
AI编程新浪潮:重塑软件开发的三驾马车
《AI驱动的软件开发革命:2025年全景透视》摘要 当前AI已深度渗透到软件开发的各个环节,形成三大核心变革领域:1)自动化代码生成:LLMs将自然语言需求直接转化为可执行代码,显著提升开发效率;2)低代码/无代码平台:通过自然语言交互赋能非技术人员快速构建应用,实现开发民主化;3)算法优化:AI自动重构代码并优化性能,如将质数查找算法从O(N√N)优化至O(NloglogN)。这场变革正重塑开发
在2025年这个冬日清晨,当我们审视软件开发领域,会发现一场由人工智能驱动的革命早已不是未来时,而是进行时。AI不再仅仅是辅助工具,它正以前所未有的深度和广度,渗透到软件开发生命周期的每一个环节。其中,自动化代码生成、低代码/无代码(LCAP/NCAP)开发以及算法优化实践,如同三驾马车,正共同拉动着整个行业向着更高效、更智能、更普惠的方向疾驰。本文将深入探讨这三大核心领域,通过实践案例、技术剖析和前瞻思考,为您描绘一幅AI编程的全景图。
第一部分:自动化代码生成 —— 从意图到实现的“魔法棒”
自动化代码生成是AI编程中最直观、最具颠覆性的体现。它利用大型语言模型(LLMs)的强大能力,将人类的自然语言意图、模糊的需求描述,甚至高阶的系统设计,直接转化为可执行、可维护的代码。
1.1 核心原理与演进
早期的代码生成依赖于模板和宏,死板且有限。而到了2025年,基于Transformer架构的LLMs(如GPT-5、Claude 4等)已经学习了全球数万亿行代码和海量技术文档。它们不再是简单的“复制粘贴”,而是真正“理解”了代码的语法、语义、上下文乃至设计模式。
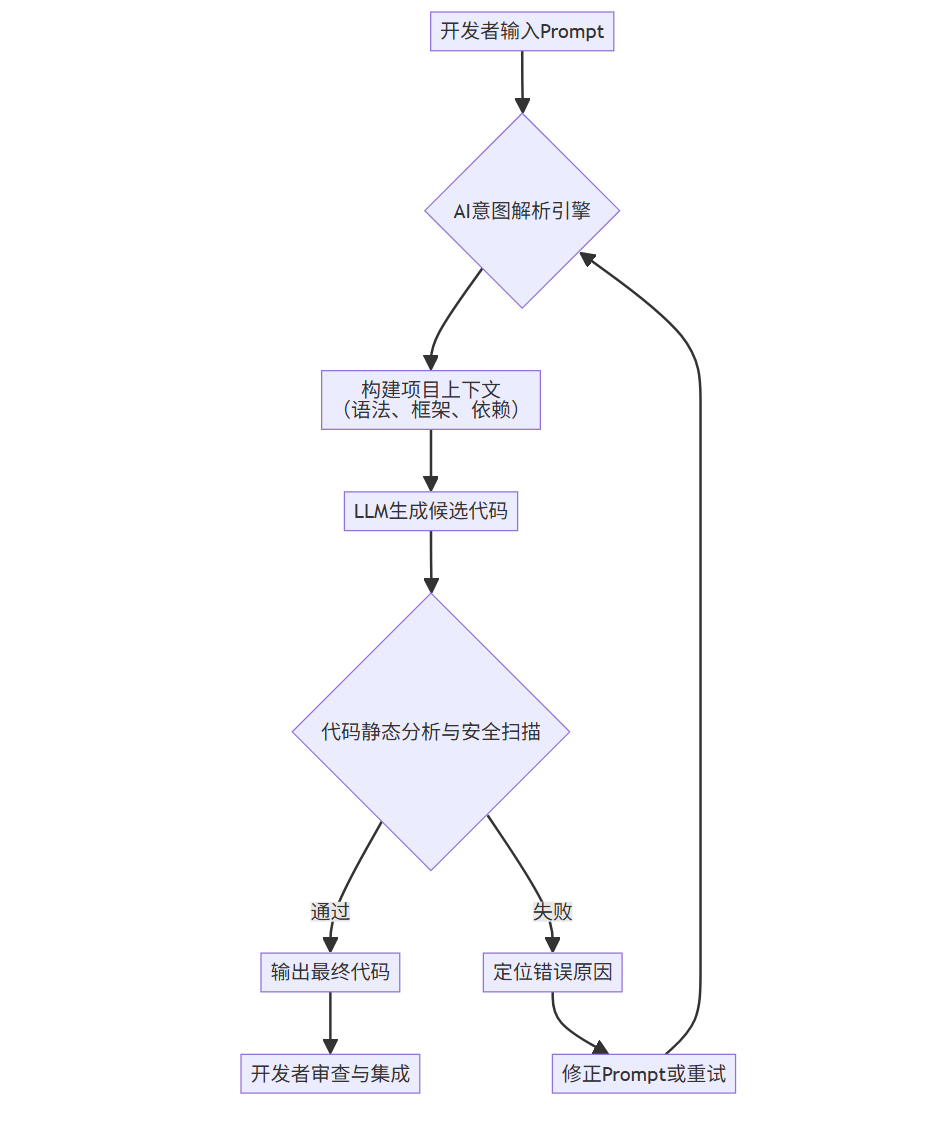
其核心流程可以概括为:意图解析 -> 上下文构建 -> 代码生成 -> 自我审查与迭代。
flowchart TD
A[开发者输入Prompt] --> B{AI意图解析引擎};
B --> C[构建项目上下文<br>(语法、框架、依赖)];
C --> D[LLM生成候选代码];
D --> E{代码静态分析与安全扫描};
E -- 通过 --> F[输出最终代码];
E -- 失败 --> G[定位错误原因];
G --> H[修正Prompt或重试];
H --> B;
F --> I[开发者审查与集成];
1.2 实践案例:用AI快速构建一个Web API
假设我们需要为一个电商系统快速构建一个“用户注册”的API端点。
Prompt示例(高质量Prompt的艺术)
一个优秀的Prompt是成功的关键。相比于“写个注册接口”,一个结构化的Prompt能带来数量级的质量提升。
# 角色与目标
你是一位资深的后端开发工程师,精通Python和FastAPI框架。你的任务是根据以下需求,生成一个高质量、生产就绪的用户注册API端点。
# 上下文信息
- 项目使用Python 3.11和FastAPI 0.104+
- 数据库使用PostgreSQL,ORM为SQLAlchemy 2.0
- 密码需要使用passlib库进行哈希处理
- 用户模型(User)已存在,包含字段: id, username, email, hashed_password
- 需要返回Pydantic模型用于数据验证和序列化
# 具体任务
1. 创建一个POST端点 `/register/`
