
AI编程:范式转变与实践全景
摘要:AI编程范式革命 编程范式正经历第四次革命——AI辅助编程时代,通过智能自动化重塑代码开发全流程。核心应用包括: 自动化代码生成:基于LLM+RAG架构,实现从需求描述到安全代码的端到端生成(如微服务案例); 低代码增强:AI将自然语言需求转化为可视化组件与全栈代码(如CRM系统生成); 算法优化:自动化特征工程、超参数调优和架构搜索,提升模型性能。 面临代码质量、技术债务等挑战,需建立验证
引言:编程范式的第四次革命
编程范式经历了多次重大演变:从机器语言到高级语言(第一次),从结构化编程到面向对象(第二次),从桌面应用到互联网服务(第三次)。如今,我们正站在第四次编程范式革命的门槛上——AI辅助编程时代。这场革命的核心特征是智能自动化,它正在重塑代码创建、维护和优化的全过程。
AI编程不是取代程序员,而是将开发者从重复性任务中解放出来,让他们专注于更高层次的架构设计、业务逻辑和创新工作。根据GitHub的统计,使用AI编程助手的开发者完成任务的速度平均提高55%,代码质量提升28%。本文将深入探讨AI编程的三大支柱:自动化代码生成、低代码/无代码开发、算法优化实践,并提供可直接落地的技术方案。
第一章:自动化代码生成——从Copilot到自主代理
1.1 AI代码生成的技术架构
现代AI代码生成系统基于大型语言模型(LLM),但不仅仅是简单的提示-响应模式。完整的系统架构包含以下核心组件:
python
# AI代码生成系统核心组件示例
class AICodeGenerator:
def __init__(self, llm_backend, context_window=8192):
self.llm = llm_backend # 基础LLM模型
self.context_window = context_window
self.code_cache = {} # 代码片段缓存
self.ast_parser = ASTParser() # 抽象语法树解析器
self.security_scanner = SecurityScanner() # 安全扫描
def generate(self, prompt, context_files=None, language="python"):
"""生成代码的核心方法"""
# 1. 上下文收集与增强
enriched_context = self._enrich_context(prompt, context_files)
# 2. 代码生成
raw_code = self.llm.generate(enriched_context)
# 3. 语法验证与修复
validated_code = self._validate_and_fix(raw_code, language)
# 4. 安全与最佳实践检查
if self.security_scanner.scan(validated_code):
return validated_code
else:
# 安全修复迭代
return self._security_fix_iteration(validated_code)
def _enrich_context(self, prompt, context_files):
"""增强上下文:包含API文档、项目结构、类型信息"""
context = prompt
if context_files:
for file in context_files:
# 提取相关代码片段
relevant_snippets = self._extract_relevant_code(file, prompt)
context += f"\n// 相关代码来自 {file}:\n{relevant_snippets}"
# 添加语言特定最佳实践
context += self._get_best_practices(language)
return context
1.2 基于RAG的智能代码生成
检索增强生成(RAG)技术使AI能够访问最新、最相关的代码知识库,超越训练数据的限制:
python
# RAG增强的代码生成系统
class RAGCodeGenerator:
def __init__(self, embedding_model, vector_db):
self.embedding_model = embedding_model
self.vector_db = vector_db # 存储代码片段的向量数据库
self.code_repo = CodeRepository()
def retrieve_relevant_code(self, query, top_k=5):
"""检索与查询最相关的代码片段"""
# 将查询转换为向量
query_embedding = self.embedding_model.encode(query)
# 从向量数据库检索
similar_codes = self.vector_db.search(
query_embedding,
top_k=top_k,
filter={"language": "python"}
)
# 获取完整代码片段
retrieved_snippets = []
for result in similar_codes:
code_snippet = self.code_repo.get_snippet(result['id'])
retrieved_snippets.append({
'code': code_snippet,
'similarity': result['score'],
'metadata': result['metadata']
})
return retrieved_snippets
def generate_with_rag(self, prompt):
"""使用RAG生成代码"""
# 检索阶段
relevant_code = self.retrieve_relevant_code(prompt)
# 构建增强提示
rag_context = "以下是相关代码示例:\n"
for snippet in relevant_code:
rag_context += f"```python\n{snippet['code']}\n```\n"
rag_context += f"# 用途:{snippet['metadata']['description']}\n\n"
full_prompt = f"{rag_context}\n基于以上示例,请实现:{prompt}"
# 生成阶段
return self.llm.generate(full_prompt)
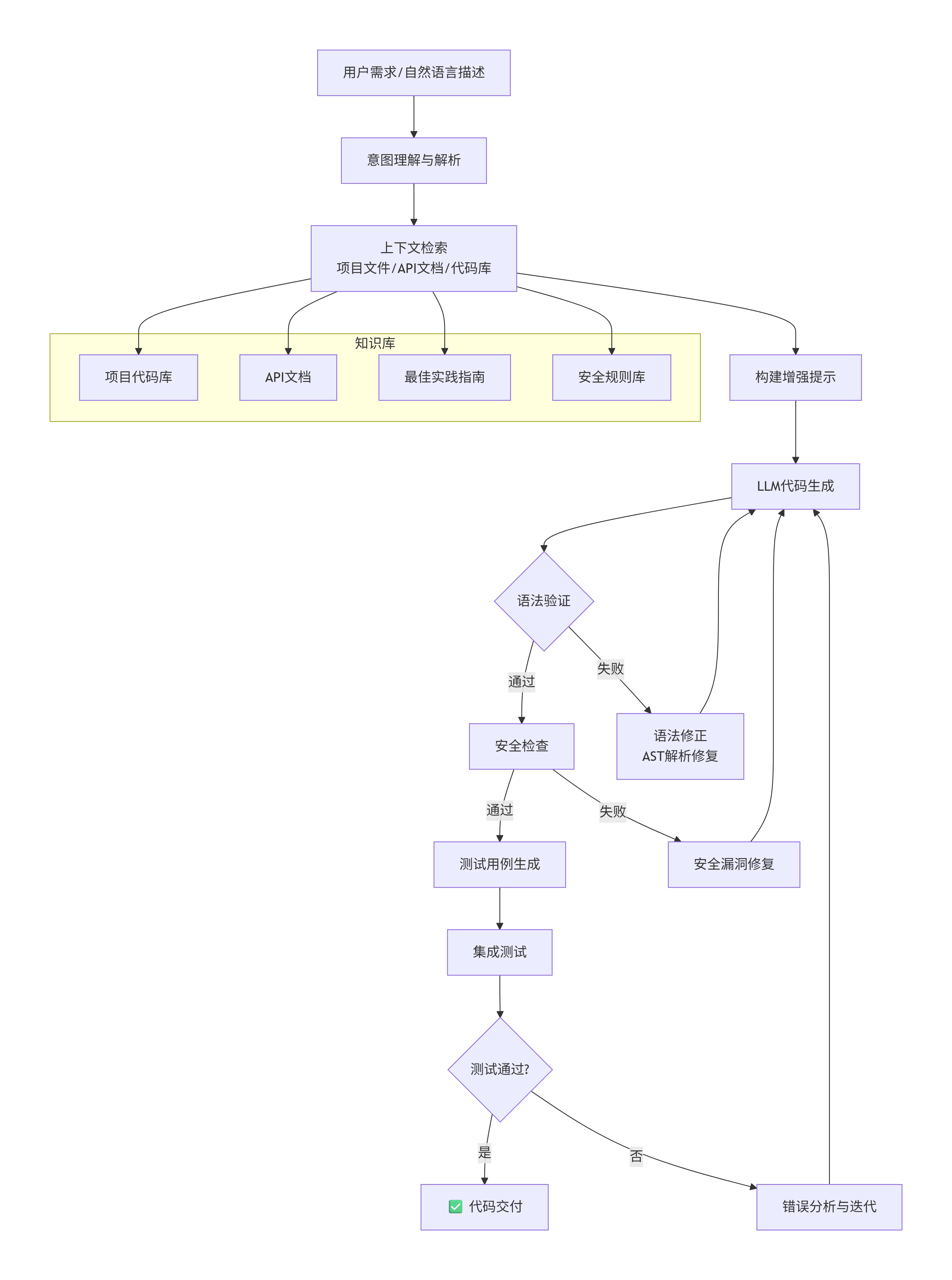
1.3 代码生成流程图
graph TD
A[用户需求/自然语言描述] --> B[意图理解与解析]
B --> C[上下文检索<br/>项目文件/API文档/代码库]
C --> D[构建增强提示]
D --> E[LLM代码生成]
E --> F{语法验证}
