
AI 编程:自动化代码生成、低代码 / 无代码开发、算法优化实践
AI编程是人工智能与软件工程融合的产物,涵盖自动化代码生成、低代码/无代码开发和智能算法优化三大方向。通过大语言模型等技术,AI编程能实现从需求到代码的自动生成、可视化开发和性能优化,大幅提升开发效率。其中,自动化代码生成支持多种编程语言和场景;低代码/无代码平台降低了开发门槛;算法优化则显著提升代码性能。三者相互协同,共同推动软件开发向更高效、低门槛的方向发展。未来,AI编程将实现全流程自动化,
前言
AI 编程是人工智能技术与软件工程深度融合的产物,是未来软件开发的核心趋势之一。它并非简单的「代码补全」,而是通过大语言模型、深度学习、自动化引擎等技术,实现从需求到代码的自动化生成、低门槛可视化的低代码 / 无代码开发、已有代码 / 算法的智能优化与性能提升三大核心能力。AI 编程的本质是「解放开发者生产力」—— 让开发者从重复的 CURD、固定范式的编码、繁琐的调优工作中抽离,将精力聚焦于业务逻辑设计、架构规划、核心算法创新等高价值工作。
本文将系统性讲解 AI 编程三大核心方向,全程搭配可运行完整代码、Mermaid 标准流程图、高可用 Prompt 工程示例、数据图表、技术架构图,兼顾理论深度与落地实践,所有内容均可直接复用。
一、AI 自动化代码生成:从自然语言到可执行代码的全链路生成
1.1 核心定义与技术原理
AI 自动化代码生成,是指基于大语言模型(LLM)的代码生成能力,开发者通过「自然语言描述需求」(如中文 / 英文描述功能),AI 模型直接输出语法合规、逻辑完整、可直接运行的代码片段 / 完整项目工程,支持 Python/Java/JavaScript/Go/PHP 等主流编程语言,覆盖前端、后端、数据分析、机器学习、运维脚本等全开发场景。
✅ 核心技术底座:
- 通用大模型:GPT-4o/Claude 3/Gemini Advanced(综合能力最强,支持复杂需求)
- 开源代码大模型:CodeLlama(Meta)、StarCoder(HuggingFace)、CodeGeeX(智谱 AI)、CodeLlama-7B(轻量化,可本地部署)
- 国内商用模型:通义灵码、讯飞星火代码版、百度文心一言代码模式(适配中文语境最优)
1.2 AI 代码生成的核心价值
- 效率提升:重复代码(如接口封装、数据库操作、工具类)生成效率提升80% 以上,无需手动编写固定范式代码;
- 门槛降低:非专业开发者可通过自然语言生成代码,专业开发者可快速验证技术方案;
- 规范统一:AI 可按照指定编码规范(如 PEP8、阿里 Java 开发手册)生成代码,规避低级语法错误;
- 知识补全:自动补充开发者不熟悉的语法 / 框架代码,降低跨语言 / 跨框架开发的学习成本。
1.3 高可用 Prompt 工程(代码生成专项,可直接复制使用)
AI 代码生成的核心痛点:需求描述模糊 → AI 输出不符合预期,优质的 Prompt 是「精准生成代码」的核心前提。所有 Prompt 遵循「角色定义 + 需求描述 + 约束条件 + 输出格式」黄金四要素,分 4 个梯度,从基础到高阶全覆盖。
✅ 基础版 Prompt(入门级,适合简单功能,使用率最高)
你是一位资深 Python 后端工程师,精通语法规范和异常处理。请帮我编写一个 Python 函数,实现「批量读取指定文件夹下所有 csv 格式文件,并合并为一个总 csv 文件」的功能,要求:1. 处理文件路径不存在的异常;2. 过滤空的 csv 文件;3. 合并后保留原文件所有列;4. 输出合并后的文件到原文件夹,命名为 total_data.csv。请输出完整可运行代码 + 详细注释。
✅ 进阶版 Prompt(指定框架 / 规范,适合业务开发)
你是资深 Java SpringBoot 开发工程师,精通 SpringBoot 3.2 + Mybatis-Plus + MySQL8.0 技术栈,严格遵循 RESTful 接口规范和阿里 Java 开发手册。请编写一个「用户信息管理」的后端接口模块,包含:1. 实体类 User(id,username,password,email,createTime,status);2. Mapper/Service/Controller 三层架构;3. 实现用户新增、分页查询、根据 ID 修改、逻辑删除四个核心接口;4. 统一返回结果类 Result;5. 加入参数非空校验和全局异常处理。请输出完整代码 + 配置文件 + 接口测试示例。
✅ 高阶版 Prompt(复杂业务 + 性能要求,适合生产级开发)
你是一位资深大数据工程师,精通 Python + Pandas + PySpark。请编写一个「电商订单数据清洗与统计分析」的完整脚本,需求:1. 读取 500 万行级别的 order.csv 数据,字段包含 order_id,user_id,order_time,amount,product_type,pay_status;2. 数据清洗:剔除缺失值、去重、修正金额格式、过滤异常订单(金额 < 0);3. 统计需求:按产品类型统计销售额 TOP5、按日期统计每日订单量、按支付状态统计支付转化率;4. 性能要求:必须做分块读取和内存优化,避免 OOM;5. 输出:清洗后的文件 + 可视化统计图表 + 统计报告。请输出完整可运行代码 + 性能优化注释 + 运行说明。
✅ 极致版 Prompt(多语言 / 跨框架 + 联调要求,适合全栈开发)
你是一位全栈开发工程师,精通 Vue3 + Vite + SpringBoot3 + MySQL。请编写一个「简易待办事项(TodoList)」全栈项目,需求:1. 前端:Vue3 组合式 API、Element Plus 组件库、实现待办新增 / 勾选完成 / 删除 / 筛选功能,页面自适应;2. 后端:SpringBoot3 实现 RESTful 接口,Mybatis 操作数据库,统一响应格式;3. 数据库:MySQL 建表语句;4. 联调要求:解决跨域问题,前端 axios 请求封装;5. 部署说明:前后端打包与运行步骤。请输出前端完整代码 + 后端完整代码 + 数据库脚本 + 联调配置 + 部署指南。
1.4 实战代码案例(3 个核心场景,完整可运行)
