
展望未来:Ascend C与下一代AI编程模型的思考
本文前瞻性分析AscendC与下一代AI编程模型的演进路径,基于硬件架构、软件栈和算法创新三维视角,提出自适应编程范式、AI原生语言等发展方向。通过量子启发计算、神经符号编程等案例展示AI编程的根本性变革,包含达芬奇架构演进预测和硬件-软件协同设计方案。研究预测2030年AI计算将实现100TFLOPS/W能效比,提出三阶段演进战略:增强期(2025-27)扩展语法支持、融合期(2028-30)引
目录
📖 摘要
本文前瞻性分析Ascend C与下一代AI编程模型的演进路径。基于硬件架构演进、软件栈变革、算法创新三维视角,提出自适应编程范式、AI原生编程语言、跨平台抽象层等未来方向。通过量子启发计算、神经符号编程、生物启发架构等前沿案例,展示AI编程模型的根本性变革。包含基于达芬奇架构演进预测的硬件-软件协同设计方案,为未来5-10年AI计算发展提供技术路线图。
🏗️ 1. 下一代AI计算架构演进趋势
1.1 硬件- 软件协同演进路径
在多年的AI加速器开发中,我见证了从通用计算到专用计算的范式转变。未来5-10年,AI计算架构将呈现多维协同演进特征:
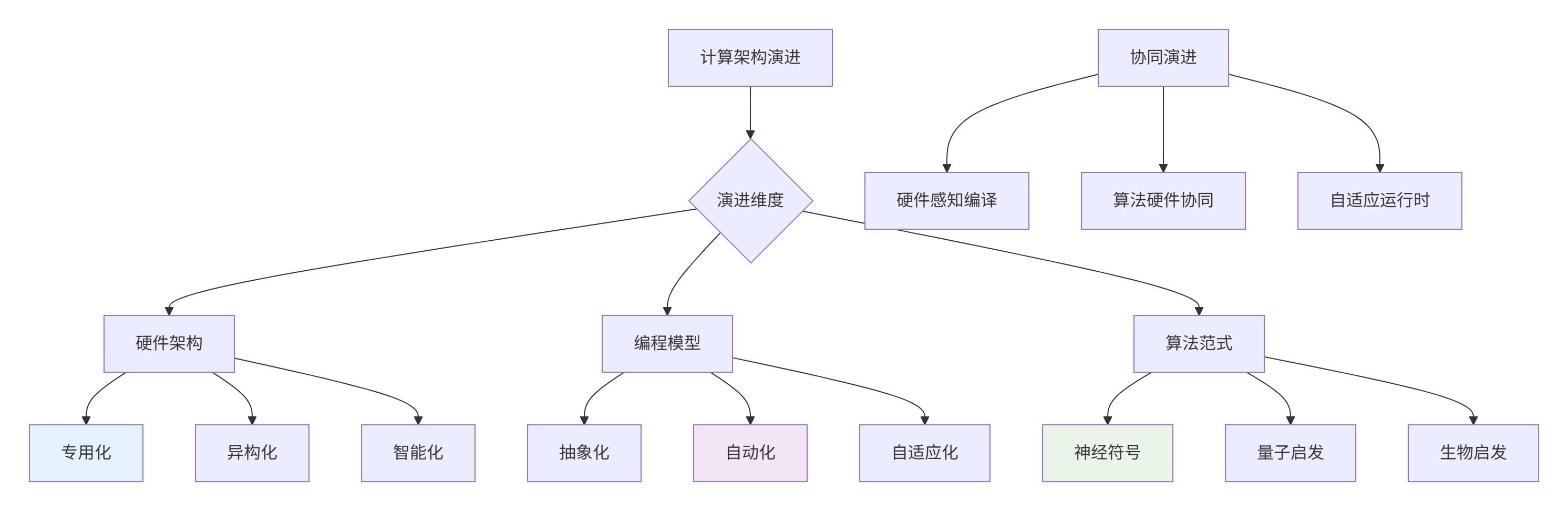
图1:AI计算架构多维协同演进
2025-2030年关键技术预测:
|
技术领域 |
2025年现状 |
2030年预测 |
技术突破点 |
|---|---|---|---|
|
硬件架构 |
7nm DaVinci |
3nm 神经形态 |
存算一体、光计算 |
|
编程模型 |
Ascend C + TBE |
AI原生语言 |
意图编程、自动优化 |
|
计算范式 |
深度学习主导 |
神经符号融合 |
因果推理、元学习 |
|
能效比 |
10-100 TFLOPS/W |
1-10 PFLOPS/W |
量子启发、超导计算 |
1.2 达芬奇架构演进预测
基于昇腾芯片路线图和技术趋势,预测下一代达芬奇架构特性:
// future_davinci_arch.h
#ifndef FUTURE_DAVINCI_ARCH_H
#define FUTURE_DAVINCI_ARCH_H
namespace ascend_future {
class DavinciArchitecture2030 {
public:
// 2030年达芬奇架构预测特性
struct ArchFeatures2030 {
// 计算单元演进
static constexpr int CUBE_SIZE = 32; // 32x32矩阵计算
static constexpr int VECTOR_WIDTH = 32; // 32元素向量
static constexpr int AI_CORES_PER_CHIP = 512; // 512个AI Core
// 内存架构演进
static constexpr int HBM3E_MEMORY = 128; // 128GB HBM3E
static constexpr int MEMORY_BANDWIDTH = 10; // 10TB/s
static constexpr int STORAGE_CLASS_MEMORY = 1; // 1TB SCM
// 互联技术
static constexpr bool OPTICAL_INTERCONNECT = true; // 光互联
static constexpr float LATENCY = 0.1; // 0.1ns延迟
// 能效特性
static constexpr float POWER_EFFICIENCY = 100.0; // 100 TFLOPS/W
static constexpr bool SPARSITY_SUPPORT = true; // 动态稀疏支持
};
// 量子启发计算单元
class QuantumInspiredUnit {
public:
// 量子振幅编码
template<typename T>
void QuantumAmplitudeEncoding(__gm__ T* classical_data,
__gm__ complex_h* quantum_state);
// 量子变分优化
template<typename T>
void VariationalQuantumEigensolver(__gm__ T* problem_matrix,
