
AI驱动的开发工具生态系统:从编码辅助到模型部署的全流程解析
本文系统介绍了三类核心AI开发工具:智能编码工具(如GitHub Copilot)、数据标注平台(如Label Studio)和模型训练系统(如TensorFlow Extended)。通过具体示例展示了这些工具如何协同构建现代AI开发流水线,包括代码生成、数据标注、模型训练到部署的全过程。文章还提供了工具选型建议和最佳实践,强调数据质量、实验可复现性和版本控制的重要性。最后展望了AI工具向多模态
人工智能正在重塑软件开发的每个环节,从代码生成到模型训练再到部署运维。本文将系统剖析三大类核心AI开发工具——智能编码工具、数据标注平台和模型训练系统,通过具体代码示例、流程图解和实战Prompt,展示它们如何协同工作构建现代AI开发流水线。我们将深入探讨GitHub Copilot的代码生成机制、Label Studio的数据标注流程、以及TensorFlow Extended的模型训练架构,最终呈现一个完整的AI应用开发闭环。
一、智能编码工具:重新定义编程范式
智能编码工具通过理解上下文和意图,将开发者从重复性工作中解放出来,同时提供代码质量和安全性保障。这类工具正从简单的代码补全进化为具备理解复杂项目结构和业务逻辑的"副驾驶"角色。
GitHub Copilot:AI驱动的编码助手
GitHub Copilot由OpenAI与GitHub联合开发,基于GPT系列模型构建,能够根据上下文生成代码建议、完整函数甚至整个文件。其核心优势在于理解自然语言描述和代码上下文,并生成符合项目风格的代码。
工作原理流程图:
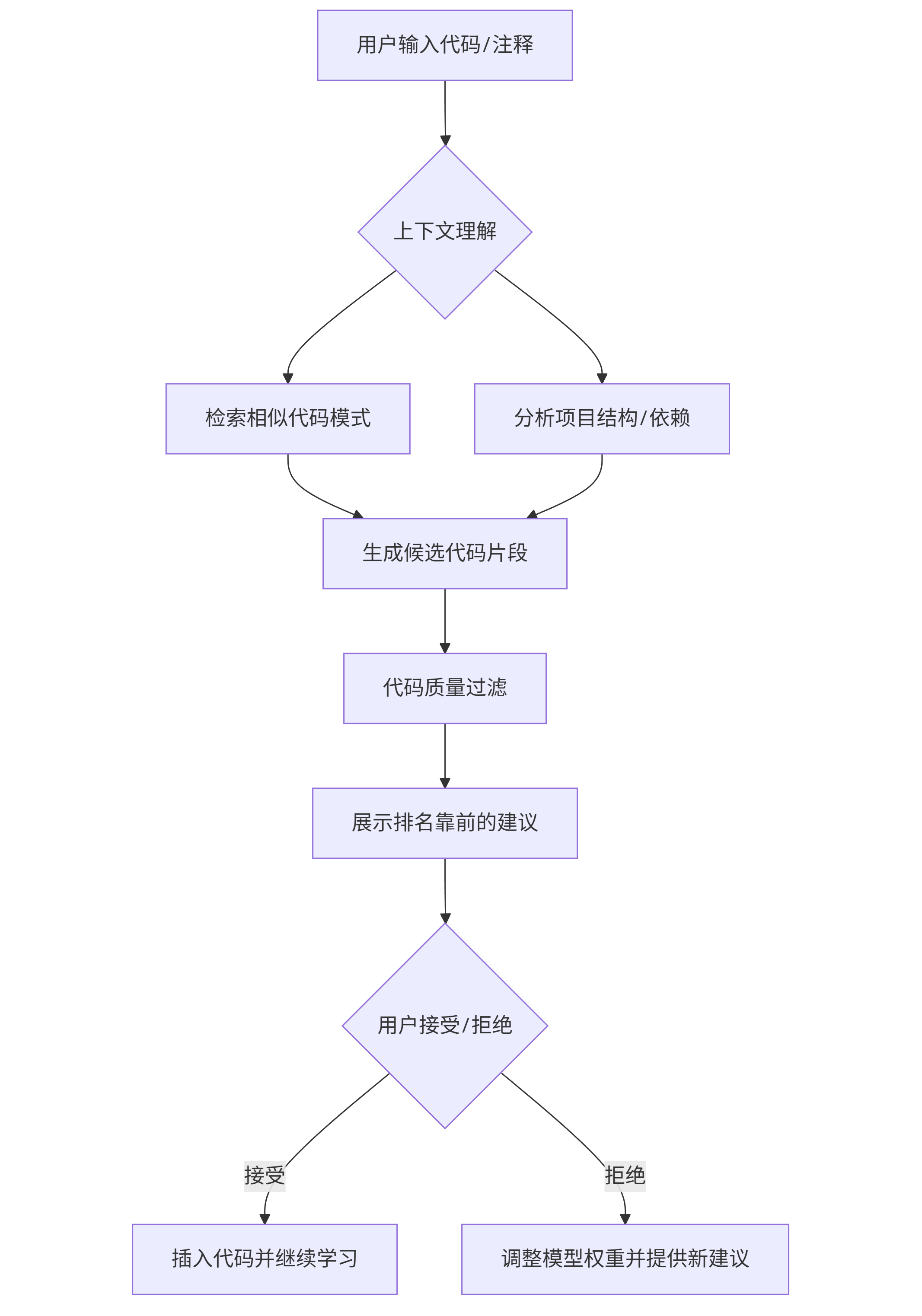
graph TD A[用户输入代码/注释] --> B{上下文理解} B --> C[检索相似代码模式] B --> D[分析项目结构/依赖] C --> E[生成候选代码片段] D --> E E --> F[代码质量过滤] F --> G[展示排名靠前的建议] G --> H{用户接受/拒绝} H -->|接受| I[插入代码并继续学习] H -->|拒绝| J[调整模型权重并提供新建议]
实战代码生成示例:
假设我们需要实现一个处理用户数据的函数,只需输入注释:
# 函数功能:从JSON文件加载用户数据,验证邮箱格式,过滤活跃用户 # 参数:file_path - JSON文件路径 # 返回:活跃用户列表,每个用户包含id、name和email字段
Copilot会自动生成如下代码:
import json import re from typing import List, Dict def load_and_filter_active_users(file_path: str) -> List[Dict]: """ 从JSON文件加载用户数据,验证邮箱格式,过滤活跃用户 Args: file_path: JSON文件路径 Returns: 活跃用户列表,每个用户包含id、name和email字段 """ # 邮箱验证正则表达式 EMAIL_PATTERN = r'^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$' try: # 加载JSON数据 with open(file_path, 'r', encoding='utf-8') as f: users = json.load(f) # 验证数据结构 if not isinstance(users, list): raise ValueError("JSON文件内容必须是用户对象的数组") active_users = [] for user in users: # 检查必要字段 required_fields = ['id', 'name', 'email', 'is_active'] if not all(field in user for field in required_fields): continue # 验证邮箱格式 if not re.match(EMAIL_PATTERN, user['email']): continue # 过滤活跃用户 if user.get('is_active', False): # 只保留需要的字段 filtered_user = { 'id': user['id'], 'name': user['name'], 'email': user['email'] } active_users.append(filtered_user) return active_users except FileNotFoundError: raise Exception(f"文件 {file_path} 不存在") except json.JSONDecodeError: raise Exception(f"文件 {file_path} 不是有效的JSON格式")
优化Copilot输出的Prompt策略:
| Prompt类型 | 示例 | 效果 |
|---|---|---|
| 详细注释引导 | # 使用快速排序算法对整数列表进行排序,要求时间复杂度O(n log n),空间复杂度O(log n) | 生成更符合特定算法要求的代码 |
| 风格约束 | # 编写JavaScript函数,遵循Airbnb编码规范,使用ES6+特性 | 生成符合特定代码规范的输出 |
| 错误处理要求 | # 实现文件读取功能,包含完整的错误处理:文件不存在、权限错误、格式错误 | 生成健壮的异常处理代码 |
| 性能要求 | # 优化以下Python代码,减少内存使用,处理100万行数据时内存占用不超过100MB | 生成更高效的代码实现 |
Copilot使用技巧:
- 增量开发:先编写函数骨架和注释,再逐步细化实现
- 接受后调整:接受建议后立即重构,使其更符合项目规范
- 多样化提示:尝试不同描述方式获取多种实现方案
- 结合文档:为复杂逻辑添加详细文档,Copilot会生成更贴合需求的代码
Tabnine:团队级智能编码助手
Tabnine与Copilot类似但更注重团队协作和私有代码库支持。它通过学习团队代码风格和最佳实践,生成符合项目特定规范的代码。