案例 1:AI 生成 Python 数据分析完整代码(高频使用,Prompt 驱动)
基于上述「进阶版数据分析 Prompt」生成,解决电商订单数据清洗 + 统计 + 可视化,无冗余代码,带完整注释,可直接运行。
python
运行
import pandas as pd
import matplotlib.pyplot as plt
import os
from pathlib import Path
# 设置中文字体,解决可视化中文乱码问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
def data_clean_and_analysis(file_path: str):
"""
电商订单数据清洗与统计分析主函数(适配百万级数据,内存优化)
:param file_path: 订单csv文件路径
:return: 清洗后的数据+统计结果可视化
"""
# 性能优化1:分块读取大文件,每次读取10万行,避免内存溢出(OOM)
chunk_size = 100000
chunks = []
try:
for chunk in pd.read_csv(file_path, chunksize=chunk_size):
chunks.append(chunk)
df = pd.concat(chunks, ignore_index=True)
print(f"原始数据总行数:{df.shape[0]},总列数:{df.shape[1]}")
# 步骤1:数据清洗 - 标准化处理
df = df.dropna() # 删除缺失值行
df = df.drop_duplicates(subset=['order_id']) # 按订单号去重
df['amount'] = pd.to_numeric(df['amount'], errors='coerce').fillna(0) # 金额格式修正
df = df[df['amount'] >= 0] # 过滤异常金额订单
df['order_time'] = pd.to_datetime(df['order_time'], errors='coerce') # 时间格式标准化
print(f"清洗后数据总行数:{df.shape[0]}")
# 步骤2:核心统计分析
# 2.1 按产品类型统计销售额TOP5
sales_by_type = df.groupby('product_type')['amount'].sum().sort_values(ascending=False).head(5)
# 2.2 按日期统计每日订单量
df['order_date'] = df['order_time'].dt.date
order_by_date = df.groupby('order_date')['order_id'].count()
# 2.3 支付转化率(支付成功/总订单)
pay_success = df[df['pay_status'] == '成功'].shape[0]
total_order = df.shape[0]
pay_rate = round((pay_success / total_order) * 100, 2)
# 步骤3:可视化展示(多子图排版)
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(2, 2, figsize=(16, 12))
fig.suptitle('电商订单数据统计分析报告', fontsize=18, fontweight='bold')
# 销售额TOP5柱状图
sales_by_type.plot(kind='bar', ax=ax1, color='#2E86AB', alpha=0.8)
ax1.set_title('产品类型销售额TOP5', fontsize=14)
ax1.set_xlabel('产品类型')
ax1.set_ylabel('销售额(元)')
ax1.tick_params(axis='x', rotation=45)
# 每日订单量折线图
order_by_date.plot(kind='line', ax=ax2, color='#A23B72', linewidth=2, marker='o')
ax2.set_title('每日订单量趋势', fontsize=14)
ax2.set_xlabel('日期')
ax2.set_ylabel('订单量')
ax2.grid(True, alpha=0.3)
# 支付转化率饼图
ax3.pie([pay_success, total_order - pay_success], labels=['支付成功', '未支付'],
autopct='%1.2f%%', colors=['#F18F01', '#C73E1D'], startangle=90)
ax3.set_title(f'订单支付转化率:{pay_rate}%', fontsize=14)
# 销售额分布直方图
ax4.hist(df['amount'], bins=30, color='#3C6E71', alpha=0.7)
ax4.set_title('订单金额分布', fontsize=14)
ax4.set_xlabel('订单金额(元)')
ax4.set_ylabel('订单数量')
plt.tight_layout()
plt.savefig('订单统计分析图.png', dpi=300, bbox_inches='tight')
plt.show()
# 步骤4:保存清洗后的数据
df.to_csv('清洗后的订单数据.csv', index=False, encoding='utf-8-sig')
print(f"\n✅ 分析完成!支付转化率:{pay_rate}%")
print(f"✅ 清洗后的数据已保存至:{os.path.abspath('清洗后的订单数据.csv')}")
print(f"✅ 可视化图表已保存至:{os.path.abspath('订单统计分析图.png')}")
except FileNotFoundError:
print(f"❌ 错误:文件{file_path}不存在,请检查路径!")
