
收藏!DeepSearcher开源项目揭秘:企业级Agentic RAG架构全解析,程序员必学的大模型搜索新范式
准备好迎接搜索3.0时代了吗?随着这几年AI技术的革新,“搜索应用”成为了AI应用层的第一个共识。从海外的OpenAI、微软Bing Copilot、Perplexity AI,再到国内的豆包、Kimi,都是这一共识下的代表产品。技术上,从传统的关键词检索,到RAG,大家已经不满足于只是生成对应的简单回答而是期待大语言模型能够更好地应用于企业级场景,产生更大的价值。不久前,OpenAI推出了最新的
文章介绍了DeepSearcher开源项目,这是一个基于Agentic RAG架构的企业级搜索工具。相比传统RAG,它具有主动响应、多轮动态检索和自我修正能力,适用于复杂推理和报告生成。DeepSearcher结合深度内容生成、超级搜索和研究助理功能,通过Milvus向量数据库支持本地数据接入,并允许更换底层模型。文章通过实例展示了其在综述类和复杂推理类问题上的优势,认为Agentic RAG是搜索AGI的发展方向。

前言
准备好迎接搜索3.0时代了吗?
随着这几年AI技术的革新,“搜索应用”成为了AI应用层的第一个共识。
从海外的OpenAI、微软Bing Copilot、Perplexity AI,再到国内的豆包、Kimi,都是这一共识下的代表产品。
技术上,从传统的关键词检索,到RAG,大家已经不满足于只是生成对应的简单回答
而是期待大语言模型能够更好地应用于企业级场景,产生更大的价值。
不久前,OpenAI推出了最新的深度内容生成神器“DeepResearch”,用户只需一个"特斯拉的合理市值是多少"的提问,
DeepResearch就能生成一份包括企业财务、业务增长分析,再到最后的市值推演的专业分析报告。
而这,也指明了搜索AGI的发展方向。
在此背景下,如何基于“DeepResearch”理念,对其做定制化改造,成为了近一个月来的市场热门话题。
当然,Zilliz也是其中非常幸运的一员。不久前我们推出了DeepSearcher开源项目 ,不到半个月,在GitHub收获的star数量就已经超过3100!
感谢全球开发者和各位读者们的火热支持!
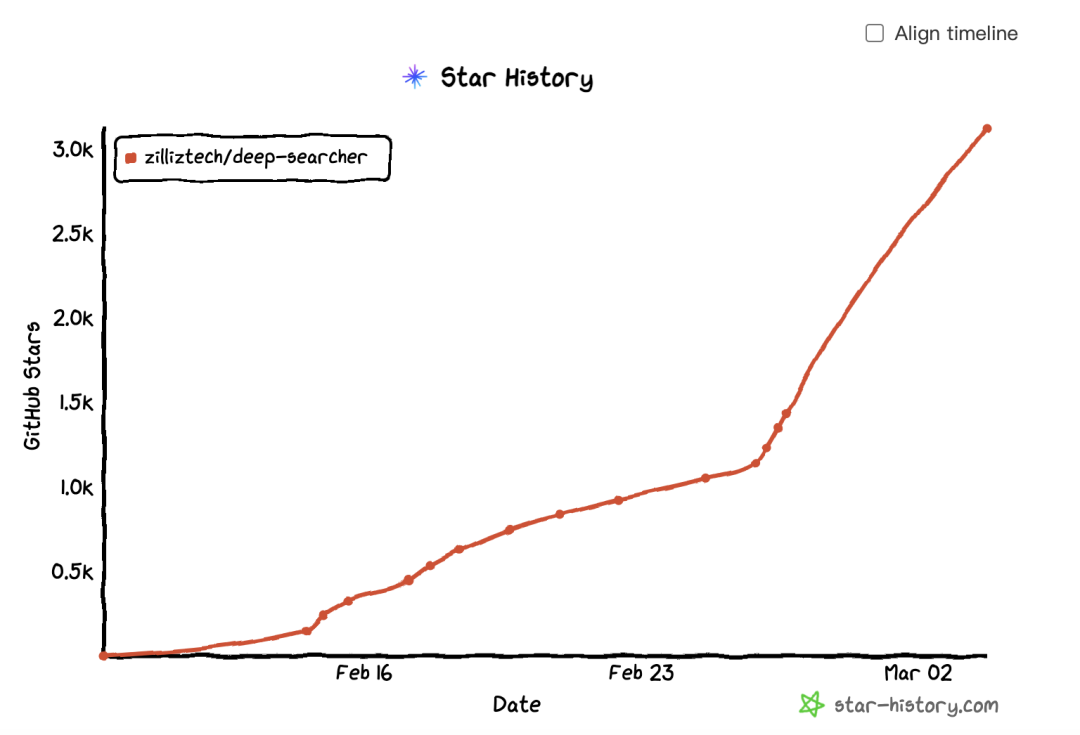
尝鲜链接:https://github.com/zilliztech/deep-searcher
建立在DeepResearch大模型+超级搜索+研究助理的三合一的基础上,
DeepSearcher还通过Milvus向量数据库引入本地数据,并支持用户自由更换包括DeepSeek-R1在内的底层模型,为用户带来了更符合企业级场景的全新RAG范式。
1、从RAG到Agentic RAG,更聪明的推理,到底为RAG带来了什么?
