
AI编程时代已来:大模型让代码小白也能写出神仙代码
大语言模型(LLM)通过学习海量文本获得语言能力,其成功源于语言数字化、计算能力提升和Transformer架构三大因素。LLM虽能完成编程辅助等任务,但缺乏真正理解。除LLM外,还有视觉、语音、强化学习、世界模型和多模态模型等多种AI技术,它们共同推动机器向"像人一样看、听、说、想、行"的方向发展,引发了对智能本质的哲学思考。
在人类历史中,语言是一种极其特殊的能力。我们用它记录经验、传递知识、表达情绪,也用它理解世界。很长时间里,计算机只能处理数字和指令。它能算得很快,却几乎不懂一句完整的人话。
LLM(Large Language Model,大语言模型) 的出现,改变了这一点。
什么是 LLM?它在做什么?
LLM 是一种专门处理语言的人工智能模型。
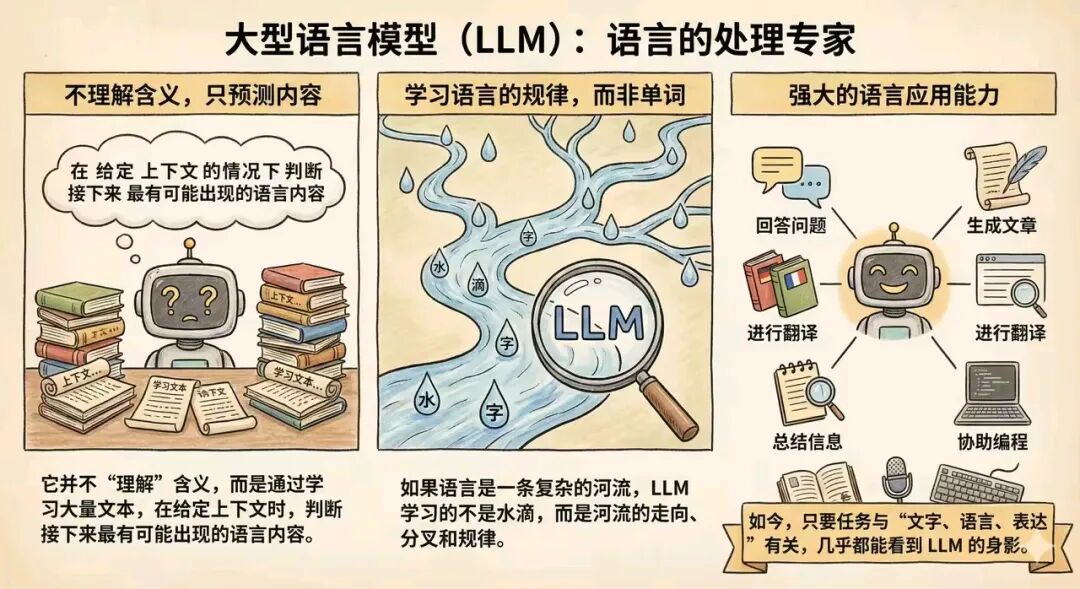
它并不“理解”语言的含义,而是通过学习大量文本,掌握一种能力:在给定上下文的情况下,判断接下来最有可能出现的语言内容。
如果把语言看成一条复杂的河流,LLM 学习的不是水滴,而是河流的走向、分叉和规律。
因此它可以:回答问题、生成文章、进行翻译、总结信息、协助编程等等。
如今,只要任务与“文字、语言、表达”有关,几乎都能看到 LLM 的身影。
关键转变:机器如何真正学会语言?