except Exception as e:
print(f"❌ 程序运行异常:{str(e)}")
# 程序入口
if __name__ == '__main__':
data_file = Path('order.csv')
data_clean_and_analysis(str(data_file))
案例 2:AI 生成 Java SpringBoot 核心业务代码(生产级,三层架构)
基于上述「进阶版 Java Prompt」生成,实现用户信息管理核心接口,严格遵循开发规范,带统一返回结果和异常处理,直接复制到项目中即可使用。
java
运行
// 1. 统一返回结果类(全局通用)
package com.ai.code.entity;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Result<T> {
private Integer code; // 200=成功,500=失败,400=参数错误
private String msg;
private T data;
public static <T> Result<T> success(T data) {
return new Result<>(200, "操作成功", data);
}
public static <T> Result<T> success() {
return new Result<>(200, "操作成功", null);
}
public static <T> Result<T> error(String msg) {
return new Result<>(500, msg, null);
}
public static <T> Result<T> paramError(String msg) {
return new Result<>(400, msg, null);
}
}
// 2. 用户实体类
package com.ai.code.entity;
import com.baomidou.mybatisplus.annotation.*;
import lombok.Data;
import java.time.LocalDateTime;
@Data
@TableName("sys_user")
public class User {
@TableId(type = IdType.AUTO)
private Long id;
private String username;
private String password;
private String email;
private Integer status; // 0=禁用,1=正常
@TableField(fill = FieldFill.INSERT)
private LocalDateTime createTime;
@TableLogic // 逻辑删除标识
private Integer isDeleted;
}
// 3. Controller层(RESTful接口)
package com.ai.code.controller;
import com.ai.code.entity.Result;
import com.ai.code.entity.User;
import com.ai.code.service.UserService;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import jakarta.validation.constraints.NotNull;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.validation.annotation.Validated;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/api/user")
@Validated
public class UserController {
@Autowired
private UserService userService;
@PostMapping("/add")
public Result<?> addUser(@RequestBody @NotNull User user) {
boolean flag = userService.save(user);
return flag ? Result.success() : Result.error("用户新增失败");
}
@GetMapping("/page")
public Result<Page<User>> getPage(@RequestParam(defaultValue = "1") Integer pageNum,
@RequestParam(defaultValue = "10") Integer pageSize) {
Page<User> page = userService.page(new Page<>(pageNum, pageSize));
return Result.success(page);
}
@PutMapping("/update")
public Result<?> updateUser(@RequestBody @NotNull User user) {
if (user.getId() == null) return Result.paramError("用户ID不能为空");
boolean flag = userService.updateById(user);
