
震惊!2025年Agent元年揭秘:大模型编程开发已悄然改变程序员命运!小白必看AI编程Agent崛起,Cursor、GitHub Copilot如何重塑开发流程?
2025年成为Agent元年,AI编程如Cursor、GitHub Copilot等垂直Agent已验证商业价值。大模型开发者需关注KnowHow→数据→Workflow→Agent的发展脉络,多Agent系统并非更优选择,Token消耗与稳定性不成正比。2026年Agent将进入更成熟阶段,垂直领域应用和强约束Workflow将成为主流,开发者应把握可交付的垂直Agent机会。
今天作为2025 Agent元年的最后一周,我们很有必要用更全面的视角,看一看 Agent 在25年到底发展的如何,各个公司实际执行情况是什么,所有这一切都将为我们在26年如何对待Agent提供方向。
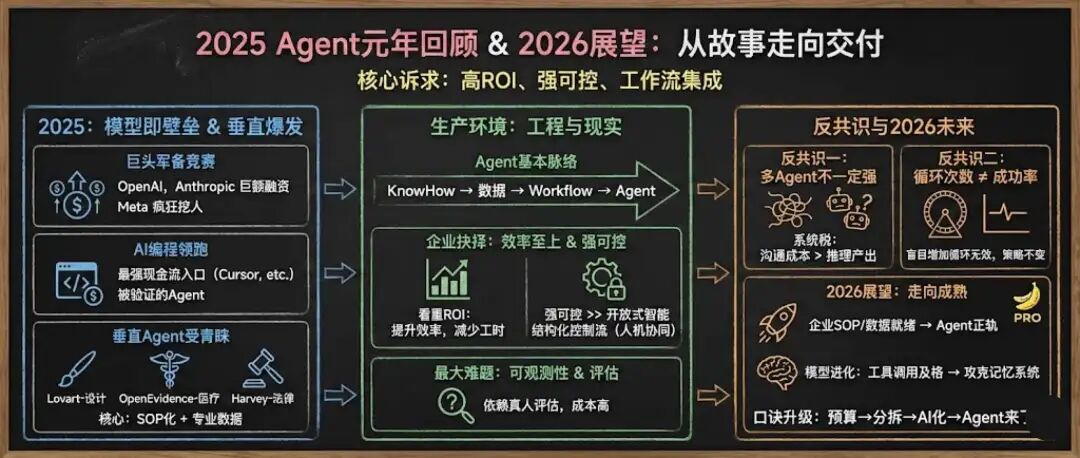
首先,我们来看看25年的AI大事件:
一、模型即壁垒
首先是今年的两个巨额融资:
- SoftBank 为履行对 OpenAI 的225 亿美元资金承诺在年底前紧急筹资,彼时 OpenAI 估值约 3000 亿美元;
- 模型界巨头Claude为代表的Anthropic完成130亿美金的融资,估值超过1800亿美元;
然后就是Meta的疯狂挖人计划:

很清晰,资本在往基座模型涌入,并且越来越具备头部效应,模型作为未来AI时代的操作系统,逐渐开始扮演赢者通吃的角色,也就是他什么都可能做,如果其他公司想要生存,需要围绕其生态展开。
二、AI编程,被验证的Agent
AI 编程成为最强现金流入口,其中Cursor累计融资32亿美金,估值近300亿。Cognition / Devin、Replit、Lovable皆有所斩获。
国内情况要差点,有硅心科技、言创万物,只不过大家可能有点陌生,因为编程IDE这块,大家还是信任大厂背书的东西。
这里就有很多不需要融资的公司,比如微软的GitHub Copilot、Google的Gemini Code Assist、通义灵码、Trae、CodeBuddy…
AI编程是特别适合拿出来说一说的,因为他是稍有的能够让人满意的Agent,并且付费意愿强、验证链路明确(能跑测试/能上 CI)、替代的是高成本人力。
整个AI 编程能够在Agent领域一枝独秀,很大程度上是源于程序员对自己的KnowHow最清晰,然后GitHub上有大量优秀代码语料,这个优势是其他行业不具备的。
其实从这里也开始分叉了,基于模型的Agent有两个类型:
- 通用Agent,以Manus为例;
- 垂直Agent,以Cursor为例;
现阶段来说,通用Agent普遍反馈不太好,但垂直Agent已经开始解决实际问题了:
三、垂直Agent备受青睐
除了AI编程外,还有几款备受好评的Agent,首先是Lovart,设计师的Agent:
其能够通过一句提示词,直接生成整套品牌级设计成果,包括 KV、海报、多尺寸社媒图等。不需要我们搭建复杂流程,上手即用、自由度极高,是当前最接近真实设计团队能力的 AI 产品。
然后就是OpenEvidence,循证医学的“证据供给链 Agent”,该产品是为了解决医疗场景幻觉来的,其产品核心是:围绕医学文献与权威来源,生成证据支持的答案并引用来源。
他们能成功的核心原因还是由于其本身工作已经做到了高度SOP化。其次对于Lovart,图像相关语料也是数不胜数;对于OpenEvidence,医疗侧的信息如临床指南、教材等数字化、标准化程度非常高。
这里还有些类似的产品如红杉宠儿法律 AI Harvey,他跟Cursor、OpenEvidence一样,都获得了不少的融资。这说明一个问题:资本其实并没有盲目跟风Agent。
这里我认为Agent正在从“泡沫故事”走向工程化可交互的产品了,原因很简单:这东西从工程角度来说太简单了,毫无壁垒,所以除了几个具备先发优势的通用Agent(如Manus)表现尚可外,其他都不大行,并且各大厂商都在分食通用Agent这块大蛋糕:
四、SEO → GEO
当前流量分发逻辑已经发生了巨大的变化,最明显的趋势就是大家不愿意为SEO付款了,AI现在获得的流量增多,但整体GEO依旧不太成熟,所以很多公司想付款却没有方向,这块也是割韭菜重灾区。
这一轮流量入口变化带来的最直接竞争就是,各个公司都在卷AI浏览器,包括Chrome、Dia、QQ浏览器、ChatGPT Atlas …
总而言之就是一个逻辑:体验从搜链接编程了问答案,各个巨头都在抢占入口。
五、企业资产竞争
另一个明显白热化的板块是AI OA领域,这对应着国内的两个IM具体:飞书与钉钉。每个企业 AI 最大的瓶颈不是模型不够强,而是企业不知道自己要自动化什么。
所以,他们的核心工作是,先整理SOP、而后做Agent化,飞书与钉钉双方这块的核心武器到很类似:AI表格,他们本质上在吃之前Excel的份额。
在AI表格之下还有一些边缘角色,比如Coze、Dify等,他们都想去吃点AI OA这块饼,但实际表现不佳;
尤其是Dify类拖拽低代码平台还直接跟AI编程冲突,在26年的整体方向,我是不很看好的。
这块可以预见的是,经过25、26年的洗礼后,各个企业内部SOP梳理清楚了、数据资产准备就绪了,那么整体企业Agent时代才会真正踏入正轨。
这里要特别提一句最近钉钉木兰1.1产品发布会,其实钉钉正在设法提出一套范式,协助各个公司整理自己的数据资产。
unsetunset工程视角unsetunset
从前面行业市场情况来说,2025确实可以成为Agent元年,因为一切都在为其成熟做准备。
Agent这东西十分依赖与模型的基础能力,上述几个Agent之所以能异军突起,也不得不提模型在编程领域、图像领域(尤其是Nano Banana)、医疗领域本身能力就很强,而且这些也是每次基准测试的重点。