LLM 的成功并不是偶然,而是三条长期发展的线索,在某一时刻汇合的结果。
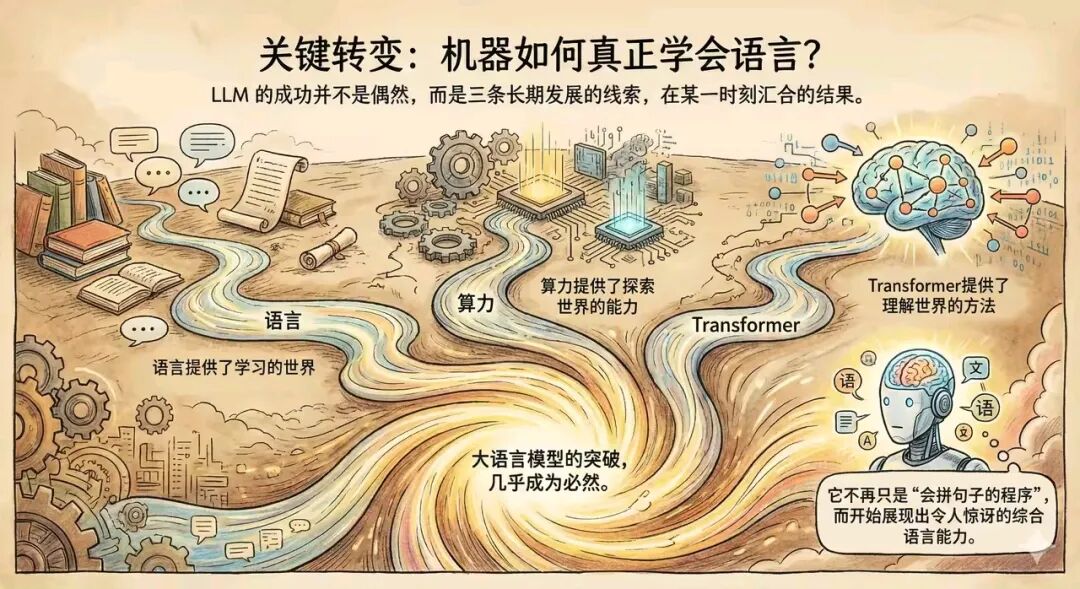
1、语言第一次成为“可学习的整体环境”
在互联网出现之前,人类的文字是零散的。它们分布在书籍、报纸、信件和个人笔记中,数量有限、形式不统一,也无法被大规模处理。
互联网改变了这一切。
当网页、论坛、百科、新闻、小说、技术文档被不断数字化,人类几乎把自己如何使用语言文字的方式,整体暴露给了机器。
对模型来说,人类语言文字的数字化意味着:
👀 它能看到同一件事在不同语境中的多种表达
👁️🗨️ 它能观察语言如何随身份、情绪、场景变化
📊 它能在海量样本中总结稳定的统计规律
人类的语言文字第一次从“零散样本”,变成了一个可以被完整学习的世界。
2、计算能力终于追上了想象力
然而,“读遍世界的文字”并不是一件容易的事。哪怕只是判断“哪个词更可能跟哪个词一起出现”,都需要大量计算。
在很长时间里,模型即使有数据,也算不过来。
转折点来自两方面:一方面,计算硬件不断进步 — GPU、TPU 等并行计算设备,使模型可以同时进行海量运算;另一方面,训练方法被重新设计 — 人们学会把庞大的学习任务拆分成无数可并行的小步骤。
于是,一个曾经只存在于理论中的想法,第一次变得现实:也许真的可以训练一个“读遍整个互联网”的模型。
当算力不再是决定性瓶颈,模型规模迅速扩大,模型的语言能力也随之出现了飞跃。
3、Transformer:让模型真正“看懂上下文”
即使有了数据和算力,语言模型仍然面临一个核心问题:一句话中,哪些词才是真正重要的?