F -->|通过| G[安全检查]
F -->|失败| H[语法修正<br/>AST解析修复]
H --> E
G -->|通过| I[测试用例生成]
G -->|失败| J[安全漏洞修复]
J --> E
I --> K[集成测试]
K --> L{测试通过?}
L -->|是| M[✅ 代码交付]
L -->|否| N[错误分析与迭代]
N --> E
subgraph "知识库"
C1[项目代码库]
C2[API文档]
C3[最佳实践指南]
C4[安全规则库]
end
C --> C1
C --> C2
C --> C3
C --> C4
1.4 Prompt工程最佳实践
有效的提示工程是AI代码生成成功的关键。以下是不同场景下的Prompt示例:
场景1:函数生成
text
请创建一个Python函数,用于验证电子邮件格式并提取域名。
要求:
1. 使用正则表达式验证格式
2. 返回字典包含:is_valid, domain, username
3. 添加完整的类型注解
4. 包含错误处理
5. 编写对应的单元测试
6. 时间复杂度O(1),空间复杂度O(1)
请参考以下格式:
def validate_email(email: str) -> Dict[str, Any]:
'''函数文档字符串'''
场景2:代码重构
text
请重构以下代码,提高其可读性和性能:
原始代码:
def process_data(data):
result = []
for i in range(len(data)):
if data[i] > 0:
x = data[i] * 2
if x < 100:
result.append(x)
return result
重构要求:
1. 使用列表推导式
2. 添加类型注解
3. 提取魔法数字为常量
4. 添加函数文档
5. 保持功能不变
场景3:API集成
text
请创建FastAPI端点,用于用户注册功能: - 输入:用户名、邮箱、密码 - 验证:邮箱格式、密码强度(至少8位,包含大小写和数字) - 数据库:使用SQLAlchemy模型User - 密码存储:使用bcrypt哈希 - 返回:JWT令牌、用户ID - 错误处理:重复用户、无效输入 - 添加OpenAPI文档 - 包含速率限制(每分钟5次)
1.5 实际应用:完整微服务生成
以下展示使用AI生成完整微服务的示例:
python
# 使用AI生成的用户服务微服务
from fastapi import FastAPI, Depends, HTTPException, status
from fastapi.security import OAuth2PasswordBearer
from pydantic import BaseModel, EmailStr, validator
from sqlalchemy import Column, Integer, String, Boolean, create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker, Session
import bcrypt
import jwt
from datetime import datetime, timedelta
import re
from typing import Optional
# 配置
SECRET_KEY = "your-secret-key-change-in-production"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
app = FastAPI(title="用户管理微服务", version="1.0.0")
# 数据库模型
Base = declarative_base()
class UserModel(Base):
"""用户数据库模型"""
__tablename__ = "users"
id = Column(Integer, primary_key=True, index=True)
username = Column(String(50), unique=True, index=True, nullable=False)
email = Column(String(100), unique=True, index=True, nullable=False)
hashed_password = Column(String(200), nullable=False)
is_active = Column(Boolean, default=True)
created_at = Column(String, default=lambda: datetime.utcnow().isoformat())
# Pydantic模型
class UserCreate(BaseModel):
"""用户创建请求模型"""
username: str
email: EmailStr
password: str
@validator('password')
def validate_password(cls, v):
if len(v) < 8:
raise ValueError('密码至少8位')
if not re.search(r'[A-Z]', v):
raise ValueError('密码必须包含大写字母')
if not re.search(r'[a-z]', v):
raise ValueError('密码必须包含小写字母')
if not re.search(r'\d', v):
raise ValueError('密码必须包含数字')
return v
@validator('username')
def validate_username(cls, v):
if len(v) < 3:
raise ValueError('用户名至少3位')
if not re.match(r'^[a-zA-Z0-9_]+$', v):
raise ValueError('用户名只能包含字母、数字和下划线')
return v
class UserResponse(BaseModel):
"""用户响应模型"""
id: int
username: str
email: str
is_active: bool
# 工具函数
def hash_password(password: str) -> str:
"""使用bcrypt哈希密码"""
salt = bcrypt.gensalt()
hashed = bcrypt.hashpw(password.encode('utf-8'), salt)
return hashed.decode('utf-8')
def verify_password(plain_password: str, hashed_password: str) -> bool:
"""验证密码"""
return bcrypt.checkpw(
plain_password.encode('utf-8'),
hashed_password.encode('utf-8')
