
我用 Codex + Alphalens,搭了一套适配 A 股的因子评估流水线
🔗 开源项目地址:https://github.com/zer0quant/zer0factor
这是因子投研自动化系列的第二篇。上一篇讲的是怎么用 Codex 做一个“从投资研报到股票因子”的 Skill,这一篇继续往下走:因子生成出来之后,怎么评估它到底有没有用。
上一篇文章里,我主要做了一件事:把“从研报到因子”的流程做成一个 Skill。
也就是说,AI 可以从研报里提取因子定义,生成结构化摘要,再根据确认后的定义生成因子代码。这个流程解决的是“因子从哪里来”的问题。
但因子生成出来之后,还有一个更重要的问题:
这些因子到底有没有效果?
这就来到因子从“能生成”走向“能使用”之前必须经过的一关:因子评估。
如果说上一篇是在解决“从研究想法到因子代码”,那么这一篇就是在补下一段链路:
从因子代码,到可复现、可批量、可比较的因子评估结果。
一、为什么不能直接套用默认 Alphalens?
因子评估里最有名的开源框架之一,是 Quantopian 开源的 Alphalens。
它的思路很经典:给定一组因子值,再给定对应的价格数据,就可以计算 forward return、IC、分组收益、分位数组合表现等指标。
不过原版 Alphalens 已经很久没有维护了,很多依赖都比较旧。后来社区里有一个维护版本叫 alphalens-reloaded,主要就是为了解决依赖老化的问题。
但即使换成 alphalens-reloaded,也还有一个问题:
Alphalens 的默认设计更偏美股市场,直接拿来评估 A 股因子,会有一些口径不匹配。
最典型的就是交易制度。
A 股是 T+1 交易制。今天收盘后算出来的因子,理论上不能用今天的收盘价买入。
更合理的做法是:
- T 日收盘后计算因子;
- T+1 才能交易;
- 更严谨一点,可以用 T+1 开盘后 15 分钟 TWAP 作为买入价格;
- 在日线版本里,先用 T+1 开盘价近似。
也就是说,A 股因子评估里,收益率口径通常更适合用开盘到开盘,而不是默认的收盘到收盘。
Alphalens 默认计算 forward return 的核心逻辑大概是:
returns = prices.pct_change(period)
forward_returns = returns.shift(-period).reindex(factor_dateindex)
等价于:
returns[t] = prices[t] / prices[t-period] - 1
forward_returns[t] = returns[t+period]
= prices[t+period] / prices[t] - 1
如果 period=5,那么 T 日的 5 日 forward return 就是:
price[T+5] / price[T] - 1
这就是 Alphalens 默认的 forward return 口径。
如果我们把传入的价格矩阵从 close 换成 open.shift(-1),那么 index 为 T 的价格,其实存的是 open[T+1]。
这时 Alphalens 算出来的就会变成:
open[T+N+1] / open[T+1] - 1
也就是从 T+1 开盘到 T+N+1 开盘的 N 日收益。
这个小改动很关键。
因为它把因子评估从“看起来能跑”,改成了更接近 A 股真实交易约束的口径。
二、因子评估的第一步,其实是定义股票池
第二个关键问题是:因子到底在哪个股票池里评估?
不同因子适合的股票池不一样。
比如基本面因子,对大市值、流动性更好的股票可能更稳定;动量类因子,可能在中小市值或某些特定风格股票里更明显。
而且股票池还有一个现实作用:过滤掉真实交易中不适合参与评估的股票。
比如:
- 涨停买不进去;
- 跌停卖不出来;
- 停牌没有可交易价格;
- ST / *ST 的涨跌幅制度不同;
- 退市整理股票的波动和交易逻辑特殊;
- 新股上市前几十天波动异常;
- 极小市值、极低流动性股票很容易带来虚假 alpha。
所以因子评估不能只问“这个因子有没有收益”,还要先问:
这个因子是在什么股票池里被评估的?
