
从零实操 Spring AI 第 4 篇:接入 Ollama,本地也能跑模型
·
远程模型很好用,但学习阶段总会遇到网络、成本、限流和 Key 管理问题。
所以我想加一个本地模型方案。
这一篇接入 Ollama。
答案先说
这一篇只做一件事:配置 Spring AI 调用 Ollama 本地模型。
读完并跟着做完后,项目会有一个明确的新增能力,而不是只停留在概念介绍。
上一篇做到哪了
第 3 篇我们完成了流式输出、系统提示词和结构化返回。
这篇会在上一节的基础上继续往前走。
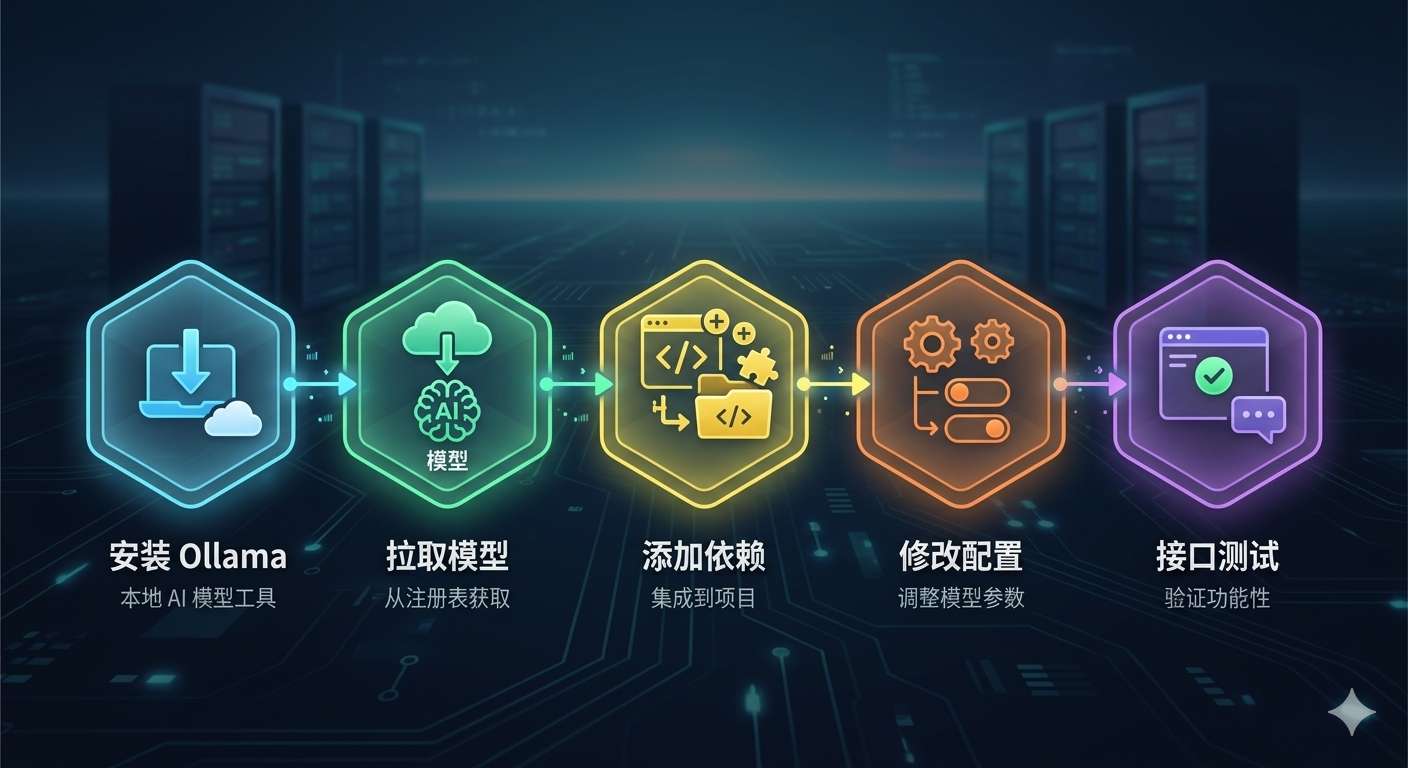
这张图就是本篇的主线。先把流程看清楚,再进入代码会轻松很多。
核心概念
Ollama 可以让我们在本地运行大语言模型。
它不一定适合所有生产场景,但非常适合学习、验证、离线开发和频繁调试。
开始实操
1. 验证 Ollama
ollama --version
2. 拉取模型
ollama pull qwen2.5
3. 添加依赖
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-ollama</artifactId>
</dependency>
4. 添加配置
spring:
ai:
ollama:
base-url: http://localhost:11434
chat:
options:
model: qwen2.5
运行效果
这里后续补充本地模型调用结果。
踩坑记录
这里先列出本篇最可能遇到的问题,后面实操时再补充真实截图和日志。
- Ollama 服务没有启动
- 模型名称和配置不一致
- 本地机器性能不足导致响应慢
- OpenAI 和 Ollama 配置同时存在时,不清楚实际调用的是哪个模型
项目里怎么理解
本地模型最大的价值是降低试错成本。后面做 RAG、Prompt 调整和 Tool Calling 时,会有大量反复实验,本地环境能让学习节奏更顺。
本篇小结
这一篇完成的不是一个孤立知识点,而是让项目继续向最终的“企业知识库问答助手”靠近了一步。
下一篇预告
下一篇我们正式进入 RAG,先准备、读取并切分知识库文档。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)