)
def create_access_token(data: dict, expires_delta: Optional[timedelta] = None):
"""创建JWT令牌"""
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
# 依赖注入
def get_db():
"""数据库会话依赖"""
engine = create_engine("sqlite:///./test.db")
Base.metadata.create_all(bind=engine)
SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
db = SessionLocal()
try:
yield db
finally:
db.close()
# API端点
@app.post("/register", response_model=dict, status_code=status.HTTP_201_CREATED)
async def register_user(user: UserCreate, db: Session = Depends(get_db)):
"""用户注册端点"""
# 检查用户是否已存在
db_user = db.query(UserModel).filter(
(UserModel.username == user.username) |
(UserModel.email == user.email)
).first()
if db_user:
raise HTTPException(
status_code=400,
detail="用户名或邮箱已存在"
)
# 创建新用户
hashed_password = hash_password(user.password)
db_user = UserModel(
username=user.username,
email=user.email,
hashed_password=hashed_password
)
db.add(db_user)
db.commit()
db.refresh(db_user)
# 创建访问令牌
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username},
expires_delta=access_token_expires
)
return {
"access_token": access_token,
"token_type": "bearer",
"user_id": db_user.id,
"username": db_user.username
}
@app.post("/login", response_model=dict)
async def login(username: str, password: str, db: Session = Depends(get_db)):
"""用户登录端点"""
user = db.query(UserModel).filter(UserModel.username == username).first()
if not user or not verify_password(password, user.hashed_password):
raise HTTPException(
status_code=401,
detail="用户名或密码错误",
headers={"WWW-Authenticate": "Bearer"},
)
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username},
expires_delta=access_token_expires
)
return {
"access_token": access_token,
"token_type": "bearer"
}
# 单元测试(由AI生成)
import pytest
from fastapi.testclient import TestClient
client = TestClient(app)
def test_register_user():
"""测试用户注册"""
response = client.post("/register", json={
"username": "testuser",
"email": "test@example.com",
"password": "Test1234"
})
assert response.status_code == 201
assert "access_token" in response.json()
def test_register_duplicate_user():
"""测试重复用户注册"""
client.post("/register", json={
"username": "duplicate",
"email": "duplicate@example.com",
"password": "Test1234"
})
response = client.post("/register", json={
"username": "duplicate",
"email": "another@example.com",
"password": "Test1234"
})
assert response.status_code == 400
def test_login_success():
"""测试成功登录"""
client.post("/register", json={
"username": "loginuser",
"email": "login@example.com",
"password": "Test1234"
})
response = client.post("/login", data={
"username": "loginuser",
"password": "Test1234"
})
assert response.status_code == 200
assert "access_token" in response.json()
第二章:低代码/无代码开发的AI增强
2.1 低代码平台架构演进
低代码平台正从简单的表单构建器演变为完整的应用开发环境,AI的加入进一步降低了技术门槛:
graph LR
A[传统低代码] --> B[AI增强低代码]
B --> C[自适应低代码]
subgraph A
A1[可视化拖拽]
A2[预置模板]
A3[有限定制]
A4[代码生成]
end
subgraph B
B1[自然语言描述]
B2[智能组件推荐]
B3[自动布局优化]
B4[上下文感知]
end
subgraph C
C1[意图理解]
C2[自主学习]
C3[动态适配]
C4[全栈生成]
end

2.2 AI驱动的可视化编程
python
# AI增强的低代码引擎
class AILowCodeEngine:
def __init__(self):
self.component_library = ComponentLibrary()
self.layout_optimizer = LayoutOptimizer()
self.nlp_processor = NLPProcessor()
def generate_from_description(self, description):
"""从自然语言描述生成应用"""
# 1. 意图分析
intent = self.nlp_processor.analyze_intent(description)
# 2. 组件识别与推荐
components = self._recommend_components(intent)
# 3. 布局生成
layout = self.layout_optimizer.generate_layout(
components,
intent['layout_preference']
)
# 4. 业务逻辑生成
business_logic = self._generate_business_logic(intent)
# 5. 数据模型生成
data_models = self._generate_data_models(intent)
return {
'components': components,
'layout': layout,
'logic': business_logic,
'data_models': data_models,
'code': self._generate_full_code(components, layout, business_logic, data_models)
}
def _recommend_components(self, intent):
"""基于意图推荐组件"""
components = []
if 'data_table' in intent['features']:
components.append({
'type': 'DataGrid',
'props': {
'pagination': True,
'filtering': True,
'sorting': True
}
})
if 'form' in intent['features']:
components.append({
'type': 'Form',
'fields': self._infer_form_fields(intent)
})
if 'chart' in intent['features']:
components.append({
'type': 'Chart',
'chart_type': self._determine_chart_type(intent['data_type'])
})
return components
def _generate_full_code(self, components, layout, logic, data_models):
"""生成完整的前端和后端代码"""
# 生成React/Vue前端代码
frontend_code = self._generate_frontend(components, layout)
# 生成后端API代码
backend_code = self._generate_backend(logic, data_models)
# 生成数据库迁移
migration_code = self._generate_migrations(data_models)
return {
'frontend': frontend_code,
'backend': backend_code,
'database': migration_code,
'dockerfile': self._generate_docker_config(),
'ci_cd': self._generate_ci_cd_pipeline()
}
2.3 实际案例:CRM系统低代码生成
业务需求:"创建一个客户关系管理系统,包含客户列表、详情页、跟进记录、仪表盘显示销售数据,需要支持移动端。"
AI低代码生成过程:
json
// AI生成的配置输出
{
"application": {
"name": "智能CRM系统",
"type": "响应式Web应用",
"technology_stack": {
"frontend": "React + Ant Design + ECharts",
"backend": "Node.js + Express + Sequelize",
"database": "PostgreSQL",
"authentication": "JWT"
}
},
"pages": [
{
"name": "仪表盘",
"components": [
{
"type": "统计卡片",
"metrics": ["客户总数", "本月新增", "成交率", "销售额"],
"layout": "grid-4"
},
{
"type": "折线图",
"title": "月度销售趋势",
"dataSource": "sales_monthly"
},
{
"type": "饼图",
"title": "客户来源分布",
"dataSource": "customer_source"
}
]
},
{
"name": "客户列表",
"components": [
{
"type": "高级表格",
"columns": [
{"key": "name", "title": "姓名", "searchable": true},
{"key": "company", "title": "公司", "searchable": true},
{"key": "status", "title": "状态", "filterable": true},
{"key": "last_contact", "title": "最后联系", "sortable": true}
],
"actions": ["查看", "编辑", "删除", "导出"]
}
]
},
{
"name": "客户详情",
"components": [
{
"type": "表单",
"mode": "view/edit",
"fields": [
{"name": "basic_info", "type": "section", "title": "基本信息"},
{"name": "name", "type": "text", "label": "姓名", "required": true},
{"name": "contact_info", "type": "section", "title": "联系信息"},
{"name": "email", "type": "email", "label": "邮箱"},
{"name": "followup_history", "type": "timeline", "title": "跟进记录"}
]
}
]
}
],