我这里先设计了一套小型股票池系统。
不同场景用不同股票池:
univ_research_base:基础研究池,用于中性化、标准化、因子横截面分析;univ_trade_base:基础交易池,用于全 A 候选选股;univ_trade_hs300:沪深 300 成分中满足交易过滤条件的股票池;univ_trade_zz500:中证 500 成分中满足交易过滤条件的股票池;univ_trade_zz1000:中证 1000 成分中满足交易过滤条件的股票池。
其中,univ_research_base 更偏研究口径,主要用于横截面分析和预处理:
univ_research_base =
A 股普通股票
∩ 当前交易日已上市
∩ 当前交易日未退市
∩ 非 ST / 非 *ST / 非退市整理
∩ 上市满 6 个月
∩ 过去 20 个交易日日均成交额 >= 1000 万
∩ 总市值排名不在全市场最后 2%
univ_trade_base 则在研究池基础上进一步加入交易约束:
univ_trade_base =
univ_research_base
∩ 当前交易日非停牌
∩ 当前交易日非一字涨停
∩ 当前交易日非一字跌停
∩ 总市值排名不在全市场最后 5%
指数股票池则在交易池基础上叠加历史指数成分:
univ_trade_hs300 =
univ_trade_base
∩ 沪深 300 历史成分股
univ_trade_zz500 =
univ_trade_base
∩ 中证 500 历史成分股
univ_trade_zz1000 =
univ_trade_base
∩ 中证 1000 历史成分股
这样做的好处是,股票池不是一坨写死的筛选条件,而是可以分层复用。
研究、交易、指数增强,不同场景可以使用不同股票池。
三、先补数据,再做股票池接口
股票池规则定下来之后,下一步就是看它依赖哪些数据。
比如要判断上市时间、退市状态、ST 状态、成交额、市值排名、涨跌停、停牌、指数成分,就需要在本地数据系统里继续补数据。
我把这个需求交给 Codex,让它先分析 zer0share 项目里还缺哪些数据,再补对应的数据同步模块。
这里顺便穿插一个小工具。
这段时间我在项目里开始重度使用 andrej-karpathy-skills。这个 skill 的灵感来自 Andrej Karpathy 对 LLM 编程陷阱的总结,比如模型会在编程时做错误假设、一路执行到底,或者过度工程。
实际用下来,我感觉它在编码任务里比 superpowers 更轻一些,token 消耗也更少。做这类工程化需求时,可以试试。
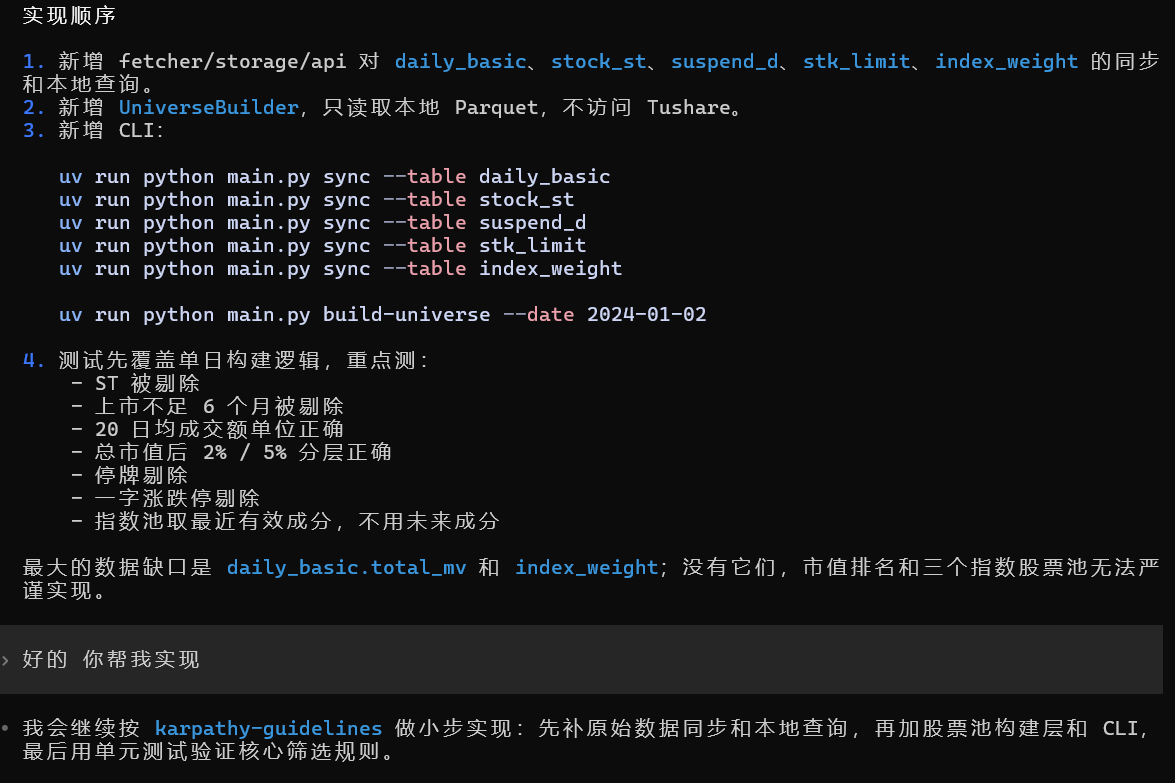
数据补完之后,就可以通过接口直接获取股票池。

到这里,因子评估的第一个基础模块就完成了:
在评估因子之前,先明确它在哪个股票池里被评估。
四、因子价格口径:我选择后复权
第三个问题是价格口径。
做因子计算和收益率评估时,价格到底用不复权、前复权,还是后复权?
