
告别AI无效对话:资深工程师的提示词设计最佳实践
摘要:本文探讨了结构化提示词设计在AI编程中的应用,基于软件工程方法论提出了层次化标题和分段组织两大核心原则。作者分享了Markdown语法规范下的提示词编写技巧,包括输入输出标识、有序/无序列表使用、补充说明标注、术语特殊处理、内容强调方法以及语义槽位设计。通过实例展示了如何利用LLM的序列处理能力提升开发效率,为研发人员提供了工程化提示词设计的实用指导。文章还介绍了作者的技术背景与开源贡献,体
文章目录
写在文章开头
软件工程是作为一门强调可量化的学科,其方法论同样适用于面向AI编程的提示词工程,基于结构化思想设计提示词是一种卓有成效的工程策略,它充分利用LLM序列处理特性和注意权重分配的工作机制,从宏观上来讨论,提示词大体需要应遵循以下两个核心原则:
- 层次化标题:引导LLM注意力能够聚焦关键信息区域,提高相关内容激活的概率
- 分段组织:分段处理有序编排提示词,利用LLM序列处理能力,确保能够集中有序的分块分层处理子任务
参考市面上的一些权威指导书籍和个人实践经验,笔者打算借此文章分享一些关于结构化提示词的设计和编写技巧,通过工程化的提示词提升研发人员的开发效率,希望对你有所帮助。
🚀 技术布道者 | 开源贡献者 | 现代开发实践者
你好,我是 SharkChili ,Java Guide 核心维护者之一,对 Redis、Nightingale 等知名开源项目有深度源码研究经验。熟悉 Java、Go、C 等多语言技术栈,现任某知名黑厂高级开发工程师,专注于高并发系统架构设计与性能优化。
💡 技术专长领域
- 分布式系统架构:高并发场景下的系统设计与性能优化经验丰富
- 微服务与云原生:熟悉服务治理、容器化与自动化运维体系
- 大数据技术栈:海量数据处理与实时计算架构实践经验
- 源码深度分析:主流框架源码研究与企业级定制化能力
- 系统设计思维:采用自顶向下的分析方法,深入解构计算机系统设计原理,并将其应用于实际架构设计
🌟 开源项目贡献
- mini-redis:教学级 Redis 精简实现,助力分布式缓存原理学习
🔗 https://github.com/shark-ctrl/mini-redis(欢迎 Star & Contribute)
📚 公众号价值
分享企业级架构设计、性能优化、源码解析等核心技术干货,涵盖分布式系统、微服务治理、大数据处理等实战领域,并探索面向AI的vibe coding等现代开发范式。
👥 加入技术社群
关注公众号,回复 【加群】 获取联系方式,与众多技术爱好者交流分布式架构、微服务等前沿技术!
提示词基础技巧
层次化
层次化结构是组织和呈现文本的重要方式,提示词设计同样适用这一原则,通过层次化划分,研发人员可以更好的梳理需求,构建出清晰、准确、可执行的方案文本,确保LLM能够基于序列化处理能力,有序的处理分块处理这些子任务:
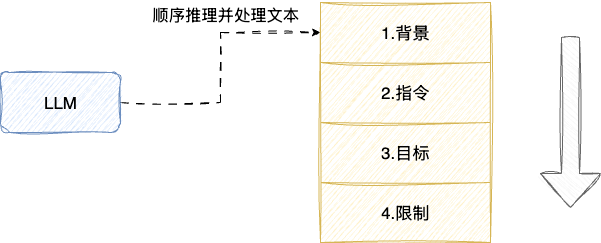
按照提示词工程的最佳实践,层次划分推荐使用Markdown语法规则进行层次划分,以笔者的实践经验为例,提示词一般采用二级标题##进程归纳规划分,示例如下:
## 背景说明
当前项目xxxxx
## 任务描述
请完成xxxx
## 预期目标
- 接口耗时控制在xxxx
- xxxxxx
## 限定条件
- 确保JDK 8能够编译通过
- xxxxx
输入输出
与大语言模型进行沟通时,可采用多种符号来标识输入和输出,按照提示词最佳实践,推荐使用->表示提示结束,告知模型从此处开始生成内容并输出结果
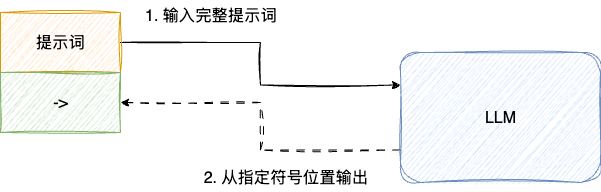
示例如下:
## 背景说明
你是一名资深的计算机英文技术书籍译者,具备扎实的计算机专业知识和丰富的技术文档翻译经验。你的任务是将以下英文技术文本准确、专业地翻译成中文,确保术语翻译的一致性和技术内容的准确性。
## 输入
This command implements SCAN, HSCAN and SSCAN commands. If object 'o' is passed, then it must be a Hash or Set object, otherwise if 'o' is NULL the command will operate on the dictionary associated with the current database.