配置示例:
// .tabnine/settings.json { "model": "team", "max_completions": 5, "language_settings": { "python": { "indentation": " ", "prefer_type_hints": true, "max_line_length": 120 }, "javascript": { "prefer_const": true, "es_version": "es2020", "semicolons": "always" } }, "exclude_patterns": [ "node_modules/**", "venv/**" ] }
团队知识库训练流程:

graph LR A[私有代码库] --> B[代码清洗与去重] B --> C[敏感信息过滤] C --> D[代码片段向量化] D --> E[团队模型微调] E --> F[模型部署到私有服务器] F --> G[实时代码建议生成] G --> H[团队反馈收集] H --> E
二、数据标注工具:AI训练的数据基石
高质量标注数据是训练可靠AI模型的基础。现代数据标注工具已从简单的人工标注发展为结合主动学习、预标注和人机协作的智能平台。
Label Studio:全功能数据标注平台
Label Studio是一个开源的数据标注工具,支持文本、图像、音频、视频等多种数据类型,提供灵活的标签设计和工作流管理。
核心功能架构:

graph TD A[数据导入模块] --> B[支持格式: CSV, JSON, COCO, Pascal VOC] A --> C[云存储集成: S3, GCS, Azure Blob] D[标注界面] --> E[文本标注: NER, 分类, 关系抽取] D --> F[图像标注: 边界框, 多边形, 关键点, 分割] D --> G[音频标注: 转写, 情感, 事件标记] D --> H[视频标注: 时空标注, 动作识别] I[项目管理] --> J[任务分配与跟踪] I --> K[标注质量控制] I --> L[团队权限管理] M[自动化标注] --> N[模型辅助标注] M --> O[主动学习建议] M --> P[预标注与审核] Q[导出模块] --> R[支持格式: JSON, CSV, COCO, TFRecord] Q --> S[直接导出到模型训练框架]
安装与启动Label Studio:
# 使用pip安装 pip install label-studio # 启动服务 label-studio start my_project --port 8080
文本分类标注配置示例:
<View> <Text name="text" value="$text" /> <Choices name="sentiment" toName="text" choice="single" showInLine="true"> <Choice value="Positive" background="#00ff00" /> <Choice value="Negative" background="#ff0000" /> <Choice value="Neutral" background="#ffff00" /> </Choices> <TextArea name="comment" toName="text" placeholder="添加标注说明..." /> </View>
图像目标检测标注界面配置:
<View> <Image name="image" value="$image" zoom="true" zoomControl="true" rotateControl="true" /> <RectangleLabels name="label" toName="image"> <Label value="Car" background="#FF0000" /> <Label value="Pedestrian" background="#00FF00" /> <Label value="Traffic Light" background="#0000FF" /> <Label value="Stop Sign" background="#FFFF00" /> </RectangleLabels> </View>
使用Python API进行批量操作:
from label_studio_sdk import Client # 连接到Label Studio实例 ls = Client(url='http://localhost:8080', api_key='your_api_key') # 创建新项目 project = ls.create_project( title='自动驾驶图像标注', description='标注道路场景中的车辆、行人和交通标志', label_config=''' <View> <Image name="image" value="$image" /> <RectangleLabels name="label" toName="image"> <Label value="Car" background="#FF0000" /> <Label value="Pedestrian" background="#00FF00" /> <Label value="Traffic Light" background="#0000FF" /> </RectangleLabels> </View> ''' ) # 导入标注数据 project.import_tasks([ {'data': {'image': 's3://my-bucket/images/001.jpg'}}, {'data': {'image': 's3://my-bucket/images/002.jpg'}}, # ... 更多图片 ]) # 获取已完成的标注结果 completed_tasks = project.get_tasks(filters=[{'status': 'completed'}]) # 导出标注结果为COCO格式 export_url = project.export_tasks('COCO')