如果要给DeepSearcher一个明确的定性,那它应该属于一个非常典型的Agentic RAG架构。
所谓Agentic RAG,是一种融合智能代理(Agent)能力的RAG架构。通过动态规划、多步骤推理和自主决策机制,Agentic RAG可以在复杂任务中实现闭环的检索-加工-验证-优化。
其崛起,主要受到大模型推理能力提升的影响。
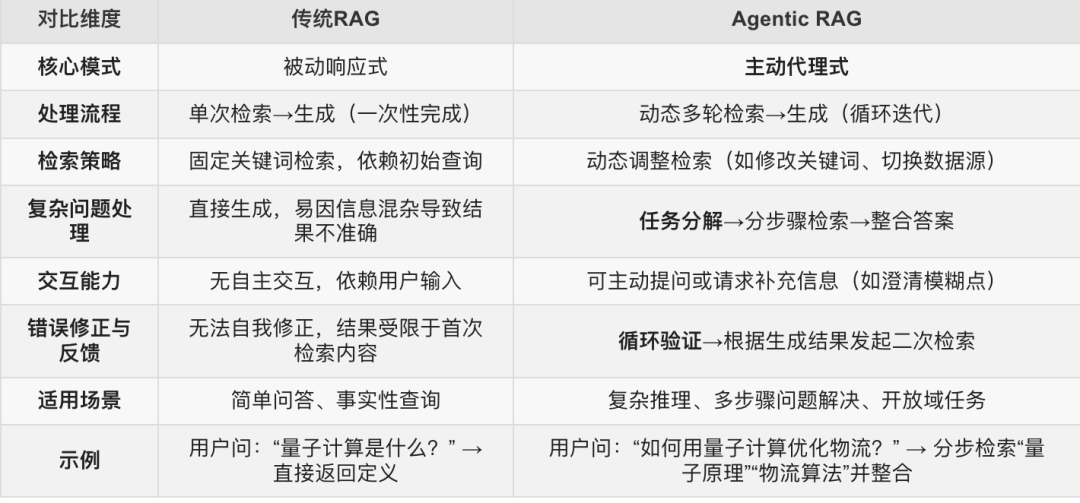
相比传统RAG,Agentic RAG可以将我们的问题,通过大模型的推理能力,拆分成多个子问题,并在多轮查询中,不断的迭代与优化,直到得到满意结果。
相应的,Agentic RAG相比传统RAG有着三大优势:
(1)被动响应变为主动响应;
(2)单次的关键词检索,升级为多轮的动态调整检索,并拥有自我修正能力;
(3)适用场景,从最基础的简单事实问答,升级为复杂推理、复杂报告生成等开放域任务。
而基于以上能力的升级,DeepSearcher能够像人类专家一样,面对提问,不仅给出答案,更能给出推理过程、执行细节在内的一整套完整方案。
在这一背景下,**长期来看,Agentic RAG必定会取代传统RAG。**一方面,传统RAG对需求的响应还停留在非常基础的阶段,另一方面,现实中,我们大部分的需求表达背后,都是有隐含逻辑的,并不能被一步检索到位,必须通过推理-反思-迭代-优化来对其进行拆解与反馈。
2、DeepSearcher 的架构设计
一个通往搜索AGI的Agentic RAG应该如何设计?
从架构上看,DeepSearcher 主要分为两大模块。
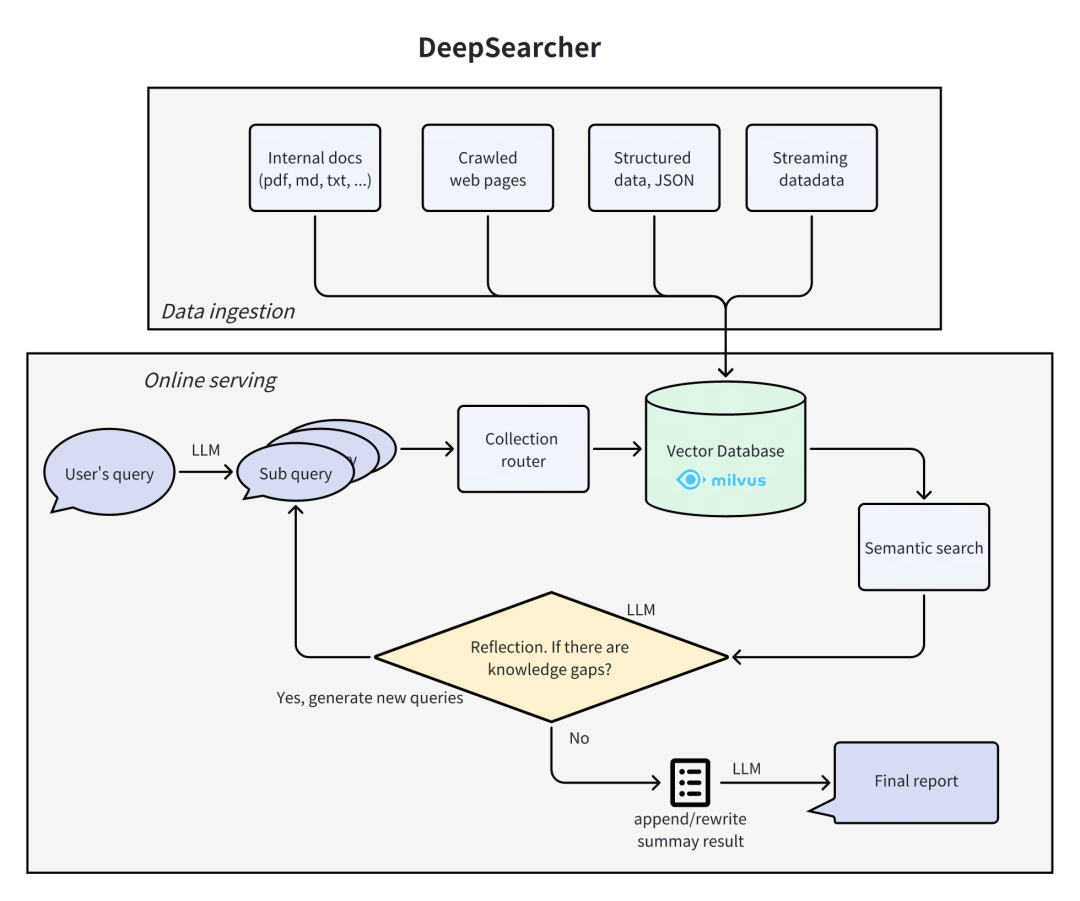
一个是数据接入模块,通过Milvus向量数据库来接入各种第三方的私有知识。这也是DeepSearcher相比OpenAI的原本DeepResearch做出的一大重大升级——更适合拥有独家数据的企业级场景。
另外一部分是在线推理查询模块。这个模块包括了各种Agent策略以及RAG的实现部分,负责给用户提供准确有深度的回答。
这部分引入了动态循环迭代机制**:**每次对向量数据库中内容完成数据查询后,系统都会启动一个反馈(reflection)流程,然后在每一轮迭代结束时,智能体(Agent)会对查询到的知识进行评估,判断其是否足以解答初始提出的问题。若发现仍存在知识缺口,便会触发下一轮迭代查询;若判定已有足够知识来作答,系统就会生成最终报告 。
这种不断“追问”“反思”的能力,其实也是Agentic RAG相比传统RAG的最大进步,甚至也是人类的文学、历史、哲学、科学千年来不断进步的根源所在。
3、Deep Searcher的效果到底如何,适合哪些场景?