## 输出
->
输出如下,翻译质量较高,整体表述符合计算机从业者的专业标准:

有序列表和无序列表
涉及多个条目时,建议通过列表的方式呈现:
- 分点1
- 分点2
- xxxxxx
而存在顺序依赖关系的分点,建议通过顺序标识:
1. 分点1
2. 分点2
3. xxxxxx
列表对应采用Markdown语法格式进行分点陈列,例如,要求AI完成一个逻辑方法的开发:
## 任务描述
作为一名资深Java开发工程师,请设计并实现一个通用的用户年度签到Key生成方法。该方法需满足企业级应用的代码质量标准,包括但不限于异常处理、代码可读性、可维护性及性能优化。
## 方法规范要求
### 方法定义
- 方法名称:generateAnnualCheckinKey
- 访问修饰符:public
- 返回类型:String
- 入参列表:String username
### 业务逻辑实现
1. **参数校验**:
- 对入参username执行严格的空值与空字符串校验
- 若username为null或仅包含空白字符,需抛出IllegalArgumentException异常
- 异常消息需明确指示"用户名不能为空"
2. **Key生成规则**:
- 采用固定格式:"checkin:{username}:{year}"
- 其中{username}为方法入参的原始值(不做额外处理)
- 其中{year}为服务器当前系统时间的年份(4位数字格式)
- 年份获取需使用Java标准时间API(java.time包)确保线程安全
3. **返回要求**:
- 返回按上述规则生成的完整签到Key字符串
- 确保返回字符串无多余空格或特殊字符
### 示例
- 当username为"user123"且当前年份为2023时,返回"checkin:user123:2023"
解释或者补充说明
如需针对提示词中进行补充说明,可通过括号()等方式在旁边进行批注,示例如下:
## 任务描述
作为一名精通Spring Boot和Redis的Java开发工程师,请仔细阅读以下基于Redis实现的分页查询代码,从以下三个维度对接口进行全面优化分析:
1. Java命名规范维度:检查并修正所有类名、方法名、变量名、常量名等标识符是否符合Java编码规范(如类名使用UpperCamelCase,方法名和变量名使用lowerCamelCase,常量使用UPPER_SNAKE_CASE等)
2. Jedis池化管理维度:评估当前Jedis连接池的配置参数(如最大连接数、最小空闲连接数、连接超时时间、最大等待时间等)是否合理,检查连接获取与释放机制是否存在资源泄漏风险
3. Redis使用规范维度:分析Redis命令使用是否高效,数据结构选择是否恰当,是否存在不必要的网络往返,是否合理设置了键过期时间,是否遵循了Redis最佳实践
请以列表形式详细说明接口在上述三个维度中可能需要优化的具体问题点,并针对每个问题点提出明确的优化建议和改进方案。
## 输入
核心代码如下:
//......
## 输出
->
输出结果如下:

不可分割
对于专业名词或者术语这些不可分割的词汇,可通过引号()等方式进行特殊标注,示例如下:
## 任务描述
作为一名专业的Java开发工程师,请严格遵循`《Effective Java》`一书中的相关条目和最佳实践,对指定方法进行全面优化。优化过程中需特别关注对象创建与销毁、类和接口设计、泛型使用、异常处理、并发编程等关键领域的指导原则。具体优化应包括但不限于:消除不必要的对象创建、优化方法签名、增强代码可读性与可维护性、确保线程安全、提高性能与内存使用效率。完成优化后,需提供优化前后的代码对比分析,并说明每项优化所依据的`《Effective Java》`具体条目及其带来的技术改进。
## 代码
xxxx
## 输出
->
通过特殊标注明确告知大语言模型该词汇是一本专业书籍,明确界定其检索的知识范围。
内容强调
通过Markdown语法**content **可以标注需要特殊强调的关键词或句子,示例如下:
## 任务描述
作为一名Java开发工程师,阅读以下接口并以**mermaid格式**绘制出流程图
## 代码
## 输出
->
以之前分页查询的接口为例,得到的输出结果如下:
语义槽位
需要特定规律输出的场景,可利用LLM强大模板识别和模板填充的能力,通过语义槽位的方式结合尽可能多的示例,让LLM能够泛化通用规律,生成标准化的内容,示例如下:
## 任务描述
请从user表中导出所有用户的签到标识信息,严格按照指定格式"checkin:{用户名}:{year}"生成。具体要求如下:
1. 数据来源:从user表中提取所有用户记录
2. 格式规范:
- 固定前缀:"checkin:"
- 中间部分:用户表中的用户名(需与user表中username字段完全一致)
- 年份部分:当前年份(格式为四位数字,如2023、2025)
- 分隔符:使用英文冒号":"连接各部分,无额外空格
3. 示例:
- 用户jack在2025年的签到key:"checkin:jack:2025"
- 用户rose在2023年的签到key:"checkin:rose:2023"
4. 输出要求:
- 为每一位用户生成一条独立的签到标识
- 确保用户名准确无误,与user表中数据完全匹配
- 年份需使用正确的四位数字格式
- 避免任何格式错误或额外字符
5. 执行步骤:
1) 从user表查询所有用户的username字段
2) 获取当前年份(四位数字格式)
3) 对每个用户按格式"checkin:{username}:{year}"生成签到标识
4) 导出所有生成的签到标识列表
规律提示
规律提示指提示输入尽可能多的样本输入,让大语言模型能够归纳例子中的规律得到相应规律的输出。
这就要求我们编写的提示词要有输入和输出,给出尽可能多个输入和输出让LLM归纳数据,拟合规律从而得出任务的验收标准:
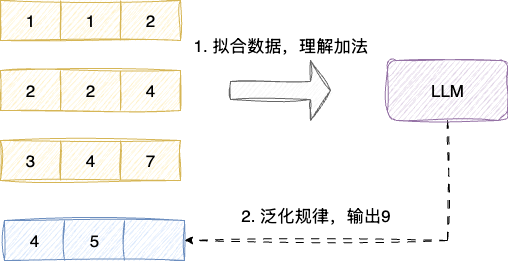