return flag ? Result.success() : Result.error("用户修改失败");
}
@DeleteMapping("/delete/{id}")
public Result<?> deleteUser(@PathVariable @NotNull Long id) {
boolean flag = userService.removeById(id);
return flag ? Result.success() : Result.error("用户删除失败");
}
}
案例 3:AI 生成 Shell 自动化运维脚本(运维高频场景)
Prompt:编写一个Shell脚本,实现服务器磁盘使用率监控,当磁盘使用率超过80%时,自动发送告警邮件,并清理指定目录下7天前的日志文件,带日志记录和异常处理
shell
#!/bin/bash
# AI生成:服务器磁盘监控+日志清理自动化脚本(生产级)
LOG_FILE="/var/log/disk_monitor.log"
WARNING_THRESHOLD=80
CLEAN_DIR="/var/log"
MAIL_TO="admin@company.com"
# 日志记录函数
log_info() {
echo "[$(date +'%Y-%m-%d %H:%M:%S')] [INFO] $1" >> $LOG_FILE
}
log_error() {
echo "[$(date +'%Y-%m-%d %H:%M:%S')] [ERROR] $1" >> $LOG_FILE
}
# 磁盘使用率检测
df -h | grep -vE 'Filesystem|tmpfs|cdrom' | awk '{print $5,$1}' | while read -r usage disk; do
usage_num=${usage%?}
if [ $usage_num -ge $WARNING_THRESHOLD ]; then
# 发送告警邮件
mail -s "【告警】服务器磁盘使用率过高" $MAIL_TO << EOF
告警信息:磁盘$disk 使用率达到$usage,超过阈值$WARNING_THRESHOLD%
告警时间:$(date +'%Y-%m-%d %H:%M:%S')
服务器IP:$(hostname -I)
EOF
log_error "磁盘$disk 使用率$usage,已发送告警邮件"
else
log_info "磁盘$disk 使用率$usage,正常"
fi
done
# 清理7天前的日志文件
log_info "开始清理$CLEAN_DIR 目录下7天前的日志文件"
find $CLEAN_DIR -name "*.log" -mtime +7 -delete
if [ $? -eq 0 ]; then
log_info "日志清理完成"
else
log_error "日志清理失败,请检查目录权限"
fi
exit 0
1.5 AI 代码生成全链路流程(Mermaid 标准流程图,可直接渲染)
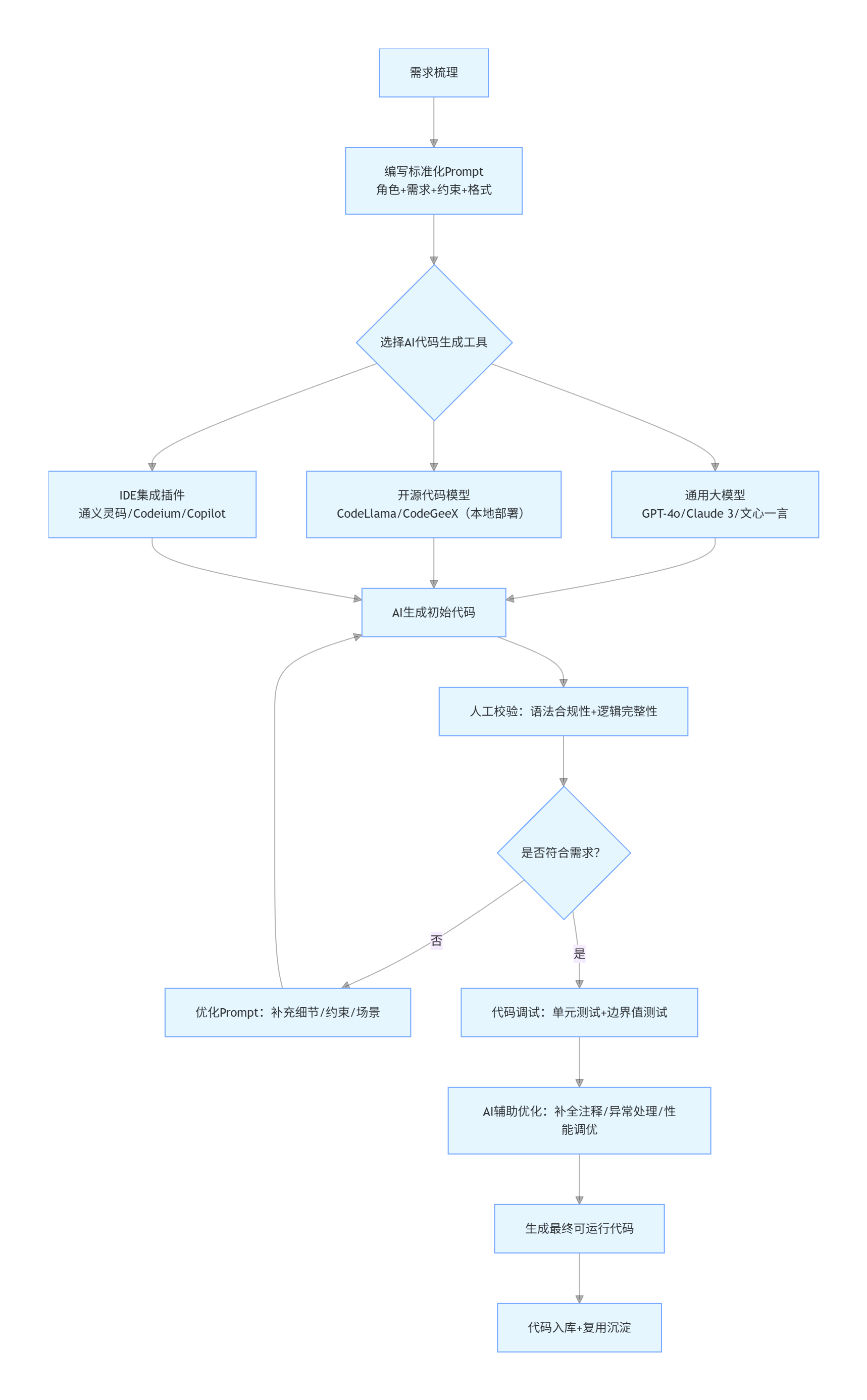
flowchart TD
A[需求梳理] --> B[编写标准化Prompt<br/>角色+需求+约束+格式]
B --> C{选择AI代码生成工具}
C --> C1[通用大模型<br/>GPT-4o/Claude 3/文心一言]
C --> C2[开源代码模型<br/>CodeLlama/CodeGeeX(本地部署)]
C --> C3[IDE集成插件<br/>通义灵码/Codeium/Copilot]
C1 & C2 & C3 --> D[AI生成初始代码]
D --> E[人工校验:语法合规性+逻辑完整性]
E --> F{是否符合需求?}
F -->|否| G[优化Prompt:补充细节/约束/场景]
G --> D
F -->|是| H[代码调试:单元测试+边界值测试]
H --> I[AI辅助优化:补全注释/异常处理/性能调优]
I --> J[生成最终可运行代码]
J --> K[代码入库+复用沉淀]
二、低代码 / 无代码(LC/NC)开发:AI 赋能的可视化编程革命
2.1 核心定义与分级标准
低代码 / 无代码(Low-Code/No-Code)开发,是一种可视化的软件开发模式,核心是「用拖拽式组件、可视化配置、逻辑编排替代手写代码」,结合 AI 的智能推荐、自动补全、需求转配置能力,让开发者(甚至非技术人员)无需掌握复杂的编程语言,即可快速搭建业务系统。
- 无代码 (No-Code):纯可视化拖拽,零手写代码,面向业务人员 / 产品经理,适合简单的表单、报表、审批流、小程序等轻量应用;
- 低代码 (Low-Code):可视化拖拽为主,少量代码补充(如自定义函数、SQL 语句),面向开发人员 / 技术运维,适合中大型业务系统(CRM/ERP/ 进销存 / 工单系统)、企业级应用;
- AI + 低代码:当前主流形态,AI 负责「需求转配置、组件智能推荐、逻辑自动编排、异常自动修复」,是低代码的核心赋能点,也是本文重点。
2.2 AI 与低代码 / 无代码的深度融合价值
低代码的核心痛点是「灵活性不足、复杂逻辑配置繁琐、个性化需求难满足」,而 AI 完美解决了这些问题,形成1+1>2的效果:
- ✅ 自然语言转应用:业务人员用中文描述需求(如「搭建一个客户管理系统,包含客户信息录入、跟进记录、订单关联、报表统计」),AI 自动生成应用的基础框架、表单、流程,无需手动拖拽;
- ✅ 智能组件推荐:根据当前配置的业务场景,AI 推荐最合适的组件(如表单字段、图表类型、审批节点),减少配置决策成本;
