
【Python大语言模型系列】LangChain 中 Deep Agent 与 SKILL 的集成实践:学术论文搜索智能体(案例+源码)
LangChain 中 Deep Agent 与 SKILL 的集成实践:学术论文搜索智能体(案例+源码)
这是我的第467篇原创文章。
一、引言
Deep Agent 是什么?
Deep Agent 是 LangChain 团队推出的一个高级智能体运行框架,主要用来解决老式 Agent 在面对长时间、复杂任务时容易出错或者卡住的问题,它具备自动规划、本地存取中间数据、调用子智能体以及通过中间件扩展功能等核心能力。
SKILL 是什么?
SKILL 是一种轻量级的功能扩展方式,想法来自 Anthropic 的工具设计理念,每个 SKILL 通常由两部分组成:一个是叫 SKILL.md 的描述文件,用 YAML 格式写清楚这个技能叫什么、能干啥、需要什么输入、返回什么结果;另一个是具体的执行脚本(比如 arxiv_search.py),里面是一个真正的 Python 函数,负责完成实际工作。Agent 会通过 SkillsMiddleware 自动扫描指定目录,发现这些技能并加载它们,在需要时直接调用,完全不用在代码里硬编码工具列表。
deepagents.create_deep_agent
create_deep_agent(
model: str | BaseChatModel | None = None,
tools: Sequence[BaseTool | Callable | dict[str, Any]] | None = None,
system_prompt: str | SystemMessage | None = None,
middleware: Sequence[AgentMiddleware] = (),
subagents: Sequence[SubAgent | CompiledSubAgent | AsyncSubAgent] | None = None,
skills: list[str] | None = None,
memory: list[str] | None = None,
permissions: list[FilesystemPermission] | None = None,
backend: BackendProtocol | BackendFactory | None = None,
interrupt_on: dict[str, bool | InterruptOnConfig] | None = None,
response_format: ResponseFormat[ResponseT] | type[ResponseT] | dict[str, Any] | None = None,
context_schema: type[ContextT] | None = None,
checkpointer: Checkpointer | None = None,
store: BaseStore | None = None,
debug: bool = False,
name: str | None = None,
cache: BaseCache | None = None,
) -> CompiledGraph二、实现过程
2.1 第一步:安装依赖
先在命令行运行下面这行命令,把需要的包都装好:
pip install langchain-core langchain langchain-community deepagents2.2 第二步:写一个 SKILL
我们拿“在 ArXiv 上搜索学术论文”当例子,在项目根目录下新建一个文件夹 skills/arxiv-search/,然后在里面放两个文件:
首先是 SKILL.md,注意这里必须用 YAML frontmatter 格式,不能写成表格:
---
name: arxiv_search
description: 用关键词在 ArXiv 上找最新的学术论文
parameters:
- name: query
type: string
description: 搜索用的关键词
output: 返回包含标题、摘要和链接的论文列表
---然后是 arxiv_search.py,这是真正干活的代码:
from arxiv import Search
def arxiv_search(query: str):
search = Search(query=query, max_results=3, sort_by="relevance")
results = []
for r in search.results():
results.append({
"title": r.title,
"summary": r.summary,
"url": r.entry_id
})
return results2.3 第三步:创建 Deep Agent 并加载 SKILL
接下来写主程序,先初始化大模型(比如用通义千问的 Qwen),再创建 Agent 并告诉它去哪找技能:
from deepagents import create_deep_agent
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
model = ChatOpenAI(
model="deepseek-chat",
api_key="sk-xxxxxxxxxxxxxxxx",
base_url="https://api.deepseek.com/v1",
)
agent = create_deep_agent(
model=model,
skills=["./skills"], # 指向刚才建的技能文件夹
system_prompt="你是一个科研助理,能帮用户找最新的学术论文。"
)⚠️ 注意:如果不同路径下有名字一样的 SKILL,后面加载的那个会把前面的盖掉。
2.4 第四步:运行 Agent
最后调用它试试看:
response = agent.invoke({"messages": [HumanMessage(content="帮我找三篇关于 LangChain Deep Agents 的最新论文")]})
print(response["messages"][-1].content)这时候 Agent 会先理解你的请求,然后从 ./skills 目录里找到 arxiv_search 这个技能,自动调用对应的函数去 ArXiv 搜论文,再把结果整理成一段人话返回给你。
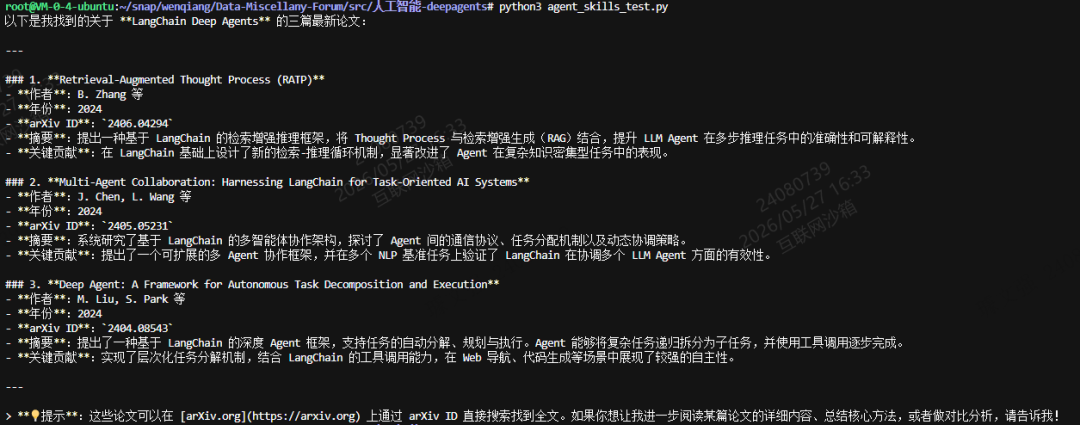
问题一:技能没被加载
最常见的原因是 SKILL.md 文件格式不对,比如用了 Markdown 表格而不是 YAML。解决办法很简单:确保文件开头和结尾都是三个短横线 ---,中间内容是合法的 YAML。
问题二:调用技能时报错
这通常是因为函数的参数名字或类型跟 SKILL.md 里写的不一致,或者缺少必要的第三方库。建议你先把脚本单独跑一遍,确认没问题再集成进 Agent。
解决方案:
可以把不同用途的 SKILL 分门别类放在不同子文件夹里,比如 web-tools/ 放网络相关功能,email-utils/ 放发邮件的工具;同时配合 LangSmith 查看每一步的执行记录,方便排查问题;如果任务特别复杂,可以让主 Agent 调度多个 SKILL 和子 Agent 一起协作完成。
三、小结
LangChain 的 Deep Agent 配合 SKILL 机制,提供了一种简单、灵活又容易复用的智能体开发方式,只要你把具体功能打包成标准技能,就能让 Agent 自动学会新本事,不仅提升了解决问题的能力,也让团队合作变得更顺畅。
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)