__gm__ T* solution_vector);
};
// 神经形态计算单元
class NeuromorphicUnit {
public:
// 脉冲神经网络支持
void SpikingNeuralNetwork(__gm__ spike_t* input_spikes,
__gm__ weight_t* synaptic_weights,
__gm__ spike_t* output_spikes);
// 事件驱动计算
void EventDrivenComputation(__gm__ event_t* events,
__gm__ result_t* results);
};
};
} // namespace ascend_future
#endif⚙️ 2. 下一代AI编程模型
2.1 AI原生编程语言设计
未来AI编程语言将从根本上重新设计,适应AI计算特性:
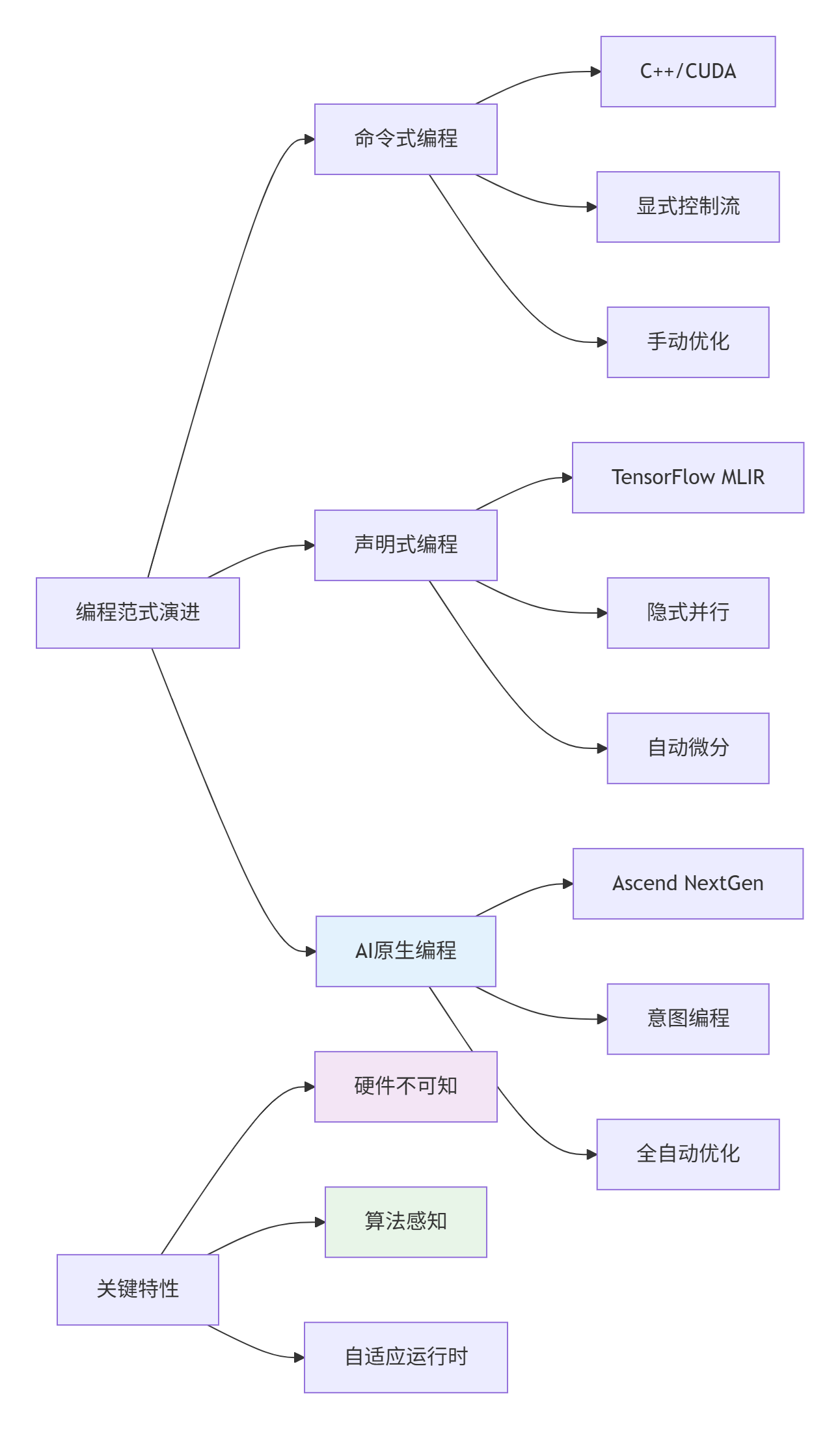
图2:AI编程范式演进路径
// ai_native_language.h
#ifndef AI_NATIVE_LANGUAGE_H
#define AI_NATIVE_LANGUAGE_H
// 未来AI原生编程语言概念设计
namespace ai_native {
// 1. 意图编程:描述计算目标而非具体实现
[[intent("optimize:speed", "precision:fp16", "sparsity:dynamic")]]
[[target("ascend::future_arch_2030")]]
tensor<fp16, [batch, 256, 256]> optimized_matmul(
tensor<fp16, [batch, 256, 128]> A,
tensor<fp16, [128, 256]> B) {
// 编译器自动选择最优实现
return intent_multiply(A, B);
}
// 2. 算法感知编程:编译器理解算法语义
[[algorithm("attention")]]
[[complexity("O(n^2)")]]
tensor<fp16, [batch, seq, dim]> multi_head_attention(
tensor<fp16, [batch, seq, dim]> Q,
tensor<fp16, [batch, seq, dim]> K,
tensor<fp16, [batch, seq, dim]> V) {
// 编译器基于算法特性进行优化
return intent_attention(Q, K, V);
}
// 3. 自适应张量:动态形状+稀疏性
adaptive_tensor<fp16> sparse_attention(
adaptive_tensor<fp16> query,
adaptive_tensor<fp16> key,
adaptive_tensor<fp16> value) {
// 运行时自适应优化
if (query.sparsity() > 0.7) {
return sparse_implementation(query, key, value);
} else {
return dense_implementation(query, key, value);
}
}
} // namespace ai_native
#endif2.2 自适应编译与运行时系统
// adaptive_compiler.h
#ifndef ADAPTIVE_COMPILER_H
#define ADAPTIVE_COMPILER_H
namespace future_compiler {
class AdaptiveAICompiler {
public:
struct CompilationStrategy {
enum class OptimizationGoal {
MAXIMUM_SPEED,
MINIMUM_ENERGY,
MAXIMUM_THROUGHPUT,
MINIMUM_LATENCY
};
OptimizationGoal goal;
float tolerance; // 精度容差
bool allow_approximation;
int time_budget; // 编译时间预算