早期的模型像是在“逐字前进”。它们主要关注相邻的词,很难理解长距离关系。而人类理解语言时,会回头关注句首、会抓住关键概念、会在长段文字中保持逻辑线索。
Transformer 的出现,解决这个问题。它引入了一种机制,让模型在阅读时能够在关注一句话中的所有词的同时,判断哪些信息对当前理解最关键, 并且在长文本中保持连贯性。
这相当于让模型从“闷头走路”,变成了“站在高处俯瞰整句话的结构”。
从这一刻起,模型才真正具备了稳定理解上下文、处理长文本、和维持语言逻辑的能力。
当语言提供了学习的世界、算力提供了探索世界的能力、Transformer提供了理解世界的方法这三条线合而唯一时,大语言模型的突破,成为必然。从此,它不再只是“会拼句子的程序”,而开始展现出令人惊讶的综合语言能力。
LLM 并不完美
尽管大语言模型LLM开始展现出类似人类的语言能力,但它并不完美。
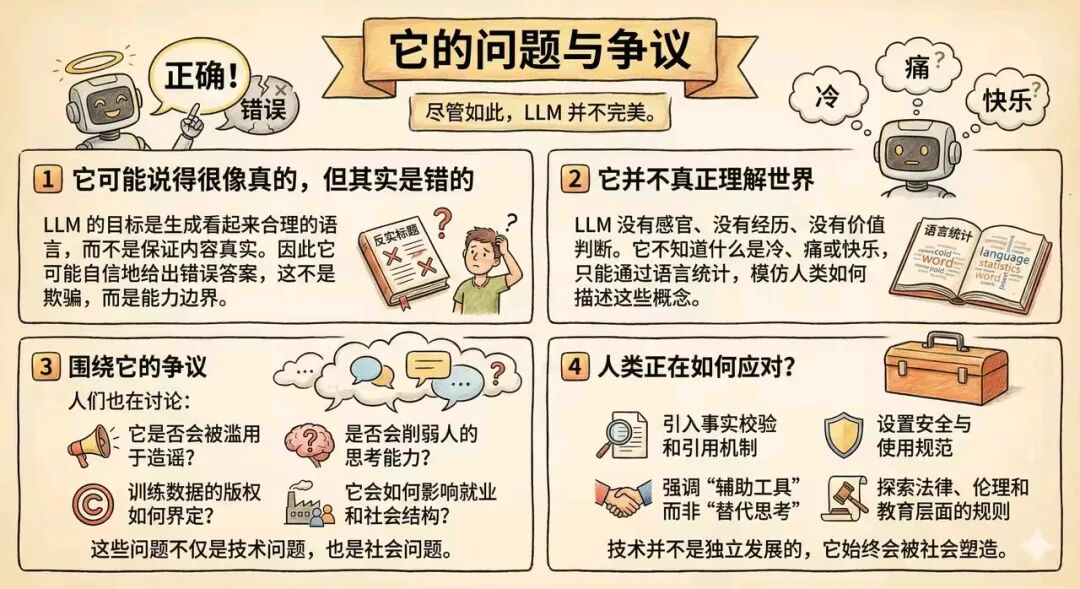
它可能说得很像真的,但其实是错的
LLM 的目标是生成看起来合理的语言,而不是保证内容真实。因此它可能自信地给出错误答案。
这不是欺骗,而是能力边界。
它并不真正理解世界
LLM 没有感官、没有经历、没有价值判断。它不知道什么是冷、痛或快乐,只能通过语言统计,模仿人类如何描述这些概念。
围绕LLM的争议
人们也在讨论:LLM是否会被滥用于造谣?它是否会削弱人的思考能力?训练它使用的数据的版权如何界定?它会如何影响就业和社会结构?
这些问题不仅是技术问题,也是社会问题。
人类正在如何应对?
