
本地部署大模型-AI Agent
从“会聊天”,到“会做事”,再到“会协作”,
从“会聊天”,到“会做事”,再到“会协作”,
AI Agent 的本质是把大模型变成一个能持续行动的系统。
一、为什么有了大模型,还需要 AI Agent?
如果你已经折腾过本地大模型、RAG、微调,你大概率会有一个感受:
模型很聪明,但它什么也“不会自己去做”。
它可以:回答问题、写代码、给建议;
但它不会:主动拆解任务、决定下一步该做什么、调用工具并根据结果修正策略
这正是 AI Agent 出现的原因,让AI自动进行拆解任务、决定下一步该做什么、调用工具并根据结果修正策略。
二、一句话理解 AI Agent
AI Agent 不是更大的模型,而是“能自己行动的大模型”。
更工程一点的定义是:
AI Agent = 大模型 + 目标 + 记忆 + 工具 + 控制循环
它不再是“一问一答”,而是一个持续运行的决策系统。
三、AI Agent 与普通大模型的区别
| 对比维度 | 普通大模型 | AI Agent |
|---|---|---|
| 交互方式 | 一问一答 | 目标驱动 |
| 是否拆任务 | No | Yes |
| 是否调用工具 | 被动 | 主动 |
| 是否有状态 | No | Yes |
| 是否能纠错 | No | Yes |
| 更像什么 | 搜索引擎 | 助理 / 执行者 |
我们提供想法和大概的思路,甚至只给大模型一个思路,大模型负责“想”,补充实现路径和实现细节,Agent 负责“想 + 做 + 改”。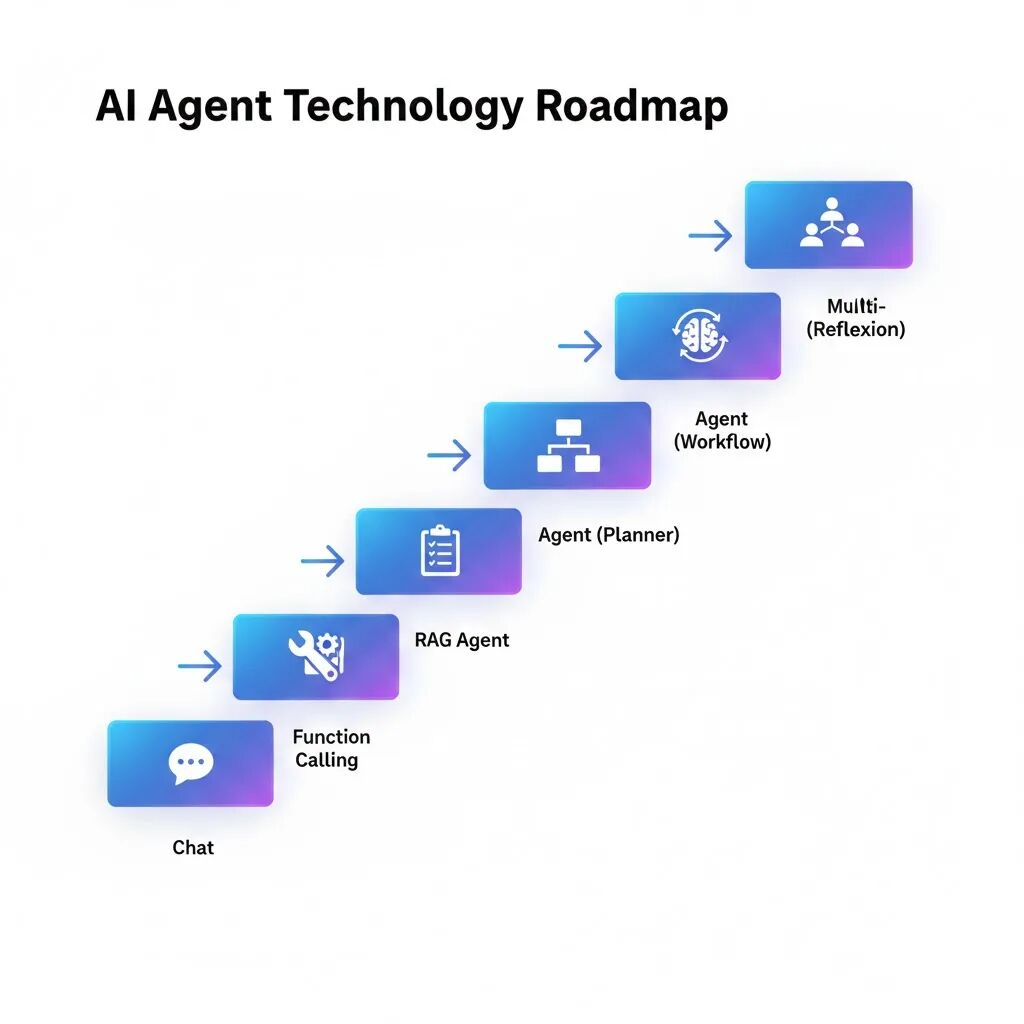
现实中 90% 的可用 Agent,其实停留在 Level 2–4,但已经非常强。
五、一个 AI Agent 的最小实现结构(MVP)
从工程角度看,一个 Agent 至少需要这几样:
用户目标
↓
任务规划(LLM)
↓
行动循环(Agent Loop)
├─ 选择工具
├─ 执行
├─ 读取结果
├─ 更新记忆
└─ 判断是否完成
# 伪代码
while not done:
plan = llm.plan(goal, memory)
action = select_tool(plan)
result = action.execute()
memory.update(result)
done = check_done(memory)
以下是 Agent 的所有“器官”,只差一个控制中枢。
| Agent 模块 | 对应技术 |
|---|---|
| 大脑 | 本地 LLM |
| 记忆 | RAG / JSON / SQLite |
| 工具 | Python / API |
| 行动 | 写代码 / 发消息 / 建待办 |
| 控制 | 一个 while 循环 |
当模型开始为目标负责,而不是为回答负责,
AI 才真正开始“工作”。
实现路线实例:
技术栈(适合 4GB 显卡)
- 本地模型:
deepseek-r1:1.5b(推理/规划)或qwen2.5-coder:1.5b(代码执行更稳) - 推理服务:Ollama
- Agent 框架:自己写一个轻量 Loop(更可控、便于写推文/教学)
- 工具:文件读写、Python 运行、R 运行、Shell(可选,建议受限)