2. 接收用户名、邮箱和密码作为输入。
3. 验证输入:
- 用户名和邮箱不能为空。
- 邮箱格式必须正确。
- 密码长度至少8位,包含大小写字母和数字。
4. 检查用户名和邮箱是否已存在于数据库中,如果存在则返回400错误。
5. 如果验证通过,将密码哈希后存入数据库,并创建新用户。
6. 返回成功信息,不包含密码等敏感信息。
# 输出要求
- 只输出完整的Python代码,包括所有必要的import语句。
- 代码中应包含清晰的注释,解释关键步骤。
- 使用依赖注入来获取数据库会话(`db: Session = Depends(get_db)`)。
- 定义清晰的输入Pydantic模型(`UserCreate`)和输出模型(`UserResponse`)。
AI生成的代码(Python + FastAPI)
# imports
from fastapi import APIRouter, Depends, HTTPException, status
from sqlalchemy.orm import Session
from pydantic import BaseModel, EmailStr, validator
import re
from passlib.context import CryptContext
# 假设这些已存在
from ..database import get_db
from ..models import User as UserModel
# 密码哈希上下文
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
# Pydantic模型
class UserCreate(BaseModel):
username: str
email: EmailStr
password: str
@validator('password')
def validate_password(cls, v):
if len(v) < 8:
raise ValueError('密码长度必须至少为8位')
if not re.search(r'[A-Z]', v):
raise ValueError('密码必须包含至少一个大写字母')
if not re.search(r'[a-z]', v):
raise ValueError('密码必须包含至少一个小写字母')
if not re.search(r'\d', v):
raise ValueError('密码必须包含至少一个数字')
return v
class UserResponse(BaseModel):
id: int
username: str
email: EmailStr
class Config:
from_attributes = True # Pydantic V2的写法
# Router
router = APIRouter(
prefix="/users",
tags=["users"]
)
# API端点
@router.post("/register/", response_model=UserResponse, status_code=status.HTTP_201_CREATED)
def register_user(user: UserCreate, db: Session = Depends(get_db)):