我们可以看到,DeepSearcher 在完成安装并导入本地文件后,针对我们的 query 命令,会对所有导入的内容进行深度搜索和分析,在搜索过程中,会打印每一步的搜索过程和思考过程,并对结果进行最后的整合。
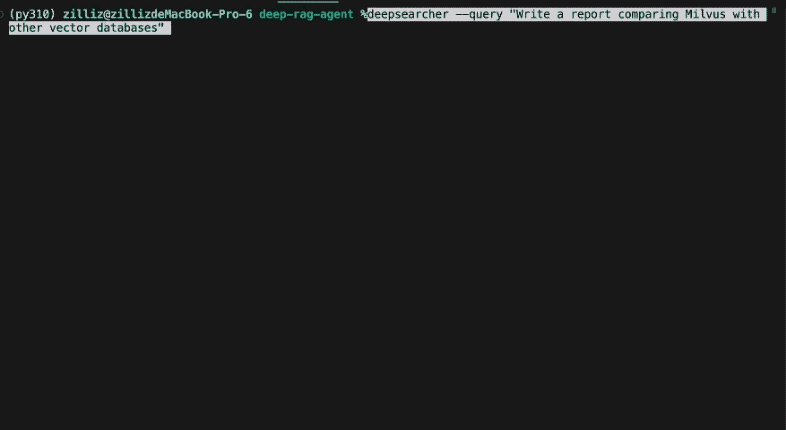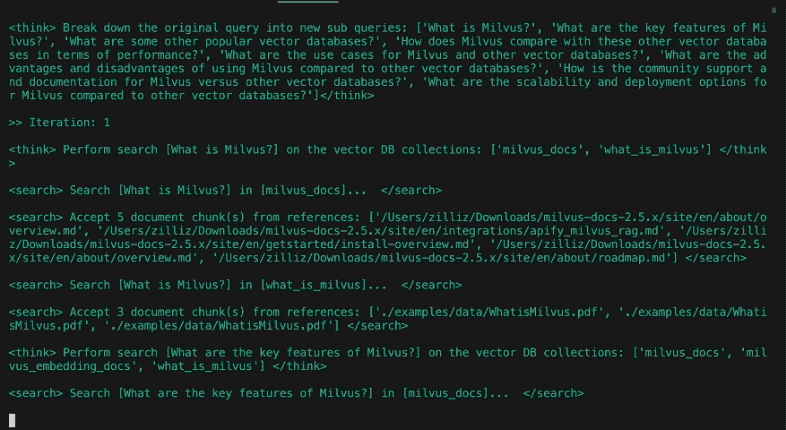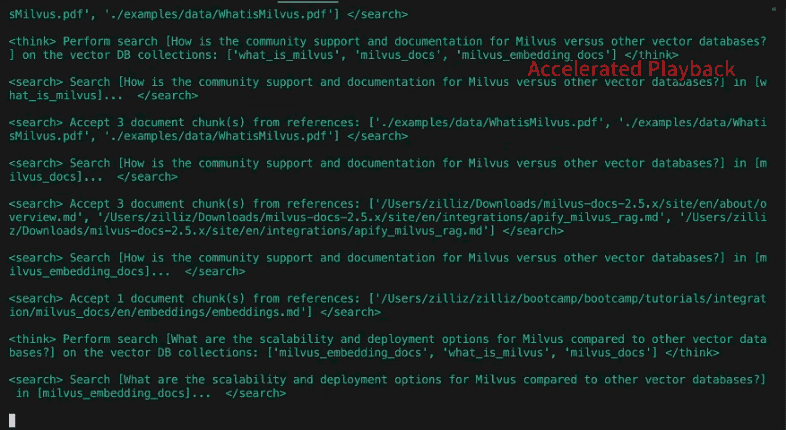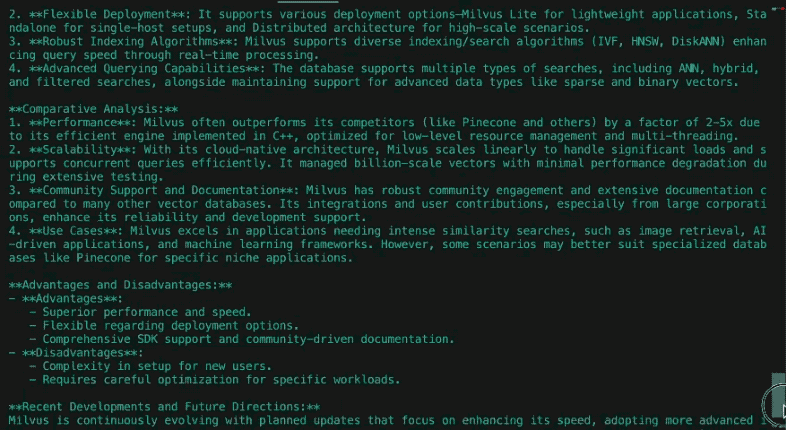
相应的,这种相对**“重思考”“重算力投入”**的模式,在落地中,更适合“综述类提问”以及“含复杂推理类提问”的场景。
(1)综述类提问
综述类提问的典型代表是写报告,写文档,写总结,它一般会给出一个简短的主题,但要求尽可能多的给出详尽汇报输出。
我们以“How has The Simpsons changed over time?”(《辛普森一家》动画剧集随着时间的推移发生了什么变化?)为例,在Deep Searcher第一轮,生成的初始子查询如下文所示:
Break down the original query into new sub queries: [
'How has the cultural impact and societal relevance of The Simpsons evolved from its debut to the present?',
'What changes in character development, humor, and storytelling styles have occurred across different seasons of The Simpsons?',
'How has the animation style and production technology of The Simpsons changed over time?',
'How have audience demographics, reception, and ratings of The Simpsons shifted throughout its run?']
在经过检索信息,反馈迭代后,又生成下一轮的子查询问题:
New search queries for next iteration: [
"How have changes in The Simpsons' voice cast and production team influenced the show's evolution over different seasons?",
"What role has The Simpsons' satire and social commentary played in its adaptation to contemporary issues across decades?",
'How has The Simpsons addressed and incorporated shifts in media consumption, such as streaming services, into its distribution and content strategies?']
每一轮的子问题都回到知识库里面检索,生成最后完整的报告:
**Report: The Evolution of _The Simpsons_ (1989–Present)**
**1. Cultural Impact and Societal Relevance**
_The Simpsons_ debuted as a subversive critique of American middle-class life, gaining notoriety for its bold satire in the 1990s. Initially a countercultural phenomenon, it challenged norms with episodes tackling religion, politics, and consumerism. Over time, its cultural dominance waned as competitors like _South Park_ and _Family Guy_ pushed boundaries further. By the 2010s, the show transitioned from trendsetter to nostalgic institution, balancing legacy appeal with attempts to address modern issues like climate change and LGBTQ+ rights, albeit with less societal resonance.
**2. Character Development and Storytelling Shifts**
Early seasons featured nuanced character arcs (e.g., Lisa’s activism, Marge’s resilience), but later seasons saw "Flanderization" (exaggerating traits, e.g., Homer’s stupidity, Ned Flanders’ piety). Humor evolved from witty, character-driven satire to reliance on pop culture references and meta-humor. Serialized storytelling in early episodes gave way to episodic, gag-focused plots, often sacrificing emotional depth for absurdity.
[...]
**12. Merchandising and Global Reach**
The 1990s merchandise boom (action figures, _Simpsons_-themed cereals) faded, but the franchise persists via collaborations (e.g., _Fortnite_ skins, Lego sets). International adaptations include localized dubbing and culturally tailored episodes (e.g., Japanese _Itchy & Scratchy_ variants).