这里我更倾向于使用后复权价格。
原因也比较简单:
- 不复权价格会受到分红、送股、转增、配股等公司行为影响,收益率不连续;
- 前复权价格会随着每次新的复权事件重新调整历史价格,不适合长期落盘和复用;
- 后复权价格能保持收益率连续,同时更方便在本地系统里存储和计算。
这也是前面文章里补复权因子的原因。
有了原始价格和复权因子,后复权价格可以按需合成;评估因子时,就可以在统一口径下计算收益率。
五、因子评估前,必须先做预处理
接下来是因子数据本身。
一个原始因子直接拿去评估,通常是不够的。
标准的截面因子预处理,一般包含四个步骤:
去极值 → 缺失值填补 → 标准化 → 中性化
这四步的顺序很重要。
而且这里还有一个细节:预处理应该在前面定义好的股票池里进行,比如先用 univ_trade_base 作为基础范围。
1. 去极值
金融数据经常有厚尾分布。少数异常值可能来自财报异常、停牌复牌、极端行情,或者数据本身的问题。
如果不处理,这些异常值会严重影响均值、标准差、回归和后续因子排序。
常见做法有几种:
- MAD 中位数绝对偏差法:更鲁棒,不容易被极端值本身污染;
- 3-sigma 法:直观,但在偏态严重的 A 股数据里容易被极值影响;
- 百分位法:直接把上下分位之外的值截断到边界。
我这里更倾向于 MAD 或百分位法,先把极端值控制住。
2. 缺失值填补
A 股里缺失值很常见。
可能是停牌,也可能是新股历史窗口不够,或者某些基本面字段缺失。
常见处理方式包括:
- 用行业均值或行业中位数填补;
- 行业数据缺失时退化为全市场均值;
- 对某些量价因子,直接剔除缺失股票。
具体选哪种,要看因子类型。
3. 标准化
不同因子的量纲差异很大。
比如换手率可能在 0.01 到 0.1 之间,市值则是非常大的数。如果后续要做多因子合成,必须把它们放到可比较的尺度上。
常见做法是:
- Z-score 标准化:转换成均值为 0、标准差为 1;
- Rank 标准化:转换成截面排序分位数,对异常值更不敏感。
4. 中性化
这一步在 A 股里非常重要。
很多因子如果不做中性化,最后测出来的可能不是因子本身,而是“小市值暴露”或者“行业暴露”。
常见做法是做截面回归,把因子对市值和行业的暴露剔除掉,取残差作为中性化后的因子:
f i = β 1 ⋅ S i z e i + ∑ j = 1 K β j ⋅ I n d u s t r y i , j + ϵ i f_i = \beta_1 \cdot Size_i + \sum_{j=1}^{K} \beta_j \cdot Industry_{i,j} + \epsilon_i fi=β1⋅Sizei+j=1∑Kβj⋅Industryi,j+ϵi
其中:
Size通常使用流通市值或总市值的对数;Industry通常使用申万一级行业或中信一级行业哑变量;- 残差 ϵ i \epsilon_i ϵi 就是中性化后的因子。
我把这套预处理流程交给 Codex,让它设计完整的 factor preprocessing pipeline。
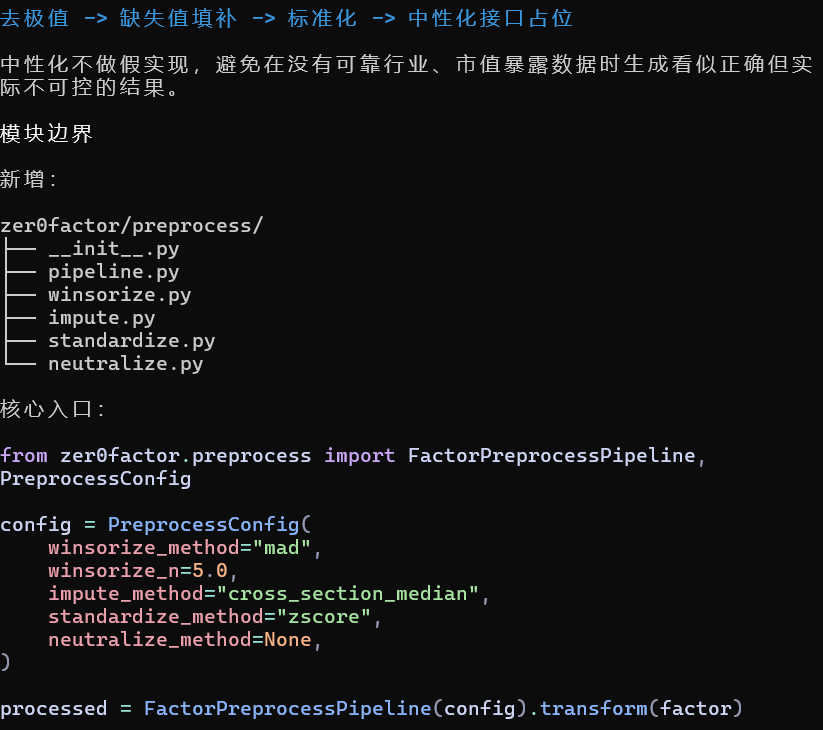
这里有个细节:市值本身也应该作为一个因子入库。
因为中性化需要用到市值暴露,而且市值本身也需要经过去极值、标准化等处理。

编码完成之后,市值相关因子也可以正常入库。
六、为了中性化,还要补行业数据
中性化除了依赖市值,还需要行业分类。
于是我又让 Claude Code 去查 Tushare 官方文档,确认是否有可用的行业数据接口。
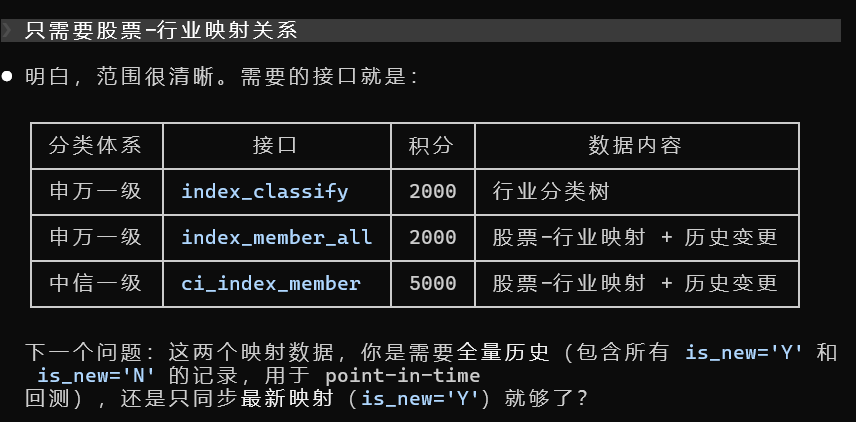
确认之后,把相关数据同步到本地。
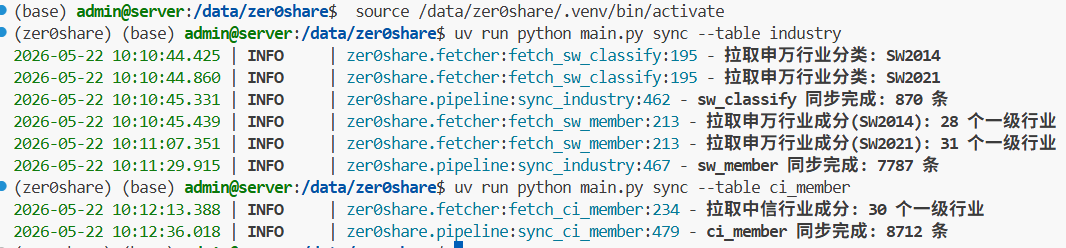
