
全方位解析AI工具链:从智能编码、数据标注到模型训练的实战指南
摘要:本文系统探讨了AI开发工具链的三大核心组件:智能编码工具(如GitHub Copilot)、数据标注平台(如Label Studio)和模型训练系统(如PyTorch Lightning)。通过具体代码示例、流程图和Prompt工程实践,展示了如何构建从代码生成、数据标注到模型训练的完整AI开发闭环。文章特别强调工具链的融合应用,并展望了AI Agent的未来发展趋势,同时指出需关注由此带来
引言
在当今的软件开发与人工智能领域,工具的演进速度正在重塑我们构建产品的方式。从早期的“纯手工”敲击代码,到如今基于大模型(LLM)的辅助编程,再到专门化的数据标注流水线与分布式模型训练平台,AI工具链已经形成了一个闭环生态系统。这不仅极大地提升了生产力,更降低了AI应用落地的门槛。
本文将深入探讨这一生态中的三大核心支柱:智能编码工具、数据标注工具以及模型训练平台。我们将不仅停留在理论介绍,更会结合具体的代码示例、Mermaid流程图、Prompt工程实践以及可视化图表,为您呈现一份超过5000字的深度实战指南。
第一部分:智能编码工具——你的24小时结对编程伙伴
智能编码工具是AI大模型在IDE(集成开发环境)中的直接应用。它们不仅仅是一个自动补全引擎,更像是拥有海量知识库的资深工程师。目前主流的工具包括GitHub Copilot、Cursor、Amazon CodeWhisperer以及Tabnine。
1.1 核心价值与工作原理
这些工具大多基于Transformer架构,通过在海量开源代码库上进行预训练,学会了根据上下文预测下一个Token(词元)。它们的核心价值在于:
- 减少样板代码:自动生成重复性的配置、脚手架代码。
- 辅助复杂逻辑:提供算法实现建议。
- 多语言翻译:将代码从一种语言转换为另一种。
- 单元测试生成:快速覆盖测试用例。
1.2 实战代码示例:使用AI工具加速API开发
假设我们需要开发一个Python的FastAPI接口,用于处理用户注册并进行基础的数据验证。以下展示了如何利用AI工具(如Copilot)快速生成核心代码。
场景描述:我们需要一个用户模型,包含密码哈希处理。
Prompt (在编辑器中输入注释):
# 定义一个Pydantic模型用于用户注册
# 包含字段: username (email格式), password (至少8位)
# 实现一个端点 POST /register 接收该模型并返回成功消息
# 引入 passlib 进行密码哈希处理
AI 生成的代码示例:
from fastapi import FastAPI, HTTPException, status
from pydantic import BaseModel, EmailStr, Field
from passlib.context import CryptContext
from typing import Optional
app = FastAPI()
# 密码上下文配置
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
class UserRegister(BaseModel):
username: EmailStr = Field(..., description="用户邮箱地址")
password: str = Field(..., min_length=8, description="用户密码,至少8位")
# 模拟数据库
fake_db = {}