**Conclusion**
_The Simpsons_ evolved from a radical satire to a television institution, navigating shifts in technology, politics, and audience expectations. While its golden-age brilliance remains unmatched, its adaptability—through streaming, updated humor, and global outreach—secures its place as a cultural touchstone. The show’s longevity reflects both nostalgia and a pragmatic embrace of change, even as it grapples with the challenges of relevance in a fragmented media landscape.
(2)含复杂推理类提问
含复杂推理类提问,通常在提问中包含着隐含着复杂的逻辑推理,比如问谁的七大姑八大姨家的小孩上学的班级的班主任名字。这类问题往往存在多个实体关系或者逻辑之间的连接,需要多次反馈迭代查询。
我们以问题:
“Which film has the director who is older, God’S Gift To Women or Aldri annet enn bråk.”(哪部电影的导演年龄更大,是《God’S Gift To Women》还是 《Aldri annet enn bråk》)为例。
对人类来说,这个问题可能很基础。
但对传统RAG来说,这显然这是个复杂的问题,因为我们的知识库,并不会存储这个问题的直接答案。
因此,我们需要先检索到两部电影的导演的信息,然后找到他们的出生日期,最后再比较哪个年纪大。
Deep Searcher的搜索过程如下:
系统针对拆解后的子问题:
["Who is the director of God'S Gift To Women?", 'Who is the director of Aldri annet enn bråk?', 'What are the ages of the respective directors?', 'Which director is older?']
然后第一次迭代找到
The director of "God's Gift To Women" is Michael Curtiz, the director of "Aldri annet enn bråk" is Edith Carlmar
定位到两部电影的导演的名字。
第二轮的子查询包括:
["Find the birthdate of Michael Curtiz, the director of God's Gift To Women", 'Find the birthdate of Edith Carlmar, the director of Aldri annet enn bråk']
然后搜索到两位导演的出生年月,最后得到正确的回答。
The director of "God's Gift To Women" is Michael Curtiz, who was born on December 24, 1886 and passed away on April 11, 1962. He was a Hungarian-born American film director known for his prolific career in Hollywood.