数据标注质量控制策略
高质量的标注数据是模型性能的关键。以下是确保标注质量的核心策略:
- 标注指南设计:创建详细的标注指南,包含边缘情况处理规则
# 情感分析标注指南 ## 定义 - **积极(Positive)**: 表达明确正面情感的文本,如"我喜欢这个产品,非常好用!" - **消极(Negative)**: 表达明确负面情感的文本,如"这个服务太糟糕了,再也不会用了" - **中性(Neutral)**: 不包含明显情感倾向的文本,如"订单将在明天送达" ## 边缘情况处理 1. **混合情感**: 如果文本同时包含正面和负面情感,选择占主导地位的情感 2. **反问句**: "这个产品难道不好吗?"应标记为积极 3. **讽刺文本**: "真是太棒了,我的订单又延迟了"应标记为消极
- 标注员培训与测试:通过测试集评估标注员准确性
import pandas as pd from sklearn.metrics import cohen_kappa_score def calculate_inter_annotator_agreement(annotations1, annotations2): """计算两个标注员之间的一致性""" return cohen_kappa_score(annotations1, annotations2) # 加载标注数据 annotator1 = pd.read_csv('annotator1.csv')['label'] annotator2 = pd.read_csv('annotator2.csv')['label'] # 计算Kappa系数 kappa = calculate_inter_annotator_agreement(annotator1, annotator2) print(f"标注一致性Kappa系数: {kappa:.3f}") # 一般认为Kappa > 0.8表示良好一致性
- 交叉验证机制:对同一数据分配给多个标注员
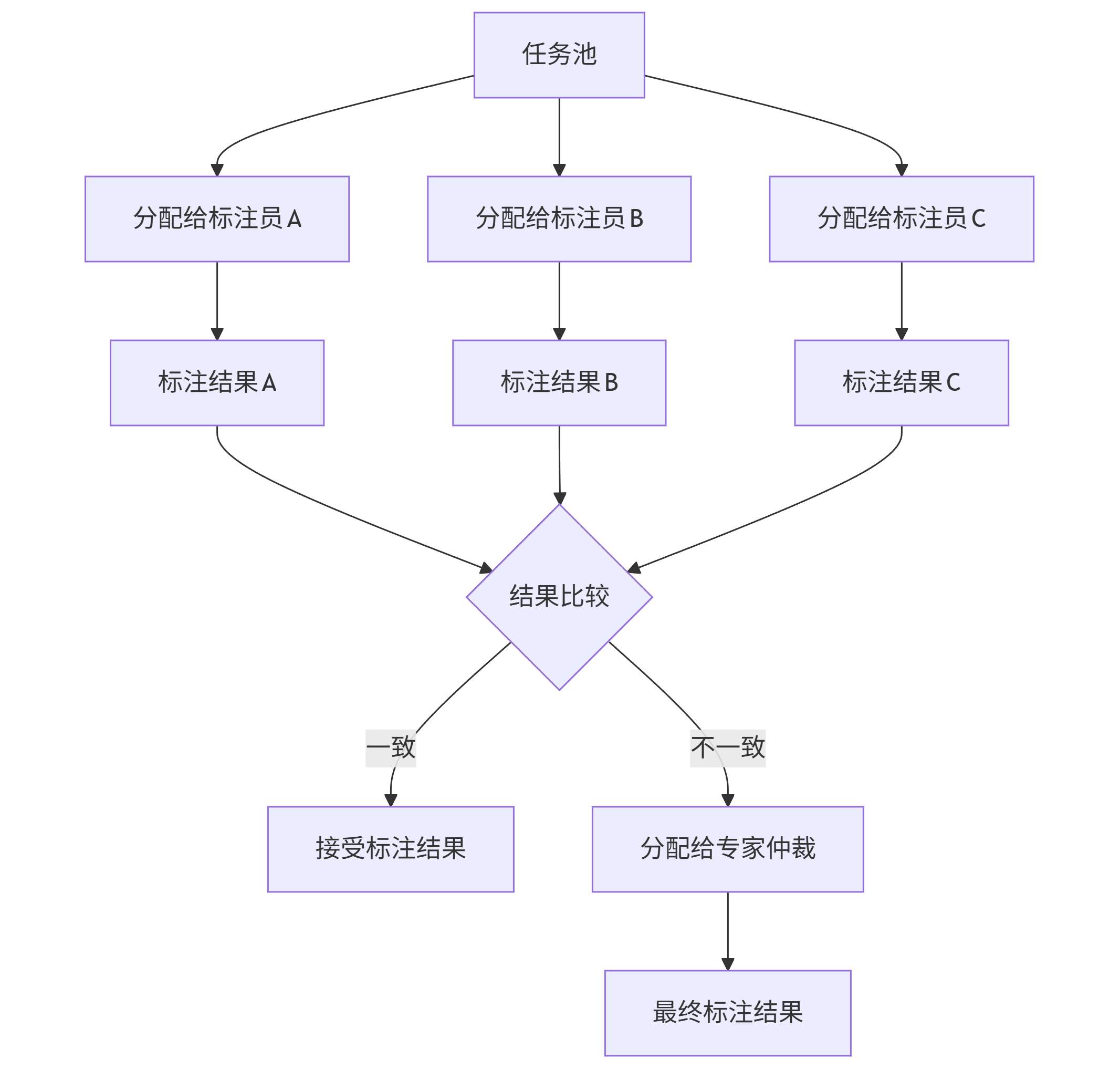
graph TD A[任务池] --> B[分配给标注员A] A --> C[分配给标注员B] A --> D[分配给标注员C] B --> E[标注结果A] C --> F[标注结果B] D --> G[标注结果C] E --> H{结果比较} F --> H G --> H H -->|一致| I[接受标注结果] H -->|不一致| J[分配给专家仲裁] J --> K[最终标注结果]
三、模型训练平台:从实验到生产的桥梁
模型训练平台提供了从数据预处理、模型构建、训练到部署的全流程支持,大大降低了AI应用开发的技术门槛。
TensorFlow Extended (TFX):端到端机器学习平台
TFX是Google开源的端到端机器学习平台,专为生产环境设计,支持大规模机器学习工作流。
TFX核心组件:
| 组件 | 功能 | 常用API |
|---|---|---|
| ExampleGen | 数据导入与拆分 | tfx.components.CsvExampleGen |
| StatisticsGen | 数据统计分析 | tfx.components.StatisticsGen |
| SchemaGen | 数据模式推断 | tfx.components.SchemaGen |
| ExampleValidator | 数据验证 | tfx.components.ExampleValidator |
| Transform | 特征工程 | tfx.components.Transform |
| Trainer | 模型训练 | tfx.components.Trainer |
| Evaluator | 模型评估 | tfx.components.Evaluator |
| Pusher | 模型部署 | tfx.components.Pusher |
TFX流水线定义示例:
import tfx.v1 as tfx from tfx.orchestration.experimental.interactive.interactive_context import InteractiveContext # 设置交互上下文 context = InteractiveContext() # 1. 数据导入 example_gen = tfx.components.CsvExampleGen(input_base='data/train') context.run(example_gen) # 2. 数据统计分析 statistics_gen = tfx.components.StatisticsGen( examples=example_gen.outputs['examples'] ) context.run(statistics_gen) # 3. 数据模式推断 schema_gen = tfx.components.SchemaGen( statistics=statistics_gen.outputs['statistics'], infer_feature_shape=True ) context.run(schema_gen) # 4. 数据验证 example_validator = tfx.components.ExampleValidator( statistics=statistics_gen.outputs['statistics'], schema=schema_gen.outputs['schema'] ) context.run(example_validator) # 5. 特征工程 transform = tfx.components.Transform( examples=example_gen.outputs['examples'], schema=schema_gen.outputs['schema'], module_file='transform.py' ) context.run(transform) # 6. 