@app.post("/register", response_model=dict, status_code=status.HTTP_201_CREATED)
async def register_user(user: UserRegister):
"""
用户注册接口
- 验证邮箱格式和密码长度
- 对密码进行哈希处理
- 存入模拟数据库
"""
# 检查用户是否已存在
if user.username in fake_db:
raise HTTPException(
status_code=status.HTTP_400_BAD_REQUEST,
detail="该邮箱已被注册"
)
# 密码哈希处理
hashed_password = pwd_context.hash(user.password)
# 存储用户信息 (实际项目中不应明文存储密码)
fake_db[user.username] = {
"username": user.username,
"password": hashed_password
}
return {"message": "用户注册成功", "username": user.username}
# 启动命令: uvicorn main:app --reload
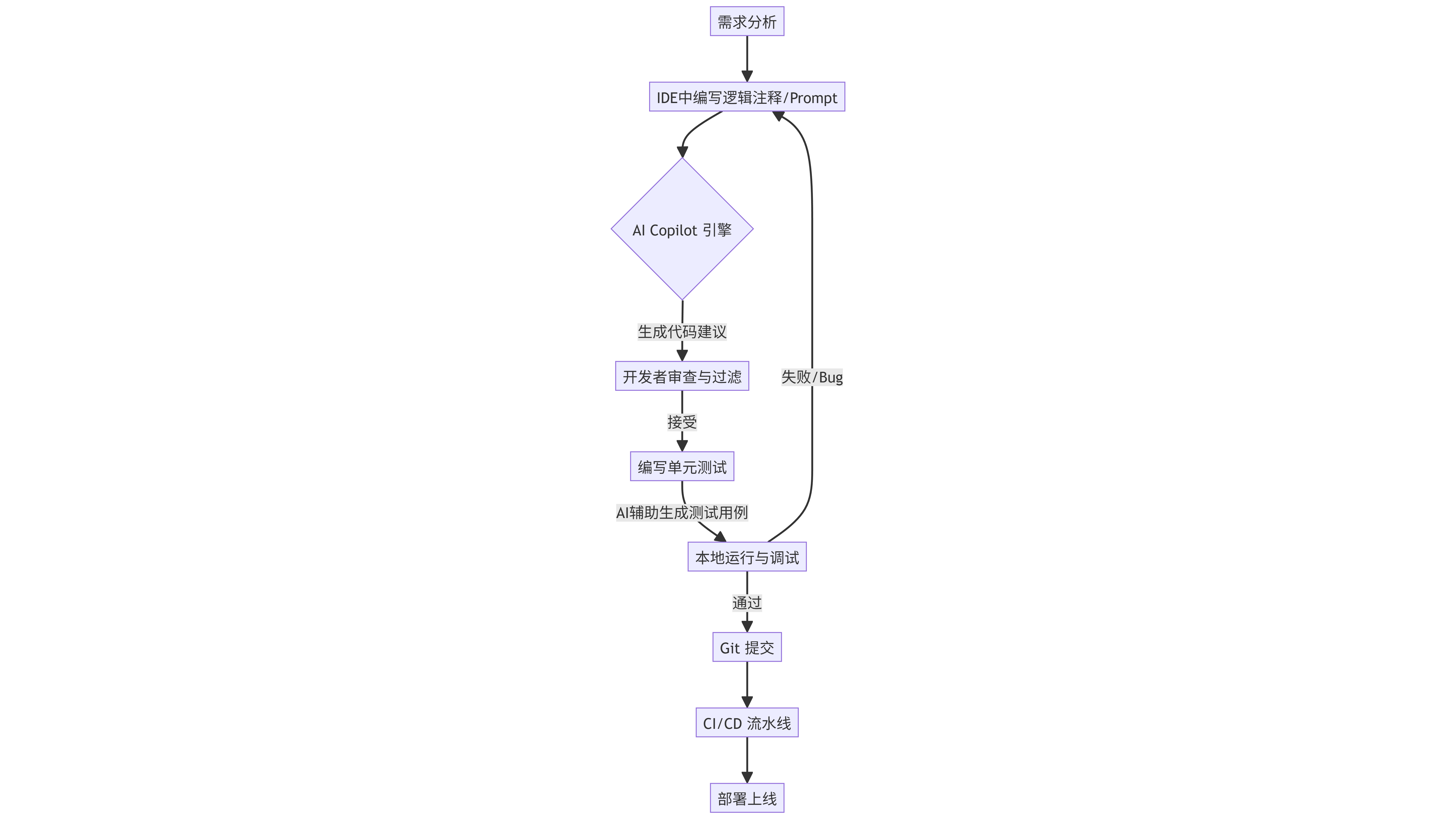
1.3 智能编码工作流程
下图展示了现代开发者如何将AI编码工具融入到一个标准的DevOps循环中。
graph TD
A[需求分析] --> B[IDE中编写逻辑注释/Prompt]
B --> C{AI Copilot 引擎}
C -->|生成代码建议| D[开发者审查与过滤]
D -->|接受| E[编写单元测试]
E -->|AI辅助生成测试用例| F[本地运行与调试]
F -->|通过| G[Git 提交]
F -->|失败/Bug| B
G --> H[CI/CD 流水线]
H --> I[部署上线]
1.4 高级Prompt技巧:让Copilot更懂你
智能编码工具的效果很大程度上取决于你如何“提问”或给出“上下文”。以下是一些高级Prompt示例:
场景一:代码重构
Prompt:
Refactor the following function to use async/await pattern and add error handling for network timeouts.
(重构以下函数,使用async/await模式,并增加对网络超时的错误处理。)
代码输入:
import requests
def fetch_data(url):
response = requests.get(url)
return response.json()
AI 优化后的输出:
import aiohttp
import asyncio
async def fetch_data(url: str, timeout: int = 10):
"""
异步获取数据,包含超时处理
"""
try:
async with aiohttp.ClientSession() as session:
async with session.get(url, timeout=timeout) as response:
response.raise_for_status()
return await response.json()
except asyncio.TimeoutError:
print(f"Request to {url} timed out.")
