
13.LangChain框架4-文件读取
LangChain 大模型
·
内容参考于:图灵AI大模型全栈
rag的步骤
准备文档、对文档进行分割、转换向量、把向量存到向量数据库中
LangChain封装了一系列文档的加载模块
它支撑PDF、CSV、HTML、JSON、Markdown、File Directory等,常用的就是PDF
PDF解析很复杂,LangChain支持的不是很好,后面会有别的库来解析PDF,这里做个了解
安装库
pip install pypdf -i https://pypi.tuna.tsinghua.edu.cn/simple
PDF不好的点
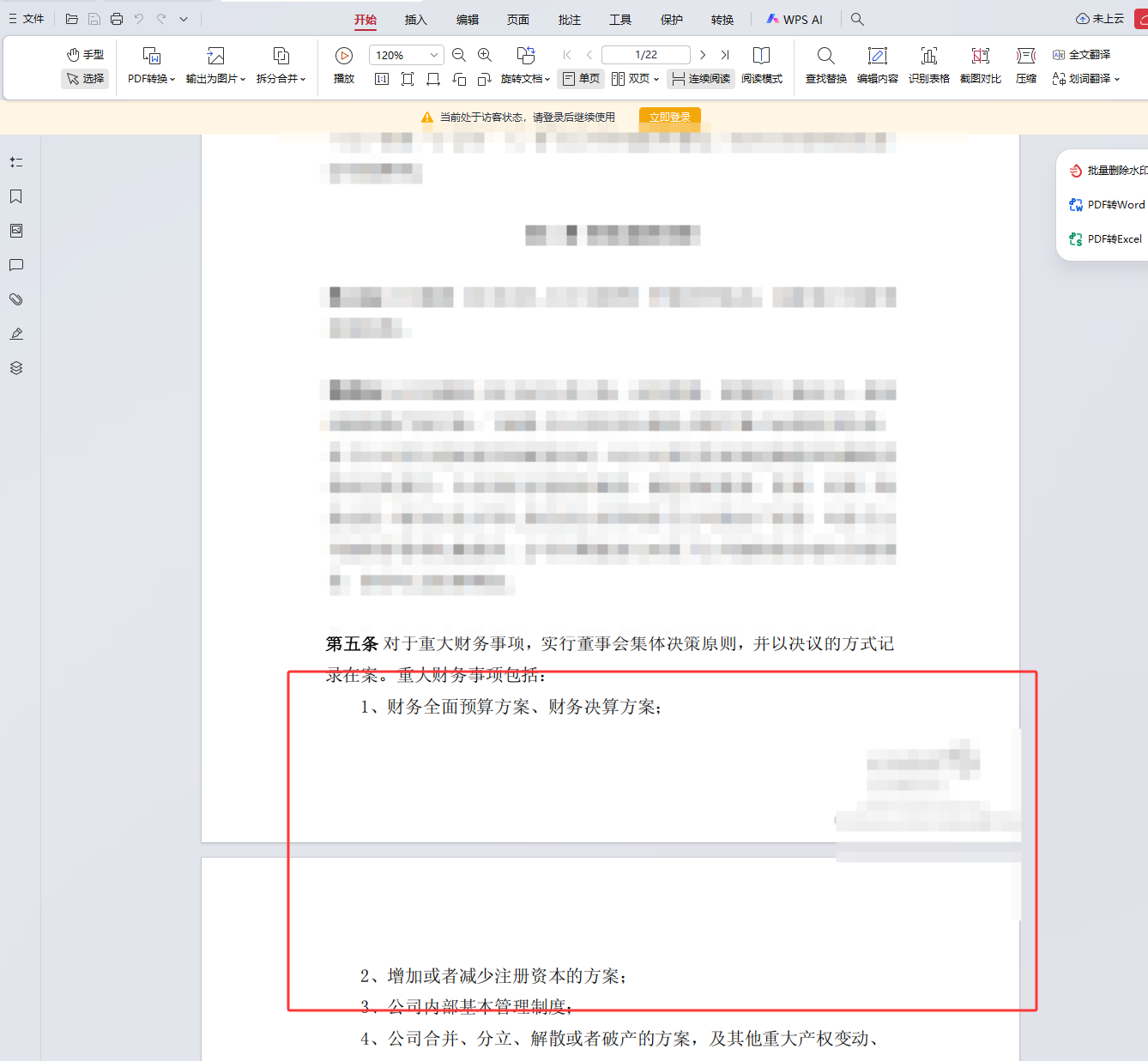
如下图,市面上一个库它都是按照一页一页的读取,如下图红框,第五条的内容进入到了第二页,这就导致语意有问题,一般会把PDF转成Markdown
如下图Markdown,它不会分页,一些格式它都带着,分片的时候就很友好
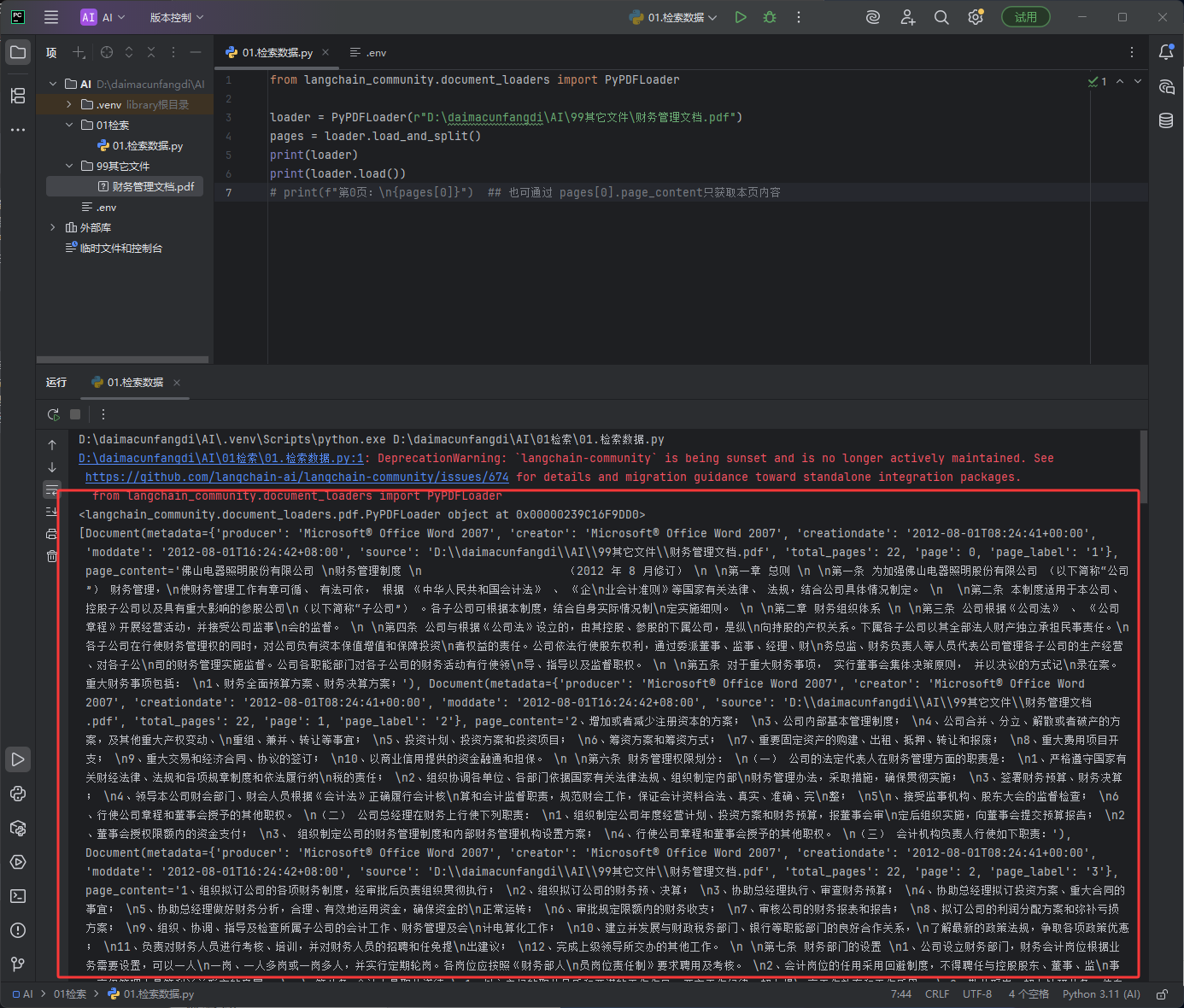
LangChain读取PDF
如下图读取全部数据
读取第一页数据
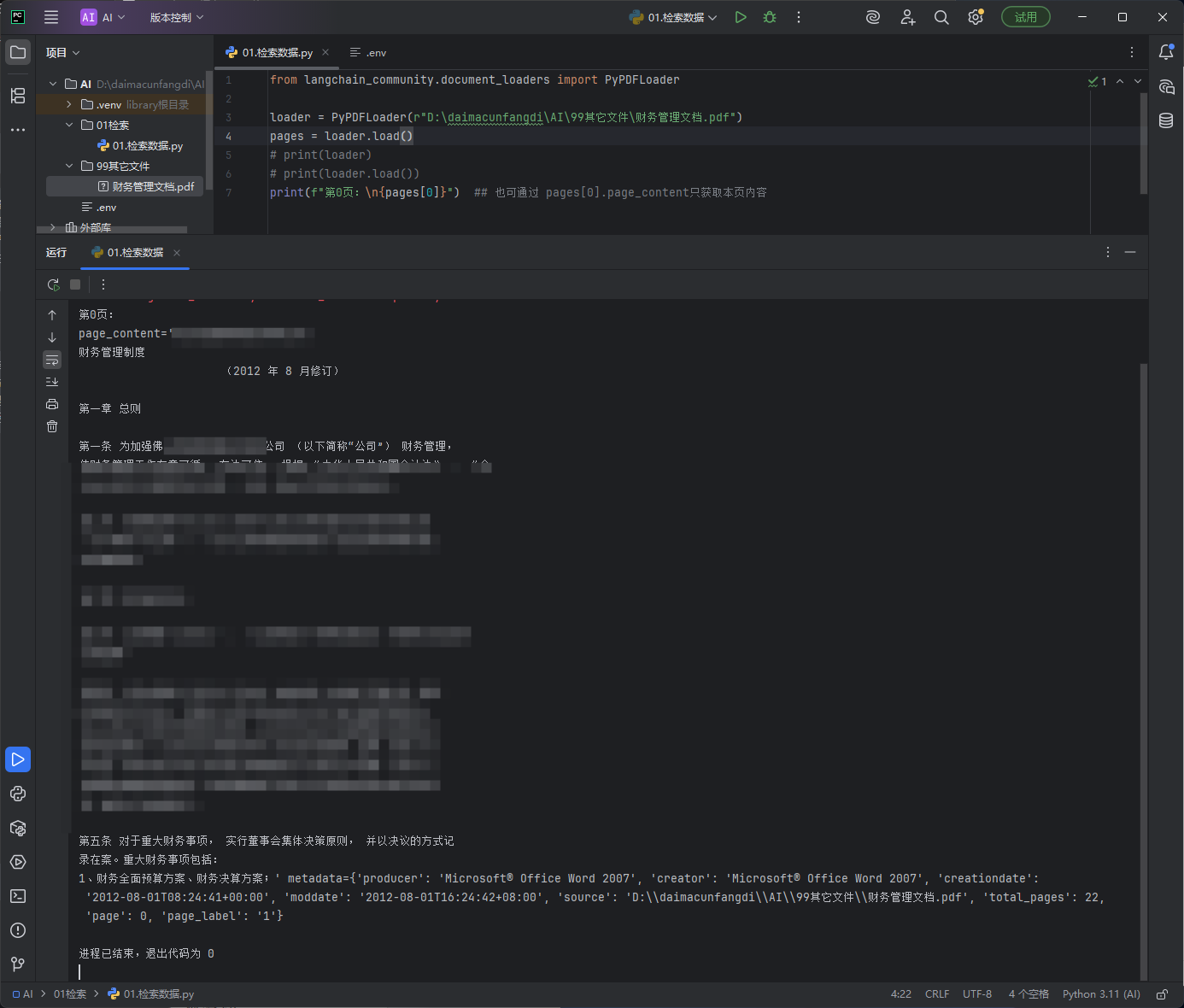
代码
