
linux安装ollama后,本地部署deepSeek教程(亲测版)
安装ollama步骤,并使用ollama拉取deepSeek实现本地部署大模型
·
现在AI很火,也是有时间玩玩本地部署。
虽然有AI一搜就能出教程步骤,但我按AI的来,不一定对。
下面是我亲测有效本地部署版,有图为证。
第一步:先得将ollama安装包下载到本地。
- 打开浏览器访问:https://github.com/ollama/ollama/releases/tag/v0.1.48
- 下载
ollama-linux-amd64文件 - 最后手动上传到linux系统
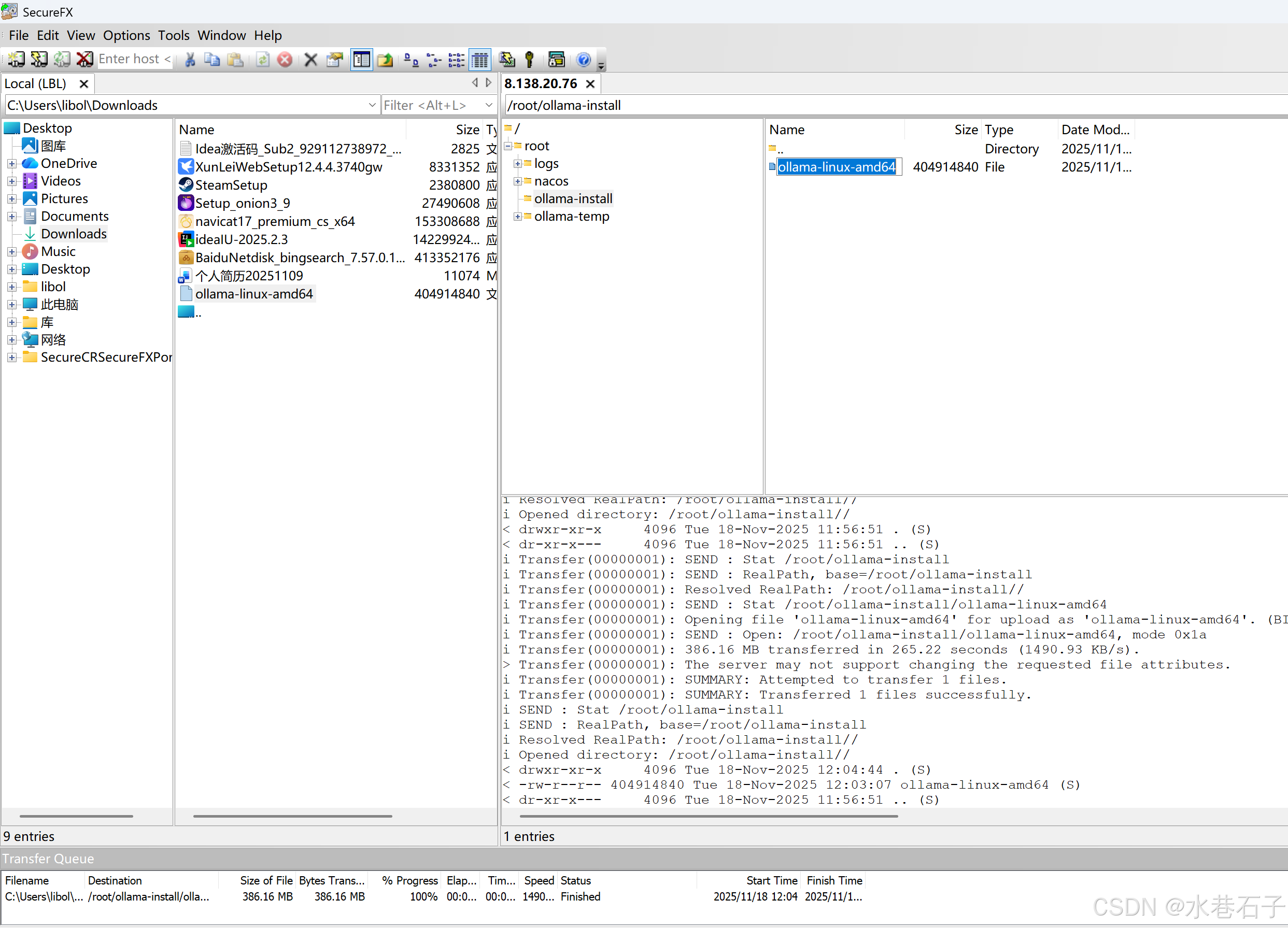
ps:别问我为什么使用手动上传方式,原因我试了一上午,什么官网下载、修改配置下载、docker镜像拉取ollama都不好使,各种问题,下载不下来!!!