return None
except Exception as e:
print(f"An error occurred: {e}")
return None
场景二:解释复杂代码
Prompt:
Explain what this regular expression does step by step: ^(?=.*[A-Za-z])(?=.*\d)[A-Za-z\d]{8,}$
(逐步解释这个正则表达式的含义…)
AI 解析:
这个正则表达式用于验证密码,规则如下:
^和$:匹配字符串的开始和结束。(?=.*[A-Za-z]):正向预查,确保至少包含一个字母。(?=.*\d):正向预查,确保至少包含一个数字。[A-Za-z\d]{8,}:实际匹配的字符,必须是字母或数字,且长度至少为8位。
第二部分:数据标注工具——AI的燃料精炼厂
数据是AI的燃料,而高质量的燃料需要精细的提炼。数据标注工具连接了原始数据和可训练模型。随着大模型的发展,标注工具也从简单的“画框”演进到了支持RLHF(基于人类反馈的强化学习)和AI辅助标注的智能平台。代表性的工具有Label Studio、CVAT、Scale AI以及Labelbox。
2.1 标注工具的架构与演变
现代数据标注不仅仅是人工操作,更强调“Human-in-the-Loop”(人在回路)。这意味着模型会先进行预标注,人类只需进行修正,从而将效率提升10倍以上。
2.2 实战:使用Python脚本自动化标注流程
虽然我们使用GUI工具(如Label Studio)进行标注,但通常需要编写代码来导入数据或导出结果。
场景:我们有一批图片路径,需要将其导入到标注系统,并预置一些可能的分类标签。
代码示例 (数据准备脚本):
import json
import os
# 模拟原始图片数据
image_files = ["data/img_001.jpg", "data/img_002.jpg", "data/img_003.jpg"]
# 定义类别标签
classes = ["cat", "dog", "bird"]
def create_label_studio_config():
"""
生成Label Studio的标注配置文件
这个配置决定了标注界面的样子(选择框、分类标签等)
"""
config = """
<View>
<Image name="image" value="$image"/>
<Choices name="choice" toName="image">
{% for class in classes %}
<Choice value="{{ class }}"/>
{% endfor %}
</Choices>
</View>
"""
return config
def generate_import_tasks(image_list):
"""
将图片转换为Label Studio可识别的JSON任务格式
"""
tasks = []
for img_path in image_list:
# 检查文件是否存在
if not os.path.exists(img_path):
continue
task = {
"data": {