一键起步(环境 & 拉模型)
# 1) 安装 ollama
# 2) 拉取模型(选一个主模型即可)
ollama pull deepseek-r1:1.5b
# 或更偏代码:
ollama pull qwen2.5-coder:1.5b
# 3) python 依赖
pip install -U requests pydantic rich
项目结构
local_agent/
agent.py # 主循环(Planner/Executor/Memory)
tools.py # 工具注册与实现
llm_ollama.py # 调用 Ollama
prompts.py # 系统提示模板
workspace/ # Agent 允许读写的沙箱目录,
#建议限制只在工作路径下进行,后期接入VS code很有必要
核心思想:用“结构化动作”驱动工具调用
Ollama 不保证原生 function-calling 一致,所以我们用强约束输出 JSON:
Agent 每一步让模型只输出下面三种之一:
{"type":"plan","steps":[...]}{"type":"action","tool":"read_file","args":{...}}{"type":"final","answer":"..."}
这样就能稳定解析并执行。
代码:Ollama 调用(llm_ollama.py)
import requests
OLLAMA_URL = "http://127.0.0.1:11434/api/chat"
def chat_ollama(model: str, messages: list[dict], temperature: float = 0.2) -> str:
r = requests.post(
OLLAMA_URL,
json={"model": model, "messages": messages, "stream": False, "options": {"temperature": temperature}},
timeout=180,
)
r.raise_for_status()
return r.json()["message"]["content"]
代码:工具系统(tools.py)
建议:工具只允许在 workspace/ 里读写,避免越权。
from __future__ import annotations
from dataclasses import dataclass
from pathlib import Path
import subprocess, json, textwrap
WORKSPACE = Path("workspace").resolve()
WORKSPACE.mkdir(exist_ok=True)
class ToolError(Exception):
pass
def _safe_path(rel_path: str) -> Path:
p = (WORKSPACE / rel_path).resolve()
if not str(p).startswith(str(WORKSPACE)):
raise ToolError("Path not allowed (outside workspace).")