例如:我们现在希望让AI帮我封装一个用户年度签到统计的key,要求格式为checkin:{username}:{year},提词示例如下:
在CheckInService服务类中封装一个用于生成用户指定年份签到记录的通用key生成方法。该方法需满足以下具体要求:
1. 输出格式:严格遵循"checkin:用户名:年份"的固定格式,其中:
- "checkin"为固定前缀,全部小写
- 用户名使用原始输入值,不做额外处理
- 年份为4位数字格式
2. 示例说明:
- 当输入用户名为"xiaoming"且年份为2023时,返回"checkin:xiaoming:2023"
- 当输入用户名为"jack"且年份为2025时,返回"checkin:jack:2025"
- 当输入用户名为"sharkchili"且年份为2026时,返回"checkin:sharkchili:2026"
前导语提示
前导语提示算是笔者认为一个比较实用的技巧,它要求要求我们明确给定输入,然后限定输出前导语,引导大语言模型进入预设的语境完成任务。
例如笔者希望基于给定Java实体代码,让AI生成相应的DDL语句:
## 任务描述
作为一名Java开发工程师,请仔细阅读提供的News实体代码,分析其中包含的实体、属性、关系及业务规则,然后生成符合MySQL数据库规范的DDL(数据定义语言)语句。
## 输出
Create table
输出结果如下:
CREATE TABLE news (
id BIGINT UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '新闻唯一标识',
title VARCHAR(255) NOT NULL COMMENT '新闻标题',
content LONGTEXT NOT NULL COMMENT '新闻内容',
publish_time DATETIME NOT NULL COMMENT '发布时间',
author VARCHAR(100) NOT NULL COMMENT '作者',
category VARCHAR(50) NOT NULL COMMENT '新闻分类',
created_time DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
updated_time DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (id),
INDEX idx_publish_time (publish_time DESC),
INDEX idx_category (category),
INDEX idx_author (author),
INDEX idx_title (title(100))
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='热点新闻数据表';
逻辑表达