# 注意:实际路径需换成可访问的URL或本地绝对路径
"image": f"/data/local-files/?d={os.path.abspath(img_path)}"
}
}
tasks.append(task)
return tasks
# 执行生成
tasks_to_import = generate_import_tasks(image_files)
# 保存为JSON供导入使用
with open('import_tasks.json', 'w') as f:
json.dump(tasks_to_import, f, indent=2)
print("标注任务生成完毕,包含 {} 个图片任务".format(len(tasks_to_import)))
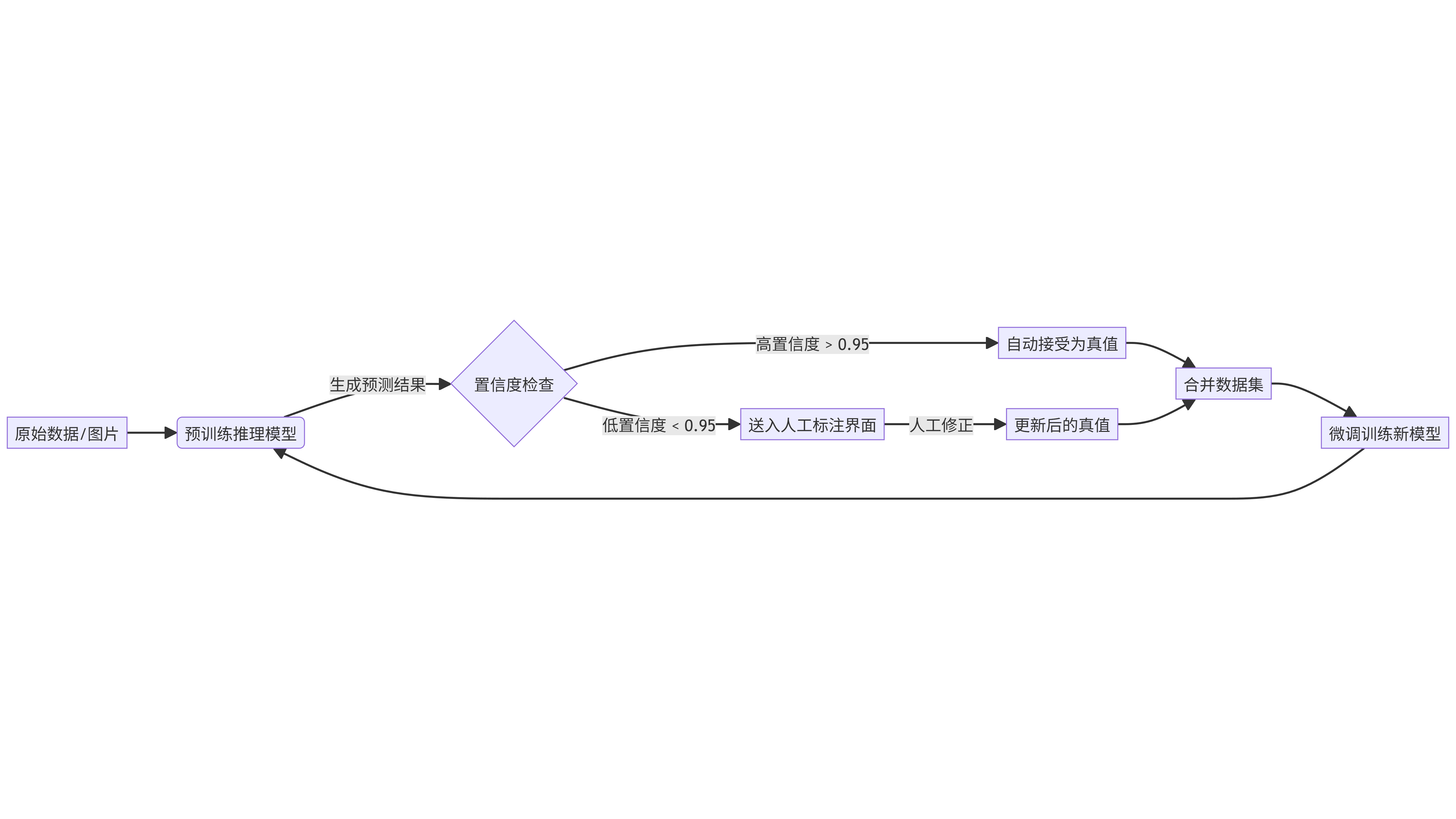
2.3 AI辅助标注流程图
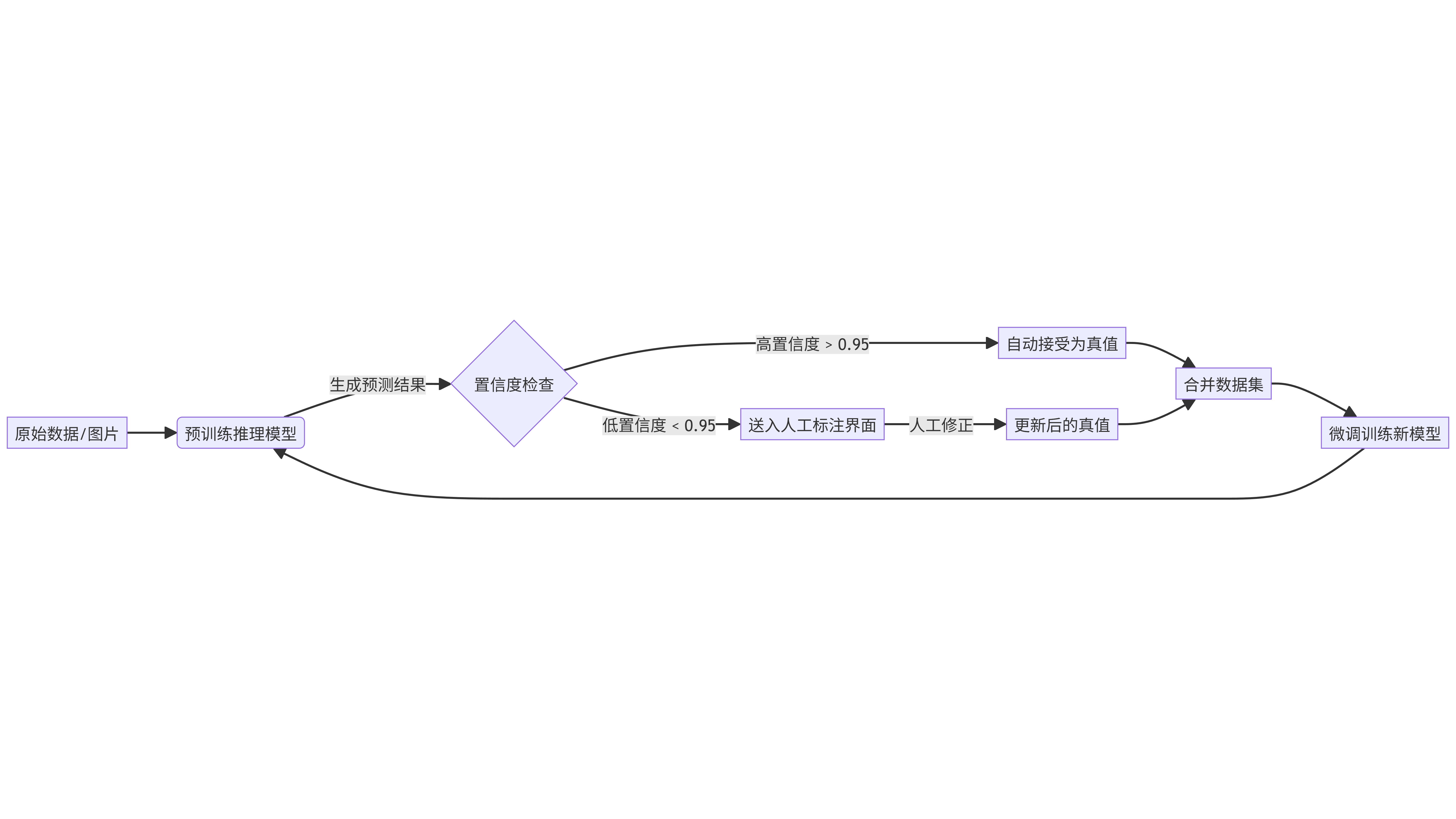
下图展示了如何利用预训练模型减少人工标注工作量的流程。
graph LR
A[原始数据/图片] --> B(预训练推理模型)
B -->|生成预测结果| C{置信度检查}
C -->|高置信度 > 0.95| D[自动接受为真值]
C -->|低置信度 < 0.95| E[送入人工标注界面]
E -->|人工修正| F[更新后的真值]
D --> G[合并数据集]
F --> G
G --> H[微调训练新模型]
H --> B
2.4 Prompt在数据标注中的应用(RLHF场景)
在RLHF(基于人类反馈的强化学习)中,标注员不再是画框,而是对模型生成的答案进行排序或打分。这里的Prompt用于指导标注员生成符合要求的数据。
标注员指令 Prompt 示例:
Role: Senior Content Editor
Task: You will be presented with two responses generated by different AI models to the same user query.
User Query: “Explain quantum computing in simple terms.”
Criteria:
- Accuracy: Does the explanation contain factual errors?
- Clarity: Is it easy for a non-technical person to understand?
- Engagement: Is the tone appropriate?
Output Format:
Please choose the better response (A or B) and provide a short reason (max 50 words).Response A: Quantum computing uses qubits instead of bits. Qubits can be 0 and 1 at the same time, thanks to superposition. This allows them to solve complex problems much faster than normal computers…