市值和行业数据都有了之后,再让 Codex 继续实现之前占位的中性化逻辑。
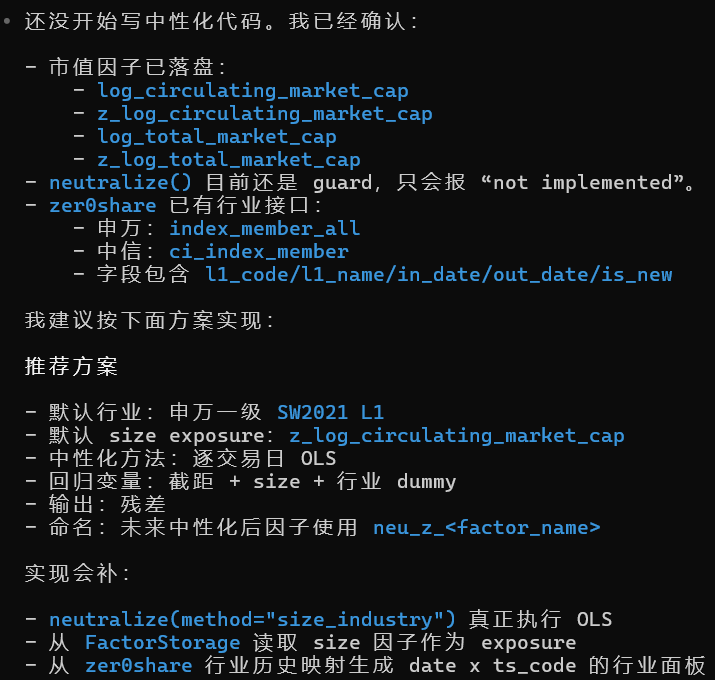
然后运行命令,测试中性化流程是否能正常跑通。

到这里,因子评估前的准备工作基本完成:
- 有股票池;
- 有后复权价格;
- 有市值因子;
- 有行业分类;
- 有预处理 pipeline;
- 可以对因子做去极值、缺失值处理、标准化和中性化。
七、先用 Notebook 跑通单因子评估
预处理完成之后,下一步就是单因子测试。
我先没有急着做自动化 pipeline,而是用 Notebook 把完整流程跑通一遍。
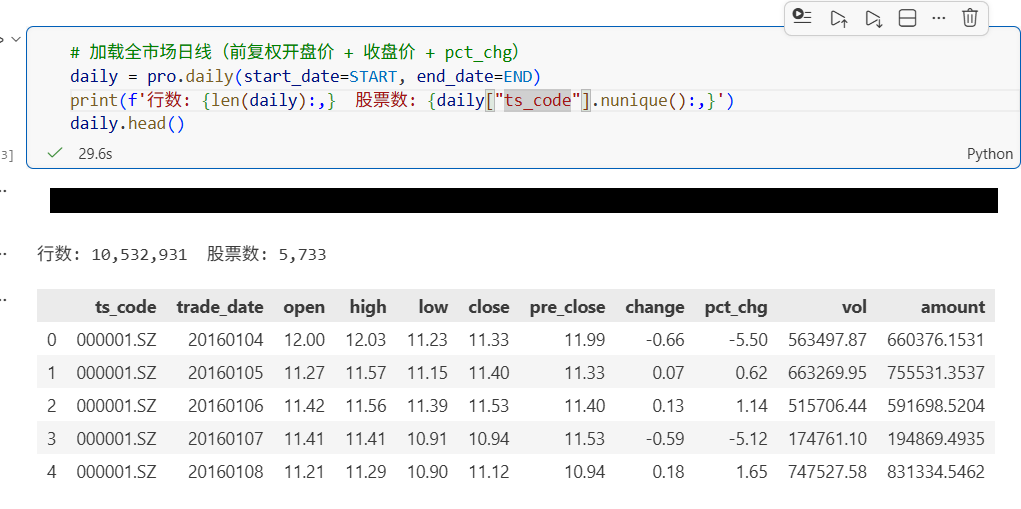
第一步,加载日线数据。
第二步,加载已经做过预处理的因子数据,包括去极值、缺失值处理、标准化、中性化等结果。
第三步,构建价格矩阵和因子矩阵。
这里有个关键细节:价格矩阵使用的是第二天的 open,对应前面说的 A 股 T+1 交易口径。

第四步,构建因子收益率和分组数据。
最后生成因子评估报告。
Alphalens 默认的 create_full_tear_sheet 信息很多,但对我这个阶段来说有点复杂,而且样式也不太适合直接看。
于是我让 Codex 帮我简化了一版报告,变成更适合快速判断的形式。
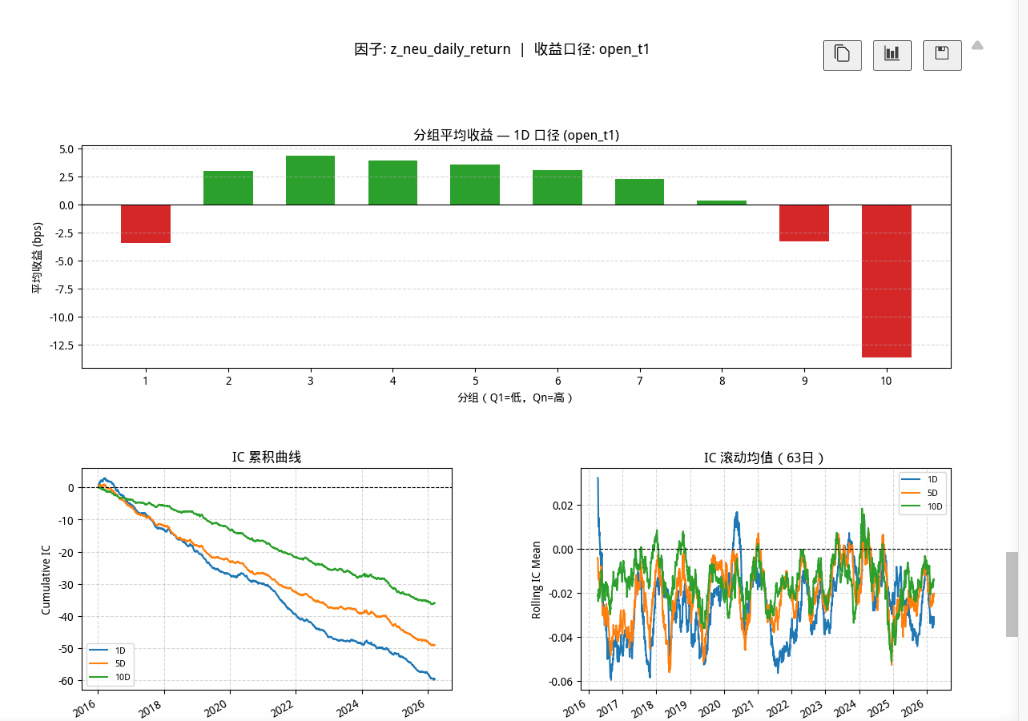
这版报告还比较粗糙,但它至少说明一件事:
单因子评估的最小闭环已经跑通了。
八、从 Notebook 到自动化评估 Pipeline
Notebook 适合探索,但不适合长期批量评估。
如果每次评估一个因子,都要手动打开 Notebook、改因子名、跑单元格、看图表,效率会很低。
所以我决定把前面的流程封装成一个自动化的因子评估 pipeline。
