
大模型应用开发 langchain 之 langchain 入门
langchain 不仅支持 Python 生态,也支持 TypeScript/JavaScript 生态,意味着开发者可以使用 JS 生态开发 AI 应用。
什么 langchain ?
LangChain是一个用于开发由大型语言模型( LLMs )支持的应用程序的框架。
从下面开始我们认知常用的 langchain 常用的生态库以及知识点。
资源库
langchain 有自己的生态,下面是 langchain 生态的一些常用的资源:
langchain 不仅支持 Python 生态,也支持 TypeScript/JavaScript 生态,意味着开发者可以使用 JS 生态开发 AI 应用。
目前的 langchain 的版本是: v0.3+。langchain 集成众多的 llm 和组件,使得 AI 开发变得容易。
langchain 经典架构图
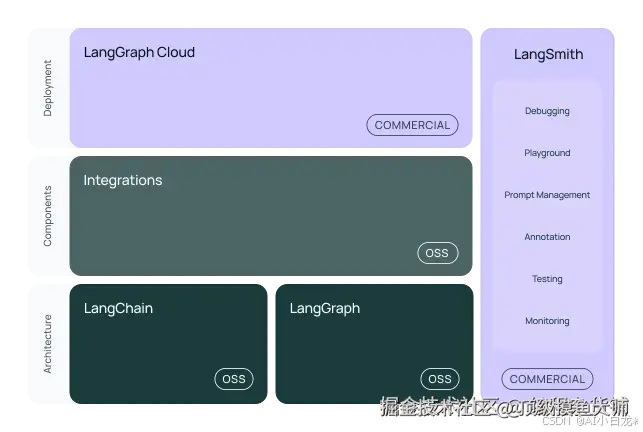
LCEL
LCEL 全称 LangChain Expression Language,是一种创建任意自定义链的方法。
核心模块和安装
langchain 目前是 v0.3+ 版本,如果使用了旧版本,可能有内容发生了变化。这里还是以 Python 为例:
如果你是使用 pip 作为安装工具:
sh
代码解读
pip install langchain-core
pip install langchain
pip install langsmith
pip install -U langgraph
pip install "langserve[all]"
pip install -U langchain-cli
# 社区
pip install langchain_community
# 大模型
pip install langchain-openai
pip install -qU langchain-anthropic
langchain 组件
langchain 提供了很多的组件帮助开发方便的开发 LLM 应用:
| 术语 | 说明 |
|---|---|
| Prompt Template | 提示词模板,用于定义输入给模型的格式和内容。 |
| Example selectors | 示例选择器,用于从一组示例中选择适当的示例以供参考或生成响应。 |
| Chat models | 聊天模型,专门设计用于与用户进行对话和互动的语言模型。 |
| Messages | 消息,指用户与模型之间的交流内容。 |
| LLM | 大模型(旧语言模型),指大型预训练语言模型,通常用于生成和理解文本。 |
| Output parsers | 输出解释器,用于处理和格式化模型生成的输出,使其更易于使用。 |
| Document loaders | 文档加载器,用于将文档内容加载到系统中以便处理和分析。 |
| Text splitters | 文本分割器,用于将长文本分割成较小的部分,以便更好地处理和分析。 |
| Embedding models | 嵌入模型,将文本转换为向量表示,以便进行相似度计算和检索。 |
| Vector stores | 向量存储,保存向量数据的数据库或系统,以支持高效的检索和查询。 |
| Retrievers | 检索器,负责从存储中获取相关数据或信息的组件。 |
| Indexing | 索引,建立数据结构以支持快速搜索和检索。 |
| Tools | 工具,辅助完成特定任务的软件组件或功能。 |
| Multimodal | 多模型,涉及处理和分析多种数据类型(如文本、图像等)的能力。 |
| Agents | 代理(智能体),自动化执行特定任务的智能系统或程序。 |
| Callbacks | 回调,允许在特定事件发生时执行自定义代码的机制。 |
| 自定义组件 | 用户自定义的模块或功能,以扩展系统的功能或适应特定需求。 |
py
代码解读
# PromptTemplate, ChatPromptTemplate
from langchain_core.prompts import PromptTemplate, ChatPromptTemplate
prompt_template = PromptTemplate.from_template("Tell me a joke about {topic}")
prompt_template = ChatPromptTemplate([
("system", "You are a helpful assistant"),
("user", "Tell me a joke about {topic}")
])
prompt_template.invoke({"topic": "cats"})
# example_selector
class BaseExampleSelector(ABC):
"""Interface for selecting examples to include in prompts."""
@abstractmethod
def select_examples(self, input_variables: Dict[str, str]) -> List[dict]:
"""Select which examples to use based on the inputs."""
@abstractmethod
def add_example(self, example: Dict[str, str]) -> Any:
"""Add new example to store."""
prompt = FewShotPromptTemplate(
example_selector=example_selector,
# ...
)
# chat model
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o-mini")
# message
from langchain_core.messages import HumanMessage
model.invoke([HumanMessage(content="Hello, how are you?")])