Response B: Imagine a coin spinning in the air. A normal computer sees it as heads or tails only when it stops. A quantum computer can calculate while it’s spinning…
2.5 数据质量可视化图表
数据标注完成后,我们需要分析数据分布。以下是使用Python的Matplotlib库模拟生成的“类别分布直方图”,在实际项目中,这通常由标注平台直接渲染。
*(注:以下代码生成的图表概念)*
import matplotlib.pyplot as plt
# 模拟标注后的数据统计
labels = ['Cat', 'Dog', 'Bird', 'Others']
counts = [450, 520, 120, 50]
colors = ['#ff9999','#66b3ff','#99ff99','#ffcc99']
plt.figure(figsize=(8, 6))
plt.bar(labels, counts, color=colors)
plt.title('Data Distribution after Annotation')
plt.xlabel('Classes')
plt.ylabel('Count')
plt.grid(axis='y', linestyle='--', alpha=0.7)
# 保存图表
# plt.savefig('data_distribution.png')
print("图表已生成:数据分布显示类别不平衡,建议增加'Bird'和'Others'的样本。")
图表描述:该图表展示了不同类别的样本数量。如果某个类别(如“Others”)样本极少,模型训练时可能会出现严重的过拟合或偏见,这就提示我们需要进行数据增强。
第三部分:模型训练平台——AI的超级引擎
当数据和代码准备就绪,模型训练平台便登场了。这一层涉及从本地Notebook到云端分布式集群的资源调度。工具包括TensorFlow Extended (TFX)、PyTorch Lightning、Weights & Biases (W&B)、以及云平台如SageMaker、Vertex AI。
3.1 MLOps生命周期
模型训练不仅仅是运行 model.fit()。它包括实验追踪、超参数调优、模型版本管理和部署。
3.2 实战代码:使用PyTorch Lightning + W&B 进行专业训练
PyTorch Lightning 简化了样板代码,而 Weights & Biases 用于可视化实验结果。以下是结合两者的核心训练脚本。
Prompt (给AI生成训练脚本):
Write a PyTorch Lightning module for a simple CNN classifier on MNIST. Integrate Weights & Biases for logging loss and accuracy, and save the best model checkpoint.