这也延伸出了一套做法:模型哪方面强,我就做哪个方面的Agent,模型60分,那我就做到70分就好…
最后总结一下,其实从上述案例中,大家也慢慢发现了Agent的基本脉络:KnowHow → 数据 → Workflow → Agent。
怎么说呢?我是认为Workflow是Agent的必经之路,尤其是市场需要的Agent,这东西对稳定性要求极高,只不过传统的Workflow维护到一定阶段后其复杂度巨高,维护起来尤其蛋疼:
要解决Workflow维护困难的问题、乃至想要提高Workflow的泛化能力,Agent架构被提出了,但是Agent表现却不稳定,这个时候就只能加大Token消耗,用Token换架构的方式去解决问题,只不过实际执行下来效果不太好罢了;
于是模型侧又有更多的工程策略被提出,最近的Skill(Claude Skill)策略更是集大成者。只不过这里问题也就出来了,之前是显式的Workflow调用,而后是转移至了各个skills,流程复杂度到了提示词了,换句话说:之前用代码写Workflow,现在用提示词写Workflow…
所以,MCP的提出是为了解决工程问题,Skill的提出也是为了解决问题,大家再看模型能力优化这张图:
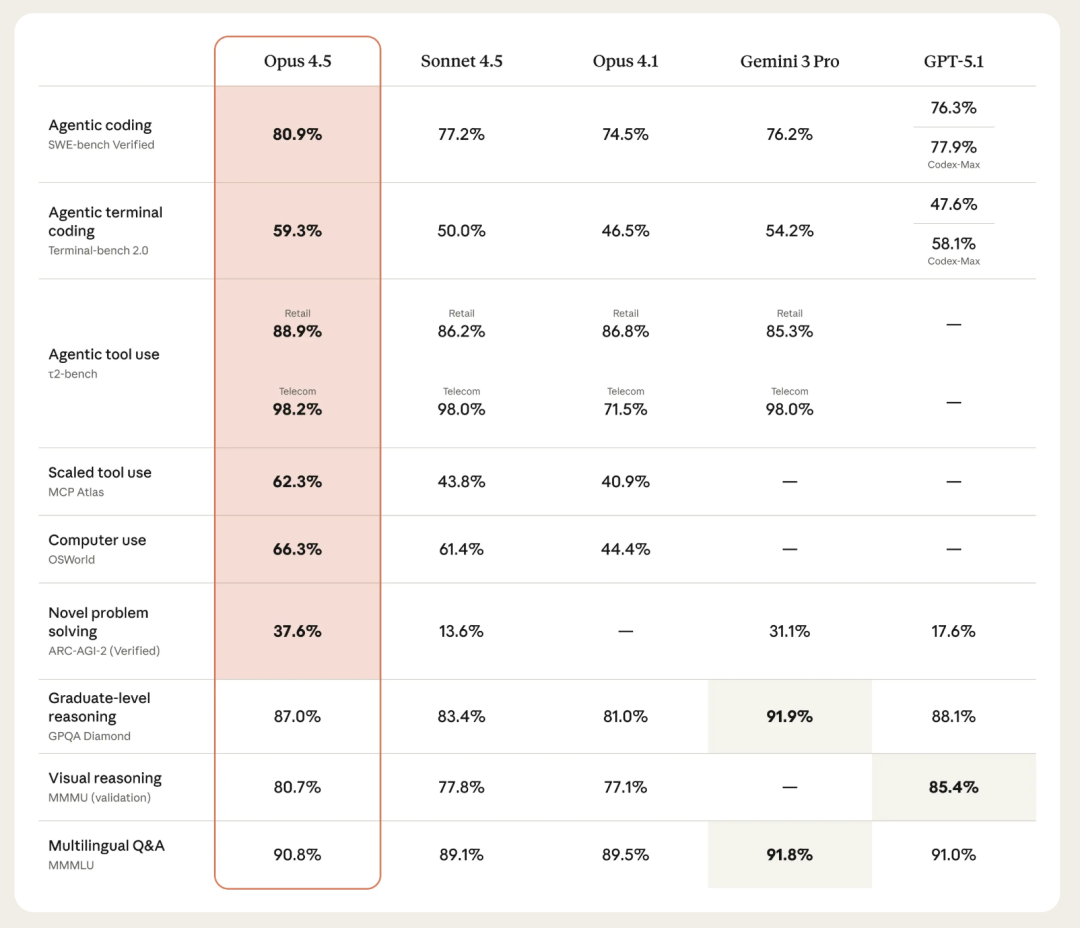
可以看到,模型能力也是一直在围绕着工具调用做优化,从整个25年模型之于Agent的优化来说,我认为Tools相关的问题已经及格了,接下来模型大概率会啃另一个大骨头:记忆系统。
现阶段RAG乃至上下文工程,复杂度还是太高,模型应该会推出类似Skill的工程优化接口,大幅降低记忆系统的构建难度;
只不过大家也不要高兴的太早,就跟Skill上了一样,他能把稳定性从70提升到90,但之前要做的工程优化动作一个都少不了…
综上,无论从模型基础能力的针对性优化,还是各种工程能力的释放,都标志着,Agent在26年都将进入一个更成熟的阶段,所以26年有可能是个Agent大年。
然后,我们由虚就实,通过各个企业实际落地看看Agent的情况:
unsetunset生产环境的Agentunsetunset
这里多数数据来源于《Measuring Agents in Production》,他们做了 306 份从业者问卷,并在 26 个业务领域做了 20 个深度案例访谈,聚焦 4 个问题:为什么做、怎么做、怎么评估、最大的坑是什么。
我们先结合论文情况做阅读,再加入我实际看到的情况做解读:
相较于故事,企业更看重效率
在为什么要做 Agent这件事上,企业高度务实:**提升效率/生产力(72.7%)、减少人力工时(63.6%)、自动化重复劳动(50%)**排在最前;而“风险缓释、加速故障恢复”这类更难量化/更慢反馈的价值排在后面。
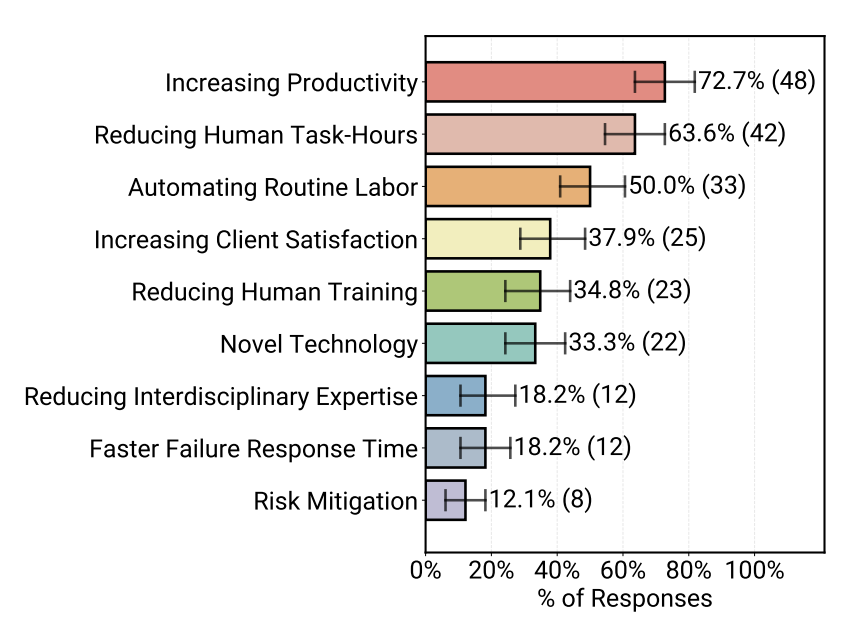