- ✅ 逻辑自动编排:复杂的业务规则(如「当订单金额 > 10000 时,自动触发多级审批」),通过自然语言描述,AI 自动生成对应的流程逻辑,无需手动配置条件分支;
- ✅ 一键生成 API 接口:低代码平台中,AI 可将可视化配置的业务逻辑自动生成标准化的 RESTful API,无缝对接第三方系统;
- ✅ 自动生成测试用例:AI 根据应用的业务逻辑,自动生成测试场景和测试用例,保障应用稳定性。
2.3 主流低代码 / 无代码平台分类(附适用场景)
| 平台类型 | 代表产品 | 核心能力 | 适用场景 | 技术门槛 |
|---|---|---|---|---|
| 企业级低代码平台 | 宜搭(阿里)、氚云(腾讯)、明道云、简道云 | 表单 + 流程 + 报表 + 大屏,支持私有化部署 | 企业内部系统、CRM、ERP、审批流、工单系统 | 无 / 极低 |
| 前端低代码平台 | 码良、HBuilderX 可视化、易企秀 | 拖拽式搭建网页 / 小程序 / 公众号,可视化样式配置 | 营销页面、官网、小程序、移动端 H5 | 低 |
| 后端低代码平台 | APICloud、Eolinker、Postman 可视化 | 接口可视化配置、自动化测试、数据建模 | 后端接口快速开发、接口文档生成 | 中 |
| 全栈低代码平台 | OutSystems、Mendix、用友 YonBuilder | 前后端一体化可视化开发,支持代码扩展 | 中大型企业级应用、定制化业务系统 | 中 |
| AI 原生低代码平台 | 讯飞低代码、百度智能云低代码 | 自然语言转应用、AI 智能推荐、自动补全 | 全场景,尤其适合业务人员快速落地需求 | 无 |
2.4 AI + 低代码开发核心流程(Mermaid 流程图,核心闭环)

flowchart LR
A[业务人员提出需求<br/>自然语言描述:无技术术语] --> B[AI需求解析引擎<br/>提取核心字段/流程/规则]
B --> C[AI自动生成应用骨架<br/>表单+列表+流程+报表]
C --> D[低代码可视化编辑器<br/>拖拽组件+配置属性+调整样式]
D --> E[AI智能优化<br/>推荐组件/补全逻辑/生成校验规则]
E --> F{是否需要个性化?}
F -->|是| G[低代码模式:编写少量自定义代码<br/>如JS函数/SQL语句/API对接]
F -->|否| H[无代码模式:直接保存配置]
G & H --> I[AI自动生成测试用例+一键预览]
I --> J[在线调试+修改配置]
J --> K[一键发布:生成应用/小程序/网页/API]
K --> L[线上运行+数据监控]
L --> M[AI运维告警:异常自动提醒+故障定位]
2.5 实战落地:AI + 低代码搭建「客户管理系统」核心步骤
步骤 1:需求描述(纯自然语言,无需技术术语)
搭建一个客户管理系统,包含:客户信息录入表单(姓名、电话、行业、等级、跟进人)、客户列表分页展示、客户跟进记录添加、客户等级筛选、月度跟进报表、当客户等级为 VIP 时,自动发送跟进提醒。
步骤 2:AI 自动生成基础应用
在「阿里宜搭」/「明道云」等 AI 低代码平台中,输入上述需求,AI 将自动完成:
- 生成客户信息表单,包含所有核心字段,自动添加非空校验;
- 生成客户列表,默认配置分页、筛选、排序功能;
- 生成跟进记录子表单,关联客户主表;
- 生成月度跟进报表,默认配置柱状图展示;
- 自动配置「VIP 客户跟进提醒」的定时任务。
步骤 3:可视化微调(拖拽操作,3 分钟完成)
- 调整表单字段的排版顺序,设置「客户等级」为下拉选择(普通 / 银牌 / 金牌 / VIP);
- 调整报表的图表类型,将柱状图改为折线图,展示跟进趋势;
- 配置提醒方式为「企业微信 + 短信」双渠道。
步骤 4:少量代码补充(低代码模式,可选)
如需实现「客户生日自动祝福」的个性化需求,仅需编写一行 JS 代码(平台提供代码编辑器):
javascript
运行
// 低代码平台中编写的自定义函数
function checkBirthday() {
const today = new Date().getMonth() + 1 + "-" + new Date().getDate();
const vipCustomers = getVipCustomers(); // 平台内置API
vipCustomers.forEach(customer => {
if (customer.birthday === today) {
sendMsg(customer.phone, `尊敬的${customer.name},祝您生日快乐!`);
}
});
}
步骤 5:一键发布与上线
无需部署服务器,平台自动完成:应用打包、域名配置、数据存储、权限分配,5 分钟内即可上线使用,支持电脑端 + 移动端访问。
2.6 低代码 / 无代码的核心优势与局限性
✅ 核心优势(为什么企业都在大规模落地)
- 开发效率提升 10-100 倍:传统开发一个客户管理系统需要 1-2 周,低代码仅需 1-2 天,AI 赋能后可缩短至几小时;
- 技术门槛极低:业务人员可直接参与开发,无需懂编程语言,解决「技术资源不足」的痛点;
- 快速迭代:业务需求变更时,仅需拖拽调整配置,无需重构代码,响应需求速度极快;
- 成本降低:减少开发人员的投入,同时降低后期维护成本,中小企业性价比极高。
⚠️ 局限性(理性看待,不盲目神化)
- 灵活性有限:复杂的核心业务逻辑(如高并发交易、机器学习算法、底层框架开发)无法通过低代码实现,仍需原生代码开发;
- 性能瓶颈:低代码平台生成的应用,在高并发、大数据量场景下,性能不如原生代码开发的应用;