我们目前的努力包括:引入事实校验和引用机制、设置安全与使用规范、强调“辅助工具”而非“替代思考“、以及探索法律、伦理和教育层面的规则等等。
技术并不是独立发展的,它始终会被社会塑造。
除了 LLM,还有哪些模型?以及它们想解决什么问题
大语言模型LLM并不是人工智能的全部。事实上,人工智能更像一个由不同能力组成的家族,每一类模型都在解决不同的问题。
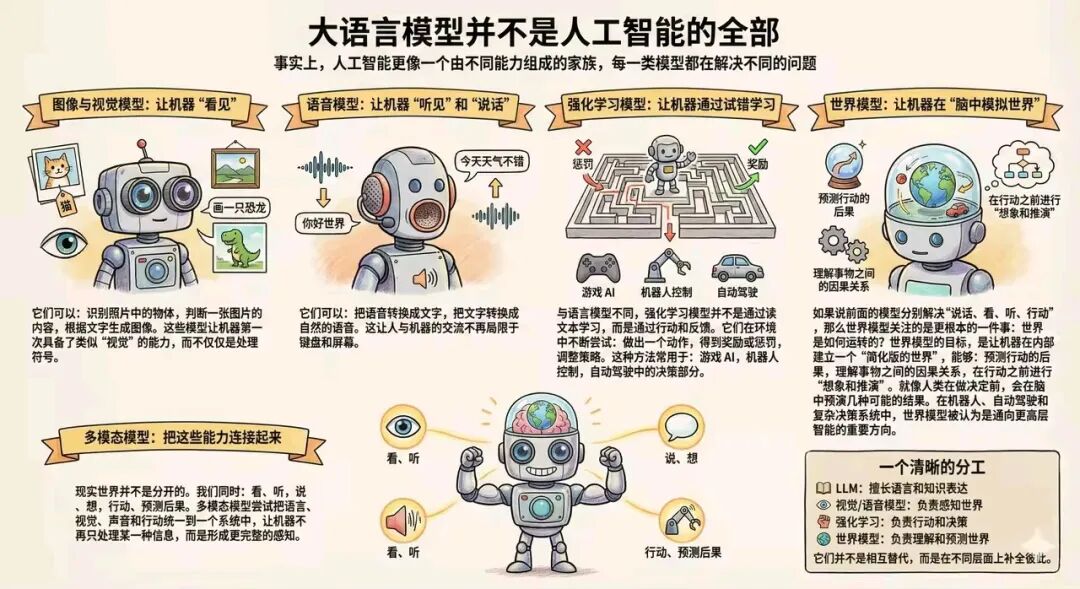
图像与视觉模型:给机器装上“电子眼睛”
过去,计算机只能读懂枯燥的代码和文字符号,而在视觉模型出现后,它们仿佛第一次“睁开了眼睛”。
这类模型不仅能处理视觉信息,还像人类一样具备了“看”与“想”的能力:
👁️ 慧眼识物:它们能瞬间认出照片里的猫是英短还是美短,或者一眼识别出X光片里微小的病灶。
🤔 理解场景:它们不再只是看到一堆像素点,而是真正读懂了画面——比如它能告诉你“这是一张一家人在草地上野餐的温馨照片”。
🖌️ 挥毫泼墨:最神奇的是,它们还能化身艺术家。你只需动动嘴说出描述,它们就能凭空画出一幅从未存在过的精美画作。
语音模型:赋予机器“耳朵”与“嗓音”
曾经的计算机像是一个“沉默的笔友”,只能通过文字交流。而语音模型打破了这份寂静,给机器装上了灵敏的听觉和真实的声带。
它们不仅能听懂你,还能与其对话,扮演着双重角色:
📝 金牌速记员:它能精准捕捉空气中的声波,将你口述的话语瞬间转化为文字,哪怕你语速飞快,它也能听音辨字,一字不差。
🔊 情感朗读者:它不再发出冷冰冰的电子机械音,而是能像真人一样抑扬顿挫地把文字“念”出来,甚至还能模仿呼吸、停顿和情绪。
从此,人与机器的交流不再被禁锢在方寸之间的键盘与屏幕上。我们终于可以像面对老朋友一样,随时随地,开口即聊。
强化学习模型:在“跌倒”与“糖果”中成长的实干家
如果说大语言模型LLM是饱读诗书的“理论派”,那么强化学习模型就是摸爬滚打的“行动派”。它们不靠死记硬背课本知识,而是像婴儿学步或训练宠物一样,在真实环境中通过“试错”来进化。
它们遵循着一套简单却强大的生存法则:
🐾 大胆尝试:就像蒙眼走路一样,先试着迈出一步,或者做出一个随机的动作。
🎁 奖惩反馈:做对了就给一颗“糖果”(正向奖励),摔倒了就记一次“教训”(负面惩罚)。
💖 自我进化:为了赢得更多的“糖果”,它们会疯狂地调整策略,在成千上万次的练习中找到最优解。
正是这种死磕到底的精神,造就了那些在电子游戏中碾压人类的超级 AI,让波士顿动力机器人学会了后空翻,也让自动驾驶汽车在复杂的车流中学会了如何安全变道。
世界模型:在机器脑中搭建“思维沙盘”