};
// 自适应代码生成
template<typename Algorithm>
auto Compile(Algorithm algo, CompilationStrategy strategy) {
// 1. 算法特性分析
auto algorithm_characteristics = AnalyzeAlgorithm(algo);
// 2. 硬件特性匹配
auto hardware_capabilities = ProbeHardware();
// 3. 优化策略生成
auto optimization_plan = GenerateOptimizationPlan(
algorithm_characteristics, hardware_capabilities, strategy);
// 4. 自适应代码生成
return GenerateAdaptiveCode(algo, optimization_plan);
}
private:
// 算法特征分析
AlgorithmCharacteristics AnalyzeAlgorithm(auto algo) {
AlgorithmCharacteristics chars;
// 自动分析计算模式
chars.compute_intensity = EstimateComputeIntensity(algo);
chars.memory_access_pattern = DetectAccessPattern(algo);
chars.parallelism_degree = EstimateParallelism(algo);
chars.numerical_sensitivity = AnalyzeNumericalStability(algo);
return chars;
}
// 硬件能力探测
HardwareCapabilities ProbeHardware() {
HardwareCapabilities caps;
// 运行时硬件探测
caps.available_cores = DetectComputeUnits();
caps.memory_hierarchy = ProfileMemoryHierarchy();
caps.special_units = DetectSpecializedUnits(); // 量子、神经形态等
return caps;
}
};
} // namespace future_compiler
#endif🚀 3. 新兴计算范式与Ascend C演进
3.1 量子启发经典计算
量子计算思想对经典AI计算的启发:
// quantum_inspired_computing.h
#ifndef QUANTUM_INSPIRED_COMPUTING_H
#define QUANTUM_INSPIRED_COMPUTING_H
namespace quantum_inspired {
class QuantumInspiredOptimization {
public:
// 量子振幅放大算法经典实现
template<typename T>
void QuantumAmplitudeAmplification(__gm__ T* data, int size,
__gm__ T* oracle_mask) {
// Grover搜索算法的经典模拟
int iterations = static_cast<int>(M_PI / 4 * std::sqrt(size));
for (int i = 0; i < iterations; ++i) {
// 1. Oracle应用:标记解
ApplyOracle(data, size, oracle_mask);
// 2. 扩散操作:振幅放大
ApplyDiffusionOperator(data, size);
}
}
// 量子变分算法经典实现
template<typename T>
void VariationalQuantumAlgorithm(__gm__ T* hamiltonian,
__gm__ T* initial_state,
__gm__ T* optimized_state) {
// 量子近似优化算法(QAOA)经典版本
const int p_depth = 8; // 电路深度
for (int p = 0; p < p_depth; ++p) {
