
从零搭建一个基于 DeepSeek API 的 Python 编程型智能体 CodePilot
一、项目背景
最近我尝试用 Python 设计一个属于自己的编程型智能体,目标不是简单地做一个聊天机器人,而是希望它能够真正参与到编程工作中,比如:
-
读取项目文件
-
创建和修改代码
-
运行 Python 脚本
-
自动执行测试
-
根据运行结果继续修复问题
-
保存一些长期记忆,例如代码风格、测试命令、项目习惯
-
通过 DeepSeek API 实现自然语言控制
经过初步实现后,项目已经可以正常运行。作为第一个版本,整体效果是可接受的。后续如果有时间,还可以继续优化工具调用逻辑、任务规划能力、代码修改算法和多轮调试能力。
本文主要记录这个项目的设计思路、核心结构、使用方式和运行效果。为了避免文章过长,本文不会贴出完整源码,只展示核心框架和关键代码思路。
二、项目目标
这个项目的定位是一个 编程型智能体 CodePilot。
它和普通聊天机器人的区别在于:
普通聊天机器人更多是:
用户提问 → 模型回答而编程型智能体希望做到:
用户提出编程任务
↓
智能体分析任务
↓
决定是否需要调用工具
↓
读取文件 / 写入文件 / 执行代码 / 运行测试
↓
根据工具结果继续判断
↓
最终给出完成结果也就是说,它不仅要“会说”,还要“会做”。
三、技术栈
本项目主要使用:
Python
DeepSeek API
SQLite
JSON 工具调用协议
文件系统操作
subprocess 执行命令
命令行交互整体没有使用特别复杂的第三方框架,主要是为了方便理解智能体底层运行逻辑。
四、整体架构设计
项目大体分为以下几个部分:
CodePilot 编程型智能体
│
├── main.py # 程序启动入口
├── config.py # 配置读取
├── llm.py # DeepSeek API 客户端
├── agent.py # 智能体核心循环
├── memory.py # SQLite 长期记忆
├── logger_setup.py # 日志配置
│
├── tools/
│ ├── base.py # 工具基类和工具注册表
│ ├── file_tools.py # 文件读写工具
│ ├── code_tools.py # 代码运行与测试工具
│ ├── git_tools.py # Git 相关工具
│ ├── memory_tools.py # 记忆工具
│ └── project_tools.py # 项目结构分析工具
│
└── workspace/
└── .agent/
├── memory.sqlite3
└── logs/这里最核心的是三个模块:
agent.py
llm.py
tools/其中:
-
llm.py负责和 DeepSeek API 通信 -
agent.py负责智能体的思考与工具调用循环 -
tools/负责给智能体提供实际操作能力
五、为什么要设计工具系统
如果智能体只能调用大模型,那它最多只能生成代码文本。
但如果我们给它工具,它就可以真正操作项目。
例如:
read_file 读取文件
write_file 写入文件
replace_text 替换代码片段
run_python 运行 Python 文件
run_tests 执行测试
list_files 查看项目结构
remember 保存长期记忆
recall 读取长期记忆这样一来,用户输入:
帮我创建一个 hello.py,运行后输出 Hello DeepSeek Agent智能体内部就可能执行:
1. 调用 write_file 创建 hello.py
2. 调用 run_python_file 运行 hello.py
3. 根据运行结果判断任务是否完成
4. 最终告诉用户执行成功六、DeepSeek API 配置方式
为了安全,API Key 不能直接写进代码里。
推荐使用 .env 文件或环境变量保存。
例如在项目根目录创建 .env 文件:
DEEPSEEK_API_KEY=你的DeepSeek_API_Key
DEEPSEEK_BASE_URL=https://api.deepseek.com
DEEPSEEK_MODEL=你的模型名称如果使用 Windows CMD,也可以临时设置:
set DEEPSEEK_API_KEY=你的DeepSeek_API_Key
set DEEPSEEK_BASE_URL=https://api.deepseek.com
set DEEPSEEK_MODEL=你的模型名称
python main.py如果使用 PowerShell,可以这样设置:
$env:DEEPSEEK_API_KEY="你的DeepSeek_API_Key"
$env:DEEPSEEK_BASE_URL="https://api.deepseek.com"
$env:DEEPSEEK_MODEL="你的模型名称"
python main.py七、核心配置模块设计
配置模块主要负责读取工作区路径、API Key、模型名称、超时时间等。
大体框架如下:
from dataclasses import dataclass
from pathlib import Path
import os
@dataclass
class Settings:
workspace: Path
api_key: str
base_url: str
model: str
command_timeout: int
max_steps: int
require_confirmation: bool
def load_settings() -> Settings:
workspace = Path("workspace").resolve()
workspace.mkdir(parents=True, exist_ok=True)
return Settings(
workspace=workspace,
api_key=os.getenv("DEEPSEEK_API_KEY", ""),
base_url=os.getenv("DEEPSEEK_BASE_URL", "https://api.deepseek.com"),
model=os.getenv("DEEPSEEK_MODEL", "your-model-name"),
command_timeout=30,
max_steps=8,
require_confirmation=True,
)这里有一个关键点:
api_key=os.getenv("DEEPSEEK_API_KEY", "")程序不会把密钥写死,而是从环境变量读取。
八、DeepSeek 客户端设计
llm.py 的作用是封装大模型调用。
它只负责一件事:
把 messages 发给 DeepSeek API
拿回模型返回的文本大体框架如下:
import requests
class DeepSeekClient:
def __init__(self, api_key: str, base_url: str, model: str):
self.api_key = api_key
self.base_url = base_url.rstrip("/")
self.model = model
@property
def enabled(self) -> bool:
return bool(self.api_key)