"""
创建一个新用户。
- 检查用户名和邮箱是否已存在。
- 对密码进行哈希处理。
"""
# 检查用户名是否已存在
db_user_by_username = db.query(UserModel).filter(UserModel.username == user.username).first()
if db_user_by_username:
raise HTTPException(
status_code=status.HTTP_400_BAD_REQUEST,
detail="用户名已被注册"
)
# 检查邮箱是否已存在
db_user_by_email = db.query(UserModel).filter(UserModel.email == user.email).first()
if db_user_by_email:
raise HTTPException(
status_code=status.HTTP_400_BAD_REQUEST,
detail="邮箱已被注册"
)
# 哈希密码
hashed_password = pwd_context.hash(user.password)
# 创建新用户对象
new_user = UserModel(
username=user.username,
email=user.email,
hashed_password=hashed_password
)
# 添加到数据库并提交
db.add(new_user)
db.commit()
db.refresh(new_user)
return new_user
1.3 挑战与思考
尽管自动化代码生成威力巨大,但挑战依然存在:
- “幻觉”问题:AI可能生成看似合理但逻辑错误或与上下文不符的代码。
- 安全风险:生成的代码可能引入SQL注入、XSS等安全漏洞,需要严格的代码审查和自动化扫描。
- 知识产权:训练数据的版权问题仍未完全解决,企业使用时需谨慎。
- 维护性:过度依赖AI生成的“黑盒”代码,可能导致后期维护困难。
结论:自动化代码生成将开发者从繁琐的“编码”工作中解放出来,使其更专注于“设计”和“架构”。未来的开发者,更像是一位指挥AI的“乐团指挥家”。
第二部分:低代码/无代码开发 —— 赋能全民开发的“民主化”工具
如果说自动化代码生成是提升了专业开发者的效率,那么低代码/无代码(LCAP/NCAP)平台则是将软件开发能力赋予了更广泛的人群,包括业务分析师、产品经理甚至一线员工。
2.1 AI如何赋能LCAP/NCAP
传统的低代码平台依赖于可视化的拖拽和配置。而AI的加入,让这个过程变得“智能”和“对话式”。
- 自然语言到应用:用户可以用一句话描述需求,AI自动生成应用页面、数据模型和业务流程。
- 智能组件推荐:根据用户意图,AI推荐最合适的UI组件、数据连接器和逻辑模块。
- 自动化流程设计:描述一个业务流程(如“报销审批”),AI能自动构建出包含条件判断、并行任务、通知节点的复杂工作流。
- 数据洞察与可视化:AI可以分析用户上传的数据,自动推荐最合适的图表类型,并生成可视化仪表盘。
2.2 实践案例:构建一个“员工休假申请”应用
我们以一个典型的企业内部应用为例,展示AI驱动的无代码开发流程。
第一步:用自然语言描述需求
在一个无代码平台的对话框中,HR经理输入:
“帮我创建一个员工休假申请应用。员工可以提交申请,填写休假类型(年假、病假、事假)、开始和结束日期、事由。提交后,需要他的直属经理审批。经理批准后,系统会自动更新HR系统中的假期余额,并向员工和HR发送邮件通知。”
第二步:AI解析并生成应用框架
平台AI理解后,会自动执行以下操作:
- 创建数据模型:生成
LeaveRequest(休假申请)表,包含EmployeeID,LeaveType,StartDate,EndDate,Reason,Status(待审批、已批准、已拒绝)等字段。 - 设计用户界面:自动生成两个页面:
- 申请提交页:包含表单,供员工填写信息。
- 经理审批页:一个列表,显示待审批的申请,每个申请项都有“批准”和“拒绝”按钮。
- 构建业务流程:生成一个自动化工作流。
[图片:一个无代码平台界面的截图,左侧是AI对话框,中间是AI自动生成的表单页面,右侧是数据模型的设计视图。]
第三步:业务流程可视化与微调
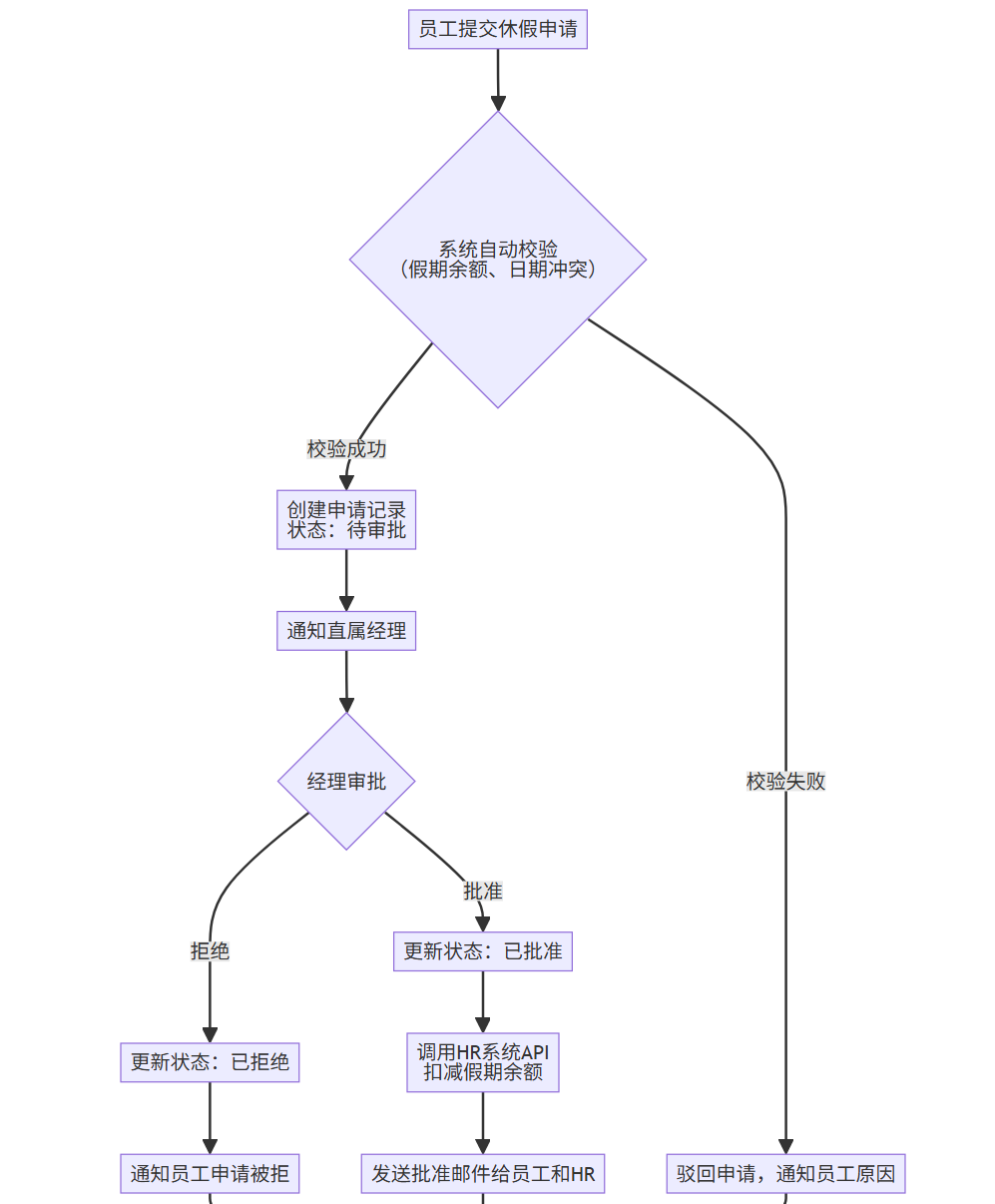
AI生成的工作流可以用Mermaid流程图清晰表示,用户可以在可视化界面上进行拖拽修改。
flowchart TD
A[员工提交休假申请] --> B{系统自动校验<br>(假期余额、日期冲突)};
B -- 校验失败 --> C[驳回申请,通知员工原因];
B -- 校验成功 --> D[创建申请记录<br>状态:待审批];
D --> E[通知直属经理];
E --> F{经理审批};
F -- 批准 --> G[更新状态:已批准];
F -- 拒绝 --> H[更新状态:已拒绝];
G --> I[调用HR系统API<br>扣减假期余额];
H --> J[通知员工申请被拒];
I --> K[发送批准邮件给员工和HR];
J --> L[结束];
K --> L;
C --> L;
第四步:发布与迭代
用户确认无误后,点击“发布”,应用即可上线。后续如需修改(例如增加“抄送给部门总监”),只需再次用自然语言告诉AI即可。
2.3 优势与局限
优势:
- 极致的速度:将数周的开发周期缩短到几小时甚至几分钟。
- 降低门槛:让不懂代码的业务人员也能创建应用,解决“影子IT”问题。
- 敏捷响应:快速响应市场变化和内部需求。
局限:
- 供应商锁定:应用深度绑定特定平台,迁移成本高。
- 定制化天花板:对于高度复杂、性能要求苛刻的系统,仍然力不从心。
- 技术债与治理:缺乏统一规范,可能导致应用泛滥、数据孤岛和维护难题。
结论:低代码/无代码并非要取代专业开发,而是与其互补。它解决了80%的标准化、流程化需求,让专业开发者能聚焦于20%的核心、复杂、高价值的系统开发。
第三部分:算法优化实践 —— AI驱动的“性能炼金术”
如果说前两者关注“开发效率”,那么算法优化则直击软件的“灵魂”——性能与效率。AI不仅能写代码,更能“优化”代码,甚至设计出超越人类专家的算法。
3.1 AI在算法优化中的应用场景
- 代码重构与并行化:AI分析代码瓶颈,自动将其重构为更高效的版本,或将串行代码转换为并行/分布式代码。
- 超参数自动调优:在机器学习中,使用贝叶斯优化、遗传算法等AI技术,自动寻找模型的最佳超参数组合。
- 编译器优化:Google的MLGO项目已经将强化学习应用于LLVM编译器,自动决定最优的代码优化策略,生成的程序比人类专家调优的更快。