我分别让 Codex GPT-5.5 和 Claude 4.6 设计整体方案。对比下来,Codex GPT-5.5 给出的数据流更清晰,也更贴近这个项目当前的结构。
整体数据流大概是这样:

然后我让 Codex 自动实现第一版。
最终,第一版自动化因子评估已经可以正常运行。

到这里,因子评估就从“Notebook 里的手工流程”,变成了“可以通过命令行触发的标准流程”。
九、批量评估:先用简单规则筛选因子
单个因子能评估之后,很自然就会遇到下一个问题:
因子多了以后,不可能每个都手工打开报告看一遍。
所以我先做了一个很简单的筛选逻辑:
IC Mean > 0.02ICIR > 0.3
这不是最终标准,只是一个初筛规则,用来快速找到值得进一步看的因子。
然后顺手生成一份汇总报告。
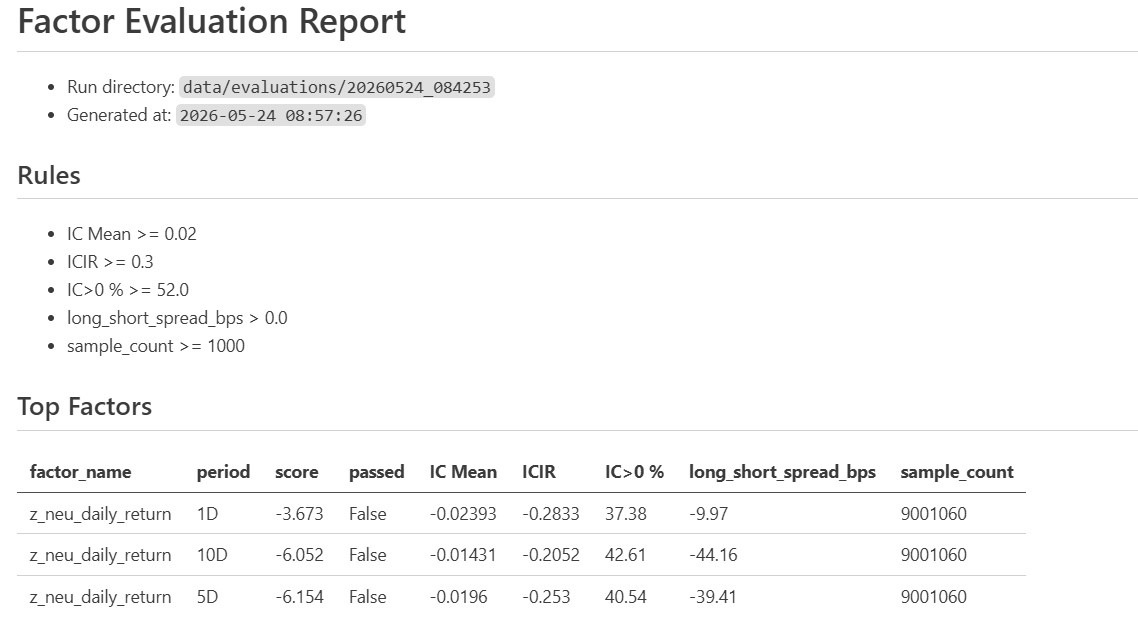
这版报告也还比较简陋,但已经比一个个手动翻表格要好很多。
接着我发现,评估和生成报告还是两个命令,每次都要输入两次。
于是继续往前推进:把评估和报告生成合并起来,用配置文件驱动。
配置文件大概是这样:

然后一次运行命令,就可以开始批量评估。
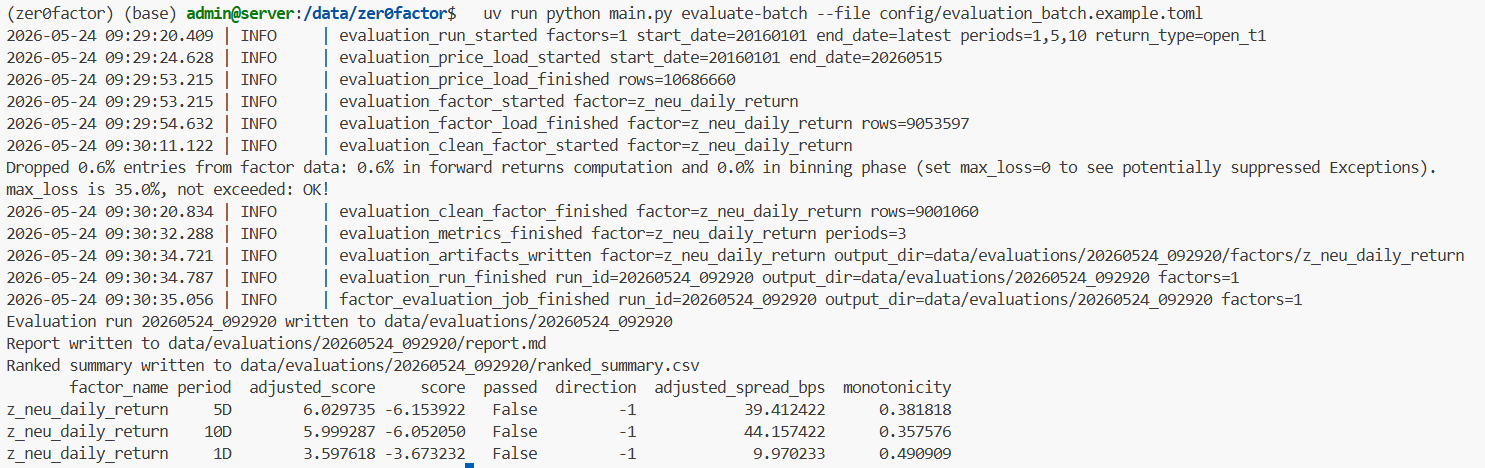
这一步之后,使用方式明显顺了很多。
用户只需要改配置,不需要每次手工拼命令。
十、再补一个 Factor Registry
批量评估还有一个小问题:每次都要在配置里手写因子名。
这件事短期可以忍,但因子越来越多之后就会变得很烦。
更好的方式是维护一个 factor registry:
- 所有因子统一注册;
- 每个因子有自己的名称、类型、路径和状态;
- 配置文件可以引用注册列表;
- 其他命令也统一从注册器读取因子信息。
于是我又让 Codex 设计了一版 factor registry。