第二步:完成安装,修改权限
# /root/ollama-linux-amd64是你上传的安装包的目录
sudo mv /root/ollama-linux-amd64 /usr/local/bin/ollama
sudo chmod +x /usr/local/bin/ollama
第三步:创建服务文件
sudo tee /etc/systemd/system/ollama.service <<EOF
[Unit]
Description=Ollama Service
After=network.target
[Service]
ExecStart=/usr/local/bin/ollama serve
User=root
Group=root
Restart=always
RestartSec=3
[Install]
WantedBy=multi-user.target
EOF
第四步:启动服务
sudo systemctl start ollama
第五步:可以查看版本了
ollama --version
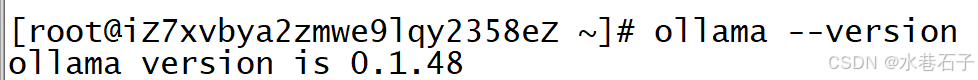
== 到此,安装就算完成了 ==
第六步:使用安装好的ollama,拉取大模型deepSeek
ollama pull deepseek-r1:1.5b
第七步:查看大模型
ollama list

第八步:启动
ollama run deepseek-r1:1.5b
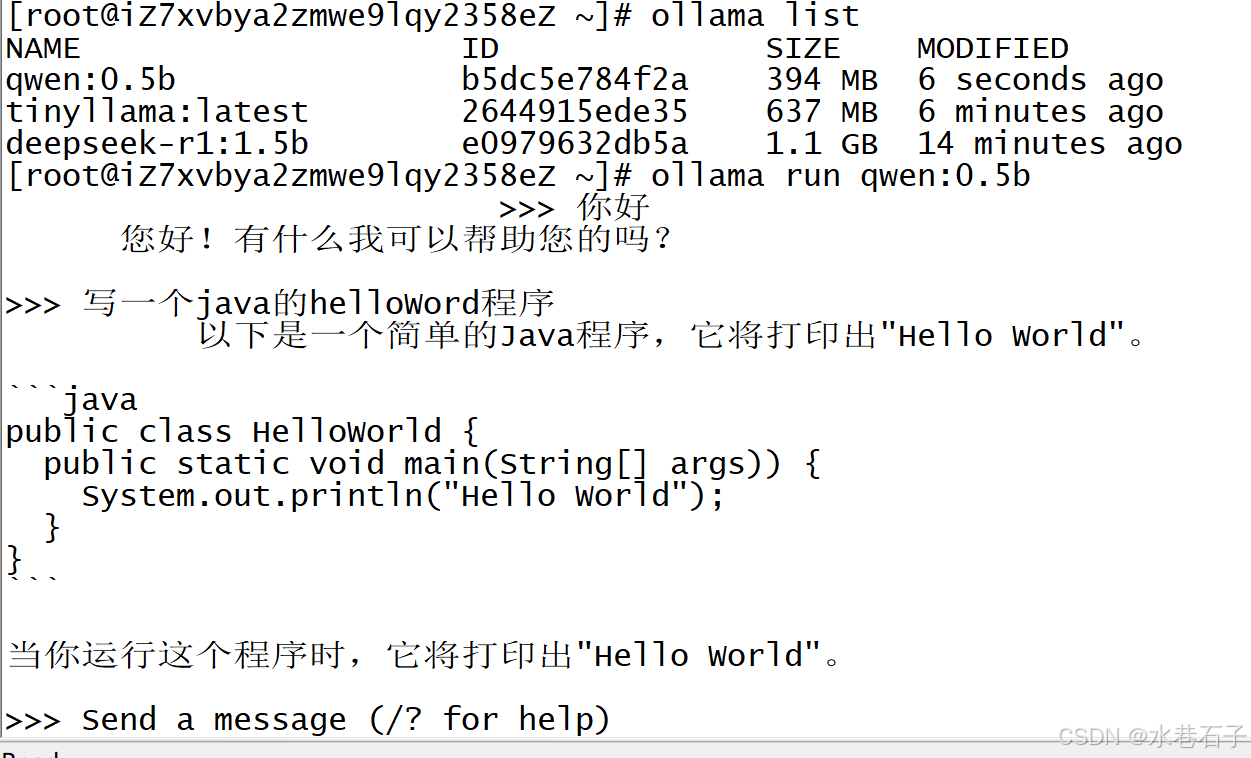
图中是启动的是千问,因为deepSeek内存需要太多,没启来,哈哈
这是当时的错误日志,没关系,用千问的试了一下,是可以的,不影响。
[root@iZ7xvbya2zmwe9lqy2358eZ ~]# journalctl -u ollama -f
-- Logs begin at Wed 2023-08-16 10:04:16 CST. --
Nov 18 12:43:09 iZ7xvbya2zmwe9lqy2358eZ ollama[2136]: llama_new_context_with_model: KV self size = 56.00 MiB, K (f16): 28.00 MiB, V (f16): 28.00 MiB
Nov 18 12:43:09 iZ7xvbya2zmwe9lqy2358eZ ollama[2136]: llama_new_context_with_model: CPU output buffer size = 0.59 MiB
Nov 18 12:43:09 iZ7xvbya2zmwe9lqy2358eZ ollama[2136]: ggml_backend_cpu_buffer_type_alloc_buffer: failed to allocate buffer of size 314310688