模型训练 trainer = tfx.components.Trainer( module_file='model.py', examples=transform.outputs['transformed_examples'], transform_graph=transform.outputs['transform_graph'], schema=schema_gen.outputs['schema'], train_args=tfx.proto.TrainArgs(num_steps=10000), eval_args=tfx.proto.EvalArgs(num_steps=5000) ) context.run(trainer) # 7. 模型评估 evaluator = tfx.components.Evaluator( examples=example_gen.outputs['examples'], model=trainer.outputs['model'], schema=schema_gen.outputs['schema'], eval_config=tfx.proto.EvalConfig( model_specs=[tfx.proto.ModelSpec(signature_name='serving_default')], metrics_specs=[ tfx.proto.MetricsSpec( metrics=[ tfx.proto.MetricConfig( class_name='AUC', threshold=0.8 ), tfx.proto.MetricConfig( class_name='Accuracy', threshold=0.7 ) ] ) ] ) ) context.run(evaluator) # 8. 模型部署 pusher = tfx.components.Pusher( model=trainer.outputs['model'], model_blessing=evaluator.outputs['blessing'], push_destination=tfx.proto.PushDestination( filesystem=tfx.proto.PushDestination.Filesystem( base_directory='serving_model' ) ) ) context.run(pusher)
特征工程模块(transform.py):
import tensorflow as tf import tensorflow_transform as tft # 定义特征名称 NUMERIC_FEATURES = ['age', 'trestbps', 'chol', 'thalach', 'oldpeak'] CATEGORICAL_FEATURES = ['sex', 'cp', 'fbs', 'restecg', 'exang', 'slope', 'ca', 'thal'] LABEL_KEY = 'target' def _transformed_name(key): return key + '_xf' def preprocessing_fn(inputs): """ 特征工程处理函数 """ outputs = {} # 处理数值特征:标准化 for key in NUMERIC_FEATURES: outputs[_transformed_name(key)] = tft.scale_to_z_score(inputs[key]) # 处理类别特征:独热编码 for key in CATEGORICAL_FEATURES: outputs[_transformed_name(key)] = tft.one_hot_encoder( inputs[key], num_buckets=tft.experimental.get_num_buckets_for_transformed_feature(inputs[key]) ) # 处理标签 outputs[LABEL_KEY] = inputs[LABEL_KEY] return outputs
模型定义模块(model.py):
import tensorflow as tf from tensorflow.keras import layers def _gzip_reader_fn(filenames): """读取gzip压缩文件""" return tf.data.TFRecordDataset(filenames, compression_type='GZIP') def _input_fn(file_pattern, tf_transform_output, batch_size=32): """创建输入数据管道""" transform_feature_spec = tf_transform_output.transformed_feature_spec().copy() dataset = tf.data.experimental.make_batched_features_dataset( file_pattern=file_pattern, batch_size=batch_size, features=transform_feature_spec, reader=_gzip_reader_fn, label_key='target' ) return dataset def build_model(hidden_units=[128, 64, 32]): """构建分类模型""" input_features = [] # 数值特征输入 for key in ['age_xf', 'trestbps_xf', 'chol_xf', 'thalach_xf', 'oldpeak_xf']: input_features.append(layers.Input(shape=(1,), name=key)) # 类别特征输入(独热编码后) for key in ['sex_xf', 'cp_xf', 'fbs_xf', 'restecg_xf', 'exang_xf', 