- 算法结构搜索(NAS):在深度学习领域,AI自动设计最优的网络结构,而非依赖人工经验。
3.2 实践案例:优化一个计算密集型函数
假设我们有一个Python函数,用于找出小于给定数字N的所有质数。这是一个经典的计算密集型任务。
初始版本(低效的“试除法”)
def find_primes_naive(n: int) -> list[int]:
"""使用试除法找出所有小于n的质数,效率较低。"""
if n < 2:
return []
primes = []
for num in range(2, n):
is_prime = True
for i in range(2, int(num**0.5) + 1):
if num % i == 0:
is_prime = False
break
if is_prime:
primes.append(num)
return primes
这个算法的时间复杂度约为O(N√N),当N很大时,性能很差。
使用AI进行优化
我们向AI编程助手提出优化请求。
# 优化任务
请优化下面的Python函数 `find_primes_naive`,使其在处理大数(例如 n=1,000,000)时,运行速度至少提升10倍。
# 优化要求
1. 解释你选择的优化算法及其原理。
2. 提供完整的优化后代码。
3. 代码应保持良好的可读性。
4. 可以使用标准库,但请说明为什么你的选择比原版更优。
# 原始代码
[此处粘贴上面的 find_primes_naive 函数]
AI的分析与优化代码(埃拉托斯特尼筛法)
AI可能会返回如下结果:
优化分析:
原始的find_primes_naive函数采用了“试除法”,对每个数都进行检查,存在大量重复计算。为了显著提升性能,我将采用埃拉托斯特尼筛法。
原理:
该算法的思路是:
- 创建一个从2到N的布尔数组
is_prime,初始时全部设为True。 - 从第一个质数2开始,将2的所有倍数(4, 6, 8, …)标记为非质数(
False)。 - 找到下一个仍为
True的数(即3),将3的所有倍数(6, 9, 12, …)标记为非质数。 - 重复此过程,直到遍历到√N。
- 最后,所有仍为
True的索引对应的数就是质数。
此算法的时间复杂度为O(N log log N),空间复杂度为O(N),对于大数N,其性能远超试除法。
优化后代码:
def find_primes_sieve(n: int) -> list[int]:
"""使用埃拉托斯特尼筛法找出所有小于n的质数,效率极高。"""
if n < 2:
return []
# 创建一个布尔数组,is_prime[i]为True表示i是质数
is_prime = [True] * n
is_prime[0] = is_prime[1] = False # 0和1不是质数
# 遍历到sqrt(n)
for i in range(2, int(n**0.5) + 1):
# 如果i是质数
if is_prime[i]:
# 将i的所有倍数标记为非质数
# 从i*i开始,因为更小的倍数已经被更小的质数标记过了
for multiple in range(i * i, n, i):
is_prime[multiple] = False
# 收集所有质数
primes = [i for i, prime in enumerate(is_prime) if prime]