后面我用 Claude Code superpowers 开发这个需求。
这块花了比较久,大概 40 分钟。对比下来,Codex GPT-5.5 在这类工程实现上的速度确实更快一些。
接着看一下现在数据库里的因子列表:
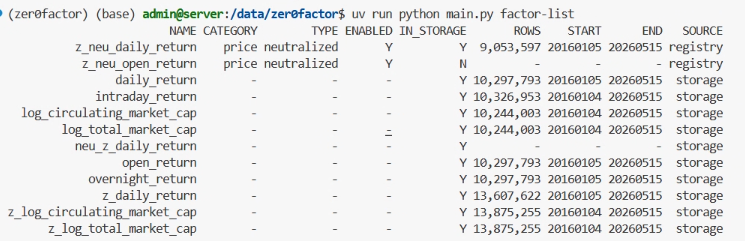
现在评估配置文件可以直接引用因子注册列表。
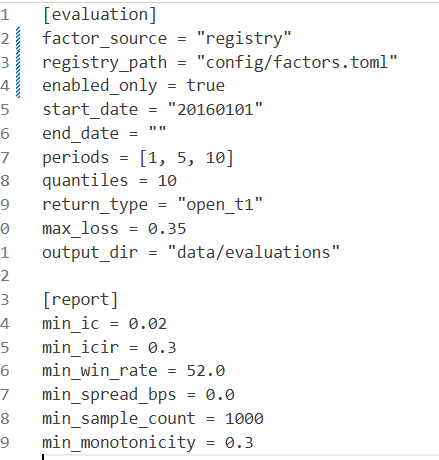
这样后续新增因子时,只需要维护注册列表,批量评估、报告生成、其他命令都可以统一读取。
这个小模块看起来不大,但它对长期维护很重要。
因为一旦因子数量多起来,真正麻烦的不是“再多写一个函数”,而是怎么管理这些因子。
十一、继续补评估指标体系
最后一步,是优化评估指标。
最早那版报告能跑,但指标太少,只能粗略判断一个因子有没有信号。
真正做因子研究时,通常还要看更丰富的指标,比如:
- IC 均值;
- ICIR;
- Rank IC;
- 分组收益;
- 多空收益;
- 分层单调性;
- 换手率;
- 不同持有期表现;
- 不同股票池表现。
我又参考了一些券商研报里的因子评估指标,让 Codex 帮我继续优化指标体系。

重新运行命令后,最终展示出来的指标更加丰富。
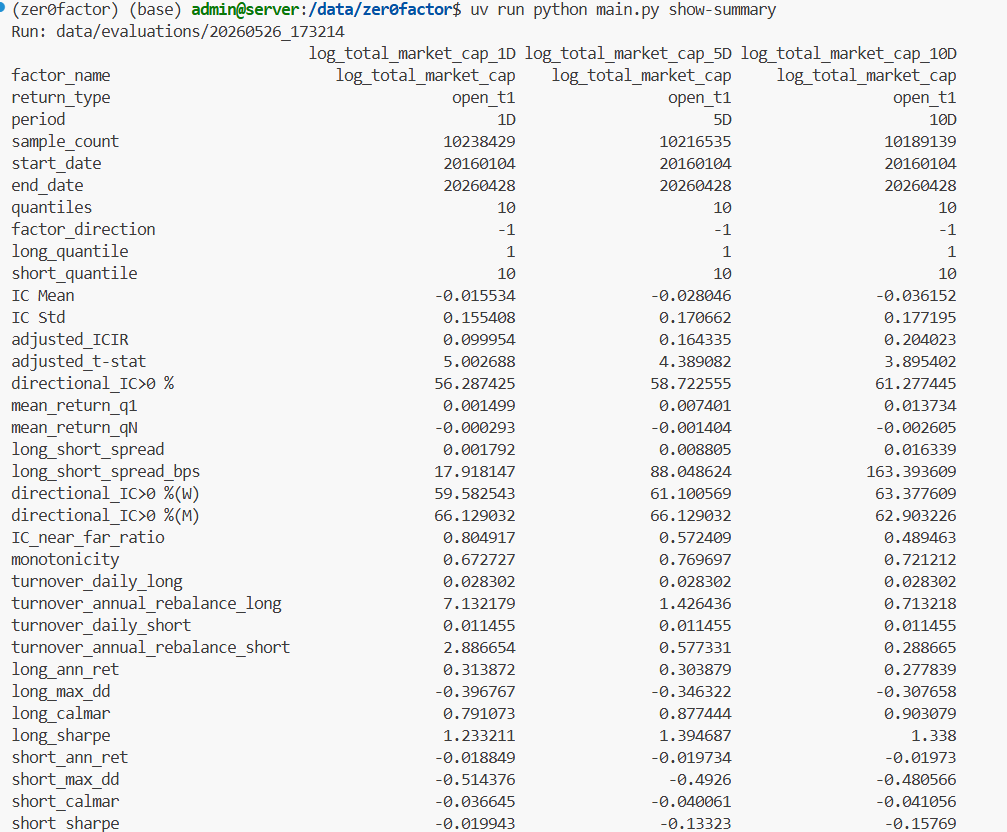
这里我有意保留了更多指标。
因为现阶段最重要的不是只给一个“好 / 不好”的结论,而是尽量保留足够多的评估维度,方便后续继续分析。
十二、这次最大的收获:因子评估不是一个函数,而是一条流水线
这次做完之后,我最大的感受是:
因子评估不是简单调用一次 Alphalens,而是一条完整的数据流水线。
如果只看表面,好像就是输入 factor 和 price,然后生成一份 tear sheet。