这背后也是大家以后做Agent的一个决策标签:
能不能计算 ROI,然后高ROI的先做,先落地,每个表格里面有写清楚,到底节省多少人小时、缩短多少处理时长,比如这里的图示:

相应的,只要是ROI不明确的,不好证明的,先不碰或先内部试点。
Agent服务于人
当前绝大多数Agent依旧是服务于人,他们更多是减轻我们某一方面的工作压力,所以一般Agent使用链路是由内而外,内部容错率高,优化好了再放出去;
另一方面,我们对延时的忍耐度极高,报告点得很直白:只要对比对象是“人要干几小时/几天”的流程,Agent 用几分钟也依然是数量级提升。
强可控 >> 开放式智能
报告里面有个关键点,跟我线下十数家企业观察到的情况几乎完全一致:生产落地追求的不是更强自治,而是更强可控,他们对稳定性要求极高。
另一方面,各个团队吃了之前百模大战的苦,当前都更倾向于直接使用线上模型,很少有后训练的团队。
原因也很简单,自己训练耗时费力,一波外部模型迭代就跟不上了,得不偿失,还不如再等等。
然后,提示词开始逐渐“代码工程化”,现在因为逻辑全部在从代码往提示词做迁移,所以结果就是提示词越来越多,越来越长,如何把提示词写得优雅可控、可迭代,逐渐会变成一个最基本能力评估。
再然后,模型能力没那么强,相应着系统在设计上会很保守,68%的系统最多跑10步就需要人的介入,并且步数越多、评估越难、延时更高,相应着越容易失败。
最后也是最关键的一点:80% 的深度案例采用结构化控制流,系统最关心的流程会在一个清晰的SOP里面运作,不会放任Agent自由规划,也就是说:
生产 Agent 的主流形态,很类似与带 LLM 的强约束 Workflow
AI产品测评
这里也是一个关键点,也是我们之前实际生产实践的经验,大型的AI产品更多还是在依赖真人评估效果,这里确实会部分依赖模型根据已有数据集做判断,但总会有真人复核。
这里也会让大家产生一个疑问:为什么AI产品评估很难做,为什么不用公告数据集?
原因很简单:因为成本高。许多行业没有可用公共数据,只能从零手工造 benchmark;有团队为了把数据集从 40 个场景扩到 100 个,花了数月到半年;
然后,用户的回答是不可控的,就算是有好的数据集,实际使用下来效果也不好,所以最终结果就是不做自动化测评,直接上真人评估。
Agent最大难题
当前Agent最难的点,并且没有被真实解决的问题依旧是:可观测性,也就是可靠性不能保证。
评估很难,如果你没有一个马上就能判断对错的自动验收标准,那么 Agent 做得对不对,只能等它在真实业务里产生后果之后才知道;而这些后果往往来得慢、代价高、还很难被程序自动判定。
整个生产级Agent生产落地情况总结下来就一句话:把不可靠的模型能力,封装成可交付的业务结果,这里的重点是如何让Workflow与Agent做结合…
接下来是Agent的两个反共识:多Agent不好用、Token带不来稳定性:
unsetunset多Agent不一定强unsetunset
当前行业里普遍有一种直觉:**任务更复杂 → 加更多 agent、分工协作 → 性能更强。**但真实落地经常出现反直觉现象:加 agent 之后变慢、变贵、还更容易出错。
这个结论来自于论文:《Towards a Science of Scaling Agent Systems》
他们做了一个很干净的对照:同一批 agentic 任务、同一套工具接口、同样的 token 预算,换不同的协作方式(独立并行/中心化/去中心化/混合),再跨不同模型能力跑大量实验。
最后得出的结果,跟我们在一线踩坑高度一致:多 Agent 引入了一种新的系统税:
很多人以为多 Agent = 多几个大脑,但可能真实情况是更像多几个部门:组织一复杂,产出没提升,一堆无聊的讨论(会议)变多了。
同预算下,多 Agent 需要更多消息传递、同步、重复描述上下文,导致有效推理预算被吃掉,你以为在增加推理能力,其实是在扩沟通。
多Agent架构,可能会使用单体Agent数倍的Token,只是为了单纯的维护上下文一致性。
然后,跳出效率视角,我们其实最为关心的是Agent是否能够让整体稳定性上升,答案是否定的:
多 Agent 不是简单地“互相纠错”,更多时候是在“互相传染”,他们很类似于带耳机传声的游戏,第一个错了,后面的全部跟着会一起错
只不过多Agent也不是总是不好用,还是得看任务类型,乃至每个Agent的边界是否清晰而彼此间又是否有关联,这里就不展开了…
unsetunset循环次数 ≠ 成功率unsetunset
最后一块也是一个很反直觉的点,他甚至对整个ReAct架构都造成了一定冲击,一般来说我们会认为:多轮反思、并行采样、多次投票,只要互相探讨的次数足够多(循环增加),那么最终的结果就一定会更好(这里包括了更多的辅助工具调用)
然而,论文《Budget-Aware Tool-Use Enables Effective Agent Scaling》给出了不一样的回答:
工具调用次数直接决定 Agent 与外部世界交互的强度,但盲目增加循环常常导致:重复搜索、无效浏览、策略不变…
这里我翻译翻译:其实模型当前的聪明程度,很有点懂的部分很快就会懂,只需要稍微提示一下,但不懂的地方,提示再多也没有办法这种情况。
然后论文接下来讲的就是一套成本工程逻辑,个人感觉对大家帮助不大,就不继续了…
unsetunset结语unsetunset
回头看 2025 的 Agent 元年,行业真正确定下来的不是“通用智能”,而是“可交付”。跑出来的基本都是垂直 Agent:因为 KnowHow 更清晰、数据更标准、验收更容易,能把模型的不稳定封装成稳定结果。
生产环境也给了两条反共识:多 Agent 往往更慢更贵更容易错;多循环、多 Token 也不必然换来更稳定。企业最终要的不是更强智能,而是更强可控,所以Workflow的路还很远,甚至正在往模型侧延伸。