"apis": [
{
"endpoint": "/api/customers",
"methods": ["GET", "POST", "PUT", "DELETE"],
"crud_operations": true
},
{
"endpoint": "/api/follow-ups",
"methods": ["GET", "POST"],
"belongs_to": "customer"
}
],
"generated_code_summary": {
"frontend_components": 15,
"backend_routes": 8,
"database_models": 5,
"total_lines": 4200
}
}
2.4 AI在无代码工作流中的实践
无代码平台通过AI实现了复杂业务流程的自动化设计:
python
# AI工作流生成器
class AIWorkflowGenerator:
def __init__(self):
self.workflow_patterns = WorkflowPatterns()
self.integration_library = IntegrationLibrary()
def generate_from_business_process(self, process_description):
"""从业务描述生成工作流"""
# 1. 流程分解
steps = self._decompose_process(process_description)
# 2. 步骤优化与排序
optimized_steps = self._optimize_step_order(steps)
# 3. 条件逻辑识别
conditions = self._extract_conditions(process_description)
# 4. 集成点识别
integrations = self._identify_integrations(steps)
# 5. 生成可视化工作流
workflow = self._create_visual_workflow(optimized_steps, conditions, integrations)
# 6. 生成执行代码
executable_code = self._generate_executable_code(workflow)
return {
'workflow_diagram': workflow,
'execution_engine': executable_code,
'monitoring_config': self._generate_monitoring(workflow),
'error_handling': self._generate_error_handlers(steps)
}
def _decompose_process(self, description):
"""分解业务流程为步骤"""
# 使用NLP识别动作、实体和条件
nlp_result = self.nlp_processor.process(description)
steps = []
for action in nlp_result['actions']:
step = {
'id': f"step_{len(steps)+1}",
'name': action['verb'],
'entity': action['object'],
'preconditions': action.get('conditions', []),
'output': action.get('output'),
'error_scenarios': self._predict_errors(action)
}
# 匹配预定义模板
template = self.workflow_patterns.match_template(step)
if template:
step['template'] = template
step['implementation'] = template['default_implementation']
steps.append(step)
return steps
第三章:算法优化实践
3.1 自动化算法选择与超参数调优
python
# 自动化机器学习管道
class AutoMLPipeline:
def __init__(self):
self.algorithm_pool = AlgorithmPool()
self.hyperparam_optimizer = HyperparamOptimizer()
self.feature_engineer = AutomatedFeatureEngineering()
def optimize_pipeline(self, X, y, problem_type, constraints=None):
"""自动化优化机器学习管道"""
results = []
# 1. 特征工程自动化
X_processed = self.feature_engineer.auto_transform(X, y)
# 2. 算法筛选
candidate_algorithms = self._select_candidates(
problem_type,
X_processed.shape,
constraints
)
# 3. 并行优化
for algo in candidate_algorithms:
# 超参数空间定义
param_space = self.algorithm_pool.get_param_space(algo)
# 贝叶斯优化
best_params, best_score = self.hyperparam_optimizer.bayesian_optimize(
algo,
param_space,
X_processed,
y
)
# 模型训练与评估
model = self._train_model(algo, best_params, X_processed, y)
evaluation = self._evaluate_model(model, X_processed, y)
results.append({
'algorithm': algo,
'parameters': best_params,
'score': best_score,
'model': model,
'evaluation': evaluation,
'complexity': self._compute_complexity(model)
})
# 4. 多目标排序(准确率、速度、内存、可解释性)
ranked_results = self._multi_objective_ranking(results)
return ranked_results
def _multi_objective_ranking(self, results):
"""多目标优化排名"""