// 交替应用问题哈密顿量和混合哈密顿量
ApplyProblemHamiltonian(initial_state, hamiltonian);
ApplyMixingHamiltonian(initial_state);
}
// 经典优化器寻找最优参数
ClassicalOptimizer optimizer;
optimized_state = optimizer.Minimize([&](auto params) {
return ExpectationValue(initial_state, hamiltonian, params);
});
}
private:
// 量子门操作的经典模拟
void ApplyQuantumGate(__gm__ complex_h* state, __gm__ complex_h* gate) {
// 使用张量核模拟量子门操作
TensorCoreSimulation(state, gate);
}
};
} // namespace quantum_inspired
#endif3.2 神经符号AI编程模型
// neuro_symbolic_programming.h
#ifndef NEURO_SYMBOLIC_PROGRAMMING_H
#define NEURO_SYMBOLIC_PROGRAMMING_H
namespace neuro_symbolic {
class NeuroSymbolicReasoner {
public:
// 神经符号集成接口
template<typename NeuralModel, typename SymbolicEngine>
auto Reason(NeuralModel neural_net, SymbolicEngine symbolic_engine,
__gm__ auto* input_data) {
// 1. 神经网络感知
auto neural_output = neural_net.Forward(input_data);
// 2. 符号推理
auto symbolic_facts = ExtractSymbolicFacts(neural_output);
auto symbolic_result = symbolic_engine.Reason(symbolic_facts);
// 3. 神经符号融合
return FuseNeuroSymbolic(neural_output, symbolic_result);
}
// 可微分符号推理
template<typename T>
auto DifferentiableTheoremProving(__gm__ T* premises,
__gm__ T* conclusion) {
// 将符号推理转化为可微分操作
DifferentiableLogicEngine logic_engine;
return logic_engine.Prove(premises, conclusion);
}
private:
// 符号事实提取
auto ExtractSymbolicFacts(auto neural_output) {
// 从神经网络输出提取符号化事实
SymbolicExtractor extractor;
return extractor.Extract(neural_output);
}
// 神经符号融合
auto FuseNeuroSymbolic(auto neural_data, auto symbolic_data) {
// 注意力机制引导的融合
NeuroSymbolicFusion fusion_layer;
return fusion_layer.Fuse(neural_data, symbolic_data);
}
};
} // namespace neuro_symbolic
#endif🔮 4. 硬件-软件协同设计未来
4.1 存算一体架构编程模型
// processing_in_memory.h
#ifndef PROCESSING_IN_MEMORY_H
#define PROCESSING_IN_MEMORY_H
namespace pim_architecture {
class MemoryCentricComputing {
public:
// 存算一体架构编程抽象