On the other hand, the director of "Aldri annet enn bråk" is Edith Carlmar, who was born on November 15, 1911 and passed away on May 17, 2003.
Therefore, Michael Curtiz is older than Edith Carlmar.
而反观普通RAG的回答效果:
1. **Aldri annet enn bråk** (1954) is directed by **Edith Carlmar**, who was born on November 15, 1911.
2. The related chunks did not provide specific details about the director of "God's Gift to Women." However, if we look at external sources for "God's Gift to Women," the film was directed by **L. M. (Lyman) Steinberg**, who was born on December 19, 1905.
By comparing their birth dates:
- Edith Carlmar: November 15, 1911
- L. M. Steinberg: December 19, 1905
**Conclusion**: L. M. Steinberg, the director of "God's Gift to Women," is older than Edith Carlmar, the director of "Aldri annet enn bråk."
由于一次性检索的内容不足,检索到的电影《God’s Gift to Women》的导演无法推断,此时LLM幻觉猜测是另外一名导演,这直接导致错误的回答。
4、Deep Searcher VS 普通RAG 定量对比
在GitHub的Deep Searcher官方代码库里,我们已经提供了定量测试的代码。
在本文中,我们以 2WikiMultiHopQA 这个常见的数据集测试。(由于测试需要消耗大量API token,这里只测试前50条数据,和全量数据测试相比会有一些抖动误差,但大致可以反映和说明问题。)
(1)和普通RAG的召回率效果对比
以Max Iterations(最大反馈迭代)为横轴,以Recall(召回率)为纵轴,下图是Deep Searcher 的召回率和普通RAG召回率的对比。
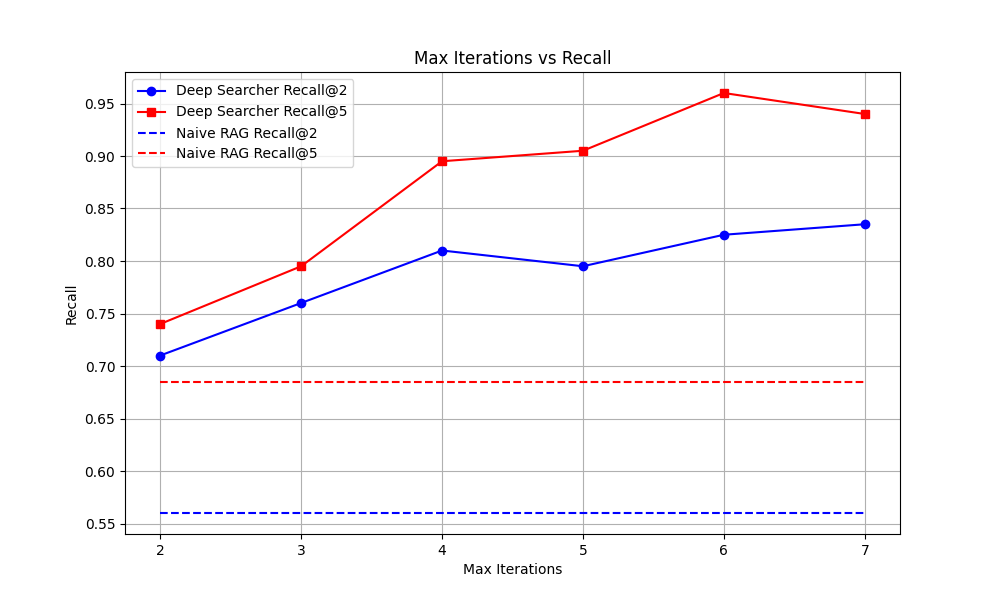
可以看到,随着Max Iterations(最大反馈迭代)次数变多,Deep Searcher 召回效果越来越好。
但也可以看到,随着迭代次数慢慢增加,边际收益越来越少,说明反馈次数增加后,可能会达到一定的上限,继续反馈可能不太能得到更好的效果(因此,我们默认迭代次数为3,您可以根据自身的需求进行调整)。
(2)token的消耗量
我们以迭代次数为横轴,50次总的token消耗为纵轴,绘制出下图:
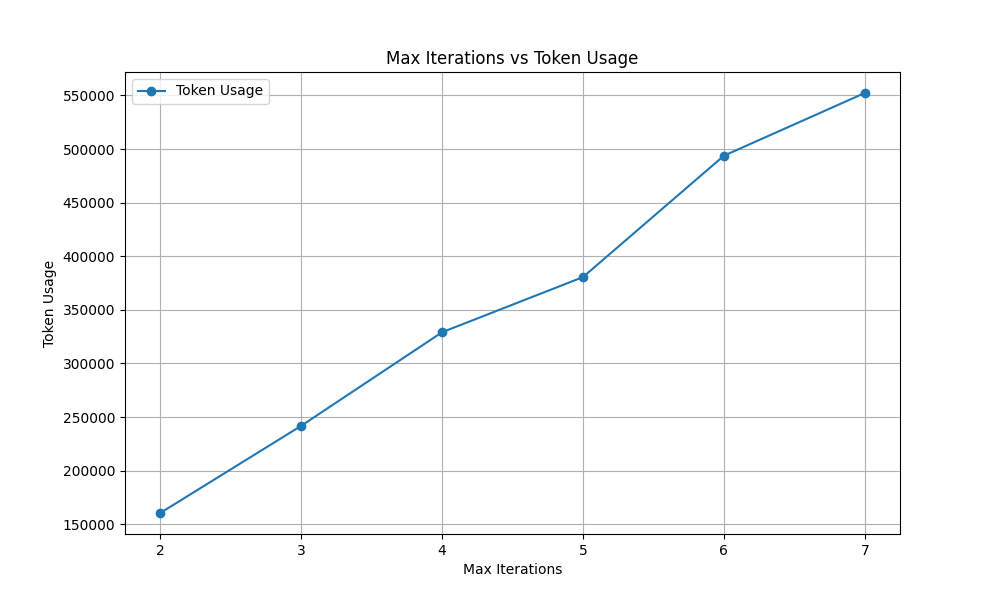
很明显可以看到,随着迭代次数的提高,我们可以看到,Deep Searcher 的token的消耗是线性地提升。如果按照4次来算,大约0.3M的token消耗,如果粗略按照OpenAI的gpt-4o-mini单价0.60$/1M output token来算,平均每次查询大约是0.18 / 50 = 0.0036美元的费用消耗。
如果换做推理模型,这个费用应该会数倍增加,包括推理模型本身的单价更贵,以及推理模型的输出token量会更多。
(3)模型间的对比
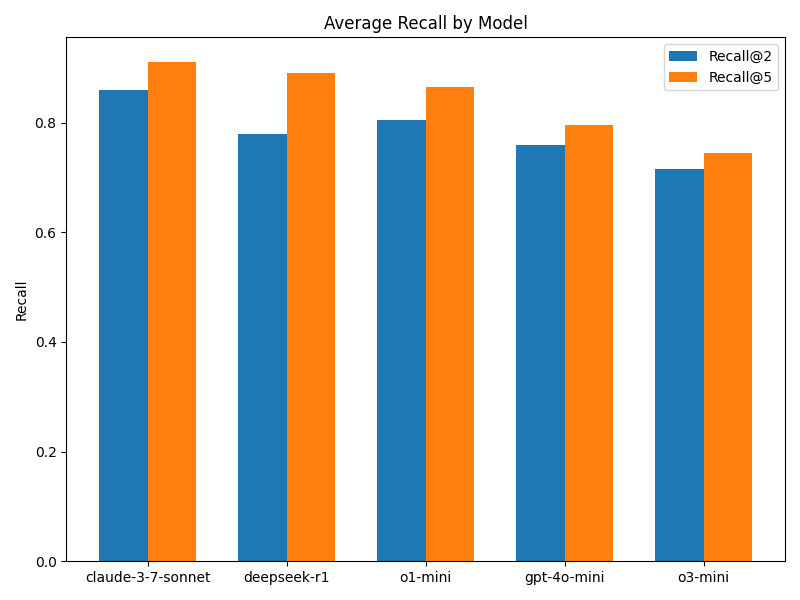
相比OpenAI官方推出的DeepResearch,我们推出的 Deep Searcher 的另一大特点是可以自由切换模型。