最后是 2026 怎么做,这就要回到我们之前上课的口诀了:先看预算、再分拆、能用AI就AI了,只不过现在要加一句,Agent可能真的来了!
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。我们整理出这套 AI 大模型突围资料包:
- ✅ 从零到一的 AI 学习路径图
- ✅ 大模型调优实战手册(附医疗/金融等大厂真实案例)
- ✅ 百度/阿里专家闭门录播课
- ✅ 大模型当下最新行业报告
- ✅ 真实大厂面试真题
- ✅ 2025 最新岗位需求图谱
所有资料 ⚡️ ,朋友们如果有需要 《AI大模型入门+进阶学习资源包》,下方扫码获取~
① 全套AI大模型应用开发视频教程
(包含提示工程、RAG、LangChain、Agent、模型微调与部署、DeepSeek等技术点)
② 大模型系统化学习路线
作为学习AI大模型技术的新手,方向至关重要。 正确的学习路线可以为你节省时间,少走弯路;方向不对,努力白费。这里我给大家准备了一份最科学最系统的学习成长路线图和学习规划,带你从零基础入门到精通!
③ 大模型学习书籍&文档
学习AI大模型离不开书籍文档,我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。
④ AI大模型最新行业报告
2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。
⑤ 大模型项目实战&配套源码
学以致用,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。
⑥ 大模型大厂面试真题
面试不仅是技术的较量,更需要充分的准备。在你已经掌握了大模型技术之后,就需要开始准备面试,我精心整理了一份大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

以上资料如何领取?

为什么大家都在学大模型?
最近科技巨头英特尔宣布裁员2万人,传统岗位不断缩减,但AI相关技术岗疯狂扩招,有3-5年经验,大厂薪资就能给到50K*20薪!

不出1年,“有AI项目经验”将成为投递简历的门槛。
风口之下,与其像“温水煮青蛙”一样坐等被行业淘汰,不如先人一步,掌握AI大模型原理+应用技术+项目实操经验,“顺风”翻盘!

这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

以上全套大模型资料如何领取?

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐



 13
13 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)