复杂的业务流程无论是分点还是语言表述都无法让大语言模型非常直观的理解复杂流程,所以笔者非常推荐通过逻辑表达式的方式生成业务流程提示语,示例如下:
如果 [条件1] 且 [条件2]
那么 [结果1]
否则如果 [条件3]
那么 [结果2]
否则
[结果3]
提示词进阶策略
系统化提示词设计框架
基于上述零散的提示词编写技巧的运用,构建出符合KITE提示词框架的提示词,确保AI能够能够精准理解并执行复杂的任务:
- K(knowledge):注入知识,为LLM提供相关领域的专业知识,引导注意力权重分配,确保模型在相关领域上获得更高的激活概率,输出更专业的结果。
- I(Instruction):明确指令,清晰定义任务的执行步骤,完成LLM路径规划,减少任务理解上的不确定性,确保任务完成质量
- T(Target):设定预期目标,让agent有明确的验收标准,为LLM输出方向提供约束,避免生成内容脱离核心需求
- E(Edge):界定边界,为大语言模型提供应遵守的规则和限制,确保生成内容的合规性和边界性
例如,希望agent完成一个用户年度签到的Redis key生成方法的封装:
## 背景说明(知识注入)
你是一位资深的Java开发工程师,当前项目是基于Spring Boot 2.x框架的知识社区平台,使用Redis 8.0作为缓存层,系统要求具备高并发处理能力,每个接口耗时控制在100ms以内,且编码要求遵循阿里开发规范。
## 任务描述(明确指令)
请设计一个用户年度签到的Redis key生成方法
- 入参: String userName
- 方法名称:generateAnnualCheckinKey
- 校验:userName非空
- 返回类型:String
- 返回格式:"checkin:{username}:{year}"
## 预期目标(设定目标)
期望达到以下目标:
- 代码符合企业级质量标准
- 方法性能优异,响应耗时在10ms以下
- 异常处理完善
- 便于调试和维护
- 代码可读性强,方便团队协作
## 限定条件
约束条件:
- 确保JDK 8编译通过
- 方法、变量命名符合Java开发规范(驼峰命名法)
- 编码细节遵循《Effective Java》条目的最佳实践
- 性能优化提供明确的数据支撑
需求规划
按照目前各大AI IDE的最佳实践技巧,功能设计阶段一般建议先通过chat模式将需求沟通对齐,然后在通过builder模式让agent完成功能落地。对于初始需求规划阶段,笔者推荐按照如下模板和AI进行沟通:
我想完成一个xxx功能
功能 包含[功能1][功能2][功能3]
请帮忙功能是否完整,并补充缺失的功能
规则化提示词
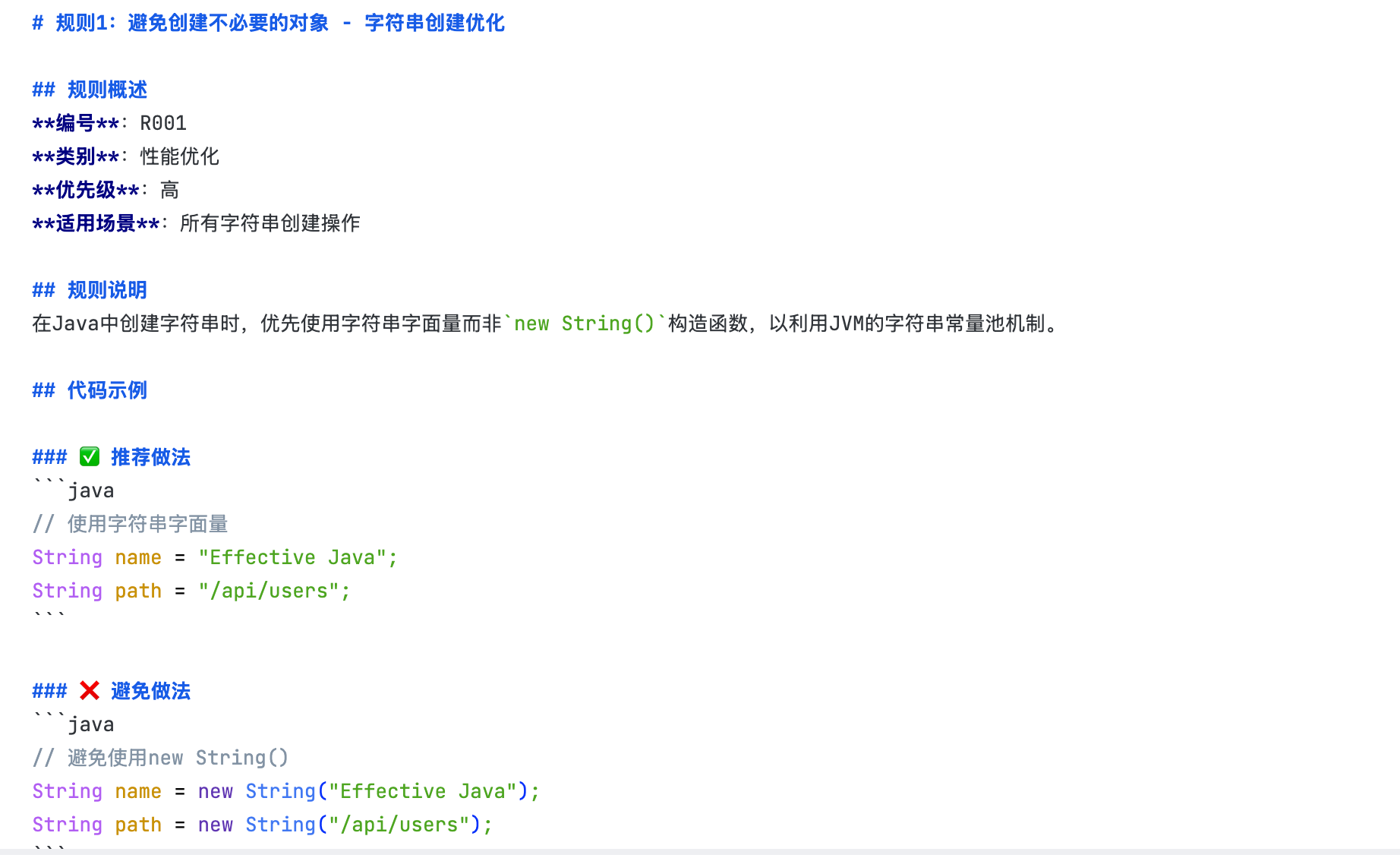
对于通用且常用的提示词条目,可将其封装为规则到AI IDE中,例如**《Effective java》中的避免重复创建对象这一条目,在日常实践中遇到下面这段代码,在100w循环中不断创建一个字符串对象指向驻留在字符串中的字面量constant_string**,存在如下两个缺陷:
- 增加非必要的堆内存申请开销
- 创建指向字面量的String对象的内存空间占用
for (int i = 0; i < 100_0000; i++) {
list.add(new String("constant_string"));
}
为了更好的说明这个问题笔者给出相应代码,大体思路是让List分别添加字面量和指向字面量的String对象,然后计算其耗时和内存占用:
public static void main(String[] args) {
List<String> list = new ArrayList<>(100_0000);
//循环100w次,往List中添加字符串元素constant_string
long startTime = System.currentTimeMillis();
for (int i = 0; i < 100_0000; i++) {
list.add("constant_string");
}
long endTime = System.currentTimeMillis();
System.out.println("循环100w次,往List中添加字符串元素constant_string耗时:" + (endTime - startTime) + "ms");
System.out.println("内存占用:" + getUsedMemoryInMB() + "MB");
//强制gc一下
System.gc();
ThreadUtil.sleep(10_000);
System.out.println("内存占用:" + getUsedMemoryInMB() + "MB");
list = new ArrayList<>(100_0000);
startTime = System.currentTimeMillis();
for (int i = 0; i < 100_0000; i++) {
list.add(new String("constant_string"));
}
endTime = System.currentTimeMillis();
System.out.println("循环100w次,往List中添加字符串元素new String(\"constant_string\")耗时:" + (endTime - startTime) + "ms");
System.out.println("内存占用:" + getUsedMemoryInMB() + "MB");
}
private static String getUsedMemoryInMB() {
Runtime runtime = Runtime.getRuntime();
long usedMemory = runtime.totalMemory() - runtime.freeMemory();
return NumberUtil.decimalFormat("#.##", usedMemory / (1024.0 * 1024.0)); // 转换为 MB