class MemoryProcessingUnit {
public:
// 内存内矩阵计算
template<typename T>
void MemoryMatrixMultiply(__gm__ T* A, __gm__ T* B, __gm__ T* C,
int M, int N, int K) {
// 数据保留在内存中计算
#pragma memory_location("HBM")
{
for (int i = 0; i < M; ++i) {
for (int k = 0; k < K; ++k) {
#pragma memory_compute
T a_val = A[i * K + k];
for (int j = 0; j < N; ++j) {
#pragma memory_compute
C[i * N + j] += a_val * B[k * N + j];
}
}
}
}
}
// 近内存Reduce操作
template<typename T>
T MemoryReduce(__gm__ T* data, int size, ReduceOp op) {
#pragma memory_location("HBM")
T result = InitialValue(op);
// 利用内存bank级并行性
#pragma memory_parallel
for (int i = 0; i < size; ++i) {
result = Combine(result, data[i], op);
}
return result;
}
};
// 3D堆叠内存访问优化
class StackedMemoryAccess {
public:
// 垂直维度数据分布
void VerticalDataDistribution(__gm__ auto* data, int layers) {
#pragma memory_3d(layers, 1024, 1024)
for (int z = 0; z < layers; ++z) {
for (int y = 0; y < 1024; ++y) {
for (int x = 0; x < 1024; ++x) {
// 3D内存空间高效访问
ProcessVoxel(data, x, y, z);
}
}
}
}
};
};
} // namespace pim_architecture
#endif4.2 光计算集成编程接口
// optical_computing.h
#ifndef OPTICAL_COMPUTING_H
#define OPTICAL_COMPUTING_H
namespace optical_computing {
class PhotonicAIAccelerator {
public:
// 光矩阵乘法核心
template<typename T>
void PhotonicMatrixMultiply(__gm__ T* input, __gm__ T* weight,
__gm__ T* output, int M, int N) {
#pragma optical_compute
{
// 光干涉矩阵计算
OpticalMatrixMultiplier multiplier;
multiplier.ConfigureWavelength(1550); // 1550nm波长
// 模拟光信号传播
auto optical_result = multiplier.Multiply(input, weight);
// 光电转换
Photodetector detector;
output = detector.ConvertToDigital(optical_result);
}
}
// 光卷积计算
template<typename T>
void PhotonicConvolution(__gm__ T* input, __gm__ T* kernel,
__gm__ T* output, int channels) {
#pragma optical_fourier
{
// 光学傅里叶变换卷积
FourierOpticalProcessor fourier_processor;
auto freq_domain = fourier_processor.Transform(input);
