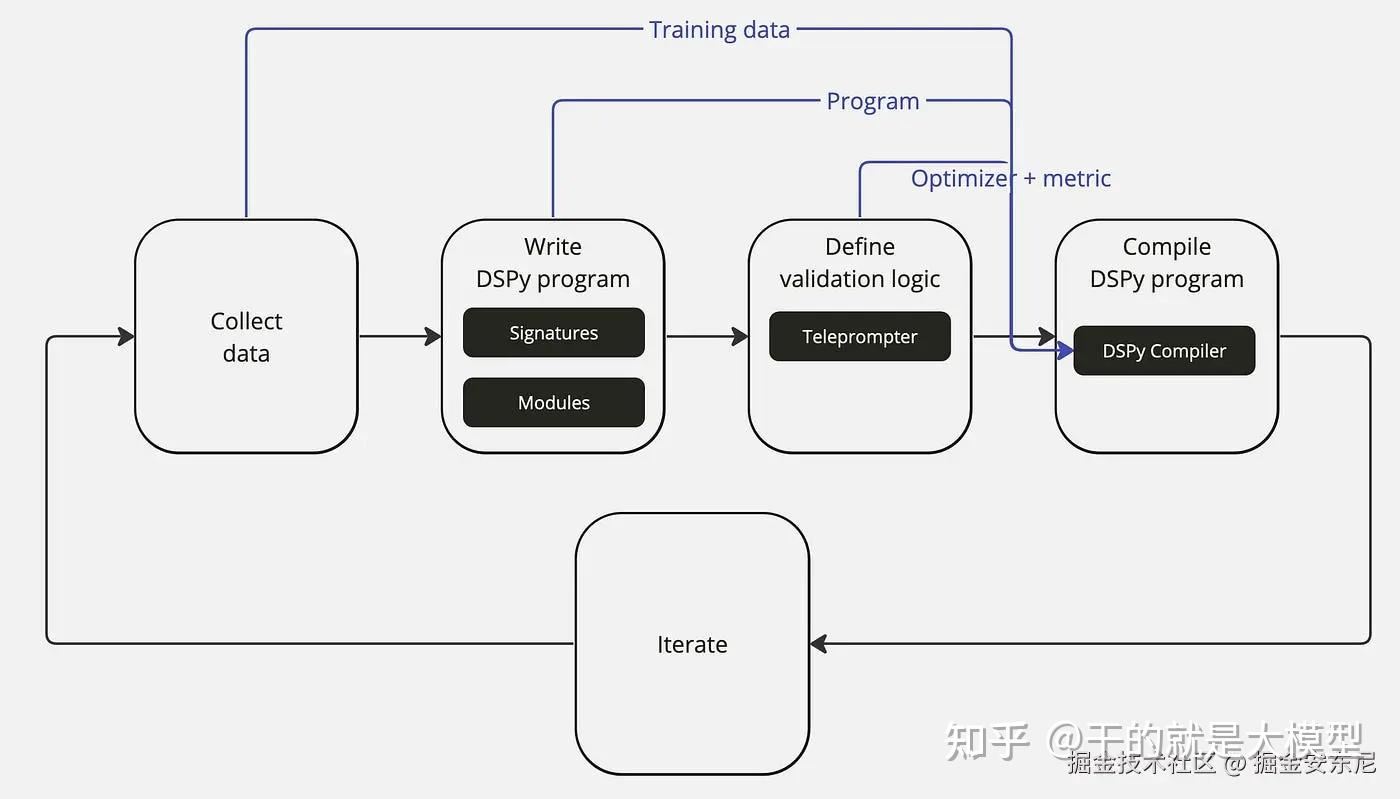
在 DSPy 中,你不再通过自然语言跟模型“聊天”来构建应用,而是通过写代码来定义架构:
-
Signature(签名):定义任务结构
-
定义输入和输出的逻辑,而不是具体的指令。
-
python
class QuestionAnswer(dspy.Signature):
"""根据给定的上下文回答问题。"""
context = dspy.InputField()
question = dspy.InputField()
answer = dspy.OutputField()
-
Module(模块):构建行为
- 如果 Signatures 是 AI 任务的蓝图,那 Modules 就是实现这些蓝图的积木。
-
用来处理逻辑的层,类似于 PyTorch 中的层。
-
例子:
dspy.ChainOfThought(思维链)。你可以直接调用这个模块,DSPy 会自动处理如何让模型进行思维链推理,而不需要你手动写 "Let's think step by step"。
-
- 如果 Signatures 是 AI 任务的蓝图,那 Modules 就是实现这些蓝图的积木。
python
question = "为什么天空是蓝色的?"