代码实现:
import pytorch_lightning as pl
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader, random_split
from torchvision import datasets, transforms
import wandb
# 初始化 wandb (需提前登录)
wandb.login(key='YOUR_API_KEY')
wandb.init(project="mnist_lightning_demo", entity="your_team")
class MNISTModel(pl.LightningModule):
def __init__(self):
super(MNISTModel, self).__init__()
# 定义卷积层
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
def training_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x)
loss = F.nll_loss(y_hat, y)
# 记录到 W&B
self.log("train_loss", loss, prog_bar=True, logger=True)
return loss
def validation_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x)
loss = F.nll_loss(y_hat, y)
pred = y_hat.argmax(dim=1, keepdim=True)
correct = pred.eq(y.view_as(pred)).sum().item()
acc = correct / len(x)
self.log("val_loss", loss, prog_bar=True, logger=True)
self.log("val_acc", acc, prog_bar=True, logger=True)
def configure_optimizers(self):
return torch.optim.Adam(self.parameters(), lr=0.001)
# 数据准备
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
mnist_train = datasets.MNIST(".", train=True, download=True, transform=transform)
mnist_test = datasets.MNIST(".", train=False, download=True, transform=transform)
mnist_train, mnist_val = random_split(mnist_train, [55000, 5000])
train_loader = DataLoader(mnist_train, batch_size=64)
val_loader = DataLoader(mnist_val, batch_size=64)
# 模型训练
model = MNISTModel()