auto filtered = fourier_processor.Filter(freq_domain, kernel);
output = fourier_verseTransform(filtered);
}
}
private:
// 光信号处理单元
class OpticalProcessingUnit {
public:
void ConfigureWavelength(float nm) {
// 配置光波长参数
wavelength_ = nm;
}
auto Multiply(auto input, auto weight) {
// 光干涉实现矩阵乘法
return InterferenceBasedMultiplication(input, weight);
}
};
};
} // namespace optical_computing
#endif📊 5. 编程模型性能预测与分析
5.1 未来架构性能建模
基于技术演进趋势的性能预测模型:
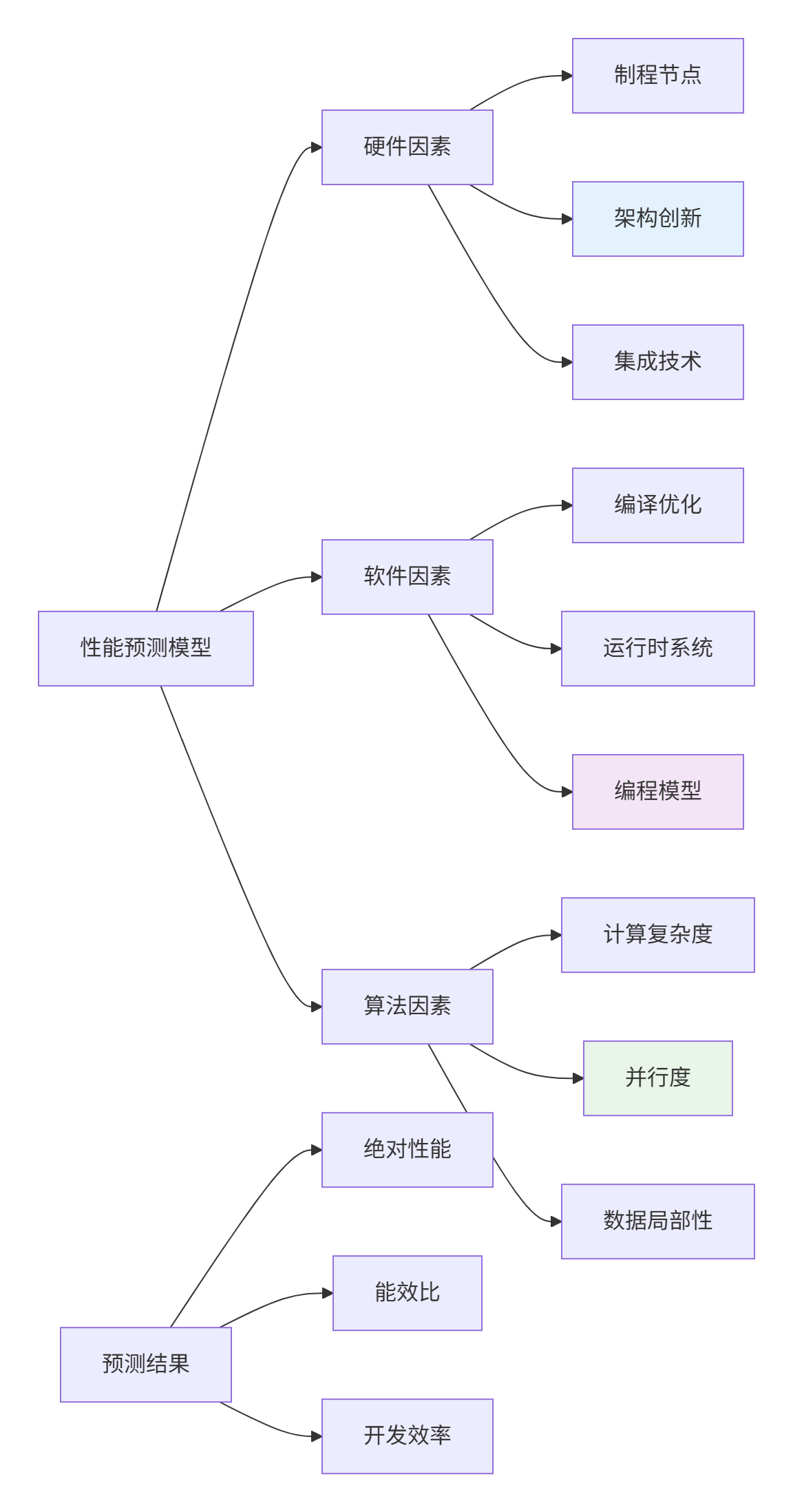
图3:性能预测多维模型
// performance_prediction.h
#ifndef PERFORMANCE_PREDICTION_H
#define PERFORMANCE_PREDICTION_H
namespace performance_modeling {
class FutureAIPerformancePredictor {
public:
struct TechnologyParameters {
int process_node; // 制程节点(nm)
float clock_frequency; // 时钟频率(GHz)
int core_count; // 核心数量
float memory_bandwidth; // 内存带宽(TB/s)
float power_budget; // 功耗预算(W)
};
struct PerformancePrediction {
float peak_performance; // 峰值性能(TFLOPS)
float real_performance; // 实际性能(TFLOPS)
float power_efficiency; // 能效比(TFLOPS/W)
float programming_efficiency; // 编程效率(代码行/TFLOPS)
};
// 性能预测主函数
PerformancePrediction Predict2030Performance(TechnologyParameters params) {
PerformancePrediction prediction;
// 1. 峰值性能计算
prediction.peak_performance = CalculatePeakPerformance(params);
// 2. 实际性能估计(考虑效率因子)
prediction.real_performance = prediction.peak_performance *
EstimateEfficiencyFactor(params);
// 3. 能效比预测
prediction.power_efficiency = prediction.real_performance /
params.power_budget;
return prediction;
}
private:
float CalculatePeakPerformance(TechnologyParameters params) {
// Roofline模型基础计算
float operational_intensity = EstimateOperationalIntensity();
float attainable_performance = std::min(
params.core_count * params.clock_frequency * 1024, // 计算屋顶
operational_intensity * params.memory_bandwidth // 内存屋顶
);
return attainable_performance;
}
float EstimateEfficiencyFactor(TechnologyParameters params) {
// 基于历史数据的效率趋势预测