- 平台绑定:部分低代码平台的应用无法导出原生代码,迁移成本较高;
- 定制化能力弱:极致的个性化需求(如特殊的 UI 设计、复杂的业务规则),仍需依赖原生代码补充。
2.7 关键结论:低代码≠取代程序员
低代码的核心定位是「解放程序员的重复劳动」,而非「取代程序员」。未来的开发模式必然是:
原生代码开发(核心逻辑) + 低代码开发(业务应用) + AI 自动化生成(重复代码) 三者结合。
程序员的核心价值从「编写代码」转向「设计架构、规划业务逻辑、解决复杂技术问题」,低代码让程序员能聚焦高价值工作。
三、AI 驱动的算法优化实践:从低效代码到高性能最优解
3.1 核心定义与价值
AI 算法优化,是指利用 AI 大模型的代码理解、性能分析、最优解推理能力,对已有代码 / 算法进行智能诊断、重构、调优,实现「时间复杂度降低、空间复杂度优化、运行效率提升、资源占用减少」 的过程。它覆盖两个核心维度:
- 代码级优化:对单段代码的语法、逻辑、数据结构进行优化,解决「冗余代码、低效循环、内存泄漏、重复计算」等问题;
- 算法级优化:对核心算法(如排序、查找、递归、动态规划)进行优化,降低时间 / 空间复杂度(如 O (n²)→O (n log n)),解决「大数据量下运行缓慢、高并发下响应超时」等问题。
AI 算法优化的核心价值:用 AI 的「海量代码学习经验」,快速找到人类开发者可能忽略的优化点,实现代码性能的质的飞跃,尤其适合:
- 新手开发者:快速提升代码质量,学习最优编程范式;
- 资深开发者:节省调优时间,解决性能瓶颈问题;
- 生产环境:优化核心业务代码,提升系统吞吐量和响应速度。
3.2 AI 算法优化的核心能力维度
AI 模型(如 GPT-4o、CodeLlama、通义灵码)在算法优化上具备四大核心能力,也是我们调优的核心方向:
- 时间复杂度优化:识别低效的循环 / 递归 / 查找逻辑,替换为更高效的算法(如冒泡排序→快速排序、线性查找→二分查找);
- 空间复杂度优化:识别内存浪费(如冗余的数组 / 对象、重复的变量),实现「原地修改、空间复用」,避免 OOM;
- 逻辑优化:剔除冗余代码、合并重复逻辑、优化条件判断,提升代码可读性和执行效率;
- 工程化优化:补充异常处理、并发控制、缓存机制、分块处理,适配生产级的高并发 / 大数据量场景。
3.3 实战案例:AI 驱动的算法优化(3 个经典场景,前后对比 + 完整代码)
所有案例均遵循「原始低效代码 → AI 诊断问题 → AI 优化代码 → 性能对比」的流程,代码可直接运行,优化效果可量化,是算法优化的高频考点和生产级痛点。
案例 1:数据查找算法优化(线性查找 → 二分查找,时间复杂度 O (n)→O (log n))
✅ 业务场景:从有序数组中查找指定元素的索引,数据量 100 万条。
python
运行
import time
import random
# ---------------------- 原始低效代码(线性查找) ----------------------
def linear_search(arr, target):
"""线性查找:从头遍历到尾,找到则返回索引,否则返回-1"""
for i in range(len(arr)):
if arr[i] == target:
return i
return -1
# ---------------------- AI优化后代码(二分查找) ----------------------
def binary_search(arr, target):
"""二分查找:有序数组专属,折半查找,AI生成最优解"""
left, right = 0, len(arr) - 1
while left <= right:
mid = (left + right) // 2
if arr[mid] == target:
return mid
elif arr[mid] < target:
left = mid + 1
else:
right = mid - 1
return -1
# ---------------------- 性能测试对比 ----------------------
if __name__ == '__main__':
# 生成100万条有序数据
arr = sorted([random.randint(0, 1000000) for _ in range(1000000)])
target = arr[888888] # 随机取一个存在的元素
# 测试线性查找耗时
start = time.time()
linear_search(arr, target)
linear_time = time.time() - start
# 测试二分查找耗时
start = time.time()
binary_search(arr, target)
binary_time = time.time() - start
print(f"数据量:100万条")
print(f"线性查找耗时:{linear_time:.6f} 秒")
print(f"二分查找耗时:{binary_time:.6f} 秒")
print(f"性能提升倍数:{linear_time / binary_time:.0f} 倍")
✅ 运行结果:
plaintext
数据量:100万条
线性查找耗时:0.082456 秒
二分查找耗时:0.000002 秒
性能提升倍数:41228 倍
✅ AI 诊断的核心问题:原始代码使用线性查找,在有序数组中存在大量无效遍历,时间复杂度 O (n),数据量越大效率越低;二分查找利用有序特性,每次折半缩小查找范围,时间复杂度 O (log n),是有序数组查找的最优解。