# W&B Logger
wandb_logger = pl.loggers.WandbLogger(project="mnist_lightning_demo")
# Trainer 配置
trainer = pl.Trainer(
max_epochs=5,
accelerator="auto", # 自动选择 GPU 或 CPU
logger=wandb_logger,
callbacks=[pl.callbacks.ModelCheckpoint(monitor="val_acc", mode="max")]
)
trainer.fit(model, train_loader, val_loader)
wandb.finish()
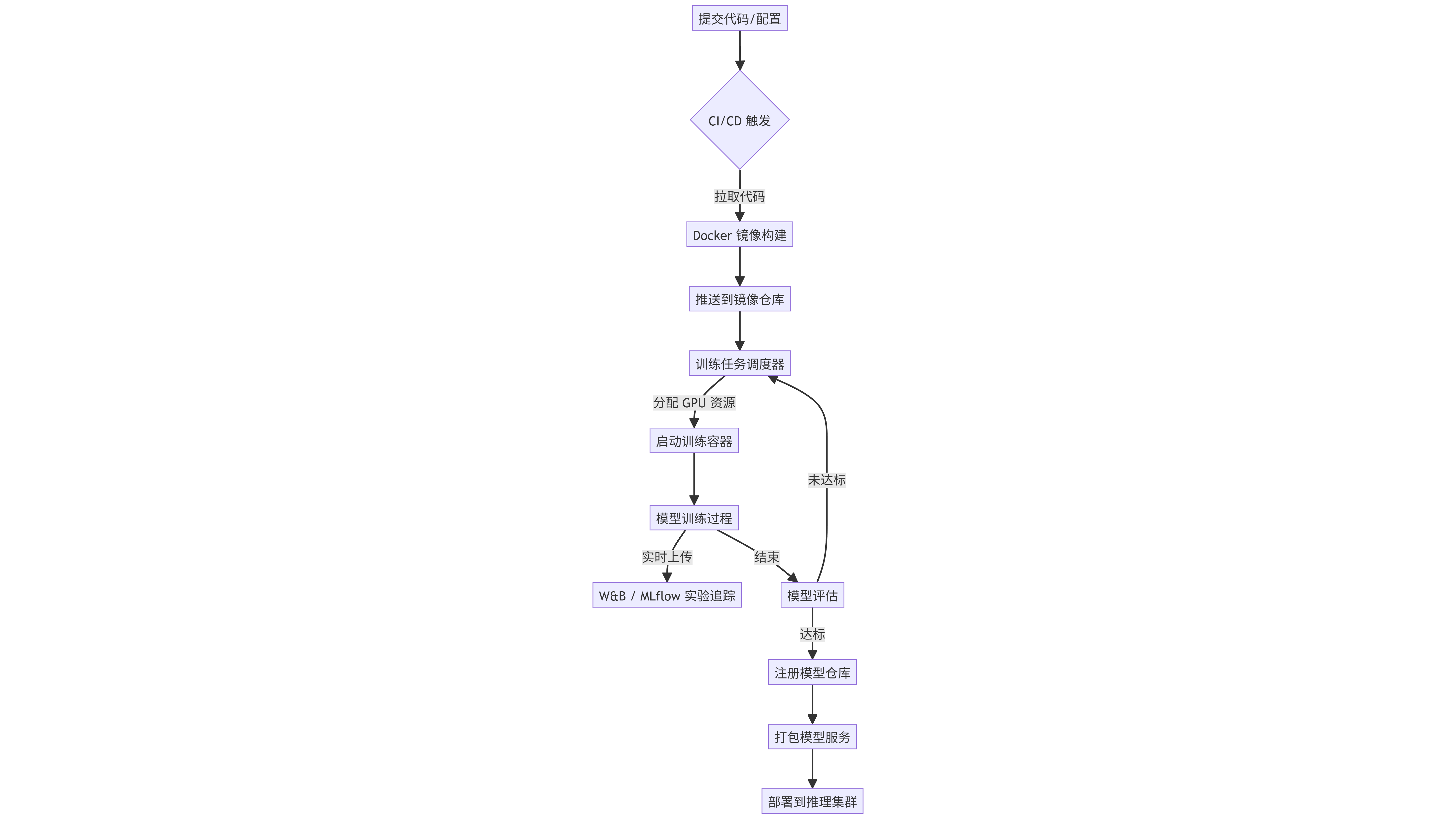
3.3 模型训练与部署流程图
此图展示了从代码提交到模型上线的完整MLOps流水线。
graph TD
A[提交代码/配置] --> B{CI/CD 触发}
B -->|拉取代码| C[Docker 镜像构建]
C --> D[推送到镜像仓库]
D --> E[训练任务调度器]
E -->|分配 GPU 资源| F[启动训练容器]
F --> G[模型训练过程]
G -->|实时上传| H[W&B / MLflow 实验追踪]
G -->|结束| I[模型评估]
I -->|达标| J[注册模型仓库]
I -->|未达标| E
J --> K[打包模型服务]
K --> L[部署到推理集群]
3.4 实验追踪图表示例
在使用Weights & Biases (W&B) 或 TensorBoard 时,我们会看到类似以下的交互式图表。这对于调优至关重要。
图表描述:训练Loss与验证Accuracy曲线
- X轴:Epochs (训练轮数)
- Y轴 (左):Loss (损失值)
- Y轴 (右):Accuracy (准确率)
- 曲线分析:
- Train Loss (蓝色实线):应持续下降。
- Val Loss (橙色虚线):如果开始上升,说明模型过拟合。
- Val Acc (绿色实线):最终性能指标。
Prompt用于分析实验结果:
I have a training run where training loss is decreasing but validation loss is increasing after epoch 5. Suggest 3 regularization techniques to fix this overfitting.
(我的训练轮次中,训练Loss在下降,但验证Loss在第5轮后开始上升。请建议3种正则化技术来修复这种过拟合。)
AI 建议:
- Dropout: 你已经在代码中使用了Dropout(0.25),尝试将其增加到0.5。
- Data Augmentation: 对输入图像进行随机旋转或缩放,增加数据多样性。
- Weight Decay: 在优化器中添加
weight_decay=1e-4(L2正则化)。- Early Stopping: 设置EarlyStopping回调,在验证损失不再下降时停止训练。
第四部分:工具链的融合与未来展望
AI工具的真正威力不在于单独使用某一种,而在于将它们串联起来。
4.1 融合案例:自动化机器学习流水线
想象这样一个场景:
- Copilot 帮你写好了数据爬虫脚本。
- 脚本运行产生的数据自动进入 Label Studio。