如果说前面的模型赋予了机器眼、耳、口、手,让它们能感知和行动,那么世界模型则赋予了机器最接近人类智慧的核心特质——“想象力”。它不再满足于识别“这是什么”,而是开始深究“世界是如何运转的”。它的目标是在芯片深处构建一个微缩版的“数字平行宇宙”:
🔮 预知未来:它就像拥有了“水晶球”,在真正采取行动之前,先在脑海中快速推演:“如果我这样做,后果会是什么?”
💭 洞察因果:它不需要亲自撞墙才知道痛。通过理解物理规律和因果关系,它能明白“杯子松手会掉落”、“下雨路面会打滑”。
🧠 脑内演习:就像我们在做重大决定前会在脑子里预演无数个剧本一样,机器也能在毫秒间模拟成千上万种可能,然后挑出结局最完美的那一个去执行。
这种“三思而后行”的能力,对于自动驾驶和机器人来说至关重要——它们终于不再是只会听指令的莽夫,而是进化成了懂得审时度势的“智者”,这被视为通向真正通用人工智能(AGI)的关键钥匙。
多模态模型:打破感官壁垒的“通感”大师
现实世界从来不是割裂的碎片。当我们走进一家咖啡馆,我们是同时在做几件事:看见热气腾腾的咖啡(视觉)、听到磨豆机的轰鸣(听觉)、闻到香气(嗅觉)、并思考要点哪一款(思维)。
多模态模型就是为了让机器拥有这种“全知视角”。它不再让“眼睛”只管看,“耳朵”只管听,而是充当了一位伟大的指挥家,将机器的所有感官融为一体:
🥊 打破壁垒:它打通了文字、图像、声音与动作之间的“任督二脉”。
🤖 交叉理解:它能看着视频里的动作(视觉),听懂背景里的解说(听觉),并用文字写出总结(语言),甚至直接指挥机器人做出同样的动作(行动)。
这种融合让机器告别了“盲人摸象”式的片面理解。它不再只是在处理单一的数据流,而是终于像人类一样,开始构建起一个立体、鲜活且完整的感知世界。
从“学习语言”到“像人一样存在”
当我们回望机器进化的历程,会发现大语言模型LLM其实只是故事的序章。在攻克了语言的壁垒后,一场关于“智能”的拼图游戏才刚刚开始。我们目睹了这一连串惊人的蜕变:
👁️ 视觉模型擦亮了它的眼睛,让它看懂了世界的斑斓;
👂 语音模型唤醒了它的耳嘴,让交流有了温度和起伏;
🎓 强化学习磨炼了它的肢体,让它在跌倒与试错中学会行动;
🌐 世界模型构建了它的心智,让它学会了思考后果与推演未来;
🌟 而多模态模型,最终打通了任督二脉,赋予了它感官的整体感。
至此,机器不再是一台只会处理冷冰冰代码的计算器。它正在一步步拼凑出感知的全貌。
机器,开始像我们一样看、听、说、想、行。当机器真正学会了人类的语言,它学到的不仅仅是词汇和语法,而是人类理解这个世界的方式——它正在跨越“工具”的边界,向着“伙伴”的形态加速奔跑。
理解从何而来?