return primes
性能对比图表
我们可以通过简单的基准测试来验证AI的优化效果。
| 算法版本 | N = 10,000 (耗时) | N = 100,000 (耗时) | N = 1,000,000 (耗时) | 时间复杂度 |
|---|---|---|---|---|
| 试除法 | ~0.15s | ~2.5s | ~65s | O(N√N) |
| 埃氏筛法 | ~0.005s | ~0.05s | ~0.6s | O(N log log N) |
| 性能提升 | ~30x | ~50x | ~100x+ | - |
[图片:一个柱状图,直观展示上述表格中两种算法在不同N值下的性能差距,埃氏筛法的柱子远低于试除法。]
3.3 更深层次的AI优化
上述案例是算法级别的替换。在2025年,AI优化更进一步:
- 硬件感知优化:AI可以根据代码运行的特定硬件(CPU型号、GPU架构、内存层级),生成针对性的优化指令(如SIMD指令、CUDA内核),榨干硬件性能。
- 自适应算法:AI可以在运行时根据数据分布特征,动态切换最优算法。例如,一个排序函数,如果数据基本有序,AI选择插入排序;如果数据完全随机,则切换到快速排序。
结论:AI正在成为性能优化的终极武器。它将开发者从复杂的底层优化和繁琐的调参中解放出来,让“写出高性能代码”不再是少数专家的专利。
综合与展望:人机协同的新纪元
自动化代码生成、低代码/无代码和算法优化,这三者并非孤立存在,而是相互交织,共同构成了AI编程的完整生态。
- 协同工作流:一个产品经理可以用无代码平台快速搭建应用原型(LCAP/NCAP),然后AI自动生成核心模块的代码供专业开发者扩展,最后AI再对整个系统进行性能优化。
- 开发者角色的演变:未来的软件开发者,其核心价值将不再是“写代码的速度”,而是:
- 系统架构师:设计复杂、可扩展、高可用的系统蓝图。
- AI指挥家:通过高质量的Prompt和指令,引导AI高效、准确地完成工作。
- 质量守门员:审查AI生成的代码,确保其安全性、合规性和可维护性。
- 创新思想家:提出新的产品构想和技术解决方案,定义要解决的问题。
挑战与伦理
这场变革也带来了深刻的挑战:
- 技能鸿沟:无法适应人机协同模式的开发者可能面临被淘汰的风险。
- 就业结构变化:初级编码岗位可能减少,但对高级架构师和AI策略师的需求会增加。
- AI偏见与安全:AI模型可能继承训练数据中的偏见,生成带有歧视性的代码;同时,AI也可能被用于生成恶意代码。
- 过度依赖:人类可能丧失深度思考和解决根本问题的能力,完全被AI“绑架”。
结语
站在2025年的节点回望,AI编程已经从一个激动人心的概念,演变为驱动软件产业变革的坚实引擎。它没有宣告程序员的终结,而是开启了一个人机协同、共创价值的新纪元。在这个新纪元里,人类的创造力、批判性思维和领域智慧,与AI的无穷算力、广博知识和不知疲倦的执行力相结合,将以前所未有的速度,将数字世界的想象变为现实。
掌握与AI共舞的艺术,将是每一位未来技术工作者的必修课。这趟旅程才刚刚开始,未来,充满无限可能。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐



 8
8 0
0- 0



 已为社区贡献80条内容
已为社区贡献80条内容

所有评论(0)