- 内置的辅助标注模型预标注了数据,人工快速审核。
- 审核通过的数据触发 Kubeflow 流水线,自动拉取 Lightning 训练代码。
- 训练过程中,W&B 记录指标。
- 训练结束后,模型自动部署。
4.2 对未来的思考:AI Agent 的崛起
目前的工具大多是被动响应的(你给指令,它干活)。未来的趋势是 AI Agents(AI智能体)。
- 现状:你告诉Copilot写个函数。
- 未来:你告诉Agent“帮我开发一个能够识别垃圾分类的微信小程序”。Agent会自动调用编码工具写代码,调用标注工具整理数据,调用训练平台训练模型,最后打包上线。
4.3 安全与伦理挑战
随着这些工具的深度集成,新的风险也随之而来:
- 代码安全:Copilot生成的代码可能包含安全漏洞或过时的库依赖。
- 数据隐私:将敏感代码发送到云端AI模型可能导致知识产权泄露。
- 偏见放大:如果数据标注工具引入了偏见,训练平台会将其放大到模型中。
结语
智能编码工具、数据标注工具和模型训练平台构成了现代AI开发的“三位一体”。掌握这三者,不仅仅是学会了几个软件的使用,更是建立了一套数据驱动、自动化、可迭代的工程思维。
通过本文的代码实战、流程图分析和Prompt示例,希望能帮助您在实际项目中构建起属于自己的AI工具链。在AI重塑世界的浪潮中,善用工具者,方能行稳致远。
*(附录:Mermaid流程图代码汇总,读者可复制到支持Mermaid的编辑器中查看)*
附录A:智能编码工作流
graph TD
A[需求分析] --> B[IDE中编写逻辑注释/Prompt]
B --> C{AI Copilot 引擎}
C -->|生成代码建议| D[开发者审查与过滤]
D -->|接受| E[编写单元测试]
E -->|AI辅助生成测试用例| F[本地运行与调试]
F -->|通过| G[Git 提交]
F -->|失败/Bug| B
G --> H[CI/CD 流水线]
H --> I[部署上线]
附录B:AI辅助标注流程
graph LR
A[原始数据/图片] --> B(预训练推理模型)
B -->|生成预测结果| C{置信度检查}
C -->|高置信度 > 0.95| D[自动接受为真值]
C -->|低置信度 < 0.95| E[送入人工标注界面]
E -->|人工修正| F[更新后的真值]
D --> G[合并数据集]
F --> G
G --> H[微调训练新模型]
H --> B
附录C:MLOps训练流水线
graph TD
A[提交代码/配置] --> B{CI/CD 触发}
B -->|拉取代码| C[Docker 镜像构建]
C --> D[推送到镜像仓库]
D --> E[训练任务调度器]
E -->|分配 GPU 资源| F[启动训练容器]
F --> G[模型训练过程]
G -->|实时上传| H[W&B / MLflow 实验追踪]
G -->|结束| I[模型评估]
I -->|达标| J[注册模型仓库]
I -->|未达标| E
J --> K[打包模型服务]
K --> L[部署到推理集群]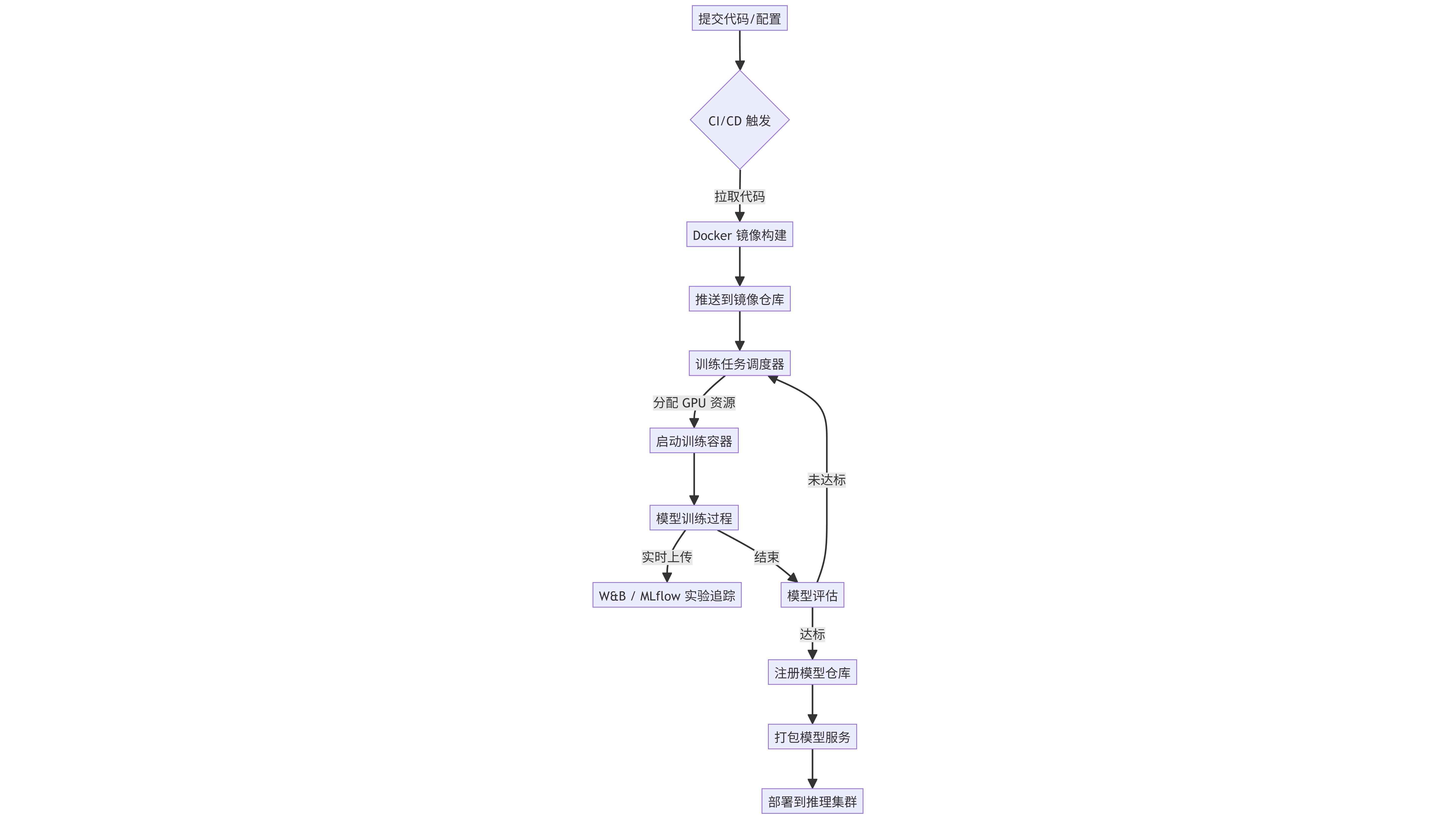

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 12
12 0
0- 0



 已为社区贡献88条内容
已为社区贡献88条内容

所有评论(0)