
从代码补全到 Agent:AI 编程的工程形态正在发生变化
AI编程正从辅助工具转变为工程参与者,业务代码增长放缓而规范约束类内容增加。核心变化在于:1)AI Agent开始承担完整任务链路,需显性表达过去隐性的决策;2)Spec的核心作用是限制决策空间而非描述需求;3)Agent"造轮子"常因信息缺失而非能力不足;4)Token成本失控源于上下文管理不善;5)提高有效信息密度是关键。这一转变要求将隐性经验转化为系统约束能力,工程化水平
在越来越多真实项目中,AI 编程正在呈现一个明显特征:业务代码的增长速度放缓,而规范、规则、约束类内容却在持续增加。
这并不是文档回潮,而是一个工程信号—— 当代码生成的执行权逐步交给 Agent,过去依赖人类经验隐式完成的决策,必须被系统显性表达出来。
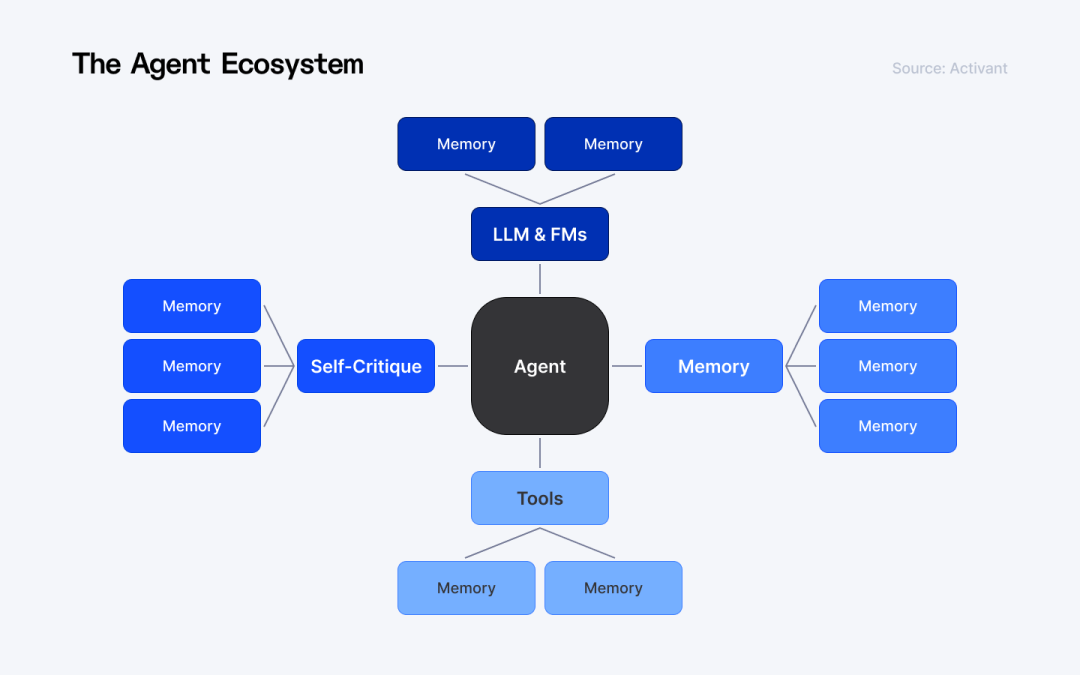
一、代码补全解决的是效率问题,Agent 解决的是任务问题
早期 AI 编程的核心形态是代码补全。 人类掌握任务主线,AI 只负责“预测下一步编辑动作”。
补全的工程边界非常清晰:
-
必须低延迟,否则会打断编辑节奏
-
只能理解局部上下文,很难承担全局决策
而 Agent 的引入,本质上是责任边界的变化:
-
AI 不再只是参与写代码
-
而是开始承担完整任务链路
-
需求理解
-
代码修改
-
工具调用(构建 / 测试 / 搜索)
-
结果校验
-
因此你会看到三种工程入口并行存在:
-
IDE:人机协作最密集,Agent 嵌入式执行
-
CLI:适合长任务、批量任务、自动化链路
-
Cloud:以 PR / Patch 作为最终交付物
工程上可以这样理解:补全是能力,Agent 是角色。

二、Spec 的作用不是“描述需求”,而是“限制决策空间”
在 Agent 场景下,最大的工程风险不是“写错代码”, 而是在没有被及时发现的情况下,持续做“方向正确但目标错误”的事。
这也是 Spec 重新变得关键的原因。
但从工程角度看,Spec 的核心价值并不是“说明”,而是:
把不该发生的决策,在系统层面提前排除掉。
一个有效的 Spec,本质上是在做三件事:
-
限定目标范围(防止无限扩展)
-
固化工程约束(性能 / 安全 / 兼容性)
-
明确验收口径(什么时候算完成)
一个工程友好的 Spec 结构
-
Goal:明确问题与成功标准
-
Non-goals:哪些情况明确不处理
-
Constraints:技术与业务硬约束
-
Interfaces:输入 / 输出 / 边界
-