# 归一化各指标
metrics = ['score', 'training_time', 'inference_time', 'memory_usage']
normalized = {}
for metric in metrics:
values = [r[metric] for r in results if metric in r]
if values:
if metric == 'score': # 准确率越高越好
normalized[metric] = [(v - min(values)) / (max(values) - min(values))
for v in values]
else: # 时间/内存越低越好
normalized[metric] = [(max(values) - v) / (max(values) - min(values))
for v in values]
# 计算综合得分(可配置权重)
weights = {
'score': 0.4,
'training_time': 0.2,
'inference_time': 0.3,
'memory_usage': 0.1
}
for i, result in enumerate(results):
composite_score = 0
for metric, weight in weights.items():
if metric in normalized and i < len(normalized[metric]):
composite_score += normalized[metric][i] * weight
result['composite_score'] = composite_score
# 按综合得分排序
return sorted(results, key=lambda x: x['composite_score'], reverse=True)
3.2 深度学习模型自动化优化
python
# 神经架构搜索(NAS)实现
class NeuralArchitectureSearcher:
def __init__(self, search_space, performance_predictor):
self.search_space = search_space
self.performance_predictor = performance_predictor
self.evolutionary_optimizer = EvolutionaryOptimizer()
def search_optimal_architecture(self, dataset_info, constraints):
"""搜索最优神经网络架构"""
# 1. 搜索策略选择
if constraints.get('search_time') < 3600: # 少于1小时
strategy = 'bayesian'
elif constraints.get('compute_budget') < 100: # GPU小时有限
strategy = 'evolutionary'
else:
strategy = 'reinforcement_learning'
# 2. 执行搜索
if strategy == 'evolutionary':
best_arch = self._evolutionary_search(dataset_info, constraints)
elif strategy == 'bayesian':
best_arch = self._bayesian_search(dataset_info, constraints)
else:
best_arch = self._rl_search(dataset_info, constraints)
# 3. 架构优化
optimized_arch = self._optimize_architecture(best_arch, constraints)
# 4. 生成训练代码
training_code = self._generate_training_code(optimized_arch)
return {
'architecture': optimized_arch,
'predicted_accuracy': self.performance_predictor.predict(optimized_arch),
'estimated_flops': self._compute_flops(optimized_arch),
'training_code': training_code,
'deployment_code': self._generate_deployment_code(optimized_arch)
}
def _evolutionary_search(self, dataset_info, constraints):
"""进化算法搜索"""
# 初始化种群
population = self._initialize_population(50)
for generation in range(constraints.get('max_generations', 20)):
# 评估适应度
fitness_scores = []
for arch in population:
score = self._evaluate_architecture(arch, dataset_info)
fitness_scores.append((arch, score))
# 选择
selected = self._tournament_selection(fitness_scores, k=20)
# 交叉与变异
offspring = []
while len(offspring) < 30:
parent1, parent2 = random.sample(selected, 2)
child = self._crossover(parent1, parent2)
child = self._mutate(child)
offspring.append(child)
# 新一代
population = selected + offspring
# 早停检查
if self._check_early_stopping(fitness_scores):
break
# 返回最优个体
best_arch = max(fitness_scores, key=lambda x: x[1])[0]
return best_arch
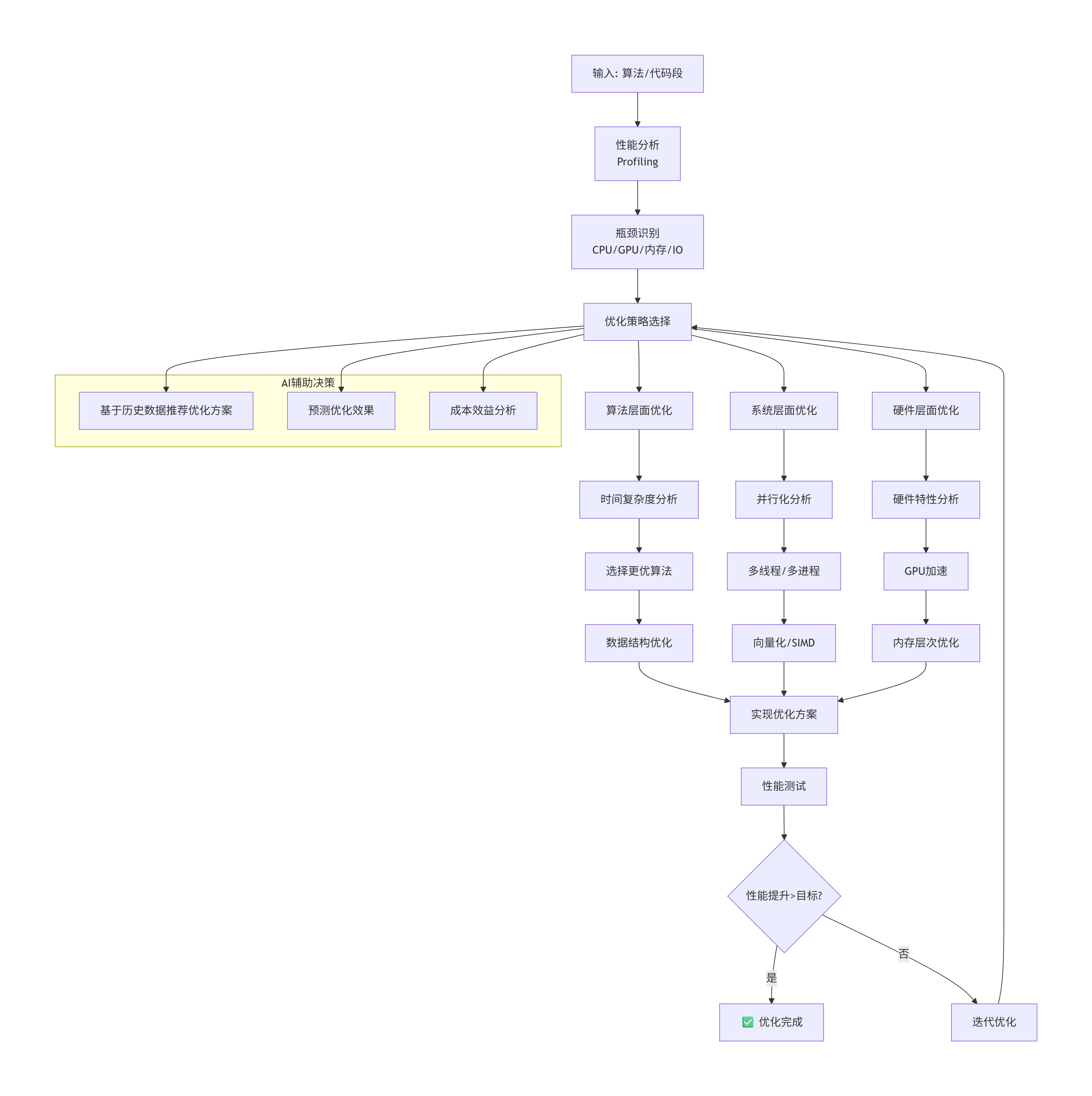
3.3 性能优化流程图
graph TB
A[输入: 算法/代码段] --> B[性能分析<br/>Profiling]
B --> C[瓶颈识别<br/>CPU/GPU/内存/IO]
C --> D[优化策略选择]
D --> E1[算法层面优化]
D --> E2[系统层面优化]
D --> E3[硬件层面优化]
E1 --> F1[时间复杂度分析]
F1 --> G1[选择更优算法]