Nov 18 12:43:09 iZ7xvbya2zmwe9lqy2358eZ ollama[2136]: ggml_gallocr_reserve_n: failed to allocate CPU buffer of size 314310656
Nov 18 12:43:09 iZ7xvbya2zmwe9lqy2358eZ ollama[2136]: llama_new_context_with_model: failed to allocate compute buffers
Nov 18 12:43:09 iZ7xvbya2zmwe9lqy2358eZ ollama[2136]: llama_init_from_gpt_params: error: failed to create context with model '/root/.ollama/models/blobs/sha256-aabd4debf0c8f08881923f2c25fc0fdeed24435271c2b3e92c4af36704040dbc'
Nov 18 12:43:09 iZ7xvbya2zmwe9lqy2358eZ ollama[2136]: ERROR [load_model] unable to load model | model="/root/.ollama/models/blobs/sha256-aabd4debf0c8f08881923f2c25fc0fdeed24435271c2b3e92c4af36704040dbc" tid="139739877652352" timestamp=1763440989
Nov 18 12:43:09 iZ7xvbya2zmwe9lqy2358eZ ollama[2136]: terminate called without an active exception
Nov 18 12:43:10 iZ7xvbya2zmwe9lqy2358eZ ollama[2136]: time=2025-11-18T12:43:10.134+08:00 level=ERROR source=sched.go:388 msg="error loading llama server" error="llama runner process has terminated: signal: aborted error:failed to create context with model '/root/.ollama/models/blobs/sha256-aabd4debf0c8f08881923f2c25fc0fdeed24435271c2b3e92c4af36704040dbc'"
Nov 18 12:43:10 iZ7xvbya2zmwe9lqy2358eZ ollama[2136]: [GIN] 2025/11/18 - 12:43:10 | 500 | 13.869660325s | 127.0.0.1 | POST "/api/chat"
到此,就使用ollama部署好了

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)