Acceptance:验收条件与回归范围
这类 Spec 的价值在于:它不是给人看的,是给 Agent 执行时用的。
三、Agent 频繁“造轮子”,通常不是能力问题,而是信息缺失

一个常见现象是: Agent 在明明存在成熟库的情况下,仍然选择从零实现功能。
从工程视角看,这并不是“判断失误”,而是风险评估结果。
当以下信息没有进入上下文:
-
明确可用的库版本
-
推荐用法与示例
-
已知边界与踩坑点
对 Agent 来说,复用反而是不确定性更高的选择。
因此工程上的正确做法不是“事后纠正”,而是:
-
在 Spec 中明确允许使用的库集合
-
提供最小可执行示例
-
明确不可用场景与替代方案
本质原则只有一句话:让复用成为低风险路径。
四、Token 成本失控,本质是上下文未被工程化管理
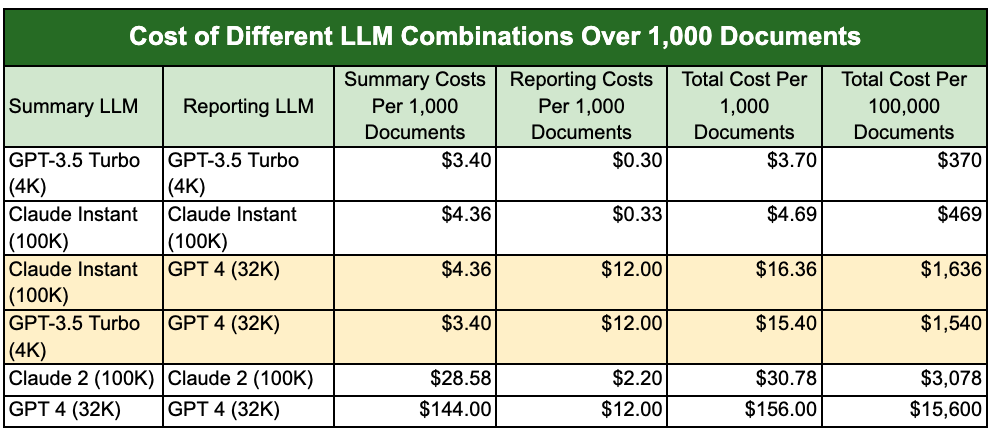
很多团队在引入 Agent 后,都会明显感受到 Token 成本上升。
但从工程角度看,问题并不在模型,而在上下文使用方式。
主要消耗通常来自:
-
工具调用产生的大量原始输出
-
日志、diff、错误栈的反复回灌
-
多 Agent 协作中的中间结果传递
这意味着 Token 成本控制,本质上是一个上下文治理问题:
-
日志是否裁剪
-
输出是否摘要
-
稳定信息是否缓存复用
而不是简单的“换模型”或“降参数”。
五、上下文工程的核心目标:提高“有效信息密度”
在 Agent 场景中,上下文并不是越多越好。
真正重要的是:
-
哪些信息是长期稳定资产
-
哪些只是阶段性产物
-
什么时候应该清理,什么时候应该复用
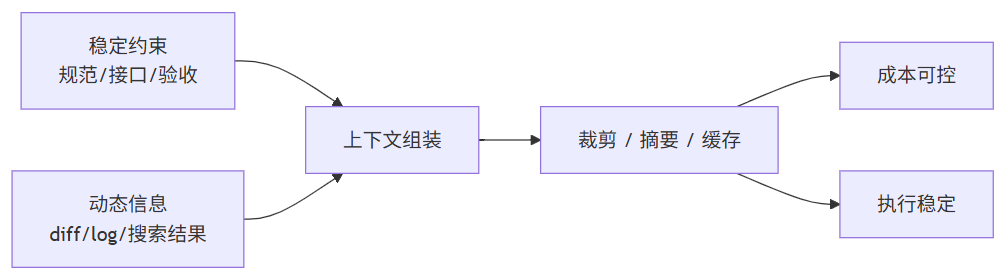
工程上可以把上下文理解为一条流水线:
一些非常“工程”的衡量指标反而更有价值:
-
Agent 首次产出到合并的修改轮次
-
单任务有效 Token / 实际代码改动
-
复用成功率
AI 编程正在从“辅助工具”演进为“工程参与者”
当 AI 开始参与完整任务链路,它不再只是工具,而是系统中的一个角色。
工程问题也随之发生变化: 不再只是“写得对不对”,而是决策是否被约束、行为是否可预测、结果是否可验证。
从这个角度看,真正拉开差距的,不是模型参数规模, 而是工程团队把隐性经验转化为系统约束的能力。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 18
18 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)