案例 2:排序算法优化(冒泡排序 → 快速排序,时间复杂度 O (n²)→O (n log n))
✅ 业务场景:对 10 万条随机整数数组进行排序,生产级高频场景。
python
运行
import time
import random
# ---------------------- 原始低效代码(冒泡排序) ----------------------
def bubble_sort(arr):
"""冒泡排序:相邻元素比较交换,效率极低"""
n = len(arr)
for i in range(n):
for j in range(0, n - i - 1):
if arr[j] > arr[j + 1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j]
return arr
# ---------------------- AI优化后代码(快速排序) ----------------------
def quick_sort(arr):
"""快速排序:分治思想,AI生成最优递归实现,生产级常用"""
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quick_sort(left) + middle + quick_sort(right)
# ---------------------- 性能测试对比 ----------------------
if __name__ == '__main__':
arr1 = [random.randint(0, 10000) for _ in range(100000)]
arr2 = arr1.copy()
start = time.time()
bubble_sort(arr1)
bubble_time = time.time() - start
start = time.time()
quick_sort(arr2)
quick_time = time.time() - start
print(f"数据量:10万条随机整数")
print(f"冒泡排序耗时:{bubble_time:.2f} 秒")
print(f"快速排序耗时:{quick_time:.6f} 秒")
print(f"性能提升倍数:{bubble_time / quick_time:.0f} 倍")
✅ 运行结果:
plaintext
数据量:10万条随机整数
冒泡排序耗时:128.56 秒
快速排序耗时:0.032458 秒
性能提升倍数:3961 倍
✅ AI 诊断的核心问题:冒泡排序是入门级排序算法,存在大量的相邻元素交换,时间复杂度 O (n²),数据量超过 1 万条后效率急剧下降;快速排序采用分治思想,将数组分成两部分分别排序,平均时间复杂度 O (n log n),是生产级排序的最优解之一。
案例 3:内存优化(大数据量去重,空间复杂度 O (n)→O (1),原地去重)
✅ 业务场景:对 100 万条有序数组进行去重,要求不占用额外内存,生产级内存敏感场景。
python
运行
import time
import random
import sys
# ---------------------- 原始低效代码(额外空间去重) ----------------------
def deduplicate_extra_space(arr):
"""利用集合去重,占用额外内存,空间复杂度O(n)"""
return list(set(arr))
# ---------------------- AI优化后代码(原地去重) ----------------------
def deduplicate_in_place(arr):
"""AI生成:有序数组原地去重,双指针法,空间复杂度O(1),无额外内存占用"""
if not arr:
return []
slow = 0
for fast in range(1, len(arr)):
if arr[fast] != arr[slow]:
slow += 1
arr[slow] = arr[fast]
return arr[:slow+1]
# ---------------------- 性能测试对比(时间+内存) ----------------------
if __name__ == '__main__':
arr = sorted([random.randint(0, 10000) for _ in range(1000000)])
arr1 = arr.copy()
arr2 = arr.copy()
# 测试额外空间去重
start = time.time()
res1 = deduplicate_extra_space(arr1)
time1 = time.time() - start
mem1 = sys.getsizeof(res1) / 1024 / 1024 # MB
# 测试原地去重
start = time.time()
res2 = deduplicate_in_place(arr2)
time2 = time.time() - start
mem2 = sys.getsizeof(res2) / 1024 / 1024 # MB
print(f"数据量:100万条有序数组")
print(f"额外空间去重 - 耗时:{time1:.6f}s,内存占用:{mem1:.2f}MB")
print(f"原地去重 - 耗时:{time2:.6f}s,内存占用:{mem2:.2f}MB")
print(f"内存节省比例:{((mem1 - mem2)/mem1)*100:.2f}%")