# 导入LangChain社区提供的 PDF文档加载器 # 作用:专门读取本地PDF文件,提取PDF中的文本内容 from langchain_community.document_loaders import PyPDFLoader # ====================== 1. 创建PDF加载器实例 ====================== # 参数:传入本地PDF文件的【绝对路径】 # r"" 原生字符串:Windows系统专用,防止路径中的反斜杠 \ 被转义报错 loader = PyPDFLoader(r"D:\daimacunfangdi\AI\99其它文件\财务管理文档.pdf") # ====================== 2. 加载PDF文件 ====================== # loader.load():核心方法 # 作用:读取整个PDF文件,按**分页**提取文本,返回一个列表 # 列表中每一个元素 = PDF的一页(包含文本内容+页面元数据) pages = loader.load() # 打印加载器对象(调试用,一般不用) # print(loader) # 打印完整的PDF所有页面内容(内容多会刷屏) # print(loader.load()) # ====================== 3. 获取指定页面内容 ====================== # pages[0]:获取PDF的【第1页】(列表索引从0开始) # 输出包含:页面文本内容 + 元数据(来源文件、页码) print(f"第0页:\n{pages[0]}") # 【重要补充】pages[0].page_content:只获取第1页的【纯文本内容】(去掉元数据,最常用!) # print(f"第0页纯文本:\n{pages[0].page_content}")
LangChain读取Word
涉及的库,三个
pip install unstructured # 官网:https://docs.unstructured.io/welcome # 下载时需要开科学上网不然会报错File is not a zip file # 如果报错开科学上网之后 # import nltk # nltk.download('punkt') # nltk.download('averaged_perceptron_tagger') # 把nltk 重新加载 pip install python-doc pip install python-docx效果图:
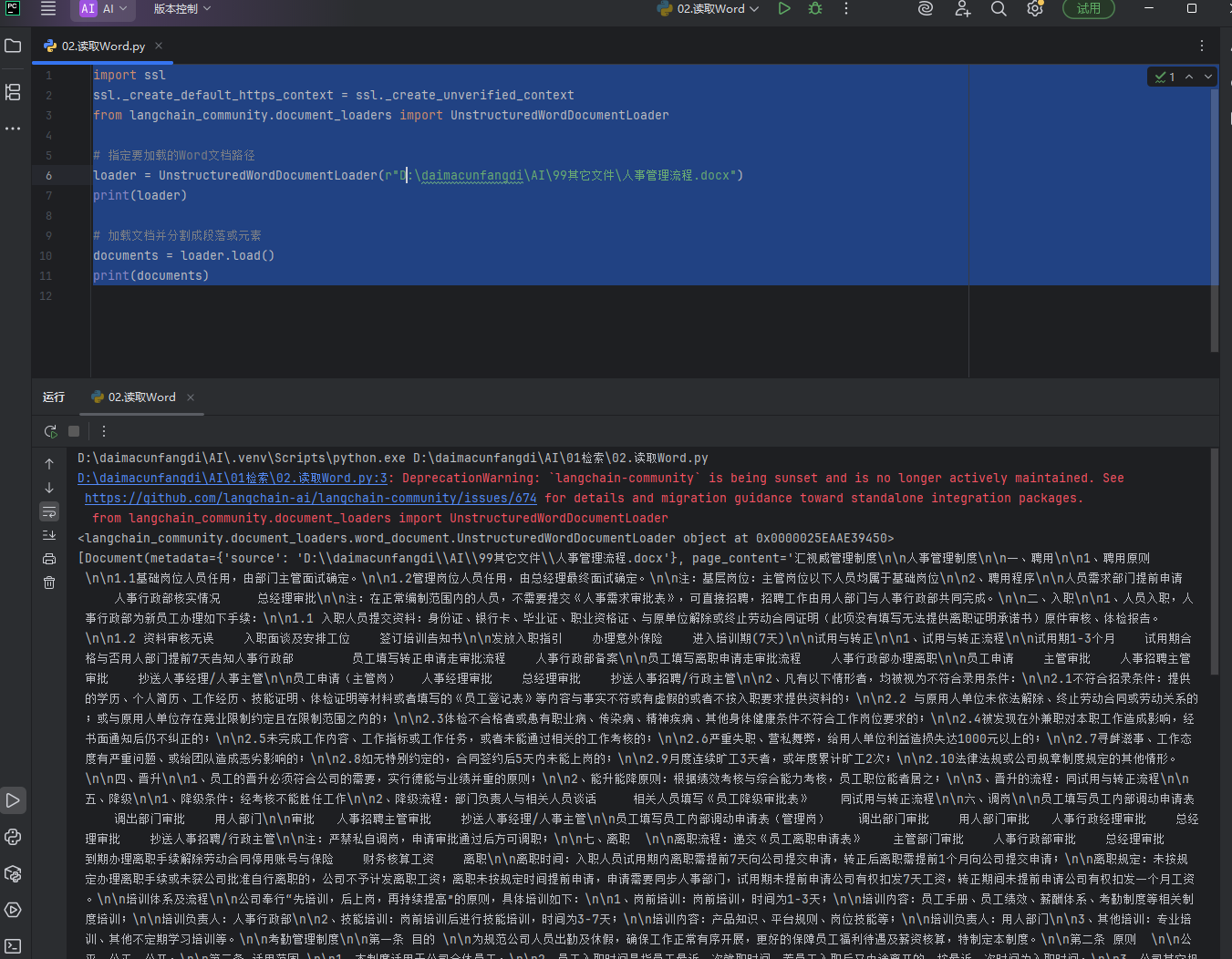
读取第一页
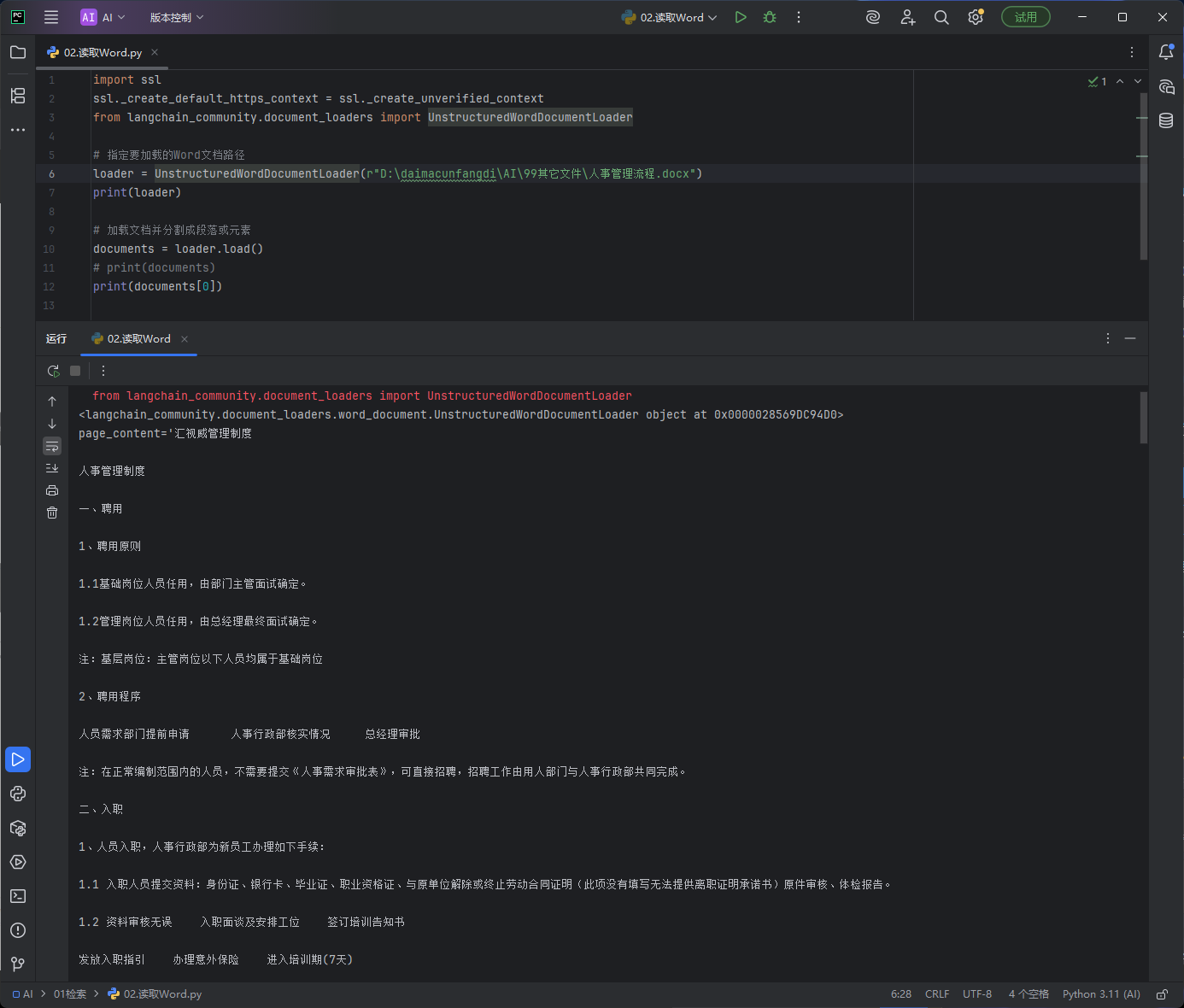
注意代码运行的时候要打开科学上网,LangChain它需要下载一个模型
# 解决Python网络请求的SSL证书报错 # 作用:关闭HTTPS证书验证,避免加载Word文档时出现网络/证书错误(固定写法,直接用) import ssl ssl._create_default_https_context = ssl._create_unverified_context # 导入LangChain专用的 Word文档加载器 # 功能:读取 .docx 格式的Word文件,提取文件内的所有文本内容 from langchain_community.document_loaders import UnstructuredWordDocumentLoader # ====================== 1. 创建Word文件加载器 ====================== # 参数:本地Word文件的绝对路径 # r"":原生字符串,Windows路径专用,防止\被转义导致报错 loader = UnstructuredWordDocumentLoader(r"D:\daimacunfangdi\AI\99其它文件\人事管理流程.docx") # 打印加载器对象(仅调试查看,无实际功能) print(loader) # ====================== 2. 读取并解析Word文档 ====================== # loader.load():核心方法 # 读取整个Word文件,返回 【文档列表】 # 注意:Word文件不会分页,整个文件是1个文档,所以列表里只有1个元素 documents = loader.load() # 打印完整文档列表(内容多会刷屏,所以注释了) # print(documents) # ====================== 3. 打印第一个文档对象 ====================== # documents[0]:获取列表中第1个(唯一)文档对象 # 包含两部分:page_content(纯文本) + metadata(文件元数据) print(documents[0])
读取在线文件
# 清华镜像源(加速下载,国内必用) # 1. 核心库:读取非结构化文档(Word、PDF、文本等)基础依赖 pip install -i https://pypi.tuna.tsinghua.edu.cn/simple unstructured # 2. PDF转图片:辅助解析PDF中的图片、复杂格式 pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pdf2image # 3. 图像处理库:配合pdf2image处理图片型PDF pip install -i https://pypi.tuna.tsinghua.edu.cn/simple opencv-python # 4. 高级文档解析:支持表格、图片文字、复杂排版解析 pip install -i https://pypi.tuna.tsinghua.edu.cn/simple unstructured-inference # 5. PDF底层处理库:加固PDF读取、解析能力 pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pikepdf效果图:
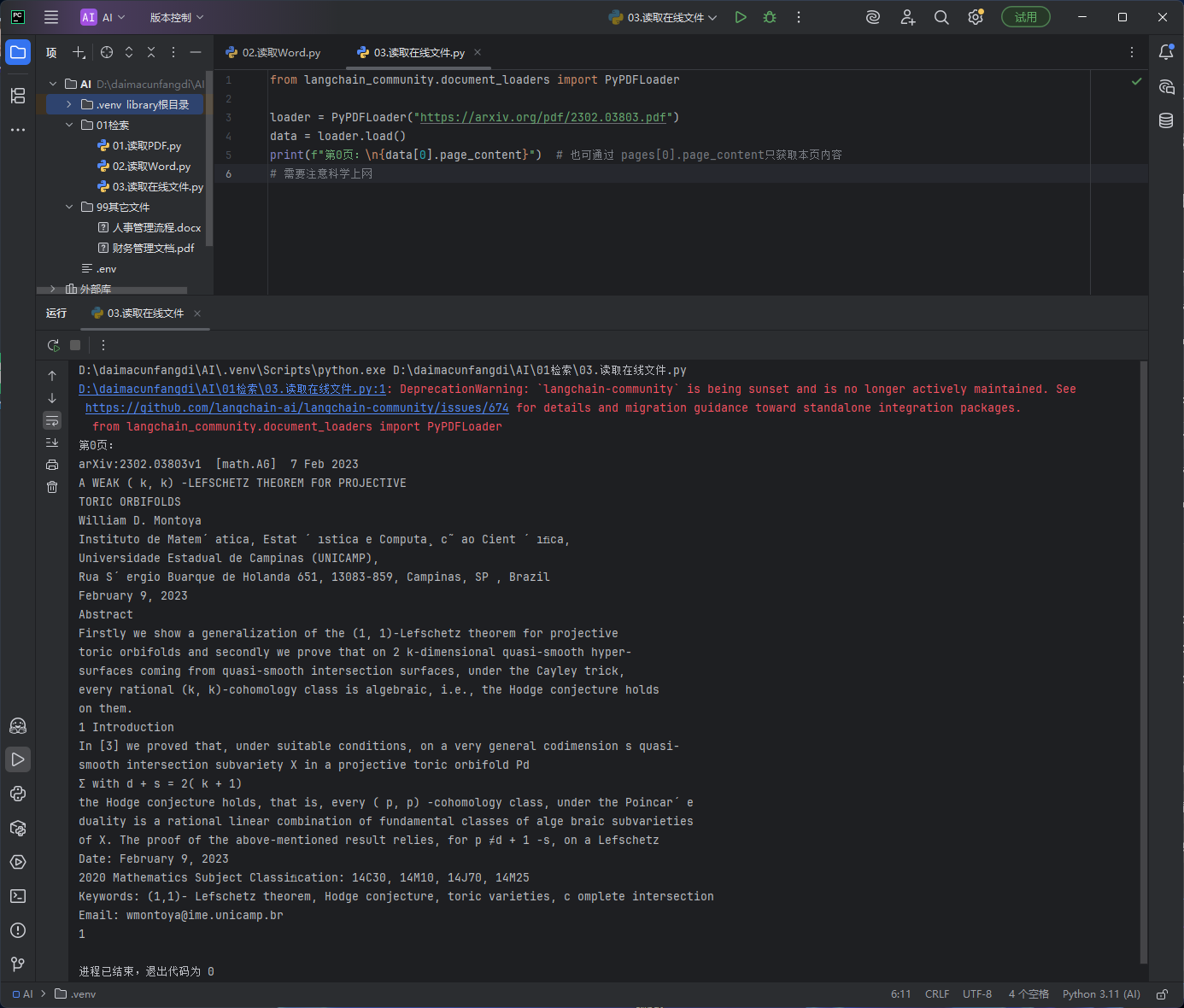
# 导入LangChain社区提供的PDF文档加载器 # 该加载器支持读取【本地PDF文件】和【在线PDF链接】,提取文档文本内容 from langchain_community.document_loaders import PyPDFLoader # 创建PDF加载器实例 # 传入在线PDF的网络链接(arxiv学术论文链接),PyPDFLoader可直接加载在线PDF loader = PyPDFLoader("https://arxiv.org/pdf/2302.03803.pdf") # 调用load()方法加载PDF文档 # 按PDF页面分页解析,返回一个文档列表,列表中每个元素对应PDF的一页 data = loader.load() # 打印PDF第0页(即第一页)的纯文本内容 # data[0].page_content:获取第一页文档的纯文本内容,不含元数据 print(f"第0页:\n{data[0].page_content}") # 也可通过 pages[0].page_content只获取本页内容 # 重要提示:arxiv属于境外网站,国内网络环境下需要科学上网才能正常访问并加载PDF # 需要注意科学上网


汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 5
5 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)