在这里,我们也对各种不同的推理模型、非推理模型(如(gpt-4o-mini))进行了测试。
可以看到,Claude 3.7 Sonnet的效果最好,不过也领先的也不多。当然,因为我们的测试样本量不多,所以每次测试的结果可能会有一些偏差。
但总体上看,推理模型是比非推理模型强的。
另外在我们的测试中,更弱更小的的非推理模型有时由于指令跟随能力太弱,无法完成整个 agent 查询流程,所以也无法完成整个测试,这个也是不少开发者在部署类似产品时经常会遇到的一个问题。
5、Deep Searcher VS Graph RAG
Deep Searcher的本质是Agentic RAG,和Graph RAG有着很明显的区别。
Graph RAG主要聚焦于对存在连接关系的文档展开查询,在处理多跳类问题上表现出色。
例如,当导入一部长篇小说时,它能够精准抽取各个人物之间错综复杂的关系。其运作方式是在文档导入环节,就对实体间关系进行抽取。因此,这一过程会大量消耗大模型的token资源 。
而在查询阶段,不论是否是查询图中某些节点的信息,都会进行图结构的搜索,这使得这一框架不太灵活。
反观Agentic RAG,它的资源消耗模式与Graph RAG恰好相反。在数据导入阶段,Agentic RAG无需执行额外特殊操作,而在回答用户提问时,才会产生较多大模型的token消耗。
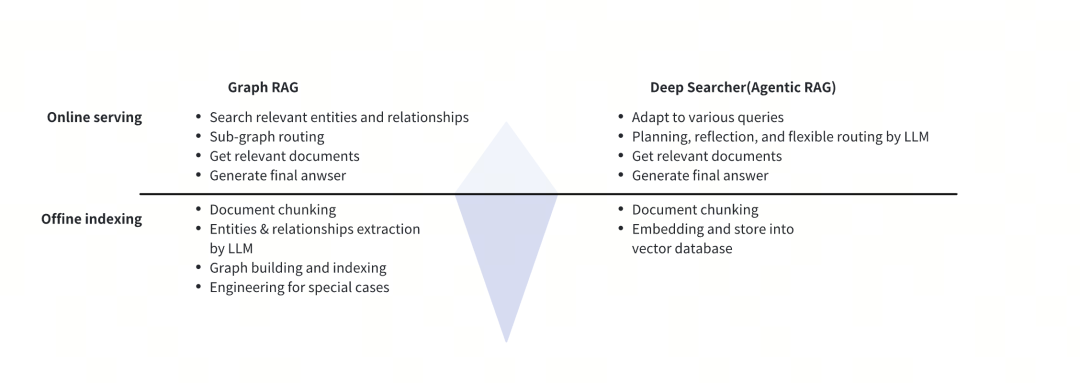
从查询模式的灵活性角度对比,Graph RAG存在明显短板,它的查询模式较为固定,通常仅适用于单一关系的查询,难以根据多样化的需求进行灵活调整。
而Agentic RAG则展现出强大的灵活性。Deep Searcher在不论是类似探究“A、B和C之间存在何种关系”这样复杂的逻辑问题,亦或是撰写各类专业报告等任务,都能在查询阶段,依据问题的特性灵活调整路由策略,进行反复的反馈迭代思考,从而给出最为精准、全面的回答。
未来,随着大模型成本持续降低,推理性能稳步提升,像Deep Searcher这样的Agentic RAG凭借其突出的灵活性与适应性,极有可能在未来成为主流技术,并在实际应用场景中实现深度落地。
但这并不意味着全盘否定Graph RAG类产品,由于其在调整方面存在一定难度,后续或许更多地作为一个基础组件,融入到更为复杂的技术体系中,与其他技术协同发挥作用。
6、Deep Searcher VS Deep Research
与OpenAI的Deep Research不同,Deep Searcher着重聚焦于对私有数据的深度检索与理解。借助向量数据库,Deep Searcher能够接入多样化的数据源,整合不同类型的数据,并将其统一存储于向量数据库的知识库中。凭借向量数据库强大的语义搜索功能,Deep Searcher可实现对海量离线数据的语义搜索。
另一方面,Deep Searcher是一个完全开源的产品。毋庸置疑,OpenAI的Deep Research在内容生成质量上,依然在业内处于领先地位,但对企业用户来说,每个账户除了需要每月需支付200美元之外,闭源的服务也就意味着其内部流程对用户而言是未知的。而Deep Searcher,所有内部流程都是开源的,用户能够清晰了解其中的细节,并基于开源代码进行定制,或者将其部署到生产环境中。
7、一些思考与经验分享
在整个项目的研发以及后续迭代过程中,我们有一些经验与心得分享:
推理模型很好,但绝非万能。我们通过实验发现,推理模型做 agent 虽然效果好,但有时也会对一些简单的指令判断,做一大堆分析与反复思考确认,不仅消耗过多token,回答速度还慢。这也印证了诸如 OpenAI 的大模型厂商,后续不再区别推理和非推理模型背后的逻辑,模型服务应该自动根据需求判断是否推理,以节省不必要的 token 开销。