'slope_xf', 'ca_xf', 'thal_xf']: input_features.append(layers.Input(shape=(None,), name=key)) # 拼接所有特征 concatenated = layers.concatenate(input_features) # 构建隐藏层 x = concatenated for units in hidden_units: x = layers.Dense(units, activation='relu')(x) x = layers.BatchNormalization()(x) x = layers.Dropout(0.2)(x) # 输出层 output = layers.Dense(1, activation='sigmoid')(x) # 构建模型 model = tf.keras.Model(inputs=input_features, outputs=output) # 编译模型 model.compile( optimizer=tf.keras.optimizers.Adam(learning_rate=0.001), loss='binary_crossentropy', metrics=['accuracy', tf.keras.metrics.AUC(name='auc')] ) return model def run_fn(fn_args): """TFX Trainer组件调用的训练函数""" tf_transform_output = tft.TFTransformOutput(fn_args.transform_output) train_dataset = _input_fn( fn_args.train_files, tf_transform_output, batch_size=32 ) eval_dataset = _input_fn( fn_args.eval_files, tf_transform_output, batch_size=32 ) model = build_model() # 模型训练 model.fit( train_dataset, epochs=50, validation_data=eval_dataset, callbacks=[ tf.keras.callbacks.EarlyStopping( monitor='val_loss', patience=5, restore_best_weights=True ), tf.keras.callbacks.ModelCheckpoint( filepath=fn_args.serving_model_dir, save_best_only=True, save_format='tf' ) ] )
MLflow:全生命周期机器学习平台
MLflow是一个开源平台,用于管理机器学习生命周期,包括实验跟踪、模型管理和部署。
MLflow核心组件:

graph TD A[MLflow Tracking] --> B[实验记录] A --> C[参数跟踪] A --> D[指标记录] A --> E[模型版本] A --> F[ artifacts 存储] G[MLflow Projects] --> H[环境封装] G --> I[依赖管理] G --> J[可复现运行] K[MLflow Models] --> L[多框架支持] K --> M[标准化格式] K --> N[多种部署选项] O[MLflow Registry] --> P[模型版本控制] O --> Q[模型阶段管理] O --> R[模型审批流程]
使用MLflow跟踪实验:
import mlflow import mlflow.sklearn from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score, roc_auc_score import pandas as pd import numpy as np # 加载数据 data = pd.read_csv('heart.csv') X = data.drop('target', axis=1) y = data['target'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 启动MLflow实验 mlflow.set_experiment("heart_disease_prediction") # 尝试不同的超参数组合 for n_estimators in [50, 100, 200]: for max_depth in [5, 10, 15, None]: with mlflow.start_run(run_name=f"rf_{n_estimators}_{max_depth}"): # 记录超参数 mlflow.log_param("n_estimators", n_estimators) mlflow.log_param("max_depth", max_depth) # 训练模型 model = RandomForestClassifier( n_estimators=n_estimators, max_depth=max_depth, random_state=42 ) model.fit(X_train, y_train) # 评估模型 y_pred = model.predict(X_test) y_proba = model.predict_proba(X_test)[:, 1] accuracy = accuracy_score(y_test, y_pred) auc = roc_auc_score(y_test, y_proba) # 记录指标 mlflow.log_metric("accuracy", accuracy) mlflow.log_metric("auc", auc) # 记录模型 mlflow.sklearn.log_model(model, "model") # 打印结果 print(f"n_estimators: {n_estimators}, max_depth: {max_depth}") print(f" Accuracy: {accuracy:.4f}") print(f" AUC: {auc:.4f}")