thinker = dspy.ChainOfThought('question -> answer', n=3)
response = thinker(question=question)
print(response.answer)
-
Teleprompter / Optimizer(优化器):自动优化AI提示
-
这是图片中提到的“编译器”部分。当你准备好一些高质量的数据集(几条到几百条)后,优化器会自动在后台运行。
-
它会尝试不同的 Few-Shot(少样本)组合,自动调整指令,直到在你的测试集上达到最高的分数。
-
根据任务自动生成高质量的示例、尝试不同的提示组合,找到最佳方案、根据定义的指标评估每个方案的效果、随着数据增加,自动调整和优化。
-
python
from dspy.teleprompt import BootstrapFewShotWithRandomSearch
optimizer = BootstrapFewShotWithRandomSearch(metric=your_metric)
super_qa = optimizer.compile(your_qa_module, trainset=your_data)
3.DSPy Python 代码示例
import dspy
# 1. 配置模型 (这里假设我们连接到了 GPT-4 或其他模型)
# 在实际使用中,你需要填入 API Key
turbo = dspy.OpenAI(model='gpt-3.5-turbo')
dspy.settings.configure(lm=turbo)
# =========================================================
# 核心部分 A: 定义签名 (Signature) -> 定义"做什么"
# =========================================================
class BasicQA(dspy.Signature):
"""回答基于事实的技术问题。""" # 这里的 Docstring 就是给模型的一个微弱暗示
question = dspy.InputField(desc="用户提出的技术问题")
answer = dspy.OutputField(desc="简短、精确的答案")
# =========================================================
# 核心部分 B: 定义模块 (Module) -> 定义"怎么做"
# =========================================================
class CoT_Pipeline(dspy.Module):
def __init__(self):
super().__init__()
# 这里直接调用了 ChainOfThought (思维链) 模块
# 我们不需要自己写 "Let's think step by step"
self.prog = dspy.ChainOfThought(BasicQA)
def forward(self, question):
return self.prog(question=question)
# =========================================================
# 运行
# =========================================================
# 实例化模块
my_agent = CoT_Pipeline()
# 调用
pred = my_agent(question="什么是混合动力汽车的能量管理策略?")
# 打印结果
print(f"推理理由 (Rationale): {pred.rationale}")
print(f"最终答案 (Answer): {pred.answer}")三个范式转移的特性:
1. 只有“类”,没有“话” (Signature)
在 BasicQA 类中,我们只定义了输入字段(question)和输出字段(answer)。
-
传统做法: 你需要写 f-string:"User asks: {question}, please answer it..."
-
DSPy 做法: 像定义函数接口一样定义输入输出。DSPy 会自动把它翻译成模型能懂的 Prompt 格式。
2. 自带思维链 (Module)
注意这行代码:self.prog = dspy.ChainOfThought(BasicQA)。
-
传统做法: 你需要在 Prompt 里手动加上 "Let's think step by step" 或者精心设计 CoT 的引导词。
-
DSPy 做法: 你直接调用
ChainOfThought模块。运行时,DSPy 会自动在 Prompt 里插入这就话,并且——最重要的是——它会自动解析模型输出的“推理过程”和“最终结论”,把它们分别存入pred.rationale和pred.answer。
3. (代码中未展示的) 编译器/优化器
上面的代码只是“写好了程序”。DSPy 最强大的地方在于接下来的**“编译”**(Compile)。
你可以给它喂 10 个正确的“问题-答案”对(Dataset),然后运行 Optimizer(优化器):
from dspy.teleprompt import BootstrapFewShot
# 定义优化器:我要让它自动学习 Few-Shot 例子
teleprompter = BootstrapFewShot(metric=dspy.evaluate.answer_exact_match)
# 编译!
# 这步操作会自动把你的 10 个数据变成 Prompt 里的 Few-Shot 示例,
# 甚至会自动筛选出 10 个例子里哪几个组合在一起效果最好。
compiled_agent = teleprompter.compile(my_agent, trainset=your_dataset)4.目前论文中极少出现DSPy的原因
1. 时间滞后性 (Time Lag)
这是最直接的原因。
-
DSPy 的出现时间: DSPy 虽然是由斯坦福大学(Stanford NLP)提出的,但它真正开始在开发者社区火起来也就是最近半年到一年的事情(Paper 发布于 2023 年 10 月)。
-
学术周期: 你现在看到的顶会论文(如 CVPR, ICML, ICLR 2024/2025),其实验和写作可能是在 6-12 个月前完成的。那时候 DSPy 还处于极其早期的阶段,很不稳定,文档也不全。绝大多数研究者当时还在手动写 "Act as a..."。
2. 研究目的不同:探究“机理” vs 构建“系统”
这是最核心的原因。
-
大多数 LLM 论文在研究什么? 目前大多数论文(包括你的故障诊断领域)关注的是 “大模型本身的能力边界” 或者 “某种特定的提示策略(如 CoT, ToT)是否有效”。
-
为了证明这些,研究者必须控制变量。
-
如果不手动写 Prompt,而是交给 DSPy 自动优化,那么 Prompt 就变成了一个“黑盒”。如果模型效果好,审稿人会问:“是因为你提出的方法好,还是因为 DSPy 碰巧搜到了一个好的 Prompt?”这会让实验结论变得不纯粹。
-
-
DSPy 是为了什么? DSPy 是为了 “工程落地”。它的目标不是为了发文章探究 Prompt 的原理,而是为了在生产环境中把准确率从 85% 提升到 92%。
-
所以,DSPy 目前更多出现在Github 项目、企业落地分享、黑客松中,而不是纯学术论文中。
-
3. 可解释性与复现性 (Reproducibility)
学术论文要求高度的可复现性。
-
传统 Prompt: 作者可以在论文附录里把 Prompt 原文贴出来,读者复制粘贴就能复现结果。
-
DSPy: 它的 Prompt 是动态生成的,而且依赖于具体的“优化集(Validation Set)”。如果你的数据集变了,DSPy 编译出来的 Prompt 可能会完全不同。这对于追求“标准答案”的学术论文来说,解释起来比较麻烦。
4. 成本问题 (Cost)
-
DSPy 的核心是“编译(Compile)”和“优化(Optimize)”。为了找到最佳 Prompt,DSPy 可能会在后台自动跑几十甚至上百次调用(API Calls)来验证效果。
-
对于很多还在用 OpenAI API 做实验的实验室来说,手动写两句就能跑通的事,为什么要花几百倍的 Token 去“搜索”一个 Prompt 呢? 除非是对精度要求极高的场景,否则手动写 Prompt 的性价比在学术实验中往往更高。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)