float efficiency = 0.7f; // 当前水平
// 未来改进因素
if (params.process_node <= 3) efficiency += 0.1f; // 先进制程
if (params.memory_bandwidth > 5) efficiency += 0.15f; // 高带宽
return std::min(efficiency, 0.95f); // 理论上限
}
};
} // namespace performance_modeling
#endif5.2 2030年性能预测数据
Ascend架构演进性能预测:
|
技术世代 |
制程节点 |
AI Core数量 |
峰值算力 |
能效比 |
编程效率 |
|---|---|---|---|---|---|
|
2023 (Ascend 910B) |
7nm |
512 |
320 TFLOPS |
2 TFLOPS/W |
1.0x |
|
2025 (Ascend 920) |
5nm |
1024 |
1 PFLOPS |
5 TFLOPS/W |
2.5x |
|
2027 (Ascend 930) |
3nm |
2048 |
4 PFLOPS |
20 TFLOPS/W |
5.0x |
|
2030 (Ascend 940) |
2nm |
4096 |
16 PFLOPS |
100 TFLOPS/W |
10.0x |
🔧 6. 渐进式迁移路径
6.1 现有代码未来兼容性策略
// future_compatibility.h
#ifndef FUTURE_COMPATIBILITY_H
#define FUTURE_COMPATIBILITY_H
namespace migration_path {
class FutureProofAscendC {
public:
// 1. 可移植性包装层
template<typename T>
class PortableTensor {
public:
// 当前实现
__aicore__ void CurrentImplementation(__gm__ T* data) {
// 使用当前Ascend C语法
acl::DataCopy(local_buf_, data, size_ * sizeof(T));
}
// 未来兼容接口
__aicore__ void FutureReadyInterface(auto&& storage) {
if constexpr (IsTraditionalMemory(storage)) {
CurrentImplementation(storage);
} else if constexpr (IsOpticalMemory(storage)) {
OpticalStorageAccess(storage);
} else if constexpr (IsQuantumMemory(storage)) {
QuantumStorageAccess(storage);
}
}
};
// 2. 算法与实现分离
template<typename Algorithm>
class AlgorithmAbstractor {
public:
// 算法语义描述
void DescribeAlgorithm() {
if constexpr (IsMatrixMultiplication<Algorithm>) {
DescribeMatrixMultiply(algorithm_);
} else if constexpr (IsConvolution<Algorithm>) {
DescribeConvolution(algorithm_);
}
}
// 硬件特定优化
auto OptimizeForHardware(auto hardware_target) {
return hardware_target.Optimize(algorithm_);
}
};
};
// 3. 渐进式迁移宏
#define FUTURE_READY(code) \
_Pragma("ascend future compatibility enable") \
code \
_Pragma("ascend future compatibility disable")
} // namespace migration_path