模型注册与部署:
# 注册最佳模型 best_run = mlflow.search_runs( experiment_ids=["heart_disease_prediction"], order_by=["metrics.auc DESC"], max_results=1 ).iloc[0] model_uri = f"runs:/{best_run.run_id}/model" mv = mlflow.register_model(model_uri, "heart_disease_classifier") # 将模型标记为生产就绪 client = mlflow.tracking.MlflowClient() client.transition_model_version_stage( name="heart_disease_classifier", version=mv.version, stage="Production" ) # 加载生产模型进行预测 model = mlflow.pyfunc.load_model( model_uri=f"models:/heart_disease_classifier/Production" ) # 预测示例 sample_data = X_test.iloc[0:5] predictions = model.predict(sample_data) print("预测结果:", predictions)
四、AI开发工具集成:构建端到端流水线
将智能编码工具、数据标注平台和模型训练系统无缝集成,构建完整的AI开发流水线,是实现高效AI应用开发的关键。
完整AI开发流水线架构
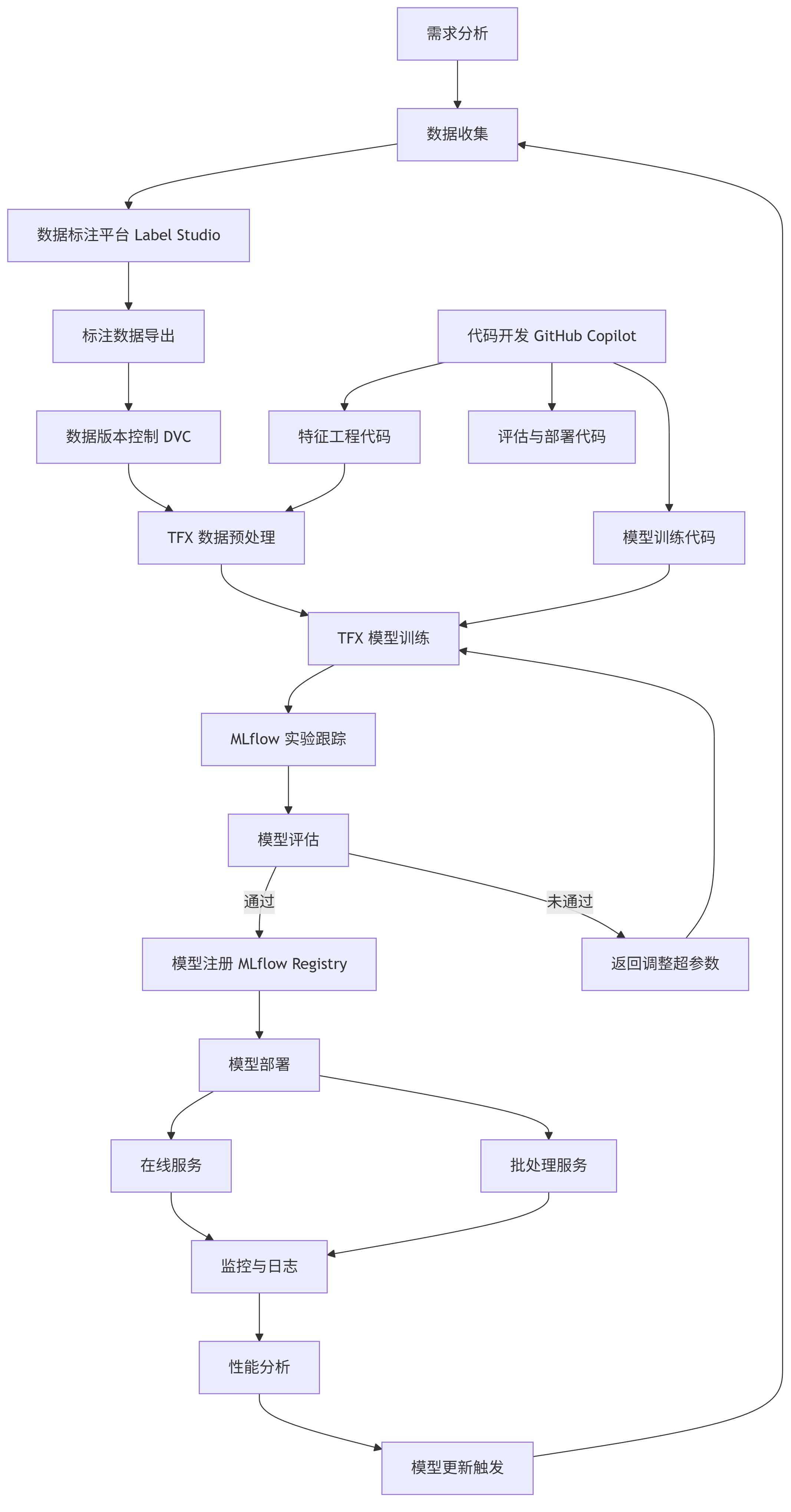
graph TD A[需求分析] --> B[数据收集] B --> C[数据标注平台 Label Studio] C --> D[标注数据导出] D --> E[数据版本控制 DVC] F[代码开发 GitHub Copilot] --> G[特征工程代码] F --> H[模型训练代码] F --> I[评估与部署代码] E --> J[TFX 数据预处理] G --> J J --> K[TFX 模型训练] H --> K K --> L[MLflow 实验跟踪] L --> M[模型评估] M -->|通过| N[模型注册 MLflow Registry] M -->|未通过| O[返回调整超参数] O --> K N --> P[模型部署] P --> Q[在线服务] P --> R[批处理服务] Q --> S[监控与日志] R --> S S --> T[性能分析] T --> U[模型更新触发] U --> B
流水线实现代码示例
使用Airflow定义AI开发流水线:
from airflow import DAG from airflow.operators.bash_operator import BashOperator from airflow.operators.python_operator import PythonOperator from datetime import datetime, timedelta import mlflow default_args = { 'owner': 'data_science_team', 'depends_on_past': False, 'start_date': datetime(2023, 1, 1), 'email': ['data_science@example.com'], 'email_on_failure': True, 'email_on_retry': False, 'retries': 1, 'retry_delay': timedelta(minutes=5), } dag = DAG( 'heart_disease_prediction_pipeline', default_args=default_args, description='End-to-end pipeline for heart disease prediction model', schedule_interval=timedelta(weeks=1), ) # 任务1: 数据收集 collect_data = BashOperator( task_id='collect_data', bash_command='python /opt/airflow/dags/scripts/collect_data.py', dag=dag, ) # 任务2: 数据标注 (通过Label Studio API) def start_annotation_task(): import requests import json API_URL = "http://label-studio:8080/api/projects/1/tasks" API_KEY = "your_label_studio_api_key" headers = { "Authorization": f"Token {API_KEY}", "Content-Type": "application/json" } with open("/opt/airflow/data/new_patients.json", "r") as f: tasks = json.load(f) response = requests.post(API_URL, headers=headers, json=tasks) response.raise_for_status() annotation_task = PythonOperator( task_id='start_annotation', python_callable=start_annotation_task, dag=dag, ) # 任务3: 数据版本控制 dvc_add_data = BashOperator( task_id='dvc_add_data', bash_command='cd /opt/airflow/data && dvc add annotations.json && dvc push', dag=dag, ) # 任务4: 模型训练 (TFX流水线) train_model = BashOperator( task_id='train_model', bash_command='python /opt/airflow/dags/scripts/tfx_pipeline.py', dag=dag, ) # 任务5: 模型评估与注册 def evaluate_and_register_model(): mlflow.set_tracking_uri("http://mlflow:5000") # 查找最新训练的模型 experiment = mlflow.get_experiment_by_name("heart_disease_prediction") runs = mlflow.search_runs( experiment_ids=[experiment.experiment_id], order_by=["start_time DESC"], max_results=1 ) best_run = runs.iloc[0] # 检查性能是否达标 if best_run["metrics.auc"] > 0.85: model_uri = f"runs:/{best_run.run_id}/model" mv = mlflow.register_model(model_uri, "heart_disease_classifier") # 标记为生产就绪 client = mlflow.tracking.MlflowClient() client.transition_model_version_stage( name="heart_disease_classifier", version=mv.version, stage="Production" ) return True else: return False model_evaluation = PythonOperator( task_id='evaluate_and_register_model', python_callable=evaluate_and_register_model, dag=dag, ) # 任务6: 模型部署 deploy_model = BashOperator( task_id='deploy_model', bash_command='python /opt/airflow/dags/scripts/deploy_model.py', dag=dag, ) # 定义任务依赖关系 collect_data >> annotation_task >> dvc_add_data >> train_model >> model_evaluation >> deploy_model
五、工具选型与最佳实践
选择合适的AI开发工具并遵循最佳实践,是确保AI项目成功的关键因素。
AI开发工具选型矩阵
| 工具类型 | 主流工具 | 优势 | 适用场景 | 学习曲线 |
|---|---|---|---|---|
| 智能编码 | GitHub Copilot | 与GitHub深度集成,支持多语言 | 通用软件开发 | ★☆☆☆☆ |
| 智能编码 | Tabnine | 团队私有模型支持,离线使用 | 企业级开发,保密项目 | ★★☆☆☆ |
| 智能编码 | CodeLlama | 开源可定制,支持长上下文 | 特定领域代码生成 | ★★★☆☆ |
| 数据标注 | Label Studio | 开源免费,支持多数据类型 | 中小型团队,多样化标注需求 | ★★☆☆☆ |
| 数据标注 | Labelbox | 企业级功能,高级协作 | 大型标注项目,多团队协作 | ★★★☆☆ |
| 数据标注 | Amazon SageMaker Ground Truth | 与AWS生态集成,自动标注 | AWS用户,大规模标注 | ★★★☆☆ |
| 模型训练 | TensorFlow Extended | 端到端流水线,企业级部署 | 大规模生产环境 | ★★★★☆ |
| 模型训练 | PyTorch Lightning | 简化PyTorch代码,科研友好 | 研究项目,快速实验 | ★★☆☆☆ |
| 模型训练 | Kubeflow | Kubernetes原生,分布式训练 | 大规模集群环境 | ★★★★★ |
| 实验跟踪 | MLflow | 全生命周期管理,多框架支持 | 跨框架项目,需要版本控制 | ★★☆☆☆ |
| 实验跟踪 | Weights & Biases | 可视化丰富,协作功能强 | 团队协作,需要详细报告 | ★★☆☆☆ |
AI开发最佳实践
- 数据质量优先:投入足够资源确保标注数据质量
# 数据质量检查示例 def data_quality_checks(df): """执行基本的数据质量检查""" quality_issues = [] # 检查缺失值 missing_values = df.isnull().sum() for column, count in missing_values.items(): if count > 0: quality_issues.append(f"缺失值: {column} 有 {count} 个缺失值") # 检查异常值 for column in df.select_dtypes(include=['float64', 'int64']).columns: q1 = df[column].quantile(0.25) q3 = df[column].quantile(0.75) iqr = q3 - q1 lower_bound = q1 - 1.5 * iqr upper_bound = q3 + 1.5 * iqr outliers = df[(df[column] < lower_bound) | (df[column] > upper_bound)] if