return p
def read_file(path: str, max_chars: int = 12000) -> str:
p = _safe_path(path)
if not p.exists():
raise ToolError(f"File not found: {path}")
txt = p.read_text(encoding="utf-8", errors="ignore")
return txt[:max_chars]
def write_file(path: str, content: str) -> str:
p = _safe_path(path)
p.parent.mkdir(parents=True, exist_ok=True)
p.write_text(content, encoding="utf-8")
return f"Wrote {len(content)} chars to {path}"
def run_python(code: str) -> str:
"""
在受限模式下运行 python:不提供网络、只在 workspace 下运行文件读写(由代码自控,仍需谨慎)
这里用子进程执行,返回 stdout/stderr。
"""
code = textwrap.dedent(code).strip()
cmd = ["python", "-c", code]
proc = subprocess.run(cmd, capture_output=True, text=True, cwd=str(WORKSPACE))
out = (proc.stdout or "") + (("\n[stderr]\n" + proc.stderr) if proc.stderr else "")
return out[:20000]
TOOLS = {
"read_file": read_file,
"write_file": write_file,
"run_python": run_python,
}
def tool_schema() -> dict:
"""给模型看的工具说明"""
return {
"read_file": {"args": {"path": "string", "max_chars": "int(optional)"}},
"write_file": {"args": {"path": "string", "content": "string"}},
"run_python": {"args": {"code": "string"}},
}
代码:提示词(prompts.py)
SYSTEM_PROMPT = """你是一个本地AI Agent。你的任务是通过“计划-行动-观察-反思”循环完成目标。
你必须严格输出 JSON(不要输出任何额外文字),JSON 只允许三种类型:
1) 计划:
{"type":"plan","steps":["...","..."]}
2) 行动(调用工具):
{"type":"action","tool":"工具名","args":{...}}
3) 最终回答:
{"type":"final","answer":"...(可包含Markdown)"}
规则:
- 工具只允许使用提供的列表;参数必须符合工具说明。
- 如果上一步工具返回错误或信息不足,你要调整策略:再次输出 action(例如先读文件、检查数据、打印报错)。
- 不允许臆造文件内容或执行结果;一切依据工具返回的 observation。
- 当目标已完成,输出 final。
"""
代码:Agent 主循环(agent.py)
import json
from rich import print
from llm_ollama import chat_ollama
from tools import TOOLS, tool_schema, ToolError
MODEL = "qwen2.5-coder:1.5b" # 或 deepseek-r1:1.5b
MAX_TURNS = 12
def safe_json_loads(s: str) -> dict:
s = s.strip()
# 有些模型会包 ```json ... ```,做个兜底剥离
if s.startswith("```"):
s = s.strip("`")
s = s.replace("json", "", 1).strip()
return json.loads(s)
def run_agent(goal: str):
tools = tool_schema()
messages = [
{"role": "system", "content": __import__("prompts").SYSTEM_PROMPT},
{"role": "user", "content": json.dumps({
"goal": goal,
"tools": tools,
"workspace_note": "所有文件读写都在 workspace/ 目录下完成。"
}, ensure_ascii=False)}
]
plan_done = False
for turn in range(1, MAX_TURNS + 1):
raw = chat_ollama(MODEL, messages, temperature=0.2)
print(f"\n[bold cyan]Turn {turn} model output:[/bold cyan]\n{raw}")
try:
obj = safe_json_loads(raw)
except Exception as e:
# 解析失败:要求模型纠正输出
messages.append({"role": "assistant", "content": raw})
messages.append({"role": "user", "content": json.dumps({
"error": f"你的输出不是合法 JSON:{e}. 请严格按三种 JSON 类型之一重写。"
}, ensure_ascii=False)})
continue
t = obj.get("type")
if t == "plan":
plan_done = True
messages.append({"role": "assistant", "content": raw})
# 推进到下一步:让它开始行动
messages.append({"role": "user", "content": json.dumps({
"ok": True,
"instruction": "请开始执行第1步。需要工具就输出 action。"
}, ensure_ascii=False)})
continue
if t == "action":
tool = obj.get("tool")
args = obj.get("args", {})
if tool not in TOOLS:
messages.append({"role": "assistant", "content": raw})
messages.append({"role": "user", "content": json.dumps({
"error": f"工具不存在:{tool}。可用工具:{list(TOOLS.keys())}"
}, ensure_ascii=False)})
continue
try:
result = TOOLS[tool](**args)
obs = {"tool": tool, "args": args, "result": result}
except Exception as e:
obs = {"tool": tool, "args": args, "error": str(e)}
messages.append({"role": "assistant", "content": raw})
messages.append({"role": "user", "content": json.dumps({
"observation": obs,
"instruction": "基于 observation 决定下一步:继续 action 或 final。"
}, ensure_ascii=False)})
continue
if t == "final":
return obj.get("answer", "")
# 未知 type
messages.append({"role": "assistant", "content": raw})
messages.append({"role": "user", "content": json.dumps({
"error": f"未知 type:{t}。只能是 plan/action/final。"
}, ensure_ascii=False)})
return "❌ 超出最大轮次,任务未完成。建议缩小目标或增加工具。"
if __name__ == "__main__":
goal = "在 workspace 下新建一个 report.md:写一段 AI Agent 的定义(100字),再列出技术路线 Level0-6 的要点。"
answer = run_agent(goal)
print("\n[bold green]FINAL:[/bold green]\n", answer)
运行:
python agent.py
在1.5b的小模型中,效果并不佳,建议换高参数模型。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
作为一名老互联网人,看着AI越来越火,也总想为大家做点啥。干脆把我这几年整理的AI大模型干货全拿出来了。
包括入门指南、学习路径图、精选书籍、视频课,还有我录的一些实战讲解。全部免费,不搞虚的。
学习从来都是自己的事,我能做的就是帮你把路铺平一点。资料都放在下面了,有需要的直接拿,能用到多少就看你自己了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以点击文章最下方的VX名片免费领取【保真100%】

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)