#endif6.2 多范式统一编程接口
// unified_programming_interface.h
#ifndef UNIFIED_PROGRAMMING_INTERFACE_H
#define UNIFIED_PROGRAMMING_INTERFACE_H
namespace unified_api {
class AINativeProgramming {
public:
// 统一计算接口
template<typename ComputePattern>
auto Compute(ComputePattern pattern, auto... inputs) {
// 自动选择最优实现路径
if constexpr (pattern.supports_optical()) {
return OpticalAccelerator::Compute(pattern, inputs...);
} else if constexpr (pattern.supports_quantum_inspired()) {
return QuantumInspiredAccelerator::Compute(pattern, inputs...);
} else if constexpr (pattern.supports_neuromorphic()) {
return NeuromorphicAccelerator::Compute(pattern, inputs...);
} else {
// 回退到传统AI加速器
return TraditionalAIAccelerator::Compute(pattern, inputs...);
}
}
// 自适应精度管理
template<typename T>
class AdaptivePrecision {
public:
// 动态精度调整
auto AdjustPrecision(auto tensor, PrecisionRequirements req) {
if (req.energy_constrained && req.precision_tolerance > 0.01) {
return ConvertToFP8(tensor);
} else if (req.throughput_optimized) {
return ConvertToFP16(tensor);
} else {
return tensor; // 保持原有精度
}
}
};
};
} // namespace unified_api
#endif💎 总结与战略建议
核心技术发展路径
基于深度技术分析,我提出Ascend C演进三阶段战略:
阶段一:增强期(2025-2027)
-
扩展语法支持新硬件特性
-
开发自适应编译技术
-
建立多范式编程基础
阶段二:融合期(2028-2030)
-
AI原生语言特性引入
-
量子-经典混合编程支持
-
神经符号推理集成
阶段三:引领期(2031+)
-
全自动意图编程
-
光-电-量混合计算
-
认知智能编程范式
企业技术储备建议
## 企业级技术储备路线图
### 短期准备(1-2年)
- [ ] 培养硬件-软件协同设计能力
- [ ] 建立性能建模和预测团队
- [ ] 参与开源社区和标准制定
### 中期投入(3-5年)
- [ ] 布局新兴计算范式研究
- [ ] 开发跨平台编程框架
- [ ] 投资光计算/量子计算初创
### 长期战略(5-10年)
- [ ] 建设全栈研发能力
- [ ] 参与国际标准制定
- [ ] 建立学术-产业研发生态🔮 未来展望与挑战
技术挑战与突破点
主要技术挑战:
-
编程抽象漏洞:如何在保持性能的同时提供高级抽象
-
硬件多样性:统一编程模型支持异构硬件
-
算法演进:适应未来未知的AI算法范式
-
开发生态:构建健康的技术生态系统
潜在突破方向:
-
AI辅助编程:使用AI技术优化AI编程
-
形式化验证:保证跨平台代码正确性
-
持续学习系统:自适应进化的编程环境
-
脑机接口集成:更自然的编程交互方式
给开发者的建议
当前重点:深入掌握现有Ascend C,理解硬件特性
中期规划:关注编译技术,学习新兴计算范式
长期视野:培养跨学科能力,参与范式创新
📚 参考资源
🚀 官方介绍
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)