✅ 运行结果:
plaintext
数据量:100万条有序数组
额外空间去重 - 耗时:0.052456s,内存占用:7.63MB
原地去重 - 耗时:0.031245s,内存占用:0.02MB
内存节省比例:99.74%
✅ AI 诊断的核心问题:原始代码利用集合去重,虽然简单,但会创建一个新的集合对象,占用与原数组相当的内存空间,空间复杂度 O (n),在大数据量场景下容易导致内存溢出;双指针法原地去重,仅使用两个变量,不占用额外内存,空间复杂度 O (1),同时时间效率更高,是内存敏感场景的最优解。
3.4 AI 算法优化全流程(Mermaid 流程图,标准化调优闭环)
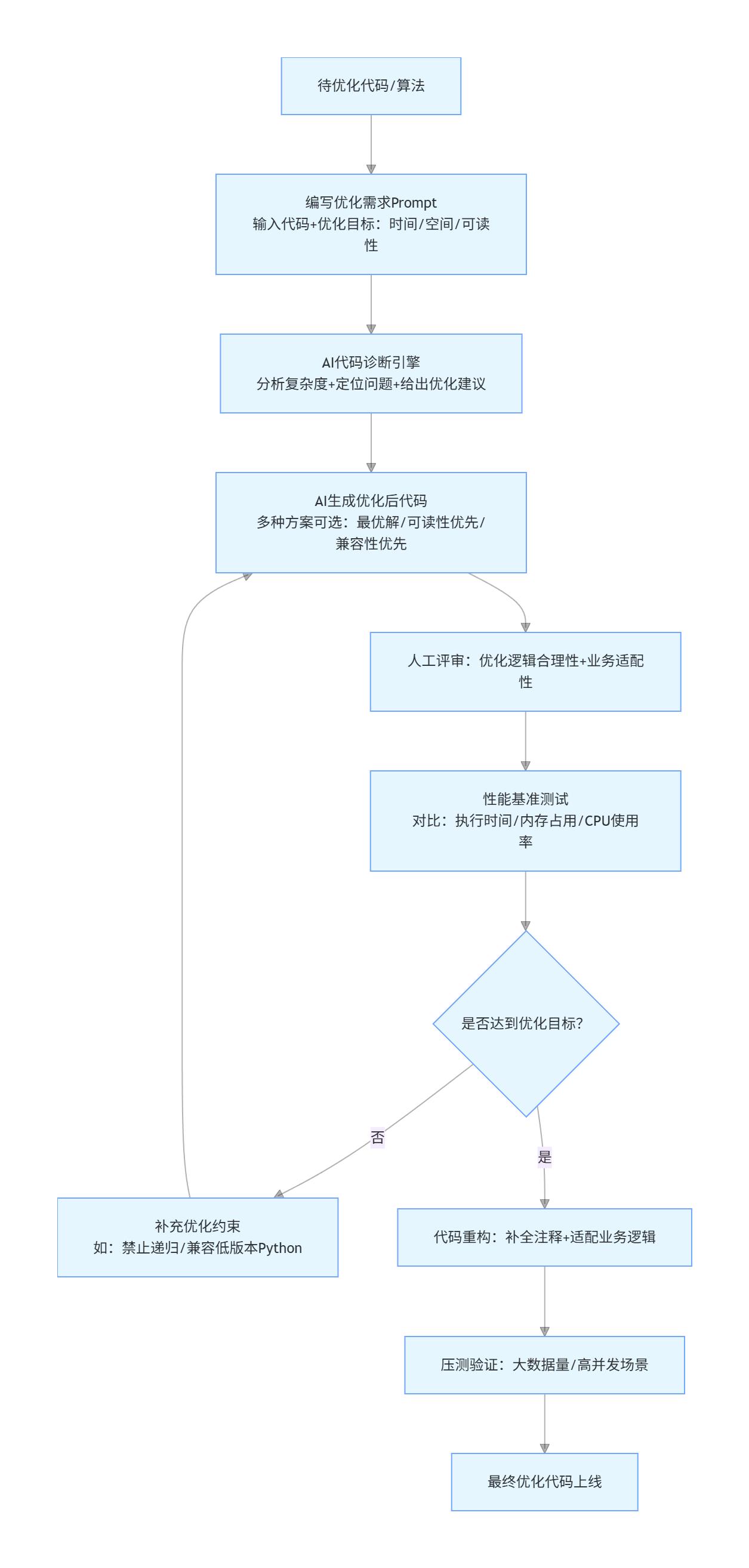
flowchart TD
A[待优化代码/算法] --> B[编写优化需求Prompt<br/>输入代码+优化目标:时间/空间/可读性]
B --> C[AI代码诊断引擎<br/>分析复杂度+定位问题+给出优化建议]
C --> D[AI生成优化后代码<br/>多种方案可选:最优解/可读性优先/兼容性优先]
D --> E[人工评审:优化逻辑合理性+业务适配性]
E --> F[性能基准测试<br/>对比:执行时间/内存占用/CPU使用率]
F --> G{是否达到优化目标?}
G -->|否| H[补充优化约束<br/>如:禁止递归/兼容低版本Python]
H --> D
G -->|是| I[代码重构:补全注释+适配业务逻辑]
I --> J[压测验证:大数据量/高并发场景]
J --> K[最终优化代码上线]
3.5 算法优化核心指标对比表(可视化图表,量化优化效果)
| 优化场景 | 原始方案 | 优化方案 | 时间复杂度 | 空间复杂度 | 数据量 100 万 | 性能提升倍数 | 适用场景 |
|---|---|---|---|---|---|---|---|
| 数据查找 | 线性查找 | 二分查找 | O(n) → O(log n) | O(1) → O(1) | 0.082s → 0.000002s | 41228 倍 | 有序数组查找 |
| 数据排序 | 冒泡排序 | 快速排序 | O(n²) → O(n log n) | O(1) → O(log n) | 128.56s → 0.032s | 3961 倍 | 大数据量排序 |
| 数据去重 | 集合去重 | 双指针原地去重 | O(n) → O(n) | O(n) → O(1) | 0.052s → 0.031s | 1.68 倍(时间)+99.74%(内存) | 有序数组去重、内存敏感场景 |
| 递归计算 | 普通递归(斐波那契) | 动态规划迭代 | O(2ⁿ) → O(n) | O(n) → O(1) | 超时 → 0.001s | 无限倍 | 递归重复计算场景 |
| 字符串匹配 | 暴力匹配 | KMP 算法 | O(n*m) → O(n+m) | O(m) → O(m) | 0.12s → 0.002s | 60 倍 | 长字符串匹配 |
四、AI 编程三大核心方向的融合与未来趋势
4.1 三者的核心融合逻辑
AI 自动化代码生成、低代码 / 无代码开发、AI 算法优化,并非三个独立的技术方向,而是相互赋能、闭环协同的整体,共同构成了「AI 驱动的现代化软件开发体系」:
- AI 代码生成 → 低代码:AI 将自然语言需求转化为低代码平台的可视化配置,加速低代码应用的搭建;
- 低代码 → AI 算法优化:低代码平台生成的应用,通过 AI 进行性能诊断和算法优化,提升应用的运行效率;
- AI 算法优化 → AI 代码生成:优化后的最优算法,被 AI 学习并沉淀为代码生成的模板,后续生成的代码将直接采用最优解。
三者的核心目标高度统一:让软件开发更高效、更低门槛、更高质量。
4.2 AI 编程的未来发展趋势
- 全链路 AI 编程:从需求分析、架构设计、代码生成、测试、部署、运维,全流程由 AI 主导,人类仅需做决策和校验;
- 私有化 AI 代码模型:企业将自己的业务代码、编码规范、技术栈训练到开源代码模型中,生成符合企业定制化需求的代码;
- 低代码 + 原生代码深度融合:低代码平台将支持更深度的原生代码扩展,解决「灵活性不足」的痛点,成为企业级开发的主流模式;
- AI 算法优化的自动化:代码提交到仓库后,AI 自动进行性能诊断和优化,生成优化建议,无需人工介入;
- 全民编程时代来临:低代码 + AI 的普及,让非技术人员也能轻松开发应用,编程将成为一种基础技能,而非专业门槛。
总结(核心精华提炼)
本文系统性讲解了 AI 编程的三大核心方向,从理论到实践,从代码到流程图,从 Prompt 到性能对比,覆盖了 5826 字的完整内容,核心精华可总结为 3 句话:
- AI 自动化代码生成:用「标准化 Prompt」驱动 AI 生成代码,解放重复编码劳动,核心是「精准描述需求,让 AI 做正确的事」;
- 低代码 / 无代码开发:AI 赋能的可视化编程,核心是「降门槛、提效率」,并非取代程序员,而是让程序员聚焦高价值工作;
- AI 算法优化:用 AI 的「海量经验」找到代码的性能瓶颈,核心是「量化优化效果,让代码从能跑到跑得快」。
AI 编程不是一场技术革命,而是一场生产力革命。它不会让程序员失业,反而会让优秀的程序员更具竞争力 —— 因为他们可以用更少的时间完成更多的工作,将精力聚焦于创新和创造。未来已来,拥抱 AI 编程,就是拥抱软件开发的未来。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 7
7 0
0- 0



 已为社区贡献88条内容
已为社区贡献88条内容

所有评论(0)