但真正放到 A 股、本地数据系统和长期研究工作流里,前面其实有几类问题必须先想清楚:
- 收益率口径怎么定义,是否符合 T+1 交易约束;
- 股票池怎么划分,哪些股票应该被排除在评估之外;
- 原始因子要不要做去极值、缺失值处理、标准化和中性化;
- 评估流程怎么批量化,因子和报告结果怎么统一管理。
这些问题不先想清楚,因子评估很容易变成“报告生成器”。
看起来图表很多,但你不确定口径是不是对的,也不确定结果能不能复现。
所以我这次更关注的不是某一个指标,而是把整条链路标准化:
数据准备 → 股票池构建 → 因子注册 → 因子预处理 → forward return 计算 → 单因子评估 → 批量评估 → 报告生成。
这条链路打通之后,后面再接新的因子,就不会每次都从头搭环境、改 Notebook、拼命令。
一起交流
如果你也在做类似的量化数据系统、因子评估流水线,或者对 AI 投研工程化感兴趣,可以通过公众号菜单「认识我」找到我交流。
我平时更关注数据系统、工具链和研究流程的工程化,也欢迎一起聊聊这些方向。
参考链接
- 本文开源项目:zer0factor
- 本地数据系统项目:zer0share
- Alphalens:quantopian/alphalens
- alphalens-reloaded:stefan-jansen/alphalens-reloaded
如果这篇文章对你有帮助
- ⭐ Star 一下项目:https://github.com/zer0quant/zer0factor
- 也可以看看前面的本地数据系统项目:https://github.com/zer0coldai/zer0share
- 关注公众号,后面继续更新因子投研自动化、因子评估和本地量化系统
我们下篇见。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)