# llm
from langchain_openai import OpenAI
llm = OpenAI(model="gpt-3.5-turbo-instruct", n=2, best_of=2)
# outparser str
from langchain_core.output_parsers import StrOutputParser
parser = StrOutputParser()
# loader
from langchain_community.document_loaders.csv_loader import CSVLoader
from langchain_community.document_loaders import PyPDFLoader
# langchain_text_splitters
from langchain_text_splitters import CharacterTextSplitter
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base", chunk_size=100, chunk_overlap=0
)
texts = text_splitter.split_text(document)
# embedding_models: OpenAIEmbeddings 和 HuggingFaceEmbeddings and ZhipuAIEmbeddings
from langchain_openai import OpenAIEmbeddings
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_community.embeddings import ZhipuAIEmbeddings
# vectorstores
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_community.vectorstores import FAISS
from langchain_chroma import Chroma
vectorstore = InMemoryVectorStore.from_texts(
[txt_content],
embedding=embeddings,
)
vectorstore = FAISS.from_documents(texts, embeddings)
vector_store = Chroma(
collection_name="example_collection",
embedding_function=embeddings,
persist_directory="./chroma_langchain_db", # Where to save data locally, remove if not necessary
)
# retriever invoke
retriever = vectorstore.as_retriever()
docs = retriever.invoke("what did the president say about ketanji brown jackson?")
# index
from langchain.indexes import SQLRecordManager, index
# tools
from langchain_core.tools import tool
@tool
def multiply(a: int, b: int) -> int:
"""Multiply two numbers."""
return a * b
# agent
from langchain.agents import AgentExecutor
agent = (
{
"input": lambda x: x["input"],
"agent_scratchpad": lambda x: format_to_openai_tool_messages(
x["intermediate_steps"]
),
"chat_history": lambda x: x["chat_history"],
}
| prompt
| llm_with_tools
| OpenAIToolsAgentOutputParser()
)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
## langgraph create_tool_calling_agent
from langchain.agents import create_tool_calling_agent
agent = create_tool_calling_agent(model, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools)
## langgraphcreate_react_agent
from langgraph.prebuilt import create_react_agent
langgraph_agent_executor = create_react_agent(model, tools)
# callbacks
from langchain_core.callbacks import BaseCallbackHandler
callbacks = [LoggingHandler()]
chain = prompt | llm
chain.invoke({"number": "2"}, config={"callbacks": callbacks})
大模型
在大模型应用中开发中,大模型直接用的是:
- chat 大模型
- embedding 大模型
常用的大模型和运行器
- OpenAI/AzureOpenAI/OpenAIEmbeddings
- Anthropic
- vertexai
- huggingface
- aws
- ollama
- ZhipuAI
- MistralAI
- Baidu Qianfan
- …
向量数据库
运行环境
运行大模型,其实可以用不同的 python 运行环境
- 硬编码:使用编辑器硬编码
- jupyter notebook: python 代码能够分段,缓存数据,结构清晰, jupyter 推荐配合 vscode 使用,可以使用通用的编辑器。
- google 的 Colab notebooks, Colab 赠送不少的内存,对于小的应用基本够用了。如果没有使用过大概是这样的
一个简单的聊天
我们使用 zhipuAI,为什么?因为 zhipu AI 的 glm-4-flash 目前是免费调用。
如果还没有注册的新进入大模型应用开发的,可以考虑使用zhipu AI,质谱的支持自己的 sdk, 和 openAI 的方式以及 langchain 的 openAI 的方式调用大模型。
同时质朴也有 embeddings 模型速度可以,在初期学习已经够用了。
首先需要创建一个 .env 文件将质谱 AI 的 key 保存起来,方便访问。
.env
代码解读
OPENAI_API_KEY = your_zhupu_ai_key
langchain_openai 使用 ChatOpenAI 调用质谱 AI 的 glm-4-flash 大模型。同时我们需要传入 openai_api_base 地址。
py
代码解读
import dotenv
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
key = dotenv.get_variable(".env", "OPENAI_API_KEY") # 不同的版本不一样
model = ChatOpenAI(
temperature=0.95,
model="glm-4-flash",
openai_api_key=key,
openai_api_base="https://open.bigmodel.cn/api/paas/v4/"
)
# 消息
messages = [
SystemMessage(content="Translate the following from English into Italian"),
HumanMessage(content="hi!"),
]
# invoke 调用模型
model.invoke(messages)
# 格式化输出
parser = StrOutputParser()
result = model.invoke(messages)
parser.invoke(result)
# 使用 chain 链
chain = model | parser
chain.invoke(messages)、
# 使用提示词
system_template = "Translate the following into {language}:"
prompt_template = ChatPromptTemplate.from_messages(
[("system", system_template), ("user", "{text}")]
)
chain = prompt_template | model | parser
chain.invoke({"language": "italian", "text": "hi"})
小结
本文主要介绍 Langchian 的基本基本概念,组件、生态内容。以及常用的大模型,向量数据库 embedding 以及使用 zhipu ai 配合 ChatOpenAI 实现一个简单的 chatmodel 的例子。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 20
20 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)