def chat(self, messages: list[dict]) -> str:
url = f"{self.base_url}/chat/completions"
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json",
}
payload = {
"model": self.model,
"messages": messages,
"temperature": 0.2,
}
response = requests.post(url, headers=headers, json=payload, timeout=60)
response.raise_for_status()
data = response.json()
return data["choices"][0]["message"]["content"]这一层不关心智能体怎么调用工具,也不关心用户任务是什么,只负责 API 通信。
九、工具注册系统设计
为了让智能体可以调用不同工具,需要一个统一的工具注册表。
每个工具包含:
工具名称
工具描述
工具参数
工具处理函数
风险等级核心框架如下:
from dataclasses import dataclass
from typing import Callable, Any
@dataclass
class Tool:
name: str
description: str
schema: dict
handler: Callable[..., str]
risk: str = "low"
def run(self, arguments: dict[str, Any]) -> str:
return self.handler(**arguments)
class ToolRegistry:
def __init__(self):
self.tools = {}
def register(self, tool: Tool):
self.tools[tool.name] = tool
def get(self, name: str) -> Tool | None:
return self.tools.get(name)
def descriptions(self) -> list[dict]:
return [
{
"name": tool.name,
"description": tool.description,
"schema": tool.schema,
"risk": tool.risk,
}
for tool in self.tools.values()
]这样后续新增工具会很方便,只要注册进去即可。
十、文件工具设计
文件工具是编程型智能体最基础的能力。
主要包括:
list_files 列出文件
read_file 读取文件
write_file 写入文件
append_file 追加内容
replace_text 替换文本
search_text 搜索文本核心设计思想是:
所有文件操作都限制在 workspace 工作区内
禁止访问工作区外部路径
写入文件前可开启备份
高风险操作需要确认大体框架如下:
from pathlib import Path
def resolve_workspace_path(workspace: Path, path: str) -> Path:
target = (workspace / path).resolve()
if not str(target).startswith(str(workspace)):
raise ValueError("禁止访问工作区之外的路径")
return target
def read_file(workspace: Path, path: str) -> str:
file_path = resolve_workspace_path(workspace, path)
return file_path.read_text(encoding="utf-8")
def write_file(workspace: Path, path: str, content: str) -> str:
file_path = resolve_workspace_path(workspace, path)
file_path.parent.mkdir(parents=True, exist_ok=True)
file_path.write_text(content, encoding="utf-8")
return f"已写入文件:{path}"这个模块最重要的不是代码复杂度,而是安全边界。
因为智能体拥有文件写入能力,如果不限制路径,可能会误操作系统文件。
十一、代码执行工具设计
代码执行工具主要负责运行 Python 文件和测试命令。
例如:
run_python_file
run_tests
run_shell_command大体框架如下:
import subprocess
import sys
from pathlib import Path
def run_python_file(workspace: Path, path: str, timeout: int = 30) -> str:
file_path = workspace / path
result = subprocess.run(
[sys.executable, str(file_path)],
cwd=workspace,
capture_output=True,
text=True,
timeout=timeout,
)
return f"""
退出码:{result.returncode}
stdout:
{result.stdout}
stderr:
{result.stderr}
"""运行代码是一个高风险操作,所以我在项目里加入了确认机制。
当智能体准备执行代码时,会提示用户:
需要确认高风险操作:
工具:run_python_file
风险:execute
是否执行?输入 y 执行,其他任意键取消:这样可以避免模型自动执行一些不安全命令。
十二、记忆系统设计
为了让智能体记住长期偏好,我使用 SQLite 实现了简单记忆系统。
例如可以记住:
我的代码风格
项目使用的测试命令
常用技术栈
命名习惯
是否优先使用 pathlib大体框架如下:
import sqlite3
import time
class SQLiteMemory:
def __init__(self, db_path):
self.db_path = db_path
self.init_db()
def init_db(self):
with sqlite3.connect(self.db_path) as conn:
conn.execute("""
CREATE TABLE IF NOT EXISTS memories (
key TEXT PRIMARY KEY,
value TEXT NOT NULL,
updated_at REAL NOT NULL
)
""")
def set(self, key: str, value: str):
with sqlite3.connect(self.db_path) as conn:
conn.execute("""
INSERT INTO memories(key, value, updated_at)
VALUES (?, ?, ?)