G1 --> H1[数据结构优化]
E2 --> F2[并行化分析]
F2 --> G2[多线程/多进程]
G2 --> H2[向量化/SIMD]
E3 --> F3[硬件特性分析]
F3 --> G3[GPU加速]
G3 --> H3[内存层次优化]
H1 --> I[实现优化方案]
H2 --> I
H3 --> I
I --> J[性能测试]
J --> K{性能提升>目标?}
K -->|是| L[✅ 优化完成]
K -->|否| M[迭代优化]
M --> D
subgraph "AI辅助决策"
D1[基于历史数据推荐优化方案]
D2[预测优化效果]
D3[成本效益分析]
end
D --> D1
D --> D2
D --> D3
3.4 实际优化案例:图像处理管道
python
# 优化前的图像处理管道
def process_image_naive(image_path):
"""未优化的图像处理"""
# 1. 读取图像
img = cv2.imread(image_path)
# 2. 一系列顺序操作
# 调整大小
img_resized = cv2.resize(img, (224, 224))
# 颜色空间转换
img_rgb = cv2.cvtColor(img_resized, cv2.COLOR_BGR2RGB)
# 归一化
img_normalized = img_rgb / 255.0
# 高斯模糊
img_blurred = cv2.GaussianBlur(img_normalized, (5, 5), 0)
# 边缘检测
img_edges = cv2.Canny(img_blurred, 100, 200)
# 直方图均衡化
img_hsv = cv2.cvtColor(img_normalized, cv2.COLOR_RGB2HSV)
img_hsv[:,:,2] = cv2.equalizeHist(img_hsv[:,:,2])
img_eq = cv2.cvtColor(img_hsv, cv2.COLOR_HSV2RGB)
return img_edges, img_eq
# AI优化后的版本
def process_image_optimized(image_path, use_gpu=True):
"""AI优化的图像处理管道"""
# AI分析建议的优化策略:
# 1. 批处理支持
# 2. GPU加速
# 3. 操作融合
# 4. 内存重用
if use_gpu:
import cupy as cp
import cv2.cuda
# GPU优化版本
stream = cv2.cuda.Stream()
# 批量读取(如果可能)
gpu_frame = cv2.cuda_GpuMat()
gpu_frame.upload(cv2.imread(image_path), stream)
# 操作链式执行,减少内存传输
gpu_resized = cv2.cuda.resize(gpu_frame, (224, 224), stream=stream)
gpu_rgb = cv2.cuda.cvtColor(gpu_resized, cv2.COLOR_BGR2RGB, stream=stream)
# 使用CUDA核函数融合多个操作
gpu_processed = cv2.cuda.GaussianBlur(gpu_rgb, (5, 5), 0, stream=stream)
# 并行执行边缘检测和均衡化
gpu_edges = cv2.cuda.createCannyEdgeDetector(100, 200).detect(
gpu_processed, stream=stream
)
# 下载结果
edges = gpu_edges.download(stream)
stream.waitForCompletion()
return edges
else:
# CPU优化版本
# 使用Numba JIT编译和并行化
from numba import jit, prange
import numpy as np
@jit(nopython=True, parallel=True)
def fused_operations(img_array):
"""融合多个图像操作"""
h, w, c = img_array.shape
output = np.zeros((h, w), dtype=np.float32)
for i in prange(h):
for j in prange(w):
# 融合的像素级操作
r, g, b = img_array[i, j]
gray = 0.2989 * r + 0.5870 * g + 0.1140 * b
# 简单的边缘检测算子
if i > 0 and j > 0:
dx = gray - img_array[i-1, j].mean()
dy = gray - img_array[i, j-1].mean()
gradient = np.sqrt(dx*dx + dy*dy)
output[i, j] = gradient
return output
img = cv2.imread(image_path)
img_resized = cv2.resize(img, (224, 224))
img_rgb = cv2.cvtColor(img_resized, cv2.COLOR_BGR2RGB).astype(np.float32) / 255.0
return fused_operations(img_rgb)
# 性能对比
def benchmark_optimizations():
"""优化效果对比"""
import time
test_image = "sample.jpg"
# 原始版本
start = time.time()
for _ in range(100):
process_image_naive(test_image)
naive_time = time.time() - start
# 优化版本(CPU)
start = time.time()
for _ in range(100):
process_image_optimized(test_image, use_gpu=False)
optimized_cpu_time = time.time() - start
# 优化版本(GPU)
start = time.time()
for _ in range(100):
process_image_optimized(test_image, use_gpu=True)
optimized_gpu_time = time.time() - start
print(f"原始版本: {naive_time:.2f}s")
print(f"CPU优化: {optimized_cpu_time:.2f}s (加速比: {naive_time/optimized_cpu_time:.1f}x)")