Agentic RAG 的爆发尽在眼前。从需求侧看,深度内容生成是一个刚需场景;技术侧来看,提升RAG效果也是刚需。长期来看,影响Agentic RAG 爆发的唯一阻碍就是成本,但是随着DeepSeek R1这样的低成本高质量LLM出现,以及摩尔定律推动的芯片降本,推理服务的成本也会变得越来越低。
Agentic RAG 也存在隐形的scaling law “墙”。实验中,面对一些复杂问题,我们一度尝试通过增加 token 数量来优化效果。但最终发现,随着 token 数量的增加,边际收益递减的现象逐渐显现,到了一定阶段,即便投入更多 token 进行反思和迭代,效果也难以得到进一步提升。
传统RAG已死:传统RAG的优势在于一次检索的低成本。但其对需求的响应还停留在非常基础语义理解-检索的阶段;但现实中,我们大部分的需求表达背后,都是有隐含逻辑的,并不能被一步检索到位(比如,如何在一年赚一个亿),必须通过推理-反思-迭代-优化来对其进行拆解与反馈,而以Deep Searcher为代表的Agentic RAG 技术方向,将是无可置疑的大势所趋。
小白/程序员如何系统学习大模型LLM?
作为在一线互联网企业深耕十余年的技术老兵,我经常收到小白和程序员朋友的提问:“零基础怎么入门大模型?”“自学没有方向怎么办?”“实战项目怎么找?”等问题。难以高效入门。
这里为了帮助大家少走弯路,我整理了一套全网最全最细的大模型零基础教程。涵盖入门思维导图、经典书籍手册、实战视频教程、项目源码等核心内容。免费分享给需要的朋友!

👇👇扫码免费领取全部内容👇👇

1、我们为什么要学大模型?
很多开发者会问:大模型值得花时间学吗?答案是肯定的——学大模型不是跟风追热点,而是抓住数字经济时代的核心机遇,其背后是明确的行业需求和实打实的个人优势:
第一,行业刚需驱动,并非突发热潮。大模型是AI规模化落地的核心引擎,互联网产品迭代、传统行业转型、新兴领域创新均离不开它,掌握大模型就是拿到高需求赛道入场券。
第二,人才缺口巨大,职业机会稀缺。2023年我国大模型人才缺口超百万,2025年预计达400万,具备相关能力的开发者岗位多、薪资高,是职场核心竞争力。
第三,技术赋能增效,提升个人价值。大模型可大幅提升开发效率,还能拓展职业边界,让开发者从“写代码”升级为“AI解决方案设计者”,对接更高价值业务。
对于开发者而言,现在入门大模型,不仅能搭上行业发展的快车,还能为自己的职业发展增添核心竞争力——无论是互联网大厂的AI相关岗位,还是传统行业的AI转型需求,都在争抢具备大模型技术能力的人才。


人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
2、大模型入门到实战全套学习大礼包分享
最后再跟大家说几句:只要你是真心想系统学习AI大模型技术,这份我耗时许久精心整理的学习资料,愿意无偿分享给每一位志同道合的朋友。
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
部分资料展示
2.1、 AI大模型学习路线图,厘清要学哪些
对于刚接触AI大模型的小白来说,最头疼的问题莫过于“不知道从哪学起”,没有清晰的方向很容易陷入“东学一点、西补一块”的低效困境,甚至中途放弃。
为了解决这个痛点,我把完整的学习路径拆解成了L1到L4四个循序渐进的阶段,从最基础的入门认知,到核心理论夯实,再到实战项目演练,最后到进阶优化与落地,每一步都明确了学习目标、核心知识点和配套实操任务,带你一步步从“零基础”成长为“能落地”的大模型学习者。后续还会陆续拆解每个阶段的具体学习内容,大家可以先收藏起来,跟着路线逐步推进。

L1级别:大模型核心原理与Prompt
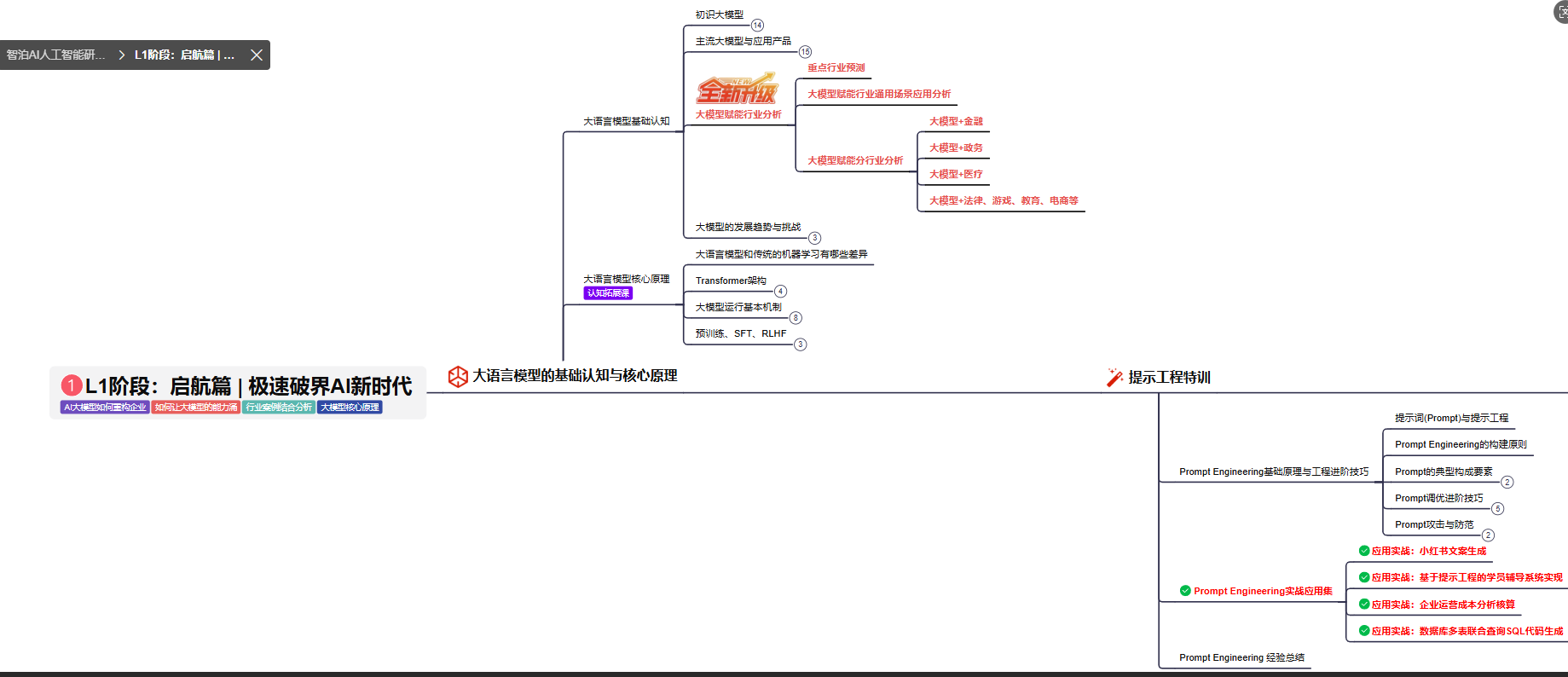
L1阶段: 将全面介绍大语言模型的基本概念、发展历程、核心原理及行业应用。从A11.0到A12.0的变迁,深入解析大模型与通用人工智能的关系。同时,详解OpenAl模型、国产大模型等,并探讨大模型的未来趋势与挑战。此外,还涵盖Pvthon基础、提示工程等内容。