ON CONFLICT(key)
DO UPDATE SET value = excluded.value,
updated_at = excluded.updated_at
""", (key, value, time.time()))
def get(self, key: str) -> str:
with sqlite3.connect(self.db_path) as conn:
row = conn.execute(
"SELECT value FROM memories WHERE key = ?",
(key,)
).fetchone()
return row[0] if row else ""使用示例:
记住我的代码风格:Python 使用类型注解,函数尽量短,优先使用 pathlib后续再让智能体生成代码时,它就可以参考这个偏好。
十三、智能体核心循环
整个项目最核心的是 agent.py。
智能体并不是一次性回答,而是一个循环:
接收用户任务
↓
构造系统提示词
↓
调用 DeepSeek
↓
解析模型返回的 JSON
↓
判断 action
↓
如果是工具,则执行工具
↓
把工具结果反馈给模型
↓
继续下一轮
↓
直到模型返回 finish大体框架如下:
class CodingAgent:
def __init__(self, settings, llm, registry):
self.settings = settings
self.llm = llm
self.registry = registry
def answer(self, user_input: str) -> str:
messages = [
{"role": "system", "content": self.build_system_prompt()},
{"role": "user", "content": user_input},
]
for step in range(self.settings.max_steps):
raw = self.llm.chat(messages)
decision = self.parse_json(raw)
action = decision.get("action")
action_input = decision.get("action_input", {})
if action == "finish":
return decision.get("final", "任务完成")
tool = self.registry.get(action)
observation = tool.run(action_input)
messages.append({
"role": "assistant",
"content": raw,
})
messages.append({
"role": "user",
"content": f"工具执行结果:{observation}",
})
return "达到最大执行步数,任务未完全完成。"这里有一个很关键的点:
模型不能随便输出自然语言,而是被要求输出固定 JSON,例如:
{
"thought": "我需要先创建 hello.py 文件",
"action": "write_file",
"action_input": {
"path": "hello.py",
"content": "print('Hello DeepSeek Agent')"
},
"final": ""
}如果任务完成,则输出:
{
"thought": "文件已经创建并运行成功",
"action": "finish",
"action_input": {},
"final": "已创建 hello.py,并验证运行成功。"
}这样 Python 程序才能稳定解析模型意图,并调用对应工具。
十四、安全机制设计
编程型智能体一定要考虑安全问题。
因为它具有:
写文件能力
运行代码能力
执行命令能力
读取项目文件能力所以必须加限制。
我在项目里做了几层保护:
1. 工作区沙盒
所有文件操作只能发生在 workspace 目录下。
例如:
允许:
workspace/hello.py
禁止:
../system_file.txt
C:/Users/xxx/Desktop/private.txt2. 高风险操作确认
对于写文件、运行代码、执行命令等操作,需要用户确认。