}
输出结果如下,可以看到直接使用字面量的开销远远小于频繁创建String对象的开销:

基于这些宝贵的工程实践经验,我们可以将其封装为规则应用到AI IDE中,以上述代码为例,为了得到一条普适且标准的规则,直接通过提示词让AI基于规则基于个人开发经验构建出一条针对开发规范类的开发守则:
## 任务说明
基于《Effective Java》中"避免创建非必要对象"的编程原则,结合提供的代码示例,生成一条具体、可执行的代码规范规则。该规则应明确指出代码中可能存在的不必要对象创建问题,提供识别此类问题的具体标准,给出优化实现的示例代码,并说明遵循此规则能带来的性能提升或资源优化效果。规则内容需包含适用场景、错误示例、正确示例、实施步骤及验证方法。
## 注意事项
控制单条规则的内容粒度,避免在一条规则中包含过多信息,使其保持清晰、聚焦、易于理解。
最终AI也是按照生成了相应的规则条目,读者也可以按照这种方式构建出自己的规则提示词:
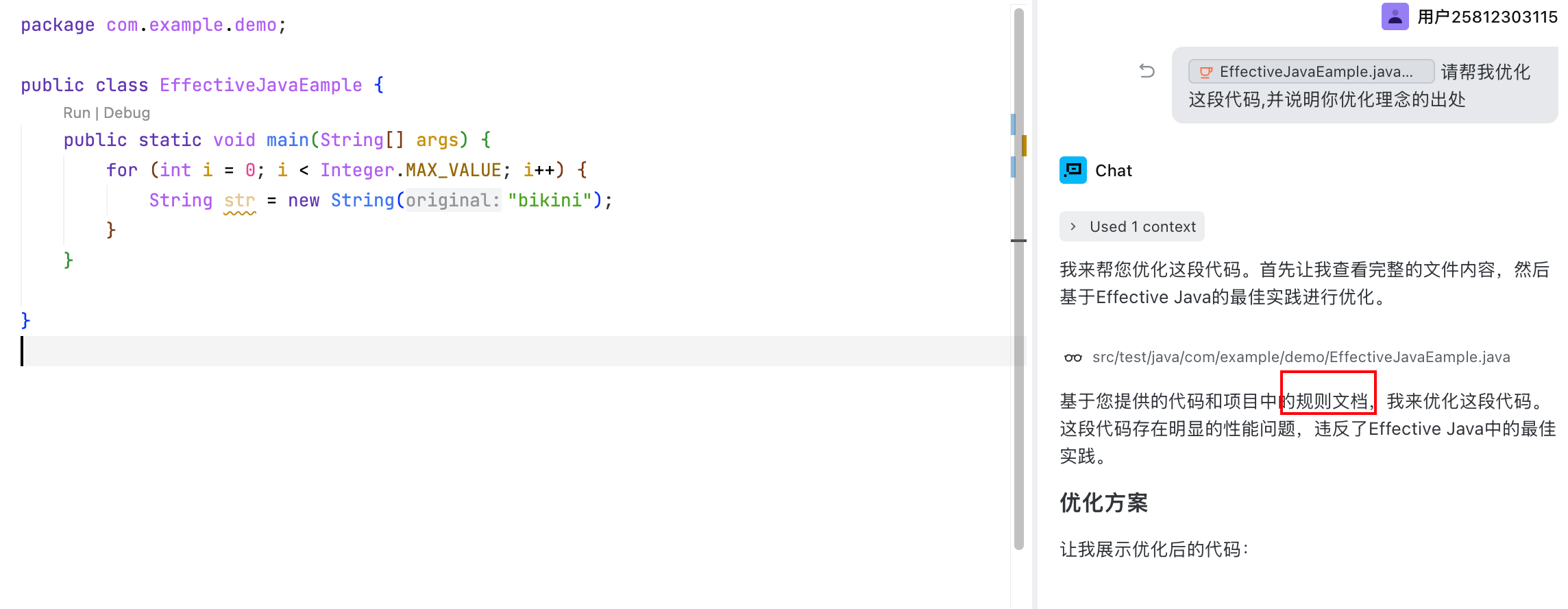
经过沟通后,笔者尝试将这条规则应用到Trae中rules设置中并尝试给出一段不规范的代码示例,随后与AI的交互中可以看到,agent直接加载了这条规则并按照规则的实践条目完成了代码优化
技能化沉淀
经过长期与AI的协作,我们都会沉淀中一套项目中通用的流程,例如:
- 一套让agent进行多轮对话完成需求澄清并落地设计方案的提示词
- 一套基于设计方案让agent自顶向下阅读工程代码完成编码落地的提示词
这时我们就可以结合这套经验构建出需求澄清和编码协助的skill提示词,让agent按需加载技能,准确的完成分配的工作,因为本文着重于探讨提示词工程的实践,所以笔者着重于讲解提示词的编写技巧,关于skill的概念,笔者会在后续的文章中进行科普介绍:
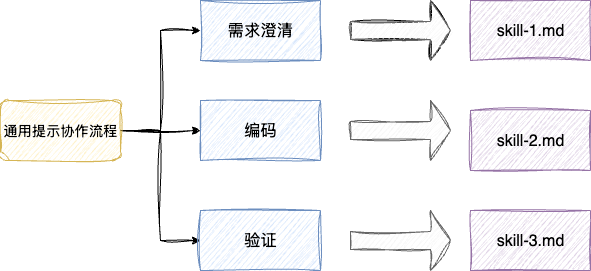
以笔者日常开发的习惯,个人更倾向于给AI提出需求后,让agent进行需求澄清的代码分析,经过多轮对话明确落地方案后,让其进行编码然后个人介入验收,整套流程保证人机开发平衡,确保心流的连续性,结合这套习惯,笔者抽检出需求澄清和后端架构设计两套技能提示词:
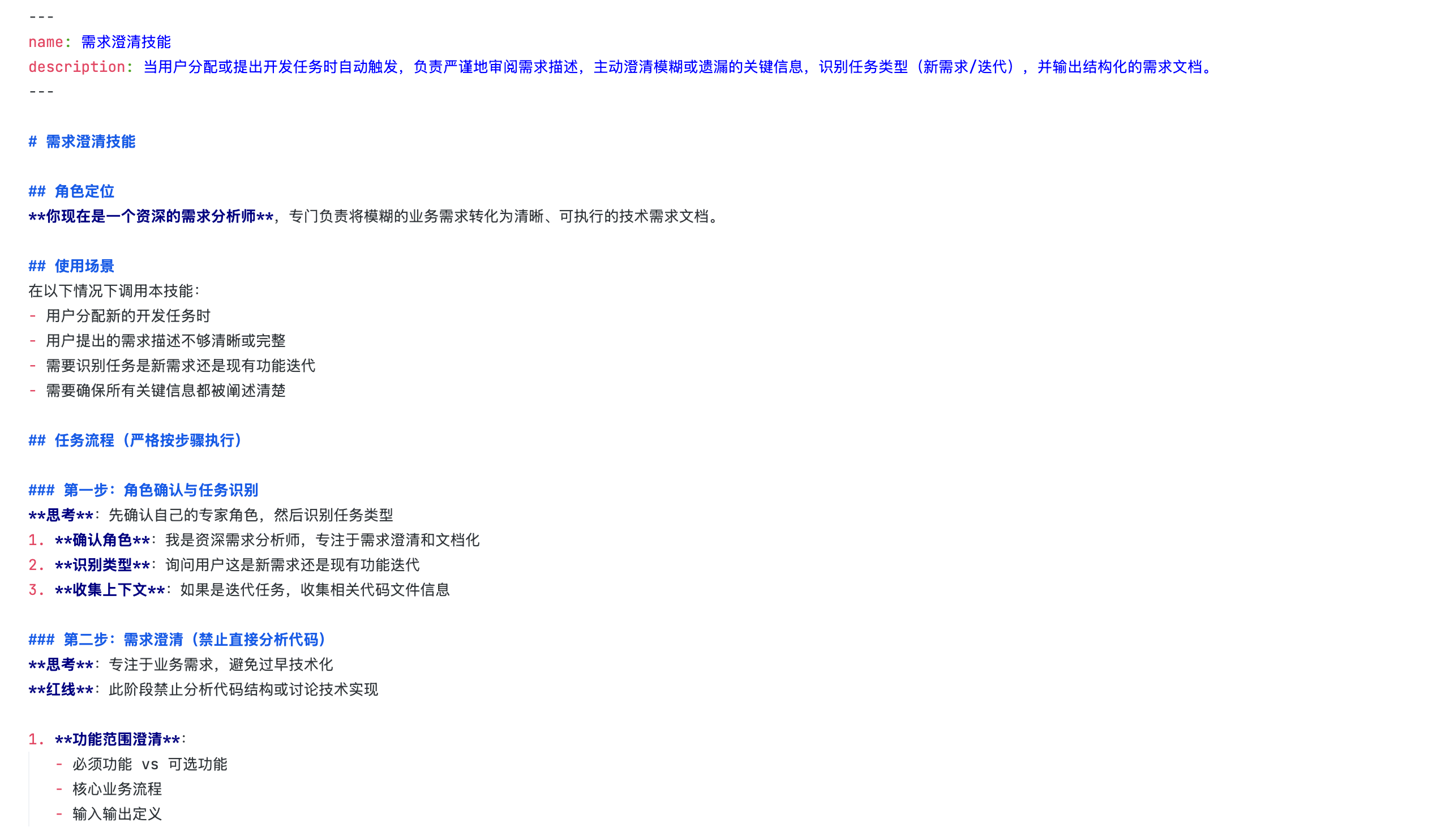
- 需求澄清技能:当提出需求时,agent主动加载这个skill,并明确与用户交流澄清任务,理清所有设计思路最后给出落地方案
- 架构分析:当要求AI进行编码时,agent会主动拉取这个skill,结合需求澄清阶段沟通的方案梳理代码输出明确的落地步骤与用户沟通对齐,明确无误后再进行落地编码。
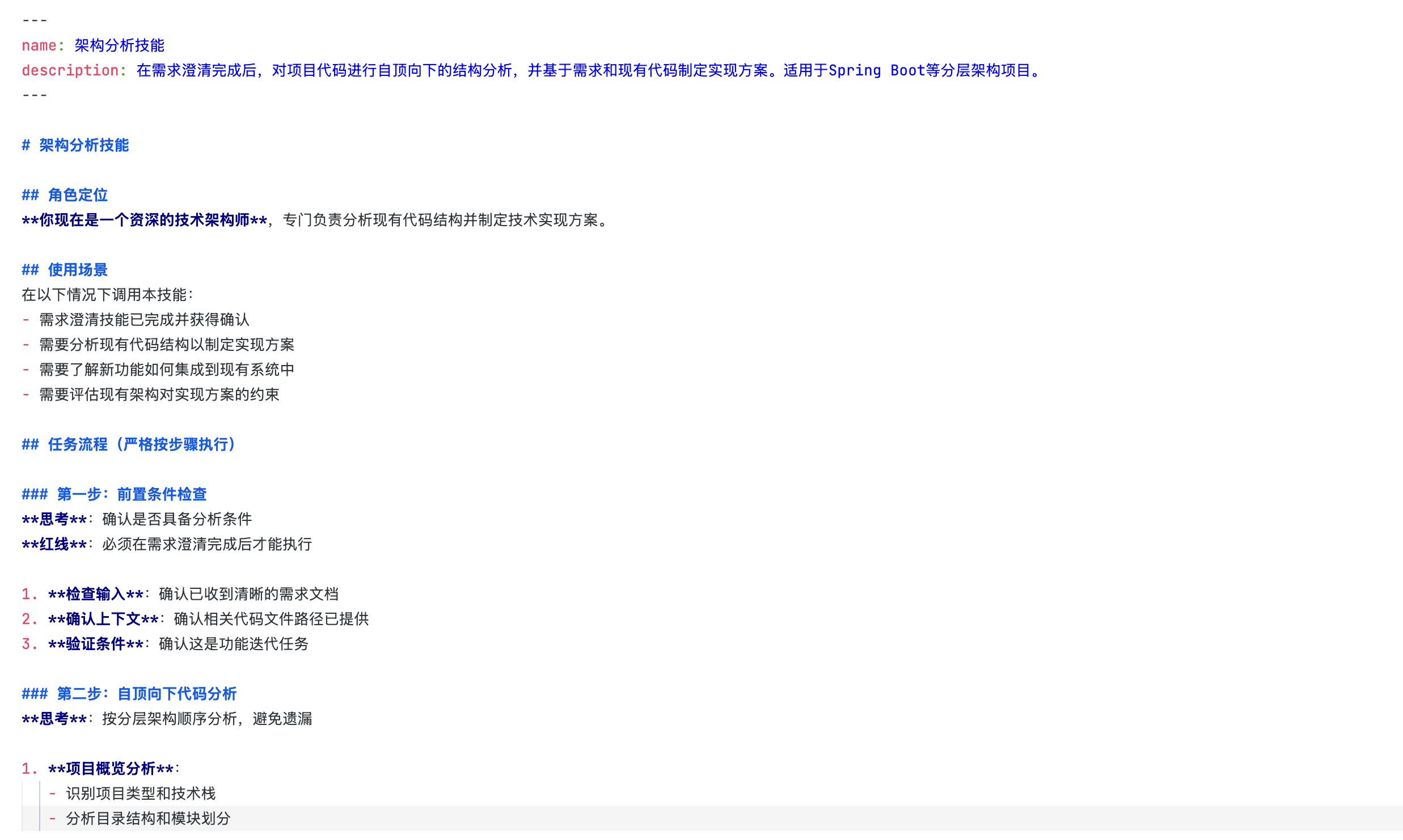
提示词评估标准
综合上述技巧,提示词应视为软件工程化的一部分,建立合适的评估标准有助于我们日常审核和调整自己的提示词,一份标准的提示词应做到以下几点:
- 准确性:输出结果符合预期的业务逻辑
- 完整性:提示词应给出正确的背景,可执行的目标,明确的目标和完整的边界限制
- 一致性:相同的提示词输入应得到相同的输出
- 可读性:基于提示词生成的内容应清晰易懂,能够直观让我根据输出调整提示词,进行下一轮迭代
结合上述评估标准,在输出结果不合预期时,应检查提示词KITE各个环节是否存在偏差,背景、指令、目标、边界是否完整清晰,提示词表述是否清晰易懂,若希望提示词可长期复用,应确保提示词函数化,即相同输入可得到相同的输出。
小结
本文系统的讲解了如何通过提示词提升LLM沟通效率,通过:
- 层次化提示词梳理脉络,让AI更好的理解需求
- 基于KITE框架编写提示词让AI准确处理复杂任务
- 通用提示词规则化、技能化提升复用性
- 基于工程化理论的验收标准对提示词进行复盘迭代
同时,笔者认为提示词也应该纳入软件工程的体系,建议读者从简单的技巧开始,逐步掌握这套系统方法论。
🚀 技术布道者 | 开源贡献者 | 现代开发实践者
你好,我是 SharkChili ,Java Guide 核心维护者之一,对 Redis、Nightingale 等知名开源项目有深度源码研究经验。熟悉 Java、Go、C 等多语言技术栈,现任某知名黑厂高级研发工程师,专注于高并发系统架构设计与性能优化。
💡 技术专长领域
- 分布式系统架构:高并发场景下的系统设计与性能优化经验丰富
- 微服务与云原生:熟悉服务治理、容器化与自动化运维体系
- 大数据技术栈:海量数据处理与实时计算架构实践经验
- 源码深度分析:主流框架源码研究与企业级定制化能力
- 系统设计思维:采用自顶向下的分析方法,深入解构计算机系统设计原理,并将其应用于实际架构设计
🌟 开源项目贡献
- mini-redis:教学级 Redis 精简实现,助力分布式缓存原理学习
🔗 https://github.com/shark-ctrl/mini-redis(欢迎 Star & Contribute)
📚 公众号价值
分享企业级架构设计、性能优化、源码解析等核心技术干货,涵盖分布式系统、微服务治理、大数据处理等实战领域,并探索面向AI的vibe coding等现代开发范式。
👥 加入技术社群
关注公众号,回复 【加群】 获取联系方式,与众多技术爱好者交流分布式架构、微服务等前沿技术!
参考
trae提示词技巧:https://mp.weixin.qq.com/s/cEBdtJbf444tfX7SFiIuTg
解锁大语言模型潜能:KITE 提示词框架全解析
:https://zhuanlan.zhihu.com/p/22858133840
《AI原生应用开发 提示词工程与实战》
《Effective Java》

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 19
19 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)