目标与收益:掌握大语言模型的核心知识,了解行业应用与趋势;熟练Python编程,提升提示工程技能,为AI应用开发打下坚实基础。
L2级别:RAG应用开发工程
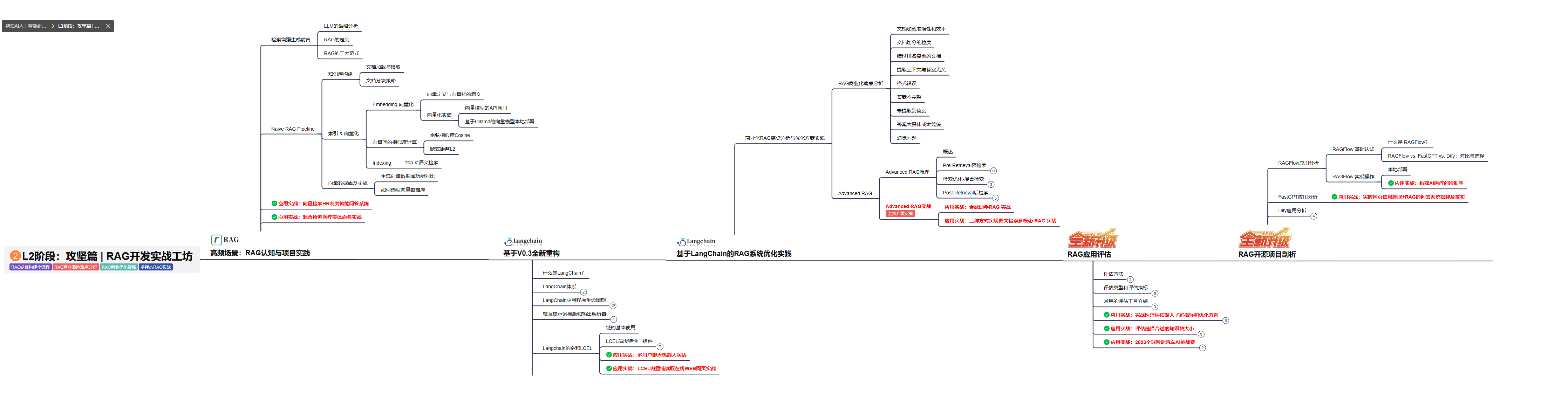
L2阶段: 将深入讲解AI大模型RAG应用开发工程,涵盖Naive RAGPipeline构建、AdvancedRAG前治技术解读、商业化分析与优化方案,以及项目评估与热门项目精讲。通过实战项目,提升RAG应用开发能力。
目标与收益: 掌握RAG应用开发全流程,理解前沿技术,提升商业化分析与优化能力,通过实战项目加深理解与应用。
L3级别:Agent应用架构进阶实践
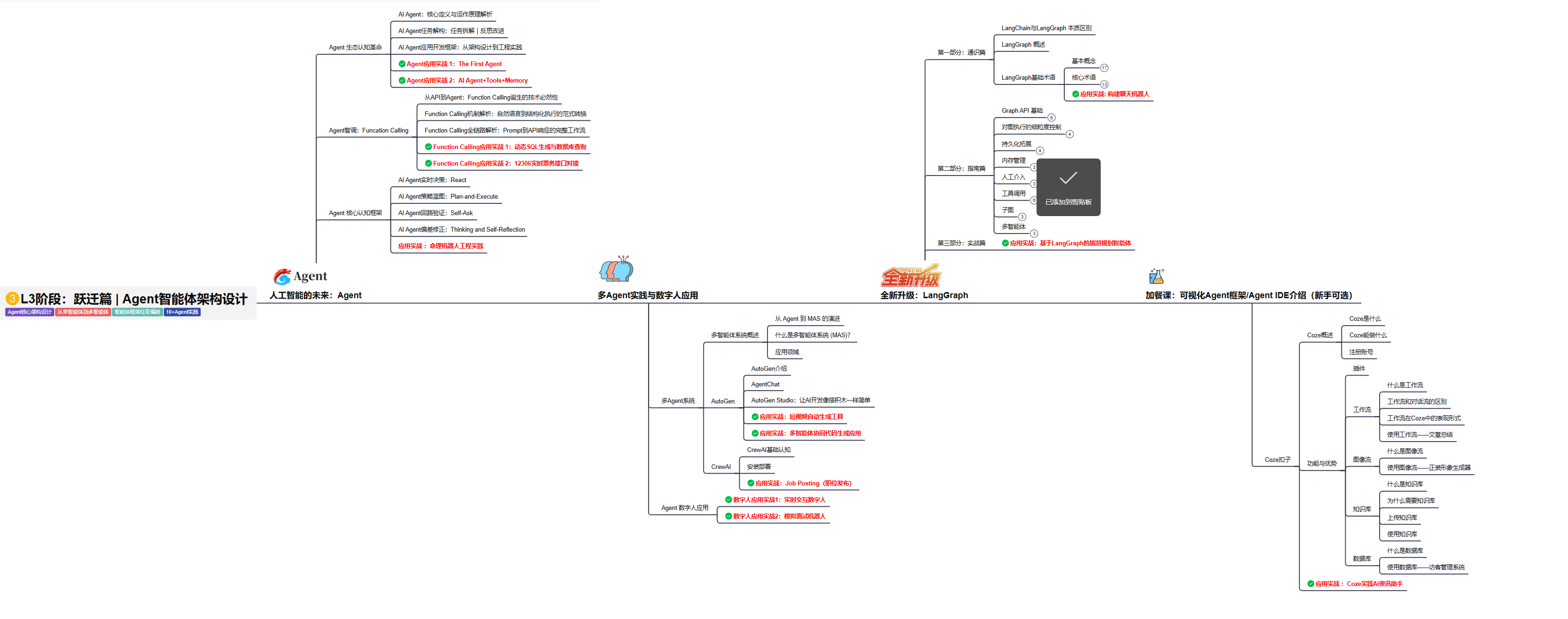
L3阶段: 将 深入探索大模型Agent技术的进阶实践,从Langchain框架的核心组件到Agents的关键技术分析,再到funcation calling与Agent认知框架的深入探讨。同时,通过多个实战项目,如企业知识库、命理Agent机器人、多智能体协同代码生成应用等,以及可视化开发框架与IDE的介绍,全面展示大模型Agent技术的应用与构建。
目标与收益:掌握大模型Agent技术的核心原理与实践应用,能够独立完成Agent系统的设计与开发,提升多智能体协同与复杂任务处理的能力,为AI产品的创新与优化提供有力支持。
L4级别:模型微调与私有化大模型
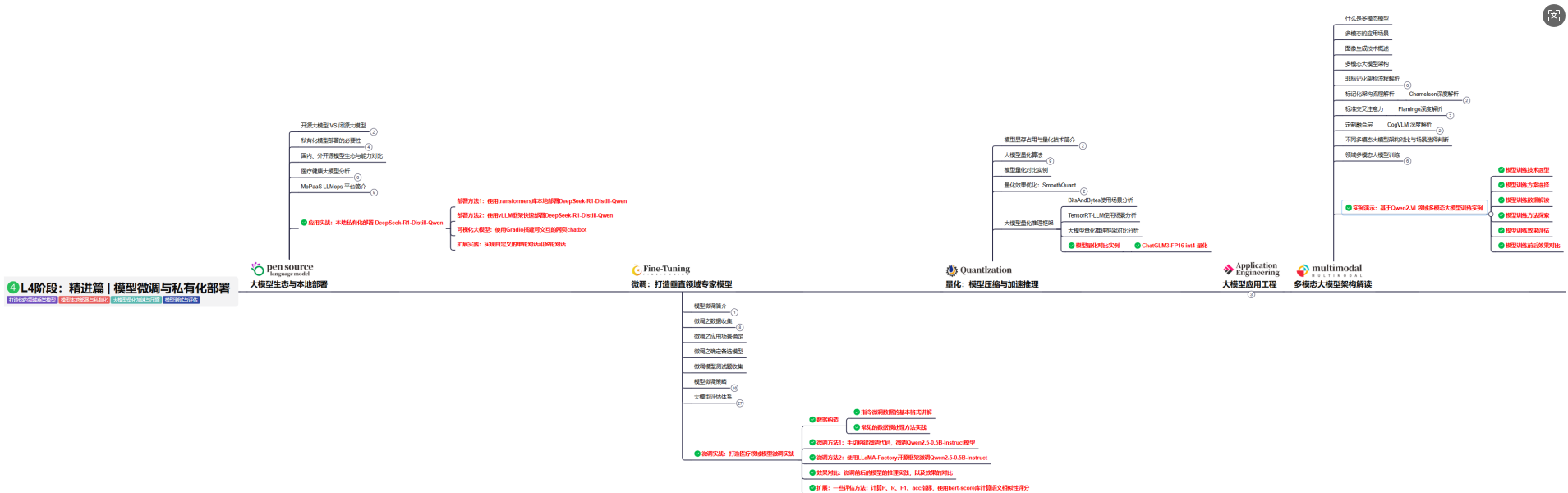
L4级别: 将聚焦大模型微调技术与私有化部署,涵盖开源模型评估、微调方法、PEFT主流技术、LORA及其扩展、模型量化技术、大模型应用引警以及多模态模型。通过chatGlM与Lama3的实战案例,深化理论与实践结合。
目标与收益:掌握大模型微调与私有化部署技能,提升模型优化与部署能力,为大模型项目落地打下坚实基础。
2.2、 全套AI大模型应用开发视频教程
从入门到进阶这里都有,跟着老师学习事半功倍。

2.3、 大模型学习书籍&文档
收录《从零做大模型》《动手做AI Agent》等经典著作,搭配阿里云、腾讯云官方技术白皮书,帮你夯实理论基础。

2.4、 AI大模型最新行业报告
2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

2.5、大模型大厂面试真题
整理了百度、阿里、字节等企业近三年的AI大模型岗位面试题,涵盖基础理论、技术实操、项目经验等维度,每道题都配有详细解析和答题思路,帮你针对性提升面试竞争力。

【大厂 AI 岗位面经分享(107 道)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

2.6、大模型项目实战&配套源码
学以致用,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。

适用人群

四阶段学习规划(共90天,可落地执行)
第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
-
硬件选型
-
带你了解全球大模型
-
使用国产大模型服务
-
搭建 OpenAI 代理
-
热身:基于阿里云 PAI 部署 Stable Diffusion
-
在本地计算机运行大模型
-
大模型的私有化部署
-
基于 vLLM 部署大模型
-
案例:如何优雅地在阿里云私有部署开源大模型
-
部署一套开源 LLM 项目
-
内容安全
-
互联网信息服务算法备案
-
…
👇👇扫码免费领取全部内容👇👇
3、这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 28
28 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)