示例:
需要确认高风险操作:
工具:write_file
风险:write
是否执行?输入 y 执行,其他任意键取消:3. API Key 不写入代码
API Key 通过环境变量读取,不硬编码到 Python 文件中。
4. 日志记录
每次运行会记录日志,方便排查问题。
日志目录大体为:
workspace/.agent/logs/5. 命令白名单
对于 shell 命令,不建议完全开放。
更安全的做法是只允许:
python
git
dir
ls
type
cat危险命令应该禁止或要求二次确认。
十五、启动入口设计
main.py 负责启动程序。
大体框架如下:
def main():
settings = load_settings()
agent = build_agent(settings)
print("DeepSeek CodePilot 编程型智能体已启动")
print(f"工作区:{settings.workspace}")
print(f"模型:{settings.model}")
if agent.llm.enabled:
print("模式:DeepSeek 自然语言智能体模式")
else:
print("模式:本地命令模式")
while True:
user_input = input("你:").strip()
if user_input in {"/exit", "exit", "quit", "退出"}:
break
response = agent.answer(user_input)
print(f"\nCodePilot:\n{response}")程序启动后,如果检测到 API Key,就进入自然语言智能体模式。
如果没有检测到 API Key,则进入本地命令模式。
十六、项目运行方式
1. 进入项目目录
cd your_project_path这里的 your_project_path 替换为自己的项目目录即可,不建议在文章或截图中暴露真实电脑路径。
2. 设置环境变量
set DEEPSEEK_API_KEY=你的DeepSeek_API_Key
set DEEPSEEK_BASE_URL=https://api.deepseek.com
set DEEPSEEK_MODEL=你的模型名称3. 启动程序
python main.py如果看到类似信息:
DeepSeek CodePilot 编程型智能体已启动
模式:DeepSeek 自然语言智能体模式说明 API Key 已经配置成功。
十七、实际测试任务
我先测试了一个最简单的任务:
帮我创建一个 hello.py,运行后输出 Hello DeepSeek Agent智能体执行流程大概是:
1. 模型判断需要创建文件
2. 调用 write_file 工具
3. 用户确认写入
4. 创建 hello.py
5. 模型判断需要运行文件
6. 调用 run_python_file 工具
7. 用户确认执行
8. 程序输出 Hello DeepSeek Agent
9. 智能体返回验证通过其中生成的 hello.py 内容非常简单:
print("Hello DeepSeek Agent")最终智能体返回:
已创建 hello.py,运行后输出 Hello DeepSeek Agent,验证通过。这个测试说明:
DeepSeek API 调用正常
JSON 决策循环正常
工具调用正常
文件写入正常
代码执行正常
高风险操作确认正常十八、效果图展示
下面预留 4 张实际运行效果图。
图 1:Shell 中启动智能体成功

图 2:Shell 中修改py文件
图 3:PyCharm 中创建并运行 hello.py
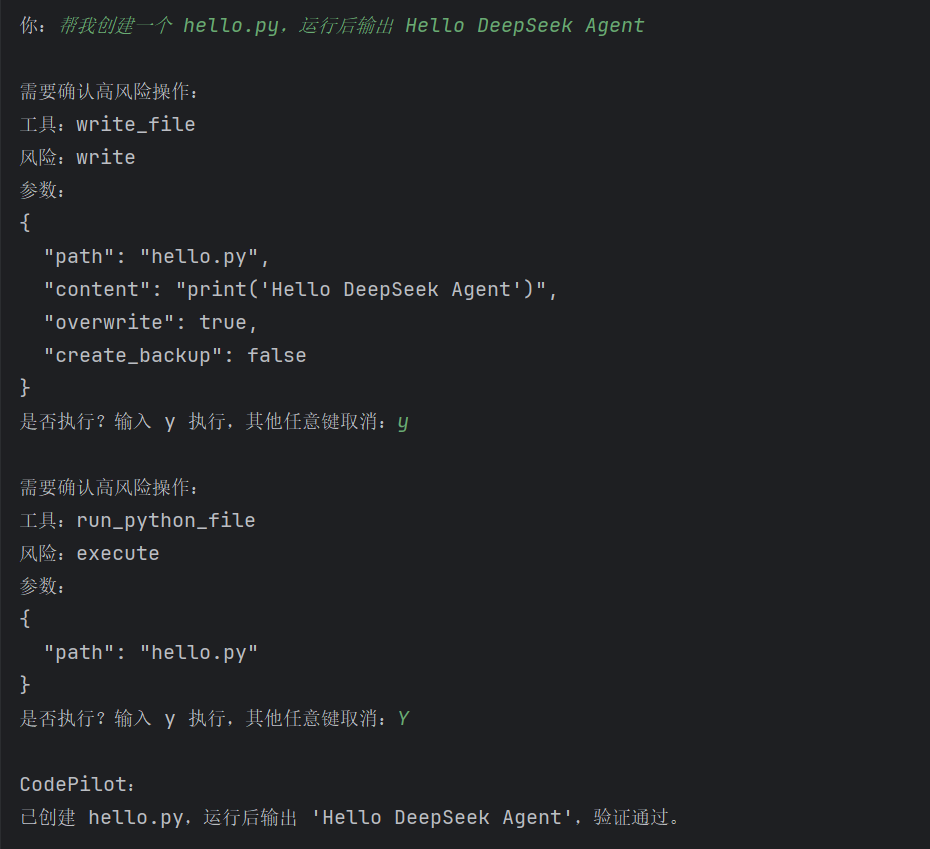
图 4:PyCharm 中查找创建的 hello.py

十九、遇到的问题和解决方法
问题 1:程序提示未检测到 API Key
一开始启动时,如果看到:
未检测到 DEEPSEEK_API_KEY说明当前 Python 运行环境没有读取到密钥。
解决方式:
set DEEPSEEK_API_KEY=你的DeepSeek_API_Key
python main.py或者在 .env 文件中配置:
DEEPSEEK_API_KEY=你的DeepSeek_API_Key需要注意的是:
.env 文件要放在项目根目录
不要命名成 .env.txt
等号两边不要有空格
PyCharm 和 CMD 的环境变量可能不是同一个环境问题 2:CMD 中检测不到环境变量
可以用下面命令测试:
python -c "import os; print('已检测到' if os.getenv('DEEPSEEK_API_KEY') else '未检测到')"如果显示:
未检测到说明当前终端没有设置成功。
CMD 中正确写法是:
set DEEPSEEK_API_KEY=你的DeepSeek_API_KeyPowerShell 中正确写法是:
$env:DEEPSEEK_API_KEY="你的DeepSeek_API_Key"这两个命令不能混用。
问题 3:文件创建后短时间内没有查到
测试时发现,有时刚创建完文件后,询问文件位置可能会出现短暂判断不稳定。
但直接查看工作区目录,可以找到文件。
例如:
dir workspace或者:
type workspace\hello.py这个问题后续可以通过优化工具调用策略解决,例如当用户问“文件在哪里”时,强制先调用 list_files,而不是直接让模型凭上下文回答。
二十、当前版本的不足
这个项目目前只是初始版本,还有很多可以优化的地方。
1. 工具选择算法还可以优化
目前模型根据提示词自行决定调用哪个工具。
后续可以加入更稳定的规则,例如:
用户问文件位置 → 优先调用 list_files
用户问文件内容 → 优先调用 read_file
用户要求运行 → 调用 run_python_file
用户要求测试 → 调用 run_tests这样可以减少模型误判。
2. 代码修改方式还可以优化
当前版本可以直接写入文件,但更理想的方式是使用补丁:
读取原文件
生成 diff
用户确认
应用 patch
运行测试这样会更安全,也更适合真实项目。
3. 项目索引能力还可以增强
后续可以加入项目索引器,自动分析:
项目入口文件
依赖文件
测试目录
核心模块
函数和类结构这样智能体面对大型项目时会更稳定。
4. 多轮调试能力还可以增强
理想状态下,智能体应该可以:
运行测试失败
↓
读取错误信息
↓
定位相关文件
↓
修改代码
↓
再次运行测试
↓
直到测试通过当前版本已经具备基础能力,但还可以继续优化任务规划和错误分析。
二十一、后续优化方向
后续如果继续完善,我计划从以下几个方向入手。
1. 增加代码 diff 展示
每次修改文件前,先展示修改前后的差异。
例如:
- old code
+ new code这样用户可以更清楚智能体改了什么。
2. 增加补丁式修改
相比直接覆盖文件,补丁式修改更安全。
流程可以设计成:
read_file
↓
generate_patch
↓
show_diff
↓
user_confirm
↓
apply_patch3. 增加项目索引数据库
可以将项目中的类、函数、文件摘要保存起来,方便智能体快速理解项目结构。
4. 增加 Web 页面
目前是命令行版本,后续可以做成:
FastAPI 后端
Vue / React 前端
Web 聊天界面
文件管理面板
工具调用日志面板5. 增加多智能体协作
例如拆分成:
架构师 Agent
编码 Agent
测试 Agent
代码审查 Agent
文档 Agent不同智能体负责不同任务。
二十二、总结
这次项目实现了一个基于 DeepSeek API 的 Python 编程型智能体 CodePilot。
它已经具备了一个编程助手的基础能力:
自然语言交互
DeepSeek API 调用
文件读写
代码运行
测试执行
高风险操作确认
SQLite 长期记忆
日志记录
工作区沙盒保护通过测试,智能体可以根据自然语言任务创建 Python 文件,并运行验证结果。
虽然当前还只是初始版本,算法和工具调用策略还不够完善,但整体流程已经跑通,说明这个方向是可行的。
后续只要继续优化工具选择、项目索引、补丁修改、测试反馈和多轮调试能力,就可以逐步把它打造成一个更加实用的个人编程智能体。
这次实践最大的收获是:
智能体的核心不是单纯调用大模型,
而是让大模型学会规划任务、调用工具、观察结果、继续行动。当模型拥有了工具能力之后,它就不再只是一个问答系统,而是可以真正参与实际开发流程的自动化助手。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)