len(outliers) > 0: quality_issues.append(f"异常值: {column} 有 {len(outliers)} 个异常值") # 检查数据分布 for column in df.select_dtypes(include=['float64', 'int64']).columns: if df[column].std() == 0: quality_issues.append(f"常量特征: {column} 所有值相同") return quality_issues # 使用示例 data = pd.read_csv('patient_data.csv') issues = data_quality_checks(data) if issues: print("发现数据质量问题:") for issue in issues: print(f"- {issue}") else: print("数据质量检查通过")
- 实验可复现:记录所有实验参数和环境配置
# environment.yml - conda环境配置 name: ml_pipeline channels: - defaults - conda-forge dependencies: - python=3.8 - pandas=1.4.2 - numpy=1.22.3 - scikit-learn=1.0.2 - tensorflow=2.8.0 - mlflow=1.23.1 - tfx=1.6.0 - label-studio=1.5.0 - pip: - airflow==2.2.5 - dvc==2.10.2
- 版本控制一切:不仅代码,数据和模型也需要版本控制
# DVC数据版本控制示例 dvc init # 初始化DVC dvc add data/training_data/ # 跟踪数据目录 dvc remote add -d myremote s3://my-bucket/dvc-store # 设置远程存储 dvc push # 推送数据到远程存储 git add data/training_data.dvc .dvc/config # 跟踪DVC文件 git commit -m "Add training data version 1" # 后续数据更新 dvc add data/training_data/ # 更新数据版本 dvc push # 推送新版本 git commit data/training_data.dvc -m "Update training data to version 2" # 恢复特定版本数据 git checkout <commit-hash> data/training_data.dvc dvc pull
- 持续集成/持续部署:自动化模型训练和部署流程
# .github/workflows/model-training.yml - GitHub Actions工作流 name: Model Training on: push: branches: [ main ] paths: - 'model/**' - 'data/**' - '.github/workflows/model-training.yml' jobs: train: runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 - name: Set up Python uses: actions/setup-python@v2 with: python-version: '3.8' - name: Install dependencies run: | python -m pip install --upgrade pip pip install -r requirements.txt - name: Start MLflow server run: mlflow server --host 0.0.0.0 --port 5000 & env: MLFLOW_TRACKING_URI: http://localhost:5000 - name: Run training pipeline run: python model/train.py env: MLFLOW_TRACKING_URI: http://localhost:5000 MLFLOW_EXPERIMENT_NAME: heart_disease_prediction - name: Evaluate model run: python model/evaluate.py - name: Deploy model if accuracy > 0.85 if: env.MODEL_ACCURACY > 0.85 run: python model/deploy.py
结语:AI工具生态的未来展望
AI开发工具正在向更智能、更集成、更自动化的方向发展。未来,我们将看到:
- 多模态智能编码:结合文本、图像和语音的全方位开发辅助
- 自适应数据标注:基于模型反馈的动态标注策略,大幅减少人工工作量
- 自动化机器学习(MLOps):从数据到部署的完全自动化流水线
- 边缘设备训练:在终端设备上进行高效模型训练,保护数据隐私
AI工具的发展不仅提高了开发效率,更降低了AI技术的使用门槛,使更多开发者能够参与到AI创新中。选择合适的工具组合,构建高效的开发流水线,将成为企业AI战略成功的关键。在这个AI驱动的开发新时代,持续学习和适应工具生态的变化,将是每位开发者的必备技能。
面对AI工具带来的变革,我们不禁思考:随着AI越来越擅长编写代码和训练模型,人类开发者的核心价值将如何重新定义?是转向更具创造性的问题定义和系统设计,还是专注于AI难以替代的领域知识和业务理解?答案或许在于人机协作的新模式——让AI处理重复性工作,人类则专注于更具战略性和创造性的任务,共同推动技术创新的边界。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐



 2
2 0
0- 0



 已为社区贡献88条内容
已为社区贡献88条内容

所有评论(0)