print(f"GPU优化: {optimized_gpu_time:.2f}s (加速比: {naive_time/optimized_gpu_time:.1f}x)")
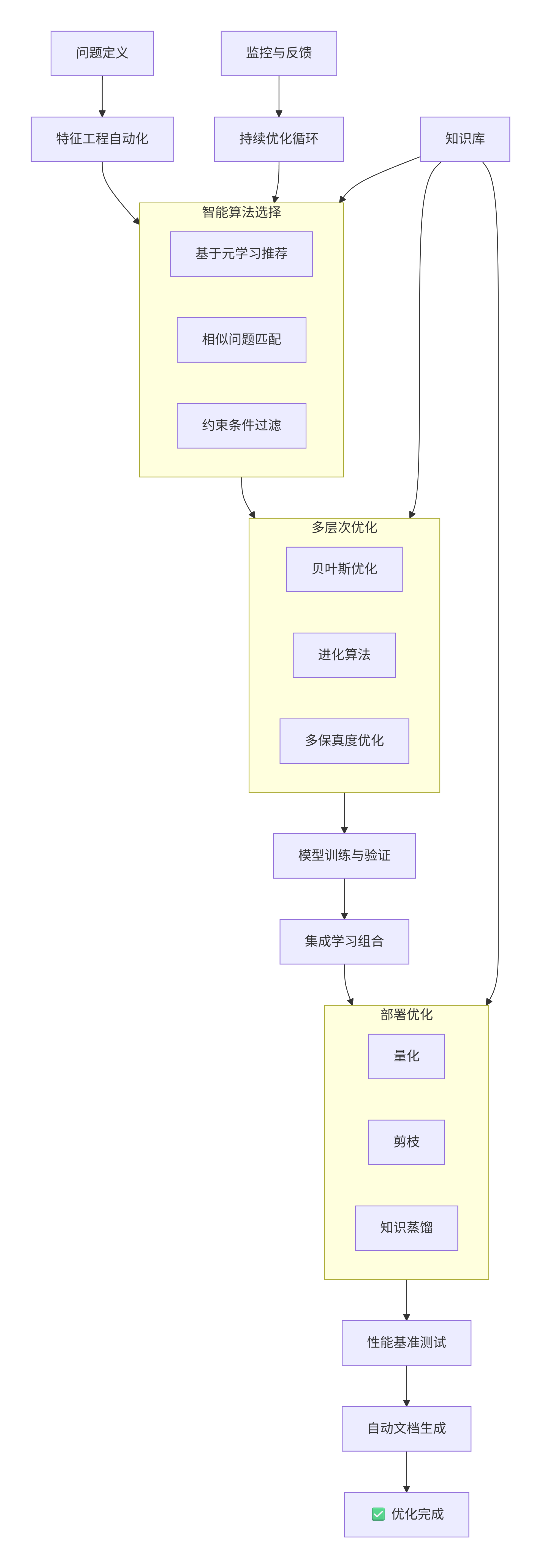
3.5 自动化算法优化平台架构
graph TD
A[问题定义] --> B[特征工程自动化]
B --> C[算法选择引擎]
subgraph C [智能算法选择]
C1[基于元学习推荐]
C2[相似问题匹配]
C3[约束条件过滤]
end
C --> D[超参数优化]
subgraph D [多层次优化]
D1[贝叶斯优化]
D2[进化算法]
D3[多保真度优化]
end
D --> E[模型训练与验证]
E --> F[集成学习组合]
F --> G[模型压缩]
subgraph G [部署优化]
G1[量化]
G2[剪枝]
G3[知识蒸馏]
end
G --> H[性能基准测试]
H --> I[自动文档生成]
I --> J[✅ 优化完成]
K[监控与反馈] --> L[持续优化循环]
L --> C
M[知识库] --> C
M --> D
M --> G
第四章:AI编程的未来趋势与挑战
4.1 技术趋势预测
| 时间范围 | 技术趋势 | 关键突破 | 影响范围 |
|---|---|---|---|
| 2024-2025 | 多模态代码生成 | 文本+图表+语音→代码 | 全栈开发 |
| 2025-2026 | 自主编程代理 | AI自主完成完整项目 | 中小型应用 |
| 2026-2027 | 代码意图理解 | 从业务需求直接生成架构 | 企业级系统 |
| 2027-2028 | 自适应代码优化 | 运行时性能自优化 | 高性能计算 |
| 2028+ | 量子算法集成 | 经典+量子混合编程 | 科学研究 |
4.2 主要挑战与解决方案
挑战1:代码质量与安全性
问题:AI生成代码可能存在安全漏洞、边界情况处理不足。
解决方案:
python
class AICodeValidator:
def __init__(self):
self.security_rules = SecurityRules()
self.code_quality_metrics = QualityMetrics()
def validate_and_enhance(self, generated_code, context):
"""验证并增强AI生成代码"""
# 多层次验证
validations = [
self._syntax_validation(generated_code),
self._security_validation(generated_code, context),
self._performance_validation(generated_code),
self._edge_case_validation(generated_code, context),
self._maintainability_check(generated_code)
]
# 综合评分
score = self._calculate_composite_score(validations)
if score < 0.8: # 阈值
# 自动修复迭代
enhanced_code = self._iterative_enhancement(
generated_code,
validations
)
return enhanced_code
return generated_code
def _security_validation(self, code, context):
"""安全性验证"""
vulnerabilities = []
# SQL注入检测
if self._detect_sql_injection(code):
vulnerabilities.append({
'type': 'SQL_INJECTION',
'severity': 'HIGH',
'suggestion': '使用参数化查询'
})
# XSS检测
if self._detect_xss(code):
vulnerabilities.append({
'type': 'XSS',
'severity': 'HIGH',
'suggestion': '实施输出编码'
})
# 敏感数据泄露
if self._detect_data_leakage(code, context):
vulnerabilities.append({
'type': 'DATA_LEAKAGE',
'severity': 'CRITICAL',
'suggestion': '添加数据脱敏'
})
return vulnerabilities
挑战2:技术债务管理
问题:AI快速生成代码可能导致技术债务积累。
解决方案:
-
建立AI代码审核流程
-
实施自动化重构建议
-
技术债务量化追踪
-
定期架构健康检查
4.3 伦理与责任框架
随着AI编程能力的增强,需要建立相应的伦理框架:
-
透明度原则:AI生成的代码应有明确标注
-
责任归属:人类开发者对最终代码负责
-
偏见防范:定期审计训练数据的代表性
-
安全性优先:安全检查必须为强制性步骤
-
持续学习:建立反馈循环改进AI能力
结论:人机协同的新范式
AI编程正在从辅助工具演变为协作伙伴。未来的软件开发将呈现以下特征:
-
增强型开发者:程序员专注于高层设计和复杂逻辑
-
自适应系统:软件能够根据运行时数据自我优化
-
民主化创造:领域专家直接创建专业级应用
-
持续演进:系统在部署后继续学习和改进
成功的组织将建立人机协同的工作流程,其中AI处理模式化、重复性任务,人类负责创造性、战略性和伦理决策。这种协同不仅提高生产效率,还将催生全新的软件形态和商业模式。
AI编程的终极目标不是自动化所有编码工作,而是放大人类创造力,让我们能够解决之前无法解决的复杂问题,创造前所未有的数字体验。
附录:实用资源与工具推荐
A. 开源AI编程工具
-
GitHub Copilot:最成熟的AI结对编程工具
-
Tabnine:全语言代码补全
-
CodeGeeX:开源代码生成模型
-
Continue:IDE中的AI开发助手
B. 低代码/无代码平台
-
Retool:企业内部工具快速开发
-
Bubble:完整Web应用无代码开发
-
Appian:企业级流程自动化
-
OutSystems:全栈低代码平台
C. 算法优化框架
-
Optuna:超参数优化框架
-
Ray Tune:分布式超参数调优
-
AutoGluon:自动化机器学习
-
NNI:神经架构搜索工具包
D. 学习路径建议
-
初级阶段:掌握Prompt工程、基础AI工具使用
-
中级阶段:学习AI代码审查、优化建议实施
-
高级阶段:构建自定义AI编程助手、参与工具开发
-
专家阶段:研究AI编程理论、推动范式创新

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 17
17 0
0- 0



 已为社区贡献88条内容
已为社区贡献88条内容

所有评论(0)