大语言模型LLM的出现,使一个长期隐含的问题变得无法回避:如果一个机器能够熟练使用语言,它是否就已经在某种意义上“理解”了世界?
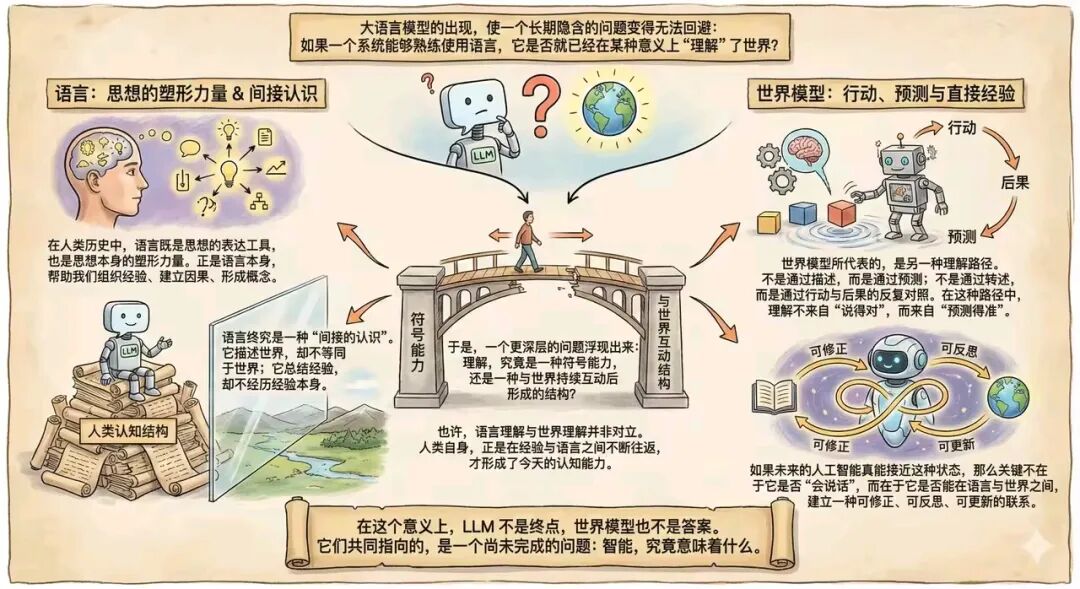
在人类历史中,语言既是思想的表达工具,也是思想本身的塑形力量。我们并不是先完全理解世界,再用语言去描述;相反,很多时候,正是语言本身,帮助我们组织经验、建立因果、形成概念。
从这个角度看,大语言模型LLM 的能力并非凭空出现。它继承的是人类在语言中长期积累的认知结构——分类方式、推理习惯、价值暗示,甚至偏见。然而,语言终究是一种“间接的认识”。它描述世界,却不等同于世界;它总结经验,却不经历经验本身。
世界模型所代表的,是另一种理解路径。不是通过描述,而是通过预测;不是通过转述,而是通过行动与后果的反复对照。
在这种路径中,理解不来自“说得对”,而来自“预测得准”。
于是,一个更深层的问题浮现出来:理解,究竟是一种符号能力,还是一种与世界持续互动后形成的结构?
也许,语言理解与世界理解并非对立。
人类自身,正是在经验与语言之间不断往返,才形成了今天的认知能力。如果未来的人工智能真能接近这种状态,那么关键不在于它是否“会说话”,而在于它是否能在语言与世界之间,建立一种可修正、可反思、可更新的联系。
在这个意义上,大语言模型LLM 不是终点,世界模型也不是答案。
它们共同指向的,是一个尚未完成的问题:
智能,究竟意味着什么。
那么,如何系统的去学习大模型LLM?
作为一名深耕行业的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~
👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 9
9 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)